






最近刚看完xgboost的paper,权当是 整理一下思路。
算法层面的:
1.XGB加了正则项,普通GBDT没有。为了防止过拟合
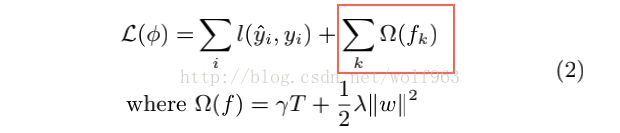
T为叶子节点的数量,W为叶子的权重。
Y帽子 为预测值,Y为目标值。
gamma ,delta 为参数
2.xgboost损失函数是误差部分是二阶泰勒展开,GBDT 是一阶泰勒展开。因此损失函数近似的更精准。
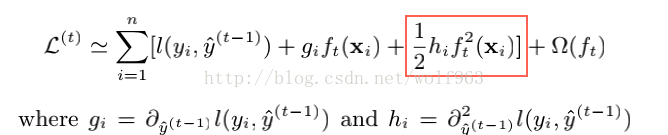
3.对每颗子树增加一个参数,使得每颗子树的权重降低,防止过拟合,这个参数叫shrinkage
对特征进行降采样,灵感来源于随机森林,除了能降低计算量外,还能防止过拟合。
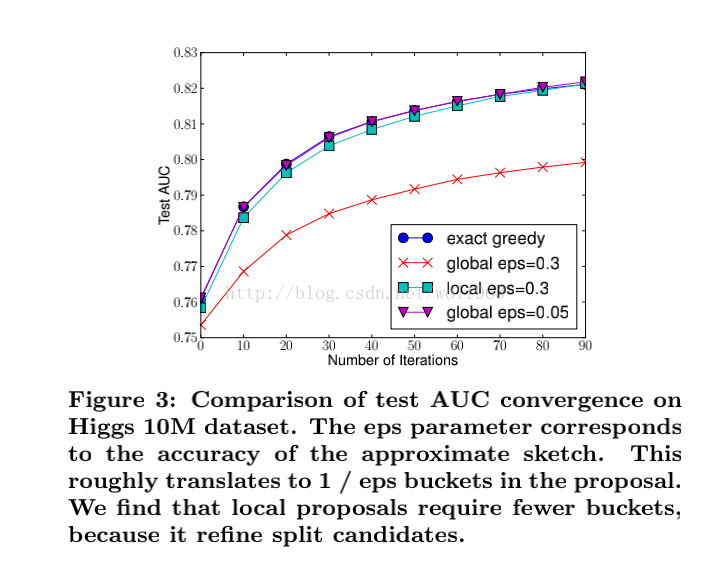
4.实现了利用分捅/分位数方法,实现了全局和局部的近似分裂点算法,降低了计算量,并且在eps参数设置合理的情况下,能达到穷举法几乎一样的性能
5.提出并实现了特征带权重的分位数的方法(好像是用到rank 场景下的,没太懂。。。)
6.增加处理缺失值的方案(通过枚举所有缺失值在当前节点是进入左子树,还是进入右子树更优来决定一个处理缺失值默认的方向)。

系统层面:
7.对每个特征进行分块(block)并排序,使得在寻找最佳分裂点的时候能够并行化计算。这是xgboost比一般GBDT更快的一个重要原因。
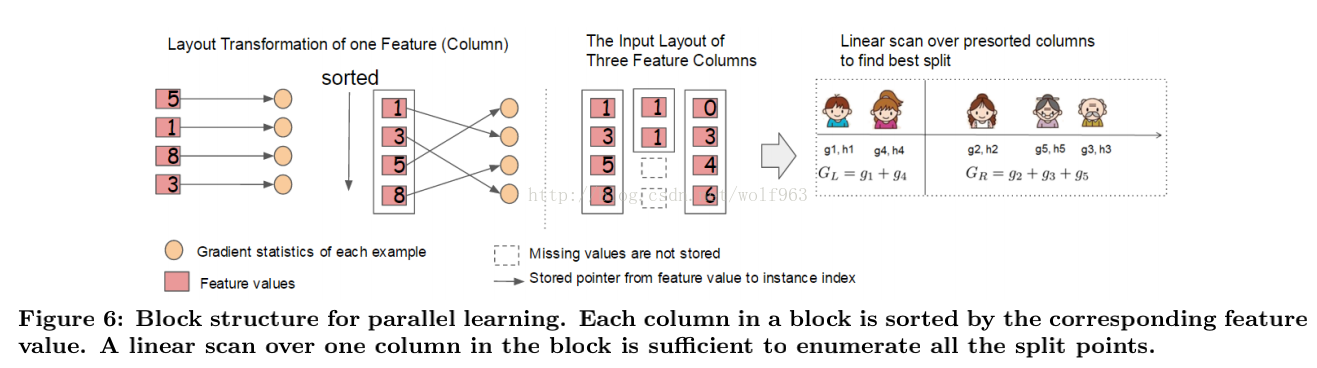
8.通过设置合理的block的大小,充分利用了CPU缓存进行读取加速(cache-aware access)。使得数据读取的速度更快。因为太小的block的尺寸使得多线程中每个线程负载太小降低了并行效率。太大的block尺寸会导致CPU的缓存获取miss掉。
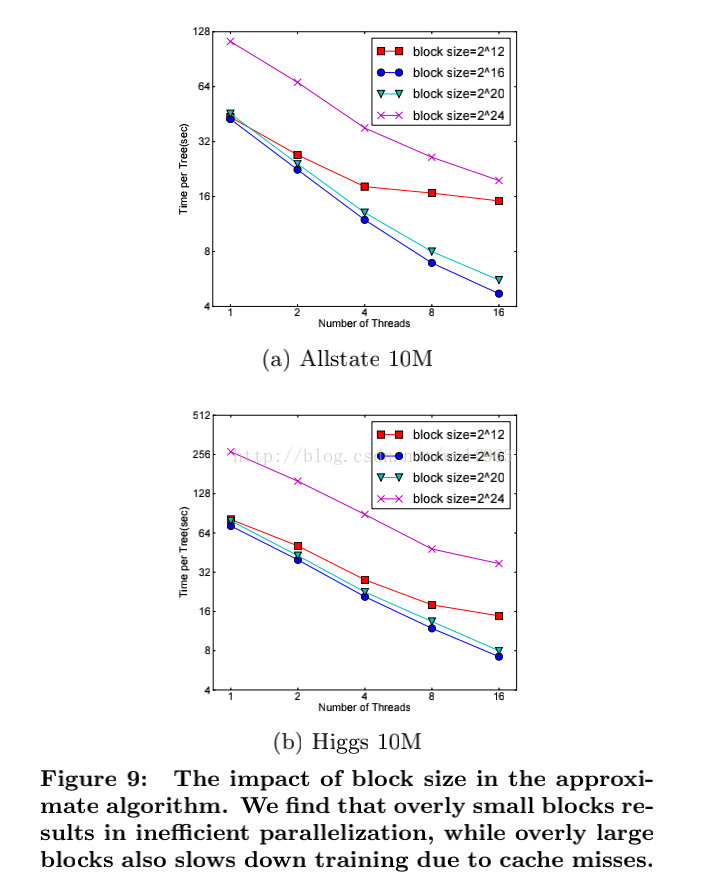
9.
out-of-core 通过将block压缩(block compressoin)并存储到硬盘上,并且通过将block分区到多个硬盘上(block Sharding)实现了更大的IO 读写速度,因此,因为加入了硬盘存储block读写的部分不仅仅使得xgboost处理大数据量的能力有所提升,并且通过提高IO的吞吐量使得xgboost相比一般实利用这种技术实现大数据计算的框架更快。
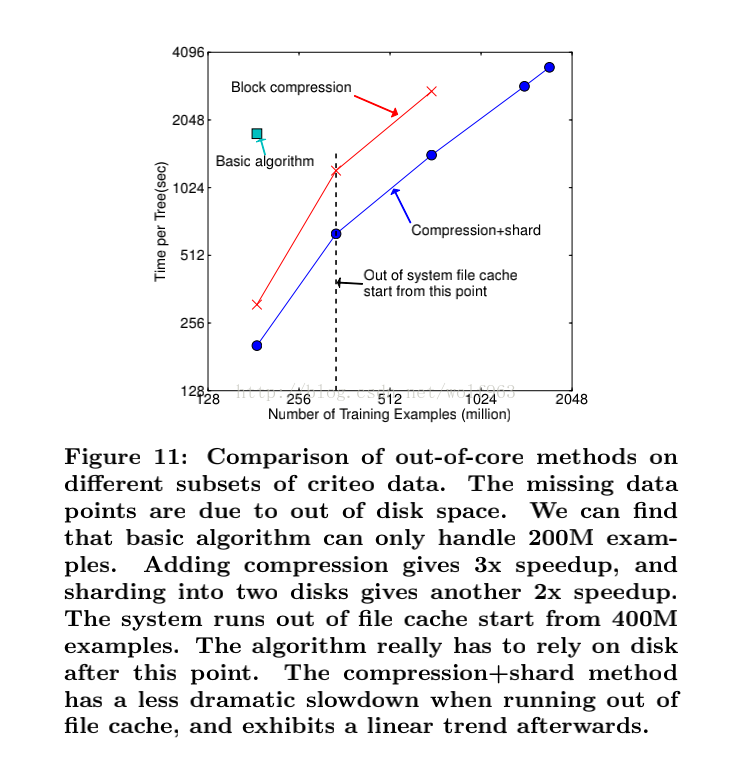














 805
805











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









