







 DETR是Facebook提出的端到端目标检测框架,基于Transformer,摒弃了以往检测器复杂的架构,实现了直接从输入图像到输出框和类别的转换。本文深入介绍了Transformer的发展,从Attention机制到DETR,再到Deformable DETR,阐述了Transformer在NLP和视觉领域的应用,并详细解析了DETR的结构和工作原理,包括自我注意力和多头注意力机制。此外,还探讨了匈牙利算法在匹配预测框和 ground truth 中的作用,以及位置编码的重要性。
DETR是Facebook提出的端到端目标检测框架,基于Transformer,摒弃了以往检测器复杂的架构,实现了直接从输入图像到输出框和类别的转换。本文深入介绍了Transformer的发展,从Attention机制到DETR,再到Deformable DETR,阐述了Transformer在NLP和视觉领域的应用,并详细解析了DETR的结构和工作原理,包括自我注意力和多头注意力机制。此外,还探讨了匈牙利算法在匹配预测框和 ground truth 中的作用,以及位置编码的重要性。
论文标题:End-to-End Object Detection with Transformers
论文官方地址:https://ai.facebook.com/research/publications/end-to-end-object-detection-with-transformers
个人整理的PPT(可编辑),下载地址:DETR学习分享.pptx-深度学习文档类资源-CSDN下载transform相关文章分享,DETR:End-to-EndObjectDetectionw更多下载资源、学习资料请访问CSDN下载频道.![]() https://download.csdn.net/download/wsLJQian/38922353
https://download.csdn.net/download/wsLJQian/38922353
B站视频学习(推荐):
下面是对上述PPT内容的简单罗列和讲解,由于Word转图存在问题,可能部分内容不能全面展示,建议下载上述文档后,再继续学习。
如果您觉得本篇文章对你有帮助,欢迎点赞,让更多人看到,这是对我继续写下去的鼓励。如果能再点击下方的红包打赏,给博主来一杯咖啡,那就太好了。

DETR全程是End-to-End Object Detection with Transformers,他是基于attention注意力机制发展出来的一种网络结构算法。
后面我们会沿着attention--->DETR--->Deformable DETR 这三个方面展开。看完整片文章,会让你对transformer,以及单attention如何使用,有个较深的认识。下面我们开始吧。
Attention机制最早在视觉领域提出,2014年Google Mind发表了《Recurrent Models of Visual Attention》,使Attention机制流行起来,这篇论文采用了RNN模型,并加入了Attention机制来进行图像的分类。
Recurrent Models of Visual Attentionhttp://de.arxiv.org/pdf/1406.6247![]() http://de.arxiv.org/pdf/1406.62472015年,Bahdanau等人在论文《Neural Machine Translation by Jointly Learning to Align and Translate》中,将attention机制首次应用在nlp领域,其采用Seq2Seq+Attention模型来进行机器翻译,并且得到了效果的提升。
http://de.arxiv.org/pdf/1406.62472015年,Bahdanau等人在论文《Neural Machine Translation by Jointly Learning to Align and Translate》中,将attention机制首次应用在nlp领域,其采用Seq2Seq+Attention模型来进行机器翻译,并且得到了效果的提升。
这篇论文是在自然语言处理(NLP)中或是encoder-decoder中第一个使用attention机制的工作,将attention机制用到了神经网络机器翻译(NMT) 。
2017 年,Google 机器翻译团队发表的《Attention is All You Need》中,完全抛弃了RNN和CNN等网络结构,而仅仅采用Attention机制来进行机器翻译任务,并且取得了很好的效果,注意力机制也成为了大家近期的研究热点。
从上面关于transform的发展历程,可以看出来。transform是基于attention机制发展起来的,尤其是在2015年和2017年两篇在翻译领域的重量级文章,推动了目前transform结构的完善。
1、Attention引入
在NLP翻译领域,输入是一串连续的英文,输出是一串连续的中文,这样就实现了最基本的英到中的翻译。
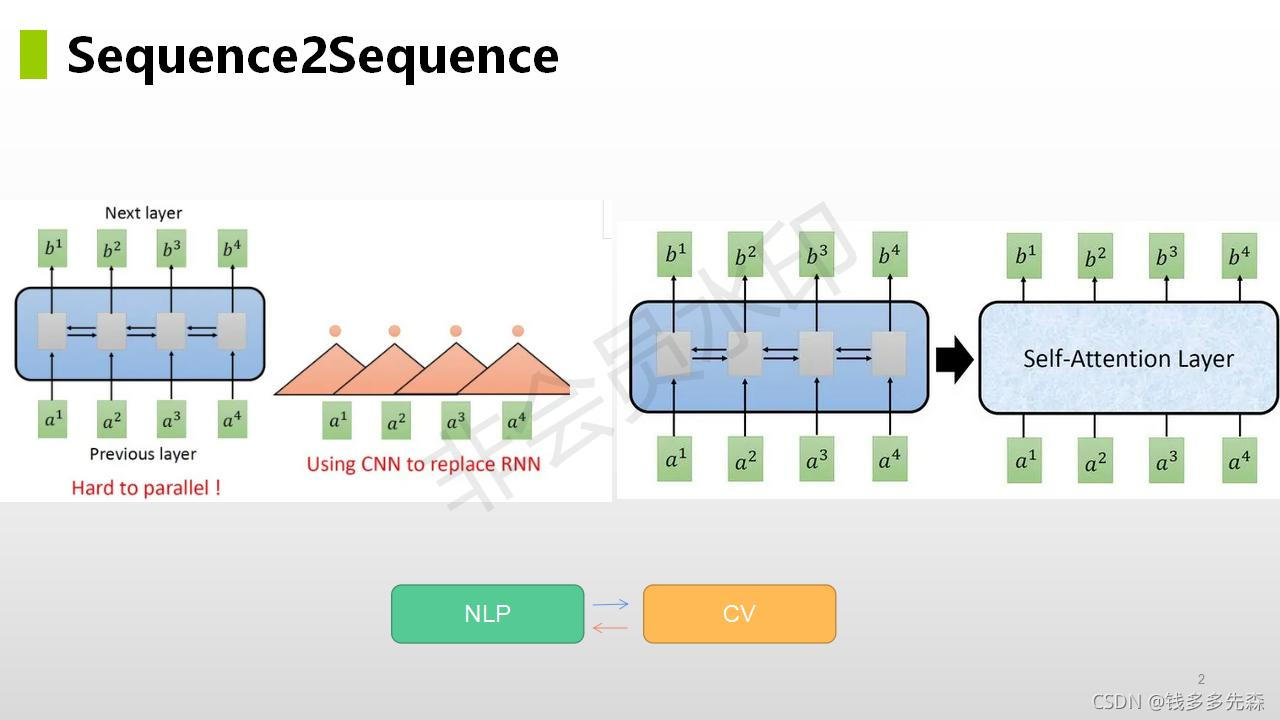
假定输入的一串是英文a1、a2、a3、a4,那么对应的输出就是b1、b2、b3、b4(输出字符长度也可能不对等)。

(摘自attention is all you need)
上图,在循环神经网络RCNN中,下一个时刻的输出 ht 要依赖于上一个时刻的输出 ht-1,从而导致无法在整个序列上进行并行处理,这会引起训练时间过长的问题。这样就没法实现翻译预测阶段的并行化,效率会相对比较低。
RNN 循环神经网络的缺点和不足:
- 时序机制,难以并行化
- 只依赖于最后state的状态很难利用句子中的结构信息
- 很早期的信息,会在后面时期的预测中,被遗忘掉(使用较大的ht,但是会较大的内存开销)

(摘自attention is all you need)
上图,为了解决RNN由于时许导致存在的无法并行化的问题,Facebook AI Research选择提出用CNN方式,解决这个问题,提出了《Convolutional Sequence to Sequence Learning》,也就是上面截图中ConvS2S的论文。
Convolutional Sequence to Sequence Learninghttps://arxiv.org/pdf/1705.03122.pdf![]() https://arxiv.org/pdf/1705.03122.pdf论文中最主要的结构图,如下所示,最最典型的部分就是对输入数据进行编码时采用的Convolutions,这样:
https://arxiv.org/pdf/1705.03122.pdf论文中最主要的结构图,如下所示,最最典型的部分就是对输入数据进行编码时采用的Convolutions,这样:
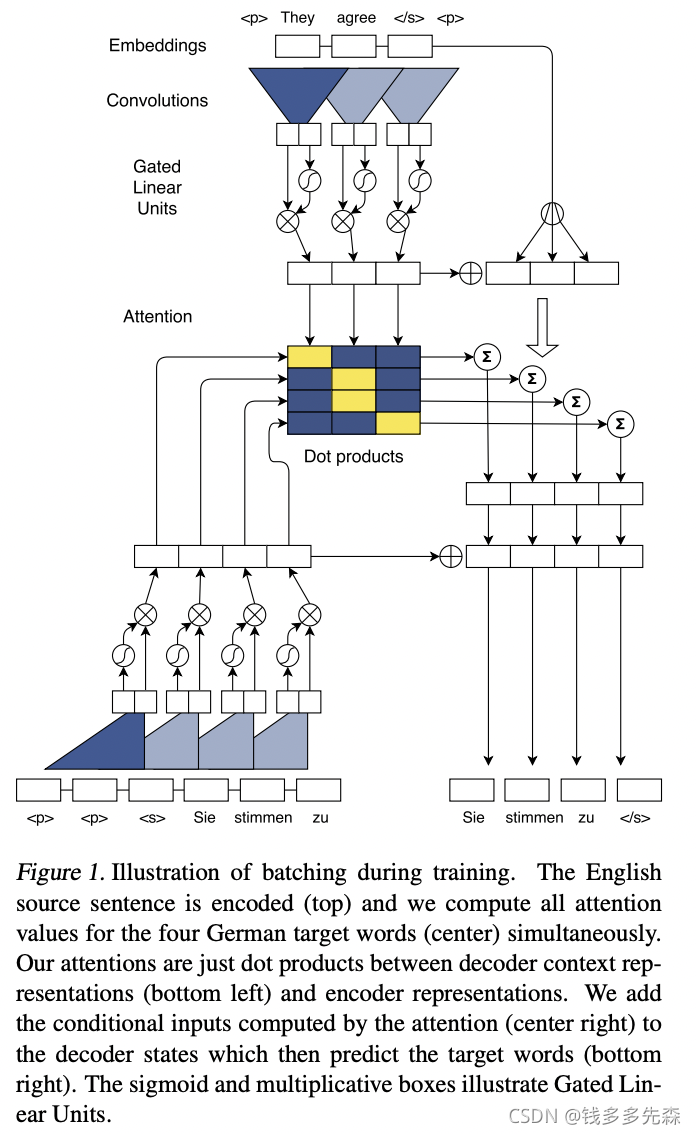
(摘自Convolutional Sequence to Sequence Learning)
CNN 卷积神经网络参与其中的优势:
- 方便并行化
- 高低维度进行融合(层层卷积)
- 多个输出通道channel,不同的输出通道,可以用于识别不同的模式
所以,为了解决RNN中难以并行化的问题,借鉴了CNN的方式,实现了NLP领域中训练过程的并行化问题。
但是呢,采用CNN实现信号间的关联,就需要层层连接,最后才能实现较远信号之间产生联系。这就是论文中提到的:
In these models, the number of operations required to relate signals(关联信号所需要的操作) from two arbitrary input or output positions grows in the distance between positions, linearly for ConvS2S and logarithmically for ByteNet。
This makes it more diffificult to learn dependencies between distant positions。在这些模型中,从两个任意输入或输出位置关联信号所需要的操作数之间的距离,ByteNet是线性的和 ConvS2S是对数增长的。
这使得将距离较远位置信号的关联起来,变得更加困难。
后面,就引入了 transform ,他有别于 RNN 和 CNN,眼界都比较大窄小。transform 能过一眼看到所有的输入数据,就为建立起对数据的整体感知,提供了前提可能。
 (摘自attention is all you need)
(摘自attention is all you need)
1.1、何为self- attention
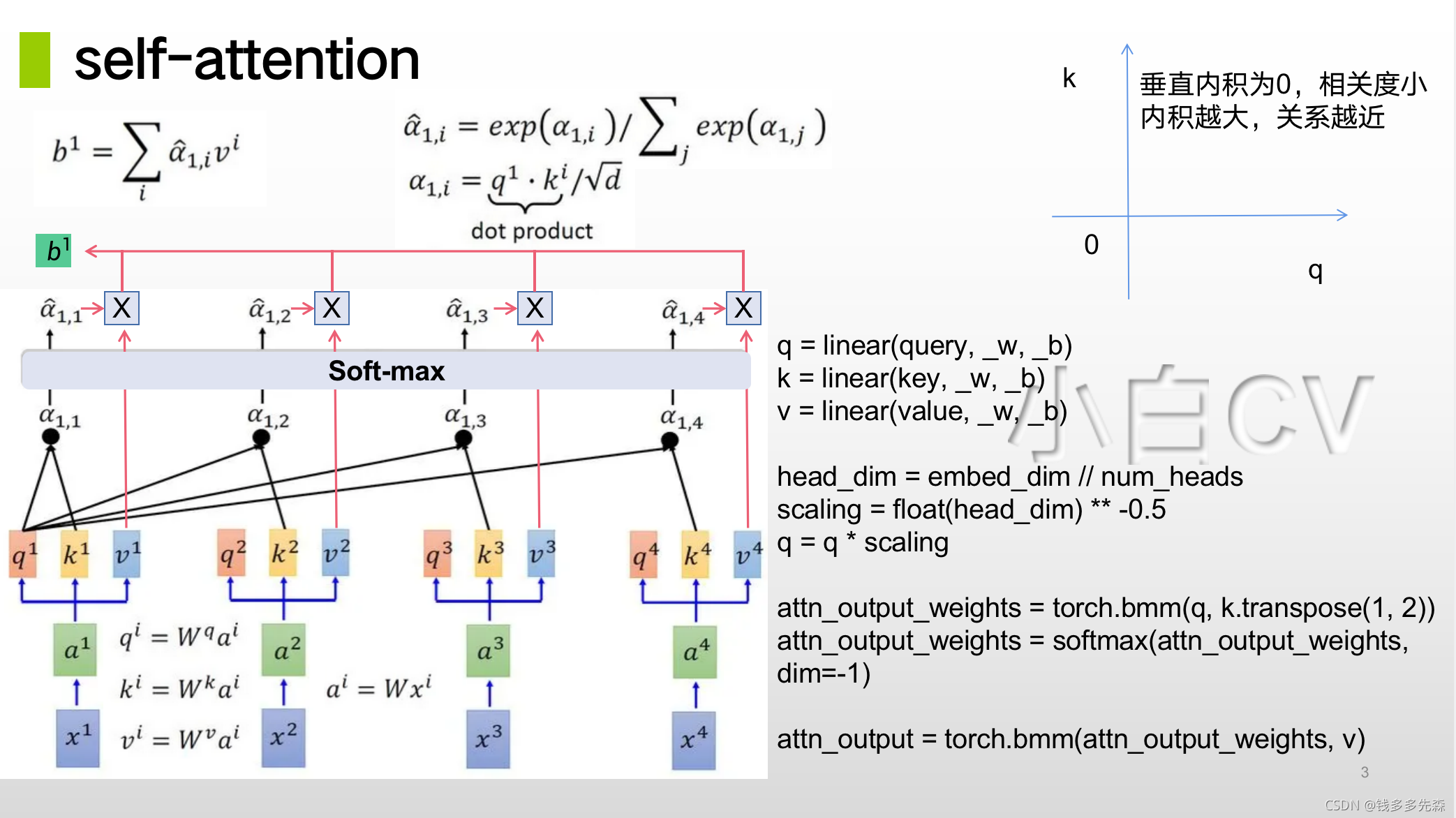
网上搜集到很多的关于介绍 transform- attention 的相关资料,最终觉得这个比较的好,并微微做了一些改变,方便我们的学习理解。
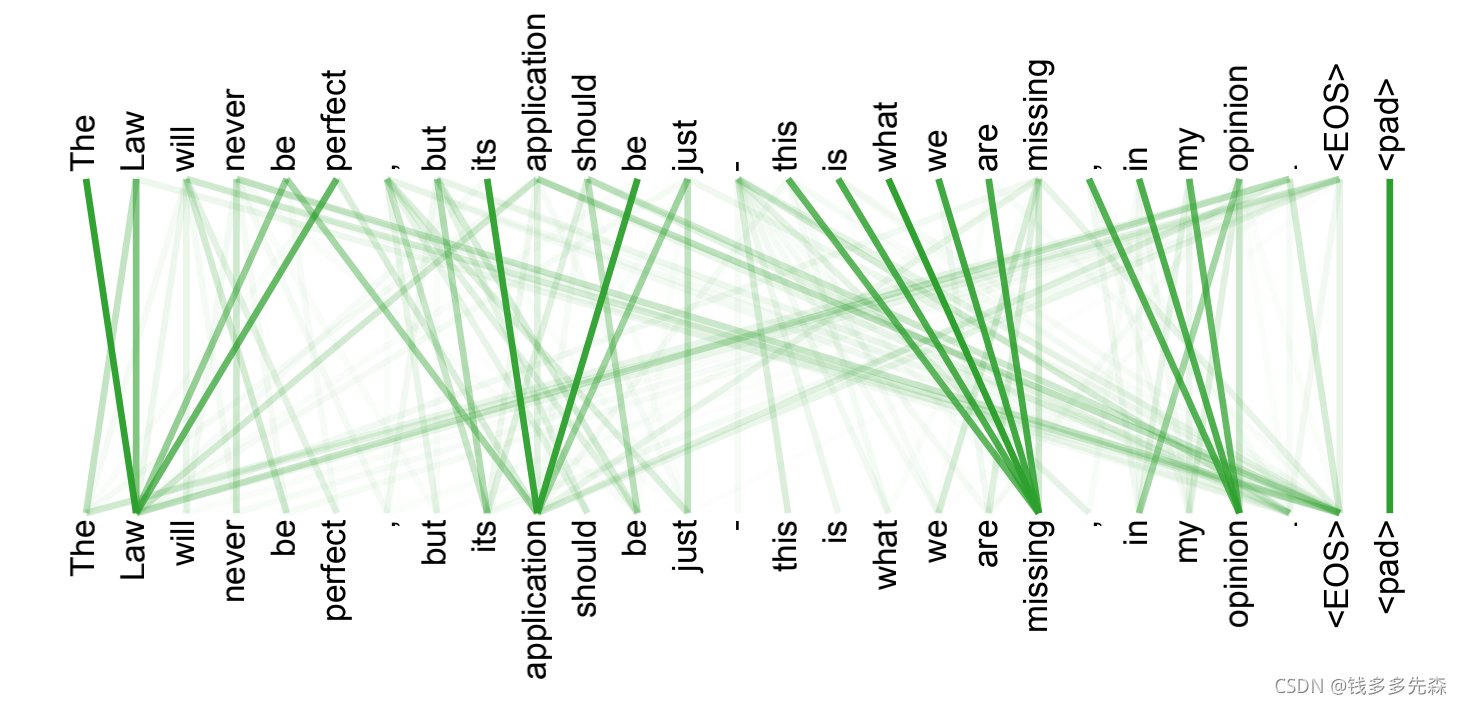
在引入阶段结束的时候,放了 《attention is all you need》中的一个attention可视化案例。其中,简单的可以看到,在词与词的关联关系之中,并不是将注意力(颜色深浅)均匀的分布到每一个词上面的,也不是只与自己最近的那几个词,有可能就是相距很远,但是关联程度很高的。
attention,顾名思义就是关注度。那么,我们该如何模拟信号与信号(词与词)之间的关联程度?使得某一个词的确定,只与句子中其中某几个词,产生较大的联系呢?
例如:
- 小红很可爱,我好***她
- 小亮欺负了小红,他是个***人
上面是一个填空题的案例,补全其中***部分缺失的词,该如何确定?我们都知道,小红很可爱,我好喜欢她,空白处填写喜欢。那如果是:小红爱欺负人,我好***她,此时***的地方,肯定是个贬义词。
这里就可以看出,空白处补写的词,和对小红的描述很重要,描述变了,后面的评价词也对发生较大的改变,这就说明空白处需要填写的词,需要与对小红描写的词产生较大的attention,才能填写正确。
在PPT中,输入是 x1、x2、x3、x4,希望得到翻译后的输出B,B 可能是 b1、b2、b3、b4或者更多组成,这里就先知关注 b1,看看是如何从输入中,推理得到 b1 的。

一个 attention 函数可以描述为:
- 一个query和一个由 key-value 组成的键值对集合
- query、key、value 和输出都是向量
- 输出是计算values的加权和
- 分配给每个value的权重,由query 和相应的 key 值确定
论文中的这句话应该描述的算是比较简单清楚的,下面我们再通过PPT中的数据传递关系(上图self-attention)和定义attention function的代码,确认下理解思路是否正确。
1.1.1、attention function的代码
######################
# a attention function
######################
q = linear(query, _w, _b)
k = linear(key, _w, _b)
v = linear(value, _w, _b)
head_dim = embed_dim // num_heads
scaling = float(head_dim) ** -0.5
q = q * scaling
attn_output_weights = torch.bmm(q, k.transpose(1, 2))
attn_output_weights = softmax(attn_output_weights, dim=-1)
attn_output = torch.bmm(attn_output_weights, v)
由上述定义代码,可以看到:q、k、v是三个可学习的参数。定义中后续的操作可以看下文,根据数据流的传递方式,辅助学习。(我把图再次贴过来了,方便查看)
1.1.2、数据传递关系
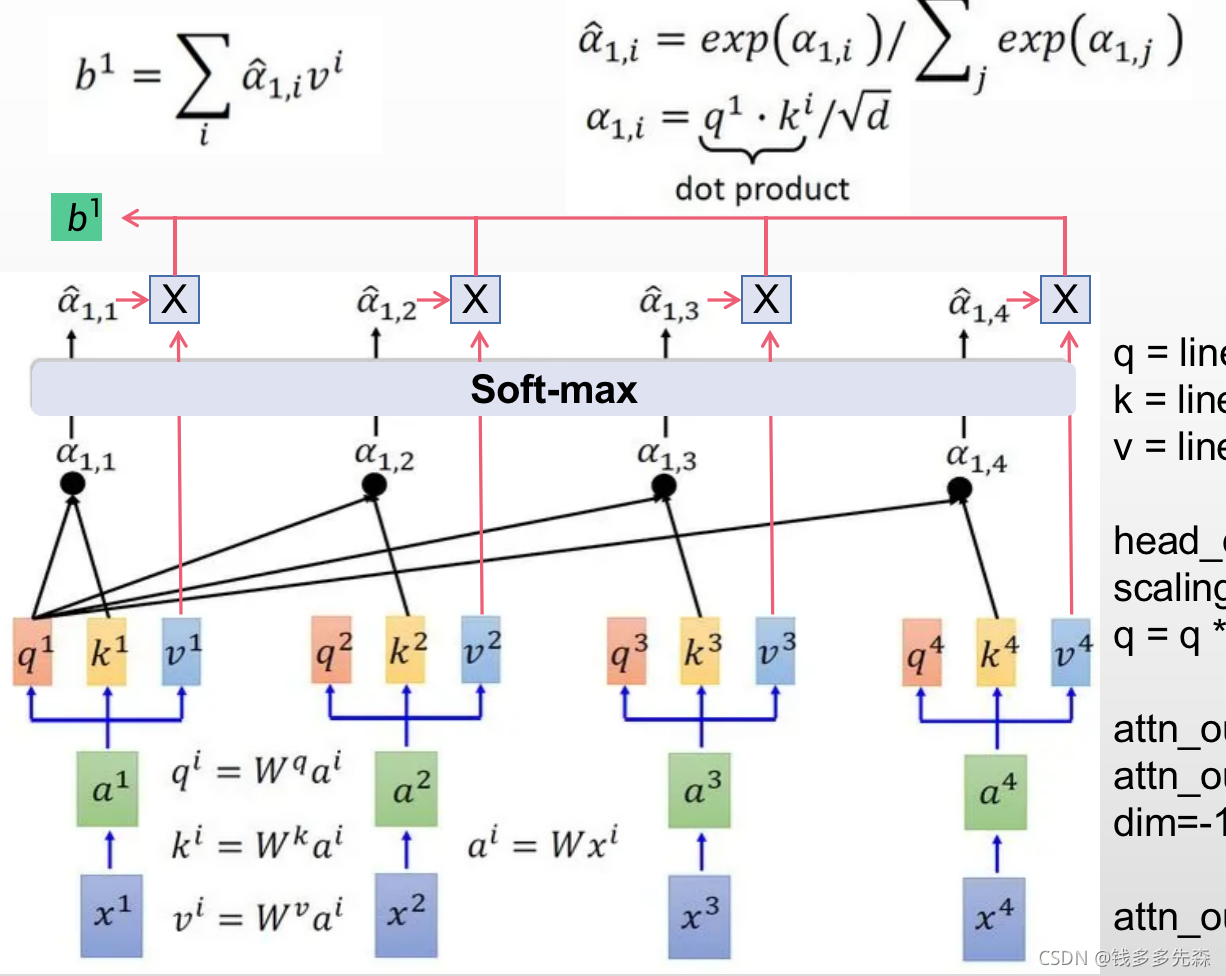
在一个attention函数中的一个输出b,它考虑了来自所有的输入x1、x2、x3、x4生成的q1、k1、v1到q4、k4、v4。其中:
- softmax操作是一种分配注意力attention的方法,他只参考了q1、k1到q4、k4的,此时的value值并未参与
- 经过了softmax后,才各个权重乘以value
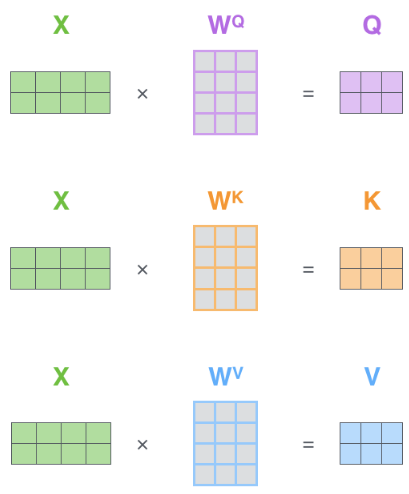
自注意力机制模块通过WQ,WK,WV矩阵得到Q,K,V矩阵。如下图:
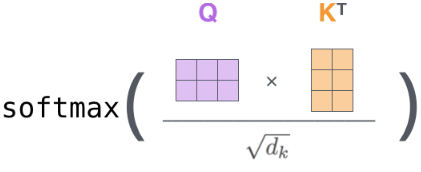
然后矩阵Q与矩阵K的转置相乘得到每个词间的相关系数,并通过词嵌入维度和softmax对相关系数进行归一化。
最后乘V矩阵,得到自注意力机制的输出,
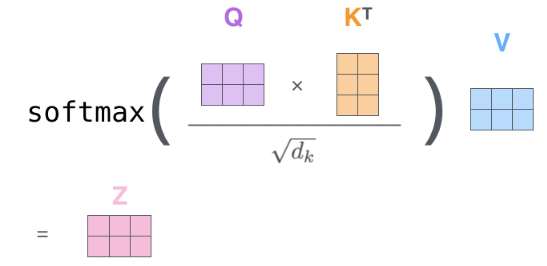
1.2、Mult-head self-attention(多头注意力)
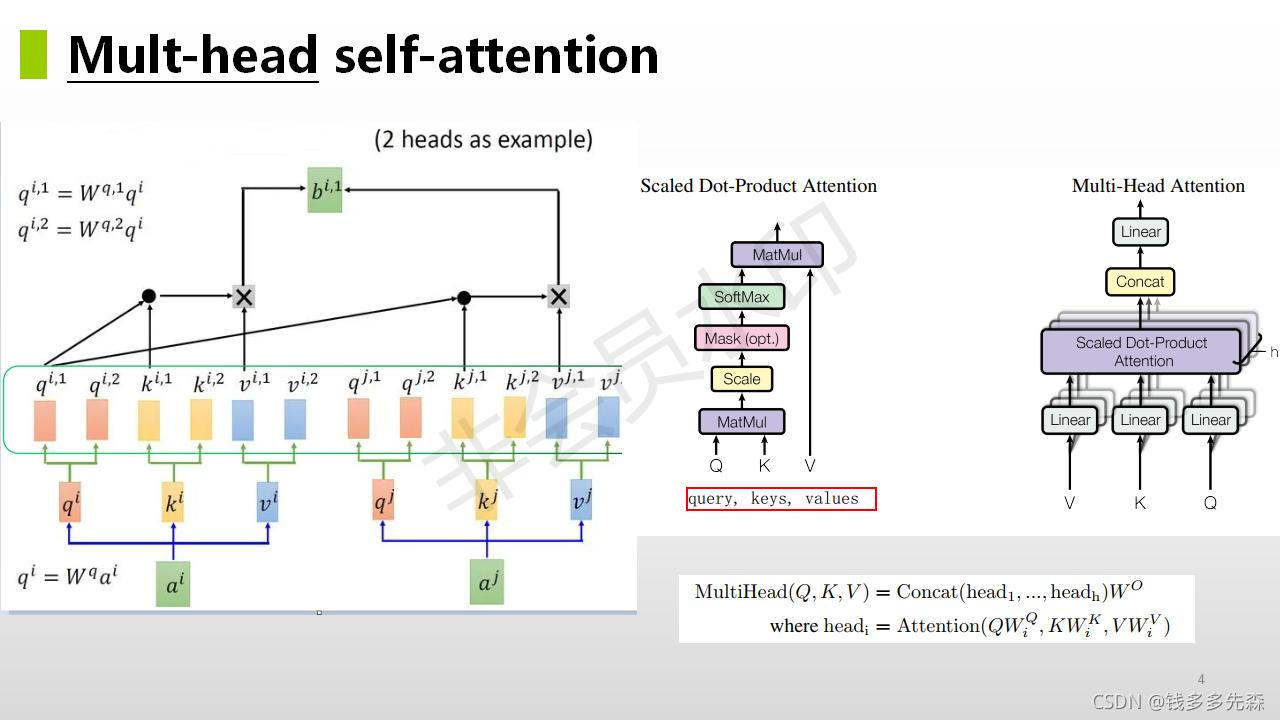
mult -head 是 self - attention 的一种扩展。在 self - attention中,一个x 经过 q、k、v 分别得到了3个输出编码向量,他们都是 x 的另一种表达形式存在。经过 softmax 后,对于x来说,它在这样一个特征下,被关注 attention or not attention。
而 multi -head attention,同样一个x,经过了不同的 head,得到了不同的表达形式。举个栗子,x表示的是一个人,对于认识这样一个人的任务,我们可以从很多种维度来认识他。
比如一个head,就负责认识他的外貌;一个haed就负责关注他的想法;还有一个head是负责学习他的说话方式。
这样这样一个mult head的结构,就比单一的 self - attention,功能就更加强化了很多。即便其他功能都退化了,那也是比一个head要好。
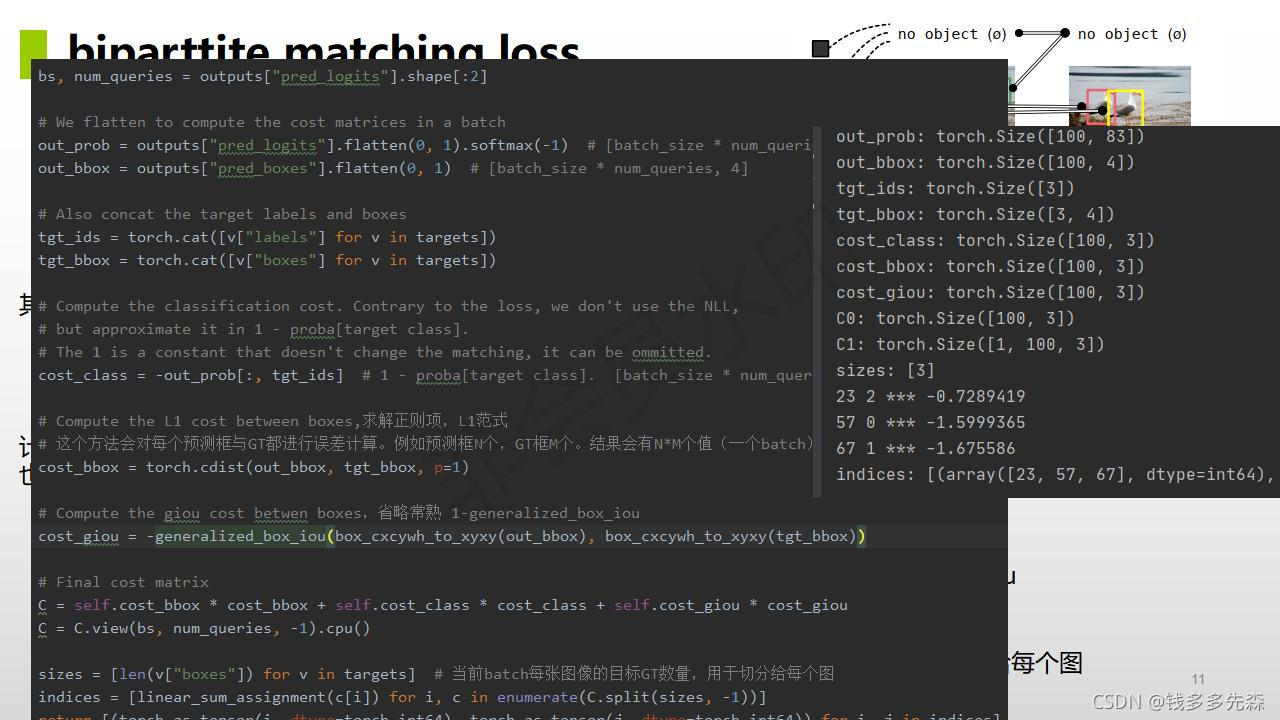
2、匈牙利算法匹配
匈牙利匹配算法,是一种典型的一对一的配对算法。一对一的匹配,与之对应的,就是一对多,或多对一的配对算法。也称作no anchor操作。
对于Anchor based 、 Anchor free 和 no anchor 的辨析,可以参考这里:【AI面试】Anchor based 、 Anchor free 和 no anchor 的辨析![]() https://qianlingjun.blog.csdn.net/article/details/129339036在目标检测算法中,预测结果与gt标注结果多对一的典型案例,就是anchor based时候,对推荐的特征框是很多的,但是图像中的标记目标是很少的。对于阳性和阴性案例的分配时候,就采用了IOU 的方式来判别。
https://qianlingjun.blog.csdn.net/article/details/129339036在目标检测算法中,预测结果与gt标注结果多对一的典型案例,就是anchor based时候,对推荐的特征框是很多的,但是图像中的标记目标是很少的。对于阳性和阴性案例的分配时候,就采用了IOU 的方式来判别。
- 大于0.7的就是positive,
- 小于0.3的就是negative。
- 即便如此,positive的数量还是相比于标记框数量还是多的,此时的状态就是多对一的。
在匈牙利匹配算法组,就是要找到一种一对一的组合方式下,目标是最优的。这里举一个案例:
一个农场主有10名工人,他们分别都有自己擅长的事情,现在需要做5件不同的事情,一个人只能干一件事情。如何分配能够使得最后的工作效率最高呢?
最简单的方式,就是采用遍历的方式,把所有的可能都计算一遍。最后把工作效率最高的一个组合留下来。此时,这种组合就是最优的匹配。
匈牙利匹配算法就是采用这种方式进行的。步骤如下:
- 先定义一个目标任务,怎么判断是最优匹配?比如这里就是误差最小;
- 列举所有的可能,最终找到误差最小的那个组合,就是一一匹配的最优组合形式了。

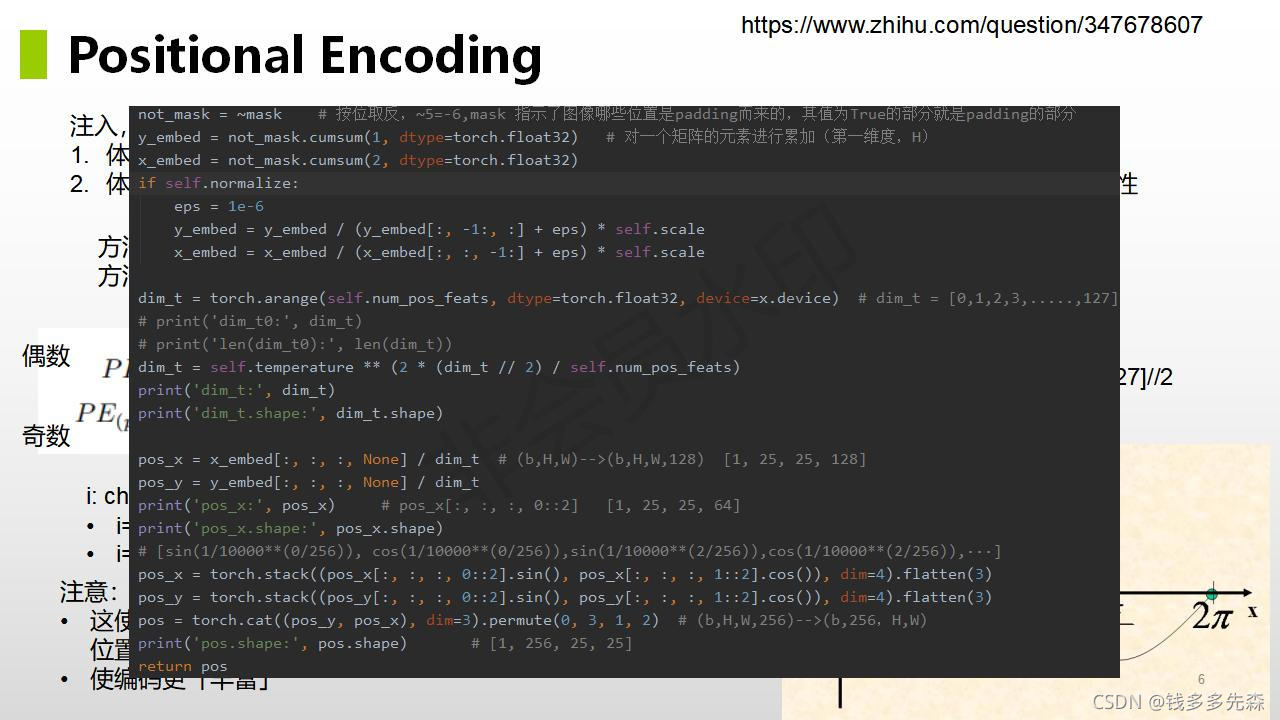
位置编码的目的,就是为了给经过crop后的图像,加入相对位置信息。因为:
- 在CNN中,像素的位置信息是天然存在的,所以不需要单独的进行编码。
- 但是在transform里面,被打散的丢失了相对位置信息,这就需要我们手动加入。
ViT论文对位置编码进行了1维和2维编码的对比。在分类任务中,并没有明显的改进。但是对于目标检测和分割任务,x和y分别编码,肯定是更有意义的。
下面给出了detr论文中,对位置编码的代码和注释内容:
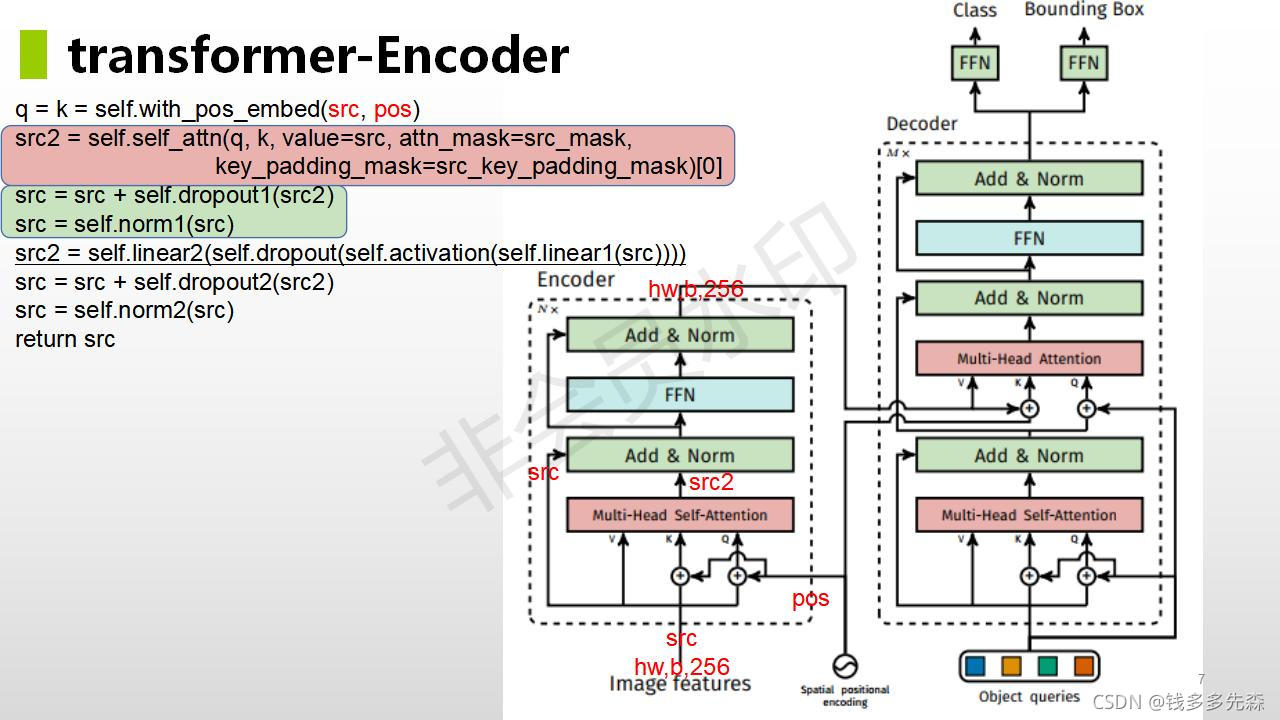
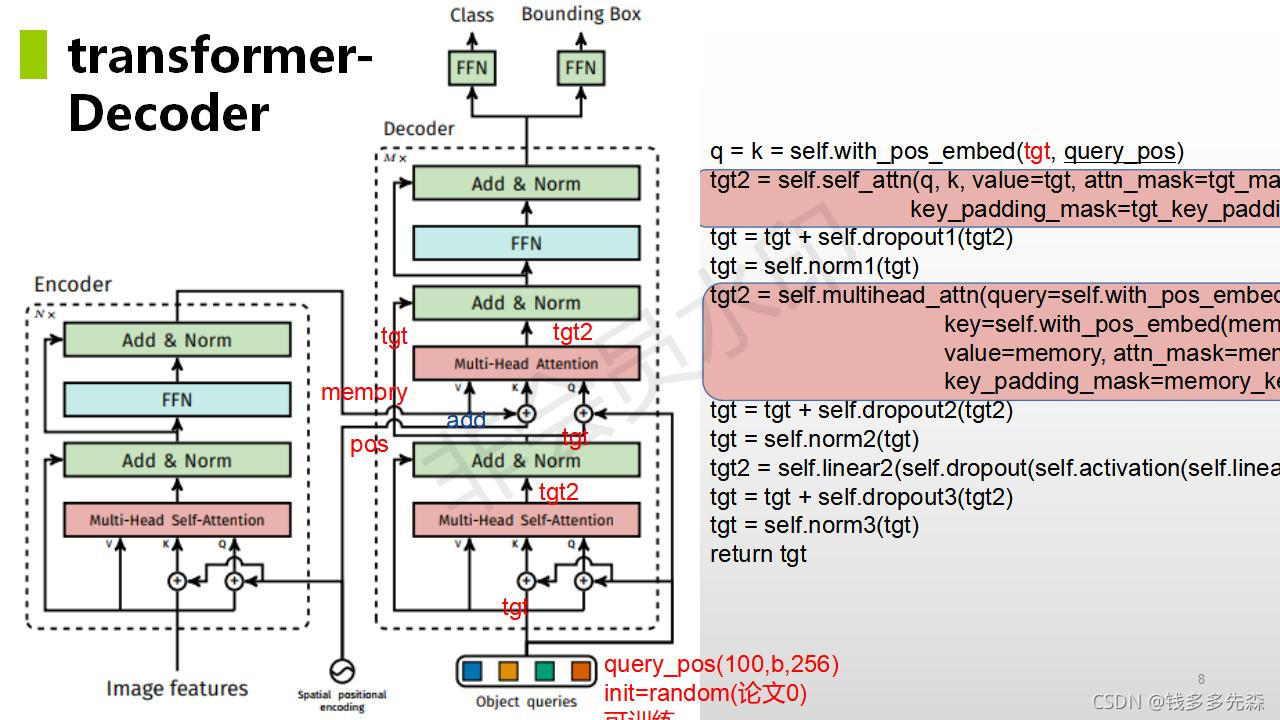
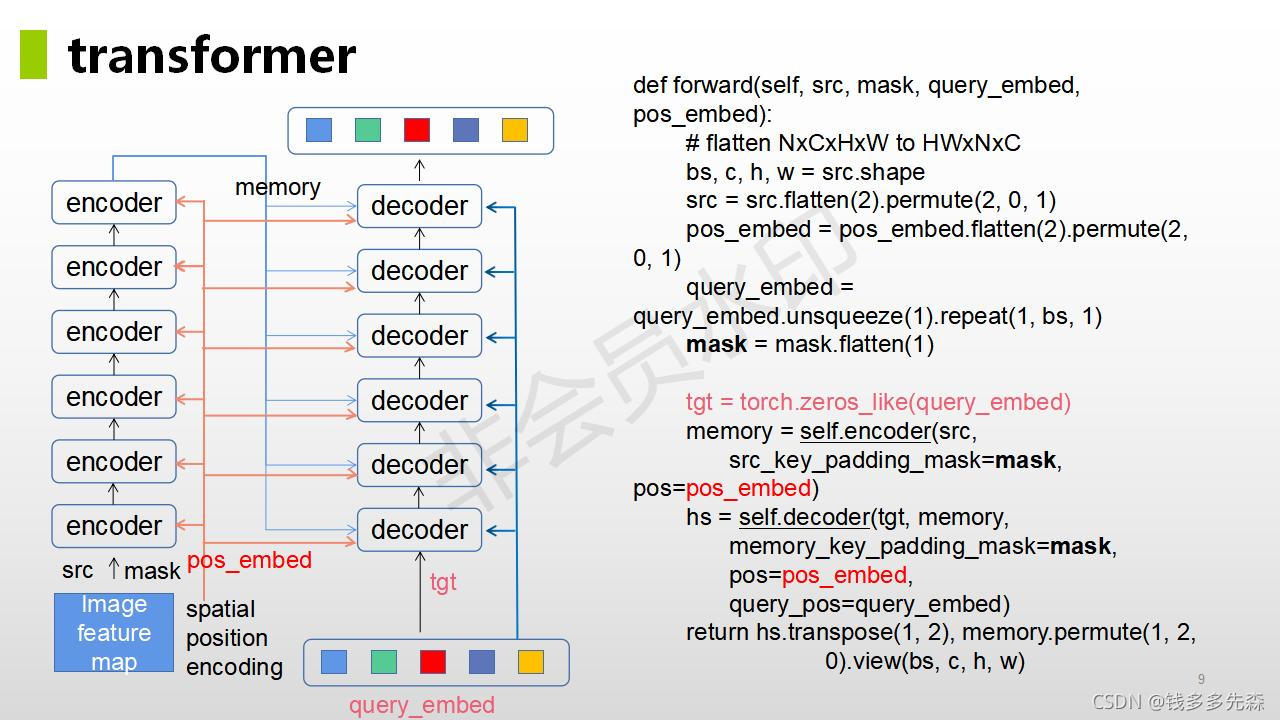
上图中query embed对应着论文中object query,是一个经过embed后可学习的参数。论文中默认设置的是100,也就是一次前向推理,最多会预测100个目标。对于这个数量的设置,已经远远的超过了一种图片中的数量了。
在论文中,对object query进行了可视化的显示,发现学习后的object query,类似于faster RCNN中的anchor based。在decode阶段,不断的询问特征图中,中心点、边缘有没有多大的目标。不同的query 负责不同的目标预测。
这里就是no anchor的机制。在经历decode后的Proposal,是不会再进行NMS操作的。在训练阶段,直接进行匈牙利匹配,计算损失。在evaluate阶段,经过指定阈值,直接对预测结果进行区分。这块又被称作NMS free。

FFN就是feed forward net。可以看到都是由全连接层组成的,包括分类任务和bounding box的预测。
- 分类任务:直接输出类别数+1(背景)
- Bbox的位置预测:输出大小是4,也就是Bbox的坐标值了。
self.linear1 = nn.Linear(d_model, hidden)
self.linear2 = nn.Linear(hidden, d_model)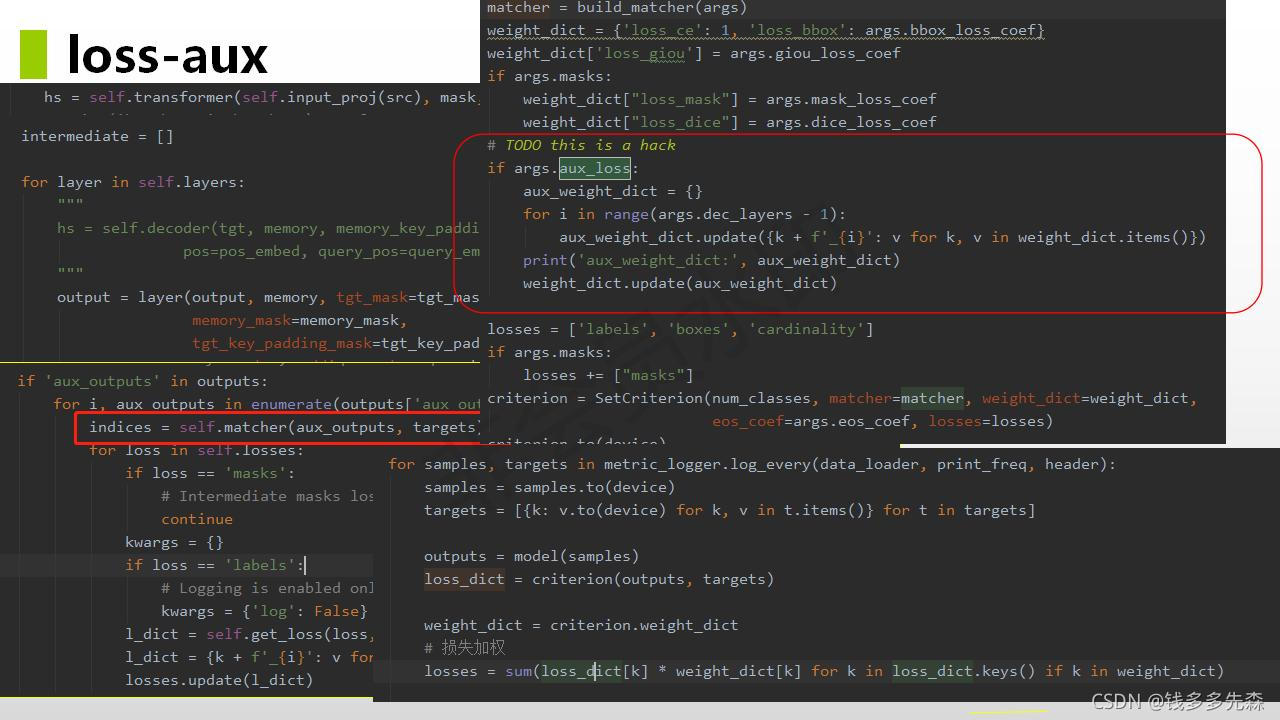
loss aux是一种可以选择是否开启的功能,开启后就会在decode的每一个阶段,都进行FFN预测。因为在decode阶段,进行是需要经历6次decode的操作,但是每一次decode的输出维度大小,其实都是一样的。
这也就意味着,每一次decode的输出数组,其实都是可以介入FFN进行预测的,这样就每一次预测完都计算一次损失,参与到优化中去。这就是aux的含义。
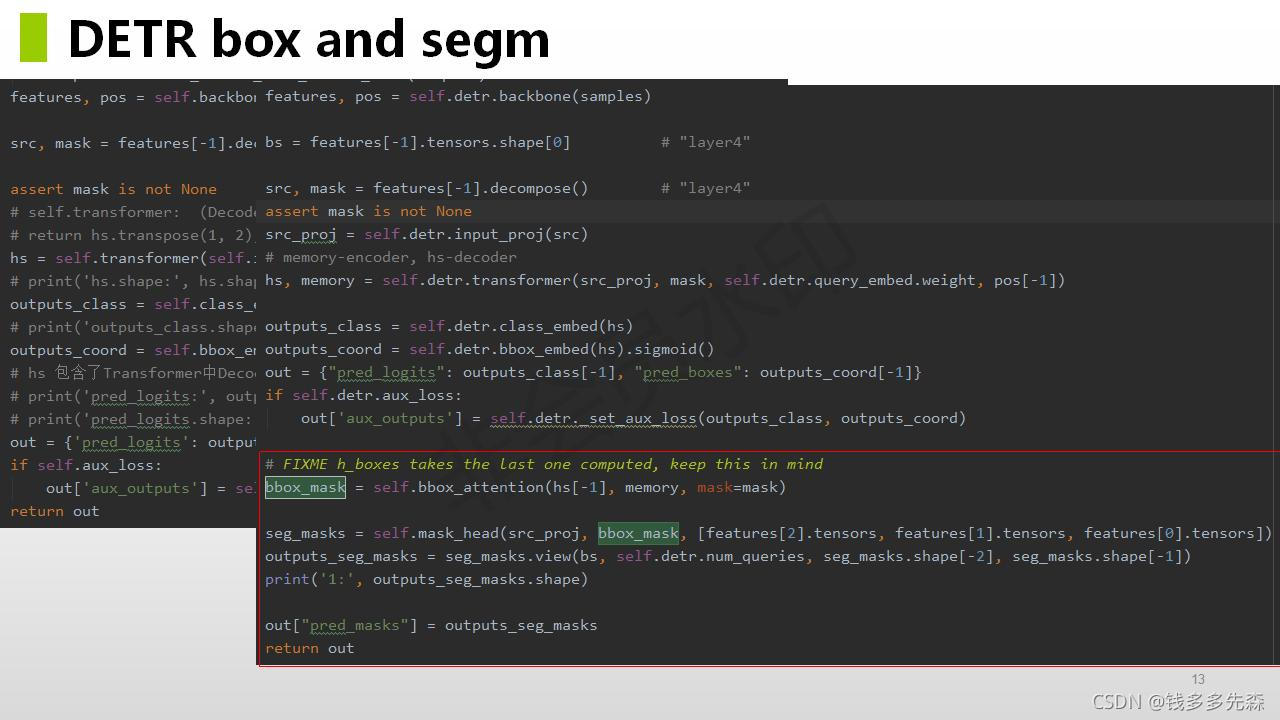
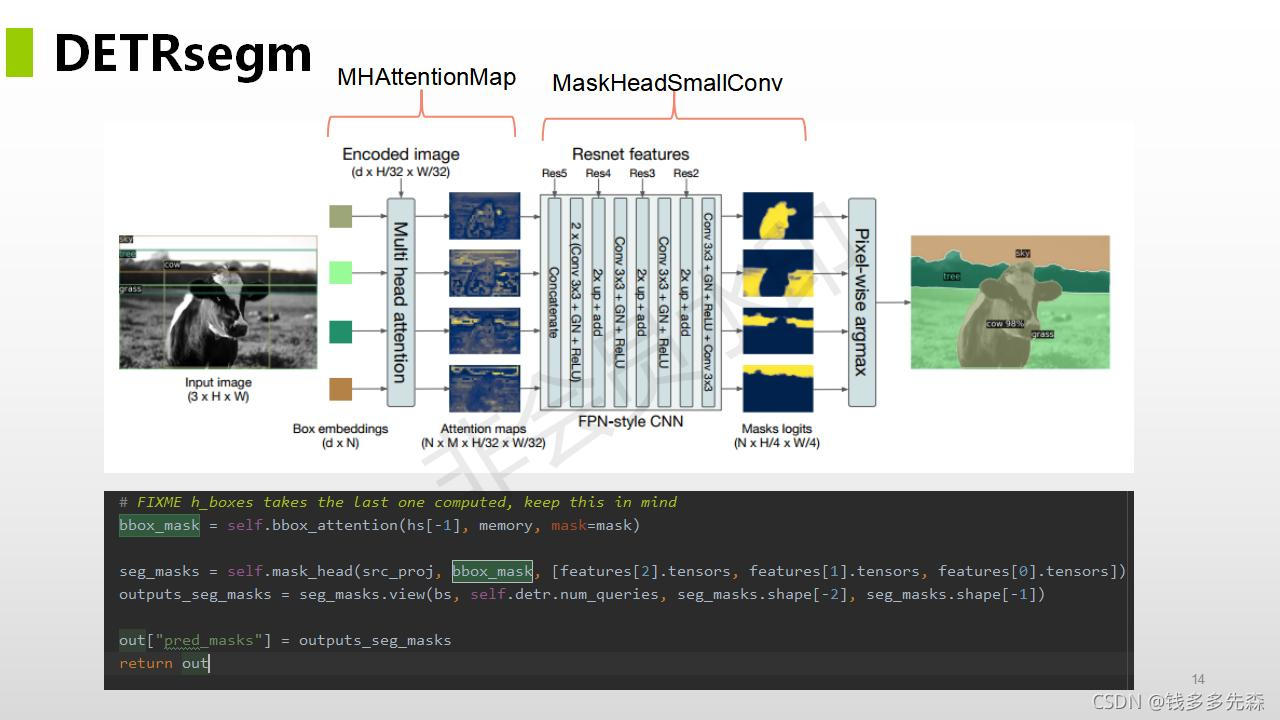
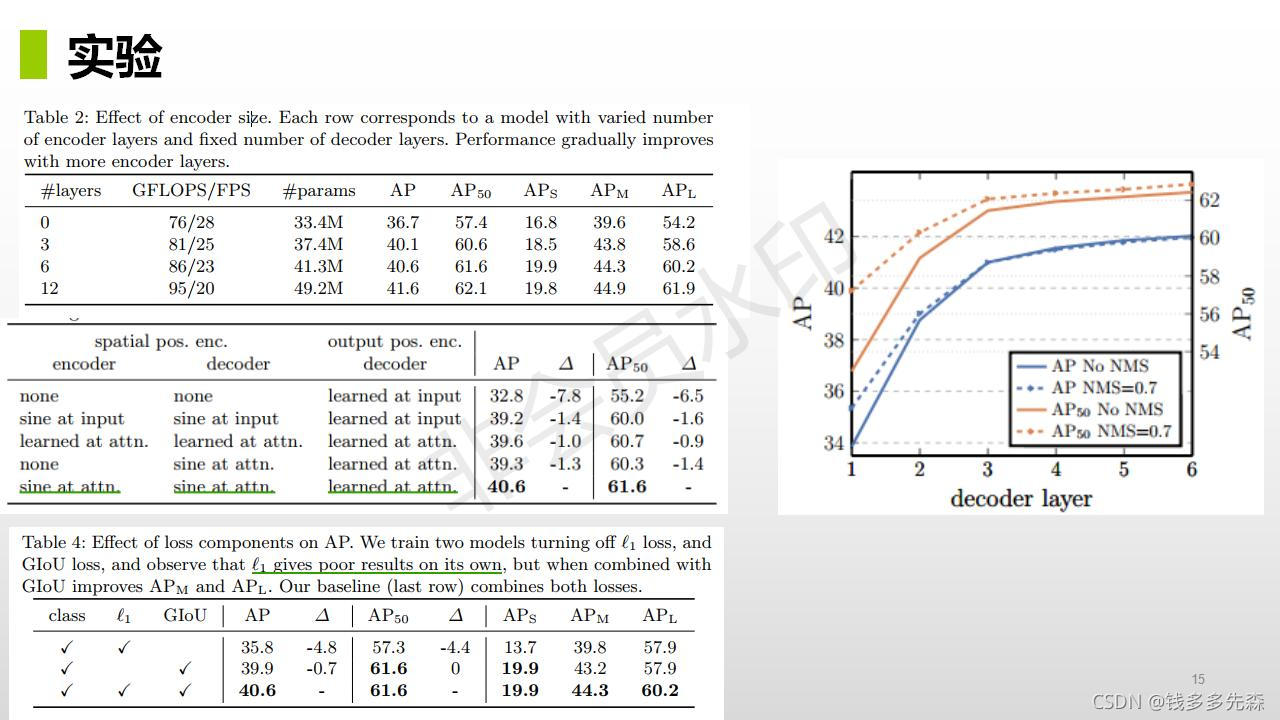



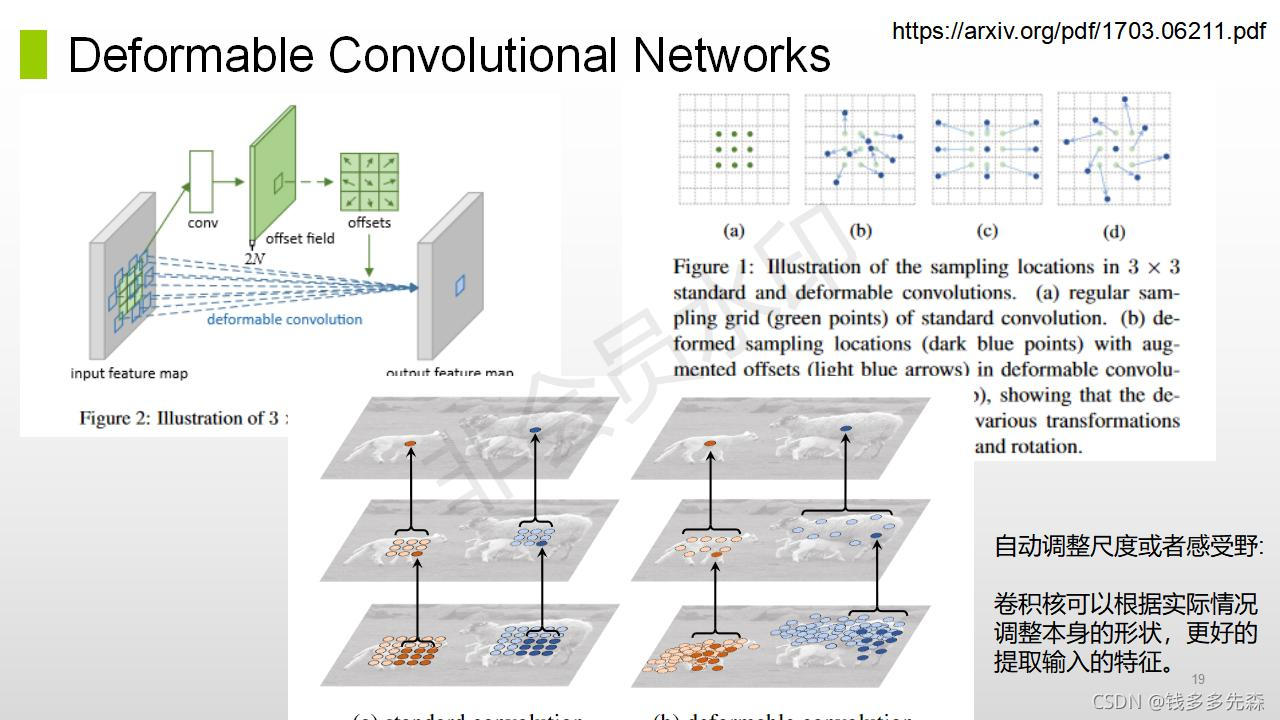
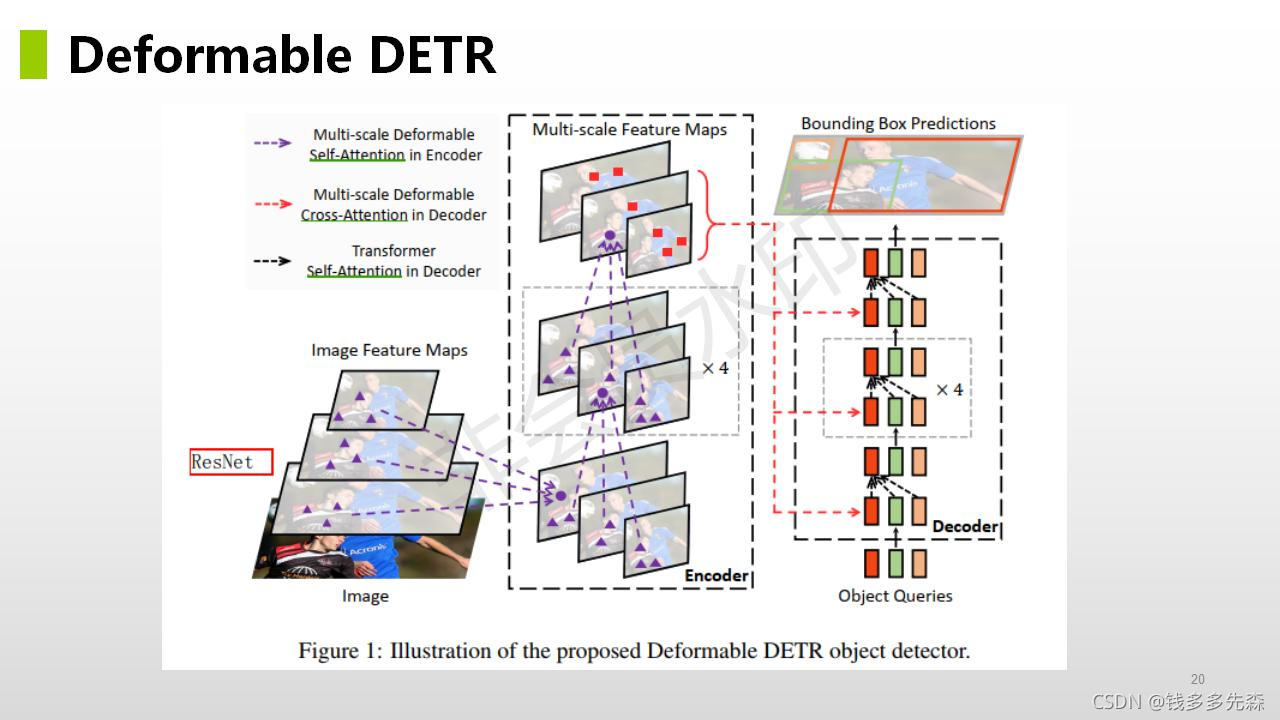

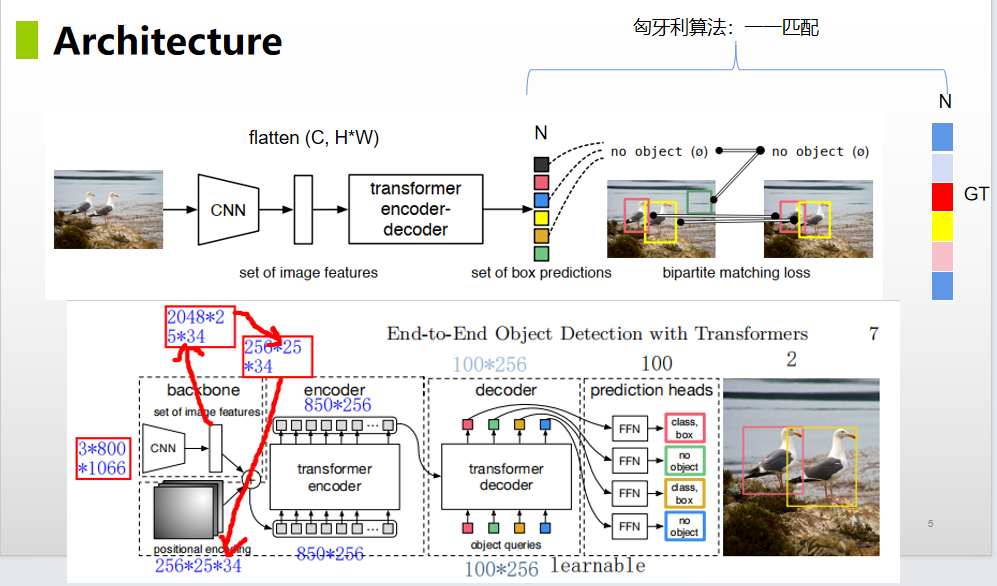
论文中提到的方法主旨结构如下所示,整个论文也是围绕这个这个结构就行展开的。

3、论文完整阅读注释




















 6639
6639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











