









1 归并排序(MergeSort)
归并排序最差运行时间是O(nlogn),它是利用递归设计程序的典型例子。
归并排序的最基础的操作就是合并两个已经排好序的序列。
假设我们有一个没有排好序的序列,那么首先我们使用分割的办法将这个序列分割成一个一个已经排好序的子序列。然后再利用归并的方法将一个个的子序列合并成排序好的序列。分割和归并的过程可以看下面的图例。
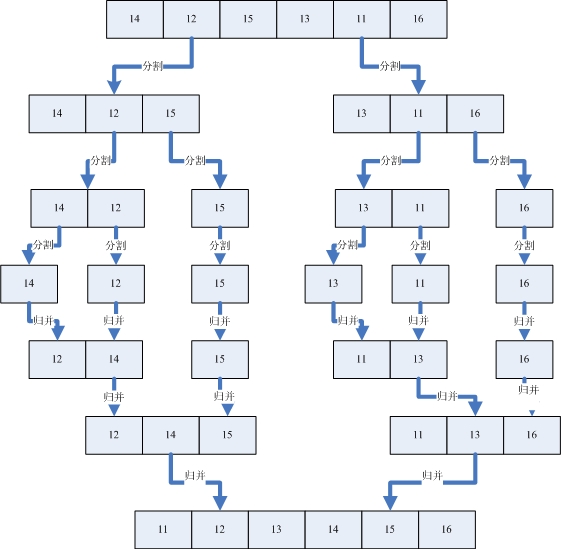
从上图可以看出,我们首先把一个未排序的序列从中间分割成2部分,再把2部分分成4部分,依次分割下去,直到分割成一个一个的数据,再把这些数据两两归并到一起,使之有序,不停的归并,最后成为一个排好序的序列。
如何把两个已经排序好的子序列归并成一个排好序的序列呢?可以参看下面的方法。
假设我们有两个已经排序好的子序列。
序列A:1 23 34 65
序列B:2 13 14 87
那么可以按照下面的步骤将它们归并到一个序列中。
(1)首先设定一个新的数列C[8]。
(2)A[0]和B[0]比较,A[0] = 1,B[0] = 2,A[0] < B[0],那么C[0] = 1
(3)A[1]和B[0]比较,A[1] = 23,B[0] = 2,A[1] > B[0],那么C[1] = 2
(4)A[1]和B[1]比较,A[1] = 23,B[1] = 13,A[1] > B[1],那么C[2] = 13
(5)A[1]和B[2]比较,A[1] = 23,B[2] = 14,A[1] > B[2],那么C[3] = 14
(6)A[1]和B[3]比较,A[1] = 23,B[3] = 87,A[1] < B[3],那么C[4] = 23
(7)A[2]和B[3]比较,A[2] = 34,B[3] = 87,A[2] < B[3],那么C[5] = 34
(8)A[3]和B[3]比较,A[3] = 65,B[3] = 87,A[3] < B[3],那么C[6] = 65
(9)最后将B[3]复制到C中,那么C[7] = 87。归并完成。
归并排序算法是一种O(nlogn)的算法。它的最差,平均,最好时间都是O(nlogn)。但是它需要额外的存储空间,这在某些内存紧张的机器上会受到限制。
归并算法是又分割和归并两部分组成的。对于分割部分,如果我们使用二分查找的话,时间是O(logn),在最后归并的时候,时间是O(n),所以总的时间是O(nlogn)。
2 堆排序(HeapSort)
堆排序属于百万俱乐部的成员。它特别适合超大数据量(百万条记录以上)的排序。因为它并不使用递归(因为超大数据量的递归可能会导致堆栈溢出),而且它的时间也是O(nlogn)。还有它并不需要大量的额外存储空间。
堆排序的思路是:
(1)将原始未排序的数据建成一个堆。
(2)建成堆以后,最大值在堆顶,也就是第0个元素,这时候将第零个元素和最后一个元素交换。
(3)这时候将从0到倒数第二个元素的所有数据当成一个新的序列,建一个新的堆,再次交换第一个和最后一个元素,依次类推,就可以将所有元素排序完毕。
建立堆的过程如下面的图所示:

堆排序主要用于超大规模的数据的排序。因为它不需要额外的存储空间,也不需要大量的递归。
3 基数排序
基数排序对于整数特别有效。是一种稳定的算法(意思是相同的数字不会交换关系)。基数排序是根据数字的性质来逐步根据个位数,十位数,百位数分类求得排序结果的方法之一。它的想法如下:
(1)先将数字根据A[n]依个位数来分类,放入含有数字0,1,2,...,9的临时数组D[10][n]中,再按照数字大小顺序放回原数组。那么这时候数据已经按照个位数大小从小到大排序。
(2)同样将数字按照百位数,千位数,万位数排序,.....最后就可以得到排好序的数字。
假设有下面4个数字需要排序:123 42 765 64
第一次按照个位数的大小排序后:42 123 64 765
第二次按照十位数的大小排序后:123 42 64 765
的三次按照百位数的大小排序后:42 64 123 765,其中42,64都小于100,因此其百位数可以看成0。
从上面的算法描述可以看出,我们首先需要知道一个数据系列中的最大数据。接下来,我们还要知道它有多少位,最后我们必须知道每一位到底是什么。比如例子中最大的数据是765,我们需要765是一个3位数,而且需要知道它的个位是5,十位是6,百位是7。基数排序法的时间为O(n logRB)。其中B是数字个数(0-9),R是基数位数(最大值数据的位数),相同数据在基数排序法的过程中的位置不会变动,是一种稳定的排序的算法。但是如果数据量很大的话,这种算法也需要很多额外的存储空间。不过从总的看来,这种算法对于整数排序还是很好的。
5 Shell排序(希尔排序)
Shell排序属于交换方法的排序算法。从前面介绍的冒泡排序法,交换排序法,选择排序法,插入排序法4者可以发现,如果数据已经大致排好序的时候,其交换数据位置的动作将会减少。例如在插入排序法过程中,如果某一整数d[i]不是较小时,则其往前比较和交换的次数会更少。
如何用简单的方式让某些数据有一定的大小次序呢?Donald Shell(Shell排序的创始人)提出了先将数据按照固定的间隔分组,例如每隔4个分成一组,然后排序各分组的数据,形成以分组来看数据已经排序,从全部数据来看,较小值已经在前面,较大值已经在后面。将初步处理了的分组再用插入排序来排序,那么数据交换和移动的次数会减少。可以得到比插入排序法更高的效率。
假设有12个数据:71 101 81 111 51 11 91 21 121 61 31 43
分成4组
第一组 71 51 121
第二组 101 11 61
第三组 81 91 31
第四组 111 21 41
当我们把各个组的数据都排好序以后,再对总的数据进行排序,那么就可以看到数据的移动次数比起普通的插入排序会少了很多。
如何进行分组呢?按照Shell的分法,h(0)=[n/2],h(i+1)=h(i)/2
6 快速排序
快速排序是最有名且最常用的排序算法之一,因为它的时间复杂度为O(nlgn),而且可以按照递归的思路来设计程序,它的想法如下:一般的排序方法(冒泡排序法,交换排序法,选择排序法,插入排序法)一次都只能减少一个数据量,而Shell排序法每次都按照分组来排序,相当于减少了较多的数据量,如果每次都大幅度地减少数据量,那么效率会更高。
如果可以在排完一个数据后,使其余数据分成两部分,一部分都比它大,另外一部分都比它小,再分别排序两组数据,那么效果会更好。快速排序就是利用了这个思路。
如果第一次先以第0个数据为比较值,用pos代表其下标,希望可以把pos放到合适的位置k,使右边的数据都比它小,左边的数据都比它大。
要达到这个目标,可以按照下面的办法来处理。
(1)一方面,我们从左边开始,向右去找一个比pos大的数据,设其位置为lower,然后从右边开始,向左去寻找一个比pos小的数据,设其位置为upper。然后我们交换lower和upper。接下来继续寻找,找到符合条件的就交换。直到upper小于lower为止,这时候说明右边的数据都小于pos,左边的数据都大于pos。
以pos的位置将数据分成两边,再按相同的办法来处理两边的数据直到所有的数据结束。
7 交换排序
交换排序是一种很简单的排序方法。其主要思想如下:
(1)利用要排序范围中的第0个数据d[i]与范围中其它数据d[j]相比较。如果前面的数据比后面大,那么就交换这两个数据(就是把较小的数据放在第0个位置)。然后再和排序范围内下一个数据d[j+1]相比较。依此类推。
(2)当执行完步骤(1)后,最小值即位于范围中的第0个位置。然后在剩下的数据中找到一个最小的,放在第1个位置,这样循环查找下去直到所有数据结束,最后可以得到由小到大的排序结果。
交换排序的思想和冒泡排序的思想很类似,实现的代码也非常相似。下面是一个简单的说明例子。
假设要排序的数据是:6 2 5 1 3 4
步骤一:
因为6>2,所以2和6交换
2 6 5 1 3 4
步骤二:因为2<5,所以不交换
2 6 5 1 3 4
步骤三:因为2>1,所以交换
1 6 5 2 3 4
步骤四:因为1<3,所以不交换
1 6 5 2 3 4
步骤五:因为1<4,所以不交换
1 6 5 2 3 4
这样我们叫找到了最小值1,按照同样的办法,就可以找到第二个,第三个最小值。。完成排序。
8选择排序
选择排序也是很简单的排序方法之一。其主要思想如下:
(1)第一次在数组中查找出最小的值a[i],将其和第0个位置交换。
(2)此时剩下n-1个值,同样从中找出最小的值a[j],a[j]和第一个数据交换
(3)重复上面的步骤,在剩下的范围中找出最小的值和最小数组下标的值进行交换。
一般会设置一个额外变量small来记录最小值的下标,以便于在循环之后,交换指定位置和最小值位置的值。根据上面的描述,我们可以很容易地就写出选择排序的算法。
9 插入排序
插入排序也是一种原理非常简单的排序方法,属于插入方法的排序。其主要思想如下:
(1)首先从第一个数据开始,将该值插入到其前面已经排好序的数据当中。插入的位置是第一个大于该数据的记录的前面。如果没有大于它的数据,就将其放在排好序的数据的最后。由于现在排序尚未开始,因此只有第1个元素。
(2)接着是第二个元素,用步骤1的方法插入到大于它的数的前面。现在第一个,第二个数据都是有序的了。
(3)依次可以排第三个,第四个数据,直到所有的数据完全排好序。可以从下面例子看出详细的过程。
还是假设要排序的数字为:6 2 5 1 3 4
步骤1:移动第一个
6 2 5 1 3 4
步骤2:移动第二个,因为2<6,所以将2放在6前面
2 6 5 1 3 4
步骤3:移动第三个,因为2<5<6,所以将5放在6前面
2 5 6 1 3 4
步骤4:移动第四个,因为1<2<5<6,所以将1放在最前面
1 2 5 6 3 4
步骤5:移动第五个,因为2<3<5<6,所以将3放在2后面
1 2 3 5 6 4
步骤6:移动第六个,因为3<4<5<6,所以将4将在3后面
1 2 3 4 5 6
这样所有的数据就都排好序了。
10总结
下面是一个总的表格,大致总结了我们常见的所有的排序算法的特点。
| 排序法 | 平均时间 | 最差情形 | 稳定度 | 额外空间 | 备注 |
| 冒泡 | O(n2) | O(n2) | 稳定 | O(1) | n小时较好 |
| 交换 | O(n2) | O(n2) | 不稳定 | O(1) | n小时较好 |
| 选择 | O(n2) | O(n2) | 不稳定 | O(1) | n小时较好 |
| 插入 | O(n2) | O(n2) | 稳定 | O(1) | 大部分已排序时较好 |
| 基数 | O(logRB) | O(logRB) | 稳定 | O(n) | B是真数(0-9), R是基数(个十百) |
| Shell | O(nlogn) | O(ns) 1<s<2 | 不稳定 | O(1) | s是所选分组 |
| 快速 | O(nlogn) | O(n2) | 不稳定 | O(nlogn) | n大时较好 |
| 归并 | O(nlogn) | O(nlogn) | 稳定 | O(1) | n大时较好 |
| 堆 | O(nlogn) | O(nlogn) | 不稳定 | O(1) | n大时较好 |
原文链接:点击打开链接















 1703
1703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









