






pandas高级篇
一、向量化函数操作
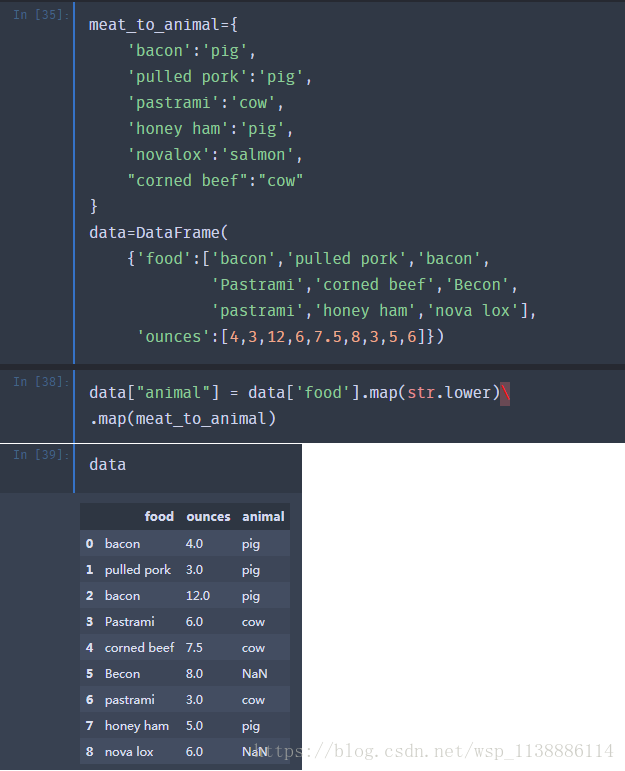
向量化函数应用 -map(变换数据和创造新变量) map是作用在 Series 上,是元素级别操作 Series.map(arg,na_action=None) arg可以是一个函数,对元素做函数变换 也可以是一个dict、series 对元素做数据映射 向量化函数应用 -applymap applymap 是作用在 dataframe 上,用于对row、column 计算是元素级别的操作 DataFrame.applymap(func,axis=0): func只能是一个函数 func为聚合函数时,对行列进行聚合处理 func为普通函数时,和applymap效果一样1.2 利用函数和映射进行转换
1、先编写一个映射 2、再利用map函数来进行映射
二、pandas 数据运算
pandas数据运算——一元运算
使用 map、applymap pandas数据运算——汇总运算 mean(axis=None,skipna=None,level=None) skipna:是否跳过NAN值 level: 对于多层索引有效
三、多层索引
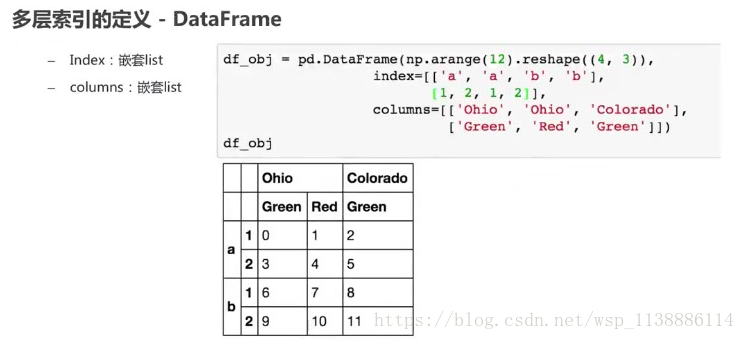
多层索引的定义
-series -index参数为嵌套list
-DataFrame - index:嵌套list - column:嵌套list
-将已有列设为多层索引 set_index(keys,drop=True,append=False,inplace=False) - 是否保留原来索引 - Drop 是否指定为索引的列删除多层索引的操作
- 交换分层 swaplevel(i=-2,j=-1,axis=0) i,j 需要被交换索引名称或者位置(从0开始) 指定某个分层进行索引排序 sort_index(axis=0,level=None,ascending=True,inplace=False,sort_remaining=True) 数据选择 df.loc[([],[]),([],[],[])] 通过内嵌的list 元组,定位到访问数据 常用函数 -sum sum(axis=None,skipna=None,level=None) 指定level后,会在此level的基础上进行聚合多层索引 s1 = Series([0,1],index=["a","b"]) s2 = Series([2,3,1],index=["c","d","i"]) s3 = Series([6,8,1],index=["u","i","j"]) result = pd.concat([s1,s2,s3],keys=["one","two","three"]) #指定索引名列表 >>> one a 0 b 1 two c 2 d 3 i 1 three u 6 i 8 j 1 dtype: int64 __________________________________________________ 合并重叠数据 a = Series([NA,2.5,NA,3.5,4.5,NA],index=list("fedcba")) b = Series(np.arange(len(a)),dtype=np.float64, index=list("fedcba")) b[:-2].combine_first(a[2:]) #合并重叠数据(用a 给 b 打补丁:用a填充b中不存在的索引与值和空值) >>> a NaN b 4.5 c 3.0 d 2.0 e 1.0 f 0.0 dtype: float64 _______________________________________________________ df1 = DataFrame({"a":[1.,NA,5.,NA], "b":[NA,2.,NA,6.], "c":range(2,18,4)}) df2 = DataFrame({"a":[5.,4.,NA,3.,7.], "b":[NA,3.,4.,6.,8.]}) df1.combine_first(df2) >>> a b c 0 1.0 NaN 2.0 1 4.0 2.0 6.0 2 5.0 4.0 10.0 3 3.0 6.0 14.0 4 7.0 8.0 NaN

四、pandas数据变形-连接与关联
关联几种方式:
轴关联:
pd.concat 沿轴方向将多个对象合并到一起 Append: pd1.append(df2,ignore_index=False,verify_integrity=False) concat简化版本,axis=0,join="outer"轴关联 -concat series
Axis=0 :将不同对象行连接,用列名关联,可以使用 ignore_index。inner、outer的效果一致 Axis=1 :将不同对象列连接,用行索引关联,行索引不会重复。inner、outer的效果不一样 Axis=0 :将不同对象行连接,用列名做join 进行关联 pd.concat([df_obj1,df_obj2],axis=0,join="outer") pd.concat([df_obj1,df_obj2],axis=0,join="inner")s1 = Series([0,1],index=["a","b"]) s2 = Series([2,3,1],index=["c","d","i"]) s3 = Series([6,8,1],index=["u","i","j"]) pd.concat([s1,s2]) >>> a 0 b 1 c 2 d 3 i 1 c 2 d 3 i 1 dtype: int64 pd.concat([s1,s2,s2],axis=1) >>> 0 1 2 a 0.0 NaN NaN b 1.0 NaN NaN c NaN 2.0 NaN d NaN 3.0 NaN i NaN 1.0 8.0 j NaN NaN 1.0 u NaN NaN 6.0列关联 -merge (合并)
merge() 根据单个或者多列进行join 关联,将不同的 Dtaframe 的行连接起来 how 取 outer 保留两边所有的行 right_index 与 left_index 的使用 right_on 与 left_on 的使用 suffixes 的使用
df3 = DataFrame({"key1":list("bbacaab"), "key2":list("dbachub"), "data1":range(7)}) df4 = DataFrame({"key1":list("vfdb"), "key2":list("vuib"), "data2":range(4)}) pd.merge(df3,df4,on=["key1","key2"],how="outer") >>> data1 key1 key2 data2 0 0.0 b d NaN 1 1.0 b b 3.0 2 6.0 b b 3.0 3 2.0 a a NaN 4 3.0 c c NaN 5 4.0 a h NaN 6 5.0 a u NaN 7 NaN v v 0.0 8 NaN f u 1.0 9 NaN d i 2.0


五、pandas-数据重塑(行列旋转)
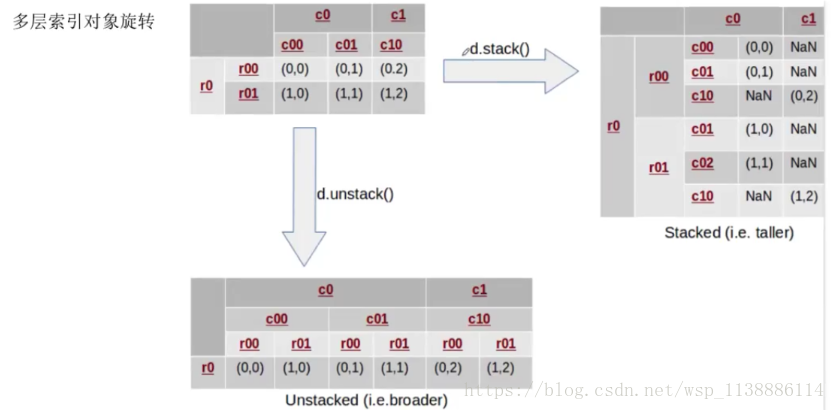
5.1 轴向旋转:stack、unstack
stack(level=-1,dropna=True) 将数据的列旋转为行 level:指定旋转索引等级,默认最里层索引进行旋转 unstack(level=-1,fill_value=None) 将数据的行旋转为列 level:指定旋转索引等级,默认最里层索引进行旋转单层索引对象旋转:
多层索引对象旋转:
data =Series(np.random.randn(10), index=[list("aaabbbccdd"), [1,2,3,1,2,3,1,2,2,3]]) >>> a 1 0.484419 2 0.856405 3 -0.983942 b 1 -1.066771 2 -0.267273 3 0.802730 c 1 -0.572871 2 0.665871 d 2 0.475567 3 0.317334 dtype: float64 data.unstack() #unstack:将数据的行“旋转”为列 >>> 1 2 3 a 0.484419 0.856405 -0.983942 b -1.066771 -0.267273 0.802730 c -0.572871 0.665871 NaN d NaN 0.475567 0.317334 __________________________________________ data = DataFrame(np.arange(6).reshape(2,3), index=pd.Index(["上海","北京"],name="省份"), columns=pd.Index([2011,2012,2013],name="年份")) >>> 年份 2011 2012 2013 省份 上海 0 1 2 北京 3 4 5 result1 = data1.unstack([0]) #指定索引位置 进行旋转 >>> 年份 省份 2011 上海 0 北京 3 2012 上海 1 北京 4 2013 上海 2 北京 5 dtype: int32 result1.unstack("省份") #指定索引名 进行旋转 >>> 省份 上海 北京 年份 2011 0 3 2012 1 4 2013 2 5data_x = DataFrame(np.arange(6).reshape(2,3), index=pd.Index(["Ohio","Colorado"],name="state"), columns=pd.Index(["one","two","three"],name="numbers")) result = data_x.stack() 输出:result state numbers Ohio one 0 two 1 three 2 Colorado one 3 two 4 three 5 dtype: int32 df = DataFrame({"left":result,"right":result+5}, columns = pd.Index(["left","right"],name="side")) 输出:df side left right state numbers Ohio one 0 5 two 1 6 three 2 7 Colorado one 3 8 two 4 9 three 5 10 df.unstack("state") 输出: side left right state Ohio Colorado Ohio Colorado numbers one 0 3 5 8 two 1 4 6 9 three 2 5 7 10 df.unstack("state").stack("side") 输出: state Colorado Ohio numbers side one left 3 0 right 8 5 two left 4 1 right 9 6 three left 5 2 right 10 75.2 行旋转为列:pivot
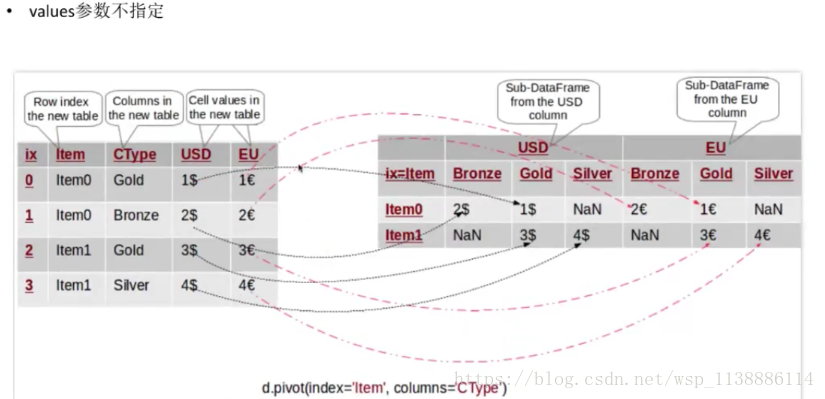
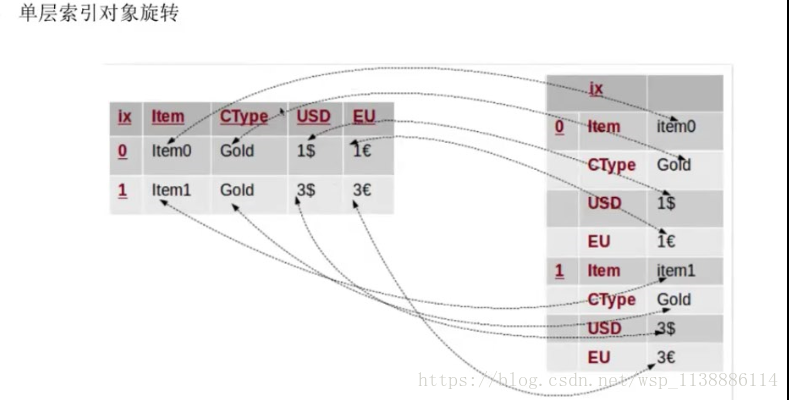
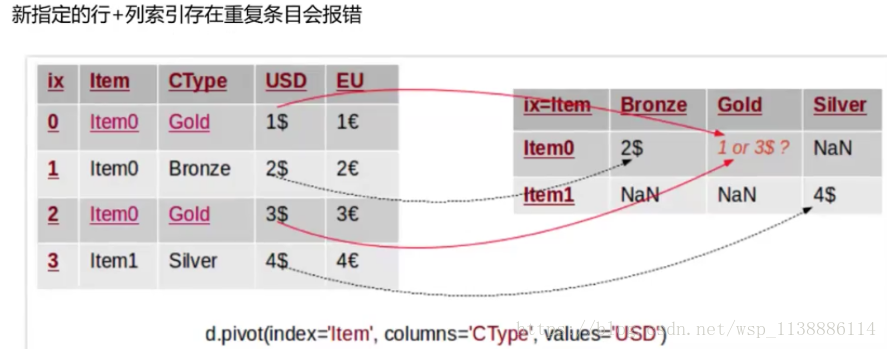
需要以某列为主视角观察数据 pivot(index=None,column=None,values=None) index:新对象行索引,指定原对象的某一列,不填默认为原来的index column:新对象列索引,指定原对象的某一列 values:新对象值,如果没有指定剩余列都默认为新对象的值, 并与 column 指定的列生成多层索引

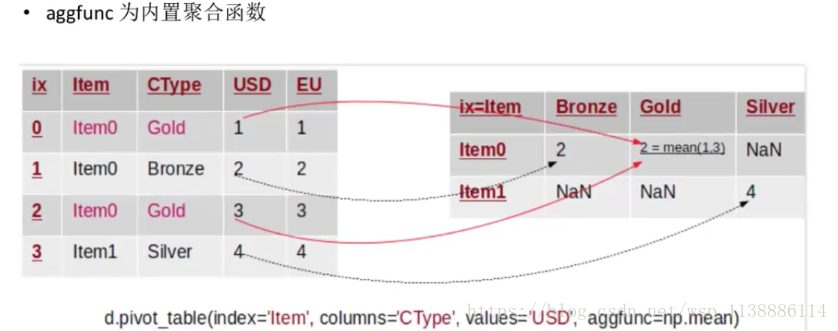
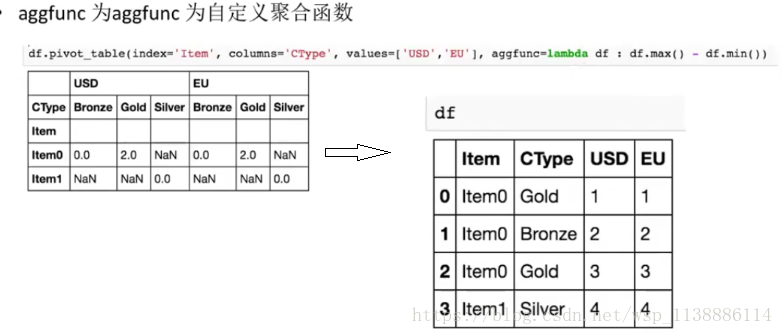
5.3 行旋转为列并聚合:pivot_table
pivot_table(index=None,column=None,values=None,aggfunc="mean",fill_value=None,dropna=True,margins_name="All") index:新对象行索引 指定原对象的某一列,或者多列 也可以是一个新的列表或者新的嵌套列表,也可以为一组值组成的list column:新对象列索引 指定原对象的某一列,或者多列 也可以是一个新的列表或者新的嵌套列表,也可以为一组值组成的list values:新对象值,如果没有指定剩余列都默认为新对象的值,并与 column 指定的列生成多层索引 aggfunc values 值的汇总函数,默认为mean,始终做聚合操作 aggfunc: 取内置聚合函数(max,min) 取自定义函数 取函数列表 取key为列名、value为函数的dict margins_name
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











