








一 概述
我们经常在创建线程执行函数/worker执行函数,定时器执行函数等等情况下,会经常看到schedule函数的调用,这是进程上下文,还有中断上下文的调度,即preempt_schedule_irq.另外我们在进程调度的时候会看到是否需要设置重新调度的标识,这时候
1.1 schedule()
这个函数是最常使用的调度函数:
static inline void sched_submit_work(struct task_struct *tsk)
{ /*确保当前进程是存在的*/
if (!tsk->state || tsk_is_pi_blocked(tsk))
return;
/*
* If we are going to sleep and we have plugged IO queued,
* make sure to submit it to avoid deadlocks.
*/ /*确保IO队列能够在休眠之前提交,防止死锁*/
if (blk_needs_flush_plug(tsk))
blk_schedule_flush_plug(tsk);
}
asmlinkage __visible void __sched schedule(void)
{ /*获得当前进程*/
struct task_struct *tsk = current;
/*根据进程状态信息/根据是否有io队列插入来避免死锁机制*/
sched_submit_work(tsk);
do {/*抢占禁止*/
preempt_disable();
/*进行调度*/
__schedule(false);
sched_preempt_enable_no_resched();
} while (need_resched());
}
1.1.1 抢占是如何实现的
可以看看禁止抢占和enable抢占是怎么实现的:
#define preempt_disable() \
do { \
/*增加preempt_count数值 +1*/
preempt_count_inc(); \
/*目的保证preempt_counter数值及时的更新到内存中*/
barrier(); \
} while (0)
#define __preempt_count_inc() __preempt_count_add(1)
#define preempt_count_add(val) __preempt_count_add(val)
/*
* The various preempt_count add/sub methods
*/
static __always_inline void __preempt_count_add(int val)
{
*preempt_count_ptr() += val;
}
static __always_inline int *preempt_count_ptr(void)
{
return ¤t_thread_info()->preempt_count;
}
/*启用抢占,与禁止抢占是两个相反的过程,启用是减少抢占计数器的数值 -1.*/
#define sched_preempt_enable_no_resched() \
do { \
/*确保修改的抢占计数器的数值是内存中最新的数值.*/
barrier(); \
preempt_count_dec(); \
} while (0)
1.1.2 调度标识实现原理
即函数need_resched()函数是如何实现的:
static __always_inline bool need_resched(void)
{ /*判断是否需要重新调度*/
return unlikely(tif_need_resched());
}
#define tif_need_resched() test_thread_flag(TIF_NEED_RESCHED)
#define test_thread_flag(flag) \
test_ti_thread_flag(current_thread_info(), flag)
/*是否ti->flags标识符集合里面是否设置了 flag这个bit位.test_bit函数实现还是挺有趣的*/
static inline int test_ti_thread_flag(struct thread_info *ti, int flag)
{
return test_bit(flag, (unsigned long *)&ti->flags);
}
/**
* test_bit - Determine whether a bit is set
* @nr: bit number to test
* @addr: Address to start counting from
*/
static inline int test_bit(int nr, const volatile unsigned long *addr)
{
return 1UL & (addr[BIT_WORD(nr)] >> (nr & (BITS_PER_LONG-1)));
}
/*arch/arm64/include/asm/thread_info.h*/
/*
* thread information flags:
* TIF_SYSCALL_TRACE - syscall trace active
* TIF_SYSCALL_TRACEPOINT - syscall tracepoint for ftrace
* TIF_SYSCALL_AUDIT - syscall auditing
* TIF_SECOMP - syscall secure computing
* TIF_SIGPENDING - signal pending
* TIF_NEED_RESCHED - rescheduling necessary /*必须重新调度标识*/
* TIF_NOTIFY_RESUME - callback before returning to user
* TIF_USEDFPU - FPU was used by this task this quantum (SMP)
*/
#define TIF_SIGPENDING 0
#define TIF_NEED_RESCHED 1
#define TIF_NOTIFY_RESUME 2 /* callback before returning to user */
#define TIF_FOREIGN_FPSTATE 3 /* CPU's FP state is not current's */
#define TIF_NOHZ 7
#define TIF_SYSCALL_TRACE 8
#define TIF_SYSCALL_AUDIT 9
#define TIF_SYSCALL_TRACEPOINT 10
........
在头文件include/linux/sched.h文件里面涉及到很多与重新调度标识相关的函数实现,比如test/set/clear等等操作.可以看到下面这个函数:
/*
* resched_curr - mark rq's current task 'to be rescheduled now'.
*
* On UP this means the setting of the need_resched flag, on SMP it
* might also involve a cross-CPU call to trigger the scheduler on
* the target CPU.
*/
void resched_curr(struct rq *rq)
{
struct task_struct *curr = rq->curr;
int cpu;
lockdep_assert_held(&rq->lock);
/*是否当前进程设置了TIF_NEED_RESCHED标识*/
if (test_tsk_need_resched(curr))
return;
cpu = cpu_of(rq);
if (cpu == smp_processor_id()) {
/*设置必须重新调度标识*/
set_tsk_need_resched(curr);
set_preempt_need_resched();
return;
}
if (set_nr_and_not_polling(curr))
smp_send_reschedule(cpu);
else
trace_sched_wake_idle_without_ipi(cpu);
}
可以看到很多地方都会使用到TIF_NEED_RESCHED标识符
1.2 preempt_schedule_common()
实现原理如下:
static void __sched notrace preempt_schedule_common(void)
{
do {
/*设置禁止抢占,即减少preempt_count计数器数值 +1*/
preempt_disable_notrace();
__schedule(true);/*抢占标识为true*/
preempt_enable_no_resched_notrace();
/*
* Check again in case we missed a preemption opportunity
* between schedule and now.
*//*是否需要重新调度,即不断的检测当前进程是否需要重新调度*/
} while (need_resched());
}
实现原理比较简单,但是使用在何处呢?有下面四种用途:
/*
* this is the entry point to schedule() from in-kernel preemption
* off of preempt_enable. Kernel preemptions off return from interrupt
* occur there and call schedule directly.
*//*这是来自抢占起用的内核内抢占关闭schedule()的入口点。从中断返回的内核抢占发生在那里并直接调用调度。*/
asmlinkage __visible void __sched notrace preempt_schedule(void)
{
/*
* If there is a non-zero preempt_count or interrupts are disabled,
* we do not want to preempt the current task. Just return..
*/ /*表示抢占禁止或者中断禁止,则直接返回*/
if (likely(!preemptible()))
return;
/*抢占调度*/
preempt_schedule_common();
}
NOKPROBE_SYMBOL(preempt_schedule);
/*
*
* Returns true when we need to resched and can (barring IRQ state).
*/
static __always_inline bool should_resched(int preempt_offset)
{
return unlikely(preempt_count() == preempt_offset &&
tif_need_resched());
}
int __sched _cond_resched(void)
{ /*检测抢占计数器是否为0,为0表示可以抢占,并且检测当前进程是否设置了抢占标识bit.只
有两者完全符合条件,才开始抢占调度*/
if (should_resched(0)) {
preempt_schedule_common();
return 1;
}
return 0;
}
/*
* __cond_resched_lock() - if a reschedule is pending, drop the given lock,
* call schedule, and on return reacquire the lock.
*
* This works OK both with and without CONFIG_PREEMPT. We do strange low-level
* operations here to prevent schedule() from being called twice (once via
* spin_unlock(), once by hand).
*/
int __cond_resched_lock(spinlock_t *lock)
{
int resched = should_resched(PREEMPT_LOCK_OFFSET);
int ret = 0;
lockdep_assert_held(lock);
/*是否在spin_lock期间有紧急事情处理,需要中断spinlock发起临时调度*/
if (spin_needbreak(lock) || resched) {
spin_unlock(lock);
/*可以抢占调度*/
if (resched)
preempt_schedule_common();
else
cpu_relax();/*等待抢占resched为true,否则一直在这里低功耗忙等待*/
ret = 1;
spin_lock(lock); /*抢占调度完毕之后,重新加上spinlock锁*/
}
return ret;
}
int __sched __cond_resched_softirq(void)
{
BUG_ON(!in_softirq());
/*在软中断上下文环境,是否可以发生抢占调度*/
if (should_resched(SOFTIRQ_DISABLE_OFFSET)) {
local_bh_enable();
preempt_schedule_common();
local_bh_disable();
return 1;
}
return 0;
}
上面的也比较好理解,关键还是需要理解若干个涉及到抢占相关的几个offset数值
1.3 preempt_schedule_irq()
/*
* this is the entry point to schedule() from kernel preemption
* off of irq context.
* Note, that this is called and return with irqs disabled. This will
* protect us against recursive calling from irq.
*/
asmlinkage __visible void __sched preempt_schedule_irq(void)
{ /*上下文状态
enum ctx_state {
CONTEXT_DISABLED = -1,/* returned by ct_state() if unknown */
CONTEXT_KERNEL = 0,
CONTEXT_USER,
CONTEXT_GUEST,
*/
enum ctx_state prev_state;
/* Catch callers which need to be fixed */
BUG_ON(preempt_count() || !irqs_disabled());
/*获取异常进入的上下文状态,实在userspace还是在kernelspace?*/
prev_state = exception_enter();
do {/*抢占禁止和本地中断enable,并开始抢占调度*/
preempt_disable();
local_irq_enable();
__schedule(true);
local_irq_disable();
sched_preempt_enable_no_resched();
} while (need_resched());
/*在异常情况下,告知上下文tracing,CPU正在进入prev_state状态*/
exception_exit(prev_state);
}
1.4 preempt_schedule_notrace()
源代码如下:
/**
* preempt_schedule_notrace - preempt_schedule called by tracing
*
* The tracing infrastructure uses preempt_enable_notrace to prevent
* recursion and tracing preempt enabling caused by the tracing
* infrastructure itself. But as tracing can happen in areas coming
* from userspace or just about to enter userspace, a preempt enable
* can occur before user_exit() is called. This will cause the scheduler
* to be called when the system is still in usermode.
*
* To prevent this, the preempt_enable_notrace will use this function
* instead of preempt_schedule() to exit user context if needed before
* calling the scheduler.
*/ /*从其解释可以看出,目的是在退出用户空间上下文期间需要调度的话,需要防止无限循环*/
asmlinkage __visible void __sched notrace preempt_schedule_notrace(void)
{
enum ctx_state prev_ctx;
if (likely(!preemptible()))
return;
do {
preempt_disable_notrace();
/*
* Needs preempt disabled in case user_exit() is traced
* and the tracer calls preempt_enable_notrace() causing
* an infinite recursion.
*/
prev_ctx = exception_enter();
__schedule(true);
exception_exit(prev_ctx);
preempt_enable_no_resched_notrace();
} while (need_resched());
}
代码比较好理解,最重要的是设置这个函数的目的是什么,用途是什么?
1.5 编译属性解析
在上面的代码中,在函数定义的前面出现的__sched/notrace/__visible/__always_inline分析如下.
__attribute__这个关键词是GNU编译器中的编译属性,ARM编译器也支持这个用法。__attribute__主要用于改变所声明或定义的函数或 数据的特性,它有很多子项,用于改变作用对象的特性。比如对函数,noline将禁止进行内联扩展、noreturn表示没有返回值、pure表明函数除 返回值外,不会通过其它(如全局变量、指针)对函数外部产生任何影响。当然,__attribute__肯定有很多的用法,今天就用到了section部分,所以就只针对这个做一些记录。
提到section,就得说RO RI ZI了,在ARM编译器编译之后,代码被划分为不同的段,RO Section(ReadOnly)中存放代码段和常量,RW Section(ReadWrite)中存放可读写静态变量和全局变量,ZI Section(ZeroInit)是存放在RW段中初始化为0的变量。
MDK给出的帮助文档如下,他将__attribute__的用法归类到编译器特性里,以变量和函数的两种用法做区分。
- 编译时为变量指定段:
__attribute__((section("name")))
RealView Compilation Tools for µVision Compiler Reference Guide Version 4.0
Home > Compiler-specific Features > Variable attributes > __attribute__((section("name")))
4.5.6. __attribute__((section("name")))
Normally, the ARM compiler places the objects it generates in sections like data and bss. However, you might require additional data sections or you might want a variable to appear in a special section, for example, to map to special hardware. The section attribute specifies that a variable must be placed in a particular data section. If you use the section attribute, read-only variables are placed in RO data sections, read-write variables are placed in RW data sections unless you use the zero_init attribute. In this case, the variable is placed in a ZI section.
Note
This variable attribute is a GNU compiler extension supported by the ARM compiler.
Example
/* in RO section */
const int descriptor[3] __attribute__ ((section ("descr"))) = { 1,2,3 };
/* in RW section */
long long rw[10] __attribute__ ((section ("RW")));
/* in ZI section *
long long altstack[10] __attribute__ ((section ("STACK"), zero_init));
- 编译时为函数指定段
__attribute__((section("name")))
RealView Compilation Tools for µVision Compiler Reference Guide Version 4.0
Home > Compiler-specific Features > Function attributes > __attribute__((section("name")))
4.3.13. __attribute__((section("name")))
The section function attribute enables you to place code in different sections of the image.
Note
This function attribute is a GNU compiler extension that is supported by the ARM compiler.
Example
In the following example, Function_Attributes_section_0 is placed into the RO section new_section rather than .text.
void Function_Attributes_section_0 (void)
__attribute__ ((section ("new_section")));
void Function_Attributes_section_0 (void)
{
static int aStatic =0;
aStatic++;
}
In the following example, section function attribute overrides the #pragma arm section setting.
#pragma arm section code="foo"
int f2()
{
return 1;
} // into the 'foo' area
__attribute__ ((section ("bar"))) int f3()
{
return 1;
} // into the 'bar' area
int f4()
{
return 1;
} // into the 'foo' area
#pragma arm section
上面清晰的简介了__attribute__属性的原理和用法,当然,字段很多,可以参考相应的arm文档.
http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.dui0348bc/CHDFIBBI.html
1.5.1 __sched属性
其定义如下:
/* Attach to any functions which should be ignored in wchan output. */
#define __sched __attribute__((__section__(".sched.text")))
代码的意思比较简单,就是把带有__sched的函数放到.sched.text段。
上面还有一行注释,解释了为什么要放到.sched.text段,这才是有意思的地方。说的是,如果不想让函数在waiting channel中显示出来,就该加上__sched。
kernel有个waiting channel,如果用户空间的进程睡眠了,可以查到是停在内核空间哪个函数中等待的:cat "/proc/<pid>/wchan"
那显然,.sched.text段的代码是会被wchan忽略的,schedule这个函数是不会出现在wchan的结果中的。其实主要的目的还是提升代码性能和稳定性而做的.可以在代码中看到涉及到schedule的调度都是__sched属性,都存放在.sched.text段中,即存放在同一段物理地址中. 这部分待解.后面仔细check下.sched.text内容.
我们能够看到.sched.text内容如下:
/* sched.text is aling to function alignment to secure we have same
* address even at second ld pass when generating System.map */
#define SCHED_TEXT \
ALIGN_FUNCTION(); \
VMLINUX_SYMBOL(__sched_text_start) = .; \
*(.sched.text) \
VMLINUX_SYMBOL(__sched_text_end) = .;
解释的一目了然.
1.5.2 notrace属性
定义如下:
#if defined(CC_USING_HOTPATCH) && !defined(__CHECKER__)
#define notrace __attribute__((hotpatch(0,0)))
#else
#define notrace __attribute__((no_instrument_function))
#endif
此函数属性将指示在使用 --gnu_instrument 进行检测时不包括该函数。即不执行instrument操作,可能的意思是不可寻址???不太明白
1.5.3 __visible属性
定义如下:
#if GCC_VERSION >= 40600
/*
* When used with Link Time Optimization, gcc can optimize away C functions or
* variables which are referenced only from assembly code. __visible tells the
* optimizer that something else uses this function or variable, thus preventing
* this.
*/
#define __visible __attribute__((externally_visible))
#endif
意思就是__visible告知优化器,某些地方使用此函数或者变量,__visible会阻止对其进行优化操作.此变量属性影响 ELF 符号的可见性。
1.5.4 __always_inline属性
定义如下:
/*include/linux/compiler-gcc.h*/
#define __always_inline inline __attribute__((always_inline))
#define noinline __attribute__((noinline))
/*include/linux/compiler.h*/
#ifndef __always_inline
#define __always_inline inline
#endif
此函数属性指示必须内联函数。
编译器将尝试内联函数,而不考虑函数的特性。但是,如果这样做导致出现问题,编译器将不内联函数。例如,递归函数仅内联到本身一次。必须注意的是:
此函数属性是 ARM 编译器支持的 GNU 编译器扩展。它具有等效的关键字__forceinline 。
使用示例:
__forceinline static int max(int x, in y)
{
return x > y ? x : y; // always inline if possible
}
很好理解.
上面是简单的了解下__attribute__属性,需要再次加强在汇编和编译属性方面的知识积累.
二 核心函数__schedule原理
我们看看其源码如下:
/*
* __schedule() is the main scheduler function.
*
* The main means of driving the scheduler and thus entering this function are:
*
* 1. Explicit blocking: mutex, semaphore, waitqueue, etc.
*
* 2. TIF_NEED_RESCHED flag is checked on interrupt and userspace return
* paths. For example, see arch/x86/entry_64.S.
*
* To drive preemption between tasks, the scheduler sets the flag in timer
* interrupt handler scheduler_tick().
*
* 3. Wakeups don't really cause entry into schedule(). They add a
* task to the run-queue and that's it.
*
* Now, if the new task added to the run-queue preempts the current
* task, then the wakeup sets TIF_NEED_RESCHED and schedule() gets
* called on the nearest possible occasion:
*
* - If the kernel is preemptible (CONFIG_PREEMPT=y):
*
* - in syscall or exception context, at the next outmost
* preempt_enable(). (this might be as soon as the wake_up()'s
* spin_unlock()!)
*
* - in IRQ context, return from interrupt-handler to
* preemptible context
*
* - If the kernel is not preemptible (CONFIG_PREEMPT is not set)
* then at the next:
*
* - cond_resched() call
* - explicit schedule() call
* - return from syscall or exception to user-space
* - return from interrupt-handler to user-space
*
* WARNING: must be called with preemption disabled!
*/
static void __sched notrace __schedule(bool preempt)
{
struct task_struct *prev, *next;
unsigned long *switch_count;
struct rq *rq;
int cpu;
u64 wallclock;
cpu = smp_processor_id();
rq = cpu_rq(cpu);
rcu_note_context_switch();
prev = rq->curr;
/*
* do_exit() calls schedule() with preemption disabled as an exception;
* however we must fix that up, otherwise the next task will see an
* inconsistent (higher) preempt count.
*
* It also avoids the below schedule_debug() test from complaining
* about this.
*/
if (unlikely(prev->state == TASK_DEAD))
preempt_enable_no_resched_notrace();
schedule_debug(prev);
if (sched_feat(HRTICK))
hrtick_clear(rq);
/*
* Make sure that signal_pending_state()->signal_pending() below
* can't be reordered with __set_current_state(TASK_INTERRUPTIBLE)
* done by the caller to avoid the race with signal_wake_up().
*/
smp_mb__before_spinlock();
raw_spin_lock_irq(&rq->lock);
lockdep_pin_lock(&rq->lock);
rq->clock_skip_update <<= 1; /* promote REQ to ACT */
switch_count = &prev->nivcsw;
if (!preempt && prev->state) {
if (unlikely(signal_pending_state(prev->state, prev))) {
prev->state = TASK_RUNNING;
} else {
deactivate_task(rq, prev, DEQUEUE_SLEEP);
prev->on_rq = 0;
/*
* If a worker went to sleep, notify and ask workqueue
* whether it wants to wake up a task to maintain
* concurrency.
*/
if (prev->flags & PF_WQ_WORKER) {
struct task_struct *to_wakeup;
to_wakeup = wq_worker_sleeping(prev, cpu);
if (to_wakeup)
try_to_wake_up_local(to_wakeup);
}
}
switch_count = &prev->nvcsw;
}
if (task_on_rq_queued(prev))
update_rq_clock(rq);
next = pick_next_task(rq, prev);
wallclock = walt_ktime_clock();
walt_update_task_ravg(prev, rq, PUT_PREV_TASK, wallclock, 0);
walt_update_task_ravg(next, rq, PICK_NEXT_TASK, wallclock, 0);
clear_tsk_need_resched(prev);
clear_preempt_need_resched();
rq->clock_skip_update = 0;
if (likely(prev != next)) {
#ifdef CONFIG_SCHED_WALT
if (!prev->on_rq)
prev->last_sleep_ts = wallclock;
#endif
rq->nr_switches++;
rq->curr = next;
++*switch_count;
trace_sched_switch(preempt, prev, next);
rq = context_switch(rq, prev, next); /* unlocks the rq */
cpu = cpu_of(rq);
} else {
lockdep_unpin_lock(&rq->lock);
raw_spin_unlock_irq(&rq->lock);
}
balance_callback(rq);
}
对于这个函数的注释部分解析如下:
__schedule()是主要的调度器函数,驱动调度器从而进入此函数的主要方法如下:
1.显示阻塞:比如mutex,semaphore,waitqueue等等
2.TIF_NEED_RESCHED标识在中断和用户空间返回路径上被检测.目的在进程间驱动抢占,调度器设置这个flag在定时器中断handler scheduler_tick()函数中
3.wakeup并不会真正的进入schedule(),调度器会把其加入到运行队列,并且就是这样做的.现在,如果新的进程加入到运行队列并且抢占了当前进程,然后wakeup 就会设置TIF_NEED_RESCHED这个flag,并且schedule()会以下面几种场合调用:
3.1 接着如果kernel是可抢占的(CONFIG_PREEMPT=y)
3.1.1 在系统调用/异常上下文,在下一个最外层启用抢占调度.这可能是wakeup的spin_unlock().这时候会发生抢占调度
3.1.2 在中断上下文,从中断handler到抢占上下文返回.这时候会发生抢占调度
3.2 如果kernel是不可抢占的(CONFIG_PREEMPT is not set)
3.2.1 cond_resched()调用
3.2.2 显示调用schedule()
3.2.3 从系统调用/异常返回到用户空间
3.2.4 从中断handler返回到用户空间
上面是明确调度的时机.
从上面的解释可以看到,调用路径很多.也说明了调度器的复杂性.
代码分如下几个部分来拆解解析:
- 调度之前初始化工作
- 根据preempt flag/当前进程的状态
- 挑选next进程来取代当前运行的进程
- prev与next进程上下文切换
- balance_callback调用
下面各个来分析
2.1 调度之前初始化工作
本部分分析下面的代码:
static void __sched notrace __schedule(bool preempt)
{
struct task_struct *prev, *next;
unsigned long *switch_count;
struct rq *rq;
int cpu;
u64 wallclock;
/*__schedule函数运行所在的cpu id上*/
cpu = smp_processor_id();
rq = cpu_rq(cpu); /*获取此cpu的rq运行队列*/
/*注意上下文切换。这是RCU-sched的静止状态,需要对可抢占的RCU进行特殊处理。调用者
必须禁用抢占。*/
rcu_note_context_switch();
prev = rq->curr; /*获取当前在rq上运行的task*/
/*
* do_exit() calls schedule() with preemption disabled as an exception;
* however we must fix that up, otherwise the next task will see an
* inconsistent (higher) preempt count.
*
* It also avoids the below schedule_debug() test from complaining
* about this.
*//*do_exit()调用schedule()函数的时候,将抢占禁用作为一个异常.这就会
引入一个bug,下一个进程调度会看到不一样的preempt count(数值变高了),所以当进程
dead的状态,需要将preempt count减一操作,恢复原来的数值.*/
if (unlikely(prev->state == TASK_DEAD))
preempt_enable_no_resched_notrace();/*preempt_count - 1操作*/
/*基于时间调度检测和调度统计,debug使用*/
schedule_debug(prev);
/*在feature.h中SCHED_FEAT(HRTICK, false),不成立*/
if (sched_feat(HRTICK))
hrtick_clear(rq);/*取消rq成员变量 hrtick_timer hrtimer结构体变量*/
/*
* Make sure that signal_pending_state()->signal_pending() below
* can't be reordered with __set_current_state(TASK_INTERRUPTIBLE)
* done by the caller to avoid the race with signal_wake_up().
*/
/*对上面的理解如下:
1. 当存在signal_pending_state()->signal_pending()时候,即后面有signal处于
pending状态
2. 但是此时调用者设置了进程状态为TASK_INTERRUPTIBLE(可响应信号/中断)
3. 确保他们响应signal的次序不会被重排,目的避免使用signal_wake_up引起竞争.*/
smp_mb__before_spinlock();
raw_spin_lock_irq(&rq->lock);
lockdep_pin_lock(&rq->lock);
rq->clock_skip_update <<= 1; /* promote REQ to ACT */
/*获取当前进程上下文切换次数.*/
switch_count = &prev->nivcsw;
.............................
}
上面主要处理两种情况,一种就是处理进程进入dead状态.另外一种就是解决进程signal竞争
2.2 根据preempt flag/当前进程的状态
需要分析的代码如下:
static void __sched notrace __schedule(bool preempt)
{
.............................
switch_count = &prev->nivcsw;
if (!preempt && prev->state) {
if (unlikely(signal_pending_state(prev->state, prev))) {
/*如果preempt为false && prev进程状态存在,并且此进程有pending的signal发
生,则将此进程状态设置为running状态*/
prev->state = TASK_RUNNING;
} else {
/*其他情况,则直接将prev进程出队列,同时设置on_rq=0,表示prev进程不在当前
rq上*/
deactivate_task(rq, prev, DEQUEUE_SLEEP);
prev->on_rq = 0;
/*
* If a worker went to sleep, notify and ask workqueue
* whether it wants to wake up a task to maintain
* concurrency.
*/
/*对上面的解释如下:
* 如果工作者线程已经休眠了,通知并且询问工作者队列是否需要唤醒进程来维持并发性
* 如果当前进程的flags集配置了PF_WQ_WORKER则需要处理.
*/
if (prev->flags & PF_WQ_WORKER) {
struct task_struct *to_wakeup;
/*获取线程池中第一个idle的worker,如果此worker不为空,则返回此
worker相关联的进程.*/
to_wakeup = wq_worker_sleeping(prev, cpu);
/*将to_wakeup进程放入到运行队列中,开始被调度*/
if (to_wakeup)
try_to_wake_up_local(to_wakeup);/*入队,虚拟运行时间update*/
}
}
switch_count = &prev->nvcsw;
}
/*如果进程在rq中,则update rq的clock相关信息*/
if (task_on_rq_queued(prev))
update_rq_clock(rq);
.............................
}
有一个挺有意思的就是,在struct task_struct结构体存有三个相关的上下文切换的计数器:
unsigned long nvcsw, nivcsw; /* context switch counts */
/* hung task detection */
unsigned long last_switch_count;
nvcsw/nivcsw是自愿(voluntary)/非自愿(involuntary)上下文切换计数.last_switch_count是nvcsw和nivcsw的总和。比如在fork,exit等操作的时候都会修改这几个参数数值
2.3 挑选next进程来取代当前运行的进程
需要解析的代码如下:
static void __sched notrace __schedule(bool preempt)
{
............................................
/*根据prev信息,rq信息,pick一个进程即next*/
next = pick_next_task(rq, prev);
/*update 使用WALT方式计算进程负载的真实时间,即当前窗口的时间*/
wallclock = walt_ktime_clock();
/*根据进程状态,分别更新prev和next两个进程的walt相关参数*/
walt_update_task_ravg(prev, rq, PUT_PREV_TASK, wallclock, 0);
walt_update_task_ravg(next, rq, PICK_NEXT_TASK, wallclock, 0);
/*清除prev进程TIF_NEED_RESCHED flag*/
clear_tsk_need_resched(prev);
/*清除PREEMPT_NEED_RESCHED flag,ARM平台此函数为空*/
clear_preempt_need_resched();
rq->clock_skip_update = 0;
............................................
}
下面来看下核心函数pick_next_task的实现方式:
/*
* Pick up the highest-prio task:
*/
static inline struct task_struct *
pick_next_task(struct rq *rq, struct task_struct *prev)
{ /*首先选择调度类为fair调度类,后面会根据实际情况修改.因为大部分的进程都是fair调度类*/
const struct sched_class *class = &fair_sched_class;
struct task_struct *p;
/*
* Optimization: we know that if all tasks are in
* the fair class we can call that function directly:
*//*当前调度类为fair类,并且运行队列的nr_running数量=cfs队列h_nr_running数量
即当前运行队列里面只有normal类型的进程,没有RT类的进程*/
if (likely(prev->sched_class == class &&
rq->nr_running == rq->cfs.h_nr_running)) {
/*执行fair调度类的pick next函数*/
p = fair_sched_class.pick_next_task(rq, prev);
if (unlikely(p == RETRY_TASK))
goto again;
/* assumes fair_sched_class->next == idle_sched_class */
/*如果pick到了idle进程,则修改调度类,执行idle调度类,使rq进入idle状态*/
if (unlikely(!p))
p = idle_sched_class.pick_next_task(rq, prev);
return p;
}
again:
/*按照class优先级的高低依次遍历各个class并执行对应的pick next task函数,直到失败为
止*/
for_each_class(class) {
p = class->pick_next_task(rq, prev);
if (p) {
if (unlikely(p == RETRY_TASK))
goto again;
return p;
}
}
BUG(); /* the idle class will always have a runnable task */
}
仅仅分析fair调度类的pick_next_task函数,代码比较长,源码如下:
static struct task_struct *
pick_next_task_fair(struct rq *rq, struct task_struct *prev)
{
struct cfs_rq *cfs_rq = &rq->cfs;
struct sched_entity *se;
struct task_struct *p;
int new_tasks;
again:
#ifdef CONFIG_FAIR_GROUP_SCHED
if (!cfs_rq->nr_running)
goto idle;
if (prev->sched_class != &fair_sched_class)
goto simple;
/*
* Because of the set_next_buddy() in dequeue_task_fair() it is rather
* likely that a next task is from the same cgroup as the current.
*
* Therefore attempt to avoid putting and setting the entire cgroup
* hierarchy, only change the part that actually changes.
*/
do {
struct sched_entity *curr = cfs_rq->curr;
/*
* Since we got here without doing put_prev_entity() we also
* have to consider cfs_rq->curr. If it is still a runnable
* entity, update_curr() will update its vruntime, otherwise
* forget we've ever seen it.
*/
if (curr) {
if (curr->on_rq)
update_curr(cfs_rq);
else
curr = NULL;
/*
* This call to check_cfs_rq_runtime() will do the
* throttle and dequeue its entity in the parent(s).
* Therefore the 'simple' nr_running test will indeed
* be correct.
*/
if (unlikely(check_cfs_rq_runtime(cfs_rq)))
goto simple;
}
se = pick_next_entity(cfs_rq, curr);
cfs_rq = group_cfs_rq(se);
} while (cfs_rq);
p = task_of(se);
/*
* Since we haven't yet done put_prev_entity and if the selected task
* is a different task than we started out with, try and touch the
* least amount of cfs_rqs.
*/
if (prev != p) {
struct sched_entity *pse = &prev->se;
while (!(cfs_rq = is_same_group(se, pse))) {
int se_depth = se->depth;
int pse_depth = pse->depth;
if (se_depth <= pse_depth) {
put_prev_entity(cfs_rq_of(pse), pse);
pse = parent_entity(pse);
}
if (se_depth >= pse_depth) {
set_next_entity(cfs_rq_of(se), se);
se = parent_entity(se);
}
}
put_prev_entity(cfs_rq, pse);
set_next_entity(cfs_rq, se);
}
if (hrtick_enabled(rq))
hrtick_start_fair(rq, p);
rq->misfit_task = !task_fits_max(p, rq->cpu);
return p;
simple:
cfs_rq = &rq->cfs;
#endif
if (!cfs_rq->nr_running)
goto idle;
put_prev_task(rq, prev);
do {
se = pick_next_entity(cfs_rq, NULL);
set_next_entity(cfs_rq, se);
cfs_rq = group_cfs_rq(se);
} while (cfs_rq);
p = task_of(se);
if (hrtick_enabled(rq))
hrtick_start_fair(rq, p);
rq->misfit_task = !task_fits_max(p, rq->cpu);
return p;
idle:
rq->misfit_task = 0;
/*
* This is OK, because current is on_cpu, which avoids it being picked
* for load-balance and preemption/IRQs are still disabled avoiding
* further scheduler activity on it and we're being very careful to
* re-start the picking loop.
*/
lockdep_unpin_lock(&rq->lock);
#ifdef CONFIG_64BIT_ONLY_CPU
if (cpumask_test_cpu(rq->cpu, &compat_32bit_cpu_mask) ||
!sysctl_sched_packing_enabled)
new_tasks = idle_balance(rq);
else {
int cpu, over = 0;
for_each_cpu(cpu, &compat_32bit_cpu_mask) {
/* only idle balance if a CA53 is loaded over threshold */
if (cpu_rq(cpu)->cfs.avg.load_avg >
sysctl_sched_packing_threshold)
over = 1;
}
if (over)
new_tasks = idle_balance(rq);
else
new_tasks = 0;
}
#else
new_tasks = idle_balance(rq);
#endif
lockdep_pin_lock(&rq->lock);
/*
* Because idle_balance() releases (and re-acquires) rq->lock, it is
* possible for any higher priority task to appear. In that case we
* must re-start the pick_next_entity() loop.
*/
if (new_tasks < 0)
return RETRY_TASK;
if (new_tasks > 0)
goto again;
return NULL;
}
对上面代码的分析,先解析若干个核心函数:
- update_curr
- check_cfs_rq_runtime
- pick_next_entity
- group_cfs_rq
- is_same_group
- put_prev_entity
- set_next_entity
- parent_entity
- task_fits_max
- put_prev_task
- idle_balance
下面简单分析之.
2.3.1 函数update_curr解析
函数代码如下:
/*
* Update the current task's runtime statistics.
*/
static void update_curr(struct cfs_rq *cfs_rq)
{ /*获取当前cfs_rq队列的调度实体*/
struct sched_entity *curr = cfs_rq->curr;
u64 now = rq_clock_task(rq_of(cfs_rq));/*当前cfs_rq的时间*/
u64 delta_exec;
if (unlikely(!curr))
return;
/*当前调度实体已经分配的运行时间*/
delta_exec = now - curr->exec_start;
if (unlikely((s64)delta_exec <= 0))
return;
curr->exec_start = now;
schedstat_set(curr->statistics.exec_max,
max(delta_exec, curr->statistics.exec_max));
/*更新当前调度实体的总的运行时间*/
curr->sum_exec_runtime += delta_exec;
schedstat_add(cfs_rq, exec_clock, delta_exec);
/*根据分配的运行时间和调度实体的权重,增加当前调度实体的虚拟运行时间*/
curr->vruntime += calc_delta_fair(delta_exec, curr);
/*更新cfs_rq最小虚拟运行时间(这个是作为所以虚拟运行时间的base value).同时调整由各个
调度实体的虚拟运行时间组成的红黑树(根据当前调度实体的虚拟运行时间调整当前调度实体在红
黑树的节点位置)*/
update_min_vruntime(cfs_rq);
if (entity_is_task(curr)) {
struct task_struct *curtask = task_of(curr);
trace_sched_stat_runtime(curtask, delta_exec, curr->vruntime);
/*将此进程的运行时间添加到它的会话组内(即进程组中.)*/
cpuacct_charge(curtask, delta_exec);
/*维护线程组执行 运行时间,其实就是维护thread_group_cputimer这个结构体里面的
成员变量(thread group interval timer counts)*/
account_group_exec_runtime(curtask, delta_exec);
}
/*此函数涉及到throttle相关的feature,如果被throttle或者运行时间运行完毕,会重新分配
一部分运行时间给当前进程,如果分配失败,则设置重新调度的条件,或者抢占调度*/
account_cfs_rq_runtime(cfs_rq, delta_exec);
}
这个函数的最重要目的如下:
- 更新当前调度实体的虚拟运行时间
- 更新当前cfs_rq的最小虚拟运行时间
- 统计调度相关信息和数据
- 根据分配的运行时间来确定是否需要抢占调度
我们来看看account_cfs_rq_runtime函数的来龙去脉:
static __always_inline
void account_cfs_rq_runtime(struct cfs_rq *cfs_rq, u64 delta_exec)
{
if (!cfs_bandwidth_used() || !cfs_rq->runtime_enabled)
return;
__account_cfs_rq_runtime(cfs_rq, delta_exec);
}
static void __account_cfs_rq_runtime(struct cfs_rq *cfs_rq, u64 delta_exec)
{
/* dock delta_exec before expiring quota (as it could span periods) */
/*runtime_remaining是一个配额,这次分配了delta_exec运行时间,则配额自然会减少*/
cfs_rq->runtime_remaining -= delta_exec;
expire_cfs_rq_runtime(cfs_rq);
/*还有运行时间配额,则不需要重新分别运行时间和重新调度*/
if (likely(cfs_rq->runtime_remaining > 0))
return;
/*
* if we're unable to extend our runtime we resched so that the active
* hierarchy can be throttled
*/
if (!assign_cfs_rq_runtime(cfs_rq) && likely(cfs_rq->curr))
resched_curr(rq_of(cfs_rq));
}
/* returns 0 on failure to allocate runtime */
static int assign_cfs_rq_runtime(struct cfs_rq *cfs_rq)
{
struct task_group *tg = cfs_rq->tg;
struct cfs_bandwidth *cfs_b = tg_cfs_bandwidth(tg);
u64 amount = 0, min_amount, expires;
/*min_amount = 5ms - runtime_remaining(runtime_remaining <= 0)*/
/* note: this is a positive sum as runtime_remaining <= 0 */
min_amount = sched_cfs_bandwidth_slice() - cfs_rq->runtime_remaining;
raw_spin_lock(&cfs_b->lock);
if (cfs_b->quota == RUNTIME_INF)
amount = min_amount;
else {
/*重新激活throttle/unthrottle的定时器*/
start_cfs_bandwidth(cfs_b);
/*runtime是可以运行的运行时间限额,是cfs_rq在启动时候申请的.*/
if (cfs_b->runtime > 0) {
amount = min(cfs_b->runtime, min_amount);
/*增加了amount运行时间,则限额需要减去新分配的运行时间*/
cfs_b->runtime -= amount;
cfs_b->idle = 0;
}
}
expires = cfs_b->runtime_expires;
raw_spin_unlock(&cfs_b->lock);
/*增加运行时间配额,也即是增加了进程的运行时间*/
cfs_rq->runtime_remaining += amount;
/*
* we may have advanced our local expiration to account for allowed
* spread between our sched_clock and the one on which runtime was
* issued.
*/
if ((s64)(expires - cfs_rq->runtime_expires) > 0)
cfs_rq->runtime_expires = expires;
return cfs_rq->runtime_remaining > 0;
}
至此update_curr是更新当前调度实体的虚拟运行时间,调整其红黑树节点位置,同时处理其运行时间使用完毕之后的逻辑流程.
2.3.2 函数check_cfs_rq_runtime解析
其source code如下:
/* conditionally throttle active cfs_rq's from put_prev_entity() */
static bool check_cfs_rq_runtime(struct cfs_rq *cfs_rq)
{
if (!cfs_bandwidth_used())
return false;
if (likely(!cfs_rq->runtime_enabled || cfs_rq->runtime_remaining > 0))
return false;
/*
* it's possible for a throttled entity to be forced into a running
* state (e.g. set_curr_task), in this case we're finished.
*/
if (cfs_rq_throttled(cfs_rq))
return true;
/*对cfs_rq做throttle操作*/
throttle_cfs_rq(cfs_rq);
return true;
}
这个函数的功能是检测当前是否做throttle操作.如果throttle操作,则直接将prev进程重新入队,重新选择新的调度实体.后面的函数会讲解到put_prev_entity函数的原理
2.3.3 函数pick_next_entity解析
source code代码如下:
/*
* Pick the next process, keeping these things in mind, in this order:
* 1) keep things fair between processes/task groups
* 2) pick the "next" process, since someone really wants that to run
* 3) pick the "last" process, for cache locality
* 4) do not run the "skip" process, if something else is available
*/
static struct sched_entity *
pick_next_entity(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{ /*挑选红黑树最左边的叶子节点,即虚拟运行时间最小的节点,也是优先被调度的节点*/
struct sched_entity *left = __pick_first_entity(cfs_rq);
struct sched_entity *se;
/*
* If curr is set we have to see if its left of the leftmost entity
* still in the tree, provided there was anything in the tree at all.
*//*根据当前调度实体的虚拟运行时间来修改left调度实体的指向*/
if (!left || (curr && entity_before(curr, left)))
left = curr;
/*理想情况下,我们需要调度最小虚拟运行时间的调度实体*/
se = left; /* ideally we run the leftmost entity */
/*
* Avoid running the skip buddy, if running something else can
* be done without getting too unfair.
*/ /*skip buddy是不应该被选择的调度实体,但是最小的虚拟运行时间的调度实体与
skip_buddy是同一个,则需要重现选择候选者.*/
if (cfs_rq->skip == se) {
struct sched_entity *second;
if (se == curr) {
/*rb tree的最左边的节点,与当前调度实体是同一个调度实体,则直接选择当前调度
实体的下一个节点作为候选调度实体*/
second = __pick_first_entity(cfs_rq);
} else {
/*否则选最小虚拟运行时间的调度实体的下一个节点作为候选的调度实体*/
second = __pick_next_entity(se);
/*根据系统状态变化修正候选者,比如选择的候选者为空或者候选者的虚拟运行时间
大于当前调度实体*/
if (!second || (curr && entity_before(curr, second)))
second = curr;
}
/*统一决策:目的只有一个,在选择next调度实体的时候,不要选择之后导致抢占的发生,否则
浪费系统资源还影响系统性能.具体在后面分析wakeup_preempt_entity函数*/
if (second && wakeup_preempt_entity(second, left) < 1)
se = second;
}
/*
* Prefer last buddy, try to return the CPU to a preempted task.
*//*如果cfs_rq的last成员不为空,并且last调度实体的虚拟运行时间等因素比left更需要被
调度,则重新设置选择的调度实体为last*/
if (cfs_rq->last && wakeup_preempt_entity(cfs_rq->last, left) < 1)
se = cfs_rq->last;
/*
* Someone really wants this to run. If it's not unfair, run it.
*/ /*再次检测对应的调度环境,正如这条语句所说的,某些进程想要本次运行,并且也符合抢占
的条件,那么修改选择的调度实体*/
if (cfs_rq->next && wakeup_preempt_entity(cfs_rq->next, left) < 1)
se = cfs_rq->next;
/*对cfs_rq队列的三个成员变量,last,skip,next分别进行清空操作.即只要任一个等于
se,则将其设置为NULL*/
clear_buddies(cfs_rq, se);
return se;
}
static inline int entity_before(struct sched_entity *a,
struct sched_entity *b)
{
return (s64)(a->vruntime - b->vruntime) < 0;
}
struct sched_entity *__pick_first_entity(struct cfs_rq *cfs_rq)
{
struct rb_node *left = cfs_rq->rb_leftmost;
if (!left)
return NULL;
return rb_entry(left, struct sched_entity, run_node);
}
static struct sched_entity *__pick_next_entity(struct sched_entity *se)
{
struct rb_node *next = rb_next(&se->run_node);
if (!next)
return NULL;
return rb_entry(next, struct sched_entity, run_node);
}
/*
* Should 'se' preempt 'curr'.
*
* |s1
* |s2
* |s3
* g
* |<--->|c
*
* w(c, s1) = -1
* w(c, s2) = 0
* w(c, s3) = 1
*
*/
static int
wakeup_preempt_entity(struct sched_entity *curr, struct sched_entity *se)
{
s64 gran, vdiff = curr->vruntime - se->vruntime;
/*如果vdiff<=0,表示curr应该优先调度*/
if (vdiff <= 0)
return -1;
/*惩罚优先级低的进程,即增加优先级低的虚拟运行时间.如果vdiff差值大于惩罚值,则se可
以抢占curr调度实体,也即是说,在pick next entity的时候会选择se而不会选择curr调度
实体*/
gran = wakeup_gran(curr, se);
if (vdiff > gran)
return 1;
return 0;
}
/*保证调度实体se的最少运行时间为sysctl_sched_wakeup_granularity,转化为se虚拟运行
时间增益*/
static unsigned long
wakeup_gran(struct sched_entity *curr, struct sched_entity *se)
{ /*最小运行时间颗粒度,是必须保证的,否则进程运行时间过短没有多大意义*/
unsigned long gran = sysctl_sched_wakeup_granularity;
/*
* Since its curr running now, convert the gran from real-time
* to virtual-time in his units.
*
* By using 'se' instead of 'curr' we penalize light tasks, so
* they get preempted easier. That is, if 'se' < 'curr' then
* the resulting gran will be larger, therefore penalizing the
* lighter, if otoh 'se' > 'curr' then the resulting gran will
* be smaller, again penalizing the lighter task.
*
* This is especially important for buddies when the leftmost
* task is higher priority than the buddy.
*/
return calc_delta_fair(gran, se);
}
static void __clear_buddies_last(struct sched_entity *se)
{
for_each_sched_entity(se) {
struct cfs_rq *cfs_rq = cfs_rq_of(se);
if (cfs_rq->last != se)
break;
cfs_rq->last = NULL;
}
}
static void __clear_buddies_next(struct sched_entity *se)
{
for_each_sched_entity(se) {
struct cfs_rq *cfs_rq = cfs_rq_of(se);
if (cfs_rq->next != se)
break;
cfs_rq->next = NULL;
}
}
static void __clear_buddies_skip(struct sched_entity *se)
{
for_each_sched_entity(se) {
struct cfs_rq *cfs_rq = cfs_rq_of(se);
if (cfs_rq->skip != se)
break;
cfs_rq->skip = NULL;
}
}
static void clear_buddies(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
if (cfs_rq->last == se)
__clear_buddies_last(se);
if (cfs_rq->next == se)
__clear_buddies_next(se);
if (cfs_rq->skip == se)
__clear_buddies_skip(se);
}
从上面的代码可以清晰的知道,pick_next_entity目的是从rb tree中选择最左边的节点作为next entity. 重点是需要考虑与当前调度实体,cfs_rq队列中last/next/skip调度实体参数的关系,最后确定next entity.最重要的目的就是选择next entity之后,尽可能的减少被抢占的可能性.
2.3.4 函数group_cfs_rq解析
源码如下:
/* runqueue "owned" by this group */
static inline struct cfs_rq *group_cfs_rq(struct sched_entity *grp)
{
return grp->my_q;
}
表示调度实体grp是一个进程组内的一个进程,进程组有自己的cfs_rq运行队列.进程组内的调度实体都放到my_q运行队列,而不会放到其他cfs_rq队列
2.3.5 函数is_same_group解析
/* Do the two (enqueued) entities belong to the same group ? */
static inline struct cfs_rq *
is_same_group(struct sched_entity *se, struct sched_entity *pse)
{
if (se->cfs_rq == pse->cfs_rq)
return se->cfs_rq;
return NULL;
}
比较两个调度实体是否在同一个cfs_rq上,即同一个运行队列中.
2.3.6 函数put_prev_entity解析
static void put_prev_entity(struct cfs_rq *cfs_rq, struct sched_entity *prev)
{
/*
* If still on the runqueue then deactivate_task()
* was not called and update_curr() has to be done:
*//*如果prev调度实体还在运行队列里面,直接update此调度实体的vruntime和此cfs_rq的
min_vruntime*/
if (prev->on_rq)
update_curr(cfs_rq);
/* throttle cfs_rqs exceeding runtime */
check_cfs_rq_runtime(cfs_rq);
check_spread(cfs_rq, prev);
if (prev->on_rq) {
update_stats_wait_start(cfs_rq, prev);
/* Put 'current' back into the tree. */
/*将prev根据vruntime数值插入到rb tree中*/
__enqueue_entity(cfs_rq, prev);
/* in !on_rq case, update occurred at dequeue */
/*根据PELT算法,更新调度实体和队列本身的负载*/
update_load_avg(prev, 0);
}
cfs_rq->curr = NULL;
}
2.3.7 函数set_next_entity解析
static void
set_next_entity(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
/* 'current' is not kept within the tree. */
if (se->on_rq) {
/*
* Any task has to be enqueued before it get to execute on
* a CPU. So account for the time it spent waiting on the
* runqueue.
*/
update_stats_wait_end(cfs_rq, se);
/*将调度实体se从rb tree中删除,即选择此调度实体开始运行*/
__dequeue_entity(cfs_rq, se);
/*更新进程组的load*/
update_load_avg(se, UPDATE_TG);
}
update_stats_curr_start(cfs_rq, se);
/*设置当前运行的调度实体为se*/
cfs_rq->curr = se;
#ifdef CONFIG_SCHEDSTATS
/*
* Track our maximum slice length, if the CPU's load is at
* least twice that of our own weight (i.e. dont track it
* when there are only lesser-weight tasks around):
*/
if (rq_of(cfs_rq)->load.weight >= 2*se->load.weight) {
se->statistics.slice_max = max(se->statistics.slice_max,
se->sum_exec_runtime - se->prev_sum_exec_runtime);
}
#endif
se->prev_sum_exec_runtime = se->sum_exec_runtime;
}
2.3.8 函数parent_entity解析
static inline struct sched_entity *parent_entity(struct sched_entity *se)
{
return se->parent;
}
返回调度实体se的父节点
2.3.9 函数task_fits_max解析
static inline bool __task_fits(struct task_struct *p, int cpu, int util)
{
unsigned long capacity = capacity_of(cpu);
util += boosted_task_util(p);
return (capacity * 1024) > (util * capacity_margin);
}
static inline bool task_fits_max(struct task_struct *p, int cpu)
{
unsigned long capacity_orig = capacity_orig_of(cpu);
unsigned long max_capacity = cpu_rq(cpu)->rd->max_cpu_capacity.val;
if (capacity_orig == max_capacity)
return true;
return __task_fits(p, cpu, 0);
}
判断进程p是否为Misfit task,即根据进程p的util是否超过了capacity的90%.
2.3.10 函数put_prev_task解析
代码如下:
static inline void put_prev_task(struct rq *rq, struct task_struct *prev)
{
prev->sched_class->put_prev_task(rq, prev);
}
/*
* Account for a descheduled task:
*/
static void put_prev_task_fair(struct rq *rq, struct task_struct *prev)
{
struct sched_entity *se = &prev->se;
struct cfs_rq *cfs_rq;
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se);
put_prev_entity(cfs_rq, se);
}
}
目的是将进程prev取消调度
2.3.11 函数idle_balance解析
代码如下:
/*
* idle_balance is called by schedule() if this_cpu is about to become
* idle. Attempts to pull tasks from other CPUs.
*/
static int idle_balance(struct rq *this_rq)
{
unsigned long next_balance = jiffies + HZ;
int this_cpu = this_rq->cpu;
struct sched_domain *sd;
int pulled_task = 0;
u64 curr_cost = 0;
idle_enter_fair(this_rq);
/*
* We must set idle_stamp _before_ calling idle_balance(), such that we
* measure the duration of idle_balance() as idle time.
*/
this_rq->idle_stamp = rq_clock(this_rq);
if (!energy_aware() &&
(this_rq->avg_idle < sysctl_sched_migration_cost ||
!this_rq->rd->overload)) {
rcu_read_lock();
sd = rcu_dereference_check_sched_domain(this_rq->sd);
if (sd)
update_next_balance(sd, 0, &next_balance);
rcu_read_unlock();
goto out;
}
raw_spin_unlock(&this_rq->lock);
update_blocked_averages(this_cpu);
rcu_read_lock();
#ifdef CONFIG_INTEL_DWS
if (sched_feat(INTEL_DWS)) {
sd = rcu_dereference(per_cpu(sd_dws, this_cpu));
if (sd) {
struct cpumask *consolidated_cpus =
this_cpu_cpumask_var_ptr(load_balance_mask);
cpumask_copy(consolidated_cpus, cpu_active_mask);
/*
* If we encounter masked CPU here, don't do balance on it
*/
dws_consolidated_cpus(sd, consolidated_cpus);
if (!cpumask_test_cpu(this_cpu, consolidated_cpus))
goto unlock;
dws_unload_cpu(consolidated_cpus, sd);
}
}
#endif
for_each_domain(this_cpu, sd) {
int continue_balancing = 1;
u64 t0, domain_cost;
if (!(sd->flags & SD_LOAD_BALANCE)) {
if (time_after_eq(jiffies, sd->groups->sgc->next_update))
update_group_capacity(sd, this_cpu);
continue;
}
if (this_rq->avg_idle < curr_cost + sd->max_newidle_lb_cost) {
update_next_balance(sd, 0, &next_balance);
break;
}
if (sd->flags & SD_BALANCE_NEWIDLE) {
t0 = sched_clock_cpu(this_cpu);
pulled_task = load_balance(this_cpu, this_rq,
sd, CPU_NEWLY_IDLE,
&continue_balancing);
domain_cost = sched_clock_cpu(this_cpu) - t0;
if (domain_cost > sd->max_newidle_lb_cost)
sd->max_newidle_lb_cost = domain_cost;
curr_cost += domain_cost;
}
update_next_balance(sd, 0, &next_balance);
/*
* Stop searching for tasks to pull if there are
* now runnable tasks on this rq.
*/
if (pulled_task || this_rq->nr_running > 0)
break;
}
#ifdef CONFIG_INTEL_DWS
unlock:
#endif
rcu_read_unlock();
raw_spin_lock(&this_rq->lock);
if (curr_cost > this_rq->max_idle_balance_cost)
this_rq->max_idle_balance_cost = curr_cost;
/*
* While browsing the domains, we released the rq lock, a task could
* have been enqueued in the meantime. Since we're not going idle,
* pretend we pulled a task.
*/
if (this_rq->cfs.h_nr_running && !pulled_task)
pulled_task = 1;
out:
/* Move the next balance forward */
if (time_after(this_rq->next_balance, next_balance))
this_rq->next_balance = next_balance;
/* Is there a task of a high priority class? */
if (this_rq->nr_running != this_rq->cfs.h_nr_running)
pulled_task = -1;
if (pulled_task) {
idle_exit_fair(this_rq);
this_rq->idle_stamp = 0;
}
return pulled_task;
}
牵涉到负载均衡,后面单独列出一章来讲解.
2.4 prev与next进程上下文切换
需要分析的源码如下:
static void __sched notrace __schedule(bool preempt)
{
..................................
/*如果prev进程与pick的next进程不是同一个进程*/
if (likely(prev != next)) {
#ifdef CONFIG_SCHED_WALT
if (!prev->on_rq)
/*设置prev进程退出rq的时间戳*/
prev->last_sleep_ts = wallclock;
#endif /*rq里面进程被切换的次数*/
rq->nr_switches++;
/*设置rq的当前进程为选择的next进程*/
rq->curr = next;
/*增加进程上下文切换的次数*/
++*switch_count;
trace_sched_switch(preempt, prev, next);
/*prev和next进程上下文切换*/
rq = context_switch(rq, prev, next); /* unlocks the rq */
cpu = cpu_of(rq);
} else {
/*prev与next是同一个进程,则不需要做上下文切换,直接unlock即可*/
lockdep_unpin_lock(&rq->lock);
raw_spin_unlock_irq(&rq->lock);
}
..................................
}
核心函数context_switch源码如下:
/*
* context_switch - switch to the new MM and the new thread's register state.
*/
static inline struct rq *
context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next)
{
struct mm_struct *mm, *oldmm;
prepare_task_switch(rq, prev, next);
/*获取next进程的地址空间描述符*/
mm = next->mm;
/*获取prev进程正在使用的地址空间描述符*/
oldmm = prev->active_mm;
/*
* For paravirt, this is coupled with an exit in switch_to to
* combine the page table reload and the switch backend into
* one hypercall.
*/
arch_start_context_switch(prev);
/*如果next进程的地址空间描述符为空,则表示next是内核线程,那么next进程的地址空间描述符
使用prev进程的描述符.由于是kernespace,所以使用lazy tlb,不需要flush tlb操作.这里
next进程借用了prev进程的地址空间描述符,所以不需要switch_mm操作.*/
if (!mm) {
next->active_mm = oldmm;
atomic_inc(&oldmm->mm_count);
enter_lazy_tlb(oldmm, next);
} else/*这里next有自己的地址空间描述符,那么就必须使用switch_mm与prev进程切换
地址空间描述符了.*/
switch_mm(oldmm, mm, next);
/*prev是内核线程,则将prev进程的使用的地址空间描述符置为空,并且保存当前rq上次使用的
地址描述符为prev进程的.由于prev是内核线程,在切换之后其地址空间没有用处了(即不会被借用
了)*/
if (!prev->mm) {
prev->active_mm = NULL;
rq->prev_mm = oldmm;
}
/*
* Since the runqueue lock will be released by the next
* task (which is an invalid locking op but in the case
* of the scheduler it's an obvious special-case), so we
* do an early lockdep release here:
*/
lockdep_unpin_lock(&rq->lock);
spin_release(&rq->lock.dep_map, 1, _THIS_IP_);
/* Here we just switch the register state and the stack. */
switch_to(prev, next, prev);
barrier();
return finish_task_switch(prev);
}
分析上面的函数之前,我们需要了解下进程结构体(struct task_struct)中两个成员变量:
struct mm_struct *mm, *active_mm;
解释如下:
mm指向进程所拥有的内存描述符,而active_mm指向进程运行时所使用的内存描述符。对于普通进程而言,这两个指针变量的值相同。但是,内核线程不拥有任何内存描述符,所以它们的mm成员总是为NULL。当内核线程得以运行时,它的active_mm成员被初始化为前一个运行进程的 active_mm值。涉及到内存管理,目前知识优先,以后在详细分析
这样就好解释进程上下文切换的逻辑了.分别分析如下:
2.4.1 prepare_task_switch分析
其源码如下:
/**
* prepare_task_switch - prepare to switch tasks
* @rq: the runqueue preparing to switch
* @prev: the current task that is being switched out
* @next: the task we are going to switch to.
*
* This is called with the rq lock held and interrupts off. It must
* be paired with a subsequent finish_task_switch after the context
* switch.
*
* prepare_task_switch sets up locking and calls architecture specific
* hooks.
*/
static inline void
prepare_task_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next)
{ /*调度信息切换,即将prev进行清除其调度信息,next进程添加其调度信息,主要
是确定next进程还需要等待多久才能被正在的调度到*/
sched_info_switch(rq, prev, next);
/*perf event切换*/
perf_event_task_sched_out(prev, next);
/*触发抢占调度notification*/
fire_sched_out_preempt_notifiers(prev, next);
/*设定next在rq所在的cpu上*/
prepare_lock_switch(rq, next);
/*arm架构此函数为空*/
prepare_arch_switch(next);
}
2.4.2 enter_lazy_tlb分析
如果mm为NULL,则表示切换的进程是内核线程:
atomic_inc(&oldmm->mm_count);//是对“struct mm_struct”的引用数量(用户数为1)
在arm架构中,enter_lazy_tlb函数没有实现.
2.4.3 switch_mm分析
对于ARM64这个cpu arch,每一个cpu core都有两个寄存器来指示当前运行在该CPU core上的进程(线程)实体的地址空间。这两个寄存器分别是ttbr0_el1(用户地址空间)和ttbr1_el1(内核地址空间)。由于所有的进程共享内核地址空间,因此所谓地址空间切换也就是切换ttbr0_el1而已。地址空间听起来很抽象,实际上就是内存中的若干Translation table而已,每一个进程都有自己独立的一组用于翻译用户空间虚拟地址的Translation table,这些信息保存在内存描述符中,具体位于struct mm_struct中的pgd成员中。以pgd为起点,可以遍历该内存描述符的所有用户地址空间的Translation table。源码如下:
static inline void
switch_mm(struct mm_struct *prev, struct mm_struct *next,
struct task_struct *tsk)
{
if (prev != next)
__switch_mm(next);
/*
* Update the saved TTBR0_EL1 of the scheduled-in task as the previous
* value may have not been initialised yet (activate_mm caller) or the
* ASID has changed since the last run (following the context switch
* of another thread of the same process). Avoid setting the reserved
* TTBR0_EL1 to swapper_pg_dir (init_mm; e.g. via idle_task_exit).
*/
if (next != &init_mm)
update_saved_ttbr0(tsk, next);
}
static inline void __switch_mm(struct mm_struct *next)
{
unsigned int cpu = smp_processor_id();
/*
* init_mm.pgd does not contain any user mappings and it is always
* active for kernel addresses in TTBR1. Just set the reserved TTBR0.
*/
if (next == &init_mm) {
cpu_set_reserved_ttbr0();
return;
}
check_and_switch_context(next, cpu);
}
struct mm_struct init_mm = {
.mm_rb = RB_ROOT,
.pgd = swapper_pg_dir,
.mm_users = ATOMIC_INIT(2),
.mm_count = ATOMIC_INIT(1),
.mmap_sem = __RWSEM_INITIALIZER(init_mm.mmap_sem),
.page_table_lock = __SPIN_LOCK_UNLOCKED(init_mm.page_table_lock),
.mmlist = LIST_HEAD_INIT(init_mm.mmlist),
.user_ns = &init_user_ns,
INIT_MM_CONTEXT(init_mm)
};
具体的解释如下:
(1)prev是要切出的地址空间,next是要切入的地址空间,tsk是将要切入的进程。
(2)要切出的地址空间和要切入的地址空间是一个地址空间的话,那么切换地址空间也就没有什么意义了。
(3)在ARM64中,地址空间的切换主要是切换ttbr0_el1,对于swapper进程的地址空间,其用户空间没有任何的mapping,而如果要切入的地址空间就是swapper进程的地址空间的时候,将(设定ttbr0_el1指向empty_zero_page)。
(4)check_and_switch_context中有很多TLB、ASID相关的操作,我们将会在另外的文档中给出细致描述,这里就简单略过,实际上,最终该函数会调用arch/arm64/mm/proc.S文件中的cpu_do_switch_mm将要切入进程的L0 Translation table物理地址(保存在内存描述符的pgd成员)写入ttbr0_el1。
2.4.4 switch_to分析
很奇怪,switch_to函数为何会使用三个参数呢?
switch_to定义如下:
#define switch_to(prev, next, last) \
do { \
((last) = __switch_to((prev), (next))); \
} while (0)
一个switch_to将代码分成两段:
AAA
switch_to(prev, next, prev);
BBB
一次进程切换,涉及到了三个进程,prev和next是大家都熟悉的参数了,对于进程A(下图中的右半图片),如果它想要切换到B进程,那么:
prev=A
next=B
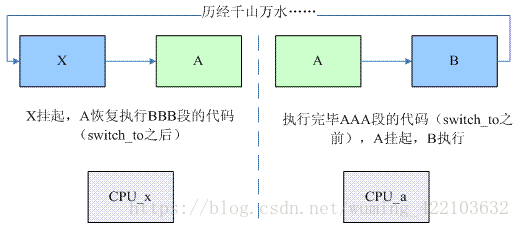
这时候,在A进程中调用 switch_to 完成A到B进程的切换。但是,当经历万水千山,A进程又被重新调度的时候,我们又来到了switch_to返回的这一点(下图中的左半图片),这时候,我们是从哪一个进程切换到A呢?谁知道呢(在A进程调用switch_to 的时候是不知道的)?在A进程调用switch_to之后,cpu就执行B进程了,后续B进程切到哪个进程呢?随后又经历了怎样的进程切换过程呢?当然,这一切对于A进程来说它并不关心,它唯一关心的是当切换回A进程的时候,该cpu上(也不一定是A调用switch_to切换到B进程的那个CPU)执行的上一个task是谁?这就是第三个参数的含义(实际上这个参数的名字就是last,也基本说明了其含义)。也就是说,在AAA点上,prev是A进程,对应的run queue是CPUa的run queue,而在BBB点上,A进程恢复执行,last是X进程,对应的run queue是CPUx的run queue。
由于存在MMU,内存中可以有多个task,并且由调度器依次调度到cpu core上实际执行。系统有多少个cpu core就可以有多少个进程(线程)同时执行。即便是对于一个特定的cpu core,调度器可以可以不断的将控制权从一个task切换到另外一个task上。实际的context switch的动作也不复杂:就是将当前的上下文保存在内存中,然后从内存中恢复另外一个task的上下文。对于ARM64而言,context包括:
(1)通用寄存器
(2)浮点寄存器
(3)地址空间寄存器(ttbr0_el1和ttbr1_el1),上一节已经描述
(4)其他寄存器(ASID、thread process ID register等)
__switch_to代码(位于arch/arm64/kernel/process.c)如下:
/*
* Thread switching.
*/
struct task_struct *__switch_to(struct task_struct *prev,
struct task_struct *next)
{
struct task_struct *last;
fpsimd_thread_switch(next);--------------(1)
tls_thread_switch(next); --------------(2)
/*跟硬件跟踪相关*/
hw_breakpoint_thread_switch(next);
contextidr_thread_switch(next);
sprd_update_cpu_usage(prev, next);
#ifdef CONFIG_THREAD_INFO_IN_TASK
entry_task_switch(next);
#endif
/**/
uao_thread_switch(next);
/*
* Complete any pending TLB or cache maintenance on this CPU in case
* the thread migrates to a different CPU.
*/
dsb(ish);
/* the actual thread switch */
last = cpu_switch_to(prev, next);--------------(3)
return last;
}
(1)fp是float-point的意思,和浮点运算相关。simd是Single Instruction Multiple Data的意思,和多媒体以及信号处理相关。fpsimd_thread_switch其实就是把当前FPSIMD的状态保存到了内存中(task.thread.fpsimd_state),从要切入的next进程描述符中获取FPSIMD状态,并加载到CPU上。
(2)概念同上,不过是处理tls(thread local storage)的切换。这里硬件寄存器涉及tpidr_el0和tpidrro_el0,涉及的内存是task.thread.tp_value。具体的应用场景是和线程库相关,具体大家可以自行学习了。
(3)具体的切换发生在arch/arm64/kernel/entry.S文件中的cpu_switch_to,代码如下:
/*
* Register switch for AArch64. The callee-saved registers need to be saved
* and restored. On entry:
* x0 = previous task_struct (must be preserved across the switch)
* x1 = next task_struct
* Previous and next are guaranteed not to be the same.
*
*/
ENTRY(cpu_switch_to) -------------------(1)
mov x10, #THREAD_CPU_CONTEXT ----------(2)
add x8, x0, x10 --------------------(3)
mov x9, sp
stp x19, x20, [x8], #16 ----------------(4)
stp x21, x22, [x8], #16
stp x23, x24, [x8], #16
stp x25, x26, [x8], #16
stp x27, x28, [x8], #16
stp x29, x9, [x8], #16
str lr, [x8] ---------A
add x8, x1, x10 -------------------(5)
ldp x19, x20, [x8], #16 ----------------(6)
ldp x21, x22, [x8], #16
ldp x23, x24, [x8], #16
ldp x25, x26, [x8], #16
ldp x27, x28, [x8], #16
ldp x29, x9, [x8], #16
ldr lr, [x8] -------B
mov sp, x9 -------C
#ifdef CONFIG_THREAD_INFO_IN_TASK
msr sp_el0, x1
#else
and x9, x9, #~(THREAD_SIZE - 1)
msr sp_el0, x9
#endif
ret -------------------------(7)
ENDPROC(cpu_switch_to)
(1)进入cpu_switch_to函数之前,x0,x1用做参数传递,x0是prev task,就是那个要挂起的task,x1是next task,就是马上要切入的task。cpu_switch_to和其他的普通函数没有什么不同,尽管会走遍万水千山,但是最终还是会返回调用者函数__switch_to。
在进入细节之前,先想一想这个问题:cpu_switch_to要如何保存现场?要保存那些通用寄存器呢?其实上一小段描述已经做了铺陈:尽管有点怪异,本质上cpu_switch_to仍然是一个普通函数,需要符合ARM64标准过程调用文档。在该文档中规定,x19~x28是属于callee-saved registers,也就是说,在__switch_to函数调用cpu_switch_to函数这个过程中,cpu_switch_to函数要保证x19~x28这些寄存器值是和调用cpu_switch_to函数之前一模一样的。除此之外,pc、sp、fp当然也是必须是属于现场的一部分的。
(2)得到THREAD_CPU_CONTEXT的偏移,保存在x10中
(3)x0是pre task的进程描述符,加上偏移之后就获取了访问cpu context内存的指针(x8寄存器)。所有context的切换的原理都是一样的,就是把当前cpu寄存器保存在内存中,这里的内存是在进程描述符中的 thread.cpu_context中。
(4)一旦定位到保存cpu context(各种通用寄存器)的内存,那么使用stp保存硬件现场。这里x29就是fp(frame pointer),x9保存了stack pointer,lr是返回的PC值。到A代码处,完成了pre task cpu context的保存动作。
(5)和步骤(3)类似,只不过是针对next task而言的。这时候x8指向了next task的cpu context。
(6)和步骤(4)类似,不同的是这里的操作是恢复next task的cpu context。执行到代码B处,所有的寄存器都已经恢复,除了PC和SP,其中PC保存在了lr(x30)中,而sp保存在了x9中。在代码C出恢复了sp值,这时候万事俱备,只等PC操作了。
(7)ret指令其实就是把x30(lr)寄存器的值加载到PC,至此现场完全恢复到调用cpu_switch_to那一点上了。
2.4.5 finish_task_switch分析
涉及到mm的处理,我们整体理清楚这部分代码:
我们上面已经说过:如果切入内核线程,那么其实进程地址空间实际上并没有切换,该内核线程只是借用了切出进程使用的那个地址空间(active_mm)。对于内核中的实体,我们都会使用引用计数来根据一个数据对象,从而确保在没有任何引用的情况下释放该数据对象实体,对于内存描述符亦然。因此,在context_switch中有代码如下:
if (!mm) {
next->active_mm = oldmm;
atomic_inc(&oldmm->mm_count);-----增加引用计数
enter_lazy_tlb(oldmm, next);
}
既然是借用别人的内存描述符(地址空间),那么调用atomic_inc是合理的,反正马上就切入B进程了,在A进程中提前增加引用计数也OK的。话说有借有还,那么在内核线程被切出的时候,就是归还内存描述符的时候了。
这里还有一个悖论,对于内核线程而言,在运行的时候,它会借用其他进程的地址空间,因此,在整个内核线程运行过程中,需要使用该地址空间(内存描述符),因此对内存描述符的增加和减少引用计数的操作只能在在内核线程之外完成。假如一次切换是这样的:…A—>B(内核线程)—>C…,增加引用计数比较简单,上面已经说了,在A进程调用context_switch的时候完成。现在问题来了,如何在C中完成减少引用计数的操作呢?我们还是从代码中寻找答案,如下(context_switch函数中,去掉了不相关的代码):
if (!prev->mm) {
prev->active_mm = NULL;
rq->prev_mm = oldmm;---在rq->prev_mm上保存了上一次使用的mm struct
}
借助其他进程内存描述符的东风,内核线程B欢快的运行,然而,快乐总是短暂的,也许是B自愿的,也许是强迫的,调度器最终会剥夺B的执行,切入C进程。也就是说,B内核线程调用switch_to(执行了AAA段代码),自己挂起,C粉墨登场,执行BBB段的代码。具体的代码在finish_task_switch,如下:
/**
* finish_task_switch - clean up after a task-switch
* @prev: the thread we just switched away from.
*
* finish_task_switch must be called after the context switch, paired
* with a prepare_task_switch call before the context switch.
* finish_task_switch will reconcile locking set up by prepare_task_switch,
* and do any other architecture-specific cleanup actions.
*
* Note that we may have delayed dropping an mm in context_switch(). If
* so, we finish that here outside of the runqueue lock. (Doing it
* with the lock held can cause deadlocks; see schedule() for
* details.)
*
* The context switch have flipped the stack from under us and restored the
* local variables which were saved when this task called schedule() in the
* past. prev == current is still correct but we need to recalculate this_rq
* because prev may have moved to another CPU.
*/
static struct rq *finish_task_switch(struct task_struct *prev)
__releases(rq->lock)
{
struct rq *rq = this_rq();
struct mm_struct *mm = rq->prev_mm;――――――――――――――――(1)
long prev_state;
/*
* The previous task will have left us with a preempt_count of 2
* because it left us after:
*
* schedule()
* preempt_disable(); // 1
* __schedule()
* raw_spin_lock_irq(&rq->lock) // 2
*
* Also, see FORK_PREEMPT_COUNT.
*/
if (WARN_ONCE(preempt_count() != 2*PREEMPT_DISABLE_OFFSET,
"corrupted preempt_count: %s/%d/0x%x\n",
current->comm, current->pid, preempt_count()))
preempt_count_set(FORK_PREEMPT_COUNT);
rq->prev_mm = NULL;
/*
* A task struct has one reference for the use as "current".
* If a task dies, then it sets TASK_DEAD in tsk->state and calls
* schedule one last time. The schedule call will never return, and
* the scheduled task must drop that reference.
*
* We must observe prev->state before clearing prev->on_cpu (in
* finish_lock_switch), otherwise a concurrent wakeup can get prev
* running on another CPU and we could rave with its RUNNING -> DEAD
* transition, resulting in a double drop.
*/
prev_state = prev->state;
vtime_task_switch(prev);
perf_event_task_sched_in(prev, current);
finish_lock_switch(rq, prev);
finish_arch_post_lock_switch();
fire_sched_in_preempt_notifiers(current);
if (mm)
mmdrop(mm);――――――――――――――――(2)
if (unlikely(prev_state == TASK_DEAD)) {
if (prev->sched_class->task_dead)
prev->sched_class->task_dead(prev);
/*
* Remove function-return probe instances associated with this
* task and put them back on the free list.
*/
kprobe_flush_task(prev);
put_task_struct(prev);
}
tick_nohz_task_switch();
return rq;
}
(1)我们假设B是内核线程,在进程A调用context_switch切换到B线程的时候,借用的地址空间被保存在CPU对应的run queue中。在B切换到C之后,通过rq->prev_mm就可以得到借用的内存描述符。
(2)已经完成B到C的切换后,借用的地址空间可以返还了。因此在C进程中调用mmdrop来完成这一动作。很神奇,在A进程中为内核线程B借用地址空间,但却在C进程中释放它。
进程切换这部分参考如下:http://www.wowotech.net/process_management/context-switch-arch.html
感谢.
2.5 balance_callback调用
源码如下:
/* rq->lock is NOT held, but preemption is disabled */
static void __balance_callback(struct rq *rq)
{
struct callback_head *head, *next;
void (*func)(struct rq *rq);
unsigned long flags;
raw_spin_lock_irqsave(&rq->lock, flags);
head = rq->balance_callback;
rq->balance_callback = NULL;
while (head) {
func = (void (*)(struct rq *))head->func;
next = head->next;
head->next = NULL;
head = next;
func(rq);
}
raw_spin_unlock_irqrestore(&rq->lock, flags);
}
static inline void balance_callback(struct rq *rq)
{
if (unlikely(rq->balance_callback))
__balance_callback(rq);
}
对于fail sched class并没有定义此函数,但是rt sched class定义了,如下:
static inline void
queue_balance_callback(struct rq *rq,
struct callback_head *head,
void (*func)(struct rq *rq))
{
lockdep_assert_held(&rq->lock);
if (unlikely(head->next))
return;
head->func = (void (*)(struct callback_head *))func;
head->next = rq->balance_callback;
rq->balance_callback = head;
}
static inline void queue_push_tasks(struct rq *rq)
{
if (!has_pushable_tasks(rq))
return;
queue_balance_callback(rq, &per_cpu(rt_push_head, rq->cpu), push_rt_tasks);
}
static inline void queue_pull_task(struct rq *rq)
{
queue_balance_callback(rq, &per_cpu(rt_pull_head, rq->cpu), pull_rt_task);
}
以上细节不在深入解析,留到讲解rt sched class章节详细分析.
上面有两个遗留问题:
- fair sched class的负载均衡
- rt 调度算法思想和负载均衡
本月会完结此专栏.
进程上下文切换(context_switch)参考如下:
http://www.wowotech.net/process_management/context-switch-arch.html
感谢窝窝科技提供大量的原创性文章.推荐愿意学习内核的同学们仔细阅读每一篇文章.再次致谢!!!















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









