







 本文主要探讨了Android 22版HashMap的数据结构和实现原理。HashMap是基于哈希表的,提供快速的查找、添加和删除操作。其内部使用了Entry数组和加载因子,当元素数量超过容量与加载因子的乘积时,会进行扩容。HashMap是线程不安全的,适合单线程环境。文章详细阐述了HashMap的构造函数、HashMapEntry节点结构、添加和删除键值对的逻辑,并提及了Wang/Jenkins哈希算法在分布均匀性上的作用。
本文主要探讨了Android 22版HashMap的数据结构和实现原理。HashMap是基于哈希表的,提供快速的查找、添加和删除操作。其内部使用了Entry数组和加载因子,当元素数量超过容量与加载因子的乘积时,会进行扩容。HashMap是线程不安全的,适合单线程环境。文章详细阐述了HashMap的构造函数、HashMapEntry节点结构、添加和删除键值对的逻辑,并提及了Wang/Jenkins哈希算法在分布均匀性上的作用。
最近在学习数据结构和算法,对于一开始就接触java语言的我来说,感觉数据结构离java很远(当然是jdk封装的好啦)。为了更好的结合所学语言理解数据结构,就决定学习一下java中hashmap的实现原理。
先声明一下本人所看的源码是android-22的hashmap源码
简单介绍下哈希表
哈希表
Hash table,也叫散列表,是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
切入正题 HashMap
public class HashMap<K, V> extends AbstractMap<K, V> implements Cloneable, Serializablehashmap是继承了abstractmap,并且实现了serializable、cloneable接口。源码中的NOTE主要有以下几点:
1、任何元素都可以当作map中的key和value,当然null也是可以的。
2、hashmap是线程不安全的类,当多个线程对同一个hashmap进行操作时,需要同步处理。
3、hashmap在使用迭代器的时候是不确定的(重新迭代出的键值对的顺序与原来的不一致),LinkedHashMap是迭代时是一致的。
hashmap的字段
首先先介绍下hashmap中最重要的两个参数:初始容量和加载因子。容量是哈希表中桶(Entry数组)的数量,初始容量只是哈希表在创建时的容量。加载因子是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,通过调用 rehash 方法将容量翻倍。
通常,默认加载因子 (0.75) 在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查询成本(在大多数 HashMap 类的操作中,包括 get 和 put 操作,都反映了这一点)。在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少 rehash 操作次数。如果初始容量大于最大条目数除以加载因子,则不会发生 rehash 操作。
默认的最小的容量
private static final int MINIMUM_CAPACITY = 4
默认的最大的容量
private static final int MAXIMUM_CAPACITY = 1 << 30
注意hashmap的容量都是2的次幂数,这里默认的最小容量为2^2=4 最大容量为2^30。
实例化一个EMPTY_TABLE 大小为最小容量的一半,默认的构造函数的表就是这个。
private static final Entry[] EMPTY_TABLE = new HashMapEntry[MINIMUM_CAPACITY >>> 1]
默认的加载因子为0.75
static final float DEFAULT_LOAD_FACTOR =0 .75F
threshold = capacity*load_factor当map的size大于此值得时候就需要进行rehash动作
private transient int threshold
上面列举的是比较重要的字段,其他字段就不多做解释(像size、modCount等)
构造函数

先看无参构造函数
public HashMap() {
table = (HashMapEntry<K, V>[]) EMPTY_TABLE;
threshold = -1; // Forces first put invocation to replace EMPTY_TABLE
}其中EMPTY_TABLE早就实例化好了,它是一个具有默认初始容量(2)和默认的加载因子(0.75)的空hashmap.
再看两个参数的构造函数
public HashMap(int capacity, float loadFactor) {
this(capacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor)) {
throw new IllegalArgumentException("Load factor: " + loadFactor);
}
}这个构造函数虽说有loadFactor这个参数,但是从源代码来看,说白了不会对加载因子的值做修改,仅仅对加载因子进行判断,保证它的值是数并且大于0。其实这个构造函数的作用和public HashMap(int capacity) 一样的。
public HashMap(int capacity) {
if (capacity < 0) {
throw new IllegalArgumentException("Capacity: " + capacity);
}
if (capacity == 0) {
@SuppressWarnings("unchecked")
HashMapEntry<K, V>[] tab = (HashMapEntry<K, V>[]) EMPTY_TABLE;
table = tab;
threshold = -1; // Forces first put() to replace EMPTY_TABLE
return;
}
if (capacity < MINIMUM_CAPACITY) {
capacity = MINIMUM_CAPACITY;
} else if (capacity > MAXIMUM_CAPACITY) {
capacity = MAXIMUM_CAPACITY;
} else {
capacity = Collections.roundUpToPowerOfTwo(capacity);
}
makeTable(capacity);
}这个构造函数先是对capacity的值进行一系列的判断,如下图:
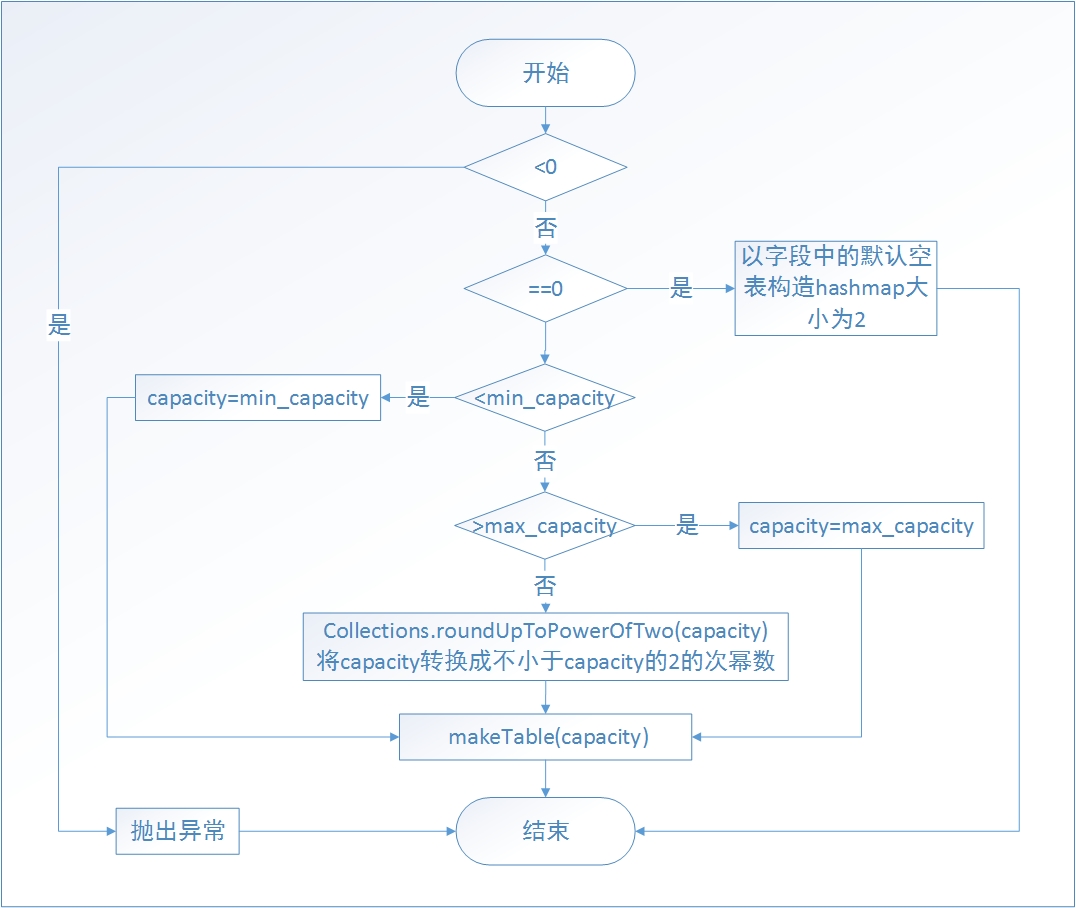
最终通过 makeTable(capacity)进行建表工作。
private HashMapEntry<K, V>[] makeTable(int newCapacity) {
@SuppressWarnings("unchecked") HashMapEntry<K, V>[] newTable
= (HashMapEntry<K, V>[]) new HashMapEntry[newCapacity];
table = newTable;
threshold = (newCapacity >> 1) + (newCapacity >> 2); // 3/4 capacity
return newTable;
}HashMapEntry
从上面的makeTable(capacity)可以看出其实hashmap中维护着一个HashMapEntry的数组,那么我们先来看看HashMapEntry这个类的具体实现。HashMapEntry是实现entry这个接口。构造函数如下:
HashMapEntry(K key, V value, int hash, HashMapEntry<K, V> next) {
this.key = key;
this.value = value;
this.hash = hash;
this.next = next;
}HashMapEntry的实现是使用单链表的方式,保存了三个字段,key、value、hash值,并用next链接到下一个HashMapEntry上。
HashMapEntry提供的方法有:
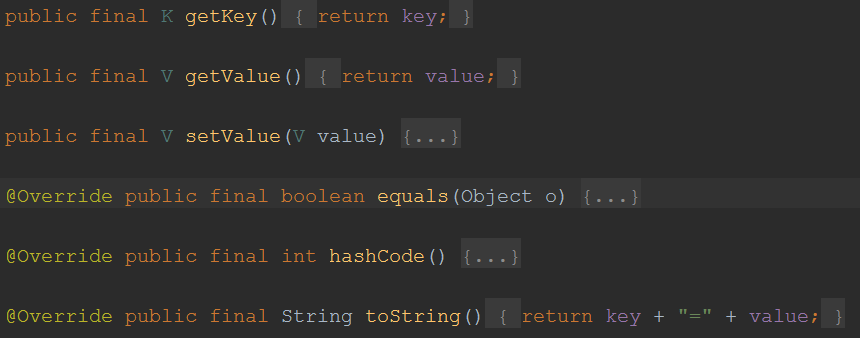
看一下hashcode方法
public final int hashCode() {
return (key == null ? 0 : key.hashCode())^(value == null ? 0 : value.hashCode());
}可以看出HashMapEntry的hash值是通过key和value两个的hash值计算的。
再来看一下equals方法
public final boolean equals(Object o) {
if (!(o instanceof Entry)) {
return false;
}
Entry<?, ?> e = (Entry<?, ?>) o;
return Objects.equal(e.getKey(), key)
&& Objects.equal(e.getValue(), value);
}HashMapEntry的equals方法是通过key对象的equals方法和valuey对象的equals方法决定的。
接下看看集合类的通用方法:对对象的添加、删除、查找和修改。
添加键值对
public V put(K key, V value) {
if (key == null) {
return putValueForNullKey(value);
}
int hash = Collections.secondaryHash(key);
HashMapEntry<K, V>[] tab = table;
int index = hash & (tab.length - 1);
for (HashMapEntry<K, V> e = tab[index]; e != null; e = e.next) {
if (e.hash == hash && key.equals(e.key)) {
preModify(e);
V oldValue = e.value;
e.value = value;
return oldValue;
}
}
// No entry for (non-null) key is present; create one
modCount++;
if (size++ > threshold) {
tab = doubleCapacity();
index = hash & (tab.length - 1);
}
addNewEntry(key, value, hash, index);
return null;
}可以看出对于添加键值对的操作,hashmap的做法主要是通过对key值的哈希值进行映射,最后寻找到键值对在数组中存储的位置。主要分为两步骤:
1、int hash = Collections.secondaryHash(key);
2、 int index = hash & (tab.length - 1);
先看看第一步中干了什么。
public static int secondaryHash(Object key) {
return secondaryHash(key.hashCode());
}
private static int secondaryHash(int h) {
// Spread bits to regularize both segment and index locations,
// using variant of single-word Wang/Jenkins hash.
h += (h << 15) ^ 0xffffcd7d;
h ^= (h >>> 10);
h += (h << 3);
h ^= (h >>> 6);
h += (h << 2) + (h << 14);
return h ^ (h >>> 16);
}secondaryHash中首先获取到key的哈希值,之后利用Wang/Jenkins hash算法计算出对应的哈希值。
第二步其实很简单,但是此处另有玄机。
经过上面的源码分析,我们已经知道HashMap中的数据结构是数组+单链表的组合,我们希望的是元素存放的更均匀,最理想的效果是,Entry数组中每个位置都只有一个元素,这样,查询的时候效率最高,不需要遍历单链表,也不需要通过equals去比较K,而且空间利用率最大。那如何计算才会分布最均匀呢?我们首先想到的就是%运算。而源码里并非使用直接的%运算,而是采用位运算而对上一步计算出来的值进行处理。
int index = hash & (tab.length - 1);
上文中说hashmap的大小一定是2的次幂数,这里好像解释了这个问题。只有当hashmap的大小为2的次幂数时,位运算的值才会等于取余的值。那么问题又来了。
Q:既然使用取余就可以让hashmap的大小没有额外的规定(这里指的是大小必须是2的次幂数),为什么不用取余运算呢?
A:我猜测,由于位运算的效率要远远高于取余运算,而hashmap在进行各种操作(添加、删除、查找、修改等)都会将key值的哈希值进行映射,那就必须要进行上面的步骤,这种频繁的工作,使用效率高一点的要好很多。这是一个很好的使用空间换时间的例子。
继续看添加键值对的源代码。利用位运算的结果(对应着entry数组的下角标)就可以找到数据要存放的位置了。其中的逻辑我配图简单说明一下:
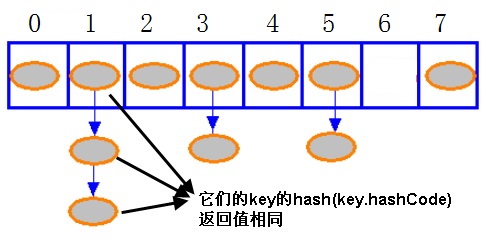
先判断entry数组中相应下角标的值是否为空,如果不为空的就开始遍历其中的单链表,例如图中的1位置中的entry链表,这其中的元素,他们通过Wang/Jenkins hash算法计算出的值是一样的,这就需要通过key是否相等来判断是否是同一个entry。如果是的话,就直接修改entry中的value。不是的话,就插入到此单链表中(这里是从头插入)。而对于entry数组中相应下角标的值为空的话,也就直接插入(同样也是从头插入)。所以插入的动作可以一起完成,只需要对特定的条件(通过Wang/Jenkins hash算法计算出的值是一样的并且key的值也是一样的)进行特定的修改动作。
void addNewEntry(K key, V value, int hash, int index) {
table[index] = new HashMapEntry<K, V>(key, value, hash, table[index]);
}至此就将hashmap中的添加键值对的过程解释清楚了。这其中也就包含了修改的过程(通过Wang/Jenkins hash算法计算出的值是一样的并且key的值也是一样的,此时的添加过程就是修改的过程)知道了添加的过程,接下来的查看与删除的过程就简单了。
删除键值对
map中的查看有以下三种:
1、通过键值查找对应的value:get(Object key)
2、判断是否有此key值:containsKey(Object key)
3、判断是否有此value值:containsValue(Object value)
public V get(Object key) {
if (key == null) {
HashMapEntry<K, V> e = entryForNullKey;
return e == null ? null : e.value;
}
int hash = Collections.secondaryHash(key);
HashMapEntry<K, V>[] tab = table;
for (HashMapEntry<K, V> e = tab[hash & (tab.length - 1)];
e != null; e = e.next) {
K eKey = e.key;
if (eKey == key || (e.hash == hash && key.equals(eKey))) {
return e.value;
}
}
return null;
}public boolean containsKey(Object key) {
if (key == null) {
return entryForNullKey != null;
}
int hash = Collections.secondaryHash(key);
HashMapEntry<K, V>[] tab = table;
for (HashMapEntry<K, V> e = tab[hash & (tab.length - 1)];
e != null; e = e.next) {
K eKey = e.key;
if (eKey == key || (e.hash == hash && key.equals(eKey))) {
return true;
}
}
return false;
}public boolean containsValue(Object value) {
HashMapEntry[] tab = table;
int len = tab.length;
if (value == null) {
for (int i = 0; i < len; i++) {
for (HashMapEntry e = tab[i]; e != null; e = e.next) {
if (e.value == null) {
return true;
}
}
}
return entryForNullKey != null && entryForNullKey.value == null;
}
// value is non-null
for (int i = 0; i < len; i++) {
for (HashMapEntry e = tab[i]; e != null; e = e.next) {
if (value.equals(e.value)) {
return true;
}
}
}
return entryForNullKey != null && value.equals(entryForNullKey.value);
}不管是get、containsKey还是containsValue他们的实现逻辑都差不多,这里就不解释了。不得提一句containsValue的查找速度要慢很多,主要是map在存储的时候使用的是key的哈希值经过运算作为数组的索引的,所以对于key的搜索要快很多。而对于value的搜索则需要将数组中的每个链表都要遍历一次(最坏的打算)。
删除键值对
删除源代码
public V remove(Object key) {
if (key == null) {
return removeNullKey();
}
int hash = Collections.secondaryHash(key);
HashMapEntry<K, V>[] tab = table;
int index = hash & (tab.length - 1);
for (HashMapEntry<K, V> e = tab[index], prev = null;
e != null; prev = e, e = e.next) {
if (e.hash == hash && key.equals(e.key)) {
if (prev == null) {
tab[index] = e.next;
} else {
prev.next = e.next;
}
modCount++;
size--;
postRemove(e);
return e.value;
}
}
return null;
}这里主要是链表的操作,因为是单链表的原因,遍历的时候,需要记录删除元素的上一个元素,以便将他的next指向删除元素的下一个元素。
上述详细介绍了hashMap中的正常键值对的操作,对于key=null,value!=null、key!=null,value=null、key=null,value=null这三种情况的操作请大家自行分析。















 216
216

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









