







文章目录
一、生成模型作用
-
内容创建:想象一下,广告公司可以自动生成具有吸引力的产品图像,而且该图像不仅与广告内容相匹配,而且与镶嵌这些图片的网页风格也相融合;时尚设计师可以通过让算法生成 20 种与「休闲、帆布、夏日、激情」字样有关的样鞋来汲取灵感;新游戏允许玩家基于简单描述生成逼真头像。
-
内容感知智能编辑:摄影师可以通过几次单击改变证件照的面部表情、皱纹数量和发型;好莱坞制片厂的艺术家可以将镜头里多云的夜晚转换成阳光灿烂的早晨,而且阳光从屏幕的左侧照射进来。
-
数据增强:自动驾驶汽车公司可以通过合成特定类型事故现场的逼真视频来增强训练数据集;信用卡公司可以合成数据集中代表性不足的特定类型欺诈数据,以改进欺诈检测系统。
生成模型其中有三种比较有前景的模型:自回归模型,变分自编码器(VAE)和生成对抗网络(GAN),如下图所示。
传送门:https://wiki.math.uwaterloo.ca/statwiki/index.php?title=STAT946F17/Conditional_Image_Generation_with_PixelCNN_Decoders
| VAE | GAN | Autoregressive Models | |
|---|---|---|---|
| Pros | Efficient inference with approximate latent variables. | GAN can generate sharp image; There is no need for any Markov chain or approx networks during sampling. | The model is very simple and training process is stable. It currently gives the best log likelihood, which is tractable. |
| Cons | generated samples tend to be blurry. | difficult to optimize due to unstable training dynamics. | relatively inefficient during sampling |
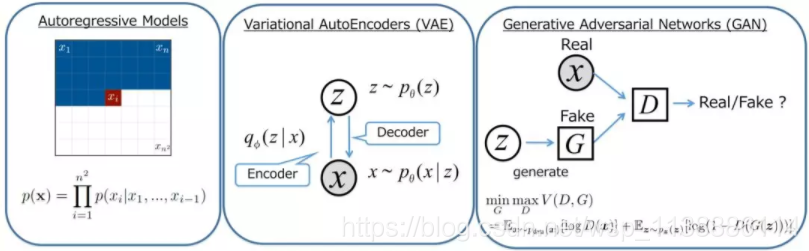
GAN 的原始版本和很多流行的模型(如 DC-GAN 和 pg-GAN)都是无监督学习模型。训练后,生成器网络将随机噪声作为输入,并生成几乎无法与训练数据集区分开来的逼真图像。然而,我们无法进一步控制生成图像的特征。但在大部分应用程序(如第一部分中描述的场景)中,用户希望生成带有自定义特征(如年龄、发色、面部表情等)的样本,而且理想情况是能够不断调整每个特征。
二、GAN 的两大类:风格迁移网络和条件生成器。
关于该网络详情:https://blog.csdn.net/wsp_1138886114/article/details/81488260
2.1 风格迁移网络
风格迁移,以 CycleGAN 和 pix2pix 为代表,是用来将图像从一个领域迁移到另一领域(例如,从马到斑马,从素描到彩色图像)的模型。因此,我们不能在两个离散状态之间连续调整一个特征(例如,在脸上添加更多胡须)。另外,一个网络专用于一种类型的迁移,因此调整 10 个特征需要十个不同的神经网络。
2.2 条件生成器
条件生成器以 conditional GAN,AC-GAN 和 Stack-GAN 为代表,是在训练期间联合学习带有特征标签的图像的模型,使得图像生成能够以自定义特征为条件。因此,如果你想在生成过程中添加新的可调特征,你就得重新训练整个 GAN 模型,而这将耗费大量的计算资源和时间(例如,在带有完美超参数的单一 K80 GPU 上需要几天甚至几个星期)。此外,你要用包含所有自定义特征标签的单个数据集来执行训练,而不是利用来自多个数据集的不同标签。
2.3 Transparent Latent-space GAN 模型
TL-GAN:一种新型高效的可控合成和编辑方法。它允许用户使用单个网络逐渐调整单个或多个特征。除此之外,添加新的可调特征可以在一个小时之内非常高效地完成。
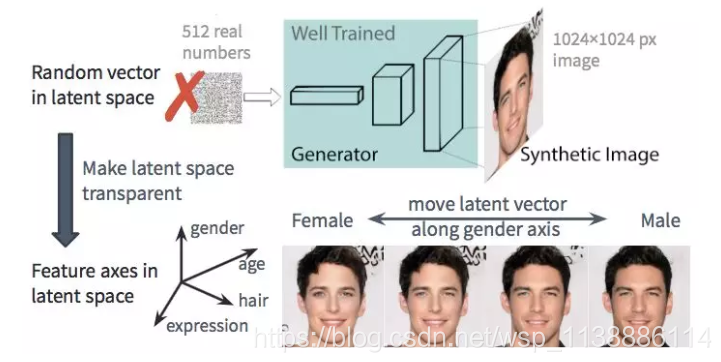
通过用预训练的 pg-GAN 进行实验,我发现潜在空间具有两个良好的特性:
- 它很稠密,这意味着空间汇总的大多数点能够生成合理的图像;
- 它相当连续,意味着潜在空间中两点之间的插值通常会导致相应图像的平滑过渡。
考虑到这两点,我觉得可以在潜在空间中找到能够预测我们关心的特征(如,女性-男性)的方向。如果是这样的话,我们可以把这些方向的单位向量用作控制生成过程(更男性化或更女性化)的特征轴。
揭示特征轴
为了在潜在空间中找到这些特征轴,我们将通过在成对数据 (z,y) 上训练的监督学习方法构建潜在向量 z 与特征标签 y 之间的关系。现在问题变成了如何得到此类成对数据,因为现有数据集仅包含图像 x 及其对应特征标签 y。
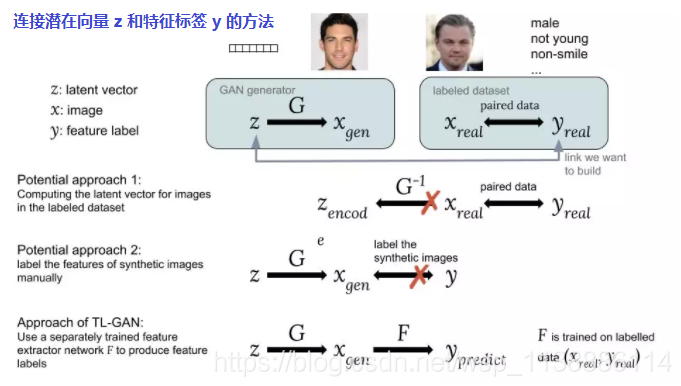
可能的方法
- 一种可能方法是计算来自现有数据集的图像 x_real 的潜在向量 z,x_real 的标签是 y_real。但是,GAN 无法提供计算 z_encode=G^(−1)(x_real) 的简单方式,因此这个方法很难实现。
- 第二种可能方法是使用来自随机潜在向量 z 的 GAN 来生成合成图像 x_gen,即 x_gen=G(z)。问题在于合成图像没有标签,我们无法轻松地利用可用的标注数据集。
为了解决该问题,TL-GAN 模型做出了一项重要创新:
- 利用已有标注图像数据集 (x_real, y_real) 训练单独的特征提取器(用于离散标签的分类器或用于连续标签的回归器)模型 y=F(x)
- 然后将训练好的 GAN 生成器 G 与特征提取器网络 F 结合起来。这样,我们就能利用训练好的特征提取器网络来预测合成图像 x_gen 的特征标签 y_pred,从而通过合成图像建立 z 和 y 之间的联系,即 x_gen=G(z) and y_pred=F(x_gen)。
现在我们有了成对的潜在向量和特征,可以序列回归器模型y=A(z) 来找出可用于控制图像生成过程的所有特征轴。
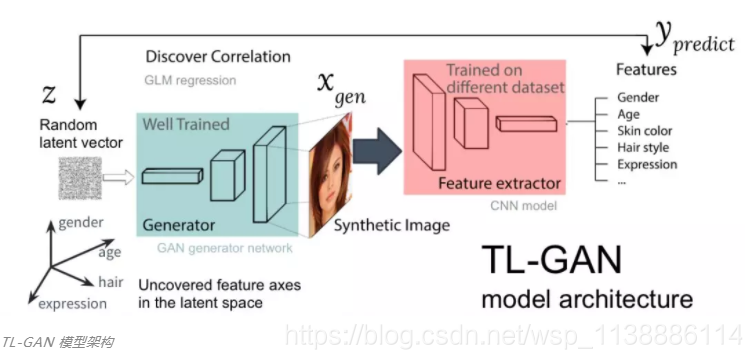
如上图所示: TL-GAN 模型的架构,共包括五步:
- 学习分布:选择一个训练好的 GAN 模型作为生成器网络。我选择的是训练好的 pg-GAN,它提供的人脸生成质量最好。
- 分类:选择一个预训练的特征提取器模型(可以是卷积神经网络,也可以是其它计算机视觉模型),或者利用标注数据集训练自己的特征提取器。我在 CelebA 数据集上训练了一个简单的 CNN,该数据集包含三万余张人脸图像,每个图像有 40 个标签。
- 生成:生成大量随机潜在向量,并传输到训练好的 GAN 生成器中以生产合成图像,然后使用训练好的特征提取器为每张图像生成特征。
- 关联:使用广义线性模型(Generalized Linear Model,GLM)执行潜在向量和特征之间的回归任务。回归斜率(regression slope)即特征轴。
- 探索:从一个潜在向量开始,沿着一或多个特征轴移动,并检测对生成图像的影响。
这个过程非常高效。只要具备一个预训练的 GAN 模型,在单 GPU 机器上识别特征轴仅需一小时。这是通过多个工程 trick 达成的,如迁移学习、下采样图像大小、预缓存合成图像等。
沿着特征轴移动潜在向量
- 首先,测试发现的特征轴能否用于控制生成图像的对应特征。为此,我在 GAN 的潜在空间中生成了一个随机向量 z_0,
- 然后将它传输到生成器网络 x_0=G(z_0) 以生成合成图像 x_0。
- 接下来,我将潜在向量沿着特征轴 u(潜在空间中的单位向量,对应人脸的性别)移动距离 λ,到达新的位置 x_1=x_0+λu,并生成新的图像 x1=G(z1)。理想情况下,新图像的对应特征可以沿着期望方向进行修改。
结果
下图展示了沿着多个示例特征轴(性别、年龄等)移动潜在空间向量的结果。效果非常棒!我们可以流畅地在男性 ←→ 女性、年轻 ←→ 年老之间变化图像。

解除相关特征轴之间的关联
上述示例也展示了该方法的缺点:相关特征轴。举例来说,当我打算减少胡须量时,生成的人脸图像更女性化,而这并非用户期望的结果。问题在于性别特征和胡须特征天然相关,修改一个必然会导致另一个也发生改变。类似的还有发际线和卷发。如下图所示,潜在空间中原始的「胡须」特征轴不垂直于性别特征轴。
为了解决这个问题,我使用直接的线性代数 trick。具体来说,我将胡须特征轴投影到新的方向,新方向垂直于性别特征轴,这就有效去除了二者之间的关联,从而解除生成人脸图像中这两个特征的关联。
该方法具备以下显著优势:
- 高效性:为生成器添加新的特征调整器(feature tuner)时,无需重新训练 GAN 模型。使用该方法添加 40 个特征调整器仅需不到一小时。
- 灵活性:你可以使用在任意数据集上训练的任意特征提取器来给训练好的 GAN 模型添加特征调整器。
代码:https://github.com/SummitKwan/transparent_latent_gan
https://blog.insightdatascience.com/generating-custom-photo-realistic-faces-using-ai-d170b1b59255















 775
775











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











