







昨天了解了suggest包中的spell相关的内容,主要是拼写检查和相似度查询提示;
今天准备了解下关于联想词的内容,lucene的联想词是在org.apache.lucene.search.suggest包下边,提供了自动补全或者联想提示功能的支持;
InputIterator说明
InputIterator是一个支持枚举term,weight,payload三元组的供suggester使用的接口,目前仅支持AnalyzingSuggester,FuzzySuggester andAnalyzingInfixSuggester 三种suggester支持payloads;
InputIterator的实现类有以下几种:
BufferedInputIterator:对二进制类型的输入进行轮询;
DocumentInputIterator:从索引中被store的field中轮询;
FileIterator:从文件中每次读出单行的数据轮询,以\t进行间隔(且\t的个数最多为2个);
HighFrequencyIterator:从索引中被store的field轮询,忽略长度小于设定值的文本;
InputIteratorWrapper:遍历BytesRefIterator并且返回的内容不包含payload且weight均为1;
SortedInputIterator:二进制类型的输入轮询且按照指定的comparator算法进行排序;
InputIterator提供的方法如下:
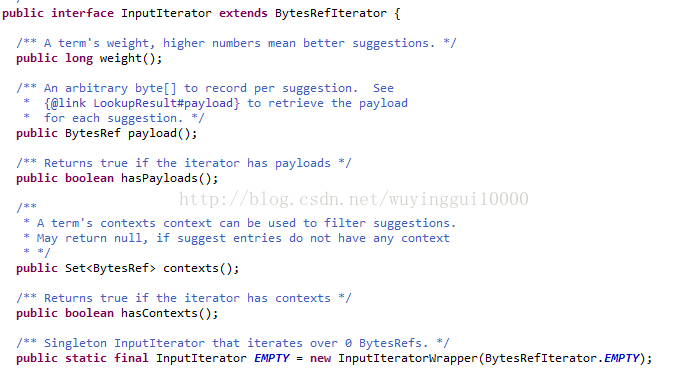
weight():此方法设置某个term的权重,设置的越高suggest的优先级越高;
payload():每个suggestion对应的元数据的二进制表示,我们在传输对象的时候需要转换对象或对象的某个属性为BytesRef类型,相应的suggester调用lookup的时候会返回payloads信息;
hasPayload():判断iterator是否有payloads;
contexts():获取某个term的contexts,用来过滤suggest的内容,如果suggest的列表为空,返回null
hasContexts():获取iterator是否有contexts;
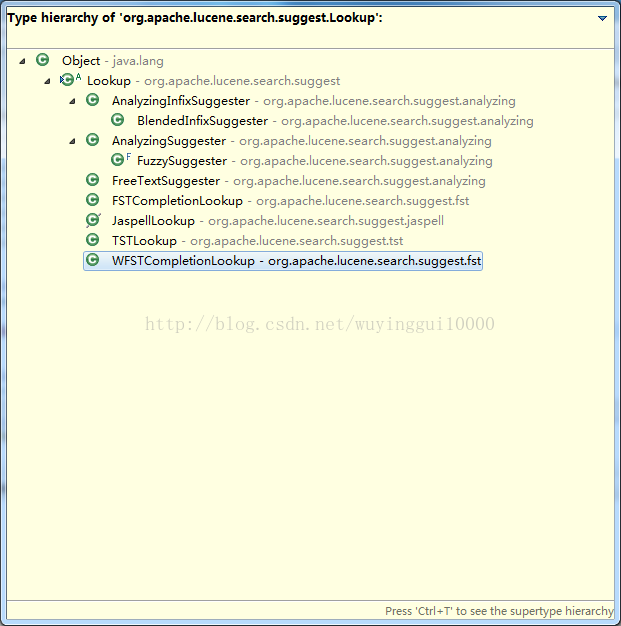
Suggester查询工具Lookup类说明
此类提供了字符串的联想查询功能
Lookup类提供了一个CharSequenceComparator,此comparator主要是用来对CharSequence进行排序,按字符顺序排序;
内置LookupResult,用于返回suggest的结果,同时也是按照CharSequenceComparator进行key的排序;
内置了LookupPriorityQueue,用以存储LookupResult;
LookUp提供的方法
build(Dictionary dict) : 从指定directory进行build;
load(InputStream input) : 将InputStream转成DataInput并执行load(DataInput)方法;
store(OutputStream output) : 将OutputStream转成DataOutput并执行store(DataOutput)方法;
getCount() : 获取lookup的build的项的数量;
build(InputIterator inputIterator) : 根据指定的InputIterator构建Lookup对象;
lookup(CharSequence key, boolean onlyMorePopular, int num) :根据key查询可能的结果返回值为List<LookupResult>;
Lookup的相关实现如下:
编写自己的suggest模块
注意:在suggest的时候我们需要导入lucene-misc-5.1.0.jar否则系统会提示类SortedMergePolicy没有找到;
首先我们定义自己的实体类:
package com.lucene.suggest;
import java.io.Serializable;
public class Product implements Serializable {
private static final long serialVersionUID = 1L;
private String name;
private String image;
private String[] regions;
private int numberSold;
public Product(String name, String image, String[] regions, int numberSold) {
this.name = name;
this.image = image;
this.regions = regions;
this.numberSold = numberSold;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getImage() {
return image;
}
public void setImage(String image) {
this.image = image;
}
public String[] getRegions() {
return regions;
}
public void setRegions(String[] regions) {
this.regions = regions;
}
public int getNumberSold() {
return numberSold;
}
public void setNumberSold(int numberSold) {
this.numberSold = numberSold;
}
}
然后定义InputIterator这里定义消费者是List<Object>,并对list进行遍历放入payload中:
package com.lucene.suggest;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
import java.io.UnsupportedEncodingException;
import java.util.Comparator;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
import org.apache.lucene.search.suggest.InputIterator;
import org.apache.lucene.util.BytesRef;
public class ProductIterator implements InputIterator {
private Iterator<Product> productIterator;
private Product currentProduct;
ProductIterator(Iterator<Product> productIterator) {
this.productIterator = productIterator;
}
public boolean hasContexts() {
return true;
}
/**
* 是否有设置payload信息
*/
public boolean hasPayloads() {
return true;
}
public Comparator<BytesRef> getComparator() {
return null;
}
public BytesRef next() {
if (productIterator.hasNext()) {
currentProduct = productIterator.next();
try {
return new BytesRef(currentProduct.getName().getBytes("UTF8"));
} catch (UnsupportedEncodingException e) {
throw new RuntimeException("Couldn't convert to UTF-8",e);
}
} else {
return null;
}
}
public BytesRef payload() {
try {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream out = new ObjectOutputStream(bos);
out.writeObject(currentProduct);
out.close();
return new BytesRef(bos.toByteArray());
} catch (IOException e) {
throw new RuntimeException("Well that's unfortunate.");
}
}
public Set<BytesRef> contexts() {
try {
Set<BytesRef> regions = new HashSet<BytesRef>();
for (String region : currentProduct.getRegions()) {
regions.add(new BytesRef(region.getBytes("UTF8")));
}
return regions;
} catch (UnsupportedEncodingException e) {
throw new RuntimeException("Couldn't convert to UTF-8");
}
}
public long weight() {
return currentProduct.getNumberSold();
}
}
编写测试类
package com.lucene.suggest;
import java.io.ByteArrayInputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.search.suggest.Lookup.LookupResult;
import org.apache.lucene.search.suggest.analyzing.AnalyzingInfixSuggester;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.BytesRef;
public class SuggestProducts {
private static void lookup(AnalyzingInfixSuggester suggester, String name,
String region) throws IOException {
HashSet<BytesRef> contexts = new HashSet<BytesRef>();
contexts.add(new BytesRef(region.getBytes("UTF8")));
List<LookupResult> results = suggester.lookup(name, contexts, 2, true, false);
System.out.println("-- \"" + name + "\" (" + region + "):");
for (LookupResult result : results) {
System.out.println(result.key);
BytesRef bytesRef = result.payload;
ObjectInputStream is = new ObjectInputStream(new ByteArrayInputStream(bytesRef.bytes));
Product product = null;
try {
product = (Product)is.readObject();
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("product-Name:" + product.getName());
System.out.println("product-regions:" + product.getRegions());
System.out.println("product-image:" + product.getImage());
System.out.println("product-numberSold:" + product.getNumberSold());
}
System.out.println();
}
public static void main(String[] args) {
try {
Directory indexDir = FSDirectory.open(Paths.get("suggestPath", new String[0]));
StandardAnalyzer analyzer = new StandardAnalyzer();
AnalyzingInfixSuggester suggester = new AnalyzingInfixSuggester(indexDir, analyzer);
ArrayList<Product> products = new ArrayList<Product>();
products.add(new Product("Electric Guitar",
"http://images.example/electric-guitar.jpg", new String[] {
"US", "CA" }, 100));
products.add(new Product("Electric Train",
"http://images.example/train.jpg", new String[] { "US",
"CA" }, 100));
products.add(new Product("Acoustic Guitar",
"http://images.example/acoustic-guitar.jpg", new String[] {
"US", "ZA" }, 80));
products.add(new Product("Guarana Soda",
"http://images.example/soda.jpg",
new String[] { "ZA", "IE" }, 130));
suggester.build(new ProductIterator(products.iterator()));
lookup(suggester, "Gu", "US");
lookup(suggester, "Gu", "ZA");
lookup(suggester, "Gui", "CA");
lookup(suggester, "Electric guit", "US");
suggester.refresh();
} catch (IOException e) {
System.err.println("Error!");
}
}
}
相关代码会在明天放出
一步一步跟我学习lucene是对近期做lucene索引的总结,大家有问题的话联系本人的Q-Q: 891922381,同时本人新建Q-Q群:106570134(lucene,solr,netty,hadoop),大家共同探讨,本人争取每日一博,希望大家持续关注,会带给大家惊喜的














 828
828











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









