









源代码
package edu.uci.ics.crawler4j.url;
// 将相对地址转化为绝对地址(具体内容参考文档http://www.faqs.org/rfcs/rfc1808.html)
public final class UrlResolver {
/**
* Class <tt>Url</tt> represents a Uniform Resource Locator.
*
* @author Martin Tamme
*/
// 一般的超链接格式 <scheme>://<net_loc>/<path>;<params>?<query>#<fragment>
private static class Url {
String scheme_;
String location_;
String path_;
String parameters_;
String query_;
String fragment_;
/**
* Creates a <tt>Url</tt> object.
*/
public Url() {
}
/**
* Creates a <tt>Url</tt> object from the specified
* <tt>Url</tt> object.
*
* @param url a <tt>Url</tt> object.
*/
public Url(final Url url) {
scheme_ = url.scheme_;
location_ = url.location_;
path_ = url.path_;
parameters_ = url.parameters_;
query_ = url.query_;
fragment_ = url.fragment_;
}
/**
* Returns a string representation of the <tt>Url</tt> object.
*
* @return a string representation of the <tt>Url</tt> object.
*/
@Override
public String toString() {
final StringBuilder sb = new StringBuilder();
if (scheme_ != null) {
sb.append(scheme_);
sb.append(':');
}
if (location_ != null) {
sb.append("//");
sb.append(location_);
}
if (path_ != null) {
sb.append(path_);
}
if (parameters_ != null) {
sb.append(';');
sb.append(parameters_);
}
if (query_ != null) {
sb.append('?');
sb.append(query_);
}
if (fragment_ != null) {
sb.append('#');
sb.append(fragment_);
}
return sb.toString();
}
}
/**
* Resolves a given relative URL against a base URL. See
* <a href="http://www.faqs.org/rfcs/rfc1808.html">RFC1808</a>(具体内容请看这)
* Section 4 for more details.
*
* @param baseUrl The base URL in which to resolve the specification.
* @param relativeUrl The relative URL to resolve against the base URL.
* @return the resolved specification.
*/
// 调用算法,将相对地址根据其所在页面的上下文(主要是所在页面的绝对地址),转化成等价的绝对地址
public static String resolveUrl(final String baseUrl, final String relativeUrl) {
if (baseUrl == null) {
throw new IllegalArgumentException("Base URL must not be null");
}
if (relativeUrl == null) {
throw new IllegalArgumentException("Relative URL must not be null");
}
// 调用算法,将相对地址根据其所在页面的上下文(主要是所在页面的绝对地址),转化成等价的绝对地址
final Url url = resolveUrl(parseUrl(baseUrl.trim()), relativeUrl.trim());
return url.toString();
}
/**
* Returns the index within the specified string of the first occurrence of
* the specified search character.
*
* @param s the string to search
* @param searchChar the character to search for
* @param beginIndex the index at which to start the search
* @param endIndex the index at which to stop the search
* @return the index of the first occurrence of the character in the string or <tt>-1</tt>
*/
// 从beginIndex开始,到endIndex结束中,字符串s中第一个为searchChar的字符的位置
private static int indexOf(final String s, final char searchChar, final int beginIndex, final int endIndex) {
for (int i = beginIndex; i < endIndex; i++) {
if (s.charAt(i) == searchChar) {
return i;
}
}
return -1;
}
/**
* Parses a given specification using the algorithm depicted in
* <a href="http://www.faqs.org/rfcs/rfc1808.html">RFC1808</a>:
*
* Section 2.4: Parsing a URL
*
* An accepted method for parsing URLs is useful to clarify the
* generic-RL syntax of Section 2.2 and to describe the algorithm for
* resolving relative URLs presented in Section 4. This section
* describes the parsing rules for breaking down a URL (relative or
* absolute) into the component parts described in Section 2.1. The
* rules assume that the URL has already been separated from any
* surrounding text and copied to a "parse string". The rules are
* listed in the order in which they would be applied by the parser.
*
* @param spec The specification to parse.
* @return the parsed specification.
*/
// 将一个字符串格式的链接,变为标准格式 <scheme>://<net_loc>/<path>;<params>?<query>#<fragment>
private static Url parseUrl(final String spec) {
final Url url = new Url();
int startIndex = 0;
int endIndex = spec.length();
// Section 2.4.1: Parsing the Fragment Identifier
//
// If the parse string contains a crosshatch "#" character, then the
// substring after the first (left-most) crosshatch "#" and up to the
// end of the parse string is the <fragment> identifier. If the
// crosshatch is the last character, or no crosshatch is present, then
// the fragment identifier is empty. The matched substring, including
// the crosshatch character, is removed from the parse string before
// continuing.
//
// Note that the fragment identifier is not considered part of the URL.
// However, since it is often attached to the URL, parsers must be able
// to recognize and set aside fragment identifiers as part of the
// process.
final int crosshatchIndex = indexOf(spec, '#', startIndex, endIndex);
// 如果字符串中包含井号,则井号之后的都是fragment
if (crosshatchIndex >= 0) {
url.fragment_ = spec.substring(crosshatchIndex + 1, endIndex);
endIndex = crosshatchIndex;
}
// Section 2.4.2: Parsing the Scheme
//
// If the parse string contains a colon ":" after the first character
// and before any characters not allowed as part of a scheme name (i.e.,
// any not an alphanumeric, plus "+", period ".", or hyphen "-"), the
// <scheme> of the URL is the substring of characters up to but not
// including the first colon. These characters and the colon are then
// removed from the parse string before continuing.
final int colonIndex = indexOf(spec, ':', startIndex, endIndex);
// 如果字符串中包含冒号,则冒号之前的都是scheme
if (colonIndex > 0) {
final String scheme = spec.substring(startIndex, colonIndex);
if (isValidScheme(scheme)) { // 是否为符合文档要求的scheme
url.scheme_ = scheme;
startIndex = colonIndex + 1; // 起始点变为冒号之后的位置
}
}
// Section 2.4.3: Parsing the Network Location/Login
//
// If the parse string begins with a double-slash "//", then the
// substring of characters after the double-slash and up to, but not
// including, the next slash "/" character is the network location/login
// (<net_loc>) of the URL. If no trailing slash "/" is present, the
// entire remaining parse string is assigned to <net_loc>. The double-
// slash and <net_loc> are removed from the parse string before
// continuing.
//
// Note: We also accept a question mark "?" or a semicolon ";" character as
// delimiters for the network location/login (<net_loc>) of the URL.
final int locationStartIndex;
int locationEndIndex;
// 如果以"//"开始,则之后直到"/"(不包括/)的字符,就是network location
if (spec.startsWith("//", startIndex)) {
locationStartIndex = startIndex + 2;
locationEndIndex = indexOf(spec, '/', locationStartIndex, endIndex);
if (locationEndIndex >= 0) {
startIndex = locationEndIndex;
}
// 如果不包含"/",之后所有的字符都被看做是network location, 如http://www.baidu.com
}
else {
locationStartIndex = -1;
locationEndIndex = -1;
}
// Section 2.4.4: Parsing the Query Information
//
// If the parse string contains a question mark "?" character, then the
// substring after the first (left-most) question mark "?" and up to the
// end of the parse string is the <query> information. If the question
// mark is the last character, or no question mark is present, then the
// query information is empty. The matched substring, including the
// question mark character, is removed from the parse string before
// continuing.
final int questionMarkIndex = indexOf(spec, '?', startIndex, endIndex);
if (questionMarkIndex >= 0) {
if ((locationStartIndex >= 0) && (locationEndIndex < 0)) {
// The substring of characters after the double-slash and up to, but not
// including, the question mark "?" character is the network location/login
// (<net_loc>) of the URL.
locationEndIndex = questionMarkIndex;
startIndex = questionMarkIndex;
}
url.query_ = spec.substring(questionMarkIndex + 1, endIndex);
endIndex = questionMarkIndex;
}
// Section 2.4.5: Parsing the Parameters
//
// If the parse string contains a semicolon ";" character, then the
// substring after the first (left-most) semicolon ";" and up to the end
// of the parse string is the parameters (<params>). If the semicolon
// is the last character, or no semicolon is present, then <params> is
// empty. The matched substring, including the semicolon character, is
// removed from the parse string before continuing.
final int semicolonIndex = indexOf(spec, ';', startIndex, endIndex);
if (semicolonIndex >= 0) {
if ((locationStartIndex >= 0) && (locationEndIndex < 0)) {
// The substring of characters after the double-slash and up to, but not
// including, the semicolon ";" character is the network location/login
// (<net_loc>) of the URL.
locationEndIndex = semicolonIndex;
startIndex = semicolonIndex;
}
url.parameters_ = spec.substring(semicolonIndex + 1, endIndex);
endIndex = semicolonIndex;
}
// Section 2.4.6: Parsing the Path
//
// After the above steps, all that is left of the parse string is the
// URL <path> and the slash "/" that may precede it. Even though the
// initial slash is not part of the URL path, the parser must remember
// whether or not it was present so that later processes can
// differentiate between relative and absolute paths. Often this is
// done by simply storing the preceding slash along with the path.
if ((locationStartIndex >= 0) && (locationEndIndex < 0)) {
// The entire remaining parse string is assigned to the network
// location/login (<net_loc>) of the URL.
locationEndIndex = endIndex;
}
else if (startIndex < endIndex) {
url.path_ = spec.substring(startIndex, endIndex);
}
// Set the network location/login (<net_loc>) of the URL.
if ((locationStartIndex >= 0) && (locationEndIndex >= 0)) {
url.location_ = spec.substring(locationStartIndex, locationEndIndex);
}
return url;
}
/*
* Returns true if specified string is a valid scheme name.
*/
private static boolean isValidScheme(final String scheme) {
final int length = scheme.length();
if (length < 1) {
return false;
}
char c = scheme.charAt(0);
if (!Character.isLetter(c)) {
return false;
}
for (int i = 1; i < length; i++) {
c = scheme.charAt(i);
if (!Character.isLetterOrDigit(c) && c != '.' && c != '+' && c != '-') {
return false;
}
}
return true;
}
/**
* Resolves a given relative URL against a base URL using the algorithm
* depicted in <a href="http://www.faqs.org/rfcs/rfc1808.html">RFC1808</a>:
*
* Section 4: Resolving Relative URLs
*
* This section describes an example algorithm for resolving URLs within
* a context in which the URLs may be relative, such that the result is
* always a URL in absolute form. Although this algorithm cannot
* guarantee that the resulting URL will equal that intended by the
* original author, it does guarantee that any valid URL (relative or
* absolute) can be consistently transformed to an absolute form given a
* valid base URL.
*
* @param baseUrl The base URL in which to resolve the specification.
* @param relativeUrl The relative URL to resolve against the base URL.
* @return the resolved specification.
*/
private static Url resolveUrl(final Url baseUrl, final String relativeUrl) {
final Url url = parseUrl(relativeUrl);
// Step 1: The base URL is established according to the rules of
// Section 3. If the base URL is the empty string (unknown),
// the embedded URL is interpreted as an absolute URL and
// we are done.
// 没有baseUrl,则relativeUrl作为绝对地址
if (baseUrl == null) {
return url;
}
// Step 2: Both the base and embedded URLs are parsed into their
// component parts as described in Section 2.4.
// a) If the embedded URL is entirely empty, it inherits the
// entire base URL (i.e., is set equal to the base URL)
// and we are done.
// 相对地址为空,则baseUrl作为其绝对地址
if (relativeUrl.length() == 0) {
return new Url(baseUrl);
}
// b) If the embedded URL starts with a scheme name, it is
// interpreted as an absolute URL and we are done.
if (url.scheme_ != null) {
return url;
}
// c) Otherwise, the embedded URL inherits the scheme of
// the base URL.
url.scheme_ = baseUrl.scheme_;
// Step 3: If the embedded URL's <net_loc> is non-empty, we skip to
// Step 7. Otherwise, the embedded URL inherits the <net_loc>
// (if any) of the base URL.
if (url.location_ != null) {
return url;
}
url.location_ = baseUrl.location_;
// Step 4: If the embedded URL path is preceded by a slash "/", the
// path is not relative and we skip to Step 7.
if ((url.path_ != null) && ((url.path_.length() > 0) && ('/' == url.path_.charAt(0)))) {
url.path_ = removeLeadingSlashPoints(url.path_);
return url;
}
// Step 5: If the embedded URL path is empty (and not preceded by a
// slash), then the embedded URL inherits the base URL path,
// and
if (url.path_ == null) {
url.path_ = baseUrl.path_;
// a) if the embedded URL's <params> is non-empty, we skip to
// step 7; otherwise, it inherits the <params> of the base
// URL (if any) and
if (url.parameters_ != null) {
return url;
}
url.parameters_ = baseUrl.parameters_;
// b) if the embedded URL's <query> is non-empty, we skip to
// step 7; otherwise, it inherits the <query> of the base
// URL (if any) and we skip to step 7.
if (url.query_ != null) {
return url;
}
url.query_ = baseUrl.query_;
return url;
}
// Step 6: The last segment of the base URL's path (anything
// following the rightmost slash "/", or the entire path if no
// slash is present) is removed and the embedded URL's path is
// appended in its place. The following operations are
// then applied, in order, to the new path:
final String basePath = baseUrl.path_;
String path = "";
if (basePath != null) {
final int lastSlashIndex = basePath.lastIndexOf('/');
if (lastSlashIndex >= 0) {
path = basePath.substring(0, lastSlashIndex + 1);
}
}
else {
path = "/";
}
path = path.concat(url.path_);
// a) All occurrences of "./", where "." is a complete path
// segment, are removed.
int pathSegmentIndex;
while ((pathSegmentIndex = path.indexOf("/./")) >= 0) {
path = path.substring(0, pathSegmentIndex + 1).concat(path.substring(pathSegmentIndex + 3));
}
// b) If the path ends with "." as a complete path segment,
// that "." is removed.
if (path.endsWith("/.")) {
path = path.substring(0, path.length() - 1);
}
// c) All occurrences of "<segment>/../", where <segment> is a
// complete path segment not equal to "..", are removed.
// Removal of these path segments is performed iteratively,
// removing the leftmost matching pattern on each iteration,
// until no matching pattern remains.
while ((pathSegmentIndex = path.indexOf("/../")) > 0) {
final String pathSegment = path.substring(0, pathSegmentIndex);
final int slashIndex = pathSegment.lastIndexOf('/');
if (slashIndex < 0) {
continue;
}
if (!"..".equals(pathSegment.substring(slashIndex))) {
path = path.substring(0, slashIndex + 1).concat(path.substring(pathSegmentIndex + 4));
}
}
// d) If the path ends with "<segment>/..", where <segment> is a
// complete path segment not equal to "..", that
// "<segment>/.." is removed.
if (path.endsWith("/..")) {
final String pathSegment = path.substring(0, path.length() - 3);
final int slashIndex = pathSegment.lastIndexOf('/');
if (slashIndex >= 0) {
path = path.substring(0, slashIndex + 1);
}
}
path = removeLeadingSlashPoints(path);
url.path_ = path;
// Step 7: The resulting URL components, including any inherited from
// the base URL, are recombined to give the absolute form of
// the embedded URL.
return url;
}
/**
* "/.." at the beginning should be removed as browsers do (not in RFC)
*/
private static String removeLeadingSlashPoints(String path) {
while (path.startsWith("/..")) {
path = path.substring(3);
}
return path;
}
}
测试
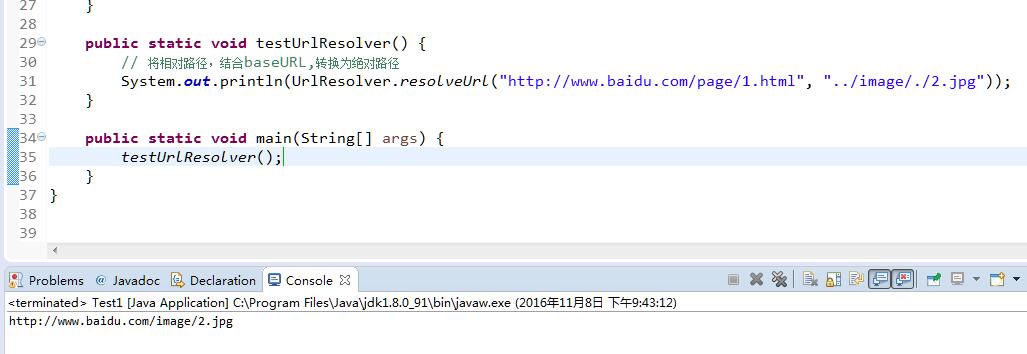
分析
UrlResolver是一个比较复杂的类,要想根本理解代码,需要详细阅读理解文档(RFC1808)。主要包含两个功能函数:
1.private static Url parseUrl(final String spec)
将字符串格式的链接转换为标准格式的URL,标准格式为:
<scheme>://<net_loc>/<path>;<params>?<query>#<fragment>具体的算法步骤请参考RFC1808.
2.private static Url resolveUrl(final Url baseUrl, final String relativeUrl)
结合标准格式的baseUrl和字符串格式的relativeUrl得到其所对应的标准格式的绝对路径,用于爬取过程中的URL去重。















 177
177

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









