






在编译c文件的时候,出现如下错误:
error: stray ‘\357’ in program
error: stray ‘\274’in program
error: stray ‘\233’in program
百思不得其解,怒百度之,几番查找之下,终于找出原因:
原来是UTF-8编码问题。UTF-8编码有BOM和无BOM格式。BOM,ByteOrderMark(字节标记顺序),表明使用UTF8来进行编码。UTF-8的BOM通常为3个字节EF BB BF。转换成对应的字符查看,就是‘\357’,‘\274’,‘\233’。
本着实践才是硬道理的原则,我做了一个验证:
1):notepadd++打开一个文件,分别使用UTF-8无BOM格式和UFT-8格式,使用winhex进行查看,可以看到带BOM格式的头部有EF BB BF三个字节,所以编译时会报错。

无BOM格式不存在头3个,

2):notepadd++打开一个文件,分别使用UTF-8无BOM格式和UFT-8格式,linux下输入od -tc 源文件名,查看。
带BOM:
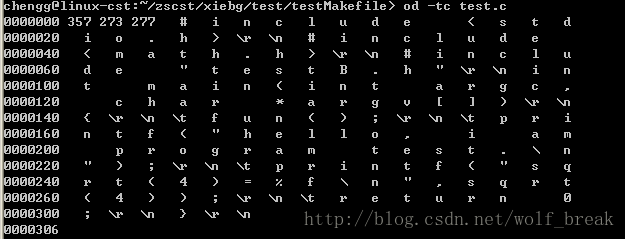
无BOM:

问题解决,所以以后编程时特别注意编码问题。使用UTF-8无BOM格式或者ANSI格式。
考虑到之前写php程序时也经常出现一些编码问题,在这里我对各种编码进行一个系统的学习。学习资料来自你到底是UTF-8还是ANSI,该文简洁易懂,实乃居家旅行,出门必备之必读文章。扯远了。。
现在做对各种编码格式作一个总结:
1):ANSI.
谈到ANSI,估计你就想到ascii码表了。0-31这32个值用作特殊用途,当打印机或终端遇上这些字符时,便会做出特定的动作。从32到127,这些值用来表示打印字符(英文字符,运算符等),再之后,世界其他国家开始使用计算机,他们国家的文字编码相应的就填充到128-255这些值中,这些就被称为拓展字符集。上述就统称为ANSI编码.
ASCII码大致可以分作三部分組成:
第一部分是:ASCII非打印控制字符;
第二部分是:ASCII打印字符;
第三部分是:扩展ASCII打印字符。
ascii码
2):gb2312, gbk, gb18030
gb2312:
等到中国人民开始使用计算机的时候,已经没有剩余的字符给中国人民使用了。但是,美帝是无法难倒聪明的中国人民的,中国人开始想到用两个字节表示汉字,第一个字节从OXA1-OXF7,第二个字节从OXA1-OXFE,这样就可以组合出7000多个汉字,ascii码本来有的数字标点,字母统一重新编了两个字符的编码,这就是全角字符,原来的127一下的就叫做半角字符。这就是gb2312编码的由来。
gbk:
后来中国人民发现,还是有些汉字在gb2312中无法显示出来,所以规定第一个字节从OXA0-0XFF,第二个字节不限。这样又增加了近20000个新汉字和符号。这就是gbk编码的由来。
gb18030:
在汉字系统中,少数民族也开始进入,为了增加少数民族汉字,又加了几千个少数民族汉字,这就是gb18030编码由来。
这三种编码统一称为DBCS,double byte charecter set双字节字符编码。
3):UCS(俗称UNICODE)
这时候,每个国家都开始制定自己的文字编码,编码格式乱的一B,这时候ISO站了出来,发明了UNICODE这种编码来统一世界上各种编码。
UNICODE--universal multiple-octet coded charecter set。unicode直接规定,所有字符统一用两个字节来表示。对于ascci码半角字符小于127字符,编码不变,8位拓展为16位(只含英文字符的unicode文章大大浪费存储啊,这么多高位0,不过ISO表示咱不在乎这点空间),对于其他国家的双字符编码,统一重新进行编码。如上就是UNICODE编码。这里要说一个问题,两个字节存储,你会想到什么?没错,那就是大小端问题。所谓大小端,无法就是大端高位字节存在低位存储单元(高位在前),小端就是低位字节存在低位存储单元(低位在前)。UNICODE区分出大小端,在网络传输时,如何判断字节流是大端还是小端呢?为了解决这个问题,UNICODE引入两个字节的BOM,对于大端模式来说,那就是FE FF;对于小端模式来说,那就是FF FE(OX00位置FF,OX00位置FE,别混乱了啊)。这样我们就可以区分出是大端还是小端。
4)UTF
随着网络时代的来临,UNICODE在网络上的传输成为一个问题。并且,考虑到unicode编码和ansi编码之间的兼容问题,此时出现UTF(UCS Tranfer Format)编码,一来解决传输问题,二来和ASCII编码保持最大程度的兼容,这样做的好处是压缩了字符在西欧一些国家的内存消耗,减少了不必要的资源浪费。这里给出一个UNICODE和UTF-8的对换标准:
| UNICODE | 0000-007f | 0080-07ff | 0800-FFFF |
| UTF | 0xxxxxxx | 110xxxxx 10xxxxxx | 1110xxxx 10xxxxxx 10xxxxxx |
好了,各个编码标准的来源都扯了一遍,感觉更明白了点。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









