







初识MapReduce,本能的想到了datastage orchestrate并行引擎(partition,collection),很亲切,核心思想看起来差不多。只不过orchestrate中包含了各种partition、collection的具体method。但总体还是分为两类,以均匀分布为主旨的方法以及KEY值相关的方法(保证KEY相同在相同分区)。
从《Hadoop in Action》中找了两段段代码(MyJob以及Citationhistogram),学习研究如下:
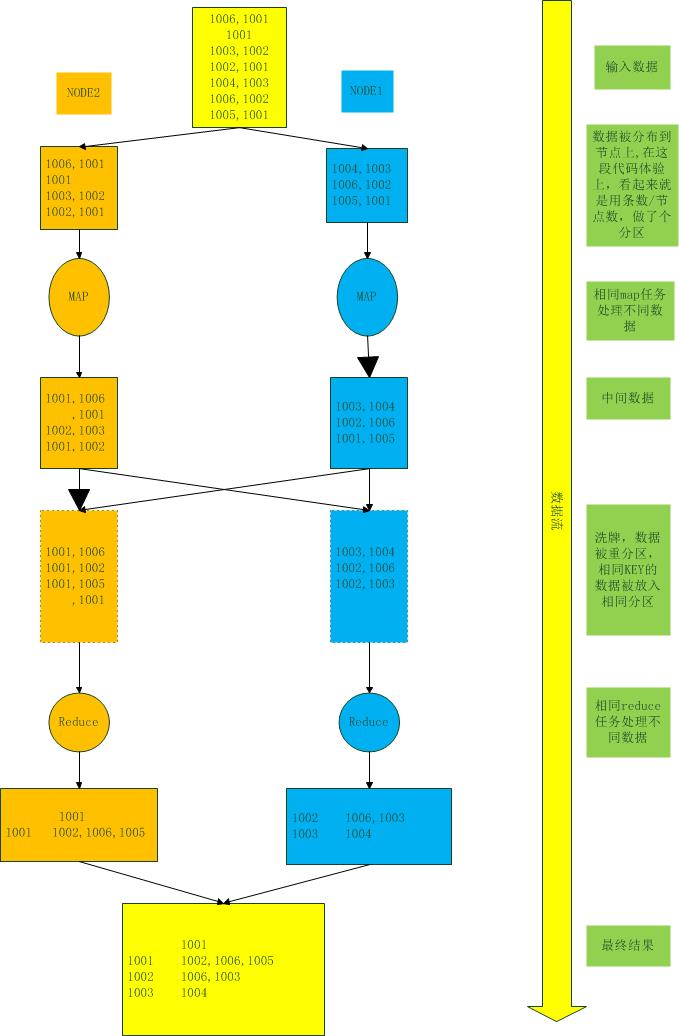
1、自己造了几条测试数据,第一列代表专利好,第二列代表对专利的引用,其中还包括一条空数据,1001没有引用专利如下(其中数据刻意没有排序):
1006,1001
1001
1003,1002
1002,1001
1004,1003
1006,1002
1005,1001
2、运行MyJob,并设置 mapred.reduce.tasks=0 ,仅仅查看Map阶段的输出
hadoop jar /home/hdpuser/IdeaProjects/MyHadooTraining/out/production/MyJob.jar MyJob -D mapred.reduce.tasks=0 /user/hdpuser/testdt/in.txt /user/hdpuser/out/myjob
注意:map阶段,将key和value对换了一下。output.collect(value, key);
3、对应输出查看如下:
[hdpuser@hdpNameNode testdt]$ hadoop fs -cat /user/hdpuser/out/myjob/*
1003 1004
1002 1006
1001 1005
1001 1006
1001
1002 1003
1001 1002
4、到本地文件系统查看相应的BLK文件
[hdpuser@hdpNameNode finalized]$ cat blk_1073742183
1001 1006
1001
1002 1003
1001 1002
[hdpuser@hdpNameNode finalized]$ cat blk_1073742184
1003 1004
1002 1006
1001 1005
5、注意上述的对应关系,刻意发现数据被分成两个文件处理(我的HADOOP集群有两个节点),原始文件的前三条一个数据块,后四条一个数据块。
6、取消 mapred.reduce.tasks=0的设置后,再次运行(先删除myjob目录)
hadoop jar /home/hdpuser/IdeaProjects/MyHadooTraining/out/production/MyJob.jar MyJob /user/hdpuser/testdt/in.txt /user/hdpuser/out/myjob
7、查看最终结果
[hdpuser@hdpNameNode testdt]$ hadoop fs -cat /user/hdpuser/out/myjob/*
1001
1001 1002,1006,1005
1002 1006,1003
1003 1004
8、从最终结果中,可以明显看出,数据是按照key排序的,虽然在测试代码中,从来没有排序的内容存在。看起来,应该是在map和reduce中间的洗牌过程,进行的排序。
9、画图整理如下:
随后学习了CitationHistogram的代码,运行的时候一直报错,发现是做类型转换时,因为我的测试数据中包含"",转int时报错,随后修改了部分代码,运行成功,数据正确。
参考代码
MyJob
主要功能是整理哪些专利被引用,例如
1001 (1002,1006,1005)
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.KeyValueTextInputFormat;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class MyJob extends Configured implements Tool {
public static class MapClass extends MapReduceBase
implements Mapper<Text, Text, Text, Text> {
public void map(Text key, Text value,
OutputCollector<Text, Text> output,
Reporter reporter) throws IOException {
output.collect(value, key);
}
}
public static class Reduce extends MapReduceBase
implements Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterator<Text> values,
OutputCollector<Text, Text> output,
Reporter reporter) throws IOException {
String csv = "";
while (values.hasNext()) {
if (csv.length() > 0) csv += ",";
csv += values.next().toString();
}
output.collect(key, new Text(csv));
}
}
public int run(String[] args) throws Exception {
Configuration conf = getConf();
JobConf job = new JobConf(conf, MyJob.class);
Path in = new Path(args[0]);
Path out = new Path(args[1]);
FileInputFormat.setInputPaths(job, in);
FileOutputFormat.setOutputPath(job, out);
job.setJobName("MyJob");
job.setMapperClass(MapClass.class);
job.setReducerClass(Reduce.class);
job.setInputFormat(KeyValueTextInputFormat.class);
job.setOutputFormat(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.set("key.value.separator.in.input.line", ",");
JobClient.runJob(job);
return 0;
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new MyJob(), args);
System.exit(res);
}
}CitationHistogram
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.KeyValueTextInputFormat;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class CitationHistogram extends Configured implements Tool {
public static class MapClass extends MapReduceBase
implements Mapper<Text, Text, IntWritable, IntWritable> {
private final static IntWritable uno = new IntWritable(1);
private IntWritable citationCount = new IntWritable();
public void map(Text key, Text value,
OutputCollector<IntWritable, IntWritable> output,
Reporter reporter) throws IOException {
try
{
citationCount.set(Integer.parseInt(value.toString()));
}
catch (NumberFormatException e)
{
citationCount.set(9999);
}
output.collect(citationCount, uno);
}
}
public static class Reduce extends MapReduceBase
implements Reducer<IntWritable,IntWritable,IntWritable,IntWritable>
{
public void reduce(IntWritable key, Iterator<IntWritable> values,
OutputCollector<IntWritable, IntWritable>output,
Reporter reporter) throws IOException {
int count = 0;
while (values.hasNext()) {
count += values.next().get();
}
output.collect(key, new IntWritable(count));
}
}
public int run(String[] args) throws Exception {
Configuration conf = getConf();
JobConf job = new JobConf(conf, CitationHistogram.class);
Path in = new Path(args[0]);
Path out = new Path(args[1]);
FileInputFormat.setInputPaths(job, in);
FileOutputFormat.setOutputPath(job, out);
job.setJobName("CitationHistogram");
job.setMapperClass(MapClass.class);
job.setReducerClass(Reduce.class);
job.setInputFormat(KeyValueTextInputFormat.class);
job.setOutputFormat(TextOutputFormat.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
job.set("key.value.separator.in.input.line", ",");
JobClient.runJob(job);
return 0;
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(),
new CitationHistogram(),
args);
System.exit(res);
}
}















 1201
1201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









