







数据挖掘分类:supervised和unsupervised两类。supervised有:classification和regression,decision tree 。unsupervised有clustering,association两类。今天看了decision tree这一节。
decision tree就是有各种属性和路劲。属性是分类的根本。有predictor factor 和response factor(ps:这两个是所有的supervised的方法都有的)。用entropy来度量每一次分类的好坏,entropy的减少就代表我们得到了新的信息。
其中谈到了entropy这个概念,entropy就是信息熵,表示需要多少个bit来秒速一个set中包含的信息。它的值越小说明需要的bit越少。它的值可以是大于等于0的任何实数,不一定是整数,可以是小数等。得到一个结果以后先计算entropy,然后结合上一层的概率,计算总的entropy,期望的entropy值变小,否则就不是一个好的分类。
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ 今儿看了算法的第一周的第一讲:
首先通过一个例子引出算法:对于现实中的问题,先建模,然后实现,分析算法,改进算法。通过一个percolation的例子(即如何找到两个点是否相连)。
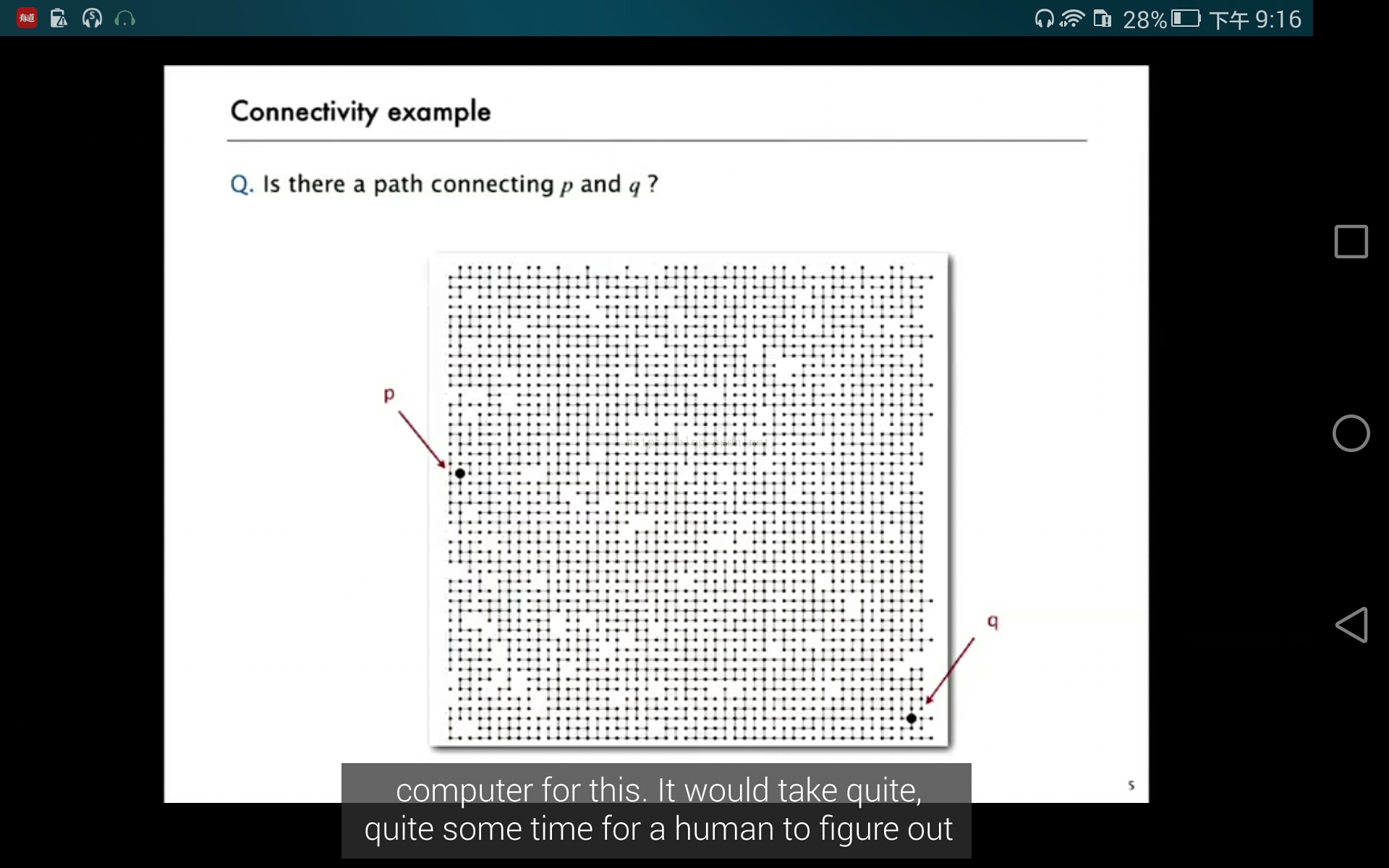
讲到的算法基本思路:先将所有的点用以为数组array表示,分别用1到n的值来表示array数组的值,然后将图中的连接信息用txt文本文件表示,程序读取文件,将连接信息用union方法表示在先前定义的数组array中,然后判断(connected方法)两个点是否相连。
算法的实现方法:
fast find(union(p,q)当两个点相连的时候,将数组中所有的值等于array[p]的点的值都换成array[q]的值),它的特点是:union的时间复杂度是n,connected的时间复杂度是1。。。
fast union:虽然它用的名字是fast union,但是它的union并不快速,connected和union 的时间复杂度都是n因为用到了root方法。(union只是更改最新连接进来的点的值即array的值)
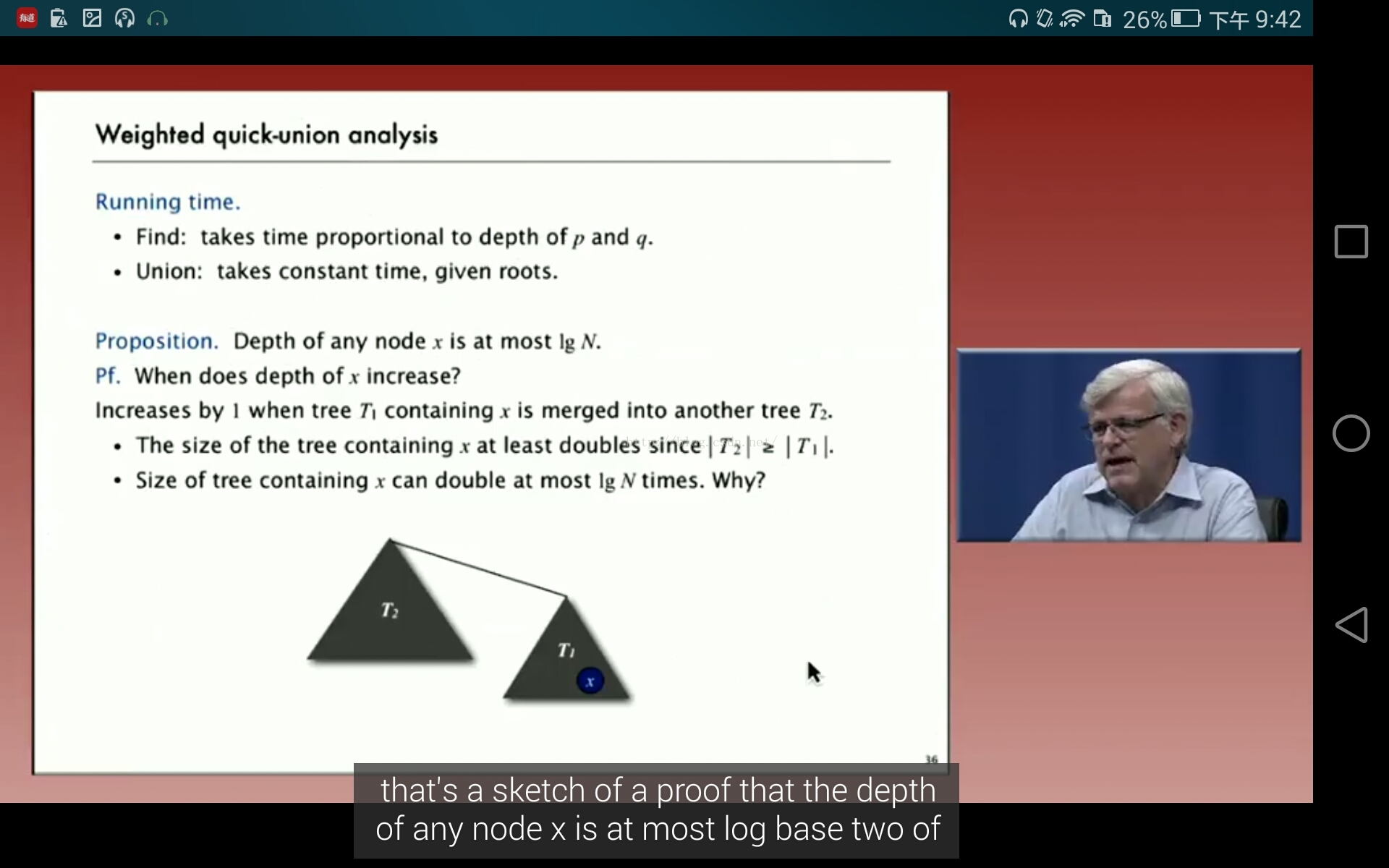
改进的fast union :两种方法:weighted和pass compass。weighted考虑在把它们连接的时候将size较大的根指向size较小的根。weighted时间复杂度是lgn,证明:当你把较小size的作为孩子连接到较大的size的时候,它的size的变化最大是两倍,而size的最大值是n。所以是lgn
pass compass考虑将孙子节点直接和祖父节点相连。
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
文本文件和二进制文件的区别:文本文件包含字符,由asc码组成,而二进制文件则是01表示,与系统有关。dat就是一个二进制文件,文本编辑器是无法查看它的内容的。
serializable接口是:减少内存而设计的,就是当一个对象被第二次存储时,直接就存储这个序列,而不用存储第二次。
写入文件:printwriter
读出文件:scanner
它们都需要用一个管道才可以与文件交流,就是fileinputstream和filereader等。
问题:1,2是怎么算出来的entropy,为什么1.75的反而用到了更多的bit?
2,pass compass之后的时间复杂度?
3,应用Monte carlo simulation?














 3816
3816











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









