






目录
案例一
案例二
同样是求解案例1的问题,这里我们在定义目标函数时不加ea.Problem.single标记。这意味着evalVars()传入的是一个Numpy ndarray二维数组。下面直接看代码:
1.问题

2.代码
# 构建问题
r = 1 # 模拟该案例问题计算目标函数时需要用到的额外数据
def evalVars(Vars): # 定义目标函数(含约束)
ObjV = np.sum((Vars - r) ** 2, 1, keepdims=True) # 计算目标函数值
x1 = Vars[:, [0]] # 把Vars的第0列取出来
x2 = Vars[:, [1]] # 把Vars的第1列取出来
CV = np.hstack([(x1 - 0.5) ** 2 - 0.25,
(x2 - 1) ** 2 - 1]) # 计算违反约束程度
return ObjV, CV # 返回目标函数值矩阵和违反约束程度矩阵
problem = ea.Problem(name='soea quick start demo',
M=1, # 目标维数
maxormins=[1], # 目标最小最大化标记列表,1:最小化该目标;-1:最大化该目标
Dim=5, # 决策变量维数
varTypes=[0, 0, 1, 1, 1], # 决策变量的类型列表,0:实数;1:整数
lb=[-1, 1, 2, 1, 0], # 决策变量下界
ub=[1, 4, 5, 2, 1], # 决策变量上界
evalVars=evalVars)
# 构建算法
algorithm = ea.soea_SEGA_templet(problem,
ea.Population(Encoding='RI', NIND=20),
MAXGEN=50, # 最大进化代数。
logTras=1, # 表示每隔多少代记录一次日志信息,0表示不记录。
trappedValue=1e-6, # 单目标优化陷入停滞的判断阈值。
maxTrappedCount=10) # 进化停滞计数器最大上限值。
# 求解
res = ea.optimize(algorithm, seed=1,
verbose=True, drawing=1,
outputMsg=True, drawLog=False, saveFlag=True, dirName='result')
3. 分析
可以发现,发生最大变化的是目标函数的定义上。不加ea.Problem.single标记后,传入目标函数evalVars()的参数Vars是一个Numpy ndarray二维数组。它是NIND行Dim列。NIND即种群的个体数,即种群规模;Dim即自定义的问题的决策变量个数。
因此我们可以用Numpy向量化的方法同时算出所有个体对应的目标函数值和违反约束程度值。结果分别保存为ObjV和CV。其中ObjV是一个NIND行1列的Numpy ndarray二维数组。CV是一个NIND行2列的Numpy ndarray二维数组。
案例三
1.问题
用NSGA2算法求解下面的双目标优化问题:

下面展示第二种风格——“面向对象”风格的写法:
2.代码
class MyProblem(ea.Problem): # 继承Problem父类
def __init__(self):
name = 'MyProblem' # 初始化name(函数名称,可以随意设置)
M = 2 # 优化目标个数
maxormins = [1] * M # 初始化maxormins(目标最小最大化标记列表,1:最小化该目标;-1:最大化该目标)
Dim = 1 # 初始化Dim(决策变量维数)
varTypes = [0] # 初始化varTypes(决策变量的类型,0:实数;1:整数)
lb = [-10] # 决策变量下界
ub = [10] # 决策变量上界
lbin = [1] # 决策变量下边界(0表示不包含该变量的下边界,1表示包含)
ubin = [1] # 决策变量上边界(0表示不包含该变量的上边界,1表示包含)
# 调用父类构造方法完成实例化
ea.Problem.__init__(self, name, M, maxormins, Dim, varTypes, lb, ub, lbin, ubin)
def evalVars(self, Vars): # 目标函数
f1 = Vars ** 2
f2 = (Vars - 2) ** 2
ObjV = np.hstack([f1, f2]) # 计算目标函数值矩阵
CV = -Vars ** 2 + 2.5 * Vars - 1.5 # 构建违反约束程度矩阵
return ObjV, CV
# 实例化问题对象
problem = MyProblem()
# 构建算法
algorithm = ea.moea_NSGA2_templet(problem,
ea.Population(Encoding='RI', NIND=50),
MAXGEN=200, # 最大进化代数
logTras=0) # 表示每隔多少代记录一次日志信息,0表示不记录。
# 求解
res = ea.optimize(algorithm, seed=1,
verbose=False, drawing=1,
outputMsg=True, drawLog=False, saveFlag=False, dirName='result')
3.结果
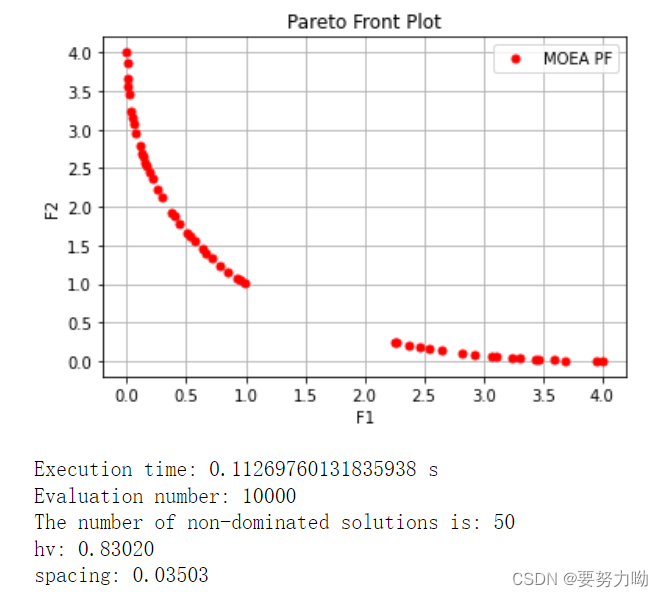
ea.moea_NSGA2_templet(
problem,
population,
MAXGEN=None,
MAXTIME=None,
MAXEVALS=None,
MAXSIZE=None,
logTras=None,
verbose=None,
outFunc=None,
drawing=None,
dirName=None,
**kwargs,
)
Docstring:
moea_NSGA2_templet : class - 多目标进化NSGA-II算法类
算法描述:
采用NSGA-II进行多目标优化,算法详见参考文献[1]。
参考文献:
[1] Deb K , Pratap A , Agarwal S , et al. A fast and elitist multiobjective
genetic algorithm: NSGA-II[J]. IEEE Transactions on Evolutionary
Computation, 2002, 6(2):0-197.
4.分析
这里通过构建geatpy问题类Problem的子类来定义问题。第14行定义了目标函数evalVars,它重写了Problem类中的evalVars()。注意这个名字不能随便更改。Geatpy的Problem问题类提供两种目标函数的定义,分别是evalVars和aimFunc。前者(evalVars)是Geatpy2.7.0之后新增的写法,它传入决策变量矩阵Vars且需要返回对应的目标函数值矩阵ObjV和违反约束程度矩阵CV(若待求解的问题没有约束条件,则可以只返回目标函数矩阵)。后者(aimFunc)是传统的写法,它传入一个种群对象,且不需要返回值。
采用aimFunc()的传统写法如下:
class MyProblem(ea.Problem): # 继承Problem父类
def __init__(self):
name = 'MyProblem' # 初始化name(函数名称,可以随意设置)
M = 2 # 优化目标个数
maxormins = [1] * M # 初始化maxormins(目标最小最大化标记列表,1:最小化该目标;-1:最大化该目标)
Dim = 1 # 初始化Dim(决策变量维数)
varTypes = [0] # 初始化varTypes(决策变量的类型,0:实数;1:整数)
lb = [-10] # 决策变量下界
ub = [10] # 决策变量上界
lbin = [1] # 决策变量下边界(0表示不包含该变量的下边界,1表示包含)
ubin = [1] # 决策变量上边界(0表示不包含该变量的上边界,1表示包含)
# 调用父类构造方法完成实例化
ea.Problem.__init__(self, name, M, maxormins, Dim, varTypes, lb, ub, lbin, ubin)
def aimFunc(self, pop): # 目标函数
Vars = pop.Phen # 获取决策变量矩阵,它等于种群的表现型矩阵Phen
f1 = Vars ** 2
f2 = (Vars - 2) ** 2
pop.ObjV = np.hstack([f1, f2]) # 计算目标函数值矩阵,赋值给种群对象的ObjV属性
pop.CV = -Vars ** 2 + 2.5 * Vars - 1.5 # 构建违反约束程度矩阵,赋值给种群对象的CV属性
# 实例化问题对象
problem = MyProblem()
# 构建算法
algorithm = ea.moea_NSGA2_templet(problem,
ea.Population(Encoding='RI', NIND=50),
MAXGEN=200, # 最大进化代数
logTras=0) # 表示每隔多少代记录一次日志信息,0表示不记录。
# 求解
res = ea.optimize(algorithm, seed=1,
verbose=False, drawing=1, outputMsg=True,
drawLog=False, saveFlag=False, dirName='result')
Geatpy的种群信息保存在种群对象中。Geatpy中有Population单染色体种群类(每个个体只有一条染色体)和PsyPopulation多染色体种群类(每个个体有多条染色体)。Population种群对象主要拥有以下属性:Encoding(染色体编码方式)、sizes(种群规模)、ChromNum(染色体条数(Population类的对象这里ChromNum固定为1))、Field(译码矩阵)、Chrom(染色体矩阵)、Lind(染色体长度)、ObjV(目标函数值矩阵)、FitnV(适应度列向量)、CV(违反约束程度值矩阵)、Phen(种群表现型矩阵(等价于决策变量组成的矩阵))。【详见《Geatpy数据结构】
案例四
调用内置的benchmark测试问题。
Geatpy2.7.0把已实现的测试问题归档进了benchmarks文件夹中。比如ZDT1、DTLZ1、WFG1,等等。以DTLZ1为例,可以通过ea.benchmarks.DTLZ1()直接实例化DTLZ1问题对象。用NSGA3算法求解DTLZ1的代码如下:
problem = ea.benchmarks.DTLZ1() # 生成问题对象
# 构建算法
algorithm = ea.moea_NSGA3_templet(problem,
ea.Population(Encoding='RI', NIND=100),
MAXGEN=500, # 最大进化代数。
logTras=1) # 表示每隔多少代记录一次日志信息,0表示不记录。
# 求解
res = ea.optimize(algorithm, verbose=True, drawing=1, outputMsg=True, drawLog=True, saveFlag=True, dirName='result')














 8197
8197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









