









1.源代码
package edu.uci.ics.crawler4j.util;
public class Util {
// 将long类型(8字节64位)变量,转化为长度为8的byte数组。变量的高位位于byte数组的前面
public static byte[] long2ByteArray(long l) {
byte[] array = new byte[8];
int i, shift;
//依次右移56(取前8位),48(取8-16位),40···
for (i = 0, shift = 56; i < 8; i++, shift -= 8) {
array[i] = (byte) (0xFF & (l >> shift));
}
return array;
}
// 将int类型(4字节32位)变量,转化为长度为4的byte数组
public static byte[] int2ByteArray(int value) {
byte[] b = new byte[4];
//依次无符号右移24(取前8位),16(取8-16位),8···
for (int i = 0; i < 4; i++) {
int offset = (3 - i) * 8;
b[i] = (byte) ((value >>> offset) & 0xFF); //注意此处为无符号右移(左边补充0)
}
return b;
}
// 类似与int2ByteArray,增加了byte[]和offset参数
public static void putIntInByteArray(int value, byte[] buf, int offset) {
for (int i = 0; i < 4; i++) {
int valueOffset = (3 - i) * 8;
buf[offset + i] = (byte) ((value >>> valueOffset) & 0xFF);
}
}
//byte数组转化为Int
public static int byteArray2Int(byte[] b) {
int value = 0;
//依次左移得到前8位,8-16位,16-24位,24-32位
for (int i = 0; i < 4; i++) {
int shift = (4 - 1 - i) * 8;
value += (b[i] & 0x000000FF) << shift;
}
return value;
}
//byte数组转化为long
public static long byteArray2Long(byte[] b) {
int value = 0; // 是否应该是 long value = 0;
for (int i = 0; i < 8; i++) {
int shift = (8 - 1 - i) * 8;
value += (b[i] & 0x000000FF) << shift;
}
return value;
}
// 验证Http协议头中的contentType,是否为二进制数据,如image,audio等
public static boolean hasBinaryContent(String contentType) {
String typeStr = contentType != null ? contentType.toLowerCase() : "";
return typeStr.contains("image") || typeStr.contains("audio") || typeStr.contains("video")
|| typeStr.contains("application");
}
// 验证Http协议头中的contentType,是否为文本制数据
public static boolean hasPlainTextContent(String contentType) {
String typeStr = contentType != null ? contentType.toLowerCase() : "";
return typeStr.contains("text") && !typeStr.contains("html");
}
}2.需要注意的地方
2.1 函数int2ByteArray和函数int2ByteArray中使用的是无符号右移,即不管输入参数是正是负,右移过程中左边添0。其实也可以是有符号右移,因为只有相应的位置才会被与操作保留。这里不用考虑符号位,因为符号位在左移和右移的过程中都被很好的保持和恢复了。
2.2 注意到在函数byteArray2Long中,定义了一个int型的临时变量,返回的时候将int型变量强制转换为long,这里存在一些问题。
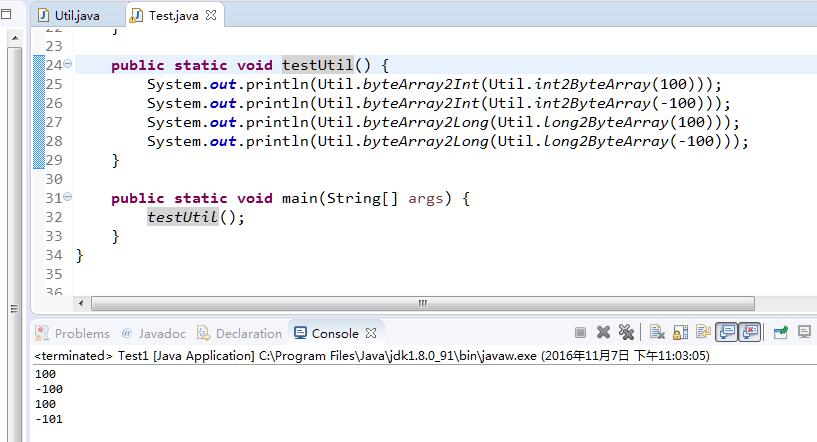
可以看到long类型负数的输入会出现一些错误,加入如下调试信息:
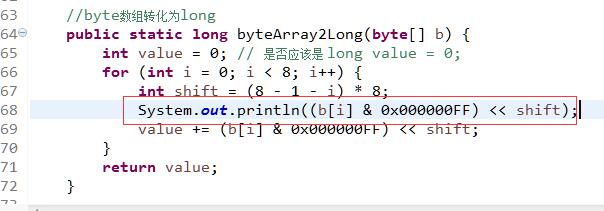
重新运行,结果如下
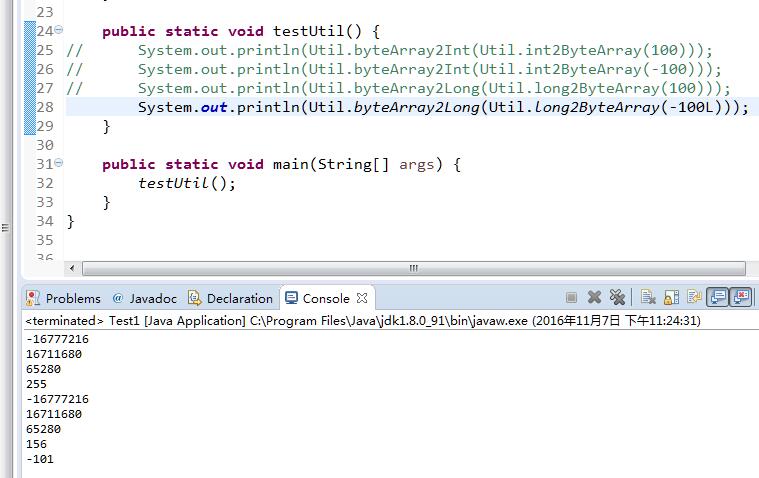
数据的十六进制对应关系如下
| 十进制 | 十六进制补码 |
|---|---|
| -16777216 | FF000000 |
| 16711680 | 00FF0000 |
| 65280 | 0000FF00 |
| 255 | 000000FF |
| 156 | 0000009C |
注意-100的8字节补码为FFFFFFFFFFFFFF9C,另外32位的数据左移56位和左移24位是等价的。
解决办法:改成:value += ((long)b[i] & 0x000000FF) << shift;
(注:a & b, 结果为多少位,由a和b中的最大者决定)
2.3 函数hasBinaryContent和hasPlainTextContent用来确定content-type的类型。
具体的content-type类型可以参考对照表。














 1152
1152











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









