







Elasticsearch 最少必要知识实战教程直播回放
引言
Elasticsearch上海Meetup中ebay工程师提了索引生命周期管理的概念。的确,在Demo级别的验证阶段我们数据量比较小,不太需要关注索引的生命周期,一个或几个索引基本就能满足需要。所以,这也会产生一种假象,认为:“Elasticsearch不就是增删改查,毛毛雨啦”的荒诞的假象。
但是,在实战开发的生产环境中,索引的动态模板设置、索引Mapping设置、索引分片数/副本数设置、索引创建、打开、关闭、删除的全生命周期的管理必须高度关注,做好提前知识储备,
否则,会在开发后期出现由于数据激增暴露架构设计不合理问题,甚至引发分片/节点数据丢失、集群宕机等严重问题。
1、什么是Elasticsearch索引生命周期管理?
Elasticsearch索引生命周期管理指:Elasticsearch从设置、创建、打开、关闭、删除的全生命周期过程的管理。
Elasticsearch生产环境中一般采用多索引结合基于时间、基于空间的横向扩展的方式存储数据,随着数据量的增多,不用修改索引的底层架构逻辑。
2、索引生命周期管理为什么重要?
索引管理决定Elasticsearch鲁棒性、高可用性。
索引管理和搜索、插入性能也密切相关。
实际场景例子:100节点的集群中某一个节点数据丢失后,GET /_cat/nodes?v 接口的返回时延时延非常大,接近5-8s。搜索、聚合的性能更不必说。
原因:节点丢失后,ES会自动复制分片到新的节点中去,但是该丢失节点的shard非常大(几百个GB甚至上TB),集群当时的写入压力也非常大。这么大量级的数据拷贝和实时写入,最终导致延时会非常大。
3、索引生命周期管理面临的挑战
1)索引管理需要ES专业知识和业务知识的结合。
业务数据多少结合业务场景,有突发情况。
2)涉及生产环境的操作。
3)用户使用有突发情况。
比如:参数设置错误,分片数和副本数弄反了,路由设置错误。
4)索引操作的时候可能会失败。
5)高可用性挑战。
4、高可用的索引管理初探
Ebay的分享提及内部团队开发了索引管理系统,会择期分享,截止20180805 github还没有开源,期待中。
索引生命周期管理的核心就是定义索引的早期阶段,前面考虑充分了,后面的架构才会高效、稳定。
实际Elasticsearch5.X之后的版本已经推出:新增了一个Rollover API。Rollover API解决的是以日期作为索引名称的索引大小不均衡的问题。
medcl介绍如下:Rollover API对于日志类的数据非常有用,一般我们按天来对索引进行分割(数据量更大还能进一步拆分),没有Rollover之前,需要在程序里设置一个自动生成索引的模板,
相比于模板,Rollover API是更为简洁的方式。
4.1 RollOver 的定义
当现有索引被认为太大或太旧时,滚动索引API将别名滚动到新索引。该API接受一个别名和一个条件列表。别名必须只指向一个索引。如果索引满足指定条件,则创建一个新索引,并将别名切换到指向新索引的位置。
6.XRollover支持的三种条件是:
- 1)索引存储的最长时间。如: “max_age”: “7d”,
- 2)索引支持的最大文档数。如:“max_docs”: 1000,
- 3)索引最大磁盘空间大小。“max_size”: “5gb”。
注意:
5.X版本不支持"max_size": "5gb"磁盘大小的方式。
分片的大小并不是一个可靠的测量标准,因为正在进行中的合并会产生大量的临时分片大小增长,而当合并结束后这些增长会消失掉。五个主分片,每个都在合并到一个 5GB 分片的过程中,那么此时索引大小会临时增多 25GB!而对于文档数量来说,它的增长则是可以预测的。
4.2 RollOver的适用场景
这个特性对于存放日志数据的场景、索引非常大、索引实时导入数据的场景是极为友好的。
你也可以先在索引模板里面设置索引的setting、mapping等参数, 然后设定好_rollover 规则,剩下的es会自动帮你处理。
4.3 6.XRollOverAPI调用方式如下:
方式一:基于序号的索引管理。
步骤1:创建索引(注意序号)
PUT /logs-000001
{
"aliases": {
"logs_write": {}
}
}
步骤2:指定RollOver规则。
POST /logs_write/_rollover
{
"conditions": {
"max_age": "7d",
"max_docs": 2,
"max_size": "5gb"
}
}
步骤3:批量插入数据。
POST logs_write/log/_bulk
{ "create": {"_id":1}}
{ "text": "111"}
{ "create": {"_id":2}}
{ "text": "222" }
{ "create": {"_id":3}}
{ "text": "333"}
{ "create": {"_id":4}}
{ "text": "4444"}
注意啦,理论上:_id=3和_id=4的数据会滚动到logs-000002的索引,实际并没有。
这个问题困扰我一上午。
实践验证发现,然并卵。
步骤4:重复步骤2。
查看返回结果如下:
{
"old_index": "logs-000001",
"new_index": "logs-000002",
"rolled_over": true,
"dry_run": false,
"acknowledged": true,
"shards_acknowledged": true,
"conditions": {
"[max_docs: 2]": true,
"[max_age: 7d]": false,
"[max_size: 5gb]": false
}
}
这样以后,后续插入的数据索引就自动变为logs-000002,logs-000003…logs-00000N。
注意:
1)执行数据插入前要先执行_rollover API。
2)_rollover API不是一劳永逸的,需要手动执行后才能生效。
方式二:基于时间的索引管理。
步骤1:创建基于日期的索引。
#PUT /<logs-{now/d}-1> with URI encoding:
PUT /%3Clogs-%7Bnow%2Fd%7D-1%3E
{
"aliases": {
"logs_write": {}
}
}
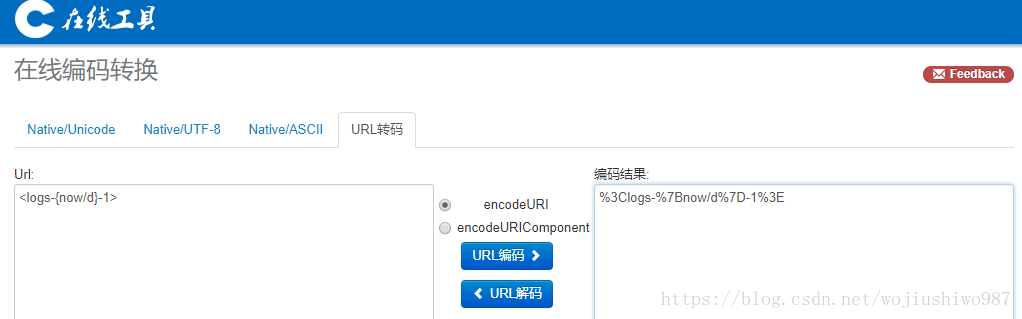
URI 编码工具:http://tool.oschina.net/encode?type=4
输入:<logs-{now/d}-1>
输出:%3Clogs-%7Bnow%2Fd%7D-1%3E
步骤2:插入一条数据。
PUT logs_write/_doc/1
{
"message": "a dummy log"
}
步骤3:指定RollOver规则。
POST /logs_write/_rollover
{
"conditions": {
"max_docs": "1"
}
}
返回结果:
{
"old_index": "logs-2018.08.05-1",
"new_index": "logs-2018.08.05-000002",
"rolled_over": true,
"dry_run": false,
"acknowledged": true,
"shards_acknowledged": true,
"conditions": {
"[max_docs: 1]": true
}
}
注意,可能感觉到日期没有变更困惑的问题解释如下:
1)如果立即执行,new_index的名字就是当前的日期:logs-2018.08.05-000002。
2)如果24小时候后执行,new_index的名字就是+1天后的日期:logs-2018.08.06-000002。
5、高可用的索引管理进阶
ES官网博客做了更好的诠释:https://www.elastic.co/blog/managing-time-based-indices-efficiently。
翻译版本:https://juejin.im/post/5a990cdbf265da239b40de65。
在基础RollOver滚动索引的基础上,引入冷、热数据分离。这是实际业务非常需要一种场景。
冷热分离结合滚动模式工作流程如下:
步骤1:有一个用于写入的索引别名,其指向活跃索引(热数据);
步骤2:另外一个用于读取(搜索)的索引别名,指向不活跃索引(冷数据);
步骤3:活跃索引具有和热节点数量一样多的分片,可以充分发挥昂贵硬件的索引写入能力;
步骤4:当活跃索引太满或者太老的时候,它就会滚动:新建一个索引并且索引别名自动从老索引切换到新索引;
步骤5:移动老索引到冷节点上并且缩小为一个分片,之后可以强制合并和压缩。
具体实现,官方博客已经做了具体的说明。
注意:
"routing.allocation.include.box_type": "hot",
"routing.allocation.total_shards_per_node": 2
单节点执行上述操作会导致失败,具体原因待进一步验证。
6、Rollover的不足和改进
Rollover API大大简化了基于时间的索引的管理。但是,仍然需要以一种重复的方式调用_rollover API接口,可以手动调用,也可以通过基于crontab的工具(如director)调用。
但是,如果翻转过程是隐式的并在内部进行管理,则会简单得多。其思想是在创建索引时(或在索引模板中相等地)在别名中指定滚动条件。
PUT /<logs-{now/d}-1>
{
"mappings": {...},
"aliases" : {
"logs-search" : {},
"logs-write" : {
"rollover" : {
"conditions": {
"max_age": "1d",
"max_docs": 100000
}
}
}
}
}
github提出的改进建议如下:
https://github.com/elastic/elasticsearch/issues/26092
截止:20180805这种方式没有实现。
7、小结
- Elasticsearch索引生命周期管理是件大事,无论你是开发还是运维人员,千万不要轻视。
- Rollover的出现能相对缓解分片、索引、集群的压力,相对高效的管理索引的生命周期。
- 结合curator的定时删除机制会更高效。
参考:
https://elasticsearch.cn/slides/120
打造Elasticsearch基础、进阶、实战第一公众号!
















 527
527











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











