







1. Solr简介
前言
学习Solr需要一些和java相关的储备知识,在此之前,假设您已经:
- 拥有 Java 开发环境以及相应 IDE(eclipse idea)
- 熟悉 Spring Boot
- 熟悉 Maven
- 熟悉 Lucene
1.1 Solr是什么
- Solr是Apache旗下基于Lucene开发的全文检索的服务。用户可以通过http请求,向Solr服务器提交一定格式的数据(XML,JSON),完成索引库的索引。也可以通过Http请求查询索引库获取返回结果(XML,JSON)。
Solr和Lucene的区别
- Lucene是一个开放源代码的全文检索引擎工具包,它不是一个完整的全文检索引擎,Lucene提供了完整的查询引擎和索引引擎,目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者以Lucene为基础构建全文检索引擎。
Solr的目标是打造一款企业级的搜索引擎系统,它是一个搜索引擎服务,可以独立运行,通过Solr可以非常快速的构建企业的搜索引擎,通过Solr也可以高效的完成站内搜索功能。

1.2 Solr的发展历程
- 2004年,CNET NetWorks公司的Yonik Seeley工程师为公司网站开发搜索功能时完成了Solr的雏形。
起初Solr知识CNET公司的内部项目。
-
2006 年1月,CNET公司决定将Solr源码捐赠给Apache软件基金会。
-
2008 年9月,Solr1.3发布了新功能,其他包括分布式搜索和性能增强等功能。
-
2009 年11月,Solr1.4版本发布,此版本对索引,搜索,Facet等方面进行优化,提高了对PDF,HTML等富文本文件处理能力,还推出了许多额外的插件;
-
2010 年3月,Lucene和Solr项目合并,自此,Solr称为了Lucene的子项目,产品现在由双方的参与者共同开发。
-
2011年,Solr改变了版本编号方案,以便与Lucene匹配。为了使Solr和Lucene有相同的版本号,Solr1.4下一版的版本变为3.1。
-
2012年10月,Solr4.0版本发布,新功能Solr Cloud也随之发布。
-
目前Solr最新版本8.4.1
1.3 Solr的功能优势
- 灵活的查询语法;
- 支持各种格式文件(Word,PDF)导入索引库;
- 支持数据库数据导入索引库;
- 分页查询和排序
- Facet维度查询;
- 自动完成功能;
- 拼写检查;
- 搜索关键字高亮显示;
- Geo地理位置查询;
- Group 分组查询;
- Solr Cloud;
2. 下载和安装
2.1 下载
solr的下载地址:Solr Downloads - Apache Solr
Solr最新版本是8.4.1的版本,由于8属于比较新的版本,可能有一些未知的Bug,出现问题后可能不好解决,所以我们使用Solr7.
因为Solr是基于java语言开发,且Solr7.x要求的JDK版本最少是JDK8.所以我们在安装solr之前,首先必须安装JDK。

2.2 Solr学习资源
为了方便学习,Solr官方也提供了很多学习资料。可以在官方的Resources中查看;


2.3 Window下安装Solr
window系统是我们平时开发和学习使用的一个平台,我们首先先来学习如何在window系统中安装Solr;
2.3.1运行环境
solr 需要运行在一个Servlet容器中,Solr7.x 要求jdk最少使用1.8以上,Solr默认提供Jetty(java写的Servlet容器),本教程使用Tocmat作为Servlet容器,环境如下:
Solr:Solr7.x
Jdk:jdk1.8
Tomcat:tomcat8.5
2.3.2 安装步骤
-
下载solr-7.zip并解压;

bin:官方提供的一些solr的运行脚本。
contrib:社区的一些贡献软件/插件,用于增强solr的功能。
dist:Solr的核心JAR包和扩展JAR包
docs:solr的API文档
example:官方提供的一些solr的demo代码
licenses:solr遵守的一些开源协议文件
server:这个目录有点意思,取名为sever,有点迷惑人,其实就是一个jetty.官方为了方便部署Solr,在安装包中内置了一个Jetty; 我们直接就可以利用内置的jetty部署solr;
server/solr-webapp/webapp:进入到sever目录中有一个webapp的目录,这个目录下部署的就是solr的war包(solr的服务);

在实际开发中通常我们需要将solr部署到tomcat服务器中;接下来我们要讲解的就是如何将solr部署到tomcat;
-
部署solr到tomcat;
1.解压一个新的tomcat
2.将安装包下server/solr-webapp/webapp下的solr服务打war包;
进入server/solr-webapp/webapp目录
使用cmd窗口
jar cvf solr.war ./*
3.将solr.war复制到tomcat/webapps目录中;

4.启动tomcat,解压war包;5.修改webapp/solr/WEB-INF/web.xml的配置solr_home的位置;
<env-entry> <env-entry-name>solr/home</env-entry-name> <env-entry-value>“你的solrhome位置”</env-entry-value> <env-entry-type>java.lang.String</env-entry-type> </env-entry>Solr home目录,SolrHome是Solr运行的主目录,将来solr产生的数据就存储在SolrHOME中;
SolrHOME可以含多个SolrCore;
SolrCore即Solr实例每个SolrCore可以对外单独提供全文检索的服务.
理解为关系型数据库中的数据库. 关于solrCore的创建我们在后面的课程中专门来讲解;
6.取消安全配置
<!-- <security-constraint> <web-resource-collection> <web-resource-name>Disable TRACE</web-resource-name> <url-pattern>/</url-pattern> <http-method>TRACE</http-method> </web-resource-collection> <auth-constraint/> </security-constraint> <security-constraint> <web-resource-collection> <web-resource-name>Enable everything but TRACE</web-resource-name> <url-pattern>/</url-pattern> <http-method-omission>TRACE</http-method-omission> </web-resource-collection> </security-constraint>-->7.将solr-7.7.2/server/solr中所有的文件复制到solrHome
8.拷贝日志工具相关jar包:将solr-7.7.2/server/lib/ext下的jar包拷贝至上面Tomcat下Solr的/WEB-INF/lib/目录下
9.拷贝metrics相关jar包:将solr-7.7.2/server/lib下metrics相关jar包也拷贝至/WEB-INF/lib/目录下
10.拷贝dataimport相关jar包:solr-7.7.2/dist下dataimport相关jar包也拷贝至/WEB-INF/lib/目录下
11.拷贝log4j2配置文件:将solr-7.7.2/server/resources目录中的log4j配置文件拷入web工程目录WEB-INF/classes(自行创建目录) ,并且修改日志文件的路径
12.重启tomcat,看到welcome,说明solr就安装完毕

13.访问后台管理系统进行测试http://localhost:8080/solr/index.html
14.在tomcat的bin\catalina.bat中配置日志文件的环境参数
set "JAVA_OPTS=%JAVA_OPTS% -Dsolr.log.dir=D:\live\solr\logs"

2.4 Linux下安装Solr
在实际的生产环境中,通常我们都需要将solr安装到linux服务器中;由于我们目前属于学习阶段。我们就使用虚拟机来模拟一个Linux服务器安装solr;
环境准备
Cent0S 7.0 linux系统;
Jdk1.8 linux安装包
tomcat:tomcat8.5
solr7.x 安装包
http://mirror.bit.edu.cn/apache/lucene/solr/7.7.2/solr-7.7.2.tgz
这一块的安装包在资料中已经准备好了;
将linux中相关的安装包上传到linux
sftp上传 Jdk1.8 tomcat8.5 solr7.x 安装包到linux;
-
使用CRT连接到Linux
-
alt+p打开sftp,上传相关的软件安装到到linux

安装jdk
1.解压jdk
tar -xzvf jdk18 -C /usr/local
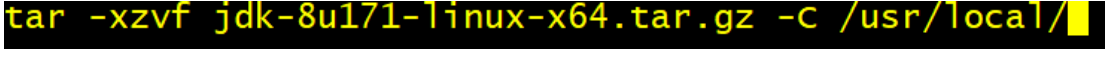
2.配置环境变量
vi /etc/profile
export JAVA_HOME=/usr/local/jdk1.8.0_171
export PATH=$JAVA_HOME/bin:$PATH
3.重新加载profile文件,让配置文件生效;
4.测试
安装tomcat,tomcat的安装比较简单,只需要解压即可;
安装solr,安装solr的过程和windows系统过程完全相同。只不过通过linux命令来操作而已;
1.解压solr安装包,直接解压在宿主目录即可;
2.将server/solr-webapp/webapp下的solr服务打war包;
2.1 进入到webapp目录
cd server/solr-webapp/webapp
2.2 将webapp中的代码打成war包
jar -cvf solr.war ./*
3.将war包部署到tomcat的webapps目录
4.启动tomcat,解压solr.war
4.1进入到tomcat的bin目录
cd /usr/local/apache-tomcat-8.5.50
4.2 启动tomcat
4.3 进入到webapp目录中查看
5. 修改webapp/solr/WEB-INF/web.xml的配置solrhome的位置;
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>“你的solrhome位置”</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>

6.取消安全配置(和window相同)
7.将solr-7.7.2/server/solr中所有的文件复制到solrHome
7.1进入到solr-7.7.2/server/solr
7.2将所有的文件复制到solrHome
8.拷贝日志工具相关jar包:将solr-7.7.2/server/lib/ext下的jar包拷贝至上面Tomcat下Solr的/WEB-INF/lib/目录下
8.1 进入solr-7.7.2/server/lib/ext
cd solr-7.7.2/server/lib/ext
8.2 将所有文件复制到Tomcat下Solr的/WEB-INF/lib/
9.拷贝 metrics相关jar包:将solr-7.7.2/server/lib下metrics相关jar包也拷贝至/WEB-INF/lib/目录下
9.1 进入solr-7.7.2/server/lib
cd solr-7.7.2/server/lib

9.2 将metrics-开始的所有文件复制到Tomcat下Solr的/WEB-INF/lib/
10. 将solr安装包中dist目录中和数据导入相关的2个包,复制到tomcat/webapps/solr/WEB-INF/lib
11.拷贝log4j2配置文件:将solr-7.7.2/server/resource目录中的log4j配置文件拷入web工程目录WEB-INF/classes(自行创建目录) ,并且修改日志文件的路径
11.1 进入到solr-7.7.2/server/resource目录中
11.2 将log4j2的配置文件复制到solr 的WEB-INF/classes目录;

3. Solr基础
3.1 SolrCore
solr部署启动成功之后,需要创建core才可以使用的,才可以使用Solr;类似于我们安装完毕MySQL以后,需要创建数据库一样;
3.1.1 什么是SolrCore
在Solr中、每一个Core、代表一个索引库、里面包含索引数据及其配置信息。
Solr中可以拥有多个Core、也就是可以同时管理多个索引库、就像mysql中可以有多个数据库一样。
所以SolrCore可以理解成MySQL中的数据库;
3.1.2 SolrCore维护(windows)
简单认识SolrCore以后,接下来要完成的是SolrCore的创建。在创建solrCore之前,我们首先认识一下SolrCore目录结构:
1.SolrCore目录结构
Core中有二个重要目录:conf和data
conf:存储SolrCore相关的配置文件;
data:SolrCore的索引数据;
core.properties:SolrCore的名称,name=SolrCore名称;
所以搭建一个SolrCore只需要创建 2个目录和一个properties文件即可;
2.SolrHome中搭建SolrCore
2.1 solrCore的目录结构搞清楚以后,接下来就是关于SolrCore在哪里进行创建呢?
在之前搭建Solr的时候,我们说一个solr_home是由多个solrCore构成,所以solrCore是搭建在solrHome中;
2.2 将solr安装包中的配置文件复制到conf目录;
搭建好solrCore以后,conf目录还没没有配置文件,我们需要将solr安装包中提供的示例配置文件复制到conf目录
solr安装包中配置文件的位置:solr-7.7.2\example\example-DIH\solr\solr\conf
2.3 重启solr
2.4 在solr的管理后台来查看
3.如何创建多个solrCore;
只需要复制SolrCore一份,重启solr;

3.1.3 SolrCore维护(linux)
进入到SolrHome
cd /usr/local/solr_home/

创建SolrCore
mkdir -p collection1/data
mkdir -p collection1/conf
cd collection1
touch core.properties

将solr安装包中提供的示例配置文件复制到conf目录
cd solr-8.3.1/example/example-DIH/solr/solr/conf/
cp -r * /usr/local/solr_home/collection1/conf/
重启tomcat
访问后台管理系统
3.2 Solr后台管理系统的使用
上一个章节我们已经学习完毕如何在solr中创建SolrCore。有了SolrCore以后我们就可以进行索引和搜索的操作,在进行索引和搜索操作之前,首先学习一下Solr后台管理系统的使用;
1.DashBoard:solr的版本信息、jvm的相关信息还有一些内存信息。
2.Logging:日志信息,也有日志级别,刚进入查看的时候肯定是有几个警告(warn)信息的,因为复制solr的时候路径发生了变化导致找不到文件,但是并不影响。
3.Core Admin:SolrCore的管理页面。可以使用该管理界面完成SolrCore的卸载。也可以完成SolrCore的添加
能添加的前提,SolrCore在solr_home中目录结构是完整的。
4.Java Properties:顾名思义,java的相关配置,比如类路径,文件编码等。
5.Thread Dump:solr服务器当前活跃的一些线程的相关信息。
以上的5个了解一下就行。
6.当我们选择某一个solrCore以后,又会出现一些菜单,这些菜单就是对选择的SolrCore进行操作的,接下来我们重点要讲解的就是这些菜单的使用;
3.2.1 Documents
首先我们先来讲解第一个菜单:Documents
作用:向SolrCore中添加数据,删除数据,更新数据(索引)。
在讲解如何使用Documents菜单向Solr中添加数据之前,我们首先回顾一下我们之前在Lucene中学习的一些概念;
1. 概念介绍:
文档:document是lucene进行索引创建以及搜索的基本单元,我们要把数据添加到Lucene的索引库中,数据结构就是document,如果我从Lucene的索引库中进行数据的搜索, 搜索出来的结果的数据结构也document;
文档的结构:学习过Lucene的同学都知道,一个文档是由多个域(Field)组成,每个域包含了域名和域值;
如果数据库进行类比,文档相单于数据库中的一行记录,域(Field)则为一条记录的字段。

索引:通常把添加数据这个操作也成为创建索引;
搜索:通常把搜索数据这个操作也成为搜索索引;
倒排索引:
Solr添加数据的流程:


Lucene首先对文档域中的数据进行分词,建立词和文档之间的关系;

将来我们就可以根据域中的词,快速查找到对应的文档;
Lucene中相关概念回顾完毕;
2.添加文档
使用后台管理系统,向Solr中添加文档。文档的数据格式可以是JSON,也可以XML;
以JSON的形式添加文档:
以XML的形式添加文档

通常我们可以添加一些测试数据;
3.修改数据
Solr要求每一个文档都需要有一个id域;如果添加的文档id在SolrCore中已经存在,即可完成数据修改;
4.删除数据
只能通过XML的格式删除文档;下面我们提供2种删除方式
根据id删除
<delete>
<id>8</id>
</delete>
<commit/>
根据条件删除,需要指定查询的字符串,根据查询的字符串删除。查询字符串如何编写,后面详细讲解。
<delete>
<query>*:*</query>
</delete>
<commit/>
3.2.2 Analyse
作用:测试域/域类型(后面讲解)分词效果;
之前我们在讲解倒排索引的时候,当我们向Solr中添加一个文档,底层首先要对文档域中的数据进行分词。
建立词和文档关系。
测试刚才添加文档的域id ,title,name域的分词效果;
思考的问题?
id为什么不分词,name域为什么可以分词?
name域可以对中文进行分词吗?
添加文档的时候,域名可以随便写吗?
要想搞清楚这些问题,我们需要学习Solr的配置;
3.2.3 Solr的配置-Field
在Solr中我们需要学习其中4个配置文件;
SolrHome中solr.xml
SolrCore/conf中solrconfig.xml
SolrCore/confSolrCore中managed-schema
SolrCore/conf/data-config.xml
其中我们最常用的一个配置文件,managed-schema。
managed-schema(掌握)
在Solr中进行索引时,文档中的域需要提前在managed-schema文件中定义,在这个文件中,solr已经提前定义了一些域,比如我们之前使用的id,price,title域。通过管理界面查看已经定义的域;
下面就是solr中一定定义好的一个域,name
<field name="name" type="text_general" indexed="true" stored="true"/>
field标签:定义一个域;
name属性:域名
indexed:是否索引,是否可以根据该域进行搜索;一般哪些域不需要搜索,图片路径。
stored:是否存储,将来查询的文档中是否包含该域的数据; 商品的描述。
举例:将图书的信息存储到Solr中;Description域。indexed设置为true,store设置成false;
可以根据商品描述域进行查询,但是查询出来的文档中是不包含description域的数据;
multiValued:是否多值,该域是否可以存储一个数组; 图片列表;
required:是否必须创建文档的时候,该域是否必须;id
type:域类型,决定该域使用的分词器。分词器可以决定该域的分词效果(分词,不分词,是否支持中文分词)。域的类型在使用之前必须提前定义;在solr中已经提供了很多的域类型
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<!-- in this example, we will only use synonyms at query time
<filter class="solr.SynonymGraphFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
<filter class="solr.FlattenGraphFilterFactory"/>
-->
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
以上这些概念和Lucene中讲解的是一样的;
自定义一个商品描述域:
<field name="item_description" type="text_general" indexed="true" stored="false"/>
定义一个图片域
<field name="item_image" type="string" indexed="false" stored="true" multiValued=true/>
重启solr

测试添加文档
{id:"1101",name:"java编程思想",item_image:["big.jpg","small.jpg"],item_description:"lucene是apache的开源项目,是一个全文检索的工具包。"}

3.2.4 Solr的配置-FieldType
介绍
上一章节我们讲解了Field的定义。接下来我们要讲解的是FieldType域类型;
刚才我们给大家讲解了如何在schema文件中定义域,接下来我们要讲解域类型如何定义;
每个域都需要指定域类型,而且域类型必须提前定义。域类型决定该域使用的索引和搜索的分词器,影响分词效果。
Solr中已经提供好了一些域类型;
text_general:支持英文分词,不支持中文分词;
string:不分词;适合于id,订单号等。
pfloat:适合小数类型的域,特殊分词,支持大小比较;
pdate:适合日期类型的域,特殊分词,支持大小比较;
pint:适合整数类型的域,特殊分词,支持大小比较;
plong:适合长整数类型的域,特殊分词,支持大小比较;
我们以text_general为例看一下如何定义FiledType.text_general是solr中已经提供好的一个域类型;他的定义如下;
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<!-- in this example, we will only use synonyms at query time
<filter class="solr.SynonymGraphFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
<filter class="solr.FlattenGraphFilterFactory"/>
-->
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
3.2.4.1 相关属性
name:域类型名称,定义域类型的必须指定,并且要唯一;将来定义域的时候需要指定通过域名称来指定域类型;(重点)
class:域类型对应的java类,必须指定,如果该类是solr中的内置类,使用solr.类名指定即可。如果该类是第三方的类,需要指定全类名。(重点)
如果class是TextField,我们还需要使用子标签来配置分析器;
positionIncrementGap:用于多值字段,定义多值间的间隔,来阻止假的短语匹配(了解)。
autoGeneratePhraseQueries:用于文本字段,如果设为true,solr会自动对该字段的查询生成短语查询,即使搜索文本没带“”(了解)
enableGraphQueries:是否支持图表查询(了解)
docValuesFormat:docValues字段的存储格式化器:schema-aware codec,配置在solrconfig.xml中的(了解)
postingsFormat:词条格式器:schema-aware codec,配置在solrconfig.xml中的(了解)
3.2.4.2 Solr自带的FieldType类
solr除了提供了TextField类,我们也可以查看它提供的其他的FiledType类,我们可以通过官网查看其他的FieldType类的作用:
Field Types Included with Solr | Apache Solr Reference Guide 8.1

以上的FieldType类的使用,我们不会一一进行讲解,只会讲解常用的一部分;
3.2.4.3 FieldType常用类的使用
首先我们来讲解第一个FieldType类;
TextField:支持对字符类型的数据进行分词;对于 solr.TextField 域类型,需要为其定义分析器;
我们首先先来搞清楚什么是Solr分析器;
分析器的基本概念
分析器就是将用户输入的一串文本分割成一个个token,一个个token组成了tokenStream,然后遍历tokenStream对其进行过滤操作,比如去除停用词,特殊字符,标点符号和统一转化成小写的形式等。分词的准确的准确性会直接影响搜索的结果,从某种程度上来讲,分词的算法不同,都会影响返回的结果。因此分析器是搜索的基础;
分析器的工作流程:
分词
过滤

在solr中已经为我们提供了很多的分词器及过滤器;
Solr中提供的分词器tokenizer:Tokenizers | Apache Solr Reference Guide 8.1
标准分词器,经典分词器,关键字分词器,单词分词器等,不同的分词器分词的效果也不尽相同;
Solr中提供的过滤器tokenfilter:About Filters | Apache Solr Reference Guide 8.1
不同的过滤器过滤效果也不同,有些是去除标点符号的,有些是大写转化小写的;
这是关于Solr中的分析器我们先介绍到这里;
常用分词器的介绍
Standard Tokenizer
作用:这个Tokenizer将文本的空格和标点当做分隔符。注意,你的Email地址(含有@符合)可能会被分解开;用点号(就是小数点)连接的部分不会被分解开。对于有连字符的单词,也会被分解开。
例子:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
</analyzer>
输入:“Please, email john.doe@foo.com by 03-09, re: m37-xq.”
输出: “Please”, “email”, “john.doe”, “foo.com”, “by”, “03”, “09”, “re”, “m37”, “xq
Classic Tokenizer
作用:基本与Standard Tokenizer相同。注意,用点号(就是小数点)连接的部分不会被分解开;用@号(Email中常用)连接的部分不会被分解开;互联网域名(比如wo.com.cn)不会被分解开;有连字符的单词,如果是数字连接也会被分解开。
例子:
<analyzer>
<tokenizer class="solr.ClassicTokenizerFactory"/>
</analyzer>
输入: “Please, email john.doe@foo.com by 03-09, re: m37-xq.”
输出: “Please”, “email”, “john.doe@foo.com”, “by”, “03-09”, “re”, “m37-xq”
Keyword Tokenizer
作用:把整个输入文本当做一个整体。
例子:
<analyzer>
<tokenizer class="solr.KeywordTokenizerFactory"/>
</analyzer>
输入: “Please, email john.doe@foo.com by 03-09, re: m37-xq.”
输出: “Please, email john.doe@foo.com by 03-09, re: m37-xq.”
Letter Tokenizer
作用:只处理字母,其他的符号都被认为是分隔符
例子:
<analyzer>
<tokenizer class="solr.LetterTokenizerFactory"/>
</analyzer>
输入: “I can’t.”
输出: “I”, “can”, “t”
Lower Case Tokenizer
作用:以非字母元素分隔,将所有的字母转化为小写。
<analyzer>
<tokenizer class="solr.LowerCaseTokenizerFactory"/>
</analyzer>
输入: “I just LOVE my iPhone!”
输出: “i”, “just”, “love”, “my”, “iphone”
N-Gram Tokenizer
作用:将输入文本转化成指定范围大小的片段的词,注意,空格也会被当成一个字符处理;
| 参数 | 值 | 说明 |
|---|---|---|
| minGramSize | 整数,默认1 | 指定最小的片段大小,需大于0 |
| maxGramSize | 整数,默认2 | 指定最大的片段大小,需大于最小值 |
例子1:
<analyzer>
<tokenizer class="solr.NGramTokenizerFactory"/>
</analyzer>
输入: “hey man”
输出: “h”, “e”, “y”, ” “, “m”, “a”, “n”, “he”, “ey”, “y “, ” m”, “ma”, “an”
例子2:
<analyzer>
<tokenizer class="solr.NGramTokenizerFactory" minGramSize="4" maxGramSize="5"/>
</analyzer>
输入: “bicycle”
输出: “bicy”, “bicyc”, “icyc”, “icycl”, “cycl”, “cycle”, “ycle“
Edge N-Gram Tokenizer
作用:用法和N-Gram Tokenizer类似
| 参数 | 值 | 说明 |
|---|---|---|
| minGramSize | 整数,默认1 | 指定最小的片段大小,需大于0 |
| maxGramSize | 整数,默认1 | 指定最大的片段大小,需大于或等于最小值 |
| side | “front” 或 “back”, 默认”front” | 指定从哪个方向进行解析 |
例子1:
<analyzer>
<tokenizer class="solr.EdgeNGramTokenizerFactory" />
</analyzer>
输入: “babaloo”
输出: “b”
例子2:
<analyzer>
<tokenizer class="solr.EdgeNGramTokenizerFactory" minGramSize="2" maxGramSize="5"/>
</analyzer>
输入: “babaloo”
输出: “ba”, “bab”, “baba”, “babal”
例子3:
<analyzer>
<tokenizer class="solr.EdgeNGramTokenizerFactory" minGramSize="2" maxGramSize="5" side="back"/>
</analyzer>
输入: “babaloo”
输出: “oo”, “loo”, “aloo”, “baloo”
Regular Expression Pattern Tokenizer
作用:可以指定正则表达式来分析文本。
| 参数 | 值 | 说明 |
|---|---|---|
| attern | 必选项 | 正规表达式 |
| roup | 数字,可选,默认-1 | 负数表示用正则表达式做分界符;非正数表示只分析满足正则表达式的部分;0表示满足整个正则表达式;大于0表示满足正则表达式的第几个括号中的部分 |
例子1:
<analyzer>
<tokenizer class="solr.PatternTokenizerFactory" pattern="\s*,\s*"/>
</analyzer>
输入: “fee,fie, foe , fum”
输出: “fee”, “fie”, “foe”, “fum”
例子2:
<analyzer>
<tokenizer class="solr.PatternTokenizerFactory" pattern="[A-Z][A-Za-z]*" group="0"/>
</analyzer>
输入: “Hello. My name is Inigo Montoya. You killed my father. Prepare to die.”
输出: “Hello”, “My”, “Inigo”, “Montoya”, “You”, “Prepare”
这里的group为0,表示必须满足整个表达式,正则表达式的含义是以大写字母开头,之后是大写字母或小写字母的组合。
例子3:
<analyzer>
<tokenizer class="solr.PatternTokenizerFactory" pattern="(SKU|Part(\sNumber)?):?\s(\[0-9-\]+)" group="3"/>
</analyzer>
输入: “SKU: 1234, Part Number 5678, Part: 126-987”
输出: “1234”, “5678”, “126-987”
这个group等于3,表示满足第三个括号”[0-9-]+”中的正则表达式
White Space Tokenizer
作用:这个Tokenizer将文本的空格当做分隔符。
| 参数 | 值 | 说明 |
|---|---|---|
| rule | 默认java | 如何定义空格 |
例子:
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory" rule="java" />
</analyzer>
输入: “To be, or what?”
输出: “To”, “be,”, “or”, “what?”
在这些分词器中,我们最常用的一个分词器。Standard Tokenizer;但也仅仅只能对英文进行分词;
常用过滤器介绍
上一小结我们学习了Solr中的常用分词器,接下来我们讲解过滤器。过滤器是对分词器的分词结果进行再次处理,比如:将词转化为小写,排除掉停用词等。
Lower Case Filter
作用:这个Filter将所有的词中大写字符转化为小写
例子:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
原始文本: “Down With CamelCase”
输入: “Down”, “With”, “CamelCase”
输出: “down”, “with”, “camelcase”
Length Filter
作用:这个Filter处理在给定范围长度的tokens。
参数:
| 参数 | 值 | 说明 |
|---|---|---|
| min | 整数,必填 | 指定最小的token长度 |
| max | 整数,必填,需大于min | 指定最大的token长度 |
例子:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LengthFilterFactory" min="3" max="7"/>
</analyzer>
原始文本: “turn right at Albuquerque”
输入: “turn”, “right”, “at”, “Albuquerque”
输出: “turn”, “right”
pattern Replace Filter
作用:这个Filter可以使用正则表达式来替换token的一部分内容,与正则表达式想匹配的被替换,不匹配的不变。
参数:
| 参数 | 值 | 说明 |
|---|---|---|
| pattern | 必填,正则表达式 | 需要匹配的正则表达式 |
| replacement | 必填,字符串 | 需要替换的部分 |
| replace | “all” 或 “first”, 默认”all” | 全部替换还是,只替换第一个 |
例子1:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.PatternReplaceFilterFactory" pattern="cat" replacement="dog"/>
</analyzer>
原始文本: “cat concatenate catycat”
输入: “cat”, “concatenate”, “catycat”
输出: “dog”, “condogenate”, “dogydog”
例子2:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.PatternReplaceFilterFactory" pattern="cat" replacement="dog" replace="first"/>
</analyzer>
原始文本: “cat concatenate catycat”
输入: “cat”, “concatenate”, “catycat”
输出: “dog”, “condogenate”, “dogycat”
Stop Words Filter
作用:这个Filter会在解析时忽略给定的停词列表(stopwords.txt)中的内容;
参数:
| 参数 | 值 | 说明 |
|---|---|---|
| words | 可选,停词列表 | 指定停词列表的路径 |
| format | 可选,如”snowball” | 停词列表的格式 |
| ignoreCase | 布尔值,默认false | 是否忽略大小写 |
例子1:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" words="stopwords.txt"/>
</analyzer>
保留词列表stopwords.txt
be
or
to
原始文本: “To be or what?”
输入: “To”(1), “be”(2), “or”(3), “what”(4)
输出: “To”(1), “what”(4)
例子2:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" words="stopwords.txt" ignoreCase="true"/>
</analyzer>
保留词列表stopwords.txt
be
or
to
原始文本: “To be or what?”
输入: “To”(1), “be”(2), “or”(3), “what”(4)
输出: “what”(4)
Keep Word Filter
作用:这个Filter将不属于列表中的单词过滤掉。和Stop Words Filter的效果相反。
| 参数 | 值 | 说明 |
|---|---|---|
| words | 必填,以.txt结尾的文件 | 提供保留词列表 |
| ignoreCase | 布尔值,默认false | 是否忽略保留词列表大小写 |
例子1:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.KeepWordFilterFactory" words="keepwords.txt"/>
</analyzer>
保留词列表keepwords.txt
happy
funny
silly
原始文本: “Happy, sad or funny”
输入: “Happy”, “sad”, “or”, “funny”
输出: “funny”
例子2:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.KeepWordFilterFactory" words="keepwords.txt" ignoreCase="true" />
</analyzer>
保留词列表keepwords.txt
happy
funny
silly
原始文本: “Happy, sad or funny”
输入: “Happy”, “sad”, “or”, “funny”
输出: “Happy”, “funny”
Synonym Filter
作用:这个Filter用来处理同义词;
| 参数 | 值 | 说明 |
|---|---|---|
| synonyms | 必选,以.txt结尾的文件 | 指定同义词列表 |
| ignoreCase | 布尔值,默认false | 是否忽略大小写 |
| format | 可选,默认solr | 指定解析同义词的策略 |
注意,常用的同义词列表格式:
1. 以#开头的行为注释内容,忽略
2. 以,分隔的文本,为双向同义词,左右内容等价,互为同义词
3. 以=>分隔的文本,为单向同义词,匹配到左边内容,将替换为右边内容,反之不成立
例子:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory" synonyms="mysynonyms.txt"/>
</analyzer>
同义词列表synonyms.txt
couch,sofa,divan
teh => the
huge,ginormous,humungous => large
small => tiny,teeny,weeny
原始文本: “teh small couch”
输入: “teh”(1), “small”(2), “couch”(3)
输出: “the”(1), “tiny”(2), “teeny”(2), “weeny”(2), “couch”(3), “sofa”(3), “divan”(3)
原始文本: “teh ginormous, humungous sofa”
输入: “teh”(1), “ginormous”(2), “humungous”(3), “sofa”(4)
输出: “the”(1), “large”(2), “large”(3), “couch”(4), “sofa”(4), “divan”(4)
到这常用的过滤器我们就讲解完毕了,这些常用的过滤器将来我们在开发一些复杂的需求时候,都可能会用到;
TextField的使用
前面我们已经学习完毕solr中的分词器和过滤器,有了这些知识的储备后,我们就可以使用TextField这种类定义FieldType.
之前我们说过,在我们在使用TextField作为FieldType的class的时候,必须指定Analyzer,用一个<analyzer>标签来声明一个Analyzer;
方式一:直接通过class属性指定分析器类,该类必须继承org.apache.lucene.analysis.Analyzer
<fieldType name="nametext" class="solr.TextField">
<analyzer class="org.apache.lucene.analysis.core.WhitespaceAnalyzer"/>
</fieldType>
这里的WhitespaceAnalyzer就是一种分析器,这个分析器中封装了我们之前讲过了一个分词器WhitespaceTokenizer。
这种方式写起来比较简单,但是透明度不够,使用者可能不知道这个分析器中封装了哪些分词器和过滤器
测试:

对于那些复杂的分析需求,我们也可以在分析器中灵活地组合分词器、过滤器;
方式二:可以灵活地组合分词器、过滤器
<fieldType name="nametext" class="solr.TextField">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" words="stopwords.txt"/>
</analyzer>
</fieldType>
测试:
方式三:如果该类型字段索引、查询时需要使用不同的分析器,则需区分配置analyzer
<fieldType name="nametext" class="solr.TextField">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.SynonymFilterFactory" synonyms="syns.txt"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
测试索引分词效果:
测试搜索分词效果
通过测试我们发现索引和搜索产生的分词结果是不同;
接下来我们使用myFeildType3定义一个域。使用该域创建一个文档。我们来测试;
item_content:sofa可以搜索到吗?
索引的时候: sofa被分为couch,sofa,divan;
搜索的时候,sofa这个内容就被分为sofa这一个词;
item_content:couch可以搜索到吗?
item_content:small可以搜索到吗?
索引的时候,small经过同义词过滤器变成 tiny,teeny,weeny 。small并没有和文档建立倒排索引关系;
搜索的时候small内容只能被分为samll这个词;所以找不到;
结论:
所以一般我们在定义FieldType的时候,索引和搜索往往使用的分析器规则相同;
或者索引的时候采用细粒度的分词器,目的是让更多的词和文档建立倒排索引;
搜索的时候使用粗粒度分词器,词分的少一点,提高查询的精度;
DateRangeField的使用

Solr中提供的时间域类型( DatePointField, DateRangeField)是以时间毫秒数来存储时间的。要求域值以ISO-8601标准格式来表示时间:yyyy-MM-ddTHH:mm:ssZ。Z表示是UTC时间,如1999-05-20T17:33:18Z;
秒上可以带小数来表示毫秒如:1972-05-20T17:33:18.772Z、1972-05-20T17:33:18.77Z、1972-05-20T17:33:18.7Z
域类型定义很简单:
<fieldType name="myDate" class="solr.DateRangeField" />
使用myDate域类型定义一个域
<field name="item_birthday" type="myDate" indexed="true" stored="true" />
基于item_birthday域来索引
{id:666777,name:"xiaoming",item_birthday:"2020-3-6T19:21:22Z"}
{id:777888,name:"misscang",item_birthday:"2020-3-6T19:22:22.333Z"}
如何基于item_birthday搜索
语法:
查询时如果是直接的时间串,需要用转义字符进行转义:
item_birthday:2020-2-14T19\:21\:22Z
#用字符串表示的则不需要转义
item_birthday:"2020-2-14T19:21:22Z"
DateRangeField除了支持精确时间查询,也支持对间段数据的搜索,支持两种时间段表示方式:
方式一:截断日期,它表示整个日期跨度的精确指示。
方式二:时间范围,语法 [t1 TO t2] {t1 TO t2},中括号表示包含边界,大括号表示不包含边界
例子:
2000-11 #表示2000年11月整个月.
2000-11T13 #表示2000年11月每天的13点这一个小时
[2000-11-01 TO 2014-12-01] #日到日
[2014 TO 2014-12-01] #2014年开始到2014-12-01止.
[* TO 2014-12-01] #2014-12-01(含)前.
演示:
item_birthday:2020-11-21
item_birthday:[2020-02-14T19:21 TO 2020-02-14T19:22]
Solr中还支持用 【NOW ±/ 时间】的数学表达式来灵活表示时间。
NOW+1MONTH #当前时间加上1个月
NOW+2MONTHS #当前时间加上两个月,复数要机上S
NOW-1DAY
NOW-2DAYS
NOW/DAY, NOW/HOURS表示,截断。如果当前时间是2017-05-20T23:32:33Z,那么即是2017-05-20T00:00:00Z,2017-05-20T23:00:00Z。取当日的0点,取当前小时0点
NOW+6MONTHS+3DAYS/DAY
1972-05-20T17:33:18.772Z+6MONTHS+3DAYS/DAY
演示:
item_birthday:[NOW-3MONTHS TO NOW] 生日在三个月内的;
item_birthday:[NOW/DAY TO NOW] 当前时间的0点到当前时间
item_birthday:[NOW/HOURS TO NOW] 当前小时的0点到当前时间
这个关于DateRangeField我们就讲解完毕;
EnumFieldType的使用

EnumFieldType 用于域值是一个枚举集合,且排序顺序可预定的情况,如新闻分类这样的字段。如果我们想定义一个域类型,他的域值只能取指定的值,我们就可以使用EnumFieldType 定义该域类型;
域类型定义:
<fieldType name="mySex" class="solr.EnumFieldType"
enumsConfig="enumsConfig.xml" enumName="sexType" docValues="true" />
属性:
| 参数 | 值 | 说明 |
|---|---|---|
| enumsConfig | enumsConfig.xml | 指定枚举值的配置文件,绝对路径或相对内核conf/的相对路径 |
| enumName | 任意字符串 | 指定配置文件的枚举名。 |
| docValues | true/false | 枚举类型必须设置 true |
enumsConfig.xml配置示例(若没有该文件则新建)如下:注意以UTF-8无BOM格式保存;
<?xml version="1.0" encoding="UTF-8"?>
<enumsConfig>
<enum name="sexType">
<value>男</value>
<value>女</value>
</enum>
<enum name="new_cat">
<value>a</value>
<value>b</value>
<value>c</value>
<value>d</value>
</enum>
</enumsConfig>
演示:
<field name="item_sex" type="mySex" indexed="true" stored="true" />
基于item_sex进行索引
{id:123321,item_birthday:"1992-04-20T20:33:33Z",item_content:"i love sofa",item_sex:"男"}
{id:456564,item_birthday:"1992-04-20T20:33:33Z",item_content:"i love sofa",item_sex:"女"}
{id:789987,item_birthday:"1992-04-20T20:33:33Z",item_content:"i love sofa",item_sex:"妖"}
报错

基于item_sex进行搜索
item_sex:男
item_sex:女
到此关于FieldType就讲解完毕;
3.2.5 Solr的配置-DynamicField 动态域
在schema文件中我们还可以看到一种标签dynamicField,这个标签也是用来定义域的;他和field标签有什么区别呢
作用:如果某个业务中有近百个域需要定义,其中有很多域类型是相同,重复地定义域就十分的麻烦,因此可以定一个域名的规则,索引的时候,只要域名符合该规则即可;
如:整型域都是一样的定义,则可以定义一个动态域如下
<dynamicField name="*_i" type="pint" indexed="true" stored="true"/>
注意:动态域只能用符号*通配符进行表示,且只有前缀和后缀两种方式
基于动态域索引;
{id:38383,item_birthday:"1992-04-20T20:33:33Z",item_content:"i love sofa",item_sex:"女",
bf_i:5}
bf_i就是符合上面动态域的域名;
3.2.6 Solr的配置-复制域
在schema文件中我们还可以看到一种标签copyField ,这个标签是用来定义复制域的;复制域的作用是什么呢?
作用:复制域允许将一个或多个域的数据填充到另外一个域中。他的最主要的作用,基于某一个域搜索,相当于在多个域中进行搜索;
<copyField source="cat" dest="text"/>
<copyField source="name" dest="text"/>
<copyField source="manu" dest="text"/>
<copyField source="features" dest="text"/>
<copyField source="includes" dest="text"/>
cat name manu features includes text都是solr提前定义好的域。
将 cat name manu features includes域的内容填充到text域中;
将来基于text域进行搜索,相当于在cat name manu features includes域中搜索;
演示:
索引:
{id:1,name:"pitter wang"}
{id:2,name:"pitter ma"}
{id:3,manu:"jack ma"}
{id:4,manu:"joice liu"}
搜索:
text:ma
结果:

3.2.7 Solr的配置-主键域
指定用作唯一标识文档的域,必须。在solr中默认将id域作为主键域;也可以将其他改为主键域,但是一般都会修改;
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<uniqueKey>id</uniqueKey>
注意:主键域不可作为复制域,且不能分词。
3.2.8 Solr的配置-中文分词器
中文分词器的介绍
之前我们给大家讲解Solr中的分词器的时候,我们说Solr中最常用的分词器是Standard Tokenizer,
Standard Tokenizer可以对英文完成精确的分词,但是对中文分词是有问题的。
之前我们在schema文件中定义的一个FieldType.name为myFeildType2,class为TextField。使用TextField定义的域类型需要指定分析器,该分析器中使用的分词器就是Standard Tokenizer。
<fieldType name="myFeildType2" class="solr.TextField">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" words="stopwords.txt"/>
</analyzer>
</fieldType>
测试myFeildType2的分词效果:
对于这种分词效果,显然不符合我们的要求.
中文分词一直以来是分词领域的一个难题,因为中文中的断词需要依赖语境。相同的一句话语境不同可能分出的词就不同。
在Solr中提供了一个中文分词器SmartCN。但是该分词器并没有纳入到Solr的正式包中,属于扩展包。
位置:solr-7.7.2\contrib\analysis-extras\lucene-libs\lucene-analyzers-smartcn-7.7.2.jar
而且SmartCN对中文分词也不太理想,目前市面上比较主流的中文分词器有IK,MMSeg4J,Ansj,Jcseg,TCTCLAS,HanLP.等
接下来我们就介绍一下这些分词器。并且使用这些分词器定义FieldType;
IK Analyzer
IK Analyzer是一个基于java语言开发的轻量级中文分词器包。采用词典分词的原理,允许使用者扩展词库。
使用流程:
1.下载地址:GitHub - EugenePig/ik-analyzer-solr5: IKAnalyzer for Solr5
2.编译打包源码:mvn package
3.安装: 把ik-analyzer-solr5-5.x.jar拷贝到Tomcat的Solr/WEB-INF/lib目录;
4.配置: 把IKAnalyzer.cfg.xml和stopword.dic(停用词库),ext.dic(扩展词库)拷贝到Solr/WEB-INF/classes。
5.使用IK的分析器定义FiledType,IKAnalyzer分析器中提供了中分词器和过滤器。
<fieldType name ="text_ik" class ="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
6.测试text_ik分词效果。
7.传智播客,被单字分词,此处我们也可以添加扩展词库,让传智播客分成一个词;
编辑Solr/WEB-INF/classes/ext.dic(扩展词库),加入传智播客;
再次测试
到此关于IKAnalyzer我们就讲解完毕。
Ansj
Ansj 是一个开源的 Java 中文分词工具,基于中科院的 ictclas 中文分词算法,比其他常用的开源分词工具(如mmseg4j)的分词准确率更高。Ansj中文分词是一款纯Java的、主要应用于自然语言处理的、高精度的中文分词工具,目标是“准确、高效、自由地进行中文分词”,可用于人名识别、地名识别、组织机构名识别、多级词性标注、关键词提取、指纹提取等领域,支持行业词典、用户自定义词典。
使用流程:
1.下载ansj以及其依赖包nlp-lang的源码
GitHub - NLPchina/ansj_seg: ansj分词.ict的真正java实现.分词效果速度都超过开源版的ict. 中文分词,人名识别,词性标注,用户自定义词典
GitHub - NLPchina/nlp-lang: 这个项目是一个基本包.封装了大多数nlp项目中常用工具
2.编译打包源码mvn package -DskipTests=true

进入到ansj/plugin/ansj_lucene5_plugin目录,打包ansj_lucene5
4.安装:将以上三个jar包复制到solr/WEB-INF/lib目录
5.配置:将ansj的词库和配置文件复制到solr/WEB-INF/classes目录
6.使用ansj中提供的分析器,分词器配置FieldType
<fieldType name="text_ansj" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.ansj.lucene.util.AnsjTokenizerFactory" isQuery="false"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.ansj.lucene.util.AnsjTokenizerFactory"/>
</analyzer>
</fieldType>
7.测试
关于Ansj中文分词器的使用我们就给大家讲解完毕。
MMSeg4J
mmseg4j用Chih-Hao Tsai 的MMSeg算法实现的中文分词工具包,并实现lucene的analyzer和solr的r中使用。 MMSeg 算法有两种分词方法:Simple和Complex,都是基于正向最大匹配。Complex加了四个规则。官方说:词语的正确识别率达到了 98.41%。mmseg4j已经实现了这两种分词算法。
流程:
1.下载mmseg4j-core及mmseg4J-solr的源码;
mmseg4j-core包含了一些词库;
mmseg4J-solr包含了和solr整合相关的分析器
GitHub - chenlb/mmseg4j-core: mmseg4j core MMSEG for java chinese analyzer
GitHub - chenlb/mmseg4j-solr: mmseg4j for lucene or solr analyzer
2.编译打包源码:mvn package
3.安装: 把 mmseg4j-core.jar和mmseg4J-solr.jar复制到Solr/WEB-INF/lib
4.使用mmseg4j的分析器定义FiledType,mmseg4j提供了3种不同模式。分别针对不同情况的解析。
tokenizer 的参数:
-
dicPath 参数 - 设置词库位置,支持相对路径(相对于 solrCore).
-
mode 参数 - 分词模式。
complex:复杂模式,针对语义复杂的情况
<fieldtype name="textComplex" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" dicPath="dic"/>
</analyzer>
</fieldtype>
max-word:最大词模式,针对分出的词最多
<fieldtype name="textMaxWord" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="max-word"
dicPath="dic"/>
</analyzer>
</fieldtype>
simple:简单模式,针对一般情况
<fieldtype name="textSimple" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="simple" dicPath="dic" />
</analyzer>
</fieldtype>
5.在collection1下创建词库目录dic
将 mmseg4j-core/resources/data目录中的词库文件复制到solr_home/collection1/dic目录
chars.dic 是单字的词,一般不用改动我们不需要关心它。
units.dic 是单字的单位,一般不用改动我们不需要关心它。
words.dic 是词库文件,一行一词,可以自己进行扩展词库。
6.测试mmseg4j分词效果。
近一百多年来,总有一些公司很幸运地、有意识或者无意识地站在技术革命的浪尖之上。一旦处在了那个位置,即使不做任何事,也可以随着波浪顺顺当当地向前漂个十年甚至更长的时间。在这十几年间,它们代表着科技的浪潮,直到下一波浪潮的来临。从一百年前算起,AT&T公司、IBM公司、苹果(Apple)公司 、英特尔(Intel) 公司、微软(Microsoft) 公司、和谷歌(Google)公司都先后被幸运地推到了浪尖。虽然,它们来自不同的领域,中间有些已经衰落或者正在衰落,但是它们都极度辉煌过。这些公司里的人,无论职位高低,在外人看来,都是时代的幸运儿。因为,虽然对一个公司来说,赶上一次浪潮不能保证其长盛不衰;但是,对一个人来说,一生赶上一次这样的浪潮就足够了。一个弄潮的年轻人,最幸运的,莫过于赶上一波大潮。

综上所述可以看出,三种分词方法存在着一些同样的错误,比如名词“英特尔“和”谷歌“都没有识别出来。综合比较Complex的分词方法准确率最高。
到这关于mmseg4j分词器就讲解完毕。
jcseg
Jcseg是基于mmseg算法的一个轻量级Java中文分词工具包,同时集成了关键字提取,关键短语提取,关键句子提取和文章自动摘要等功能,并且提供了一个基于Jetty的web服务器,方便各大语言直接http调用,同时提供了最新版本的lucene,solr和elasticsearch的搜索分词接口;
使用流程:
2.编译打包源码jcseg-core,jcseg-analyzer
3.安装: 将jcseg-analyze.jar和jcseg-core.jar复制到Solr/WEB-INF/lib目录
4.使用jcseg的分析器定义FieldType,Jcseg提供了很多模式;复杂模式最常用。
(1).简易模式:FMM算法,适合速度要求场合。
(2).复杂模式:MMSEG四种过滤算法,具有较高的歧义去除,分词准确率达到了98.41%。
(3).检测模式:只返回词库中已有的词条,很适合某些应用场合。
(4).最多模式:细粒度切分,专为检索而生,除了中文处理外(不具备中文的人名,数字识别等智能功能)其他与复杂模式一致(英文,组合词等)。
(5).分隔符模式:按照给定的字符切分词条,默认是空格,特定场合的应用。
(6).NLP模式:继承自复杂模式,更改了数字,单位等词条的组合方式,增加电子邮件,大陆手机号码,网址,人名,地名,货币等以及无限种自定义实体的识别与返回。
(7).n-gram模式:CJK和拉丁系字符的通用n-gram切分实现。
<!-- 复杂模式分词: -->
<fieldtype name="text_jcseg" class="solr.TextField">
<analyzer>
<tokenizer class="org.lionsoul.jcseg.analyzer.JcsegTokenizerFactory" mode="complex"/>
</analyzer>
</fieldtype>
<!-- 简易模式分词: -->
<fieldtype name="textSimple" class="solr.TextField">
<analyzer>
<tokenizer class="org.lionsoul.jcseg.analyzer.JcsegTokenizerFactory" mode="simple"/>
</analyzer>
</fieldtype>
<!-- 检测模式分词: -->
<fieldtype name="textDetect" class="solr.TextField">
<analyzer>
<tokenizer class="org.lionsoul.jcseg.analyzer.JcsegTokenizerFactory" mode="detect"/>
</analyzer>
</fieldtype>
<!-- 检索模式分词: -->
<fieldtype name="textSearch" class="solr.TextField">
<analyzer>
<tokenizer class="org.lionsoul.jcseg.analyzer.JcsegTokenizerFactory" mode="most"/>
</analyzer>
</fieldtype>
<!-- NLP模式分词: -->
<fieldtype name="textSearch" class="solr.TextField">
<analyzer>
<tokenizer class="org.lionsoul.jcseg.analyzer.JcsegTokenizerFactory" mode="nlp"/>
</analyzer>
</fieldtype>
<!-- 空格分隔符模式分词: -->
<fieldtype name="textSearch" class="solr.TextField">
<analyzer>
<tokenizer class="org.lionsoul.jcseg.analyzer.JcsegTokenizerFactory" mode="delimiter"/>
</analyzer>
</fieldtype>
<!-- n-gram模式分词: -->
<fieldtype name="textSearch" class="solr.TextField">
<analyzer>
<tokenizer class="org.lionsoul.jcseg.analyzer.JcsegTokenizerFactory" mode="ngram"/>
</analyzer>
</fieldtype>
6.扩展词库定义
jcseg也支持对词库进行扩展
将jcseg的配置文件从jc-core/jcseg.properties复制到solr/WEB-INF/classess目录
编辑jcseg.properties配置文件,指定lexicon.path即词库位置。
lexicon.path = D:/jcseg/lexicon
将jcseg\vendors\lexicon目录下的词库文件复制到 D:/jcseg/lexicon
jcseg对这些词库文件进行分类
修改词库文件lex-place.lex加入新词
传智播客/ns/chuan zhi bo ke/null
7.测试jcseg分词效果。
ICTCLAS(中科院分词器)
ICTCLAS分词器是中国科学院计算技术研究所在多年研究工作积累的基础上,研制出了汉语词法分析系统ICTCLAS(Institute of Computing Technology, Chinese Lexical Analysis System),基于完全C/C++编写,主要功能包括中文分词;词性标注;命名实体识别;新词识别;同时支持用户词典。先后精心打造五年,内核升级6次,目前已经升级到了ICTCLAS3.0。ICTCLAS3.0分词速度单机996KB/s,分词精度98.45%,API不超过200KB,各种词典数据压缩后不到3M,是当前世界上最好的汉语词法分析器,商业收费。
使用流程:
1.下载ICTCLAS的分析器nlpir-analysis-cn-ictclas和ictclas SDK和jna.jar(java调用c的包):
nlpir-analysis-cn-ictclas:GitHub - NLPIR-team/nlpir-analysis-cn-ictclas: Lucene/Solr Analyzer Plugin. Support MacOS,Linux x86/64,Windows x86/64. It's a maven project, which allows you change the lucene/solr version. //Maven工程,修改Lucene/Solr版本,以兼容相应版本。
ictclas SDK:GitHub - NLPIR-team/NLPIR
jna.jar:https://repo1.maven.org/maven2/net/java/dev/jna/jna/5.5.0/jna-5.5.0.jar
2.编译:打包nlpir-analysis-cn-ictclas源码生成lucene-analyzers-nlpir-ictclas-6.6.0.jar
3.安装:将lucene-analyzers-nlpir-ictclas-6.6.0.jar,jna.jar复制到solr/WEB-INF/lib目录
4.配置:在tomcat/bin目录下创建配置文件nlpir.properties,为什么要在tomcat/bin目录中创建配置文件呢?
我猜是他的代码中使用了相对路径。而不是读取classpath下面的文件;
data="D:/javasoft/NLPIR/NLPIR SDK/NLPIR-ICTCLAS" #Data directory‘s parent path,在ictclas SDK中;
encoding=1 #0 GBK;1 UTF-8
sLicenseCode="" # License code,此处也可以看出其收费
userDict="" # user dictionary, a text file
bOverwrite=false # whether overwrite the existed user dictionary or not
5.配置fieldType,指定对应的分析器
<fieldType name="text_ictclas" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.nlpir.lucene.cn.ictclas.NLPIRTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.nlpir.lucene.cn.ictclas.NLPIRTokenizerFactory"/>
</analyzer>
</fieldType>
6.测试text_ictclas分词效果。
HanLP
HanLP是由一系列模型与算法组成的java开源工具包,目标是普及自然语言处理在生产环境中的应用。HanLP具备功能完善、性能高效、架构清晰、语料时新、可自定义的特点;提供词法分析(中文分词、词性标注、命名实体识别)、句法分析、文本分类和情感分析等功能。
使用流程:
1.下载词典http://nlp.hankcs.com/download.php?file=data
2.下载hanlp的jar包和配置文件http://nlp.hankcs.com/download.php?file=jar
下载handlp整合lucene的jar包https://github.com/hankcs/hanlp-lucene-plugin
3.将词典文件压缩包data-for-1.7.zip解压到指定位置 eg:d:/javasoft下;
4.安装: 将hanlp.jar和hanlp-lucene-plugin.jar包复制到solr/WEB-INF/lib
5.配置:将配置文件hanlp.properties复制solr/WEB-INF/classes
6.配置:在hanlp.properties中指定词典数据的目录
7.配置停用词,扩展词等。
8.使用HanLP中提供的分析器配置FieldType
<fieldType name="text_hanlp" class="solr.TextField">
<analyzer type="index">
<tokenizer class="com.hankcs.lucene.HanLPTokenizerFactory" enableIndexMode="true"/>
</analyzer>
<analyzer type="query">
<!-- 切记不要在query中开启index模式 -->
<tokenizer class="com.hankcs.lucene.HanLPTokenizerFactory" enableIndexMode="false"/>
</analyzer>
</fieldType>
6.测试test_hanlp分词效果。
中文分词器建议
介绍了这么多的中文分词器,在实际开发中我们如何进行选择呢?
中文分词器核心就是算法和字典,算法决定了分词的效率,字典决定了分词的结果。词库不完善导致词语分不出来,虽然可以通过扩展词典进行补充,但是补充只能是发现问题再去补充,所以分词器自动发现新词的功能就很重要。
CRF(条件随机场)算法是目前最好的识别新词的分词算法。Ansj和HanLp都支持CRF,自动补充词库;
Ansj缺点是核心词典不能修改,只能借助扩展词典进行补充。
HanLp是目前功能最齐全,社区最活跃的分词器。
MMseg4J和Jcseg两者都采用MMseg算法。但是Jcseg更活跃。MMseg4J基本不再更新。
IK分词器是使用最多的一种分词器,虽然词典不支持自动扩展词汇,但是简单,所以使用率最高;
最后一个就是Ictclas他是功能最强大的一款分词器,但是是基于C/C++编写,而且要进行商业授权。比较适合对分词要求较高且不差钱的公司。
综上:
一般对于追求简单来说建议使用IK分词器;
对分词要求较高,但是希望免费,可以使用HanLp;
关于中文分词器的使用我们就全部讲解完毕。
自定义分词器(了解)
我们都知道分析器由分词器和过滤器构成。
要想使用分析器,首先要定义分词器。如果不需要对分词结果进行过滤,过滤器是可选的。
之前我们在使用分词器的时候,都是使用Solr自带的分词器,比如标准分词器。当然也使用到第三方的一些中文分词器,比如IK分词器。为了更好的理解分析器的java体系结构,下面讲解自定义分词器。
定义分词器的步骤:
继承Tokenizer或者CharTokenizer抽象类;Tokenizer字符串级别的分词器,适合复杂分词器。CharTokenizer字符级别的分词器,适合简单分词器;
定义过滤器的步骤:
继承TokenFiler或者FilteringTokenFilter
需求:
自定义分词器将"This+is+my+family"按照+作为分隔符分成"This" "is" "My" "family";
1.搭建环境
创建模块,引入solr-core依赖,最好和当前solr版本一致
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-core</artifactId>
<version>7.7.2</version>
</dependency>
2.定义一个类继承CharTokenizer(字符级别的分词器)
public class PlusSignTokenizer extends CharTokenizer {
public PlusSignTokenizer() {
}
public PlusSignTokenizer(AttributeFactory factory) {
super(factory);
}
//isTokenChar哪些字符是词;
public boolean isTokenChar(int i) {
//将什么字符作为分隔符进行分词
return i != '+';
}
}
3.定义分词器工厂管理分词器,定义类继承TokenizerFactory
public class PlusSignTokenizerFactory extends TokenizerFactory {
/**
* 在schem配置文件中配置分词器的时候,指定参数args配置分词器时候的指定的参数
* <analyzer>
* <tokenizer class="cn.itcast.tokenizer.PlausSignTokenizerFactory" mode="complex"/>
* </analyzer>
* @param args
*/
public PlusSignTokenizerFactory(Map<String, String> args) {
//分词器属性配置
super(args);
}
@Override
public Tokenizer create(AttributeFactory attributeFactory) {
return new PlusSignTokenizer(attributeFactory);
}
}
4.package打包代码,将jar包复制到solr/WEB-INF/lib
5.配置FieldType
<fieldType name="text_custom" class="solr.TextField">
<analyzer>
<tokenizer class="cn.itcast.tokenizer.PlausSignTokenizerFactory"/>
</analyzer>
</fieldType>
6.测试
关于如何自定义一个分词器,我们就先说到这,在实际开发中我们基本上不会自己定义,主要体会流程;
自定义过滤器(了解)
上一节课,我们学习了分词器的定义,下面我们讲解定义过滤器。
在Solr中要定义一个过滤器,需要继承TokenFiler或者FilteringTokenFilter
需求:过滤掉"love"词
我们可以参考一个solr内置过滤器LenthFilter;
public final class LengthFilter extends FilteringTokenFilter {
private final int min;
private final int max;
//获取当前词
private final CharTermAttribute termAtt = addAttribute(CharTermAttribute.class);
//构造方法接收三个参数,词的集合,词的最小长度和最大长度
public LengthFilter(TokenStream in, int min, int max) {
super(in);
if (min < 0) {
throw new IllegalArgumentException("minimum length must be greater than or equal to zero");
}
if (min > max) {
throw new IllegalArgumentException("maximum length must not be greater than minimum length");
}
this.min = min;
this.max = max;
}
//该方法返回true,保留该词否则不保留;
@Override
public boolean accept() {
final int len = termAtt.length();
return (len >= min && len <= max);
}
}
开发步骤:
1.定义一个类继承FilteringTokenFilter
2.定义成员变量,获取当前的词
private final CharTermAttribute termAtt = addAttribute(CharTermAttribute.class);
3.重写FilteringTokenFilter中accept() 方法决定保留哪些词。
public class LoveTokenFilter extends FilteringTokenFilter {
private String keyword;
//获取当前词
private final CharTermAttribute termAtt = addAttribute(CharTermAttribute.class);
public LoveTokenFilter(TokenStream in,String keyword) {
super(in);
this.keyword = keyword;
}
protected boolean accept() throws IOException {
String token = termAtt.toString();
if(token.equalsIgnoreCase(keyword)) {
return false;
}
return true;
}
}
4.定义类继承TokenFilterFactory
public class LoveTokenFilterFactory extends TokenFilterFactory {
private String keywords;
//调用父类无参构造
public LoveTokenFilterFactory(Map<String, String> args) throws IllegalAccessException {
super(args);
if(args== null) {
throw new IllegalAccessException("必须传递keywords参数");
}
this.keywords = this.get(args, "keywords");
}
public TokenStream create(TokenStream input) {
return new LoveTokenFilter(input,keywords);
}
}
5.配置FieldType
<fieldType name="text_custom" class="solr.TextField">
<analyzer>
<tokenizer class="cn.itcast.tokenizer.PlusSignTokenizerFactory"/>
<filter class="cn.itcast.tokenfilter.LoveTokenFilterFactory" keywords="love"/>
</analyzer>
</fieldType>
6.梳理工作流程:
7.打包安装重写测试
自定义分析器(了解)
在Solr中我们通常会使用<tokenizer> + <filter>的形式来组合分析器,这种方式耦合性低,使用起来灵活。
在Solr中也允许我们将一个分词器和一个过滤器直接封装到分析器类中;将来直接使用分析器。
流程:
1.定义类继承Analyzer类。
2.重写createComponents()方法;
3.将分词器和过滤器封装在createComponents()方法的返回值即可;
public class MyAnalyzer extends Analyzer {
@Override
public TokenStreamComponents createComponents(String fieldName) {
//自己的分词器
Tokenizer plusSignTokenizer = new PlusSignTokenizer();
//自带的过滤器
LowerCaseFilter lowerCaseFilter = new LowerCaseFilter(plusSignTokenizer);
return new TokenStreamComponents(plusSignTokenizer, lowerCaseFilter);
}
}
4.使用分析器声明FieldType
<fieldType name="text_custom2" class="solr.TextField">
<analyzer class="cn.itcast.analyzer.MyAnalyzer">
</analyzer>
</fieldType>
5.打包测试
3.2.9 Solr的数据导入(DataImport)
在Solr后台管理系统中提供了一个功能叫DataImport,作用就是将数据库中的数据导入到索引库,简称DHI;
DataImport如何将数据库中的数据导入到索引库呢?
1.查询数据库中的记录;
2.将数据库中的一条记录转化为Document,并进行索引;
需求:将以下表中数据导入到MySQL
sql脚本在资料中;

步骤:
0.准备:
创建MySQL数据库和表(略);
在schema文件中声明图书相关的业务域;
id:使用solr提供的id域;
book_name:使用text_ik类型,因为该域中包含中文,索引,并且存储;
book_price:使用pfloat类型,索引,并且存储;
book_pic:使用string类型,不索引,存储;
book_description:使用text_ik类型,索引,不存储;
book_num:使用pint类型,索引,并且存储;
<field name="book_name" type="text_ik" indexed="true" stored="true"/>
<field name="book_price" type="pfloat" indexed="true" stored="true"/>
<field name="book_pic" type="string" indexed="false" stored="true"/>
<field name="book_description" type="text_ik" indexed="true" stored="false"/>
<field name="book_num" type="pint" indexed="true" stored="true"/>
1.将MySQL的mysql驱动mysql-connector-5.1.16-bin.jar复制到solr\WEB-INF\lib中。
2.查看SolrCore中的配置文件solrconfig.xml,solrconfig.xml文件主要配置了solrcore自身相关的一些参数(后面我们再给大家讲解)。作用:指定DataImport将MySQL数据导入Solr的配置文件为solr-data-config.xml;
<requestHandler name="/dataimport" class="solr.DataImportHandler">
<lst name="defaults">
<str name="config">solr-data-config.xml</str>
</lst>
</requestHandler>
3.编辑SolrCore/conf中solr-data-config.xml文件
<dataConfig>
<!-- 首先配置数据源指定数据库的连接信息 -->
<dataSource type="JdbcDataSource"
driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/lucene"
user="root"
password="root"/>
<document>
<!-- entity作用:数据库中字段和域名如何映射
name:标识,任意
query:执行的查询语句
-->
<entity name="book" query="select * from book">
<!-- 每一个field映射着数据库中列与文档中的域,column是数据库列,name是solr的域(必须是在managed-schema文件中配置过的域才行) -->
<field column="id" name="id"/>
<field column="name" name="book_name"/>
<field column="price" name="book_price"/>
<field column="pic" name="book_pic"/>
<field column="description" name="book_description"/>
<field column="num" name="book_num"/>
</entity>
</document>
</dataConfig>
4.使用DataImport导入。
到这关于DataImport我们就讲解完毕。
3.2.10 solrconfig.xml
上一节在使用DataImport的时候,使用到了一个配置文件solrconfig.xml,这个配置文件是solr中常用的4个配置文件之一。但是相对schema文件,用的很少。
solrconfig.xml作用:主要配置SolrCore相关的一些信息。Lucene的版本,第三方依赖包加载路径,索引和搜索相关的配置;JMX配置,缓存配置等;
1.Lucene的版本配置;一般和Solr版本一致;
<luceneMatchVersion>7.7.2</luceneMatchVersion>
2.第三方依赖包加载路径
<lib dir="${solr.install.dir:../../../..}/contrib/extraction/lib" regex=".*\.jar" />
告诉solr,第三方依赖包的位置。一般我们并不会在lib中进行设置,因为lib中的设置,只能该solrCore使用。
其他SolrCore无法使用,一般第三方的依赖包,我们直接会放在Solr/WEB-INF/lib下。所有的solrCore共享。
solr.install.dir:SolrCore所在目录,当前配置文件属于哪个SolrCore,solr.install.dir就是那个SolrCore目录‘
<dataDir>${solr.data.dir:}</dataDir>
索引数据所在目录:默认位置SolrCore/data
3.用来配置创建索引的类
<directoryFactory name="DirectoryFactory"
class="${solr.directoryFactory:solr.NRTCachingDirectoryFactory}"/>
- 用来设置Lucene倒排索引的编码工厂类,默认实现是官方提供的SchemaCodecFactory类。;
<codecFactory class="solr.SchemaCodecFactory"/>
5.索引相关配置
6.搜索相关配置
3.2.11 Query
接下来我们讲解后台管理系统中Query功能,Query的主要作用是查询;
接下来我们来讲解一下基本使用
q:表示主查询条件,必须有.
fq:过滤条件。
start,rows:指定分页;
fl:指定查询结果文档中需要的域;
wt:查询结果的格式,JSON/XML;
演示:
查询book_description中包含java;
查询book_description中包含java并且book_name中包含lucene;
对查询的结果按照价格升序,降序。
分页查询满足条件的第一页2条数据,第二页2条数据
start=(页码-1) * 每页条数
将查询结果中id域去掉;
查询的结果以JSON形式返回;
到这关于Solr管理后台Query的基本使用我们就暂时讲解到这里;
3.2.13 SolrCore其它菜单
overview(概览)
作用:包含基本统计如当前文档数,最大文档数;删除文档数,当前SolrCore配置目录;
files
作用:对SolrCore/conf目录下文件预览
Ping:拼接Solr的连通性;
Plugins:Solr使用的一些插件;
Replication:集群状态查看,后面搭建完毕集群再来说;
Schema:管理Schema文件中的Field,可以查看和添加域,动态域和复制域;
SegmentsInfo:展示底层Lucence索引段,包括每个段的大小和数据条数。Solr底层是基于lucene实现的,索引数据最终是存储到SolrCore/data/index目录的索引文件中;这些索引文件有_e开始的, _0开始的....对应的就是不同的索引段。

4. Solr查询
4.1 Solr查询概述(理解)
我们先从整体上对solr查询进行认识。当用户发起一个查询的请求,这个请求会被Solr中的Request Handler所接受并处理,Request Handler是Solr中定义好的组件,专门用来处理用户查询的请求。
Request Handler相关的配置在solrconfig.xml中;
下面就是一个请求处理器的配置
name:uri;
class:请求处理器处理请求的类;
lst:参数设置,eg:rows每页显示的条数。wt:结果的格式
<requestHandler name="/select" class="solr.SearchHandler">
<lst name="defaults">
<str name="echoParams">explicit</str>
<int name="rows">10</int>
<str name="df">text</str>
<!-- Change from JSON to XML format (the default prior to Solr 7.0)
<str name="wt">xml</str>
-->
</lst>
</requestHandler>
<requestHandler name="/query" class="solr.SearchHandler">
<lst name="defaults">
<str name="echoParams">explicit</str>
<str name="wt">json</str>
<str name="indent">true</str>
<str name="df">text</str>
</lst>
</requestHandler>
这是Solr底层处理查询的组件,RequestHandler,简单认识一下;
宏观认识Solr查询的流程;
当用户输入查询的字符串eg:book_name:java,选择查询处理器/select.点击搜索;
请求首先会到达RequestHandler。RequestHandler会将查询的字符串交由QueryParser进行解析。
Index会从索引库中搜索出相关的结果。
ResponseWriter将最终结果响应给用户;
通过这幅图大家需要明确的是,查询的本质就是基于Http协议和Solr服务进行请求和响应的一个过程。
4.2 相关度排序
上一节我们了解完毕Solr的查询流程,接下来我们来讲解相关度排序。什么叫相关度排序呢?
比如查询book_description中包含java的文档。
查询结果;
疑问:为什么id为40的文档再最前面?这里面就牵扯到Lucene的相关度排序;
相关度排序是查询结果按照与查询关键字的相关性进行排序,越相关的越靠前。比如搜索“java”关键字,与该关键字最相关的文档应该排在前边。
影响相关度排序2个要素
Term Frequency (tf):
指此Term在此文档中出现了多少次。tf越大说明越重要。词(Term)在文档中出现的次数越多,说明此词(Term)对该文档越重要,如“java”这个词,在文档中出现的次数很多,说明该文档主要就是讲java技术的。
Document Frequency (df):
指有多少文档包含此Term。df越大说明越不重要。比如,在一篇英语文档中,this出现的次数更多,就说明越重要吗?不是的,有越多的文档包含此词(Term),说明此词(Term)太普通,不足以区分这些文档,因而重要性越低。
相关度评分
Solr底层会根据一定的算法,对文档进行一个打分。打分比较高的排名靠前,打分比较低的排名靠后。
设置boost(权重)值影响相关度打分;
举例:查询book_name或者book_description域中包含java的文档;
book_name中包含java或者book_description域中包含java的文档都会被查询出来。假如我们认为book_name中包含java应该排名靠前。可以给book_name域增加权重值。book_name域中有java的文档就可以靠前。
4.3 查询解析器(QueryParser)
之前我们在讲解查询流程的时候,我们说用户输入的查询内容,需要被查询解析器解析。所以查询解析器QueryParser作用就是对查询的内容进行解析。
solr提供了多种查询解析器,为我们使用者提供了极大的灵活性及控制如何解析器查询内容。
Solr提供的查询解析器包含以下:
Standard Query Parser:标准查询解析器;
DisMax Query Parser:DisMax 查询解析器;
Extends DisMax Query Parser:扩展DisMax 查询解析器
Others Query Parser:其他查询解析器
当然Solr也运行用户自定义查询解析器。需要继承QParserPlugin类;
默认解析器:lucene
solr默认使用的解析器是lucene,即Standard Query Parser。Standard Query Parser支持lucene原生的查询语法,并且进行增强,使你可以方便地构造结构化查询语句。当然,它还有不好的,就是容错比较差,总是把错误抛出来,而不是像dismax一样消化掉。
查询解析器: disMax
只支持lucene查询语法的一个很小的子集:简单的短语查询、+ - 修饰符、AND OR 布尔操作;
可以灵活设置各个查询字段的相关性权重,可以灵活增加满足某特定查询文档的相关性权重。
查询解析器:edisMax
扩展 DisMax Query Parse 使支标准查询语法(是 Standard Query Parser 和 DisMax Query Parser 的复合)。也增加了不少参数来改进disMax。支持的语法很丰富;很好的容错能力;灵活的加权评分设置。
对于不同的解析器来说,支持的查询语法和查询参数,也是不同的。我们不可能把所有解析器的查询语法和参数讲完。实际开发也用不上。我们重点讲解的是Standard Query Parser支持的语法和参数。
4.4 查询语法
之前我们查询功能都是通过后台管理界面完成查询的。实际上,底层就是向Solr请求处理器发送了一个查询的请求,传递了查询的参数,下面我们要讲解的就是查询语法和参数。
| 地址信息 | 说明 |
|---|---|
| http://localhost:8080/solr/collection1/select?q=book_name:java | 查询请求url |
| http://localhost:8080/solr | solr服务地址 |
| collection1 | solrCore |
| /select | 请求处理器 |
| ?q=xxx | 查询的参数 |
4.4.1基本查询参数
| 参数名 | 描述 |
|---|---|
| q | 查询条件,必填项 |
| fq | 过滤查询 |
| start | 结果集第一条记录的偏移量,用于分页,默认值0 |
| rows | 返回文档的记录数,用于分页,默认值10 |
| sort | 排序,格式:sort=`+<asc |
| fl | 指定返回的域名,多个域名用逗号或者空格分隔,默认返回所有域 |
| wt | 指定响应的格式,例如xml、json等; |
演示:
查询所有文档:
http://localhost:8080/solr/collection1/select?q=*:*
查询book_name域中包含java的文档
http://localhost:8080/solr/collection1/select?q=book_name:java
查询book_description域中包含java,book_name中包含java。
http://localhost:8080/solr/collection1/select?q=book_description:java&fq=book_name:java
查询第一页的2个文档
查询第一页的2个文档
http://localhost:8080/solr/collection1/select?q=*:*&start=0&rows=2
http://localhost:8080/solr/collection1/select?q=*:*&start=2&rows=2
查询所有文档并且按照book_num升序,降序
http://localhost:8080/solr/collection1/select?q=*:*&sort=book_num+asc
http://localhost:8080/solr/collection1/select?q=*:*&sort=book_num+desc
查询所有文档并且按照book_num降序,如果数量一样按照价格升序。
http://localhost:8080/solr/collection1/select?q=*:*&sort=book_num+desc,book_price+asc
查询所有数据文档,将id域排除
http://localhost:8080/solr/collection1/select?q=*:*&fl=book_name,book_price,book_num,
book_pic
对于基础查询来说还有其他的一些系统级别的参数,但是一般用的较少。简单说2个。
| 描述 | 参数名称 |
|---|---|
| 选择哪个查询解析器对q中的参数进行解析,默认lucene,还可以使用dismax|edismax | defType |
| 覆盖schema.xml的defaultOperator(有空格时用"AND"还是用"OR"操作逻辑).默认为OR。 | q.op |
| 默认查询字段 | df |
| (query type)指定那个类型来处理查询请求,一般不用指定,默认是standard | qt |
| 查询结果是否进行缩进,开启,一般调试json,php,phps,ruby输出才有必要用这个参数 | indent |
| 查询语法的版本,建议不使用它,由服务器指定默认值 | version |
defType:更改Solr的查询解析器的。一旦查询解析器发生改变,支持其他的查询参数和语法。
q.op:如果我们搜索的关键字可以分出很多的词,到底是基于这些词进行与的关系还是或关系。
q=book_name:java编程 搜索book_name中包含java编程关键字
java编程---->java 编程。
搜索的条件时候是book_name中不仅行包含java而且包含编程,还是只要有一个即可。
q=book_name&q.op=AND
q=book_name&q.op=OR
df:指定默认搜索的域,一旦我们指定了默认搜索的域,在搜索的时候,我们可以省略域名,仅仅指定搜索的关键字
就可以在默认域中搜索
q=java&df=book_name
4.4.2 组合查询
上一节我们讲解了基础查询,接下来我们讲解组合查询。在Solr中提供了运算符,通过运算符我们就可以进行组合查询。
| 运算符 | 说明 |
|---|---|
| ? | 通配符,替代任意单个字符(不能在检索的项开始使用*或者?符号) |
| * | 通配符,替代任意多个字符(不能在检索的项开始使用*或者?符号) |
| ~ | 表示相似度查询,如查询类似于"roam"的词,我们可以这样写:roam将找到形如foam和roams的单词;roam0.8,检索返回相似度在0.8以上的文档。 邻近检索,如检索相隔10个单词的"apache"和"jakarta","jakarta apache"~10 |
| AND | 表示且,等同于 “&&” |
| OR | 表示或,等同于 “||” |
| NOT | 表示否 |
| () | 用于构成子查询 |
| [] | 范围查询,包含头尾 |
| {} | 范围查询,不包含头尾 |
| + | 存在运算符,表示文档中必须存在 “+” 号后的项 |
| - | 不存在运算符,表示文档中不包含 “-” 号后的项 |
实例:
[?]查询book_name中包含c?的词。
http://localhost:8080/solr/collection1/select?q=book_name:c?
[*]查询book_name总含spring*的词
http://localhost:8080/solr/collection1/select?q=book_name:spring*
[~]模糊查询book_name中包含和java及和java比较像的词,相似度0.75以上
http://localhost:8080/solr/collection1/select?q=book_name:java~0.75
java和jave相似度就是0.75.4个字符中3个相同。

[AND]查询book_name域中既包含servlet又包含jsp的文档;
方式1:使用and
q=book_name:servlet AND book_name:jsp
q=book_name:servlet && book_name:jsp
方式2:使用+
q=+book_name:servlet +book_name:jsp
[OR]查询book_name域中既包含servlet或者包含jsp的文档;
q=book_name:servlet OR book_name:jsp
q=book_name:servlet || book_name:jsp
[NOT]查询book_name域中包含spring,并且id不是4的文档
book_name:spring AND NOT id:4
+book_name:spring -id:4
[范围查询]
查询商品数量>=4并且<=10
http://localhost:8080/solr/collection1/select?q=book_num:[4 TO 10]
查询商品数量>4并且<10
http://localhost:8080/solr/collection1/select?q=book_num:{4 TO 10}
查询商品数量大于125
http://localhost:8080/solr/collection1/select?q=book_num:{125 TO *]
4.4.3 q和fq的区别
在讲解基础查询的时候我们使用了q和fq,这2个参数从使用上比较的类似,很多使用者可能认为他们的功能相同,下面我们来阐述他们两者的区别;
从使用上:q必须传递参数,fq可选的参数。在执行查询的时候,必须有q,而fq可以有,也可以没有;
从功能上:q有2项功能
第一项:根据用户输入的查询条件,查询符合条件的文档。
第二项:使用相关性算法,匹配到的文档进行相关度排序。
fq只有一项功能
对匹配到的文档进行过滤,不会影响相关度排序,效率高;
演示:
需求:查询book_descrption中包含java并且book_name中包含java文档;
单独使用q来完成;
由于book_name条件的加入造成排序结果的改变;说明q查询符合条件的文档,也可以进行相关度排序;
使用q + fq完成
说明fq:仅仅只会进行条件过滤,不会影响相关度排序;
4.4.4 Solr返回结果和排序
返回结果的格式
在Solr中默认支持多种返回结果的格式。分别是XML,JSON,Ruby,Python,Binary Java,PHP,CVS等。下面是Solr支持的响应结果格式以及对应的实现类。
对于使用者来说,我们只需要指定wt参数即可;
查询所有数据文档返回xml
http://localhost:8080/solr/collection1/select?q=*:*&wt=xml
返回结果文档包含的域
通过fl指定返回的文档包含哪些域。
返回伪域。
将返回结果中价格转化为分。product是Solr中的一个函数,表示乘法。后面我们会讲解。
http://localhost:8080/solr/collection1/select?q=*:*&fl=*,product(book_price,100)

域指定别名
上面的查询我们多了一个伪域。可以为伪域起别名fen
http://localhost:8080/solr/collection1/select?q=*:*&fl=*,fen:product(book_price,100)

同理也可以给原有域起别名
http://localhost:8080/solr/collection1/select?q=*:*&fl=name:book_name,price:book_price

这是返回结果,接下来我们再来说一下排序;
在Solr中我们是通过sort参数进行排序。
http://localhost:8080/solr/collection1/select?q=*:*&sort=book_price+asc&wt=json&rows=50
特殊情况:某些文档book_price域值为null,null值排在最前面还是最后面。
定义域类型的时候需要指定2个属性sortMissingLast,sortMissingFirst
sortMissingLast=true,无论升序还是降序,null值都排在最后
sortMissingFirst=true,无论升序还是降序,null值都排在最前
<fieldtype name="fieldName" class="xx" sortMissingLast="true" sortMissingFirst="false"/>
4.5 高级查询-facet查询
4.5.1简单介绍
facet 是 solr 的高级搜索功能之一 , 可以给用户提供更友好的搜索体验 。
作用:可以根据用户搜索条件 ,按照指定域进行分组并统计,类似于关系型数据库中的group by分组查询;
eg:查询title中包含手机的商品,按照品牌进行分组,并且统计数量。
select brand,COUNT(*)from tb_item where title like '%手机%' group by brand
适合场景:在电商网站的搜索页面中,我们根据不同的关键字搜索。对应的品牌列表会跟着变化。
这个功能就可以基于Facet来实现;

Facet比较适合的域
一般代表了实体的某种公共属性的域 , 如商品的品牌,商品的分类 , 商品的制造厂家 , 书籍的出版商等等;
Facet域的要求
Facet 的域必须被索引 . 一般来说该域无需分词,无需存储 ,无需分词是因为该域的值代表了一个整体概念 , 如商品的品牌 ” 联想 ” 代表了一个整体概念 , 如果拆成 ” 联 ”,” 想 ” 两个字都不具有实际意义 . 另外该字段的值无需进行大小写转换等处理 , 保持其原貌即可 .无需存储是因为查询到的文档中不需要该域的数据 , 而是作为对查询结果进行分组的一种手段 , 用户一般会沿着这个分组进一步深入搜索 .
4.5.2 数据准备
为了更好的学习我们后面的知识,我们将商品表数据导入到Solr索引库;
删除图书相关的数据
<delete>
<query>*:*</query>
</delete>
<commit/>
创建和商品相关的域
<field name="item_title" type="text_ik" indexed="true" stored="true"/> 标题域
<field name="item_price" type="pfloat" indexed="true" stored="true"/> 价格域
<field name="item_images" type="string" indexed="false" stored="true"/> 图片域
<field name="item_createtime" type="pdate" indexed="true" stored="true"/> 创建时间域
<field name="item_updatetime" type="pdate" indexed="true" stored="true"/> 更新时间域
<field name="item_category" type="string" indexed="true" stored="true"/> 商品分类域
<field name="item_brand" type="string" indexed="true" stored="true"/> 品牌域
修改solrcore/conf目录中solr-data-config.xml配置文件,使用DataImport进行导入;
<entity name="item" query="select id,title,price,image,create_time,update_time,category,brand from tb_item">
<field column="id" name="id"/>
<field column="title" name="item_title"/>
<field column="price" name="item_price"/>
<field column="image" name="item_images"/>
<field column="create_time" name="item_createtime"/>
<field column="update_time" name="item_updatetime"/>
<field column="category" name="item_category"/>
<field column="brand" name="item_brand"/>
</entity>
重启服务,使用DateImport导入;
测试
4.5.3 Facet查询的分类
facet_queries:表示根据条件进行分组统计查询。
facet_fields:代表根据域分组统计查询。
facet_ranges:可以根据时间区间和数字区间进行分组统计查询;
facet_intervals:可以根据时间区间和数字区间进行分组统计查询;
4.5.4 facet_fields
需求:对item_title中包含手机的文档,按照品牌域进行分组,并且统计数量;
1.进行 Facet 查询需要在请求参数中加入 ”facet=on” 或者 ”facet=true” 只有这样 Facet 组件才起作用
2.分组的字段通过在请求中加入 ”facet.field” 参数加以声明
http://localhost:8080/solr/collection1/select?q=item_title:手机&facet=on&facet.field=item_brand
分组结果
3.如果需要对多个字段进行 Facet查询 , 那么将该参数声明多次;各个分组结果互不影响eg:还想对分类进行分组统计.
http://localhost:8080/solr/collection1/select?q=item_title:手机&facet=on&facet.field=item_brand&facet.field=item_category
分组结果
4.其他参数的使用。
在facet中,还提供的其他的一些参数,可以对分组统计的结果进行优化处理;
| 参数 | 说明 |
|---|---|
| facet.prefix | 表示 Facet 域值的前缀 . 比如 ”facet.field=item_brand&facet.prefix=中国”, 那么对 item_brand字段进行 Facet 查询 , 只会分组统计以中国为前缀的品牌。 |
| facet.sort | 表示 Facet 字段值以哪种顺序返回 . 可接受的值为 true|false. true表示按照 count 值从大到小排列 . false表示按照域值的自然顺序( 字母 , 数字的顺序 ) 排列 . 默认情况下为 true. |
| facet.limit | 限制 Facet 域值返回的结果条数 . 默认值为 100. 如果此值为负数 , 表示不限制 . |
| facet.offset | 返回结果集的偏移量 , 默认为 0. 它与 facet.limit 配合使用可以达到分页的效果 |
| facet.mincount | 限制了 Facet 最小 count, 默认为 0. 合理设置该参数可以将用户的关注点集中在少数比较热门的领域 . |
| facet.missing | 默认为 ””, 如果设置为 true 或者 on, 那么将统计那些该 Facet 字段值为 null 的记录. |
| facet.method | 取值为 enum 或 fc, 默认为 fc. 该参数表示了两种 Facet 的算法 , 与执行效率相关 .enum 适用于域值种类较少的情况 , 比如域类型为布尔型 .fc适合于域值种类较多的情况。 |
[facet.prefix] 分组统计以中国前缀的品牌
&facet=on
&facet.field=item_brand
&facet.prefix=中国

[facet.sort] 按照品牌值进行字典排序
&facet=on
&facet.field=item_brand
&facet.sort=false

[facet.limit] 限制分组统计的条数为10
&facet=on
&facet.field=item_brand
&facet.limit=10

[facet.offset]结合facet.limit对分组结果进行分页
&facet=on
&facet.field=item_brand
&facet.offset=5
&facet.limit=5

[facet.mincount] 搜索标题中有手机的商品,并且对品牌进行分组统计查询,排除统计数量为0的品牌
q=item_title:手机
&facet=on
&facet.field=item_brand
&facet.mincount=1

4.5.5 facet_ranges
除了字段分组查询外,还有日期区间,数字区间分组查询。作用:将某一个时间区间(数字区间),按照指定大小分割,统计数量;
需求:分组查询2015年,每一个月添加的商品数量;
参数:
| 参数 | 说明 |
|---|---|
| facet.range | 该参数表示需要进行分组的字段名 , 与 facet.field 一样 , 该参数可以被设置多次 , 表示对多个字段进行分组。 |
| facet.range.start | 起始时间/数字 , 时间的一般格式为 ” 1995-12-31T23:59:59Z”, 另外可以使用 ”NOW”,”YEAR”,”MONTH” 等等 , 具体格式可以参考 org.apache.solr.schema. DateField 的 java doc. |
| facet.range.end | 结束时间 数字 |
| facet.range.gap | 时间间隔 . 如果 start 为 2019-1-1,end 为 2020-1-1.gap 设置为 ”+1MONTH” 表示间隔1 个月 , 那么将会把这段时间划分为 12 个间隔段 . 注意 ”+” 因为是特殊字符所以应该用 ”%2B” 代替 . |
| facet.range.hardend | 取值可以为 true|false它表示 gap 迭代到 end 处采用何种处理 . 举例说明 start 为 2019-1-1,end 为 2019-12-25,gap 为 ”+1MONTH”,hardend 为 false 的话最后一个时间段为 2009-12-1 至 2010-1-1;hardend 为 true 的话最后一个时间段为 2009-12-1 至 2009-12-25 举例start为0,end为1200,gap为500,hardend为false,最后一个数字区间[1000,1200] ,hardend为true最后一个数字区间[1000,1500] |
| facet.range.other | 取值范围为 before|after|between|none|all, 默认为 none. before 会对 start 之前的值做统计 . after 会对 end 之后的值做统计 . between 会对 start 至 end 之间所有值做统计 . 如果 hardend 为 true 的话 , 那么该值就是各个时间段统计值的和 . none 表示该项禁用 . all 表示 before,after,between都会统计 . |
facet=on&
facet.range=item_createtime&
facet.range.start=2015-01-01T00:00:00Z&
facet.range.end=2016-01-01T00:00:00Z&
facet.range.gap=%2B1MONTH
&facet.range.other=all
结果
需求:分组统计价格在01000,10002000,2000~3000... 19000~20000及20000以上每个价格区间商品数量;
facet=on&
facet.range=item_price&
facet.range.start=0&
facet.range.end=20000&
facet.range.gap=1000&
facet.range.hardend=true&
facet.range.other=all
结果:
4.5.6 facet_queries
在facet中还提供了第三种分组查询的方式facet query。提供了类似 filter query (fq)的语法可以更为灵活的对任意字段进行分组统计查询 .
需求:查询分类是平板电视的商品数量 品牌是华为的商品数量 品牌是三星的商品数量;
facet=on&
facet.query=item_category:平板电视&
facet.query=item_brand:华为&
facet.query=item_brand:三星
测试结果
我们会发现统计的结果中对应名称tem_category:平板电视和item_brand:华为,我们也可以起别名;
facet=on&
facet.query={!key=平板电视}item_category:平板电视&
facet.query={!key=华为品牌}item_brand:华为&
facet.query={!key=三星品牌}item_brand:三星
{---->%7B }---->%7D
这样可以让字段名统一起来,方便我们拿到请求数据后,封装成自己的对象;
facet=on&
facet.query=%7B!key=平板电视%7Ditem_category:平板电视&
facet.query=%7B!key=华为品牌%7Ditem_brand:华为&
facet.query=%7B!key=三星品牌%7Ditem_brand:三星

4.5.7 facet_interval
在Facet中还提供了一种分组查询方式facet_interval。功能类似于facet_ranges。facet_interval通过设置一个区间及域名,可以统计可变区间对应的文档数量;
通过facet_ranges和facet_interval都可以实现范围查询功能,但是底层实现不同,性能也不同.
参数:
| 参数名 | 说明 |
|---|---|
| facet.interval | 此参数指定统计查询的域。它可以在同一请求中多次使用以指示多个字段。 |
| facet.interval.set | 指定区间。如果统计的域有多个,可以通过f.<fieldname>.facet.interval.set语法指定不同域的区间。区间语法 区间必须以'(' 或 '[' 开头,然后是逗号(','),最终值,最后是 ')' 或']'。 例如: (1,10) - 将包含大于1且小于10的值 [1,10])- 将包含大于或等于1且小于10的值 [1,10] - 将包含大于等于1且小于等于10的值 |
需求:统计item_price在[0-10]及[1000-2000]的商品数量和item_createtime在2019年~现在添加的商品数量
&facet=on
&facet.interval=item_price
&f.item_price.facet.interval.set=[0,10]
&f.item_price.facet.interval.set=[1000,2000]
&facet.interval=item_createtime
&f.item_createtime.facet.interval.set=[2019-01-01T0:0:0Z,NOW]
由于有特殊符号需要进行URL编码[---->%5B ]---->%5D
http://localhost:8080/solr/collection1/select?q=*:*&facet=on
&facet.interval=item_price
&f.item_price.facet.interval.set=%5B0,10%5D
&f.item_price.facet.interval.set=%5B1000,2000%5D
&facet.interval=item_createtime
&f.item_createtime.facet.interval.set=%5B2019-01-01T0:0:0Z,NOW%5D
结果
4.5.8 facet中其他的用法
tag操作符和ex操作符
首先我们来看一下使用场景,当查询使用q或者fq指定查询条件的时候,查询条件的域刚好是facet的域;
分组的结果就会被限制,其他的分组数据就没有意义。
q=item_title:手机
&fq=item_brand:三星
&facet=on
&facet.field=item_brand导致分组结果中只有三星品牌有数量,其他品牌都没有数量

如果想查看其他品牌手机的数量。给过滤条件定义标记,在分组统计的时候,忽略过滤条件;
查询文档是2个条件,分组统计只有一个条件
&q=item_title:手机
&fq={!tag=brandTag}item_brand:三星
&facet=on
&facet.field={!ex=brandTag}item_brand
{---->%7B }---->%7D
&q=item_title:手机
&fq=%7B!tag=brandTag%7Ditem_brand:三星
&facet=on
&facet.field=%7B!ex=brandTag%7Ditem_brand
测试结果:
4.5.9 facet.pivot
多维度分组查询。听起来比较抽象。
举例:统计每一个品牌和其不同分类商品对应的数量;
| 品牌 | 分类 | 数量 |
|---|---|---|
| 华为 | 手机 | 200 |
| 华为 | 电脑 | 300 |
| 三星 | 手机 | 200 |
| 三星 | 电脑 | 20 |
| 三星 | 平板电视 | 200 |
| 。。。 | 。。。 |
这种需求就可以使用维度查询完成。
&facet=on
&facet.pivot=item_brand,item_category
测试结果
4.6 高级查询-group查询
4.6.1 group介绍和入门
solr group作用:将具有相同字段值的文档分组,并返回每个组的顶部文档。 Group和Facet的概念很像,都是用来分组,但是分组的结果是不同;
group查询相关参数
| 参数 | 类型 | 说明 |
|---|---|---|
| group | 布尔值 | 设为true,表示结果需要分组 |
| group.field | 字符串 | 需要分组的字段,字段类型需要是StrField或TextField |
| group.func | 查询语句 | 可以指定查询函数 |
| group.query | 查询语句 | 可以指定查询语句 |
| rows | 整数 | 返回多少组结果,默认10 |
| start | 整数 | 指定结果开始位置/偏移量 |
| group.limit | 整数 | 每组返回多数条结果,默认1 |
| group.offset | 整数 | 指定每组结果开始位置/偏移量 |
| sort | 排序算法 | 控制各个组的返回顺序 |
| group.sort | 排序算法 | 控制每一分组内部的顺序 |
| group.format | grouped/simple | 设置为simple可以使得结果以单一列表形式返回 |
| group.main | 布尔值 | 设为true时,结果将主要由第一个字段的分组命令决定 |
| group.ngroups | 布尔值 | 设为true时,Solr将返回分组数量,默认fasle |
| group.truncate | 布尔值 | 设为true时,facet数量将基于group分组中匹相关性高的文档,默认fasle |
| group.cache.percent | 整数0-100 | 设为大于0时,表示缓存结果,默认为0。该项对于布尔查询,通配符查询,模糊查询有改善,却会减慢普通词查询。 |
需求:查询Item_title中包含手机的文档,按照品牌对文档进行分组;
q=item_title:手机
&group=true
&group.field=item_brand
group分组结果和Fact分组查询的结果完全不同,他把同组的文档放在一起,显示该组文档数量,仅仅展示了第一个文档。

4.6.2 group参数-分页参数
上一节我们讲解了group的入门,接下来我们对group中的参数进行详解。
首先我们先来观察一下入门的分组结果。只返回10个组结果。
[rows]通过rows参数设置返回组的个数。
q=item_title:手机&group=true&group.field=item_brand&rows=13
比上面分组结果多了三个组

通过start和rows参数结合使用可以对分组结果分页;查询第一页3个分组结果
q=item_title:手机&group=true&group.field=item_brand&start=0&rows=3

除了可以对分组结果进行分页,可以对组内文档进行分页。默认情况下。只展示该组顶部文档。
需求:展示每组前5个文档。
q=item_title:手机&group=true&group.field=item_brand&start=0&rows=3
&group.limit=5&group.offset=0

4.6.3 group参数-排序参数
排序参数分为分组排序和组内文档排序;
[sort]分组进行排序
需求:按照品牌名称进行字典排序
q=item_title:手机&group=true&group.field=item_brand&start=0&rows=5
&group.limit=5&group.offset=0
&sort=item_brand asc
[group.sort]组内文档进行排序
需求:组内文档按照价格降序;
q=item_title:手机&group=true&group.field=item_brand&start=0&rows=5
&group.limit=5&group.offset=0
&group.sort=item_price+desc
4.6.4 group查询结果分组
在group中除了支持根据Field进行分组,还支持查询条件分组。
需求:对item_brand是华为,三星,TCL的三个品牌,分组展示对应的文档信息。
q=item_title:手机
&group=true
&group.query=item_brand:华为
&group.query=item_brand:三星
&group.query=item_brand:TCL

4.6.5 group 函数分组(了解)
在group查询中除了支持Field分组,Query分组。还支持函数分组。
按照价格范围对商品进行分组。01000属于第1组,10002000属于第二组,否则属于第3组。
q=*:*&
group=true&
group.func=map(item_price,0,1000,1,map(item_price,1000,2000,2,3))
map(x,10,100,1,2) 在函数参数中的x如果落在[10,100)之间,则将x的值映射为1,否则将其值映射为2

4.6.7 group其他参数
group.ngroups:是否统计组数量
q=item_title:手机
&group=true
&group.field=item_brand
&group.ngroups=true
group.cache.percent
Solr Group查询相比Solr的标准查询来说,速度相对要慢很多。
可以通过group.cache.percent参数来开启group查询缓存。该参数默认值为0.可以设置为0-100之间的数字
该值设置的越大,越占用系统内存。对于布尔类型等分组查询。效果比较明显。
group.main
获取每一个分组中相关度最高的文档即顶层文档,构成一个文档列表。
q=item_title:手机
&group.field=item_brand
&group=true
&group.main=true
group.truncate(了解)
按照品牌分组展示相关的商品;
q=*:*&group=true&group.field=item_brand
在次基础上使用facet,按照分类分组统计;统计的结果,基于q中的条件进行的facet分组。
q=*:*&group=true&group.field=item_brand
&facet=true
&facet.field=item_category
如果我们想基于每个分组中匹配度高的文档进行Facet分组统计
q=*:*&group=true&group.field=item_brand
&facet=true
&facet.field=item_category
&group.truncate=true
4.7 高级查询-高亮查询
4.7.1 高亮的概述
高亮显示是指根据关键字搜索文档的时候,显示的页面对关键字给定了特殊样式, 让它显示更加突出,如下面商品搜索中,关键字变成了红色,其实就是给定了红色样 ;
高亮的本质,是对域中包含关键字前后加标签
4.7.2 Solr高亮分类和高亮基本使用
上一节我们简单阐述了什么是高亮,接下来我们来讲解Solr中高亮的实现方案;
在Solr中提供了常用的3种高亮的组件(Highlighter)也称为高亮器,来支持高亮查询。
Unified Highlighter
Unified Highlighter是最新的Highlighter(从Solr6.4开始),它是最性能最突出和最精确的选择。它可以通过插件/扩展来处理特定的需求和其他需求。官方建议使用该Highlighter,即使它不是默认值。
Original Highlighter
Original Highlighter,有时被称为"Standard Highlighter" or "Default Highlighter",是Solr最初的Highlighter,提供了一些定制选项,曾经一度被选择。它的查询精度足以满足大多数需求,尽管它不如统一的Highlighter完美;
FastVector Highlighter
FastVector Highlighter特别支持多色高亮显示,一个域中不同的词采用不同的html标签作为前后缀。
接下来我们来说一下Highlighter公共的一些参数,先来认识一下其中重要的一些参数;
| 参数 | 值 | 描述 |
|---|---|---|
| hl | true|false | 通过此参数值用来开启或者禁用高亮.默认值是false.如果你想使用高亮,必须设置成true |
| hl.method | unified|original|fastVector | 使用哪种哪种高亮组件. 接收的值有: unified, original, fastVector. 默认值是 original. |
| hl.fl | filed1,filed2... | 指定高亮字段列表.多个字段之间以逗号或空格分开.表示那个字段要参与高亮。默认值为空字符串。 |
| hl.q | item_title:三星 | 高亮查询条件,此参数运行高亮的查询条件和q中的查询条件不同。如果你设置了它, 你需要设置 hl.qparser.默认值和q中的查询条件一致 |
| hl.tag.pre | <em> | 高亮词开头添加的标签,可以是任意字符串,一般设置为HTML标签,默认值为.对于Original Highlighter需要指定hl.simple.pre |
| hl.tag.post | </em> | 高亮词后面添加的标签,可以是任意字符串,一般设置为HTML标签,默认值</em>.对于Original Highlighter需要指定hl.simple.post |
| hl.qparser | lucene|dismax|edismax | 用于hl.q查询的查询解析器。仅当hl.q设置时适用。默认值是defType参数的值,而defType参数又默认为lucene。 |
| hl.requireFieldMatch | true|false | 默认为fasle. 如果置为true,除非该字段的查询结果不为空才会被高亮。它的默认值是false,意味 着它可能匹配某个字段却高亮一个不同的字段。如果hl.fl使用了通配符,那么就要启用该参数 |
| hl.usePhraseHighlighter | true|false | 默认true.如果一个查询中含有短语(引号框起来的)那么会保证一定要完全匹配短语的才会被高亮 |
| hl.highlightMultiTerm | true|false | 默认true.如果设置为true,solr将会高亮出现在多terms查询中的短语。 |
| hl.snippets | 数值 | 默认为1.指定每个字段生成的高亮字段的最大数量. |
| hl.fragsize | 数值 | 每个snippet返回的最大字符数。默认是100.如果为0,那么该字段不会被fragmented且整个字段的值会被返回 |
| hl.encoder | html | 如果为空(默认值),则存储的文本将返回,而不使用highlighter执行任何转义/编码。如果设置为html,则将对特殊的html/XML字符进行编码; |
| hl.maxAnalyzedChars | 数值 | 默认10000. 搜索高亮的最大字符,对一个大字段使用一个复杂的正则表达式是非常昂贵的。 |
高亮的入门案例:
查询item_title中包含手机的文档,并且对item_title中的手机关键字进行高亮;
q=item_title:手机
&hl=true
&hl.fl=item_title
&hl.simple.pre=<font>
&hl.simple.post=</font>

关于高亮最基本的用法先介绍到这里。
4.7.3 Solr高亮中其他的参数介绍
[hl.fl]指定高亮的域,表示哪些域要参于高亮;
需求:查询Item_title:手机的文档, Item_title,item_category为高亮域
q=item_title:手机
&hl=true
&hl.fl=item_title,item_category
&hl.simple.pre=<font>
&hl.simple.post=</font>
结果中item_title手机产生了高亮,item_category中手机也产生了高亮.
这种高亮肯对我们来说是不合理的。可以使用hl.requireFieldMatch参数解决。
[hl.requireFieldMatch]只有符合对应查询条件的域中参数才进行高亮;只有item_title手机才会高亮。
q=item_title:手机
&hl=true
&hl.fl=item_title,item_category
&hl.simple.pre=<font>
&hl.simple.post=</font>
&hl.requireFieldMatch=true

[hl.q] 默认情况下高亮是基于q中的条件参数。 使用fl.q让高亮的条件参数和q的条件参数不一致。比较少见。但是solr提供了这种功能。
需求:查询Item_tile中包含三星的文档,对item_category为手机的进行高亮;
q=item_title:三星
&hl=true
&hl.q=item_category:手机
&hl.fl=item_category
&hl.simple.pre=<em>
&hl.simple.post=</em>

[hl.highlightMultiTerm]默认为true,如果为true,Solr将对通配符查询进行高亮。如果为false,则根本不会高亮显示它们。
q=item_title:micro* OR item_title:panda
&hl=true
&hl.fl=item_title
&hl.simple.pre=<em>
&hl.simple.post=</em>

对应基于通配符查询的结果不进行高亮;
q=item_title:micro* OR item_title:panda
&hl=true
&hl.fl=item_title
&hl.simple.pre=<em>
&hl.simple.post=</em>
&hl.highlightMultiTerm=false
[hl.usePhraseHighlighter]为true时,将来我们基于短语进行搜索的时候,短语做为一个整体被高亮。为false时,短语中的每个单词都会被单独高亮。在Solr中短语需要用引号引起来;
q=item_title:"老人手机"
&hl=true
&hl.fl=item_title
&hl.simple.pre=<font>
&hl.simple.post=</font>
当不带双引号时q=item_title:老人手机,会先将老人手机先分词,然后在进行索引查询,如果加上双引号q=item_title:"老人手机",会老人手机以整体在solr库中进行索引查询,不会分词以后进行查询
关闭hl.usePhraseHighlighter=false;
q=item_title:"老人手机"
&hl=true
&hl.fl=item_title
&hl.simple.pre=<font>
&hl.simple.post=</font>
&hl.usePhraseHighlighter=false;

4.7.4 Highlighter的切换
之前我们已经讲解完毕Highlighter中的通用参数,所有Highlighter都有的。接下来我们要讲解的是Highlighter的切换和特有参数。
如何切换到unified (hl.method=unified),切换完毕后,其实我们是看不出他和original有什么区别。因为unified Highlighter比original Highlighter只是性能提高。精确度提高。
区别不是很大,unified 相比original 的粒度更细;
q=item_title:三星平板电视
&hl=true
&hl.fl=item_title
&hl.simple.pre=<font>
&hl.simple.post=</font>
&hl.method=unified

如何切换到fastVector
优势:使用fastVector最大的好处,就是可以为域中不同的词使用不同的颜色,第一个词使用黄色,第二个使用红色。而且fastVector和orignal可以混合使用,不同的域使用不同的Highlighter;
使用fastVector的要求:使用FastVector Highlighter需要在高亮域上设置三个属性(termVectors、termPositions和termOffset);
需求:查询item_title中包含三星平板电视,item_category是平板电视的文档。
item_title中的高亮词要显示不同的颜色。
<field name="item_title" type="text_ik" indexed="true" stored="true" termVectors="true" termPositions="true" termOffsets="true" />
重启Solr,重写生成索引;
<delete>
<query>*:*</query>
</delete>
<commit/>
修改solrcofig.xml配置文件指定fastVector高亮器的前后缀
官方给的一个例子
<fragmentsBuilder name="colored"
class="solr.highlight.ScoreOrderFragmentsBuilder">
<lst name="defaults">
<str name="hl.tag.pre"><![CDATA[
<b style="background:yellow">,<b style="background:lawgreen">,
<b style="background:aquamarine">,<b style="background:magenta">,
<b style="background:palegreen">,<b style="background:coral">,
<b style="background:wheat">,<b style="background:khaki">,
<b style="background:lime">,<b style="background:deepskyblue">]]></str>
<str name="hl.tag.post"><![CDATA[</b>]]></str>
</lst>
</fragmentsBuilder>
需要请求处理器中配置使用colored这一套fastVector的前后缀;
<str name="hl.fragmentsBuilder">colored</str>
q=item_title:三星平板电视 AND item_category:平板电视
&hl=true
&hl.fl=item_title,item_category
&hl.method=original
&f.item_title.hl.method=fastVector
测试
到这关于Highlighter的切换我们就讲解完毕了。不同的Highlighter也有自己特有的参数,这些参数大多是性能参数。大家可以参考官方文档。http://lucene.apache.org/solr/guide/8_1/highlighting.html#the-fastvector-highlighter
4.8 Solr Query Suggest
4.8.1 Solr Query Suggest简介
Solr从1.4开始便提供了Query Suggest,Query Suggest目前是各大搜索应用的标配,主要作用是避免用户输入错误的搜索词,同时将用户引导到相应的关键词上进行搜索。Solr内置了Query Suggest的功能,它在Solr里叫做Suggest模块. 使用该模块.我们通常可以实现2种功能。拼写检查(Spell-Checking),再一个就是自动建议(AutoSuggest)。
什么是拼写检查(Spell-Checking)
比如说用户搜索的是sorl,搜索应用可能会提示你,你是不是想搜索solr.百度就有这个功能。
这就是拼写检查(Spell Checking)的功能。
什么又是自动建议(AutoSuggest)
AutoSuggest是指用户在搜索的时候,给用户一些提示建议,可以帮助用户快速构建自己的查询。
比如我们搜索java.
关于Query Suggest的简介,我们先暂时说道这里。
4.8.2 Spell-Checking的使用
要想使用Spell-Checking首先要做的事情,就是在SolrConfig.xml文件中配置SpellCheckComponent;并且要指定拼接检查器,Solr一共提供了4种拼写检查器IndexBasedSpellChecker,DirectSolrSpellChecker,FileBasedSpellChecker和WordBreakSolrSpellChecker。这4种拼写检查的组件,我们通常使用的都是第二种。
IndexBasedSpellChecker(了解)
IndexBasedSpellChecker 使用 Solr 索引作为拼写检查的基础。它要求定义一个域作为拼接检查term的基础域。
需求:对item_title域,item_brand域,item_category域进行拼接检查。
-
定义一个域作为拼接检查term 的基础域item_title_spell,将item_title,item_brand,item_category域复制到item_title_spell;
<field name="item_title_spell" type="text_ik" indexed="true" stored="false" multiValued="true"/> <copyField source="item_title" dest="item_title_spell"/> <copyField source="item_brand" dest="item_title_spell"/> <copyField source="item_category" dest="item_title_spell"/>2.在SolrConfig.xml中配置IndexBasedSpellChecker作为拼写检查的组件
<searchComponent name="indexspellcheck" class="solr.SpellCheckComponent">
<lst name="spellchecker">
<str name="classname">solr.IndexBasedSpellChecker</str> <!--组件的实现类-->
<str name="spellcheckIndexDir">./spellchecker</str> <!--拼写检查索引生成目录-->
<str name="field">item_title_spell</str> <!--拼写检查的域-->
<str name="buildOnCommit">true</str><!--是否每次提交文档的时候,都生成拼写检查的索引-->
<!-- optional elements with defaults
<str name="distanceMeasure">org.apache.lucene.search.spell.LevensteinDistance</str>
<str name="accuracy">0.5</str>
-->
</lst>
</searchComponent>
3.在请求处理器中配置拼写检查的组件;
<arr name="last-components">
<str>indexspellcheck</str>
</arr>
q=item_title:meta
&spellcheck=true

DirectSolrSpellChecker
需求:基于item_title域,item_brand域,item_category域进行搜索的时候,需要进行拼接检查。
使用流程:
首先要定义一个词典域,拼写检查是需要根据错误词--->正确的词,正确的词构成的域;
1.由于我们在进行拼写检查的时候,可能会有中文,所以需要首先创建一个词典域的域类型。
<!-- 说明 这里spell 单独定义一个类型 是为了屏蔽搜索分词对中文拼写检测的影响,分词后查询结果过多不会给出建议词 -->
<fieldType name="spell_text_ik" class="solr.TextField">
<analyzer type="index" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
</analyzer>
</fieldType>
2.定义一个词典的域,将需要进行拼写检查的域复制到该域;
<field name="spell" type="spell_text_ik" multiValued="true" indexed="true" stored="false"/>
<copyField source="item_title" dest="spell"/>
<copyField source="item_brand" dest="spell"/>
<copyField source="item_category" dest="spell"/>
3.修改SolrConfig.xml中的配置文件中的拼写检查器组件。指定拼写词典域的类型,词典域

4.在Request Handler中配置拼写检查组件
<arr name="last-components">
<str>spellcheck</str>
</arr>
5.重启,重新创建索引。
测试,spellcheck=true参数表示是否开启拼写检查,搜索内容一定大于等于4个字符。
http://localhost:8080/solr/collection1/select?q=item_title:iphono&spellcheck=true
http://localhost:8080/solr/collection1/select?q=item_title:galax&spellcheck=true
http://localhost:8080/solr/collection1/select?q=item_brand:中国移走&spellcheck=true

到这关于DirectSolrSpellChecker我们就讲解完毕了。
FileBasedSpellChecker
使用外部文件作为拼写检查字的词典,基于词典中的词进行拼写检查。
1.在solrconfig.xml中配置拼写检查的组件。
<searchComponent name="fileChecker" class="solr.SpellCheckComponent">
<lst name="spellchecker">
<str name="classname">solr.FileBasedSpellChecker</str>
<str name="name">fileChecker</str>
<str name="sourceLocation">spellings.txt</str>
<str name="characterEncoding">UTF-8</str>
<!-- optional elements with defaults-->
<str name="distanceMeasure">org.apache.lucene.search.spell.LevensteinDistance</str>
<!--精确度,介于0和1之间的值。值越大,匹配的结果数越少。假设对 helle进行拼写检查,
如果此值设置够小的话," hellcat","hello"都会被认为是"helle"的正确的拼写。如果此值设置够大,则"hello"会被认为是正确的拼写 -->
<str name="accuracy">0.5</str>
<!--表示最多有几个字母变动。比如:对"manag"进行拼写检查,则会找到"manager"做为正确的拼写检查;如果对"mana"进行拼写检查,因为"mana"到"manager",需有3个字母的变动,所以"manager"会被遗弃 -->
<int name="maxEdits">2</int>
<!-- 最小的前辍数。如设置为1,意思是指第一个字母不能错。比如:输入"cinner",虽然和"dinner"只有一个字母的编辑距离,但是变动的是第一个字母,所以"dinner"不是"cinner"的正确拼写 -->
<int name="minPrefix">1</int>
<!-- 进行拼写检查所需要的最小的字符数。此处设置为4,表示如果只输入了3个以下字符,则不会进行拼写检查(3个以下的字符用户基本) -->
<int name="minQueryLength">4</int>
<!-- 被推荐的词在文档中出现的最小频率。整数表示在文档中出现的次数,百分比数表示有百分之多少的文档出现了该推荐词-->
<float name="maxQueryFrequency">0.01</float>
</lst>
</searchComponent>
2.在SolrCore/conf目录下,创建一个拼写检查词典文件,该文件已经存在。

3.加入拼写检查的词;
pizza
history
传智播客
4.在请求处理器中配置拼写检查组件
<arr name="last-components">
<str>fileChecker</str>
</arr>
http://localhost:8080/solr/collection1/select?q=item_title:pizzaaa&spellcheck=true&spellcheck.dictionary=fileChecker&spellcheck.build=true
补充:spellcheck.dictionary参数值对应下面参数的name的值,如果name的值为default,spellcheck.dictionary参数可以不写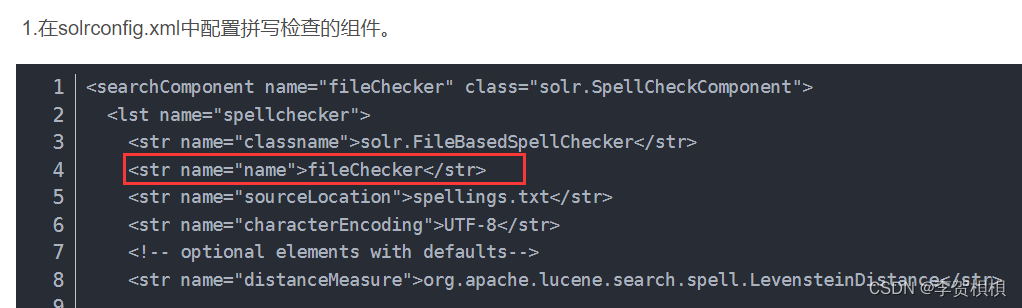

WordBreakSolrSpellChecker
WordBreakSolrSpellChecker可以通过组合相邻的查询词/或将查询词分解成多个词来提供建议。是对SpellCheckComponent增强,通常WordBreakSolrSpellChecker拼写检查器可以配合一个传统的检查器(即:DirectSolrSpellChecker)。
<lst name="spellchecker">
<str name="name">wordbreak</str>
<str name="classname">solr.WordBreakSolrSpellChecker</str>
<str name="field">sepll</str>
<str name="combineWords">true</str>
<str name="breakWords">true</str>
<int name="maxChanges">10</int>
</lst>
http://localhost:8080/solr/collection1/select?
q=item_title:ip hone&spellcheck=true
&spellcheck.dictionary=default&spellcheck.dictionary=wordbreak
4.8.3 拼写检查相关的参数
| 参数 | 值 | 描述 |
|---|---|---|
| spellcheck | true|false | 此参数为请求打开拼写检查建议。如果true,则会生成拼写建议。如果需要拼写检查,则这是必需的。 |
| spellcheck.build | true|false | 如果设置为true,则此参数将创建用于拼写检查的字典。在典型的搜索应用程序中,您需要在使用拼写检查之前构建字典。但是,并不总是需要先建立一个字典。例如,您可以将拼写检查器配置为使用已存在的字典。 |
| spellcheck.count | 数值 | 此参数指定拼写检查器应为某个术语返回的最大建议数。如果未设置此参数,则该值默认为1。如果参数已设置但未分配一个数字,则该值默认为5。如果参数设置为正整数,则该数字将成为拼写检查程序返回的建议的最大数量。 |
| spellcheck.dictionary | 指定要使用的拼写检查器 | 默认值defualt |
其他参数参考http://lucene.apache.org/solr/guide/8_1/spell-checking.html
4.8.4 AutoSuggest 入门
AutoSuggest 是搜索应用一个方便的功能,对用户输入的关键字进行预测和建议,减少了用户的输入。首先我们先来讲解一下suggest的入门流程;
1.在solrconfig.xml中配置suggsetComponent,并且要在组件中配置自动建议器,配置文件已经配置过。
<searchComponent name="suggest" class="solr.SuggestComponent">
<lst name="suggester">
<str name="name">mySuggester</str> 自动建议器名称,需要在查询的时候指定
<str name="lookupImpl">FuzzyLookupFactory</str> 查找器工厂类,确定如何从字典索引中查找词
<str name="dictionaryImpl">DocumentDictionaryFactory</str>决定如何将词存入到索引。
<str name="field">item_title</str> 词典域。一般指定查询的域/或者复制域。
<str name="weightField">item_price</str> 根据哪个域进行查询结果文档的排序
<str name="suggestAnalyzerFieldType">text_ik</str> 自动建议分析器的域类型,自动建议的参数中可能包括中文,所以选用ik
</lst>
</searchComponent>
2.修改组件参数
3.在请求处理器中配置suggest组件,sugges名称要和SearchComponent的name一致。
<arr name="components">
<str>suggest</str>
</arr>
补充:在solrConfig.xml中已经定义了一个请求处理器,并且已经配置了查询建议组件
<requestHandler name="/suggest" class="solr.SearchHandler" startup="lazy">
<lst name="defaults">
<str name="suggest">true</str>
<str name="suggest.count">10</str>
</lst>
<arr name="components">
<str>suggest</str>
</arr>
</requestHandler>
4.执行查询,指定suggest参数
http://localhost:8080/solr/collection1/suggest?q=三星
http://localhost:8080/solr/collection1/select?q=三星&suggest=true&suggest.dictionary=mySuggester
5.结果

4.8.5 AutoSuggest中相关的参数。
<searchComponent name="suggest" class="solr.SuggestComponent">
<lst name="suggester">
<str name="name">mySuggester</str> 自动建议器名称,需要在查询的时候指定
<str name="field">item_title</str> 表示自动建议的内容是基于哪个域的
<str name="dictionaryImpl">DocumentDictionaryFactory</str>词典实现类,表示分词(Term)是如何存储Suggestion字典的。 DocumentDictionaryFactory一个基于词,权重,创建词典;
<str name="lookupImpl">FuzzyLookupFactory</str> 查询实现类,表示如何在Suggestion词典中找到分词(Term)
<str name="weightField">item_price</str> 权重域。
<str name="suggestAnalyzerFieldType">text_ik</str> 域类型
<str name="buildOnCommit">true</str>
</lst>
</searchComponent>
4.8.6 AutoSuggest查询相关参数
http://localhost:8080/solr/collection1/select?q=三星&suggest=true&suggest.dictionary=mySuggester
| 参数 | 值 | 描述 |
|---|---|---|
| suggest | true|false | 是否开启suggest |
| suggest.dictionary | 字符串 | 指定使用的suggest器名称 |
| suggest.count | 数值 | 默认值是1 |
| suggest.build | true|false | 如果设置为true,这个请求会导致重建suggest索引。这个字段一般用于初始化的操作中,在线上环境,一般不会每个请求都重建索引,如果线上你希望保持字典最新,最好使用buildOnCommit或者buildOnOptimize来操作。 |
4.8.7 其他lookupImpl,dictionaryImpl.
其他的实现大家可以参考。
http://lucene.apache.org/solr/guide/8_1/suggester.html
5.SolrJ
5.1 SolrJ的引入
使用java如何操作Solr;
第一种方式Rest API

使用Rest API的好处,我们只需要通过Http协议连接到Solr,即可完成全文检索的功能。
在java中可以发送Http请求的工具包比较多。
Apache:HttpClient
Square: OKHttpClient
JDK : URLConnection
Spring: 以上的API提供的发送Http请求的方式都是不同,所以Spring提供了一个模板RestTemplate,可以对以上Http请求工具类进行封装从而统一API。
演示:
通过RestTemplate发送http请求,请求Solr服务完成查询item_title:手机的文档。并且需要完成结果封装。
开发步骤:
1.创建服务,引入spring-boot-stater-web的依赖(包含了RestTemplate)
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.10.RELEASE</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
</dependencies>
2.编写启动类和yml配置文件
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
3.将RestTemplate交由spring管理
@Bean
public RestTemplate restTemplate() {
return new RestTemplate(); //底层封装URLConnection
}
4. 使用RestTemplate,向Solr发送请求,获取结果并进行解析。
@Test
public void test01() {
//定义请求的url
String url = "http://localhost:8080/solr/collection1/select?q=item_title:手机";
//发送请求,指定响应结果类型,由于响应的结果是JSON,指定Pojo/Map
ResponseEntity<Map> resp = restTemplate.getForEntity(url, Map.class);
//获取响应体结果
Map<String,Object> body = resp.getBody();
//获取Map中--->response
Map<String,Object> response = (Map<String, Object>) body.get("response");
//获取总记录数
System.out.println(response.get("numFound"));
//获取起始下标
System.out.println(response.get("start"));
//获取文档
List<Map<String,Object>> docs = (List<Map<String, Object>>) response.get("docs");
for (Map<String, Object> doc : docs) {
System.out.println(doc.get("id"));
System.out.println(doc.get("item_title"));
System.out.println(doc.get("item_price"));
System.out.println(doc.get("item_image"));
System.out.println("=====================");
}
}
到这使用Solr RestAPI的方式我们就讲解完毕了。
5.2 SolrJ 介绍
Solr官方就推出了一套专门操作Solr的java API,叫SolrJ。
使用SolrJ操作Solr会比利用RestTemplate来操作Solr要简单。SolrJ底层还是通过使用httpClient中的方法来完成Solr的操作.
SolrJ核心的API
SolrClient
HttpSolrClient:适合于单节点的情况下和Solr进行交互。
CloudSolrClient:适合于集群的情况下和Solr进行交互。
由于当前我们Solr未搭建集群,所以我们使用HttpSolrClient即可。要想使用SolrJ,需要在项目中引入SorlJ的依赖,建议Solr的版本一致.
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-solrj</artifactId>
<version>7.7.2</version>
</dependency>
将HttpSolrClient交由spring管理。
1.在yml配置文件中配置Solr服务· `
url: http://localhost:8080/solr/collection1
2.在启动类中配置HttpSolrClient
@Value("${url}")
private String url;
@Bean
public HttpSolrClient httpSolrClient() {
HttpSolrClient.Builder builder = new HttpSolrClient.Builder(url);
return builder.build();
}
准备工作到此就准备完毕。
5.3 HttpSolrClient
5.3.1 索引
5.3.1.1添加
需求:添加一个图书文档。
添加有很多重载方法,SolrJ中支持添加一个文档,也支持一次添加文档集合。
@Test
public void testAddDocument() throws IOException, SolrServerException {
//创建文档
SolrInputDocument document = new SolrInputDocument();
//指定文档中的域
document.setField("id", "889922");
document.setField("item_title","华为 Meta30 高清手机");
document.setField("item_price", 20);
document.setField("item_images", "21312312.jpg");
document.setField("item_createtime", new Date());
document.setField("item_updatetime", new Date());
document.setField("item_category", "手机");
document.setField("item_brand","华为");
//添加文档
httpSolrClient.add(document);
httpSolrClient.commit();
}
5.3.1.2 修改
如果文档id相同就是修改;
@Test
public void testUpdateDocument() throws IOException, SolrServerException {
//创建文档
SolrInputDocument document = new SolrInputDocument();
//指定文档中的域
document.setField("id", "889922");
document.setField("item_title","SolrJ是Solr提供的操作Solr的javaAPI,挺好用");
document.setField("item_price", 20);
document.setField("item_images", "21312312.jpg");
document.setField("item_createtime", new Date());
document.setField("item_updatetime", new Date());
document.setField("item_category", "手机");
document.setField("item_brand","华为");
//添加文档
httpSolrClient.add(document);
httpSolrClient.commit();
}
5.3.1.3 删除
支持基于id删除,支持基于条件删除。
基于id删除
@Test
public void testDeleteDocument() throws IOException, SolrServerException {
httpSolrClient.deleteById("889922");
httpSolrClient.commit();
}
支持基于条件删除,删除所有数据要慎重
@Test
public void testDeleteQuery() throws IOException, SolrServerException {
httpSolrClient.deleteByQuery("book_name:java"); //*:*删除所有
httpSolrClient.commit();
}
到这关于使用SolrJ完成索引相关的操讲解完毕。下面讲解查询。
5.3.2 基本查询
5.3.2.1 主查询+过滤查询
查询的操作分为很多种下面我们讲解基本查询。
核心的API方法:
solrClient.query(SolrParams);
SolrParams是一个抽象类,通常使用其子类SolrQuery封装查询条件;
查询item_title中包含手机的商品
@Test
public void testBaseQuery() throws IOException, SolrServerException {
SolrQuery solrQuery=new SolrQuery();
//封装查询条件
//solrQuery.set("q","item_title:手机");
//solrQuery.setQuery与solrQuery.set("q","item_title:手机")等价
solrQuery.setQuery("item_title:手机");
QueryResponse response = httpSolrClient.query(solrQuery);
//获取满足条件文档
SolrDocumentList solrDocumentList = response.getResults();
solrDocumentList.stream().forEach(System.out::println);
//获取满足条件文档数量
System.out.println(solrDocumentList.getNumFound());
}
这是关于我们这一块核心API,接下来我们在这个基础上。我们做一些其他操作。添加过滤条件:品牌是华为。
价格在[1000-2000].
注意:过滤条件可以添加多个,所以使用的是SolrQuery的add方法。如果使用set后面过滤条件会将前面的覆盖.
@Test
public void testBaseQuery() throws IOException, SolrServerException {
SolrQuery solrQuery=new SolrQuery();
//封装查询条件
//solrQuery.set("q","item_title:手机");
//solrQuery.setQuery与olrQuery.set("q","item_title:手机")等价
solrQuery.setQuery("item_title:手机");
solrQuery.setFilterQueries("item_brand:华为");
solrQuery.setFilterQueries("item_price:[1000 TO 2000]");
QueryResponse response = httpSolrClient.query(solrQuery);
//获取满足条件文档
SolrDocumentList solrDocumentList = response.getResults();
solrDocumentList.stream().forEach(System.out::println);
//获取满足条件文档数量
System.out.println(solrDocumentList.getNumFound());
}
5.3.2.1 分页
接下来我们要完成的是分页,需求:在以上查询的条件查询,查询第1页的20条数据。
solrQuery.setStart((1-1)*20);
solrQuery.setRows(20);
5.3.2.1 排序
除了分页外,还有排序。需求:按照价格升序。如果价格相同,按照id降序。
solrQuery.addSort("item_price", SolrQuery.ORDER.desc);
solrQuery.addSort("id",SolrQuery.ORDER.asc);
5.3.2.2 域名起别名
到这基本查询就基本讲解完毕。有时候我们需要对查询结果文档的字段起别名。
需求:将域名中的item_去掉。
//指定查询结果的字段列表,并且指定别名
solrQuery.setFields("id,price:item_price,title:item_title,brand:item_brand,category:item_category,image:item_image");
别名指定完毕后,便于我们后期进行封装;到这关于基本查询讲解完毕,下面讲解组合查询。
5.3.3 组合查询
需求:查询Item_title中包含手机或者平板电视的文档。
solrQuery.setQuery("q","item_title:手机 OR item_title:平板电视");
需求:查询Item_title中包含手机 并且包含三星的文档
solrQuery.setQuery("item_title:手机 AND item_title:三星");
solrQuery.setQuery("+item_title:手机 +item_title:三星");
需求: 查询item_title中包含手机但是不包含三星的文档
solrQuery.setQuery("item_title:手机 NOT item_title:三星");
solrQuery.setQuery("+item_title:手机 -item_title:三星");
需求:查询item_title中包含iphone开头的词的文档,使用通配符
solrQuery.setQuery("item_title:iphone*");
到这关于SolrJ中组合查询我们就讲解完毕了。
1.1 facet查询
之前我们讲解Facet查询,我们说他是分为4类。
Field,Query,Range(时间范围,数字范围),Interval(和Range类似)
1.1.2 基于Field的Facet查询
需求:对item_title中包含手机的文档,按照品牌域进行分组,并且统计数量;
http://localhost:8080/solr/collection1/select?q=item_title:手机&facet=on&facet.field=item_brand&facet.mincount=1
@Test
public void testFacetFieldQuery() throws IOException, SolrServerException {
//http://localhost:8080/solr/collection1/select?q=item_title:手机&facet=on&facet.field=item_brand&facet.mincount=1
SolrQuery query=new SolrQuery();
//查询条件
query.setQuery("item_title:手机");
//Facet相关参数
query.setFacet(true);
query.addFacetField("item_brand");
query.setFacetMinCount(1);
QueryResponse response = httpSolrClient.query(query);
FacetField facetField = response.getFacetField("item_brand");
List<FacetField.Count> valueList = facetField.getValues();
valueList.stream().forEach(System.out::println);
}
1.1.3 基于Query的Facet查询
需求:查询分类是平板电视的商品数量 ,品牌是华为的商品数量 ,品牌是三星的商品数量,价格在1000-2000的商品数量;
http://localhost:8080/solr/collection1/select?
q=*:*&
facet=on&
facet.query=item_category:平板电视&
facet.query=item_brand:华为&
facet.query=item_brand:三星&
facet.query=item_price:%5B1000 TO 2000%5D
@Test
public void testFacetFieldQuery()throws IOException, SolrServerException {
//http://localhost:8080/solr/collection1/select?
//q=*:*&
//facet=on&
//facet.query=item_category:平板电视&
//facet.query=item_brand:华为&
//facet.query=item_brand:三星&
//facet.query=item_price:%5B1000 TO 2000%5D
SolrQuery query=new SolrQuery();
//查询条件
query.setQuery("*:*");
//Facet相关参数
query.setFacet(true);
//query.addFacetQuery("item_category:平板电视");
//query.addFacetQuery("item_brand:华为");
//query.addFacetQuery("item_brand:三星");
//query.addFacetQuery("item_price:[1000 TO 2000]");
//起别名
query.addFacetQuery("{!key=平板电视}item_category:平板电视");
query.addFacetQuery("{!key=华为品牌}item_brand:华为");
query.addFacetQuery("{!key=三星品牌}item_brand:三星");
query.addFacetQuery("{!key=1000到2000}item_price:[1000 TO 2000]");
QueryResponse response = httpSolrClient.query(query);
Map<String, Integer> facetQuery = response.getFacetQuery();
for (String key : facetQuery.keySet()) {
System.out.println(key+"--"+facetQuery.get(key));
}
}
1.1.4 基于Range的Facet查询
需求:分组查询价格0-2000 ,2000-4000,4000-6000....18000-20000每个区间商品数量
q=*:*&
facet=on&
facet.range=item_price&
facet.range.start=0&
facet.range.end=20000&
facet.range.gap=2000
@Test
public void testFacetFieldQuery()throws IOException, SolrServerException {
//http://localhost:8080/solr/collection1/select?
//q=*:*&
//facet=on&
//facet.range=item_price&
//facet.range.start=0&
//facet.range.end=20000&
//facet.range.gap=2000
SolrQuery query=new SolrQuery();
//查询条件
query.setQuery("*:*");
//Facet相关参数
query.setFacet(true);
query.addNumericRangeFacet("item_price",0,20000,2000);
QueryResponse response = httpSolrClient.query(query);
List<RangeFacet> facetRanges = response.getFacetRanges();
for (RangeFacet facetRange : facetRanges) {
System.out.println(facetRange.getName());
List<RangeFacet.Count> counts = facetRange.getCounts();
for (RangeFacet.Count count : counts) {
System.out.println(count.getValue()+"---"+count.getCount());
}
}
}
需求:统计2015年每个季度添加的商品数量
http://localhost:8080/solr/collection1/select?
q=*:*&
facet=on&
facet.range=item_createtime&
facet.range.start=2015-01-01T00:00:00Z&
facet.range.end=2016-01-01T00:00:00Z&
facet.range.gap=%2B3MONTH
@Test
public void testFacetFieldQuery() throws IOException, SolrServerException, ParseException {
//http://localhost:8080/solr/collection1/select?
//q=*:*&
//facet=on&
//facet.range=item_createtime&
//facet.range.start=2015-01-01T00:00:00Z&
//facet.range.end=2016-01-01T00:00:00Z&
//facet.range.gap=%2B3MONTH
SolrQuery query=new SolrQuery();
//查询条件
query.setQuery("*:*");
//Facet相关参数
query.setFacet(true);
Date start = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse("2015-01-01 00:00:00");
Date end = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse("2016-01-01 00:00:00");
query.addDateRangeFacet("item_createtime",start,end,"+3MONTH");
QueryResponse response = httpSolrClient.query(query);
List<RangeFacet> facetRanges = response.getFacetRanges();
for (RangeFacet facetRange : facetRanges) {
System.out.println(facetRange.getName());
List<RangeFacet.Count> counts = facetRange.getCounts();
for (RangeFacet.Count count : counts) {
System.out.println(count.getValue()+"---"+count.getCount());
}
}
}
1.1.5 基于Interval的Facet查询
需求:统计item_price在0-1000和0-100商品数量和item_createtime是2019年~现在添加的商品数量
&facet=on
&facet.interval=item_price
&f.item_price.facet.interval.set=[0,1000]
&f.item_price.facet.interval.set=[0,100]
&facet.interval=item_createtime
&f.item_createtime.facet.interval.set=[2019-01-01T0:0:0Z,NOW]
由于有特殊符号需要进行URL编码[---->%5B ]---->%5D
http://localhost:8080/solr/collection1/select?q=*:*&facet=on&facet.interval=item_price&f.item_price.facet.interval.set=%5B0,1000%5D&f.item_price.facet.interval.set=%5B0,100%5D&facet.interval=item_createtime&f.item_createtime.facet.interval.set=%5B2019-01-01T0:0:0Z,NOW%5D
@Test
public void testFacetFieldQuery() throws IOException, SolrServerException, ParseException {
//&facet=on
//&facet.interval=item_price
//&f.item_price.facet.interval.set=[0,1000]
//&f.item_price.facet.interval.set=[0,100]
//&facet.interval=item_createtime
//&f.item_createtime.facet.interval.set=[2019-01-01T0:0:0Z,NOW]
SolrQuery query=new SolrQuery();
//查询条件
query.setQuery("*:*");
//Facet相关参数
query.setFacet(true);
query.addIntervalFacets("item_price", new String[]{"[0,10]"});
query.addIntervalFacets("item_createtime", new String[]{"[2019-01-01T0:0:0Z,NOW]"});
QueryResponse response = httpSolrClient.query(query);
/*
item_price: {
[0,10]: 11
},
item_createtime: {
[2019-01-01T0:0:0Z,NOW]: 22
}
*/
List<IntervalFacet> intervalFacets = response.getIntervalFacets();
for (IntervalFacet intervalFacet : intervalFacets) {
String field = intervalFacet.getField();
System.out.println(field);
List<IntervalFacet.Count> intervals = intervalFacet.getIntervals();
for (IntervalFacet.Count interval : intervals) {
System.out.println(interval.getKey());
System.out.println(interval.getCount());
}
}
}
1.1.6 Facet维度查询
需求:统计每一个品牌和其不同分类商品对应的数量;
联想 手机 10
联想 电脑 2
华为 手机 10
...
http://localhost:8080/solr/collection1/select?q=*:*&
&facet=on
&facet.pivot=item_brand,item_category
@Test
public void testFacetFieldQuery() throws IOException, SolrServerException, ParseException {
// http://localhost:8080/solr/collection1/select?q=*:*&
// &facet=on
// &facet.pivot=item_brand,item_category
SolrQuery query=new SolrQuery();
//查询条件
query.setQuery("*:*");
//Facet相关参数
query.setFacet(true);
query.addFacetPivotField("item_brand,item_category");
QueryResponse response = httpSolrClient.query(query);
NamedList<List<PivotField>> facetPivot = response.getFacetPivot();
List<PivotField> pivotFields = facetPivot.get("item_brand,item_category");
for (PivotField pivotField : pivotFields) {
String field = pivotField.getField();
Object value = pivotField.getValue();
int count = pivotField.getCount();
System.out.println(field+"-"+value+"-"+count);
List<PivotField> fieldList = pivotField.getPivot();
for (PivotField pivotField1 : fieldList) {
String field1 = pivotField1.getField();
Object value1 = pivotField1.getValue();
int count1 = pivotField1.getCount();
System.out.println(field1+"-"+value1+"-"+count1);
}
}
}
到这关于SolrJ和Facet查询相关的操作就讲解完毕。
1.2 group查询
1.2.1 基础的分组
需求:查询Item_title中包含手机的文档,按照品牌对文档进行分组;同组中的文档放在一起。
http://localhost:8080/solr/collection1/select?
q=item_title:手机
&group=true
&group.field=item_brand
@Test
public void testGroupQuery() throws IOException, SolrServerException, ParseException {
SolrQuery params = new SolrQuery();
params.setQuery("item_title:手机");
/**
* q=item_title:手机
* &group=true
* &group.field=item_brand
*/
//注意solrJ中每没有提供分组特有API。需要使用set方法完成
params.setGetFieldStatistics(true);
params.set(GroupParams.GROUP, true);
params.set(GroupParams.GROUP_FIELD,"item_brand");
QueryResponse response = httpSolrClient.query(params);
GroupResponse groupResponse = response.getGroupResponse();
//由于分组的字段可以是多个。所以返回数组
List<GroupCommand> values = groupResponse.getValues();
//获取品牌分组结果
GroupCommand groupCommand = values.get(0);
//匹配到的文档数量
int matches = groupCommand.getMatches();
System.out.println(matches);
//每个组合每个组中的文档信息
List<Group> groups = groupCommand.getValues();
for (Group group : groups) {
//分组名称
System.out.println(group.getGroupValue());
//组内文档
SolrDocumentList result = group.getResult();
System.out.println(group.getGroupValue() +":文档个数" + result.getNumFound());
for (SolrDocument entries : result) {
System.out.println(entries);
}
}
}
1.2.2 group分页
默认情况下分组结果中只会展示前10个组,并且每组展示相关对最高的1个文档。我们可以使用start和rows可以设置组的分页,使用group.limit和group.offset设置组内文档分页。
q=item_title:手机&group=true&group.field=item_brand&start=0&rows=3
&group.limit=5&group.offset=0
展示前3个组及每组前5个文档。
//设置组的分页参数
params.setStart(0);
params.setRows(3);
//设置组内文档的分页参数
params.set(GroupParams.GROUP_OFFSET, 0);
params.set(GroupParams.GROUP_LIMIT, 5);
1.2.3 group排序
之前讲解排序的时候,group排序分为组排序,组内文档排序;对应的参数为sort和group.sort
需求:按照组内价格排序降序;
params.set(GroupParams.GROUP_SORT, "item_price desc");
当然分组还有其他的用法,都是大同小异,大家可以参考我们之前讲解分组的知识;
1.3 高亮
1.3.1 高亮查询
查询item_title中包含手机的文档,并且对item_title中的手机关键字进行高亮;
http://localhost:8080/solr/collection1/select?
q=item_title:手机
&hl=true
&hl.fl=item_title
&hl.simple.pre=<font>
&h1.simple.post=</font>
@Test
public void testHighlightingQuery() throws IOException, SolrServerException {
SolrQuery params = new SolrQuery();
params.setQuery("item_title:三星手机");
//开启高亮
params.setHighlight(true);
//设置高亮域
//高亮的前后缀
params.addHighlightField("item_title");
params.setHighlightSimplePre("<font>");
params.setHighlightSimplePost("</font>");
QueryResponse response = httpSolrClient.query(params);
SolrDocumentList results = response.getResults();
for (SolrDocument result : results) {
System.out.println(result);
}
//解析高亮
Map<String, Map<String, List<String>>> highlighting = response.getHighlighting();
//map的key是文档id,map的value包含高亮的数据
for (String id : highlighting.keySet()) {
System.out.println(id);
/**
* item_title: [
* "飞利浦 老人<em>手机</em> (X2560) 深情蓝 移动联通2G<em>手机</em> 双卡双待"
* ]
*/
Map<String, List<String>> highLightData = highlighting.get(id);
//highLightData key包含高亮域名
//获取包含高亮的数据
if(highLightData != null && highLightData.size() > 0) {
//[
// * "飞利浦 老人<em>手机</em> (X2560) 深情蓝 移动联通2G<em>手机</em> 双卡双待"
// * ]
List<String> stringList = highLightData.get("item_title");
if(stringList != null && stringList.size() >0) {
String title = stringList.get(0);
System.out.println(title);
}
}
}
//将高亮的数据替换到原有文档中。
}
1.3.2 高亮器的切换
当然我们也可以使用SolrJ完成高亮器的切换。之前我们讲解过一个高亮器fastVector,可以实现域中不同的词使用不同颜色。
查询item_title中包含三星手机的文档.item_title中三星手机中不同的词,显示不同的颜色;
http://localhost:8080/solr/collection1/select?
q=item_title:三星手机
&hl=true
&hl.fl=item_title
&hl.method=fastVector
SolrQuery params = new SolrQuery();
params.setQuery("item_title:三星手机");
//开启高亮
params.setHighlight(true);
params.addHighlightField("item_title");
params.set("hl.method","fastVector");
QueryResponse response = httpSolrClient.query(params);
到这使用SolrJ进行高亮查询就讲解完毕。
1.4 suggest查询
1.4.1 spell-checking 拼写检查。
需求:查询item_title中包含iphone的内容。要求进行拼写检查。
http://localhost:8080/solr/collection1/select?
q=item_title:iphonx&spellcheck=true
@Test
public void test01() throws IOException, SolrServerException {
SolrQuery params = new SolrQuery();
params.setQuery("item_title:iphonxx");
params.set("spellcheck",true);
QueryResponse response = httpSolrClient.query(params);
/**
* suggestions: [
* "iphonxx",
* {
* numFound: 1,
* startOffset: 11,
* endOffset: 18,
* suggestion: [
* "iphone6"
* ]
* }
* ]
*/
SpellCheckResponse spellCheckResponse = response.getSpellCheckResponse();
Map<String, SpellCheckResponse.Suggestion> suggestionMap = spellCheckResponse.getSuggestionMap();
for (String s : suggestionMap.keySet()) {
//错误的词
System.out.println(s);
//建议的词
SpellCheckResponse.Suggestion suggestion = suggestionMap.get(s);
List<String> alternatives = suggestion.getAlternatives();
System.out.println(alternatives);
}
}
1.4.2Auto Suggest自动建议。
上面我们讲解完毕拼写检查,下面我们讲解自动建议,自动建议也是需要在SolrConfig.xml中进行相关的配置。
需求:查询三星,要求基于item_title域进行自动建议
http://localhost:8080/solr/collection1/select?
q=三星&suggest=true&suggest.dictionary=mySuggester&suggest.count=5
@Test
public void test02() throws IOException, SolrServerException {
SolrQuery params = new SolrQuery();
//设置参数
params.setQuery("java");
//开启自动建议
params.set("suggest",true);
//指定自动建议的组件
params.set("suggest.dictionary","mySuggester");
QueryResponse response = httpSolrClient.query(params);
SuggesterResponse suggesterResponse = response.getSuggesterResponse();
Map<String, List<Suggestion>> suggestions = suggesterResponse.getSuggestions();
for (String key : suggestions.keySet()) {
//词
System.out.println(key);
List<Suggestion> suggestionList = suggestions.get(key);
for (Suggestion suggestion : suggestionList) {
String term = suggestion.getTerm();
System.out.println(term);
}
}
}
1.5 使用SolrJ完成Core的管理
1.5.1 Core添加
1.要想完成SolrCore的添加,在solr_home必须提前创建好SolrCore的目录结构,而且必须包相关的配置文件。
修改配置文件中url:http://localhost:8080/solr
CoreAdminRequest.createCore("collection4", "D:\\solr_home\\collection4", solrClient );
1.5.2 重新加载Core
从Solr中移除掉,然后在添加。
CoreAdminRequest.reloadCore("collection4", solrClient );
1.5.3 重命名Core
CoreAdminRequest.renameCore("collection4","newCore" , solrClient)
1.5.4 卸载solrCore
卸载仅仅是从Solr中将该Core移除,但是SolrCore的物理文件依然存在
CoreAdminRequest.unloadCore("collection4", solrClient );
1.5.5 solrCore swap
CoreAdminRequest.swapCore("collection1", "collection4", solrClient);
2. Solr集群搭建
2.1 SolrCloud简介
2.1.1 什么是SolrCloud
Solr集群也成为SolrCloud,是Solr提供的分布式搜索的解决方案,当你需要大规模存储数据或者需要分布式索引和检索能力时使用 SolrCloud。
所有数据库集群,都是为了解决4个核心个问题,单点故障,数据扩容,高并发,效率
搭建SolrCloud是需要依赖一个中间件Zookeeper,它的主要思想是使用Zookeeper作为集群的配置中心。
2.1.2 SolrCloud架构
SolrCloud逻辑概念:
一个Solr集群是由多个collection组成,collection不是SolrCore只是一个逻辑概念。一个collection是由多个文档组成,这些文档归属于指定的分片。下面表示的就是一个逻辑结构图。
该集群只有一个collection组成。connection中的文档数据分散在4个分片。
分片中的数据,到底存储在那呢?这就属于物理概念。
SolrCloud物理概念:
Solr 集群由一个或多个 Solr服务(tomcat中运行solr服务)组成,这些Solr服务可以部署一台服务器上,也可以在多台服务器。每个Solr服务可以包含一个或者多个Solr Core 。SolrCore中存储的是Shard的数据;
下面的图是一个物理结构和逻辑结构图。
概念:
Collection是一个逻辑概念,可以认为是多个文档构成的一个集合。
Shard是一个逻辑概念,是对Collection进行逻辑上的划分。
Replica:Shard的一个副本,一个Shard有多个副本,同一个Shard副本中的数据一样;
Leader:每个Shard会以多个Replica的形式存在,其中一个Replica会被选为Leader,负责集群环境中的索引和搜索。
SolrCore:存储分片数据的基本单元。一个SolrCore只存储一个分片数据,一个分片数据可以存储到多个SolrCore中;一个SolrCore对应一个Replica
Node:集群中的一个Solr服务
2.2Linux集群搭建
2.2.1 基于tomcat的集群搭建
2.2.1.1集群架构介绍
物理上:
搭建三个Zookeeper组成集群,管理SolrCloud。
搭建四个Solr服务,每个Solr服务一个SorCore.
逻辑上:
整个SolrCloud一个Connection;
Connection中的数据分为2个Shard;
Shard1的数据在物理上存储到solr1和solr2的SolrCore
Shard2的数据在物理上存储到solr3和solr4的SolrCore

2.2.1.2 环境说明
环境和我们之前搭建单机版的环境相同。
| 系统 | 版本 |
|---|---|
| Linux | CentOS 7 |
| JDK | JDK8 |
| Tomcat | tomcat 8.5 |
| zookeeper | zookeeper-3.4.14 |
| solr | solr 7.7.2 |
2.2.1.3 Zookeeper集群搭建
首先我们先要完成Zookeeper集群搭建。在搭建集群之前,首先我们先来说一下Zookeeper集群中要求节点的个数。
在Zookeeper集群中节点的类型主要有2类,Leader,Follower,一个集群只有一个Leader。
到底谁是Leader呢?
投票选举制度:集群中所有的节点来进行投票,半数以上获票的节点就是Leader.Zookeeper要求集群节点个数奇数。
容错:zookeeper集群一大特性是只要集群中半数以上的节点存活,集群就可以正常提供服务,而2n+1节点和2n+2个节点的容错能力相同,都是允许n台节点宕机。本着节约的宗旨,一般选择部署2n+1台机器
本次我们采用最少的集群节点3个。

1.下载Zookeeper的安装包到linux。
下载地址:
http://archive.apache.org/dist/zookeeper/zookeeper-3.4.14/
上面的地址可能受每日访问量现在
wget
https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz
2. 解压zookeeper, 复制三份到/usr/local/solrcloud下,复制三份分别并将目录名改为zk01、在zk02、zk03
mkdir /usr/local/solrcloud
tar -xzvf zookeeper-3.4.14.tar.gz
cp -r zookeeper-3.4.14 /usr/local/solrcloud/zk01
cp -r zookeeper-3.4.14 /usr/local/solrcloud/zk02
cp -r zookeeper-3.4.14 /usr/local/solrcloud/zk03
结果
-
为每一个Zookeeper创建数据目录
mkdir zk01/data mkdir zk02/data mkdir zk03/data

-
在data目录中为每一个Zookeeper创建myid文件,并且在文件中指定该Zookeeper的id;
使用重定向指令>>将打印在控制台上的1 2 3分别写入到data目录的myid文件中。 echo 1 >> zk01/data/myid echo 2 >> zk02/data/myid echo 3 >> zk03/data/myid

-
修改Zookeeper的配置文件名称。
5.1 需要将每个zookeeper/conf目录中的zoo_sample.cfg 文件名改名为zoo.cfg,否则该配置文件不起作用。
mv zk01/conf/zoo_sample.cfg zk01/conf/zoo.cfg mv zk02/conf/zoo_sample.cfg zk02/conf/zoo.cfg mv zk03/conf/zoo_sample.cfg zk03/conf/zoo.cfg

6. 编辑zoo.cfg配置文件
5.1 修改Zookeeper客户端连接的端口,Zookeeper对外提供服务的端口。修改目的,我们需要在一台计算机上启动三个Zookeeper。
clientPort=2181
clientPort=2182
clientPort=2183
5.2 修改数据目录
dataDir=/usr/local/solrcloud/zk01/data
dataDir=/usr/local/solrcloud/zk02/data
dataDir=/usr/local/solrcloud/zk03/data
5.3 在每一个配置文件的尾部加入,指定集群中每一个Zookeeper的节点信息。
server.1=192.168.200.128:2881:3881
server.2=192.168.200.128:2882:3882
server.3=192.168.200.128:2883:3883
server.1 server.2 server.3 指定Zookeeper节点的id.之前我们myid已经指定了每个节点的id;
内部通信端口:
Zookeeper集群节点相互通信端口;
为什么会有投票端口呢?
1.因为三台Zookeeper要构成集群,决定谁是leader,Zookeeper中是通过投票机制决定谁是leader。
2.如果有节点产生宕机,也需要通过投票机制将宕机节点从集群中剔除。
所以会有一个投票端口
7.启动Zookeeper集群。
在bin目录中提供了一个脚本zkServer.sh,使用zkServer.sh start|restart|stop|status 就可以完成启动,重启,停止,查看状态。
可以写一个脚本性启动所有Zookeeper。也可以一个个的启动;
./zk01/bin/zkServer.sh start
./zk02/bin/zkServer.sh start
./zk03/bin/zkServer.sh start

8.查看Zookeeper集群状态。
./zk01/bin/zkServer.sh status
./zk02/bin/zkServer.sh status
./zk03/bin/zkServer.sh status

follower就是slave;
leader就是master;
如果是单机版的Zookeeper,standalone
到这关于Zookeeper集群的搭建,我们就讲解完毕。
2.2.1.4 SolrCloud集群部署
上一节我们已经完成了Zookeeper集群的搭建,下面我们来搭建solr集群。

复制4个tomcat,并且要在4个tomcat中部署solr,单机版solr的搭建,我们之前已经讲解过了。
下面是我们已经搭建好的单机版的solr,他的tomcat和solrhome
1.1 将tomcat复制4份到solrcloud中,便于集中管理。这4个tomcat中都部署了solr;
cp -r apache-tomcat-8.5.50 solrcloud/tomcat1
cp -r apache-tomcat-8.5.50 solrcloud/tomcat2
cp -r apache-tomcat-8.5.50 solrcloud/tomcat3
cp -r apache-tomcat-8.5.50 solrcloud/tomcat4

1.2 复制4个solrhome到solrcloud中。分别对应每一个solr的solrhome。
cp -r solr_home solrcloud/solrhome1
cp -r solr_home solrcloud/solrhome2
cp -r solr_home solrcloud/solrhome3
cp -r solr_home solrcloud/solrhome4

1.3 修改tomcat的配置文件,修改tomcat的端口,保证在一台计算机上,可以启动4个tomcat;
编辑server.xml
修改停止端口
对外提供服务端口
AJP端口
<Server port="8005"shutdown="SHUTDOWN">
<Connector port="8080"protocol="HTTP/1.1" connectionTimeout="20000" redirect
<Connector port="8009" protocol="AJP/1.3"redirectPort="8443" />
tomcat1 8105 8180 8109
tomcat1 8205 8280 8209
tomcat1 8305 8380 8309
tomcat1 8405 8480 8409
1.4 为tomcat中每一个solr指定正确的solrhome,目前是单机版solrhome的位置。
编辑solr/web.xml指定对应的solrhome
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>/usr/local/solrcloud/solrhomeX</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>
1.5 修改每个solrhome中solr.xml的集群配置,对应指定tomcat的ip和端口
编辑solrhome中solr.xml
<solrcloud>
<str name="host">192.168.200.1288</str>
<int name="hostPort">8X80</int>
</solrcloud>
2.2.1.5 Zookeeper管理的Solr集群
上一节课我们已经搭建好了Zookeeper集群,和Solr的集群。但是现在Zookeeper集群和Solr集群没有关系。
需要让Zookeeper管理Solr集群。
1.启动所有的tomcat
./tomcat1/bin/startup.sh
./tomcat2/bin/startup.sh
./tomcat3/bin/startup.sh
./tomcat4/bin/startup.sh
2.让每一个solr节点和zookeeper集群关联
编辑每一个tomcat中bin/catalina.sh文件,指定Zookeeper集群地址。
JAVA_OPTS="-DzkHost=192.168.200.128:2181,192.168.200.128:2182,192.168.200.128:2183"
需要指定客户端端口即Zookeeper对外提供服务的端口
3.让zookeeper统一管理solr集群的配置文件。
因为现在我们已经是一个集群,集群中的每个solr节点配置文件需要一致。所以我们就需要让zookeeper管理solr集群的配置文件。主要管理的就是solrconfig.xml / schema.xml文件
下面的命令就是将conf目录中的配置文件,上传到Zookeeper,以后集群中的配置文件就以Zookeeper中的为准;
搭建好集群后,solrCore中是没有配置文件的。
./zkcli.sh -zkhost 192.168.200.128:2181,192.168.200.128:2182,192.168.200.128:2183 -cmd upconfig -confdir /usr/local/solrcloud/solrhome1/collection1/conf -confname myconf
-zkhost:指定zookeeper的地址列表;
upconfig :上传配置文件;
-confdir :指定配置文件所在目录;
-confname:指定上传到zookeeper后的目录名;
进入到solr安装包中
/root/solr-7.7.2/server/scripts/cloud-scripts
./zkcli.sh -zkhost 192.168.200.128:2181,192.168.200.128:2182,192.168.200.128:2183 -cmd upconfig -confdir /usr/local/solrcloud/solrhome1/collection1/conf -confname myconf
./zkcli.sh -zkhost 192.168.200.128:2181,192.168.200.128:2182,192.168.200.128:2183 -cmd upconfig -confdir /root/solr7.7.2/server/solr/configsets/sample_techproducts_configs/conf
-confname myconf

4.查看Zookeeper中的配置文件。
登录到任意一个Zookeeper上,看文件是否上传成功。
进入到任意一个Zookeeper,查看文件的上传状态。
/zKCli.sh -server 192.168.200.128:2182
通过Zookeeper客户端工具查看。idea的Zookeeper插件,ZooInspector等。
- 由于solr的配置文件,已经交由Zookeeper管理。所有SolrHome中的SolrCore就可以删除。
到这Zookeeper集群和Solr集群整合就讲解完毕。
2.2.1.6 创建Solr集群的逻辑结构
之前我们已经搭建好了Zookeeper集群及Solr集群。接下来我们要完成的是逻辑结构的创建。

我们本次搭建的逻辑结构整个SolrCloud是由一个Collection构成。Collection分为2个分片。每个分片有2个副本。分别存储在不同的SolrCore中。
启动所有的tomcat
./tomcat1/bin/startup.sh
./tomcat2/bin/startup.sh
./tomcat3/bin/startup.sh
./tomcat4/bin/startup.sh
访问任4个solr管理后台;
http://192.168.200.131:8180/solr/index.html#/~collections
http://192.168.200.131:8280/solr/index.html#/~collections
http://192.168.200.131:8380/solr/index.html#/~collections
http://192.168.200.131:8480/solr/index.html#/~collections
使用任何一个后台管理系统,创建逻辑结构

name:指定逻辑结构collection名称;
config set:指定使用Zookeeper中配置文件;
numShards:分片格式
replicationFactory:每个分片副本格式;
当然我们也可以通过Solr RestAPI完成上面操作
http://其中一个solr节点的IP:8983/solr/admin/collections?action=CREATE&name=testcore&numShards=2&replicationFactor=2&collection.configName=myconf
查询逻辑结构

查看物理结构

说明一下: 原来SolrCore的名字已经发生改变。
一旦我们搭建好集群后,每个SolrCore中是没有conf目录即没有配置文件。
整个集群的配置文件只有一份,Zookeeper集群中的配置文件。
2.2.1.7测试集群
向collection中添加数据
{id:"100",name:"zhangsan"}
由于整合集群逻辑上就一个collection,所以在任何一个solr节点都可以获取数据。
2.2.1.8 使用SolrJ操作集群
之前我们操作单节点的Solr,使用的是HttpSolrClient,操作集群我们使用的是CloudSolrClient。
- 将CloudSolrClient交由spring管理。
@Bean
public CloudSolrClient cloudSolrClient() {
//指定Zookeeper的地址。
List<String> zkHosts = new ArrayList<>();
zkHosts.add("192.168.200.131:2181");
zkHosts.add("192.168.200.131:2182");
zkHosts.add("192.168.200.131:2183");
//参数2:指定
CloudSolrClient.Builder builder = new CloudSolrClient.Builder(zkHosts,Optional.empty());
CloudSolrClient solrClient = builder.build();
//设置连接超时时间
solrClient.setZkClientTimeout(30000);
solrClient.setZkConnectTimeout(30000);
//设置collection
solrClient.setDefaultCollection("collection");
return solrClient;
}
2.使用CloudSolrClient中提供的API操作Solr集群,和HttpSolrClient相同
索引
@Autowired
private CloudSolrClient cloudSolrClient;
@Test
public void testSolrCloudAddDocument() throws Exception {
SolrInputDocument doc = new SolrInputDocument();
doc.setField("id", 1);
doc.setField("name", "java");
cloudSolrClient.add(doc);
cloudSolrClient.commit();
}
搜索
@Test
public void testSolrQuery() throws Exception {
SolrQuery params = new SolrQuery();
params.setQuery("*:*");
QueryResponse response = cloudSolrClient.query(params);
SolrDocumentList results = response.getResults();
for (SolrDocument result : results) {
System.out.println(result);
}
}
2.2.2 SolrCloud的其他操作
2.2.2.1 SolrCloud使用中文分词器(IK)
1.在每一个solr服务中,引入IK分词器的依赖包

2.在classes中引入停用词和扩展词库及配置文件

3.重启所有的tomcat
4.修改单机版solrcore中schema,加入FiledType
<fieldType name ="text_ik" class ="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
5.将schema重新提交到Zookeeper
Solr集群中的配置文件统一由Zookeeper进行管理,所以如果需要修改配置文件,我们需要将修改的文件上传的Zookeeper。
./zkcli.sh -zkhost 192.168.200.128:2181,192.168.200.128:2182,192.168.200.128:2183 -cmd putfile /configs/myconf/managed-schema /usr/local/solr_home/collection1/conf/managed-schema
6. 测试
7.利用text_ik 创建相关的业务域
创建业务域,我们依然需要修改shema文件,这个时候,我们建议使用后台管理系统。

8.查看schema文件是否被修改。
通过files查看集群中的配置文件,内容

到这关于如何修改集群中的配置文件,已经如何管理Filed我们就讲解完毕。
2.2.2.2 查询指定分片数据
在SolrCloud中,如果我们想查询指定分片的数据也是允许的。
需求:查询shard1分片的数据
http://192.168.200.128:8180/solr/myCollection/select?q=*:*&shards=shard1

需求:查询shard1和shard2分片的数据
http://192.168.200.128:8180/solr/myCollection/select?q=*:*&shards=shard1,shard2
上面的操作都是从根据shard的id随机从shard的副本中获取数据。shard1的数据可能来自8380,8280
shard2的数据可能来自8480,8180
也可以指定具体的副本;
需求:获取shard1分片8280副本中的数据
http://192.168.200.128:8180/solr/myCollection/select?q=*:*&shards=192.168.200.128:8280/solr/myCollection
需求:获取8280和8380副本中数据
http://192.168.200.128:8180/solr/myCollection/select?q=*:*&shards=192.168.200.128:8280/solr/myCollection,192.168.200.128:8380/solr/myCollection
混合使用,通过Shard的ID随机获取+通过副本获取。
http://192.168.200.128:8180/solr/myCollection/select?q=*:*&shards=shard1,192.168.200.128:8380/solr/myCollection
2.2.2.3 SolrCloud并发和线程池相关的一些配置
在SolrCloud中,我们也可以配置Shard并发和线程相关的配置,来优化集群性能。
主要的配置在solr.xml文件。
<solr>
<!--集群相关的配置,solr服务的地址,端口,上下文solr.是否自动生成solrCore名称,zk超时时间-->
<solrcloud>
<str name="host">192.168.200.131</str>
<int name="hostPort">8180</int>
<str name="hostContext">${hostContext:solr}</str>
<bool name="genericCoreNodeNames">${genericCoreNodeNames:true}</bool>
<int name="zkClientTimeout">${zkClientTimeout:30000}</int>
<int name="distribUpdateSoTimeout">${distribUpdateSoTimeout:600000}</int>
<int name="distribUpdateConnTimeout">${distribUpdateConnTimeout:60000}</int>
<str name="zkCredentialsProvider">${zkCredentialsProvider:org.apache.solr.common.cloud.DefaultZkCredentialsProvider}</str>
<str name="zkACLProvider">${zkACLProvider:org.apache.solr.common.cloud.DefaultZkACLProvider}</str>
</solrcloud>
<!-- 分片并发和线程相关的信息-->
<shardHandlerFactory name="shardHandlerFactory"
class="HttpShardHandlerFactory">
<int name="socketTimeout">${socketTimeout:600000}</int>
<int name="connTimeout">${connTimeout:60000}</int>
<str name="shardsWhitelist">${solr.shardsWhitelist:}</str>
</shardHandlerFactory>
</solr>
相关参数
| 参数名 | 描述 | 默认值 |
|---|---|---|
| socketTimeout | 指客户端和服务器建立连接后,客户端从服务器读取数据的timeout | distribUpdateSoTimeout |
| connTimeout | 指客户端和服务器建立连接的timeout | distribUpdateConnTimeout |
| maxConnectionsPerHost | 最大并发数量 | 20 |
| maxConnections | 最大连接数量 | 10000 |
| corePoolSize | 线程池初始化线程数量 | 0 |
| maximumPoolSize | 线程池中线程的最大数量 | Integer.MAX_VALUE |
| maxThreadldleTime | 设置线程在被回收之前空闲的最大时间 | 5秒 |
| sizeOfQueue | 指定此参数 ,那么线程池会使用队列来代替缓冲区,对于追求高吞吐量的系统而 ,可能希望配置为-1 。对于于追求低延迟的系统可能希望配置合理的队列大小来处理请求 。 | -1 |
| fairnessPolicy | 用于选择JVM特定的队列的公平策略:如果启用公平策略,分布式查询会以先进先出的方式来处理请求,但是是是以有损吞吐量为代价;如果禁用公平策略,会提高集群查询吞吐量,但是以响应延迟为代价。 | false |
| useRetries | 是否启 HTTP 连接自动重试机制,避免由 HTTP 连接池 的限制或者竞争导致的 IOException ,默认未开启 | false |
2.3.2 基于docker的集群搭建
2.3.2.1 环境准备
1.搭建docker
要想在docker上搭建solr集群,首先安装docker的环境。这个就不再演示,如果没有学过docker的同学可以参考下面的视频地址进行学习。
Docker容器化技术入门与应用-JavaEE免费视频课程-博学谷
如果学习过但是忘了如何搭建,参考一下地址。
-
拉取zookeeper镜像和solr的镜像,采用的版本是3.4.14和7.7.2
docker pull zookeeper:3.4.14 docker pull solr:7.7.2查看拉取镜像
docker images

2.3.2.2 搭建zookeeper集群
搭建zookeeper集群,我们需要利用我们刚才拉取的zookeeper的镜像创建3个容器。并且让他们产生集群关系。
单独创建一个桥接网卡
docker network create itcast-zookeeper
docker network ls
1.容器1创建
docker run
-id
--restart=always
-v /opt/docker/zookeeper/zoo1/data:/data
-v /opt/docker/zookeeper/zoo1/datalog:/datalog
-e ZOO_MY_ID=1
-e ZOO_SERVERS="server.1=zookeeper1:2888:3888 server.2=zookeeper2:2888:3888 server.3=zookeeper3:2888:3888"
-p 2181:2181
--name=zookeeper1
--net=itcast-zookeeper
--privileged
zookeeper:3.4.14
docker run -id --restart=always -v /opt/docker/zookeeper/zoo1/data:/data -v /opt/docker/zookeeper/zoo1/datalog:/datalog -e ZOO_MY_ID=1 -e ZOO_SERVERS="server.1=zookeeper1:2888:3888 server.2=zookeeper2:2888:3888 server.3=zookeeper3:2888:3888" -p 2181:2181 --name=zookeeper1 --privileged --net=itcast-zookeeper zookeeper:3.4.14
说明:
--restart:docker重启,容器重启。
-d:守护式方式运行方式,除此之外还有-it
-v:目录挂载,用宿主机/opt/docker/zookeeper/zoo1/data,映射容器的/data目录
-e:指定环境参数。分别指定了自己的id,集群中其他节点的地址,包含通信端口和投票端口
--name:容器的名称
-p:端口映射,用宿主机2181映射容器 2181,将来我们就需要通过本机2181访问容器。
--privileged:开启特权,运行修改容器参数
--net=itcast-zookeeper 指定桥接网卡
zookeeper:3.4.14:创建容器的镜像
查看创建好的容器
docker ps

查看宿主机的目录,该目录映射的就是zookeeper1容器中的data目录。
cd /opt/docker/zookeeper/zoo1/data
查看Zookeeper节点的id
cat myid
2.容器2创建
docker run -d --restart=always
-v /opt/docker/zookeeper/zoo2/data:/data
-v /opt/docker/zookeeper/zoo2/datalog:/datalog
-e ZOO_MY_ID=2
-e ZOO_SERVERS="server.1=zookeeper1:2888:3888 server.2=zookeeper2:2888:3888 server.3=zookeeper3:2888:3888"
-p 2182:2181
--name=zookeeper2
--net=itcast-zookeeper
--privileged
zookeeper:3.4.14
docker run -d --restart=always -v /opt/docker/zookeeper/zoo2/data:/data -v /opt/docker/zookeeper/zoo2/datalog:/datalog -e ZOO_MY_ID=2 -e ZOO_SERVERS="server.1=zookeeper1:2888:3888 server.2=zookeeper2:2888:3888 server.3=zookeeper3:2888:3888" -p 2182:2181 --name=zookeeper2 --net=itcast-zookeeper --privileged zookeeper:3.4.14
说明:
需要修改目录挂载。
修改Zookeeper的id
端口映射:用宿主机2182 映射容器 2181
容器名称:zookeeper2
3.容器3创建
docker run -d --restart=always
-v /opt/docker/zookeeper/zoo3/data:/data
-v /opt/docker/zookeeper/zoo3/datalog:/datalog
-e ZOO_MY_ID=3
-e ZOO_SERVERS="server.1=zookeeper1:2888:3888 server.2=zookeeper2:2888:3888 server.3=zookeeper3:2888:3888"
-p 2183:2181
--name=zookeeper3
--net=itcast-zookeeper
--privileged
zookeeper:3.4.14
docker run -d --restart=always -v /opt/docker/zookeeper/zoo3/data:/data -v /opt/docker/zookeeper/zoo3/datalog:/datalog -e ZOO_MY_ID=3 -e ZOO_SERVERS="server.1=zookeeper1:2888:3888 server.2=zookeeper2:2888:3888 server.3=zookeeper3:2888:3888" -p 2183:2181 --name=zookeeper3 --net=itcast-zookeeper --privileged zookeeper:3.4.14
说明:
需要修改目录挂载。
修改Zookeeper的id
端口映射:用宿主机2183 映射容器 2181
容器名称:zookeeper3
查看容器创建情况

2.3.2.3 测试Zookeeper集群的搭建情况
使用yum安装nc指令
yum install -y nc
方式1:
通过容器的ip查看Zookeeper容器状态
查看三个Zookeeper容器的ip
docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' zookeeper1
docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' zookeeper2
docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' zookeeper3
查看Zookeeper集群的状态
echo stat|nc ip 2181
echo stat|nc ip 2181
echo stat|nc ip 2181

方式2:通过宿主机的ip查询Zookeeper容器状态

2.3.2.4 zookeeper集群的架构
Zookeeper集群架构
Zookeeper客户端连接Zookeeper容器
2.3.2.3 搭建solr集群
搭建Solr集群,我们需要利用我们刚才拉取的solr的镜像创建4个容器。并且需要将集群交由Zookeeper管理,Solr容器内部使用jetty作为solr的服务器。
1.容器1创建
docker run --name solr1 --net=itcast-zookeeper -d -p 8983:8983 solr:7.7.2 bash -c '/opt/solr/bin/solr start -f -z zookeeper1:2181,zookeeper2:2181,zookeeper3:2181'
--name:指定容器名称
--net:指定网卡,之前创建的桥接网卡
-d:后台运行
-p:端口映射,宿主机8983映射容器中8983
-c:
/opt/solr/bin/solr:通过容器中脚本,指定Zookeeper的集群地址
2.容器2创建
docker run --name solr2 --net=itcast-zookeeper -d -p 8984:8983 solr:7.7.2 bash -c '/opt/solr/bin/solr start -f -z zookeeper1:2181,zookeeper2:2181,zookeeper3:2181'
--name:指定容器名称
--net:指定网卡,之前创建的桥接网卡
-d:后台运行
-p:端口映射,宿主机8983映射容器中8984
-c:/opt/solr/bin/solr:通过容器中脚本,指定Zookeeper的集群地址
3.容器3创建
docker run --name solr3 --net=itcast-zookeeper -d -p 8985:8983 solr:7.7.2 bash -c '/opt/solr/bin/solr start -f -z zookeeper1:2181,zookeeper2:2181,zookeeper3:2181'
--name:指定容器名称
--net:指定网卡,之前创建的桥接网卡
-d:后台运行
-p:端口映射,宿主机8983映射容器中8984
-c:/opt/solr/bin/solr:通过容器中脚本,指定Zookeeper的集群地址
4.容器4创建
docker run --name solr4 --net=itcast-zookeeper -d -p 8986:8983 solr:7.7.2 bash -c '/opt/solr/bin/solr start -f -z zookeeper1:2181,zookeeper2:2181,zookeeper3:2181'
--name:指定容器名称
--net:指定网卡,之前创建的桥接网卡
-d:后台运行
-p:端口映射,宿主机8983映射容器中8985
-c:/opt/solr/bin/solr:通过容器中脚本,指定Zookeeper的集群地址
5.查看结果

2.3.2.5 整体架构

2.3.2.6 创建集群的逻辑结构
1.通过端口映射访问solr的后台系统(注意关闭防火墙)
http://192.168.200.128:8983/solr
http://192.168.200.128:8984/solr
http://192.168.200.128:8985/solr
http://192.168.200.128:8986/solr
2.上传solr配置文件到Zookeeper集群。
进入到某个solr容器中,使用/opt/solr/server/scripts/cloud-scripts/的zkcli.sh 。上传solr的配置文件。
位置/opt/solr/example/example-DIH/solr/solr/conf到Zookeeper集群zookeeper1:2181,zookeeper2:2181,zookeeper3:2181。
docker exec -it solr1 /opt/solr/server/scripts/cloud-scripts/zkcli.sh -zkhost zookeeper1:2181,zookeeper2:2181,zookeeper3:2181 -cmd upconfig -confdir /opt/solr/server/solr/configsets/sample_techproducts_configs/conf -confname myconfig
3.使用zooInterceptor查看配置文件上传情况
4.使用后台管理系统创建connection
5. 查看集群的逻辑结构
到这基于docker的solr集群我们就讲解完毕。
6.测试集群
{id:1,name:"zx"}
2.3.2.7 solr配置文件修改
1.在linux服务器上需要有一份solr的配置文件,修改宿主机中的配置文件。
之前单机版solr的/usr/local/solr_home下,就有solr的配置文件。
/usr/local/solr_home下面的配置文件,schema已经配置了基于IK分词器的FieldType
2.将宿主机中的配置文件,替换到某个solr容器中。
docker cp /usr/local/solr_home/collection1/conf/managed-schema solr1:/opt/solr/server/solr/configsets/sample_techproducts_configs/conf/managed-schema
3.将容器中修改后managed-schema配置文件,重新上传到Zookeeper集群。
进入到solr1容器中,使用zkcli.sh命令,将最新的配置文件上传到Zookeeper集群
容器文件位置:/opt/solr/server/solr/configsets/sample_techproducts_configs/conf/managed-schema
集群文件位置: /configs/myconfig/managed-schema
docker exec -it solr1 /opt/solr/server/scripts/cloud-scripts/zkcli.sh -zkhost zookeeper1:2181,zookeeper2:2181,zookeeper3:2181 -cmd putfile /configs/myconfig/managed-schema /opt/solr/server/solr/configsets/sample_techproducts_configs/conf/managed-schema
4.在Files中查看,修改后的配置文件
5.将IK分词器的jar包,及配置文件复制到4个solr容器中。
5.1 将IK分词器上传到linux服务器
5.2 使用docker cp命令进行jar包的拷贝
docker cp /root/ik-analyzer-solr5-5.x.jar solr1:/opt/solr/server/solr-webapp/webapp/WEB-INF/lib/ik-analyzer-solr5-5.x.jar
docker cp /root/ik-analyzer-solr5-5.x.jar solr2:/opt/solr/server/solr-webapp/webapp/WEB-INF/lib/ik-analyzer-solr5-5.x.jar
docker cp /root/ik-analyzer-solr5-5.x.jar solr3:/opt/solr/server/solr-webapp/webapp/WEB-INF/lib/ik-analyzer-solr5-5.x.jar
docker cp /root/ik-analyzer-solr5-5.x.jar solr4:/opt/solr/server/solr-webapp/webapp/WEB-INF/lib/ik-analyzer-solr5-5.x.jar
5.3 使用docker cp命令进行配置文件的拷贝
将IK分析器的相关配置文件复制到/root/classes目录中
docker cp /root/classes solr1:/opt/solr/server/solr-webapp/webapp/WEB-INF/classes
docker cp /root/classes solr2:/opt/solr/server/solr-webapp/webapp/WEB-INF/classes
docker cp /root/classes solr3:/opt/solr/server/solr-webapp/webapp/WEB-INF/classes
docker cp /root/classes solr4:/opt/solr/server/solr-webapp/webapp/WEB-INF/classes
6、重启所有solr容器
docker restart solr1
docker restart solr2
docker restart solr3
docker restart solr4
7、使用text_ik创建业务域
不再使用修改配置文件的方式,直接利用后台管理系统进行。
{id:2,book_name:"java编程思想"}
2.3.2.7 使用SolrJ操作solr集群
1.修改Zookeeper地址和connection名称
@Bean
public CloudSolrClient cloudSolrClient() {
//指定Zookeeper的地址。
List<String> zkHosts = new ArrayList<>();
zkHosts.add("192.168.200.128:2181");
zkHosts.add("192.168.200.128:2182");
zkHosts.add("192.168.200.128:2183");
//参数2:指定
CloudSolrClient.Builder builder = new CloudSolrClient.Builder(zkHosts,Optional.empty());
CloudSolrClient solrClient = builder.build();
//设置连接超时时间
solrClient.setZkClientTimeout(30000);
solrClient.setZkConnectTimeout(30000);
//设置collection
solrClient.setDefaultCollection("myCollection");
return solrClient;
}
-
将之前的索引和搜索的代码执行一下
@Test public void testSolrCloudAddDocument() throws Exception { SolrInputDocument doc = new SolrInputDocument(); doc.setField("id", "3"); doc.setField("book_name", "葵花宝典"); cloudSolrClient.add(doc); cloudSolrClient.commit(); } @Test public void testSolrQuery() throws Exception { SolrQuery params = new SolrQuery(); params.setQuery("*:*"); QueryResponse response = cloudSolrClient.query(params); SolrDocumentList results = response.getResults(); for (SolrDocument result : results) { System.out.println(result); } } -
执行之前的代码会报错

错误的原因:连接不上172.19.0.6.8983。
这个容器是谁?

为什么连接不上呢?
-
错误的原因

-
正确的测试方案
将客户端应用部署到docker容器中,容器之间是可以相互通信的。
如何将我们的应用部署到docker容器中。
5.1 修改代码,将添加文档的操作写在controller方法中,便于我们进行测试;
@RestController @RequestMapping("/test") public class TestController { @Autowired private CloudSolrClient cloudSolrClient; @RequestMapping("/addDocument") public Map<String,Object> addDocument(String id,String bookName) throws IOException, SolrServerException { SolrInputDocument doc = new SolrInputDocument(); doc.setField("id", id); doc.setField("book_name", bookName); cloudSolrClient.add(doc); cloudSolrClient.commit(); Map<String,Object> result = new HashMap<>(); result.put("flag", true); result.put("msg","添加文档成功" ); return result; } }5.2 将spring boot项目打成可以运行jar包。
<build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build>5.3 使用package命令打成jar
clean package -DskipTests=true5.4 将jar包上传到linux服务器制作镜像
5.4.1上传
5.4.2 编写DockerFile文件
#基础镜像 FROM java:8 #作者 MAINTAINER itcast #将jar包添加到镜像app.jar ADD solr_solrJ_other-1.0-SNAPSHOT.jar app.jar #运行app的命令 java -jar app.jar ENTRYPOINT ["java","-jar","/app.jar"] 5.4.3 创建镜像
docker build -t myapp:1.0 ./ 使用当前目录的DockerFile文件创建镜像myapp,版本1.0 查看镜像
docker images查看

5.4.4 利用myapp:1.0镜像创建容器
docker run -d --net=itcast-zookeeper -p 8888:8080 myapp:1.0 #使用本地8888映射容器中8080 5.4.5 查看日志
docker logs -f 容器id 5.5.6 访问controller
http://192.168.200.128:8888/test/addDocument?id=999&bookName=葵花宝典 注意:如果发现连接不上Zookeeper,注意关闭防火墙;
systemctl stop firewalld
-
3.Solr查询高级
3.1 函数查询
在Solr中提供了大量的函数,允许我们在查询的时候使用函数进行动态运算。
3.2.1 函数调用语法
函数调用语法和java基本相同,格式为:函数名(实参),实参可以是常量(100,1.45,"hello"),也可以是域名,下面是函数调用例子。
functionName()
functionName(...)
functionName1(functionName2(...),..)
数据准备:为了便于我们后面的讲解,采用的案例数据,员工信息。
业务域:
员工姓名,工作,领导的员工号,入职日期,月薪,奖金
<field name="emp_ename" type="text_ik" indexed="true" stored="true"/>
<field name="emp_ejob" type="text_ik" indexed="true" stored="true"/>
<field name="emp_mgr" type="string" indexed="true" stored="true"/>
<field name="emp_hiredate" type="pdate" indexed="true" stored="true"/>
<field name="emp_sal" type="pfloat" indexed="true" stored="true"/>
<field name="emp_comm" type="pfloat" indexed="true" stored="true"/>
<field name="emp_cv" type="text_ik" indexed="true" stored="false"/>
<field name="emp_deptno" type="string" indexed="true" stored="true"/>
data-import.xml
<entity name="emp" query="select * from emp">
<!-- 每一个field映射着数据库中列与文档中的域,column是数据库列,name是solr的域(必须是在managed-schema文件中配置过的域才行) -->
<field column="empno" name="id"/>
<field column="ename" name="emp_ename"/>
<field column="ejob" name="emp_ejob"/>
<field column="mgr" name="emp_mgr"/>
<field column="hiredate" name="emp_hiredate"/>
<field column="sal" name="emp_sal"/>
<field column="comm" name="emp_comm"/>
<field column="cv" name="emp_cv"/>
<field column="deptno" name="emp_deptno"/>
</entity>
3.2.2 函数的使用
3.2.2.1 将函数返回值作为关键字
在solr中通常的搜索方式都是根据关键字进行搜索。底层首先要对关键字分词,在倒排索引表中根据词查找对应的文档返回。
item_title:三星手机
需求:查询年薪在30000~50000的员工。
主查询条件:查询所有:
过滤条件: 利用product()函数计算员工年薪,product函数是Solr自带函数,可以计算2个数之积。{!frange}指定范围。l表示最小值,u表示最大值.{!frange}语法是Function Query Parser解析器中提供的一种语法。
q=*:*
&fq={!frange l=30000 u=50000}product(emp_sal,12)
需求:查询年薪+奖金大于50000的员工
通过sum函数计算年薪+奖金。
q=*:*
&fq={!frange l=50000}sum(product(emp_sal,12),emp_comm)
上面查询不出来数据,原因是有些员工emp_comm为空值。
emp_comm进行空值处理。判断emp_comm是否存在,不存在指定位0,存在,本身的值
exists判断域是否存在
if指定存在和不存在值
{!frange l=40000}sum(product(emp_sal,12),if(exists(emp_comm),emp_comm,0))
3.2.2.1.2 将函数返回值作为伪域
伪域:文档中本身不包含的域,利用函数生成。
需求:查询所有的文档,每个文档中包含年薪域。
q=*:*&
fl=*,product(emp_sal,12)
指定别名:yearsql:product(emp_sal,12) 便于将来封装
3.2.2.1.3 根据函数进行排序
需求:查询所有的文档,并且按照(年薪+奖金)之和降序排序
q=*:*&
sort=sum(product(emp_sal,12),if(exists(emp_comm),emp_comm,0)) desc
3.2.2.1.4 使用函数影响相关度排序(了解)
之前在讲解查询的时候,我们说的相关度排序,Lucene底层会根据查询的词和文档关系进行相关度打分。
打分高的文档排在前面,打分低的排在后面。打分的2个指标tf,df;
使用函数可以影响相关度排序。
需求:查询emp_cv中包含董事长的员工,年薪高的员工相关度打分高一点。
q=emp_cv:董事长
AND _val_:"product(emp_sal,12)" #用来影响相关度排序,不会影响查询结果
可以简单这么理解
lucene本身对查询文档有一个打分叫score,每个文档分数可能不同。
通过函数干预后,打分score += 函数计算结果
_val_:规定
另外一种写法:
AND _query_:"{!func}product(emp_sal,12)"
3.2.2.1.5 Solr内置函数和自定义函数
常用内置函数
| 函数 | 说明 | 举例 |
|---|---|---|
| abs(x) | 返回绝对值 | abs(-5) |
| def(field,value) | 获取指定域中值,如果文档没有指定域,使用value作为默认值; | def(emp_comm,0) |
| div(x,y) | 除法,x除以y | div(1,5) |
| dist | 计算两点之间的距离 | dis(2,x,y,0,0) |
| docfreq(field,val) | 返回某值在某域出现的次数 | docfreq(title,’solr’) |
| field(field) | 返回该field的索引数量 | field(‘title’) |
| hsin | 曲面圆弧上两点之间的距离 | hsin(2,true,x,y,0,0) |
| idf | Inverse document frequency 倒排文档频率 | idf(field,’solr’) |
| if | if(test,value1,value2) | if(termfreq(title,’solr’),popularity,42) |
| linear(x,m,c) | 就是m*x+c,等同于sum(product(m,x),c) | linear(1,2,4)=1x2+4=6 |
| log(x) | 以10为底,x的对数 | log(sum(x,100)) |
| map(x,min,max,target) | 如果x在min和max之间,x=target,否则x=x | map(x,0,0,1) |
| max(x,y,…) | 返回最大值 | max(2,3,0) |
| maxdoc | 返回索引的个数,查看有多少文档,包括被标记为删除状态的文档 | maxdoc() |
| min(x,y,…) | 返回最小值 | min(2,4,0) |
| ms | 返回两个参数间毫秒级的差别 | ms(datefield1,2000-01-01T00:00:00Z) |
| norm(field) | 返回该字段索引值的范数 | norm(title) |
| numdocs | 返回索引的个数,查看有多少文档,不包括被标记为删除状态的文档 | numdocs() |
| ord | 根据顺序索引发货结果 | ord(title) |
| pow(x,y) | 返回x的y次方 | pow(x,log(y)) |
| product(x,y) | 返回多个值得乘积 | product(x,2) |
| query | 返回给定的子查询的得分,或者文档不匹配的默认值值 | query(subquery,default) |
| recip(x,m,a,b) | 相当于a/(m*x+b),a,m,b是常量,x是变量 | recip(myfield,m,a,b) |
| rord | 按ord的结果反序返回 | |
| scale | 返回一个在最大值和最小值之间的值 | scale(x,1,3) |
| sqedist | 平方欧氏距离计算 | sqedist(x_td,y_td,0,0) |
| sqrt | 返回指定值得平方根 | sqrt(x)sqrt(100) |
| strdist | 计算两个字符串之间的距离 | strdist(“SOLR”,id,edit) |
| sub | 返回x-y | sub(field1,field2) |
| sum(x,y) | 返回指定值的和 | sum(x,y,…) |
| sumtotaltermfreq | 返回所有totaltermfreq的和 | |
| termfreq | 词出现的次数 | termfreq(title,’sorl’) |
| tf | 词频 | tf(text,’solr’) |
| top | 功能类似于ord | |
| totaltermfreq | 返回这个词在该字段出现的次数 | ttf(title,’memory’) |
| and | 返回true值当且仅当它的所有操作为true | and(not(exists(popularity)),exists(price)) |
| or | 返回true值当有一个操作为true | or(value1,value2) |
| xor | 返回false值如果所有操作都为真 | xor(field1,field2) |
| not | 排除操作 | not(exists(title)) |
| exists | 如果字段存在返回真 | exists(title) |
| gt,gte,lt,lte,eq | 比较函数 | 2 gt 1 |
自定义函数
自定义函数流程:
准备:
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-core</artifactId>
<version>7.7.2</version>
</dependency>
1.定义一个类继承 ValueSource 类,用于封装函数执行结果。
2.定义一个类继承ValueSourceParser,用来解析函数调用语法,并且可以解析参数类型,以及返回指定结果。
3. 在solrconfig.xml中配置文件中配置ValueSourceParser实现类的全类名
需求:定义一个solr字符串拼接的函数,将来函数的调用语法concat(域1,域2),完成字符串拼接。
第一步:
/**
* 用来解析函数调用语法,并且将解析的参数返回给第一个类处理。
* concat(field1,field2)
*/
public class ConcatValueSourceParser extends ValueSourceParser {
//对函数调用语法进行解析,获取参数,将参数封装到ValueSource,返回函数执行结果
public ValueSource parse(FunctionQParser functionQParser) throws SyntaxError {
//1.获取函数调用参数,由于参数类型可能是字符串,int类型,域名,所以封装成ValueSource
//1.1获取第一个参数封装对象
ValueSource arg1 = functionQParser.parseValueSource();
//1.2获取第二个参数封装对象
ValueSource arg2 = functionQParser.parseValueSource();
//返回函数执行结果
return new ConcatValueSource(arg1, arg2);
}
}
第二步:
public class ConcatValueSource extends ValueSource {
//使用构造方法接收ConcatValueSourceParser解析获取的参数
private ValueSource arg1;
private ValueSource arg2;
public ConcatValueSource(ValueSource arg1, ValueSource arg2) {
this.arg1 = arg1;
this.arg2 = arg2;
}
//返回arg1和arg2计算结果
public FunctionValues getValues(Map map, LeafReaderContext leafReaderContext) throws IOException {
FunctionValues values1 = arg1.getValues(map, leafReaderContext); //第一个参数
FunctionValues values2 = arg1.getValues(map, leafReaderContext); //第二个参数
//返回一个字符串的结果
return new StrDocValues(this) {
@Override
public String strVal(int doc) throws IOException {
//根据参数从文档中获取值
return values1.strVal(doc) + values2.strVal(doc);
}
};
}
第三步:在solrconfig.xml配置
<valueSourceParser name="concat" class="cn.itcast.funcation.ConcatValueSourceParser" />
第四步:打包,并且在solr/WEB-INF/lib 目录中配置
第五步:测试
fl=*,concat(id,emp_ename)
3.2 地理位置查询
在Solr中也支持地理位置查询,前提是我们需要将地理位置的信息存储的Solr中,其中地理位置中必须包含一个比较重要的信息,经度和纬度,经度范围[-180,180],纬度范围[-90,90]。对于经度来说东经为正,西经为负,对于纬度来说,北纬正,南纬为负。
3.2.1 数据准备
首先我们先来完成数据准备,需要将地理位置信息存储到Solr中;
1.在MySQL导入地理位置信息
name是地址名称
position:经纬度坐标,中间用,分割(纬度,经度)
2.schema.xml中定义业务域
name域的定义
<field name="address_name" type="text_ik" indexed="true" stored="true"/>
注意:
坐标域定义
域类型location,这域类型就是用来定义地理位置域。
使用location域类型定义的域,底层会被拆分成2个域进行存储,分别是经度和维度。
这个域将来会被拆分成2个域进行存储。
所以需要定义动态域对底层操作进行支持。
<field name="address_position" type="location" indexed="true" stored="true"/>
以下在schema中已经定义好了。
<fieldType name="location" class="solr.LatLonType" subFieldSuffix="_coordinate"/>
<dynamicField name="*_coordinate" type="tdouble" indexed="true" stored="false"/>
3.使用DataImport导入数据
<entity name="address" query="select * from address">
<!-- 每一个field映射着数据库中列与文档中的域,column是数据库列,name是solr的域(必须是在managed-schema文件中配置过的域才行) -->
<field column="id" name="id"/>
<field column="name" name="address_name"/>
<field column="position" name="address_position"/>
</entity>
4.测试
id:主键
address_name:位置名称
address_position:位置坐标
还多出2个域:address_position_0_coordinate ,address_position_1_coordinate 基于动态域生成的维度和经度坐标。
3.2.2 简单地理位置查询
Solr中 提供了一种特殊的查询解析器(geofilt),它能解析以指定坐标(包含经纬度)为中心。 以指定距离(千米)为半径画圆,坐标落在圆面积中的文档,

需求:查询离西安半径 30 千米范围内的城市。
1.查询西安的坐标
address_name:西安

-
查询距离西安30千米范围内的城市
q=*:*& fq={!geofilt sfield=address_position pt=34.27,108.95 d=30}sfiled:指定坐标域
pt:中心
d:半径

除了可以查询落在圆面积中的地址外,对于精确度不高的查询,也可以查询落在外切正方形中的地理位置。
这种方式比圆的方式效率要高。

q=*:*&
ft={!bbox sfield=address_position pt=34.27,108.95 d=30}
-
在solr中还提供了一些计算地理位置的函数,比较常用的函数geodist,该函数可以计算2个地理位置中间的距离。调用方式:geodist(sfield,latitude,longitude);
需求:计算其他城市到北京的距离,作为伪域展示
q=*:*& fl=*,distance:geodist(address_position,39.92,116.46) sort=geodist(address_position,39.92,116.46) asc
3.2.3 地理位置高级查询
之前我们在讲解简单地理位置查询的时候,都是基于正方形或者基于圆进行。有时候我们在进行地理位置查询的时候需要基于其他形状。在Solr中提供了一个类SpatialRecursivePrefixTreeFieldType(RPT)可以完成基于任意多边形查询。

3.2.3.1对地理数据进行重写索引
1.修改address_position域类型
之前的域定义,域类型location
<field name="address_position" type="location" indexed="true" stored="true"/>
修改后的域定义,域类型location_rpt
<field name="address_position" type="location_rpt" indexed="true" stored="true" multiValued="true"/>
location_rpt类型是schema文件已经提供好的一个类型,class就是RPT
<fieldType name="location_rpt" class="solr.SpatialRecursivePrefixTreeFieldType"
spatialContextFactory="JTS"
geo="true" distErrPct="0.025" maxDistErr="0.001" distanceUnits="kilometers" />
-
location_rpt类型,允许存储的数据格式。
点:
纬度 经度 纬度,经度 任意形状
POLYGON((坐标1,坐标2....))将来我们可以查询一个点,或者任意形状是否在另外一个几何图形中。
3. 复制jst的jar包到solr/WEB-INF/classes目录
<dependency>
<groupId>org.locationtech.jts</groupId>
<artifactId>jts-core</artifactId>
<version>1.16.1</version>
</dependency>
jst:用于构建图形的jar包
-
插入测试数据,address_position域中存储的是一个几何图形
insert into address values(8989,'三角形任意形状','POLYGON((108.94224 35.167441,108.776664 34.788863,109.107815 34.80404,108.94224 35.167441))');

- 使用DataImport重新进行索引
3.2.3.2 基于任意图形进行查询
查询基于A,B,C,D这4个点围城的图形有哪些城市。

可以使用百度地图的坐标拾取得知A,B,C,D四个点的坐标。
拾取坐标系统
A 109.034226,35.574317
B 111.315491,33.719499
C108.243142,33.117791
D 107.98558,34.37802
利用ABCD四个点构建几个图形,查询地理坐标在该几何图形中的文档。
address_position:"Intersects(POLYGON((109.034226 35.574317,
111.315491 33.719499,
108.243142 33.117791,
107.98558 34.37802,
109.034226 35.574317)))"
说明:
POLYGON是JST中提供的构建任意多边形的语法。
每个坐标之间使用,进行分割。
经度和纬度之间使用空格隔开
如果构建的是一个封闭图形,最后一个坐标要和第一个坐标相同。
Intersects是一个操作符
作用:匹配2个图形相交部分的文档。
IsWithin
作用:匹配包含在指定图形面积之内的文档,不含边界
Contains:
作用:匹配包含在指定图形面积之内的文档,含边界
3.3 JSON Facet
在Solr中对于Facet查询提供了另外一种查询格式。称为JSON Facet。使用JSON Fact有很多好处,书写灵活,便于自定义响应结果,便于使用分组统计函数等。
3.3.1 JSON Facet 入门
根据商品分类,分组统计每个分类对应的商品数量,要求显示前3个。
传统的Facet查询
q=*:*&
facet=true&
facet.field=item_category&
facet.limit=3
JSON Facet
q=*:*&
json.facet={
category:{
type:terms,
field:item_category,
limit:3
}
}
测试
http://localhost:8080/solr/collection1/select?q=*:*&json.facet=%7Bcategory:%7Btype:terms,field:item_category,limit:3%7D%7D
其中category是自定义的一个键。
type:指的是facet的类型
field:分组统计的域

3.3.2 JSON Facet的语法
json.facet = {
<facet_name>:{
type:<fact_type>,
<other_facet_parameter>
}
}
facet_name:可以任意取值,是为了将来解析结果使用。
type:取值terms,query,range.
terms根据域进行Facet查询,query根据查询解决进行facet查询。range根据范围进行facet查询。
other_facet_parameter:其他facet的一些参数。
根据上面的语法,再来完成一个需求
需求:分组统计2015年每月添加的商品数量。
q=*:*,
json.facet={
month_count:{
type:range,
field:item_createtime,
start:'2015-01-01T00:00:00Z',
end:'2016-01-01T00:00:00Z',
gap:'+1MONTH'
}
}
http://localhost:8080/solr/collection1/select?q=*:*&json.facet=%7B
month_count:%7B
type:range,
field:item_createtime,
start:'2015-01-01T00:00:00Z',
end:'2016-01-01T00:00:00Z',
gap:'%2B1MONTH'
%7D
%7D

需求:统计品牌是华为的商品数量,分类是平板电视的商品数量。
q=*:*,
json.facet={
brand_count:{
type:query,
q:"item_brand:华为"
},
category_count:{
type:query,
q:"item_category:平板电视"
}
}
http://localhost:8080/solr/collection1/select?q=*:*&json.facet=%7B
brand_count:%7B
type:query,
q:"item_brand:华为"
%7D,
category_count:%7B
type:query,
q:"item_category:平板电视"
%7D
%7D
3.3.3 SubFacet
在JSON Facet中,还支持另外一种Facet查询,叫SubFacet.允许用户在之前分组统计的基础上,再次进行分组统计,可以实现pivot Facet(多维度分组查询功能)查询的功能。
需求:对商品的数据,按照品牌进行分组统计,获取前5个分组数据。
q=*:*&
json.facet={
top_brand:{
type:terms,
field:item_brand,
limit:5
}
}
http://localhost:8080/solr/collection1/select?q=*:*&
json.facet=%7B
top_brand:%7B
type:terms,
field:item_brand,
limit:5
%7D
%7D

在以上分组的基础上,统计每个品牌,不同商品分类的数据。eg:统计三星手机多少个,三星平板电视多少?
q=*:*&
json.facet={
top_brand:{
type:terms,
field:item_brand,
limit:5,
facet:{
top_category:{
type:terms,
field:item_category,
limit:3
}
}
}
}
http://localhost:8080/solr/collection1/select?q=*:*&
json.facet=%7B
top_brand:%7B
type:terms,
field:item_brand,
limit:5,
facet:%7B
top_category:%7B
type:terms,
field:item_category,
limit:3
%7D
%7D
%7D
%7D

3.3.4 聚合函数查询
在JSON Facet中,还支持另外一种强大的查询功能,聚合函数查询。在Facet中也提供了很多聚合函数,也成为Facet函数。很多和SQL中的聚合函数类似。
函数如下:
| 聚合函数 | 例子 | 描述 |
|---|---|---|
| sum | sum(sales) | 聚合求和 |
| avg | avg(popularity) | 聚合求平均值 |
| min | min(salary) | 最小值 |
| max | max(mul(price,popularity)) | 最大值 |
| unique | unique(author) | 统计域中唯一值的个数 |
| sumsq | sumsq(rent) | 平方和 |
| percentile | percentile(salary,30,60,10) | 可以根据百分比进行统计 |
需求:查询华为手机价格最大值,最小值,平均值.
q=item_title:手机
&fq=item_brand:华为
&json.facet={
avg_price:"avg(item_price)",
min_price:"min(item_price)",
max_price:"max(item_price)"
}
http://localhost:8080/solr/collection1/select?q=item_title:手机
&fq=item_brand:华为
&json.facet=%7B
avg_price:"avg(item_price)",
min_price:"min(item_price)",
max_price:"max(item_price)"
%7D
查询结果:
需求:查询每个品牌下,最高的手机的价格.
q=item_title:手机
&json.facet={
categories:{
type:terms,
field:item_brand,
facet:{
x : "max(item_price)"
}
}
}
http://localhost:8080/solr/collection1/select?q=item_title:手机&json.facet=%7Bcategories:%7Btype:field,field:item_brand,facet:%7Bx:"max(item_price)"%7D%7D%7D
结果:
1.1 facet查询
之前我们讲解Facet查询,我们说他是分为4类。
Field,Query,Range(时间范围,数字范围),Interval(和Range类似)
1.1.2 基于Field的Facet查询
需求:对item_title中包含手机的文档,按照品牌域进行分组,并且统计数量;
http://localhost:8080/solr/collection1/select?q=item_title:手机&facet=on&facet.field=item_brand&facet.mincount=1
@Test
public void testFacetFieldQuery() throws IOException, SolrServerException {
//http://localhost:8080/solr/collection1/select?q=item_title:手机&facet=on&facet.field=item_brand&facet.mincount=1
SolrQuery query=new SolrQuery();
//查询条件
query.setQuery("item_title:手机");
//Facet相关参数
query.setFacet(true);
query.addFacetField("item_brand");
query.setFacetMinCount(1);
QueryResponse response = httpSolrClient.query(query);
FacetField facetField = response.getFacetField("item_brand");
List<FacetField.Count> valueList = facetField.getValues();
valueList.stream().forEach(System.out::println);
}
1.1.3 基于Query的Facet查询
需求:查询分类是平板电视的商品数量 ,品牌是华为的商品数量 ,品牌是三星的商品数量,价格在1000-2000的商品数量;
http://localhost:8080/solr/collection1/select?
q=*:*&
facet=on&
facet.query=item_category:平板电视&
facet.query=item_brand:华为&
facet.query=item_brand:三星&
facet.query=item_price:%5B1000 TO 2000%5D
@Test
public void testFacetFieldQuery()throws IOException, SolrServerException {
//http://localhost:8080/solr/collection1/select?
//q=*:*&
//facet=on&
//facet.query=item_category:平板电视&
//facet.query=item_brand:华为&
//facet.query=item_brand:三星&
//facet.query=item_price:%5B1000 TO 2000%5D
SolrQuery query=new SolrQuery();
//查询条件
query.setQuery("*:*");
//Facet相关参数
query.setFacet(true);
//query.addFacetQuery("item_category:平板电视");
//query.addFacetQuery("item_brand:华为");
//query.addFacetQuery("item_brand:三星");
//query.addFacetQuery("item_price:[1000 TO 2000]");
//起别名
query.addFacetQuery("{!key=平板电视}item_category:平板电视");
query.addFacetQuery("{!key=华为品牌}item_brand:华为");
query.addFacetQuery("{!key=三星品牌}item_brand:三星");
query.addFacetQuery("{!key=1000到2000}item_price:[1000 TO 2000]");
QueryResponse response = httpSolrClient.query(query);
Map<String, Integer> facetQuery = response.getFacetQuery();
for (String key : facetQuery.keySet()) {
System.out.println(key+"--"+facetQuery.get(key));
}
}
1.1.4 基于Range的Facet查询
需求:分组查询价格0-2000 ,2000-4000,4000-6000....18000-20000每个区间商品数量
q=*:*&
facet=on&
facet.range=item_price&
facet.range.start=0&
facet.range.end=20000&
facet.range.gap=2000
@Test
public void testFacetFieldQuery()throws IOException, SolrServerException {
//http://localhost:8080/solr/collection1/select?
//q=*:*&
//facet=on&
//facet.range=item_price&
//facet.range.start=0&
//facet.range.end=20000&
//facet.range.gap=2000
SolrQuery query=new SolrQuery();
//查询条件
query.setQuery("*:*");
//Facet相关参数
query.setFacet(true);
query.addNumericRangeFacet("item_price",0,20000,2000);
QueryResponse response = httpSolrClient.query(query);
List<RangeFacet> facetRanges = response.getFacetRanges();
for (RangeFacet facetRange : facetRanges) {
System.out.println(facetRange.getName());
List<RangeFacet.Count> counts = facetRange.getCounts();
for (RangeFacet.Count count : counts) {
System.out.println(count.getValue()+"---"+count.getCount());
}
}
}
需求:统计2015年每个季度添加的商品数量
http://localhost:8080/solr/collection1/select?
q=*:*&
facet=on&
facet.range=item_createtime&
facet.range.start=2015-01-01T00:00:00Z&
facet.range.end=2016-01-01T00:00:00Z&
facet.range.gap=%2B3MONTH
@Test
public void testFacetFieldQuery() throws IOException, SolrServerException, ParseException {
//http://localhost:8080/solr/collection1/select?
//q=*:*&
//facet=on&
//facet.range=item_createtime&
//facet.range.start=2015-01-01T00:00:00Z&
//facet.range.end=2016-01-01T00:00:00Z&
//facet.range.gap=%2B3MONTH
SolrQuery query=new SolrQuery();
//查询条件
query.setQuery("*:*");
//Facet相关参数
query.setFacet(true);
Date start = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse("2015-01-01 00:00:00");
Date end = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse("2016-01-01 00:00:00");
query.addDateRangeFacet("item_createtime",start,end,"+3MONTH");
QueryResponse response = httpSolrClient.query(query);
List<RangeFacet> facetRanges = response.getFacetRanges();
for (RangeFacet facetRange : facetRanges) {
System.out.println(facetRange.getName());
List<RangeFacet.Count> counts = facetRange.getCounts();
for (RangeFacet.Count count : counts) {
System.out.println(count.getValue()+"---"+count.getCount());
}
}
}
1.1.5 基于Interval的Facet查询
需求:统计item_price在0-1000和0-100商品数量和item_createtime是2019年~现在添加的商品数量
&facet=on
&facet.interval=item_price
&f.item_price.facet.interval.set=[0,1000]
&f.item_price.facet.interval.set=[0,100]
&facet.interval=item_createtime
&f.item_createtime.facet.interval.set=[2019-01-01T0:0:0Z,NOW]
由于有特殊符号需要进行URL编码[---->%5B ]---->%5D
http://localhost:8080/solr/collection1/select?q=*:*&facet=on&facet.interval=item_price&f.item_price.facet.interval.set=%5B0,1000%5D&f.item_price.facet.interval.set=%5B0,100%5D&facet.interval=item_createtime&f.item_createtime.facet.interval.set=%5B2019-01-01T0:0:0Z,NOW%5D
@Test
public void testFacetFieldQuery() throws IOException, SolrServerException, ParseException {
//&facet=on
//&facet.interval=item_price
//&f.item_price.facet.interval.set=[0,1000]
//&f.item_price.facet.interval.set=[0,100]
//&facet.interval=item_createtime
//&f.item_createtime.facet.interval.set=[2019-01-01T0:0:0Z,NOW]
SolrQuery query=new SolrQuery();
//查询条件
query.setQuery("*:*");
//Facet相关参数
query.setFacet(true);
query.addIntervalFacets("item_price", new String[]{"[0,10]"});
query.addIntervalFacets("item_createtime", new String[]{"[2019-01-01T0:0:0Z,NOW]"});
QueryResponse response = httpSolrClient.query(query);
/*
item_price: {
[0,10]: 11
},
item_createtime: {
[2019-01-01T0:0:0Z,NOW]: 22
}
*/
List<IntervalFacet> intervalFacets = response.getIntervalFacets();
for (IntervalFacet intervalFacet : intervalFacets) {
String field = intervalFacet.getField();
System.out.println(field);
List<IntervalFacet.Count> intervals = intervalFacet.getIntervals();
for (IntervalFacet.Count interval : intervals) {
System.out.println(interval.getKey());
System.out.println(interval.getCount());
}
}
}
1.1.6 Facet维度查询
需求:统计每一个品牌和其不同分类商品对应的数量;
联想 手机 10
联想 电脑 2
华为 手机 10
...
http://localhost:8080/solr/collection1/select?q=*:*&
&facet=on
&facet.pivot=item_brand,item_category
@Test
public void testFacetFieldQuery() throws IOException, SolrServerException, ParseException {
// http://localhost:8080/solr/collection1/select?q=*:*&
// &facet=on
// &facet.pivot=item_brand,item_category
SolrQuery query=new SolrQuery();
//查询条件
query.setQuery("*:*");
//Facet相关参数
query.setFacet(true);
query.addFacetPivotField("item_brand,item_category");
QueryResponse response = httpSolrClient.query(query);
NamedList<List<PivotField>> facetPivot = response.getFacetPivot();
List<PivotField> pivotFields = facetPivot.get("item_brand,item_category");
for (PivotField pivotField : pivotFields) {
String field = pivotField.getField();
Object value = pivotField.getValue();
int count = pivotField.getCount();
System.out.println(field+"-"+value+"-"+count);
List<PivotField> fieldList = pivotField.getPivot();
for (PivotField pivotField1 : fieldList) {
String field1 = pivotField1.getField();
Object value1 = pivotField1.getValue();
int count1 = pivotField1.getCount();
System.out.println(field1+"-"+value1+"-"+count1);
}
}
}
到这关于SolrJ和Facet查询相关的操作就讲解完毕。
1.2 group查询
1.2.1 基础的分组
需求:查询Item_title中包含手机的文档,按照品牌对文档进行分组;同组中的文档放在一起。
http://localhost:8080/solr/collection1/select?
q=item_title:手机
&group=true
&group.field=item_brand
@Test
public void testGroupQuery() throws IOException, SolrServerException, ParseException {
SolrQuery params = new SolrQuery();
params.setQuery("item_title:手机");
/**
* q=item_title:手机
* &group=true
* &group.field=item_brand
*/
//注意solrJ中每没有提供分组特有API。需要使用set方法完成
params.setGetFieldStatistics(true);
params.set(GroupParams.GROUP, true);
params.set(GroupParams.GROUP_FIELD,"item_brand");
QueryResponse response = httpSolrClient.query(params);
GroupResponse groupResponse = response.getGroupResponse();
//由于分组的字段可以是多个。所以返回数组
List<GroupCommand> values = groupResponse.getValues();
//获取品牌分组结果
GroupCommand groupCommand = values.get(0);
//匹配到的文档数量
int matches = groupCommand.getMatches();
System.out.println(matches);
//每个组合每个组中的文档信息
List<Group> groups = groupCommand.getValues();
for (Group group : groups) {
//分组名称
System.out.println(group.getGroupValue());
//组内文档
SolrDocumentList result = group.getResult();
System.out.println(group.getGroupValue() +":文档个数" + result.getNumFound());
for (SolrDocument entries : result) {
System.out.println(entries);
}
}
}
1.2.2 group分页
默认情况下分组结果中只会展示前10个组,并且每组展示相关对最高的1个文档。我们可以使用start和rows可以设置组的分页,使用group.limit和group.offset设置组内文档分页。
q=item_title:手机&group=true&group.field=item_brand&start=0&rows=3
&group.limit=5&group.offset=0
展示前3个组及每组前5个文档。
//设置组的分页参数
params.setStart(0);
params.setRows(3);
//设置组内文档的分页参数
params.set(GroupParams.GROUP_OFFSET, 0);
params.set(GroupParams.GROUP_LIMIT, 5);
1.2.3 group排序
之前讲解排序的时候,group排序分为组排序,组内文档排序;对应的参数为sort和group.sort
需求:按照组内价格排序降序;
params.set(GroupParams.GROUP_SORT, "item_price desc");
当然分组还有其他的用法,都是大同小异,大家可以参考我们之前讲解分组的知识;
1.3 高亮
1.3.1 高亮查询
查询item_title中包含手机的文档,并且对item_title中的手机关键字进行高亮;
http://localhost:8080/solr/collection1/select?
q=item_title:手机
&hl=true
&hl.fl=item_title
&hl.simple.pre=<font>
&h1.simple.post=</font>
@Test
public void testHighlightingQuery() throws IOException, SolrServerException {
SolrQuery params = new SolrQuery();
params.setQuery("item_title:三星手机");
//开启高亮
params.setHighlight(true);
//设置高亮域
//高亮的前后缀
params.addHighlightField("item_title");
params.setHighlightSimplePre("<font>");
params.setHighlightSimplePost("</font>");
QueryResponse response = httpSolrClient.query(params);
SolrDocumentList results = response.getResults();
for (SolrDocument result : results) {
System.out.println(result);
}
//解析高亮
Map<String, Map<String, List<String>>> highlighting = response.getHighlighting();
//map的key是文档id,map的value包含高亮的数据
for (String id : highlighting.keySet()) {
System.out.println(id);
/**
* item_title: [
* "飞利浦 老人<em>手机</em> (X2560) 深情蓝 移动联通2G<em>手机</em> 双卡双待"
* ]
*/
Map<String, List<String>> highLightData = highlighting.get(id);
//highLightData key包含高亮域名
//获取包含高亮的数据
if(highLightData != null && highLightData.size() > 0) {
//[
// * "飞利浦 老人<em>手机</em> (X2560) 深情蓝 移动联通2G<em>手机</em> 双卡双待"
// * ]
List<String> stringList = highLightData.get("item_title");
if(stringList != null && stringList.size() >0) {
String title = stringList.get(0);
System.out.println(title);
}
}
}
//将高亮的数据替换到原有文档中。
}
1.3.2 高亮器的切换
当然我们也可以使用SolrJ完成高亮器的切换。之前我们讲解过一个高亮器fastVector,可以实现域中不同的词使用不同颜色。
查询item_title中包含三星手机的文档.item_title中三星手机中不同的词,显示不同的颜色;
http://localhost:8080/solr/collection1/select?
q=item_title:三星手机
&hl=true
&hl.fl=item_title
&hl.method=fastVector
SolrQuery params = new SolrQuery();
params.setQuery("item_title:三星手机");
//开启高亮
params.setHighlight(true);
params.addHighlightField("item_title");
params.set("hl.method","fastVector");
QueryResponse response = httpSolrClient.query(params);
到这使用SolrJ进行高亮查询就讲解完毕。
1.4 suggest查询
1.4.1 spell-checking 拼写检查。
需求:查询item_title中包含iphone的内容。要求进行拼写检查。
http://localhost:8080/solr/collection1/select?
q=item_title:iphonx&spellcheck=true
@Test
public void test01() throws IOException, SolrServerException {
SolrQuery params = new SolrQuery();
params.setQuery("item_title:iphonxx");
params.set("spellcheck",true);
QueryResponse response = httpSolrClient.query(params);
/**
* suggestions: [
* "iphonxx",
* {
* numFound: 1,
* startOffset: 11,
* endOffset: 18,
* suggestion: [
* "iphone6"
* ]
* }
* ]
*/
SpellCheckResponse spellCheckResponse = response.getSpellCheckResponse();
Map<String, SpellCheckResponse.Suggestion> suggestionMap = spellCheckResponse.getSuggestionMap();
for (String s : suggestionMap.keySet()) {
//错误的词
System.out.println(s);
//建议的词
SpellCheckResponse.Suggestion suggestion = suggestionMap.get(s);
List<String> alternatives = suggestion.getAlternatives();
System.out.println(alternatives);
}
}
1.4.2Auto Suggest自动建议。
上面我们讲解完毕拼写检查,下面我们讲解自动建议,自动建议也是需要在SolrConfig.xml中进行相关的配置。
需求:查询三星,要求基于item_title域进行自动建议
http://localhost:8080/solr/collection1/select?
q=三星&suggest=true&suggest.dictionary=mySuggester&suggest.count=5
@Test
public void test02() throws IOException, SolrServerException {
SolrQuery params = new SolrQuery();
//设置参数
params.setQuery("java");
//开启自动建议
params.set("suggest",true);
//指定自动建议的组件
params.set("suggest.dictionary","mySuggester");
QueryResponse response = httpSolrClient.query(params);
SuggesterResponse suggesterResponse = response.getSuggesterResponse();
Map<String, List<Suggestion>> suggestions = suggesterResponse.getSuggestions();
for (String key : suggestions.keySet()) {
//词
System.out.println(key);
List<Suggestion> suggestionList = suggestions.get(key);
for (Suggestion suggestion : suggestionList) {
String term = suggestion.getTerm();
System.out.println(term);
}
}
}
1.5 使用SolrJ完成Core的管理
1.5.1 Core添加
1.要想完成SolrCore的添加,在solr_home必须提前创建好SolrCore的目录结构,而且必须包相关的配置文件。
修改配置文件中url:http://localhost:8080/solr
CoreAdminRequest.createCore("collection4", "D:\\solr_home\\collection4", solrClient );
1.5.2 重新加载Core
从Solr中移除掉,然后在添加。
CoreAdminRequest.reloadCore("collection4", solrClient );
1.5.3 重命名Core
CoreAdminRequest.renameCore("collection4","newCore" , solrClient)
1.5.4 卸载solrCore
卸载仅仅是从Solr中将该Core移除,但是SolrCore的物理文件依然存在
CoreAdminRequest.unloadCore("collection4", solrClient );
1.5.5 solrCore swap
CoreAdminRequest.swapCore("collection1", "collection4", solrClient);
2. Solr集群搭建
2.1 SolrCloud简介
2.1.1 什么是SolrCloud
Solr集群也成为SolrCloud,是Solr提供的分布式搜索的解决方案,当你需要大规模存储数据或者需要分布式索引和检索能力时使用 SolrCloud。
所有数据库集群,都是为了解决4个核心个问题,单点故障,数据扩容,高并发,效率
搭建SolrCloud是需要依赖一个中间件Zookeeper,它的主要思想是使用Zookeeper作为集群的配置中心。
2.1.2 SolrCloud架构
SolrCloud逻辑概念:
一个Solr集群是由多个collection组成,collection不是SolrCore只是一个逻辑概念。一个collection是由多个文档组成,这些文档归属于指定的分片。下面表示的就是一个逻辑结构图。
该集群只有一个collection组成。connection中的文档数据分散在4个分片。
分片中的数据,到底存储在那呢?这就属于物理概念。
SolrCloud物理概念:
Solr 集群由一个或多个 Solr服务(tomcat中运行solr服务)组成,这些Solr服务可以部署一台服务器上,也可以在多台服务器。每个Solr服务可以包含一个或者多个Solr Core 。SolrCore中存储的是Shard的数据;
下面的图是一个物理结构和逻辑结构图。
概念:
Collection是一个逻辑概念,可以认为是多个文档构成的一个集合。
Shard是一个逻辑概念,是对Collection进行逻辑上的划分。
Replica:Shard的一个副本,一个Shard有多个副本,同一个Shard副本中的数据一样;
Leader:每个Shard会以多个Replica的形式存在,其中一个Replica会被选为Leader,负责集群环境中的索引和搜索。
SolrCore:存储分片数据的基本单元。一个SolrCore只存储一个分片数据,一个分片数据可以存储到多个SolrCore中;一个SolrCore对应一个Replica
Node:集群中的一个Solr服务
2.2 Linux集群搭建
2.2.1 基于tomcat的集群搭建
2.2.1.1集群架构介绍
物理上:
搭建三个Zookeeper组成集群,管理SolrCloud。
搭建四个Solr服务,每个Solr服务一个SorCore.
逻辑上:
整个SolrCloud一个Connection;
Connection中的数据分为2个Shard;
Shard1的数据在物理上存储到solr1和solr2的SolrCore
Shard2的数据在物理上存储到solr3和solr4的SolrCore
2.2.1.2 环境说明
环境和我们之前搭建单机版的环境相同。
| 系统 | 版本 |
|---|---|
| Linux | CentOS 7 |
| JDK | JDK8 |
| Tomcat | tomcat 8.5 |
| zookeeper | zookeeper-3.4.14 |
| solr | solr 7.7.2 |
2.2.1.3 Zookeeper集群搭建
首先我们先要完成Zookeeper集群搭建。在搭建集群之前,首先我们先来说一下Zookeeper集群中要求节点的个数。
在Zookeeper集群中节点的类型主要有2类,Leader,Follower,一个集群只有一个Leader。
到底谁是Leader呢?
投票选举制度:集群中所有的节点来进行投票,半数以上获票的节点就是Leader.Zookeeper要求集群节点个数奇数。
容错:zookeeper集群一大特性是只要集群中半数以上的节点存活,集群就可以正常提供服务,而2n+1节点和2n+2个节点的容错能力相同,都是允许n台节点宕机。本着节约的宗旨,一般选择部署2n+1台机器
本次我们采用最少的集群节点3个。
1.下载Zookeeper的安装包到linux。
下载地址:
http://archive.apache.org/dist/zookeeper/zookeeper-3.4.14/
上面的地址可能受每日访问量现在
wget
https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz
2. 解压zookeeper, 复制三份到/usr/local/solrcloud下,复制三份分别并将目录名改为zk01、在zk02、zk03
mkdir /usr/local/solrcloud
tar -xzvf zookeeper-3.4.14.tar.gz
cp -r zookeeper-3.4.14 /usr/local/solrcloud/zk01
cp -r zookeeper-3.4.14 /usr/local/solrcloud/zk02
cp -r zookeeper-3.4.14 /usr/local/solrcloud/zk03
结果
-
为每一个Zookeeper创建数据目录
mkdir zk01/data mkdir zk02/data mkdir zk03/data
-
在data目录中为每一个Zookeeper创建myid文件,并且在文件中指定该Zookeeper的id;
使用重定向指令>>将打印在控制台上的1 2 3分别写入到data目录的myid文件中。 echo 1 >> zk01/data/myid echo 2 >> zk02/data/myid echo 3 >> zk03/data/myid
-
修改Zookeeper的配置文件名称。
5.1 需要将每个zookeeper/conf目录中的zoo_sample.cfg 文件名改名为zoo.cfg,否则该配置文件不起作用。
mv zk01/conf/zoo_sample.cfg zk01/conf/zoo.cfg mv zk02/conf/zoo_sample.cfg zk02/conf/zoo.cfg mv zk03/conf/zoo_sample.cfg zk03/conf/zoo.cfg
6. 编辑zoo.cfg配置文件
5.1 修改Zookeeper客户端连接的端口,Zookeeper对外提供服务的端口。修改目的,我们需要在一台计算机上启动三个Zookeeper。
clientPort=2181
clientPort=2182
clientPort=2183
5.2 修改数据目录
dataDir=/usr/local/solrcloud/zk01/data
dataDir=/usr/local/solrcloud/zk02/data
dataDir=/usr/local/solrcloud/zk03/data
5.3 在每一个配置文件的尾部加入,指定集群中每一个Zookeeper的节点信息。
server.1=192.168.200.128:2881:3881
server.2=192.168.200.128:2882:3882
server.3=192.168.200.128:2883:3883
server.1 server.2 server.3 指定Zookeeper节点的id.之前我们myid已经指定了每个节点的id;
内部通信端口:
Zookeeper集群节点相互通信端口;
为什么会有投票端口呢?
1.因为三台Zookeeper要构成集群,决定谁是leader,Zookeeper中是通过投票机制决定谁是leader。
2.如果有节点产生宕机,也需要通过投票机制将宕机节点从集群中剔除。
所以会有一个投票端口
7.启动Zookeeper集群。
在bin目录中提供了一个脚本zkServer.sh,使用zkServer.sh start|restart|stop|status 就可以完成启动,重启,停止,查看状态。
可以写一个脚本性启动所有Zookeeper。也可以一个个的启动;
./zk01/bin/zkServer.sh start
./zk02/bin/zkServer.sh start
./zk03/bin/zkServer.sh start
8.查看Zookeeper集群状态。
./zk01/bin/zkServer.sh status
./zk02/bin/zkServer.sh status
./zk03/bin/zkServer.sh status
follower就是slave;
leader就是master;
如果是单机版的Zookeeper,standalone
到这关于Zookeeper集群的搭建,我们就讲解完毕。
2.2.1.4 SolrCloud集群部署
上一节我们已经完成了Zookeeper集群的搭建,下面我们来搭建solr集群。
复制4个tomcat,并且要在4个tomcat中部署solr,单机版solr的搭建,我们之前已经讲解过了。
下面是我们已经搭建好的单机版的solr,他的tomcat和solrhome
1.1 将tomcat复制4份到solrcloud中,便于集中管理。这4个tomcat中都部署了solr;
cp -r apache-tomcat-8.5.50 solrcloud/tomcat1
cp -r apache-tomcat-8.5.50 solrcloud/tomcat2
cp -r apache-tomcat-8.5.50 solrcloud/tomcat3
cp -r apache-tomcat-8.5.50 solrcloud/tomcat4
1.2 复制4个solrhome到solrcloud中。分别对应每一个solr的solrhome。
cp -r solr_home solrcloud/solrhome1
cp -r solr_home solrcloud/solrhome2
cp -r solr_home solrcloud/solrhome3
cp -r solr_home solrcloud/solrhome4
1.3 修改tomcat的配置文件,修改tomcat的端口,保证在一台计算机上,可以启动4个tomcat;
编辑server.xml
修改停止端口
对外提供服务端口
AJP端口
<Server port="8005"shutdown="SHUTDOWN">
<Connector port="8080"protocol="HTTP/1.1" connectionTimeout="20000" redirect
<Connector port="8009" protocol="AJP/1.3"redirectPort="8443" />
tomcat1 8105 8180 8109
tomcat1 8205 8280 8209
tomcat1 8305 8380 8309
tomcat1 8405 8480 8409
1.4 为tomcat中每一个solr指定正确的solrhome,目前是单机版solrhome的位置。
编辑solr/web.xml指定对应的solrhome
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>/usr/local/solrcloud/solrhomeX</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>
1.5 修改每个solrhome中solr.xml的集群配置,对应指定tomcat的ip和端口
编辑solrhome中solr.xml
<solrcloud>
<str name="host">192.168.200.1288</str>
<int name="hostPort">8X80</int>
</solrcloud>
2.2.1.5 Zookeeper管理的Solr集群
上一节课我们已经搭建好了Zookeeper集群,和Solr的集群。但是现在Zookeeper集群和Solr集群没有关系。
需要让Zookeeper管理Solr集群。
1.启动所有的tomcat
./tomcat1/bin/startup.sh
./tomcat2/bin/startup.sh
./tomcat3/bin/startup.sh
./tomcat4/bin/startup.sh
2.让每一个solr节点和zookeeper集群关联
编辑每一个tomcat中bin/catalina.sh文件,指定Zookeeper集群地址。
JAVA_OPTS="-DzkHost=192.168.200.128:2181,192.168.200.128:2182,192.168.200.128:2183"
需要指定客户端端口即Zookeeper对外提供服务的端口
3.让zookeeper统一管理solr集群的配置文件。
因为现在我们已经是一个集群,集群中的每个solr节点配置文件需要一致。所以我们就需要让zookeeper管理solr集群的配置文件。主要管理的就是solrconfig.xml / schema.xml文件
下面的命令就是将conf目录中的配置文件,上传到Zookeeper,以后集群中的配置文件就以Zookeeper中的为准;
搭建好集群后,solrCore中是没有配置文件的。
./zkcli.sh -zkhost 192.168.200.128:2181,192.168.200.128:2182,192.168.200.128:2183 -cmd upconfig -confdir /usr/local/solrcloud/solrhome1/collection1/conf -confname myconf
-zkhost:指定zookeeper的地址列表;
upconfig :上传配置文件;
-confdir :指定配置文件所在目录;
-confname:指定上传到zookeeper后的目录名;
进入到solr安装包中
/root/solr-7.7.2/server/scripts/cloud-scripts
./zkcli.sh -zkhost 192.168.200.128:2181,192.168.200.128:2182,192.168.200.128:2183 -cmd upconfig -confdir /usr/local/solrcloud/solrhome1/collection1/conf -confname myconf
./zkcli.sh -zkhost 192.168.200.128:2181,192.168.200.128:2182,192.168.200.128:2183 -cmd upconfig -confdir /root/solr7.7.2/server/solr/configsets/sample_techproducts_configs/conf
-confname myconf
4.查看Zookeeper中的配置文件。
登录到任意一个Zookeeper上,看文件是否上传成功。
进入到任意一个Zookeeper,查看文件的上传状态。
/zKCli.sh -server 192.168.200.128:2182
通过Zookeeper客户端工具查看。idea的Zookeeper插件,ZooInspector等。
- 由于solr的配置文件,已经交由Zookeeper管理。所有SolrHome中的SolrCore就可以删除。
到这Zookeeper集群和Solr集群整合就讲解完毕。
2.2.1.6 创建Solr集群的逻辑结构
之前我们已经搭建好了Zookeeper集群及Solr集群。接下来我们要完成的是逻辑结构的创建。
我们本次搭建的逻辑结构整个SolrCloud是由一个Collection构成。Collection分为2个分片。每个分片有2个副本。分别存储在不同的SolrCore中。
启动所有的tomcat
./tomcat1/bin/startup.sh
./tomcat2/bin/startup.sh
./tomcat3/bin/startup.sh
./tomcat4/bin/startup.sh
访问任4个solr管理后台;
http://192.168.200.131:8180/solr/index.html#/~collections
http://192.168.200.131:8280/solr/index.html#/~collections
http://192.168.200.131:8380/solr/index.html#/~collections
http://192.168.200.131:8480/solr/index.html#/~collections
使用任何一个后台管理系统,创建逻辑结构
name:指定逻辑结构collection名称;
config set:指定使用Zookeeper中配置文件;
numShards:分片格式
replicationFactory:每个分片副本格式;
当然我们也可以通过Solr RestAPI完成上面操作
http://其中一个solr节点的IP:8983/solr/admin/collections?action=CREATE&name=testcore&numShards=2&replicationFactor=2&collection.configName=myconf
查询逻辑结构
查看物理结构
说明一下: 原来SolrCore的名字已经发生改变。
一旦我们搭建好集群后,每个SolrCore中是没有conf目录即没有配置文件。
整个集群的配置文件只有一份,Zookeeper集群中的配置文件。
2.2.1.7测试集群
向collection中添加数据
{id:"100",name:"zhangsan"}
由于整合集群逻辑上就一个collection,所以在任何一个solr节点都可以获取数据。
2.2.1.8 使用SolrJ操作集群
之前我们操作单节点的Solr,使用的是HttpSolrClient,操作集群我们使用的是CloudSolrClient。
- 将CloudSolrClient交由spring管理。
@Bean
public CloudSolrClient cloudSolrClient() {
//指定Zookeeper的地址。
List<String> zkHosts = new ArrayList<>();
zkHosts.add("192.168.200.131:2181");
zkHosts.add("192.168.200.131:2182");
zkHosts.add("192.168.200.131:2183");
//参数2:指定
CloudSolrClient.Builder builder = new CloudSolrClient.Builder(zkHosts,Optional.empty());
CloudSolrClient solrClient = builder.build();
//设置连接超时时间
solrClient.setZkClientTimeout(30000);
solrClient.setZkConnectTimeout(30000);
//设置collection
solrClient.setDefaultCollection("collection");
return solrClient;
}
2.使用CloudSolrClient中提供的API操作Solr集群,和HttpSolrClient相同
索引
@Autowired
private CloudSolrClient cloudSolrClient;
@Test
public void testSolrCloudAddDocument() throws Exception {
SolrInputDocument doc = new SolrInputDocument();
doc.setField("id", 1);
doc.setField("name", "java");
cloudSolrClient.add(doc);
cloudSolrClient.commit();
}
搜索
@Test
public void testSolrQuery() throws Exception {
SolrQuery params = new SolrQuery();
params.setQuery("*:*");
QueryResponse response = cloudSolrClient.query(params);
SolrDocumentList results = response.getResults();
for (SolrDocument result : results) {
System.out.println(result);
}
}
2.2.2 SolrCloud的其他操作
2.2.2.1 SolrCloud使用中文分词器(IK)
1.在每一个solr服务中,引入IK分词器的依赖包
2.在classes中引入停用词和扩展词库及配置文件
3.重启所有的tomcat
4.修改单机版solrcore中schema,加入FiledType
<fieldType name ="text_ik" class ="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
5.将schema重新提交到Zookeeper
Solr集群中的配置文件统一由Zookeeper进行管理,所以如果需要修改配置文件,我们需要将修改的文件上传的Zookeeper。
./zkcli.sh -zkhost 192.168.200.128:2181,192.168.200.128:2182,192.168.200.128:2183 -cmd putfile /configs/myconf/managed-schema /usr/local/solr_home/collection1/conf/managed-schema
6. 测试
7.利用text_ik 创建相关的业务域
创建业务域,我们依然需要修改shema文件,这个时候,我们建议使用后台管理系统。
8.查看schema文件是否被修改。
通过files查看集群中的配置文件,内容
到这关于如何修改集群中的配置文件,已经如何管理Filed我们就讲解完毕。
2.2.2.2 查询指定分片数据
在SolrCloud中,如果我们想查询指定分片的数据也是允许的。
需求:查询shard1分片的数据
http://192.168.200.128:8180/solr/myCollection/select?q=*:*&shards=shard1
需求:查询shard1和shard2分片的数据
http://192.168.200.128:8180/solr/myCollection/select?q=*:*&shards=shard1,shard2
上面的操作都是从根据shard的id随机从shard的副本中获取数据。shard1的数据可能来自8380,8280
shard2的数据可能来自8480,8180
也可以指定具体的副本;
需求:获取shard1分片8280副本中的数据
http://192.168.200.128:8180/solr/myCollection/select?q=*:*&shards=192.168.200.128:8280/solr/myCollection
需求:获取8280和8380副本中数据
http://192.168.200.128:8180/solr/myCollection/select?q=*:*&shards=192.168.200.128:8280/solr/myCollection,192.168.200.128:8380/solr/myCollection
混合使用,通过Shard的ID随机获取+通过副本获取。
http://192.168.200.128:8180/solr/myCollection/select?q=*:*&shards=shard1,192.168.200.128:8380/solr/myCollection
2.2.2.3 SolrCloud并发和线程池相关的一些配置
在SolrCloud中,我们也可以配置Shard并发和线程相关的配置,来优化集群性能。
主要的配置在solr.xml文件。
<solr>
<!--集群相关的配置,solr服务的地址,端口,上下文solr.是否自动生成solrCore名称,zk超时时间-->
<solrcloud>
<str name="host">192.168.200.131</str>
<int name="hostPort">8180</int>
<str name="hostContext">${hostContext:solr}</str>
<bool name="genericCoreNodeNames">${genericCoreNodeNames:true}</bool>
<int name="zkClientTimeout">${zkClientTimeout:30000}</int>
<int name="distribUpdateSoTimeout">${distribUpdateSoTimeout:600000}</int>
<int name="distribUpdateConnTimeout">${distribUpdateConnTimeout:60000}</int>
<str name="zkCredentialsProvider">${zkCredentialsProvider:org.apache.solr.common.cloud.DefaultZkCredentialsProvider}</str>
<str name="zkACLProvider">${zkACLProvider:org.apache.solr.common.cloud.DefaultZkACLProvider}</str>
</solrcloud>
<!-- 分片并发和线程相关的信息-->
<shardHandlerFactory name="shardHandlerFactory"
class="HttpShardHandlerFactory">
<int name="socketTimeout">${socketTimeout:600000}</int>
<int name="connTimeout">${connTimeout:60000}</int>
<str name="shardsWhitelist">${solr.shardsWhitelist:}</str>
</shardHandlerFactory>
</solr>
相关参数
| 参数名 | 描述 | 默认值 |
|---|---|---|
| socketTimeout | 指客户端和服务器建立连接后,客户端从服务器读取数据的timeout | distribUpdateSoTimeout |
| connTimeout | 指客户端和服务器建立连接的timeout | distribUpdateConnTimeout |
| maxConnectionsPerHost | 最大并发数量 | 20 |
| maxConnections | 最大连接数量 | 10000 |
| corePoolSize | 线程池初始化线程数量 | 0 |
| maximumPoolSize | 线程池中线程的最大数量 | Integer.MAX_VALUE |
| maxThreadldleTime | 设置线程在被回收之前空闲的最大时间 | 5秒 |
| sizeOfQueue | 指定此参数 ,那么线程池会使用队列来代替缓冲区,对于追求高吞吐量的系统而 ,可能希望配置为-1 。对于于追求低延迟的系统可能希望配置合理的队列大小来处理请求 。 | -1 |
| fairnessPolicy | 用于选择JVM特定的队列的公平策略:如果启用公平策略,分布式查询会以先进先出的方式来处理请求,但是是是以有损吞吐量为代价;如果禁用公平策略,会提高集群查询吞吐量,但是以响应延迟为代价。 | false |
| useRetries | 是否启 HTTP 连接自动重试机制,避免由 HTTP 连接池 的限制或者竞争导致的 IOException ,默认未开启 | false |
2.3.2 基于docker的集群搭建
2.3.2.1 环境准备
1.搭建docker
要想在docker上搭建solr集群,首先安装docker的环境。这个就不再演示,如果没有学过docker的同学可以参考下面的视频地址进行学习。
Docker容器化技术入门与应用-JavaEE免费视频课程-博学谷
如果学习过但是忘了如何搭建,参考一下地址。
-
拉取zookeeper镜像和solr的镜像,采用的版本是3.4.14和7.7.2
docker pull zookeeper:3.4.14 docker pull solr:7.7.2查看拉取镜像
docker images
2.3.2.2 搭建zookeeper集群
搭建zookeeper集群,我们需要利用我们刚才拉取的zookeeper的镜像创建3个容器。并且让他们产生集群关系。
单独创建一个桥接网卡
docker network create itcast-zookeeper
docker network ls
1.容器1创建
docker run
-id
--restart=always
-v /opt/docker/zookeeper/zoo1/data:/data
-v /opt/docker/zookeeper/zoo1/datalog:/datalog
-e ZOO_MY_ID=1
-e ZOO_SERVERS="server.1=zookeeper1:2888:3888 server.2=zookeeper2:2888:3888 server.3=zookeeper3:2888:3888"
-p 2181:2181
--name=zookeeper1
--net=itcast-zookeeper
--privileged
zookeeper:3.4.14
docker run -id --restart=always -v /opt/docker/zookeeper/zoo1/data:/data -v /opt/docker/zookeeper/zoo1/datalog:/datalog -e ZOO_MY_ID=1 -e ZOO_SERVERS="server.1=zookeeper1:2888:3888 server.2=zookeeper2:2888:3888 server.3=zookeeper3:2888:3888" -p 2181:2181 --name=zookeeper1 --privileged --net=itcast-zookeeper zookeeper:3.4.14
说明:
--restart:docker重启,容器重启。
-d:守护式方式运行方式,除此之外还有-it
-v:目录挂载,用宿主机/opt/docker/zookeeper/zoo1/data,映射容器的/data目录
-e:指定环境参数。分别指定了自己的id,集群中其他节点的地址,包含通信端口和投票端口
--name:容器的名称
-p:端口映射,用宿主机2181映射容器 2181,将来我们就需要通过本机2181访问容器。
--privileged:开启特权,运行修改容器参数
--net=itcast-zookeeper 指定桥接网卡
zookeeper:3.4.14:创建容器的镜像
查看创建好的容器
docker ps
查看宿主机的目录,该目录映射的就是zookeeper1容器中的data目录。
cd /opt/docker/zookeeper/zoo1/data
查看Zookeeper节点的id
cat myid
2.容器2创建
docker run -d --restart=always
-v /opt/docker/zookeeper/zoo2/data:/data
-v /opt/docker/zookeeper/zoo2/datalog:/datalog
-e ZOO_MY_ID=2
-e ZOO_SERVERS="server.1=zookeeper1:2888:3888 server.2=zookeeper2:2888:3888 server.3=zookeeper3:2888:3888"
-p 2182:2181
--name=zookeeper2
--net=itcast-zookeeper
--privileged
zookeeper:3.4.14
docker run -d --restart=always -v /opt/docker/zookeeper/zoo2/data:/data -v /opt/docker/zookeeper/zoo2/datalog:/datalog -e ZOO_MY_ID=2 -e ZOO_SERVERS="server.1=zookeeper1:2888:3888 server.2=zookeeper2:2888:3888 server.3=zookeeper3:2888:3888" -p 2182:2181 --name=zookeeper2 --net=itcast-zookeeper --privileged zookeeper:3.4.14
说明:
需要修改目录挂载。
修改Zookeeper的id
端口映射:用宿主机2182 映射容器 2181
容器名称:zookeeper2
3.容器3创建
docker run -d --restart=always
-v /opt/docker/zookeeper/zoo3/data:/data
-v /opt/docker/zookeeper/zoo3/datalog:/datalog
-e ZOO_MY_ID=3
-e ZOO_SERVERS="server.1=zookeeper1:2888:3888 server.2=zookeeper2:2888:3888 server.3=zookeeper3:2888:3888"
-p 2183:2181
--name=zookeeper3
--net=itcast-zookeeper
--privileged
zookeeper:3.4.14
docker run -d --restart=always -v /opt/docker/zookeeper/zoo3/data:/data -v /opt/docker/zookeeper/zoo3/datalog:/datalog -e ZOO_MY_ID=3 -e ZOO_SERVERS="server.1=zookeeper1:2888:3888 server.2=zookeeper2:2888:3888 server.3=zookeeper3:2888:3888" -p 2183:2181 --name=zookeeper3 --net=itcast-zookeeper --privileged zookeeper:3.4.14
说明:
需要修改目录挂载。
修改Zookeeper的id
端口映射:用宿主机2183 映射容器 2181
容器名称:zookeeper3
查看容器创建情况
2.3.2.3 测试Zookeeper集群的搭建情况
使用yum安装nc指令
yum install -y nc
方式1:
通过容器的ip查看Zookeeper容器状态
查看三个Zookeeper容器的ip
docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' zookeeper1
docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' zookeeper2
docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' zookeeper3
查看Zookeeper集群的状态
echo stat|nc ip 2181
echo stat|nc ip 2181
echo stat|nc ip 2181
方式2:通过宿主机的ip查询Zookeeper容器状态
2.3.2.4 zookeeper集群的架构
Zookeeper集群架构
Zookeeper客户端连接Zookeeper容器
2.3.2.3 搭建solr集群
搭建Solr集群,我们需要利用我们刚才拉取的solr的镜像创建4个容器。并且需要将集群交由Zookeeper管理,Solr容器内部使用jetty作为solr的服务器。
1.容器1创建
docker run --name solr1 --net=itcast-zookeeper -d -p 8983:8983 solr:7.7.2 bash -c '/opt/solr/bin/solr start -f -z zookeeper1:2181,zookeeper2:2181,zookeeper3:2181'
--name:指定容器名称
--net:指定网卡,之前创建的桥接网卡
-d:后台运行
-p:端口映射,宿主机8983映射容器中8983
-c:
/opt/solr/bin/solr:通过容器中脚本,指定Zookeeper的集群地址
2.容器2创建
docker run --name solr2 --net=itcast-zookeeper -d -p 8984:8983 solr:7.7.2 bash -c '/opt/solr/bin/solr start -f -z zookeeper1:2181,zookeeper2:2181,zookeeper3:2181'
--name:指定容器名称
--net:指定网卡,之前创建的桥接网卡
-d:后台运行
-p:端口映射,宿主机8983映射容器中8984
-c:/opt/solr/bin/solr:通过容器中脚本,指定Zookeeper的集群地址
3.容器3创建
docker run --name solr3 --net=itcast-zookeeper -d -p 8985:8983 solr:7.7.2 bash -c '/opt/solr/bin/solr start -f -z zookeeper1:2181,zookeeper2:2181,zookeeper3:2181'
--name:指定容器名称
--net:指定网卡,之前创建的桥接网卡
-d:后台运行
-p:端口映射,宿主机8983映射容器中8984
-c:/opt/solr/bin/solr:通过容器中脚本,指定Zookeeper的集群地址
4.容器4创建
docker run --name solr4 --net=itcast-zookeeper -d -p 8986:8983 solr:7.7.2 bash -c '/opt/solr/bin/solr start -f -z zookeeper1:2181,zookeeper2:2181,zookeeper3:2181'
--name:指定容器名称
--net:指定网卡,之前创建的桥接网卡
-d:后台运行
-p:端口映射,宿主机8983映射容器中8985
-c:/opt/solr/bin/solr:通过容器中脚本,指定Zookeeper的集群地址
5.查看结果
2.3.2.5 整体架构
2.3.2.6 创建集群的逻辑结构
1.通过端口映射访问solr的后台系统(注意关闭防火墙)
http://192.168.200.128:8983/solr
http://192.168.200.128:8984/solr
http://192.168.200.128:8985/solr
http://192.168.200.128:8986/solr
2.上传solr配置文件到Zookeeper集群。
进入到某个solr容器中,使用/opt/solr/server/scripts/cloud-scripts/的zkcli.sh 。上传solr的配置文件。
位置/opt/solr/example/example-DIH/solr/solr/conf到Zookeeper集群zookeeper1:2181,zookeeper2:2181,zookeeper3:2181。
docker exec -it solr1 /opt/solr/server/scripts/cloud-scripts/zkcli.sh -zkhost zookeeper1:2181,zookeeper2:2181,zookeeper3:2181 -cmd upconfig -confdir /opt/solr/server/solr/configsets/sample_techproducts_configs/conf -confname myconfig
3.使用zooInterceptor查看配置文件上传情况
4.使用后台管理系统创建connection
5. 查看集群的逻辑结构
到这基于docker的solr集群我们就讲解完毕。
6.测试集群
{id:1,name:"zx"}
2.3.2.7 solr配置文件修改
1.在linux服务器上需要有一份solr的配置文件,修改宿主机中的配置文件。
之前单机版solr的/usr/local/solr_home下,就有solr的配置文件。
/usr/local/solr_home下面的配置文件,schema已经配置了基于IK分词器的FieldType
2.将宿主机中的配置文件,替换到某个solr容器中。
docker cp /usr/local/solr_home/collection1/conf/managed-schema solr1:/opt/solr/server/solr/configsets/sample_techproducts_configs/conf/managed-schema
3.将容器中修改后managed-schema配置文件,重新上传到Zookeeper集群。
进入到solr1容器中,使用zkcli.sh命令,将最新的配置文件上传到Zookeeper集群
容器文件位置:/opt/solr/server/solr/configsets/sample_techproducts_configs/conf/managed-schema
集群文件位置: /configs/myconfig/managed-schema
docker exec -it solr1 /opt/solr/server/scripts/cloud-scripts/zkcli.sh -zkhost zookeeper1:2181,zookeeper2:2181,zookeeper3:2181 -cmd putfile /configs/myconfig/managed-schema /opt/solr/server/solr/configsets/sample_techproducts_configs/conf/managed-schema
4.在Files中查看,修改后的配置文件
5.将IK分词器的jar包,及配置文件复制到4个solr容器中。
5.1 将IK分词器上传到linux服务器
5.2 使用docker cp命令进行jar包的拷贝
docker cp /root/ik-analyzer-solr5-5.x.jar solr1:/opt/solr/server/solr-webapp/webapp/WEB-INF/lib/ik-analyzer-solr5-5.x.jar
docker cp /root/ik-analyzer-solr5-5.x.jar solr2:/opt/solr/server/solr-webapp/webapp/WEB-INF/lib/ik-analyzer-solr5-5.x.jar
docker cp /root/ik-analyzer-solr5-5.x.jar solr3:/opt/solr/server/solr-webapp/webapp/WEB-INF/lib/ik-analyzer-solr5-5.x.jar
docker cp /root/ik-analyzer-solr5-5.x.jar solr4:/opt/solr/server/solr-webapp/webapp/WEB-INF/lib/ik-analyzer-solr5-5.x.jar
5.3 使用docker cp命令进行配置文件的拷贝
将IK分析器的相关配置文件复制到/root/classes目录中
docker cp /root/classes solr1:/opt/solr/server/solr-webapp/webapp/WEB-INF/classes
docker cp /root/classes solr2:/opt/solr/server/solr-webapp/webapp/WEB-INF/classes
docker cp /root/classes solr3:/opt/solr/server/solr-webapp/webapp/WEB-INF/classes
docker cp /root/classes solr4:/opt/solr/server/solr-webapp/webapp/WEB-INF/classes
6、重启所有solr容器
docker restart solr1
docker restart solr2
docker restart solr3
docker restart solr4
7、使用text_ik创建业务域
不再使用修改配置文件的方式,直接利用后台管理系统进行。
{id:2,book_name:"java编程思想"}
2.3.2.7 使用SolrJ操作solr集群
1.修改Zookeeper地址和connection名称
@Bean
public CloudSolrClient cloudSolrClient() {
//指定Zookeeper的地址。
List<String> zkHosts = new ArrayList<>();
zkHosts.add("192.168.200.128:2181");
zkHosts.add("192.168.200.128:2182");
zkHosts.add("192.168.200.128:2183");
//参数2:指定
CloudSolrClient.Builder builder = new CloudSolrClient.Builder(zkHosts,Optional.empty());
CloudSolrClient solrClient = builder.build();
//设置连接超时时间
solrClient.setZkClientTimeout(30000);
solrClient.setZkConnectTimeout(30000);
//设置collection
solrClient.setDefaultCollection("myCollection");
return solrClient;
}
-
将之前的索引和搜索的代码执行一下
@Test public void testSolrCloudAddDocument() throws Exception { SolrInputDocument doc = new SolrInputDocument(); doc.setField("id", "3"); doc.setField("book_name", "葵花宝典"); cloudSolrClient.add(doc); cloudSolrClient.commit(); } @Test public void testSolrQuery() throws Exception { SolrQuery params = new SolrQuery(); params.setQuery("*:*"); QueryResponse response = cloudSolrClient.query(params); SolrDocumentList results = response.getResults(); for (SolrDocument result : results) { System.out.println(result); } } -
执行之前的代码会报错
错误的原因:连接不上172.19.0.6.8983。
这个容器是谁?
为什么连接不上呢?
-
错误的原因
-
正确的测试方案
将客户端应用部署到docker容器中,容器之间是可以相互通信的。
如何将我们的应用部署到docker容器中。
5.1 修改代码,将添加文档的操作写在controller方法中,便于我们进行测试;
@RestController @RequestMapping("/test") public class TestController { @Autowired private CloudSolrClient cloudSolrClient; @RequestMapping("/addDocument") public Map<String,Object> addDocument(String id,String bookName) throws IOException, SolrServerException { SolrInputDocument doc = new SolrInputDocument(); doc.setField("id", id); doc.setField("book_name", bookName); cloudSolrClient.add(doc); cloudSolrClient.commit(); Map<String,Object> result = new HashMap<>(); result.put("flag", true); result.put("msg","添加文档成功" ); return result; } }5.2 将spring boot项目打成可以运行jar包。
<build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build>5.3 使用package命令打成jar
clean package -DskipTests=true5.4 将jar包上传到linux服务器制作镜像
5.4.1上传
5.4.2 编写DockerFile文件
#基础镜像 FROM java:8 #作者 MAINTAINER itcast #将jar包添加到镜像app.jar ADD solr_solrJ_other-1.0-SNAPSHOT.jar app.jar #运行app的命令 java -jar app.jar ENTRYPOINT ["java","-jar","/app.jar"] 5.4.3 创建镜像
docker build -t myapp:1.0 ./ 使用当前目录的DockerFile文件创建镜像myapp,版本1.0 查看镜像
docker images查看
5.4.4 利用myapp:1.0镜像创建容器
docker run -d --net=itcast-zookeeper -p 8888:8080 myapp:1.0 #使用本地8888映射容器中8080 5.4.5 查看日志
docker logs -f 容器id 5.5.6 访问controller
http://192.168.200.128:8888/test/addDocument?id=999&bookName=葵花宝典 注意:如果发现连接不上Zookeeper,注意关闭防火墙;
systemctl stop firewalld
-
3.Solr查询高级
3.1 函数查询
在Solr中提供了大量的函数,允许我们在查询的时候使用函数进行动态运算。
3.2.1 函数调用语法
函数调用语法和java基本相同,格式为:函数名(实参),实参可以是常量(100,1.45,"hello"),也可以是域名,下面是函数调用例子。
functionName()
functionName(...)
functionName1(functionName2(...),..)
数据准备:为了便于我们后面的讲解,采用的案例数据,员工信息。
业务域:
员工姓名,工作,领导的员工号,入职日期,月薪,奖金
<field name="emp_ename" type="text_ik" indexed="true" stored="true"/>
<field name="emp_ejob" type="text_ik" indexed="true" stored="true"/>
<field name="emp_mgr" type="string" indexed="true" stored="true"/>
<field name="emp_hiredate" type="pdate" indexed="true" stored="true"/>
<field name="emp_sal" type="pfloat" indexed="true" stored="true"/>
<field name="emp_comm" type="pfloat" indexed="true" stored="true"/>
<field name="emp_cv" type="text_ik" indexed="true" stored="false"/>
<field name="emp_deptno" type="string" indexed="true" stored="true"/>
data-import.xml
<entity name="emp" query="select * from emp">
<!-- 每一个field映射着数据库中列与文档中的域,column是数据库列,name是solr的域(必须是在managed-schema文件中配置过的域才行) -->
<field column="empno" name="id"/>
<field column="ename" name="emp_ename"/>
<field column="ejob" name="emp_ejob"/>
<field column="mgr" name="emp_mgr"/>
<field column="hiredate" name="emp_hiredate"/>
<field column="sal" name="emp_sal"/>
<field column="comm" name="emp_comm"/>
<field column="cv" name="emp_cv"/>
<field column="deptno" name="emp_deptno"/>
</entity>
3.2.2 函数的使用
3.2.2.1 将函数返回值作为关键字
在solr中通常的搜索方式都是根据关键字进行搜索。底层首先要对关键字分词,在倒排索引表中根据词查找对应的文档返回。
item_title:三星手机
需求:查询年薪在30000~50000的员工。
主查询条件:查询所有:
过滤条件: 利用product()函数计算员工年薪,product函数是Solr自带函数,可以计算2个数之积。{!frange}指定范围。l表示最小值,u表示最大值.{!frange}语法是Function Query Parser解析器中提供的一种语法。
q=*:*
&fq={!frange l=30000 u=50000}product(emp_sal,12)
需求:查询年薪+奖金大于50000的员工
通过sum函数计算年薪+奖金。
q=*:*
&fq={!frange l=50000}sum(product(emp_sal,12),emp_comm)
上面查询不出来数据,原因是有些员工emp_comm为空值。
emp_comm进行空值处理。判断emp_comm是否存在,不存在指定位0,存在,本身的值
exists判断域是否存在
if指定存在和不存在值
{!frange l=40000}sum(product(emp_sal,12),if(exists(emp_comm),emp_comm,0))
3.2.2.1.2 将函数返回值作为伪域
伪域:文档中本身不包含的域,利用函数生成。
需求:查询所有的文档,每个文档中包含年薪域。
q=*:*&
fl=*,product(emp_sal,12)
指定别名:yearsql:product(emp_sal,12) 便于将来封装
3.2.2.1.3 根据函数进行排序
需求:查询所有的文档,并且按照(年薪+奖金)之和降序排序
q=*:*&
sort=sum(product(emp_sal,12),if(exists(emp_comm),emp_comm,0)) desc
3.2.2.1.4 使用函数影响相关度排序(了解)
之前在讲解查询的时候,我们说的相关度排序,Lucene底层会根据查询的词和文档关系进行相关度打分。
打分高的文档排在前面,打分低的排在后面。打分的2个指标tf,df;
使用函数可以影响相关度排序。
需求:查询emp_cv中包含董事长的员工,年薪高的员工相关度打分高一点。
q=emp_cv:董事长
AND _val_:"product(emp_sal,12)" #用来影响相关度排序,不会影响查询结果
可以简单这么理解
lucene本身对查询文档有一个打分叫score,每个文档分数可能不同。
通过函数干预后,打分score += 函数计算结果
_val_:规定
另外一种写法:
AND _query_:"{!func}product(emp_sal,12)"
3.2.2.1.5 Solr内置函数和自定义函数
常用内置函数
| 函数 | 说明 | 举例 |
|---|---|---|
| abs(x) | 返回绝对值 | abs(-5) |
| def(field,value) | 获取指定域中值,如果文档没有指定域,使用value作为默认值; | def(emp_comm,0) |
| div(x,y) | 除法,x除以y | div(1,5) |
| dist | 计算两点之间的距离 | dis(2,x,y,0,0) |
| docfreq(field,val) | 返回某值在某域出现的次数 | docfreq(title,’solr’) |
| field(field) | 返回该field的索引数量 | field(‘title’) |
| hsin | 曲面圆弧上两点之间的距离 | hsin(2,true,x,y,0,0) |
| idf | Inverse document frequency 倒排文档频率 | idf(field,’solr’) |
| if | if(test,value1,value2) | if(termfreq(title,’solr’),popularity,42) |
| linear(x,m,c) | 就是m*x+c,等同于sum(product(m,x),c) | linear(1,2,4)=1x2+4=6 |
| log(x) | 以10为底,x的对数 | log(sum(x,100)) |
| map(x,min,max,target) | 如果x在min和max之间,x=target,否则x=x | map(x,0,0,1) |
| max(x,y,…) | 返回最大值 | max(2,3,0) |
| maxdoc | 返回索引的个数,查看有多少文档,包括被标记为删除状态的文档 | maxdoc() |
| min(x,y,…) | 返回最小值 | min(2,4,0) |
| ms | 返回两个参数间毫秒级的差别 | ms(datefield1,2000-01-01T00:00:00Z) |
| norm(field) | 返回该字段索引值的范数 | norm(title) |
| numdocs | 返回索引的个数,查看有多少文档,不包括被标记为删除状态的文档 | numdocs() |
| ord | 根据顺序索引发货结果 | ord(title) |
| pow(x,y) | 返回x的y次方 | pow(x,log(y)) |
| product(x,y) | 返回多个值得乘积 | product(x,2) |
| query | 返回给定的子查询的得分,或者文档不匹配的默认值值 | query(subquery,default) |
| recip(x,m,a,b) | 相当于a/(m*x+b),a,m,b是常量,x是变量 | recip(myfield,m,a,b) |
| rord | 按ord的结果反序返回 | |
| scale | 返回一个在最大值和最小值之间的值 | scale(x,1,3) |
| sqedist | 平方欧氏距离计算 | sqedist(x_td,y_td,0,0) |
| sqrt | 返回指定值得平方根 | sqrt(x)sqrt(100) |
| strdist | 计算两个字符串之间的距离 | strdist(“SOLR”,id,edit) |
| sub | 返回x-y | sub(field1,field2) |
| sum(x,y) | 返回指定值的和 | sum(x,y,…) |
| sumtotaltermfreq | 返回所有totaltermfreq的和 | |
| termfreq | 词出现的次数 | termfreq(title,’sorl’) |
| tf | 词频 | tf(text,’solr’) |
| top | 功能类似于ord | |
| totaltermfreq | 返回这个词在该字段出现的次数 | ttf(title,’memory’) |
| and | 返回true值当且仅当它的所有操作为true | and(not(exists(popularity)),exists(price)) |
| or | 返回true值当有一个操作为true | or(value1,value2) |
| xor | 返回false值如果所有操作都为真 | xor(field1,field2) |
| not | 排除操作 | not(exists(title)) |
| exists | 如果字段存在返回真 | exists(title) |
| gt,gte,lt,lte,eq | 比较函数 | 2 gt 1 |
自定义函数
自定义函数流程:
准备:
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-core</artifactId>
<version>7.7.2</version>
</dependency>
1.定义一个类继承 ValueSource 类,用于封装函数执行结果。
2.定义一个类继承ValueSourceParser,用来解析函数调用语法,并且可以解析参数类型,以及返回指定结果。
3. 在solrconfig.xml中配置文件中配置ValueSourceParser实现类的全类名
需求:定义一个solr字符串拼接的函数,将来函数的调用语法concat(域1,域2),完成字符串拼接。
第一步:
/**
* 用来解析函数调用语法,并且将解析的参数返回给第一个类处理。
* concat(field1,field2)
*/
public class ConcatValueSourceParser extends ValueSourceParser {
//对函数调用语法进行解析,获取参数,将参数封装到ValueSource,返回函数执行结果
public ValueSource parse(FunctionQParser functionQParser) throws SyntaxError {
//1.获取函数调用参数,由于参数类型可能是字符串,int类型,域名,所以封装成ValueSource
//1.1获取第一个参数封装对象
ValueSource arg1 = functionQParser.parseValueSource();
//1.2获取第二个参数封装对象
ValueSource arg2 = functionQParser.parseValueSource();
//返回函数执行结果
return new ConcatValueSource(arg1, arg2);
}
}
第二步:
public class ConcatValueSource extends ValueSource {
//使用构造方法接收ConcatValueSourceParser解析获取的参数
private ValueSource arg1;
private ValueSource arg2;
public ConcatValueSource(ValueSource arg1, ValueSource arg2) {
this.arg1 = arg1;
this.arg2 = arg2;
}
//返回arg1和arg2计算结果
public FunctionValues getValues(Map map, LeafReaderContext leafReaderContext) throws IOException {
FunctionValues values1 = arg1.getValues(map, leafReaderContext); //第一个参数
FunctionValues values2 = arg1.getValues(map, leafReaderContext); //第二个参数
//返回一个字符串的结果
return new StrDocValues(this) {
@Override
public String strVal(int doc) throws IOException {
//根据参数从文档中获取值
return values1.strVal(doc) + values2.strVal(doc);
}
};
}
第三步:在solrconfig.xml配置
<valueSourceParser name="concat" class="cn.itcast.funcation.ConcatValueSourceParser" />
第四步:打包,并且在solr/WEB-INF/lib 目录中配置
第五步:测试
fl=*,concat(id,emp_ename)
3.2 地理位置查询
在Solr中也支持地理位置查询,前提是我们需要将地理位置的信息存储的Solr中,其中地理位置中必须包含一个比较重要的信息,经度和纬度,经度范围[-180,180],纬度范围[-90,90]。对于经度来说东经为正,西经为负,对于纬度来说,北纬正,南纬为负。
3.2.1 数据准备
首先我们先来完成数据准备,需要将地理位置信息存储到Solr中;
1.在MySQL导入地理位置信息
name是地址名称
position:经纬度坐标,中间用,分割(纬度,经度)
2.schema.xml中定义业务域
name域的定义
<field name="address_name" type="text_ik" indexed="true" stored="true"/>
注意:
坐标域定义
域类型location,这域类型就是用来定义地理位置域。
使用location域类型定义的域,底层会被拆分成2个域进行存储,分别是经度和维度。
这个域将来会被拆分成2个域进行存储。
所以需要定义动态域对底层操作进行支持。
<field name="address_position" type="location" indexed="true" stored="true"/>
以下在schema中已经定义好了。
<fieldType name="location" class="solr.LatLonType" subFieldSuffix="_coordinate"/>
<dynamicField name="*_coordinate" type="tdouble" indexed="true" stored="false"/>
3.使用DataImport导入数据
<entity name="address" query="select * from address">
<!-- 每一个field映射着数据库中列与文档中的域,column是数据库列,name是solr的域(必须是在managed-schema文件中配置过的域才行) -->
<field column="id" name="id"/>
<field column="name" name="address_name"/>
<field column="position" name="address_position"/>
</entity>
4.测试
id:主键
address_name:位置名称
address_position:位置坐标
还多出2个域:address_position_0_coordinate ,address_position_1_coordinate 基于动态域生成的维度和经度坐标。
3.2.2 简单地理位置查询
Solr中 提供了一种特殊的查询解析器(geofilt),它能解析以指定坐标(包含经纬度)为中心。 以指定距离(千米)为半径画圆,坐标落在圆面积中的文档,
需求:查询离西安半径 30 千米范围内的城市。
1.查询西安的坐标
address_name:西安
-
查询距离西安30千米范围内的城市
q=*:*& fq={!geofilt sfield=address_position pt=34.27,108.95 d=30}sfiled:指定坐标域
pt:中心
d:半径
除了可以查询落在圆面积中的地址外,对于精确度不高的查询,也可以查询落在外切正方形中的地理位置。
这种方式比圆的方式效率要高。
q=*:*&
ft={!bbox sfield=address_position pt=34.27,108.95 d=30}
-
在solr中还提供了一些计算地理位置的函数,比较常用的函数geodist,该函数可以计算2个地理位置中间的距离。调用方式:geodist(sfield,latitude,longitude);
需求:计算其他城市到北京的距离,作为伪域展示
q=*:*& fl=*,distance:geodist(address_position,39.92,116.46) sort=geodist(address_position,39.92,116.46) asc
3.2.3 地理位置高级查询
之前我们在讲解简单地理位置查询的时候,都是基于正方形或者基于圆进行。有时候我们在进行地理位置查询的时候需要基于其他形状。在Solr中提供了一个类SpatialRecursivePrefixTreeFieldType(RPT)可以完成基于任意多边形查询。
3.2.3.1对地理数据进行重写索引
1.修改address_position域类型
之前的域定义,域类型location
<field name="address_position" type="location" indexed="true" stored="true"/>
修改后的域定义,域类型location_rpt
<field name="address_position" type="location_rpt" indexed="true" stored="true" multiValued="true"/>
location_rpt类型是schema文件已经提供好的一个类型,class就是RPT
<fieldType name="location_rpt" class="solr.SpatialRecursivePrefixTreeFieldType"
spatialContextFactory="JTS"
geo="true" distErrPct="0.025" maxDistErr="0.001" distanceUnits="kilometers" />
-
location_rpt类型,允许存储的数据格式。
点:
纬度 经度 纬度,经度 任意形状
POLYGON((坐标1,坐标2....))将来我们可以查询一个点,或者任意形状是否在另外一个几何图形中。
3. 复制jst的jar包到solr/WEB-INF/classes目录
<dependency>
<groupId>org.locationtech.jts</groupId>
<artifactId>jts-core</artifactId>
<version>1.16.1</version>
</dependency>
jst:用于构建图形的jar包
-
插入测试数据,address_position域中存储的是一个几何图形
insert into address values(8989,'三角形任意形状','POLYGON((108.94224 35.167441,108.776664 34.788863,109.107815 34.80404,108.94224 35.167441))');
- 使用DataImport重新进行索引
3.2.3.2 基于任意图形进行查询
查询基于A,B,C,D这4个点围城的图形有哪些城市。
可以使用百度地图的坐标拾取得知A,B,C,D四个点的坐标。
拾取坐标系统
A 109.034226,35.574317
B 111.315491,33.719499
C108.243142,33.117791
D 107.98558,34.37802
利用ABCD四个点构建几个图形,查询地理坐标在该几何图形中的文档。
address_position:"Intersects(POLYGON((109.034226 35.574317,
111.315491 33.719499,
108.243142 33.117791,
107.98558 34.37802,
109.034226 35.574317)))"
说明:
POLYGON是JST中提供的构建任意多边形的语法。
每个坐标之间使用,进行分割。
经度和纬度之间使用空格隔开
如果构建的是一个封闭图形,最后一个坐标要和第一个坐标相同。
Intersects是一个操作符
作用:匹配2个图形相交部分的文档。
IsWithin
作用:匹配包含在指定图形面积之内的文档,不含边界
Contains:
作用:匹配包含在指定图形面积之内的文档,含边界
3.3 JSON Facet
在Solr中对于Facet查询提供了另外一种查询格式。称为JSON Facet。使用JSON Fact有很多好处,书写灵活,便于自定义响应结果,便于使用分组统计函数等。
3.3.1 JSON Facet 入门
根据商品分类,分组统计每个分类对应的商品数量,要求显示前3个。
传统的Facet查询
q=*:*&
facet=true&
facet.field=item_category&
facet.limit=3
JSON Facet
q=*:*&
json.facet={
category:{
type:terms,
field:item_category,
limit:3
}
}
测试
http://localhost:8080/solr/collection1/select?q=*:*&json.facet=%7Bcategory:%7Btype:terms,field:item_category,limit:3%7D%7D
其中category是自定义的一个键。
type:指的是facet的类型
field:分组统计的域
3.3.2 JSON Facet的语法
json.facet = {
<facet_name>:{
type:<fact_type>,
<other_facet_parameter>
}
}
facet_name:可以任意取值,是为了将来解析结果使用。
type:取值terms,query,range.
terms根据域进行Facet查询,query根据查询解决进行facet查询。range根据范围进行facet查询。
other_facet_parameter:其他facet的一些参数。
根据上面的语法,再来完成一个需求
需求:分组统计2015年每月添加的商品数量。
q=*:*,
json.facet={
month_count:{
type:range,
field:item_createtime,
start:'2015-01-01T00:00:00Z',
end:'2016-01-01T00:00:00Z',
gap:'+1MONTH'
}
}
http://localhost:8080/solr/collection1/select?q=*:*&json.facet=%7B
month_count:%7B
type:range,
field:item_createtime,
start:'2015-01-01T00:00:00Z',
end:'2016-01-01T00:00:00Z',
gap:'%2B1MONTH'
%7D
%7D
需求:统计品牌是华为的商品数量,分类是平板电视的商品数量。
q=*:*,
json.facet={
brand_count:{
type:query,
q:"item_brand:华为"
},
category_count:{
type:query,
q:"item_category:平板电视"
}
}
http://localhost:8080/solr/collection1/select?q=*:*&json.facet=%7B
brand_count:%7B
type:query,
q:"item_brand:华为"
%7D,
category_count:%7B
type:query,
q:"item_category:平板电视"
%7D
%7D
3.3.3 SubFacet
在JSON Facet中,还支持另外一种Facet查询,叫SubFacet.允许用户在之前分组统计的基础上,再次进行分组统计,可以实现pivot Facet(多维度分组查询功能)查询的功能。
需求:对商品的数据,按照品牌进行分组统计,获取前5个分组数据。
q=*:*&
json.facet={
top_brand:{
type:terms,
field:item_brand,
limit:5
}
}
http://localhost:8080/solr/collection1/select?q=*:*&
json.facet=%7B
top_brand:%7B
type:terms,
field:item_brand,
limit:5
%7D
%7D
在以上分组的基础上,统计每个品牌,不同商品分类的数据。eg:统计三星手机多少个,三星平板电视多少?
q=*:*&
json.facet={
top_brand:{
type:terms,
field:item_brand,
limit:5,
facet:{
top_category:{
type:terms,
field:item_category,
limit:3
}
}
}
}
http://localhost:8080/solr/collection1/select?q=*:*&
json.facet=%7B
top_brand:%7B
type:terms,
field:item_brand,
limit:5,
facet:%7B
top_category:%7B
type:terms,
field:item_category,
limit:3
%7D
%7D
%7D
%7D
3.3.4 聚合函数查询
在JSON Facet中,还支持另外一种强大的查询功能,聚合函数查询。在Facet中也提供了很多聚合函数,也成为Facet函数。很多和SQL中的聚合函数类似。
函数如下:
| 聚合函数 | 例子 | 描述 |
|---|---|---|
| sum | sum(sales) | 聚合求和 |
| avg | avg(popularity) | 聚合求平均值 |
| min | min(salary) | 最小值 |
| max | max(mul(price,popularity)) | 最大值 |
| unique | unique(author) | 统计域中唯一值的个数 |
| sumsq | sumsq(rent) | 平方和 |
| percentile | percentile(salary,30,60,10) | 可以根据百分比进行统计 |
需求:查询华为手机价格最大值,最小值,平均值.
q=item_title:手机
&fq=item_brand:华为
&json.facet={
avg_price:"avg(item_price)",
min_price:"min(item_price)",
max_price:"max(item_price)"
}
http://localhost:8080/solr/collection1/select?q=item_title:手机
&fq=item_brand:华为
&json.facet=%7B
avg_price:"avg(item_price)",
min_price:"min(item_price)",
max_price:"max(item_price)"
%7D
查询结果:
需求:查询每个品牌下,最高的手机的价格.
q=item_title:手机
&json.facet={
categories:{
type:terms,
field:item_brand,
facet:{
x : "max(item_price)"
}
}
}
http://localhost:8080/solr/collection1/select?q=item_title:手机&json.facet=%7Bcategories:%7Btype:field,field:item_brand,facet:%7Bx:"max(item_price)"%7D%7D%7D
结果:
4.Solr查询进阶
4.1 深度分页
在Solr中 默认分页中,我们需要使用 start和 rows 参数。一般情况下使用start和rows进行分页不会有什么问题。但是在极端情况下,假如希望查询第 10000 页且每页显示10条,意味着 Solr 需要提取前 10000 × 10 = 100000 条数据,并将这100000 条数据缓存在内存中,然后返回最后10条即用户想要的第10000页数据。
引发问题:将这100000条数据缓存到内存中,会占用很多内存。页码越靠后,分页查询性能越差。多数情况下,用户也不会查询第10000页的数据,但是不排除用户直接修改url的参数,查询第10000页的数据。
解决方案:
为此Solr 提供了一种全新的分页方式, 被称为游标。游标可以返回下一页数据的起始标识。该标识记录着下一页数据在索引库中绝对的索引位置。一旦我们使用了游标,Solr就不会采用之前的分页方式。而是根据每一页数据在索引库中绝对索引位置来获取分页数据。
使用流程:
1.查询数据的时候需要指定一个参数cursorMark=*,可以理解为start=0,通过该参数就可以获取第一页数据。在返回的结果中包含另外一个参数nextCursorMark
2.nextCursorMark是下一页数据开始位置。
3.将下一页数据的开始位置作为cursorMark的值来查询下一页数据。
4.如果返回nextCursorMark和cursorMark相同,表示没有下一页数据
注意点:
1.cursorMark在进行分页的时候,是不能再指定start这个参数。
2.使用cursorMark在进行分页的时候,必须使用排序,而且排序字段中必须包含主键。
eg: id asc
eg: id asc name desc
演示:
需求:查询item_title中包含LED的第一页的50条数据
http://localhost:8080/solr/collection1/select?
q=item_title:LED&
cursorMark=*&
rows=50&
sort=id asc

利用下一页数据的起始标识查询下一页数据,将cursorMark改为下一页数据的起始标识
q=item_title:LED&
cursorMark=AoEnMTEzNjY5NQ==&
rows=50&
sort=id asc
如果发现cursorMark和返回的nextCursorMark相同,表示没有下一页数据
4.2 Solr Join查询
4.2.1 Join查询简介
在Solr 中的索引文档一般建议扁平化、非关系化,所谓扁平化即每个文档包含的域个数和类型可以不同,而非关系型化则表示每个文档之间没有任何关联,是相互独立 。不像关系型数据库中两张表之间可以通过外键建立联系。
案例场景:
需求:需要将员工表和部门表的数据导入到Solr中进行搜索。
通常我们的设计原则。将员工表和部门表的字段冗余到一个文档中。将来查询出来的文档中包含员工和部门信息。
但是在Solr中他也提供了Join查询,类似于SQL中子查询,有时候我们利用Join查询也可以完成类似子查询的功能。
4.2.2 join查询的数据准备
1.将部门表的数据导入到Solr中。
业务域
<field name="dept_dname" type="text_ik" indexed="true" stored="true"/>
<field name="dept_loc" type="text_ik" indexed="true" stored="true"/>
<fieldType name ="text_ik" class ="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
DataImport配置文件
<dataConfig>
<!-- 首先配置数据源指定数据库的连接信息 -->
<dataSource type="JdbcDataSource"
driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/lucene"
user="root"
password="123"/>
<document>
<entity name="dept" query="select * from dept">
<!-- 每一个field映射着数据库中列与文档中的域,column是数据库列,name是solr的域(必须是在managed-schema文件中配置过的域才行) -->
<field column="deptno" name="id"/>
<field column="dname" name="dept_dname"/>
<field column="loc" name="dept_loc"/>
</entity>
</document>
</dataConfig>
在collection2中导入部门数据

4.2.3 Join查询的案例使用场景
需求:查询部门名称为SALES下的员工信息。
sql子查询:
1.查询SALES部门名称对应的部门id
select depno from dept where dname = 'SALES'
2.查询部门id下员工信息
select * from emp where deptno in (select depno from dept where dname = 'SALES')

类比sql中的子查询,来完成Solr中Join查询。
q=*:*& //主查询条件------->查询所有员工
//过滤条件collection2中dept_dname:SALES
fq=dept_dname:SALES
建立连接关系
{!join fromIndex=collection2 toIndex=collection1 from=id to=emp_deptno}
fromIndex:被连接的collection
toIndex:主collection
from:部门号
to:外键
最终:
q=*:*&
fq={!join fromIndex=collection2 toIndex=collection1 from=id
to=emp_deptno}dept_dname:SALES

需求:查询7369员工的部门信息。
sql子查询
查询7369员工的部门号。
select deptno from emp where empno = 7369
根据上面部门号查询部门信息
select * from dept where deptno = (
select deptno from emp where empno = 7369
)

类比sql中的子查询,来完成Solr中Join查询。
主查询条件------->查询所有部门
q=*:*&
fq=id:7369
--------->子查询条件员工id为7369
使用join进行连接
{!join fromIndex=collection1 toIndex=collection2 from=emp_deptno to=id}

分析:
需求:查询7369员工的领导的信息。
sql子查询
1.查询7369员工的领导的编号。
select mgr from emp where empno = 7369
2.根据领导的编号,查询领导信息
select * from emp where empno = (
select mgr from emp where empno = 7369
)
类比sql中的子查询,来完成Solr中Join查询。
主查询条件
q=*:*------->主查询条件
fq={!join fromIndex=collection1 toIndex=collection1 from=emp_mgr to=id}id:7369
结果:
分析:
需求:统计SALES部门下,薪水最高的员工
步骤1:查询SALES部门下的所有员工。
q=*:*& //主查询条件------->查询所有员工
//过滤条件collection2中dept_dname:SALES
fq={!join fromIndex=collection2 toIndex=collection1 from=id to=emp_deptno}dept_dname:SALES
步骤2:使用Facet的函数查询最高的薪水;
q=*:*& //主查询条件------->查询所有员工
//过滤条件collection2中dept_dname:SALES
fq={!join fromIndex=collection2 toIndex=collection1 from=id to=emp_deptno}dept_dname:SALES&
json.facet={
x:"max(emp_sal)"
}
http://localhost:8080/solr/collection1/select?q=*:*&
fq=%7B!join fromIndex=collection2 toIndex=collection1 from=id to=emp_deptno%7Ddept_dname:SALES&
json.facet=%7B
x:"max(emp_sal)"
%7D

4.2.4 Block Join
在Solr中还支持一种Join查询,我们称为Block Join。但前提是我们的 Document 必须是 Nested Document (内嵌的Document);
4.2.4.1什么是内嵌的Document
内嵌的Document 就是我们可以在 Document 内部再添加一个Document ,形成父子关系,就好比HTML中的 div标签内部能够嵌套其他div标签,形成多层级的父子关系,以员工和部门为例,如果我们采用内嵌 Document 来进行索引,我们使用一个collection来存储部门和员工的信息。此时我们的索引数据结构应该是类似这样的:
<add>
<doc>
<field name="id">1</field>
<field name="dept_dname">ACCOUNTING</field>
<field name="dept_loc">NEW YORK</field>
<doc>
<field name="id">7369</field>
<field name="emp_ename">SMITH COCO</field>
<field name="emp_job">CLERK</field>
<field name="emp_hiredate">1980-12-17</field
...
<field name="emp_deptno">1</field>
</doc>
<doc>
<field name="id">7566</field>
<field name="emp_ename">JONES</field>
<field name="emp_job">MANAGER</field>
<field name="emp_hiredate">1981-04-02</field
...
<field name="emp_deptno">1</field>
</doc>
</doc>
</add>
4.2.4.1内嵌Document相关域创建
<!--员工相关的域-->
<field name="emp_ename" type="text_ik" indexed="true" stored="true"/>
<field name="emp_job" type="text_ik" indexed="true" stored="true"/>
<field name="emp_mgr" type="string" indexed="true" stored="true"/>
<field name="emp_hiredate" type="pdate" indexed="true" stored="true"/>
<field name="emp_sal" type="pfloat" indexed="true" stored="true"/>
<field name="emp_comm" type="pfloat" indexed="true" stored="true"/>
<field name="emp_cv" type="text_ik" indexed="true" stored="false"/>
<!--部门表的业务域-->
<field name="dept_dname" type="text_ik" indexed="true" stored="true"/>
<field name="dept_loc" type="text_ik" indexed="true" stored="true"/>
<!--标识那个是父节点-->
<field name="docParent" type="string" indexed="true" stored="true"/>
<!--创建内嵌的document必须有_root_域,该域在schema文件中已经有了,不需要额外添加-->
<field name="_root_" type="string" indexed="true" stored="true"/>
4.2.4.2 使用solrJ/spring data solr将部门和员工信息以内嵌Document的形式进行索引
SolrJ核心的API
SolrInputDocument doc = new SolrInputDocument()
SolrInputDocument subDoc = new SolrInputDocument()
doc.addChildDocument(subDoc); //建立父子关系的API方法。
Spring Data Solr
如果学习了Spring Data Solr可以使用@Field注解和@ChildDocument注解
思路
使用mybatis查询部门表的所有信息。
迭代每一个部门-------->部门Doucment
根据部门号查询该部门下所有的员工------->员工Document集合
建立部门Doucment和其员工Document的父子关系
引入依赖
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.4.RELEASE</version>
</parent>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-solrj</artifactId>
<version>7.7.2</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<!--通用mapper起步依赖-->
<dependency>
<groupId>tk.mybatis</groupId>
<artifactId>mapper-spring-boot-starter</artifactId>
<version>2.0.4</version>
</dependency>
<!--MySQL数据库驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
编写yml文件
#数据库的连接信息
spring:
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/lucene?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC
username: root
password: 123
#solr collection1地址
url: http://localhost:8080/solr/collection1
编写启动类
@SpringBootApplication
@MapperScan("cn.itcast.dao")
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
@Value("${url}")
private String url;
@Bean
public HttpSolrClient httpSolrClient() {
HttpSolrClient.Builder builder = new HttpSolrClient.Builder(url);
return builder.build();
}
}
编写实体类
@Data
@Table(name = "emp")
public class Emp {
@Id
private String empno;
private String ename;
private String job;
private String mgr;
private Date hiredate;
private Double sal;
private Double comm;
private String cv;
private String deptno;
}
@Data
@Table(name = "dept")
public class Dept {
@Id
private String deptno;
private String dname;
private String loc;
}
Dao接口的编写
public interface DeptDao extends Mapper<Dept> {
}
public interface EmpDao extends Mapper<Emp> {
}
编写测试方法,导入数据
@RunWith(SpringRunner.class)
@SpringBootTest(classes=Application.class)
public class AppTest {
@Autowired
private DeptDao deptDao;
@Autowired
private EmpDao empDao;
@Autowired
private SolrClient solrClient;
@Test
public void test01() throws IOException, SolrServerException {
List<Dept> depts = deptDao.selectAll();
//迭代每一个部门
for (Dept dept : depts) {
//每个部门转化为一个Document
System.out.println(dept);
SolrInputDocument deptDocument = new SolrInputDocument();
deptDocument.setField("id", dept.getDeptno());
deptDocument.setField("dept_dname", dept.getDname());
deptDocument.setField("dept_loc", dept.getLoc());
deptDocument.setField("docParent", "isParent");
//获取每个部门的员工。
List<SolrInputDocument> emps = findEmpsByDeptno(dept.getDeptno());
deptDocument.addChildDocuments(emps);
solrClient.add(deptDocument);
solrClient.commit();
}
}
private List<SolrInputDocument> findEmpsByDeptno(String deptno) {
Example example = new Example(Emp.class) ;
Example.Criteria criteria = example.createCriteria();
criteria.andEqualTo("deptno", deptno);
List<Emp> emps = empDao.selectByExample(example);
System.out.println(emps);
List<SolrInputDocument> solrInputDocuments = new ArrayList<>();
for (Emp emp : emps) {
SolrInputDocument document = emp2SolrInputDocument(emp);
solrInputDocuments.add(document);
}
return solrInputDocuments;
}
private SolrInputDocument emp2SolrInputDocument(Emp emp) {
SolrInputDocument document = new SolrInputDocument();
document.setField("id", emp.getEmpno());
document.setField("emp_ename", emp.getEname());
document.setField("emp_job", emp.getJob());
document.setField("emp_mgr", emp.getMgr());
document.setField("emp_hiredate", emp.getHiredate());
document.setField("emp_sal", emp.getSal());
document.setField("emp_comm", emp.getComm());
document.setField("emp_cv", emp.getCv());
return document;
}
}
测试:

4.2.4.3 基于内嵌的document查询
语法:用来查询子文档
allParents:查询所有父文档的条件,someParents过滤条件
q={!child of=<allParents>}<someParents>
语法:用来查询父文档
allParents:查询所有父文档的条件,someChildren子文档的过滤条件
q={!parent which=<allParents>}<someChildren>
需求:查询ACCOUNTING部门下面所有的员工。
q={!child of=docParent:isParent}dept_dname:ACCOUNTING
需求:查询CLARK员工所属的部门
q={!parent which=docParent:isParent}emp_ename:CLARK
4.3 相关度排序
4.3.1 Field权重
比如我们有图书相关的文档,需要根据book_name或者book_description搜索图书文档。我们可能认为book_name域的权重可能要比book_description域的权重要高。我们就可以在搜索的时候给指定的域设置权重。
演示:默认的相关度排序
q=book_name:java OR book_description:java
http://localhost:8080/solr/collection1/select?q=book_name:java OR book_description:java

演示:设置域的权重
方式1:在schema文件中给指定field指定boost属性值。
boost默认值1.0
此方式不建议:原因是需要重新对数据进行索引。
<field name="book_name" type="text_ik" indexed="true" stored="true" boost="10.0"/>
方式2:
使用edismax查询解析器。
defType=edismax
&q=java
&qf=book_name book_description^10
http://localhost:8080/solr/collection1/select?
defType=edismax&q=java
&qf=book_name book_description%5E10
q:查询条件是java
qf:在哪个域中进行查询
4.3.2 Term权重
有时候我们查询的时候希望为某个域中的词设置权重。
查询book_name中包含 java或者spring的,我们希望包含java这个词的权重高一些。
book_name:java OR book_name:spring
book_name:java^10 OR book_name:spring
4.3.3 Function权重
function权重,我们在之前讲解函数查询的时候,讲解过。
4.3.4 临近词权重
有时候我们有这种需求,比如搜索iphone plus将来包含iphone 或者 plus的文档都会被返回,但是我们希望包含iphone plus完整短语的文档权重高一些。
第一种方式:使用edismax查询解析器
http://localhost:8080/solr/collection1/select?defType=edismax&
q=iphone plus&qf=book_name

可以添加一个参数
pf=域名~slop^boost
http://localhost:8080/solr/collection1/select?
defType=edismax&
q=iphone plus&
qf=book_name&
pf=book_name~0^10
0^10 book_name中包含iphone 没有任何词 plus文档权重是10
1^10 book_name中包含iphone 一个词/没有词 plus文档权重是10
2^10 book_name中包含”iphone 2个及2个以下词 plus"文档权重是10
%5E
q:查询条件是java
qf:在哪个域中进行查询
第二种方式:使用标准解析器中也可以完成临近词的加权
/select?q=iphone plus OR "iphone plus"~0^10 &df=book_name
q:查询条件是java
df:在哪个域中进行查询
4.3.5 Document权重
除了上面的修改相关度评分的操作外,我们也可以在索引的时候,设置文档的权重。使用SolrJ或者Spring DataSolr完成索引操作的时候调用相关方法来设置文档的权重。在Solr7以后已经废弃。
@Deprecated
public void setDocumentBoost(float documentBoost) {
_documentBoost = documentBoost;
}
5.Solr性能优化
5.1 Schema文件设计的注意事项(理解)
硬件方面主要影响solr的性能主要是内存,solr的内存主要应用在两个方面:(1)Java的堆内存;(2)数据缓存;建议使用64位jdk,并且配套64位操作系统(32位的jdk最大支持的堆内存使用2G)
indexed属性(重要):设置了indexed=true的域要比indxed=false的域,索引时占用更多的内存空间。而且设置了index=true的域所占用磁盘空间也比较大,所以对于一些不需要搜索的域,我们需要将其indexed属性设置为false。比如:图片地址。
omitNorms属性选择:如果我们不关心词在文档中出现总的次数,影响最终的相关度评分。可以设置omitNorms=true。它可以减少磁盘和内存的占用,也可以加快索引时间。
omitPosition属性选择:如果我们不需要根据该域进行高亮,可以设置成true,也可以减少索引体积。
omitTermFreqAndPositions属性:如果我们只需要利用倒排索引结构根据指定Term找到相应Document,不需要考虑词的频率,词的位置信息,可以将该属性设置为true,也可以减少索引体积。
stored属性(重要):如果某个域的值很长,比如想要存储一本书的信息,首先我们要考虑该域要不要存储。如果我们确实想要在Solr 查询中能够返回该域值,此时可以考虑使用 ExtemalFileField 域类型。
如果我们存储的域值长度不是很大,但是希望降低磁盘的IO。可以设置 compressed=true 即启用域值数据 压缩,域值数据压缩可以降低磁盘 IO ,同时会增加 CPU 执行开销。
如果你的域值很大很大,比如是一个几十MB PDF 文件的内容 ,此时如果你将域的 stored 属性设置为 true 存储在 Solr中,它不仅会影响你的索引创建性能,还会影响我们的查询性能,如果查询时,fl参数里返回该域,那对系统性能打击会很大,如果了使用 ExtemalFileField 域类型,该域是不支持查询的,只支持显示。通常我们的做法是将该域的信息存储到Redis,Memcached缓存数据库。当我们需要该域的数据时,我们可以根据solr中文档的主键在缓存数据库中查询。
multiValued属性:如果我们某个域的数据有多个时,通常可以使用multiValued属性。eg:鞋子的尺码,鞋子的尺码可能会有多个36,38,39,40,41...。就可以设置multiValued属性为true。
但是有些域类型是不支持multiValued属性,eg:地理位置查询LatLonType;
Group查询也不支持multiValued属性为true的域。
我们可以考虑使用内嵌的Document来解决次问题。可以为该文档添加多个子文档。
对于日期类型的数据,在Solr中我们强烈建议使用solr中提供的日期类型域类来存储。不建议使用string域类型来存储。否则是无法根据范围进行查询。
Solr官方提供的schema示例文件中定义了很多<dynamicField>、<copyField>以及
<fieldType>,上线后这里建议你将它们都清理掉, <fieldType>只保留一些基本的域类型string、 boolean
pint plong pfloat pdate 即可,一定保留内置的_version_,_root_ 域,否则一些功能就不能使用。
比如删除_root_就无法创建内嵌的document;
5.2 索引更新和提交的建议
在Solr中我们在进行索引更新的时候,一般不建议显式的调用 commit()进行硬提交,建议我们 solrconfig. xml 中配置自动提交和软提交;
硬提交: 所谓硬提交是将没有提交的数据flush到硬盘中,并且能够查询到这条数据。如果我们每次都进行硬提交的话,频繁的和磁盘IO进行交互,会影响索引的性能。
软提交:所谓软提交是将提交数据到写到内存里面,并且开启一个searcher。它可以保证数据可以被搜索到,等到一定的时机后再进行自动硬提交,再将数据flush到硬盘上。
在SolrConfig.xml中如何配置软提交呢
<updateHandler class="solr.DirectUpdateHandler2">
<autoCommit>
<!--表示软提交达到1万条的时候会自动进行一次硬提交-->
<maxDocs>10000</maxDocs>
<!--每10秒执行一次硬提交-->
<maxTime>10000</maxTime>
</autoCommit>
<autoSoftCommit>
<!--1秒执行一次软提交-->
<maxTime>1000</maxTime>
</autoSoftCommit>
</updateHandler>
5.3 Solr缓存
在Solr中缓存扮演者很重要的角色,它很大程度上决定了我们的Solr查询性能。在Solr中一共开启了3种内置缓存filterCache documentCache queryResultCache ,这些缓存都是被IndexSearcher所管理。

1.用户发起一个查询请求后,请求首先被请求处理器接收
2.请求处理器会将搜索的查询字符串,交由QueryParser解析
3.解析完成后会生成Query对象,由IndexSearcher来执行查询。
在Solr中对IndexSearcher的实现类,叫SolrIndexSearcher。在SolrIndexSearcher中,管理了相关的缓存。
一个SolrIndexSearcher对应一套缓存体系,一般来说一个SolrCore只需要一个SolrIndexSearcher实例
在Solr中允许我们在solrConfig.xml的<query>标签下修改缓存的属性。
5.3.1 缓存公共属性
无论是那种缓存,都有4个相同属性。
class:设置缓存的实现类,solr内置了三个实现类。FastLRUCache,LRUCache,LFUCache
LRU和LFU是2种不同的缓存淘汰算法。
LRU算法的思想是:如果一个数据在最近一段时间没有被访问到,那么可以认为在将来它被访问的可能性也很小。因此,当缓存满时,最久没有访问的数据最先被置换(淘汰)。
LFU算法的思想是:如果一个数据在最近一段时间很少被访问到,那么可以认为在将来它被访问的可能性也很小。因此,当空间满时,最小频率访问的数据最先被淘汰。
size:cache中可保存的最大的项数。
initialSize:cache初始化时的大小。
autowarmCount:SolrCore重启(reload)的时候,Indexsearcher会重新创建,不过旧的SolrCore和旧的Indexsearcher会继续存在一段时间,autowarmCount表示从旧的缓存中获取多少项来在新的SolrIndexSearcher缓存中被重新生成。如果设置成0,表示SolrCore重启(reload)的时候,旧的缓存数据就不要了。我们把这个过程叫缓存预热。
5.3.2 缓存特有属性
不同的缓存类型有一些特有的属性。
FastLRUCache:
minSize:当cache达到size以后,使用淘汰策略使其降到minSize大小,默认是0.9*size;
acceptableSize:当淘汰数据时,首先会尝试删除到minSize,但可能会做不到,至少可以删除到acceptableSize,默认是0.95*size。
cleanupThread:它表示是否需要单独起一个线程来删除缓存项,当我们的缓存 size非常大时你可能会需要将此参数设置为 true,默认值false。因为当cache大小很大时,每一次的淘汰数据就可能会花费较长时间,这对于提供查询请求的线程来说就不太合适,由独立的后台线程来做就很有必要。
5.3.3 Solr查询缓存的分类和作用
filterCache
filterCache中存储的是满足过滤条件的document id集合。
什么时候filterCache会进行缓存。
(1)当我们执行一个查询,如果包含fq(可能会有多个),Solr会先执行每一个fq,对fq执行的结果取并集,之后将fq和q结果取并集。在这个过程中filerCache会将单个过滤条件(类型为Query)作为key,符合条件的document id存储到Set集合中作为value缓存起来。
(2)filterCache也会缓存Facet查询结果。
演示FilterCache
q:item_title:手机&
fq:item_brand:华为
item_price:[2000 TO 3000]

将来我们就可以根据后台的统计来设置filterCache的参数。
queryResultCache
查询结果集缓存,缓存的是查询结果集有序文档ID的集合,key是q和fq及sort组合的一个唯一标识。value是满足条件文档的id集合。
eg:查询q=item_title:手机 fq=item_brand:华为,item_price:[1000 TO 2000],并且按照价格排序;
会将q,fq及sort作为key将满足条件的文档id集合作为value缓存到queryResultCache。
要想命中缓存,需要保证q,fq,sort一致。

接下来我们再来说一下queryResult缓存的2个配置。
比如查询匹配的documentID是[0, 10)之间,queryResultWindowSize= 50,那么DocumentID [0, 50] 会被并缓存。
为什么这么做呢?原因是我们查询的时候可能会带有start和rows,如果所以某个QueryResultKey可能命中了cache,但是start和rows可能不在缓存的文档id集合范围。 可以使用参数来加大缓存的文档id集合范围。
<queryResultWindowSize>20</queryResultWindowSize>
value中最大存储的文档的id个数
<queryResultMaxDocsCached>200</queryResultMaxDocsCached>
这两个值一般设置为每个page大小的2-3倍。
documentCache
documentCache (即索引文档缓存)用于存储已经从磁盘上查询出来的Document 对象。键是文档id值是文档对象。
但是Document中并不会保存所有域的信息,只会保存fl中指定的域,如果没有指定则保存所有的域。
没有保存的域会标识为延迟加载,当我们需要延迟加载的域信息的时候,再从磁盘上进行查询。
5.4 其他优化建议
增大JVM的堆内存
需要在tomcat/catalina.sh文件中加入
JAVA_OPTS="$JAVA_OPTS -server -Xms2048m -Xmx2048m"
-Xms:初始Heap大小,使用的最小内存,cpu性能高时此值应设的大一些
-Xmx:java heap最大值,使用的最大内存
上面两个值是分配JVM的最小和最大内存,取决于硬件物理内存的大小,建议均设为物理内存的一半。
取消指定过滤查询的Filter缓存。
在Solr中默认会为每个FilterQuery 启用 Filter 缓存,大部分情况下这能提升查询性能,但是比如我们想要查询某个价格区间或者时间范围内的商品信息。
q=*:*,
fq=item_price:[0 TO 3000],
fq=item_brand:三星
但是对于每个用户而言,设置的价格区间参数可能是不一致的,有的用户提供的价格区间可能是 [20, 50],也有可能 [20 ,60] ,[30, 60],这种价格区间太多太多,如果对每个价格区间的 Filter Query都启用 Filter缓存就不太合适。
q=*:*
&fq={!cache=false}item_price:[0 TO 3000],
&fq=item_brand:三星
对于什么时候要禁用Filter缓存,我们需要判断,取决于这个Filter Query的查询条件有没有共性。item_brand:三星过滤条件就比较适合做缓存。因为品牌的值本身就比较少。价格区间、时间区间就不适合,因为区间范围有不确定性。就算你做了缓存,缓存的命中率也很低,对于我们内存也是一种浪费。
Filter Query的执行顺序。
假如我们的查询中有多个FilterQuery ,此时我们需要考虑每个 Filter Query 的执行顺序,因为Filter Query 的执行顺序可能会影响最终的查询的性能。
一般我们需要让能过滤掉大量文档的FilterQuery优先执行。我们当前有三个过滤条件,其中item_category:手机过滤能力最强,其次是item_brand:三星。设置cost参数,参数值越小,优先级越高。
q=*:*
&fq={!cache=false cost=100}item_price:[0 TO 3000],
&fq={!cost=2}item_brand:三星,
&fq={!cost=1}item_category:手机
6.Spring Data Solr(开发)
6.1 Spring Data Solr的简介
Spring Data Solr和SolrJ的关系
Spring Data Solr是Spring推出的对SolrJ封装的一套API,使用Spring Data Solr可以极大的简化编码。
Spring Data 家族还有其他的API,Spring Data Redis|JPA|MongoDB等。
Spring Data Solr的环境准备。
1.创建服务,继承父工程引入spring data solr的起步依赖
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.10.RELEASE</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-solr</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
2.编写启动类和yml配置文件。
在yml配置文件中,我们需要配置Solr的地址。
如果使用单机版的Solr配置host;指定solr服务的地址。
spring:
data:
solr:
host: http://localhost:8080/solr
如果使用集群版的solr配置zk-host,如果Zookeeper搭建了集群,地址中间使用,分割。
spring:
data:
solr:
zk-host: 192.168.200.131:2181,192.168.200.131:2182,192.168.200.131:2183
6.2 SolrTemplate
如果我们要使用Spring Data Solr来操作Solr,核心的API是SolrTemplate,所以首先我们需要在配置类中,将SolrTemplate交由spring管理;
@Bean
public SolrTemplate solrTemplate(SolrClient solrClient) {
return new SolrTemplate(solrClient);
}
6.2.1 索引
6.2.1.1添加
需求:添加一个商品。
1.创建一个商品实体类,并且建立实体类属性和域的映射关系。将来操作实体类对象,就是操作文档。
@Data
public class Item {
@Field("id")
@Id
private String id;
@Field("item_title")
private String title;
@Field("item_price")
private Double price;
@Field("item_images")
private String image;
@Field("item_createtime")
private Date createTime;
@Field("item_updatetime")
private Date updateTime;
@Field("item_category")
private String category;
@Field("item_brand")
private String brand;
}
2.注入SolrTemplate,使用saveBean方法完成添加操作
@Test
public void testSave() {
Item item = new Item();
item.setId("9999");
item.setBrand("锤子");
item.setTitle("锤子(SHARP) 智能锤子");
item.setCategory("手机");
item.setCreateTime(new Date());
item.setUpdateTime(new Date());
item.setPrice(9999.0);
item.setImage("https://www.baidu.com/img/bd_logo1.png");
solrTemplate.saveBean("collection1",item);
solrTemplate.commit("collection1");
}
- 在后台管理系统中进行查看

6.2.1.2 修改
如果文档id在索引库中已经存在就是修改;
@Test
public void testUpdate() {
Item item = new Item();
item.setId("9999");
item.setBrand("香蕉");
item.setTitle("香蕉(SHARP)LCD-46DS40A 46英寸 日本原装液晶面板 智能全高清平板电脑");
item.setCategory("平板电脑");
item.setCreateTime(new Date());
item.setUpdateTime(new Date());
item.setPrice(9999.0);
item.setImage("https://www.baidu.com/img/bd_logo1.png");
solrTemplate.saveBean("collection1",item);
solrTemplate.commit("collection1");
}
6.2.1.3 删除
支持基于id删除,支持基于条件删除。
基于id删除
@Test
public void testDeleteDocument() {
solrTemplate.deleteByIds("collection1", "9999");
solrTemplate.commit("collection1");
}
支持基于条件删除,删除collection1中所有的数据(删除所有数据要慎重)
@Test
public void testDeleteQuery(){
SolrDataQuery query = new SimpleQuery("*:*");
solrTemplate.delete("collection1",query);
solrTemplate.commit("collection1");
}
6.2.2 基本查询
6.2.2.1 主查询+过滤查询
核心的API方法:
/**
* 参数1:要操作的collection
* 参数2:查询条件
* 参数3: 查询的文档数据要封装成什么类型。
* 返回值ScoredPage是一个分页对象,封装了总记录数,总页数,当前页的数据。
*/
public <T> ScoredPage<T> queryForPage(String collection, Query query, Class<T> clazz);
需求:查询item_title中包含手机的文档
@Test
public void testBaseQuery() {
//条件封装
Query query = new SimpleQuery("item_title:手机");
//执行查询
ScoredPage<Item> scoredPage = solrTemplate.queryForPage("collection1", query, Item.class);
//解析结果
long elements = scoredPage.getTotalElements();
System.out.println("总记录数" + elements);
int totalPages = scoredPage.getTotalPages();
System.out.println("总页数" + totalPages);
//第一页的数据
List<Item> content = scoredPage.getContent();
for (Item item : content) {
System.out.println(item);
}
}
结果:总记录数,总页数是1页,说明没有分页。虽然没有分页。但是他并没有把716条数据都查询出来,只查询了满足条件并且相关度高的前10个。

接下来我们在这个基础上。我们进行过滤查询。添加过滤条件:品牌是华为,价格在[1000-2000].
@Test
public void testBaseQuery() {
//条件封装
Query query = new SimpleQuery("item_title:手机");
FilterQuery filterQuery=new SimpleFilterQuery();
//品牌:华为过滤条件
filterQuery.addCriteria(new Criteria("item_brand").is("华为"));
//价格:区间
filterQuery.addCriteria(new Criteria("item_price").greaterThanEqual(1000));
filterQuery.addCriteria(new Criteria("item_price").lessThanEqual(2000));
query.addFilterQuery(filterQuery);
//执行查询
ScoredPage<Item> scoredPage = solrTemplate.queryForPage("collection1", query, Item.class);
//解析结果
long elements = scoredPage.getTotalElements();
System.out.println("总记录数" + elements);
int totalPages = scoredPage.getTotalPages();
System.out.println("总页数" + totalPages);
//第一页的数据
List<Item> content = scoredPage.getContent();
for (Item item : content) {
System.out.println(item);
}
}
6.2.2.2分页
查询满足条件的第2页的10条数据
query.setOffset(20L); //start
query.setRows(10);//rows
查询结果

6.2.2.3 排序
需求:按照价格升序。如果价格相同,按照id降序。
query.addSort(new Sort(Sort.Direction.ASC,"item_price"));
query.addSort(new Sort(Sort.Direction.DESC,"id"));
6.2.3 组合查询
需求:查询Item_title中包含手机或者电视的文档。
Query query = new SimpleQuery("item_title:手机 OR item_title:电视");
Query query = new SimpleQuery("item_title:手机 || item_title:电视");
需求:查询Item_title中包含手机 并且包含三星的文档
Query query = new SimpleQuery("+item_title:手机 +item_title:三星");
Query query = new SimpleQuery("item_title:手机 AND item_title:三星");
Query query = new SimpleQuery("item_title:手机 && item_title:三星");
需求: 查询item_title中包含手机但是不包含三星的文档
Query query = new SimpleQuery("+item_title:手机 -item_title:三星");
Query query = new SimpleQuery("item_title:手机 NOT item_title:三星");
需求:查询item_title中包含iphone开头的词的文档,使用通配符。;
Query query = new SimpleQuery("item_title:iphone*");
6.3 其他查询
6.3.1 facet查询
之前我们讲解Facet查询,我们说他是分为4类。
Field,Query,Range(时间范围,数字范围),Interval(和Range类似)
6.3.1.1 基于Field的Facet查询
需求:查询item_title中包含手机的文档,并且按照品牌域进行分组统计数量;
http://localhost:8080/solr/collection1/select?q=item_title:手机&facet=on&facet.field=item_brand&facet.mincount=1
//查询条件
FacetQuery query = new SimpleFacetQuery(new Criteria("item_title").is("手机"));
//设置Facet相关的参数
FacetOptions facetOptions = new FacetOptions("item_brand");
facetOptions.addFacetOnField("item_brand");
facetOptions.setFacetMinCount(1);
//facet分页:页码从零开始
//facetOptions.setPageable(PageRequest.of(1,10));
query.setFacetOptions(facetOptions);
//执行Facet查询
FacetPage<Item> facetPage = solrTemplate.queryForFacetPage("collection1", query, Item.class);
//解析Facet的结果
//由于Facet的域可能是多个,需要指定名称
Page<FacetFieldEntry> facetResultPage = facetPage.getFacetResultPage("item_brand");
List<FacetFieldEntry> content = facetResultPage.getContent();
for (FacetFieldEntry facetFieldEntry : content) {
System.out.println(facetFieldEntry.getValue());
System.out.println(facetFieldEntry.getValueCount());
}
6.3.1.2 基于Query的Facet查询
需求:查询分类是平板电视的商品数量 ,品牌是华为的商品数量 ,品牌是三星的商品数量,价格在1000-2000的商品数量;
http://localhost:8080/solr/collection1/select?
q=*:*&
facet=on&
facet.query=item_category:平板电视&
facet.query=item_brand:华为&
facet.query=item_brand:三星&
facet.query=item_price:%5B1000 TO 2000%5D
@Test
public void testQueryFacet() {
//主查询条件,查询所有
FacetQuery query = new SimpleFacetQuery(new SimpleStringCriteria("*:*"));
//设置Facet相关的参数
//定义4个query
SolrDataQuery solrDataQuery1 = new SimpleQuery("{!key=pb}item_category:平板电视");
SolrDataQuery solrDataQuery2 = new SimpleQuery("{!key=hw}item_brand:华为");
SolrDataQuery solrDataQuery3 = new SimpleQuery("{!key=sx}item_brand:三星");
SolrDataQuery solrDataQuery4 = new SimpleQuery(new Criteria("{!key=price}item_price").between(1000,2000));
FacetOptions facetOptions = new FacetOptions();
facetOptions.addFacetQuery(solrDataQuery1);
facetOptions.addFacetQuery(solrDataQuery2);
facetOptions.addFacetQuery(solrDataQuery3);
facetOptions.addFacetQuery(solrDataQuery4);
query.setFacetOptions(facetOptions);
//执行Facet查询
FacetPage<Item> facetPage = solrTemplate.queryForFacetPage("collection1", query, Item.class);
//获取分页结果
Page<FacetQueryEntry> facetQueryResult = facetPage.getFacetQueryResult();
//获取当前页数据
List<FacetQueryEntry> content = facetQueryResult.getContent();
for (FacetQueryEntry facetQueryEntry : content) {
System.out.println(facetQueryEntry.getValue());
System.out.println(facetQueryEntry.getValueCount());
}
}
6.3.1.3 基于Range的Facet查询
需求:分组查询价格0-2000 ,2000-4000,4000-6000....18000-20000每个区间商品数量
http://localhost:8080/solr/collection1/select?
q=*:*&
facet=on&
facet.range=item_price&
facet.range.start=0&
facet.range.end=20000&
facet.range.gap=2000&
&facet.range.other=all
@Test
public void testRangeFacet() {
//设置主查询条件
FacetQuery query = new SimpleFacetQuery(new SimpleStringCriteria("*:*"));
//设置Facet参数
FacetOptions facetOptions = new FacetOptions();
facetOptions.addFacetByRange(new FacetOptions.FieldWithNumericRangeParameters("item_price", 0, 20000, 2000));
query.setFacetOptions(facetOptions);
//执行Facet查询
FacetPage<Item> facetPage = solrTemplate.queryForFacetPage("collection1", query, Item.class);
//解析Facet的结果
Page<FacetFieldEntry> page = facetPage.getRangeFacetResultPage("item_price");
List<FacetFieldEntry> content = page.getContent();
for (FacetFieldEntry facetFieldEntry : content) {
System.out.println(facetFieldEntry.getValue());
System.out.println(facetFieldEntry.getValueCount());
}
}
需求:统计2015年每个季度添加的商品数量
http://localhost:8080/solr/collection1/select?
q=*:*&
facet=on&
facet.range=item_createtime&
facet.range.start=2015-01-01T00:00:00Z&
facet.range.end=2016-01-01T00:00:00Z&
facet.range.gap=%2B3MONTH
@Test
public void testRangeDateFacet() throws ParseException {
//设置主查询条件
FacetQuery query = new SimpleFacetQuery(new SimpleStringCriteria("*:*"));
//设置Facet参数
FacetOptions facetOptions = new FacetOptions();
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
simpleDateFormat.setTimeZone(TimeZone.getTimeZone("GMT+8:00"));
//facet为0的也可以查询出来
facetOptions.setFacetMinCount(0);
Date start = simpleDateFormat.parse("2015-01-01 00:00:00");
Date end = simpleDateFormat.parse("2016-01-01 00:00:00");
facetOptions.addFacetByRange(new FacetOptions.FieldWithDateRangeParameters("item_createtime", start, end, "+3MONTH"));
query.setFacetOptions(facetOptions);
//执行Facet查询
FacetPage<Item> facetPage = solrTemplate.queryForFacetPage("collection1", query, Item.class);
//解析Facet的结果
Page<FacetFieldEntry> page = facetPage.getRangeFacetResultPage("item_createtime");
List<FacetFieldEntry> content = page.getContent();
for (FacetFieldEntry facetFieldEntry : content) {
System.out.println(facetFieldEntry.getValue());
System.out.println(facetFieldEntry.getValueCount());
}
}
6.3.1.4 Facet维度查询
需求:统计每一个品牌和其不同分类商品对应的数量;
联想 手机 10
联想 电脑 2
华为 手机 10
http://localhost:8080/solr/collection1/select?
q=*:*&
&facet=on
&facet.pivot=item_brand,item_category
@Test
public void intervalFacet() {
//设置主查询条件
FacetQuery query = new SimpleFacetQuery(new SimpleStringCriteria("*:*"));
//设置Facet查询参数
FacetOptions facetOptions = new FacetOptions();
facetOptions.addFacetOnPivot("item_brand","item_category");
query.setFacetOptions(facetOptions);
//执行Facet查询
FacetPage<Item> facetPage = solrTemplate.queryForFacetPage("collection1", query, Item.class);
//解析Facet结果
List<FacetPivotFieldEntry> pivot = facetPage.getPivot("item_brand,item_category");
for (FacetPivotFieldEntry facetPivotFieldEntry : pivot) {
//品牌分组
System.out.println(facetPivotFieldEntry.getValue());
System.out.println(facetPivotFieldEntry.getValueCount());
//品牌下对应的分类的分组数据
List<FacetPivotFieldEntry> fieldEntryList = facetPivotFieldEntry.getPivot();
for (FacetPivotFieldEntry pivotFieldEntry : fieldEntryList) {
System.out.println(" "+pivotFieldEntry.getValue());
System.out.println(" " +pivotFieldEntry.getValueCount());
}
}
}
6.3.2 group查询
使用Group查询可以将同组文档进行归并。在Solr中是不支持多维度group。group的域可以是多个,但是都是独立的。
6.3.2.1 基础的分组
需求:查询Item_title中包含手机的文档,按照品牌对文档进行分组,同组中的文档放在一起.
http://localhost:8080/solr/collection1/select?
q=item_title:手机
&group=true
&group.field=item_brand
//设置主查询条件
Query query = new SimpleQuery("item_title:手机");
//设置分组参数
GroupOptions groupOptions = new GroupOptions();
groupOptions.addGroupByField("item_brand");
groupOptions.setOffset(0);
query.setGroupOptions(groupOptions);
//执行分组查询
GroupPage<Item> groupPage = solrTemplate.queryForGroupPage("collection1", query, Item.class);
//解析分组结果,由于分组的域可能是多个,需要根据域名获取分组
GroupResult<Item> groupResult = groupPage.getGroupResult("item_brand");
System.out.println("匹配到的文档数量" + groupResult.getMatches());
//获取分组数据
Page<GroupEntry<Item>> groupEntries = groupResult.getGroupEntries();
List<GroupEntry<Item>> content = groupEntries.getContent();
//迭代每一个分组数据,包含组名称,组内文档数据
for (GroupEntry<Item> itemGroupEntry : content) {
String groupValue = itemGroupEntry.getGroupValue();
System.out.println("组名称" + groupValue);
//组内文档数据
Page<Item> result = itemGroupEntry.getResult();
List<Item> itemList = result.getContent();
for (Item item : itemList) {
System.out.println(item);
}
}
}
6.3.2.2 group分页
默认情况下group查询只会展示前10个组,并且每组展示相关对最高的1个文档。我们可以使用start和rows可以设置组的分页,使用group.limit和group.offset设置组内文档分页。
展示前3个组及每组前5个文档。
http://localhost:8080/solr/collection1/select?
q=item_title:手机&group=true&group.field=item_brand&start=0&rows=3&group.limit=5&group.offset=0
//设置组的分页参数
query.setOffset(0L);
query.setRows(3);
//设置组内文档的分页参数
groupOptions.setOffset(0);
groupOptions.setLimit(5);
6.3.2.3 group排序
之前讲解group排序的时候,group排序分为组排序,组内文档排序;对应的参数为sort和group.sort
需求:按照组内价格排序降序;
groupOptions.addSort(new Sort(Sort.Direction.DESC,"item_price"));
6.3.3 高亮
6.3.3.1 高亮查询
查询item_title中包含手机的文档,并且对item_title中的手机关键字进行高亮;
http://localhost:8080/solr/collection1/select?
q=item_title:手机
&hl=true
&hl.fl=item_title
&hl.simple.pre=<font>
&simpletag.post=</font>
@Test
public void testHighlightingQuery() throws IOException, SolrServerException {
//指定查询条件
HighlightQuery query = new SimpleHighlightQuery(new Criteria("item_title").is("手机"));
//设置高亮参数
HighlightOptions highlightOptions = new HighlightOptions();
highlightOptions.addField("item_title");
highlightOptions.setSimplePrefix("<font>");
highlightOptions.setSimplePostfix("</font>");
query.setHighlightOptions(highlightOptions);
//执行高亮查询
HighlightPage<Item> highlightPage = solrTemplate.queryForHighlightPage("collection1", query, Item.class);
//获取满足条件的文档数据
List<Item> content = highlightPage.getContent();
for (Item item : content) {
System.out.println(content);
}
//解析高亮数据
List<HighlightEntry<Item>> highlighted = highlightPage.getHighlighted();
for (HighlightEntry<Item> highlightEntry : highlighted) {
Item item = highlightEntry.getEntity();
List<HighlightEntry.Highlight> highlights = highlightEntry.getHighlights();
if(highlights != null && highlights.size() > 0) {
List<String> snipplets = highlights.get(0).getSnipplets();
if(snipplets != null && highlights.size() >0) {
String s = snipplets.get(0);
item.setTitle(s);
}
}
}
}
}
6.3.3.2 高亮器的切换
需求:查询item_title中包含三星手机的文档,要求item_title中三星手机中不同的词,显示不同的颜色;
http://localhost:8080/solr/collection1/select?
q=item_title:三星手机
&hl=true
&hl.fl=item_title
&hl.method=fastVector
highlightOptions.addHighlightParameter("hl.method", "fastVector");
6.3.4 suggest查询
6.3.4.1 spell-checking 拼写检查。
要完成拼写检查,首先我们需要在SolrConfig.xml中进行相关的配置。在之前课程中已经讲解完毕,并且已经配置过了。
需求:查询item_title中包含:iphoneX galaxz 的内容。要求进行拼写检查。
http://localhost:8080/solr/collection1/select?q=item_title:iphoneX galaxz&spellcheck=true
对于我们来说,我们就需要通过Spring Data Solr将正确的词提取处理。
@Test
public void test01() throws IOException, SolrServerException {
//查询item_title中包含iphonexX Galaxz的
SimpleQuery q = new SimpleQuery("item_title:iphonxx Galaxz");
q.setSpellcheckOptions(SpellcheckOptions.spellcheck().extendedResults());
SpellcheckedPage<Item> page = solrTemplate.query("collection1",q, Item.class);
long totalElements = page.getTotalElements();
if(totalElements == 0) {
Collection<SpellcheckQueryResult.Alternative> alternatives = page.getAlternatives();
for (SpellcheckQueryResult.Alternative alternative : alternatives) {
System.out.println(alternative.getTerm());
System.out.println(alternative.getSuggestion());
}
}
}
6.3.4.2Auto Suggest自动建议。
自动建议的API,在Spring Data Solr中没有好像没有封装。官方API没有找到。
我们需要使用SolrJ中的API完成。在Spring Data Solr中如何使用SolrJ的API呢?
1.注入SolrClient-------->HttpSolrClient CloudSolrClient,取决于我们在YML中配置的是单机还是集群。
2.通过SolrTemplate获取SolrClient。本身SolrTemplate封装SolrClient
3.参考之前课程中SolrJ完成查询建议的代码。
6.3.5 Join查询
准备:需要将员工的信息导入collection1,将部门信息导入到collection2
需求:查询部门名称为SALES下的员工信息。
主查询条件q=*:*
过滤条件fq={!join fromIndex=collection2 toIndex=collection1 from=id to=emp_deptno}dept_dname:SALES
Spring Data Solr 完成 Join查询
创建Emp的实体类,并且建立实体类属性和域字段映射关系
@Data
public class Emp {
@Field("id")
@Id
private String empno;
@Field("emp_ename")
private String ename;
@Field("emp_job")
private String job;
@Field("emp_mgr")
private String mgr;
@Field("emp_hiredate")
private String hiredate;
@Field("emp_sal")
private String sal;
@Field("emp_comm")
private String comm;
private String cv;
@Field("emp_deptno")
private String deptno;
}
代码
@Test
public void test03() {
//主查询条件
Query query = new SimpleQuery("*:*");
//过滤条件collection2中dept_name是SALES
SimpleFilterQuery simpleFilterQuery = new SimpleFilterQuery(new Criteria("dept_dname").is("SALES"));
//使用Join建立子查询关系
Join join = new Join.Builder("id").fromIndex("collection2").to("emp_deptno");
simpleFilterQuery.setJoin(join);
query.addFilterQuery(simpleFilterQuery);
ScoredPage<Emp> scoredPage = solrTemplate.queryForPage("collection1", query, Emp.class);
List<Emp> content = scoredPage.getContent();
for (Emp emp : content) {
System.out.println(emp);
}
}
J的API呢?
1.注入SolrClient-------->HttpSolrClient CloudSolrClient,取决于我们在YML中配置的是单机还是集群。
2.通过SolrTemplate获取SolrClient。本身SolrTemplate封装SolrClient
3.参考之前课程中SolrJ完成查询建议的代码。
6.3.5 Join查询
准备:需要将员工的信息导入collection1,将部门信息导入到collection2
需求:查询部门名称为SALES下的员工信息。
主查询条件q=*:*
过滤条件fq={!join fromIndex=collection2 toIndex=collection1 from=id to=emp_deptno}dept_dname:SALES
Spring Data Solr 完成 Join查询
创建Emp的实体类,并且建立实体类属性和域字段映射关系
@Data
public class Emp {
@Field("id")
@Id
private String empno;
@Field("emp_ename")
private String ename;
@Field("emp_job")
private String job;
@Field("emp_mgr")
private String mgr;
@Field("emp_hiredate")
private String hiredate;
@Field("emp_sal")
private String sal;
@Field("emp_comm")
private String comm;
private String cv;
@Field("emp_deptno")
private String deptno;
}
代码
@Test
public void test03() {
//主查询条件
Query query = new SimpleQuery("*:*");
//过滤条件collection2中dept_name是SALES
SimpleFilterQuery simpleFilterQuery = new SimpleFilterQuery(new Criteria("dept_dname").is("SALES"));
//使用Join建立子查询关系
Join join = new Join.Builder("id").fromIndex("collection2").to("emp_deptno");
simpleFilterQuery.setJoin(join);
query.addFilterQuery(simpleFilterQuery);
ScoredPage<Emp> scoredPage = solrTemplate.queryForPage("collection1", query, Emp.class);
List<Emp> content = scoredPage.getContent();
for (Emp emp : content) {
System.out.println(emp);
}
}















 875
875











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









