







1.背景
随着项目的访问量增加,单个数据库压力越来越大,最终演变成数据库的性能瓶颈,各种操作也会更加耗时。
一般会采用以下几种方式优化系统
本文主要就是介绍springboot+mybatis+druib 连接池架构下如何实现读写分离以加快数据库读取速度。
2.如何实现
注:这里不讲如何搭建主从数据库集群。主要讲代码集成。
总结下来需要实现读写分离,主要需要解决2个问题
-
如何切换数据源
-
如何根据不同的方法选择正确的数据源
2.1如何切换数据源
spring是支持多数据源配置的,可以把多个数据源放到一个Map中。这里需要自定义一个数据源继承AbstractRoutingDataSource,并重写determineCurrentLookupKey方法,通过获取的key来决定使用哪个数据源。
附:AbstractRoutingDataSource类设置数据源-(源码示例片段)
public void setTargetDataSources(Map<Object, Object> targetDataSources) { this.targetDataSources = targetDataSources;}2.2如何选择数据源事务一般是在 Service 层的,因此在开始这个 service 方法调用时要确定数据源。
那么有什么通用方法能够在开始执行一个方法前做操作呢?
-
切面
这里切面拦截设计也有两种(也可以同时使用)
-
注解式,定义一个自定义注解,使用切面进行拦截使用了该注解的方法
-
方法名,根据方法名写切点,比如 getXXX 用读库,setXXX 用写库
3.前置准备
本文实例是以 1个主数据源,2个从数据源,为例
创建一张测试表,初始化部分测试数据
CREATE TABLE `user_info` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增主键id', `user_id` varchar(32) NOT NULL COMMENT '人员id', `user_name` varchar(32) NOT NULL COMMENT '用户名', `user_password` varchar(32) NOT NULL COMMENT '密码', `real_name` varchar(64) NOT NULL COMMENT '真实姓名', `mobile` varchar(20) NOT NULL DEFAULT '' COMMENT '手机号', `remark` varchar(255) NOT NULL DEFAULT '' COMMENT '备注', `create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', `update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间', `del_flag` tinyint(4) NOT NULL DEFAULT '0' COMMENT '删除标记 0正常 1-删除', PRIMARY KEY (`id`) USING BTREE, UNIQUE KEY `uniq_user_id` (`user_id`) USING BTREE) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='人员信息表';初始化测试数据
INSERT INTO `db_test2`.`user_info`(`id`, `user_id`, `user_name`, `user_password`, `real_name`, `mobile`, `remark`, `create_time`, `update_time`, `del_flag`) VALUES (1, '1001', 'lisi', '333222', '李四', '15678298934', '我是 - 李四', '2020-07-25 18:57:06', '2020-07-26 17:49:11', 0);INSERT INTO `db_test2`.`user_info`(`id`, `user_id`, `user_name`, `user_password`, `real_name`, `mobile`, `remark`, `create_time`, `update_time`, `del_flag`) VALUES (2, '1002', 'wangwu', '555666', '王五', '18778298934', '我是 - 王五', '2020-07-25 18:57:06', '2020-07-26 17:49:15', 0);4.代码实战
注:文末附录源码地址
先创建一个springBoot项目,依赖以及配置文件,详见下文中附录

4.1数据源类型枚举
/** * 数据源-枚举 * * @author 程序员小强 * @date 2020-07-26 */public enum DataSourceTypeEnum { MASTER, SLAVE1, SLAVE2;}4.2数据源切换注解
/** * 目标数据源注解-作用于方法上 * * @author 程序员小强 * @date 2020-07-26 */@Documented@Target({ElementType.METHOD})@Retention(RetentionPolicy.RUNTIME)public @interface TargetDataSource { /** * 目标数据源枚举名称 */ DataSourceTypeEnum value();}4.3自定义动态数据源/** * 扩展动态-数据源 * * @author 程序员小强 * @date 2020-07-26 */public class DynamicDataSource extends AbstractRoutingDataSource { private final Logger logger = LoggerFactory.getLogger(DynamicDataSource.class); /** * 通过路由Key切换数据源 * * spring 在开始进行数据库操作时会通过这个方法来决定使用哪个数据库, * 因此我们在这里调用 DynamicDataSourceContextHolder.getDataSourceType()方法获取当前操作类别, * 同时可进行读库的负载均衡 */ @Override protected Object determineCurrentLookupKey() { DataSourceTypeEnum typeEnum = DynamicDataSourceContextHolder.getDataSourceType(); logger.info("[ Change data source ] >> " + typeEnum.name()); return typeEnum; }}/** * 通过ThreadLocal将数据源设置到每个线程上下文中 * 用于切换读/写模式数据源 * 原理: * 1.利用ThreadLocal保存当前线程数据源模式 * 2.操作结束后清除该数据,避免内存泄漏,同时也为了后续在该线程进行写操作时任然为读模式 * * @author 程序员小强 * @date 2020-07-26 */public class DynamicDataSourceContextHolder { private static final ThreadLocal CONTEXT_HOLDER = new ThreadLocal<>(); public static void setDataSourceType(DataSourceTypeEnum dataSourceType) { CONTEXT_HOLDER.set(dataSourceType); } /** * 获取数据源路由key * 默认主库 */ public static DataSourceTypeEnum getDataSourceType() { return CONTEXT_HOLDER.get() == null ? DataSourceTypeEnum.MASTER : CONTEXT_HOLDER.get(); } public static void removeDataSourceType() { CONTEXT_HOLDER.remove(); }}4.4主从数据源核心配置
/** * 数据源配置 * * @author 程序员小强 * @date 2020-07-25 */@Configurationpublic class DataSourceConfig { /** * 主数据源 (可读可写的主数据源) */ @Primary @Bean(name = "masterDataSource") @Qualifier("masterDataSource") @ConfigurationProperties(prefix = "spring.datasource.master") public DataSource masterDataSource() { //指定连接池类型-DruidDataSource return DataSourceBuilder.create().type(DruidDataSource.class).build(); } /** * 从数据源1(只读从数据源1) */ @Bean(name = "slave1DataSource") @ConfigurationProperties(prefix = "spring.datasource.slave1") public DataSource salve1DataSource() { return DataSourceBuilder.create().type(DruidDataSource.class).build(); } /** * 从数据源2(只读从数据源2) */ @Bean(name = "slave2DataSource") @ConfigurationProperties(prefix = "spring.datasource.slave2") public DataSource salve2DataSource() { return DataSourceBuilder.create().type(DruidDataSource.class).build(); } /** * 动态数据源 * * @param masterDataSource 可读可写主数据源 * @param slave1DataSource 只读子数据源1 * @param slave2DataSource 只读子数据源2 */ @Bean(name = "dynamicDataSource") public DataSource createDynamicDataSource( @Qualifier(value = "masterDataSource") final DataSource masterDataSource, @Qualifier(value = "slave1DataSource") final DataSource slave1DataSource, @Qualifier("slave2DataSource") DataSource slave2DataSource) { //将所有数据源放到Map中 Map targetDataSources = new HashMap<>(4); targetDataSources.put(DataSourceTypeEnum.MASTER, masterDataSource); targetDataSources.put(DataSourceTypeEnum.SLAVE1, slave1DataSource); targetDataSources.put(DataSourceTypeEnum.SLAVE2, slave2DataSource); //动态数据源 DynamicDataSource dynamicDataSource = new DynamicDataSource(); //设置默认数据源 dynamicDataSource.setDefaultTargetDataSource(masterDataSource); //设置可通过路由key,切换的数据源Map集 dynamicDataSource.setTargetDataSources(targetDataSources); return dynamicDataSource; }}4.5Mybatis配置
/** * MyBatis 配置 * * @author 程序员小强 */@Configuration@MapperScan(basePackages = "com.example.mapper")public class MyBatisConfig { @Resource(name = "dynamicDataSource") private DataSource dynamicDataSource; /** * sqlSessionFactory 配置 * 扫描mybatis下的xml文件 * * @return * @throws Exception */ @Bean public SqlSessionFactory sqlSessionFactory() throws Exception { SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean(); //指定数据源 sqlSessionFactoryBean.setDataSource(dynamicDataSource); //mybatis下xml扫描地址 sqlSessionFactoryBean.setMapperLocations(new PathMatchingResourcePatternResolver() .getResources("classpath:mybatis/mapper/*.xml")); return sqlSessionFactoryBean.getObject(); } /** * 事务管理 */ @Bean public DataSourceTransactionManager transactionManager() { return new DataSourceTransactionManager(dynamicDataSource); }}4.6测试接口实现
分别写了几个测试方法,并且通过注解@TargetDataSource指定了数据源
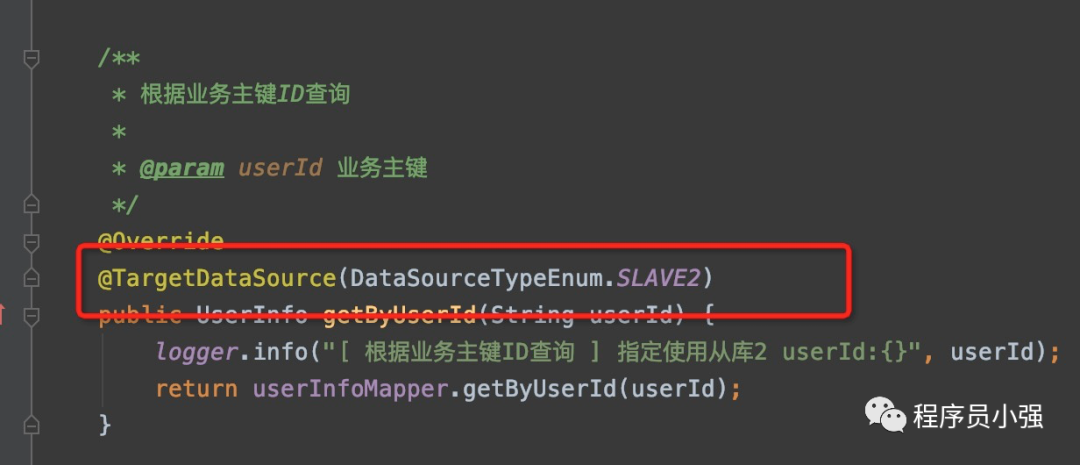
/** * @author 程序员小强 * @date 2020-07-26 00:52 */@Servicepublic class UserServiceImpl implements UserService { private static final Logger logger = LoggerFactory.getLogger(UserServiceImpl.class); @Resource private UserInfoMapper userInfoMapper; /** * 新增人员 * 指定使用主库 * * @param addBO */ @Override @TargetDataSource(DataSourceTypeEnum.MASTER) public void addUser(UserAddBO addBO) { logger.info("[ 新增人员 ] start param:{}", addBO); String userId = UUID.randomUUID().toString().replaceAll("-", ""); UserInfo userInfo = new UserInfo(); userInfo.setUserId(userId); userInfo.setUserName(addBO.getUserName()); userInfo.setRealName(addBO.getRealName()); userInfo.setMobile(addBO.getMobile()); userInfo.setCreateTime(new Date()); userInfo.setUpdateTime(new Date()); userInfo.setRemark(addBO.getRemark()); //demo项目部分参数值写死 userInfo.setUserPassword("123456"); userInfo.setDelFlag(0); userInfoMapper.insert(userInfo); logger.info("[ 新增人员 ] end userId:{},userName:{}", userId, addBO.getUserName()); } /** * 修改人员信息 * * @param updateBO */ @Override @TargetDataSource(DataSourceTypeEnum.MASTER) public void updateUser(UserUpdateBO updateBO) { logger.info("[ 修改人员信息 ] start param:{}", updateBO); UserInfo userInfo = new UserInfo(); userInfo.setUserId(updateBO.getUserId()); userInfo.setUserName(updateBO.getUserName()); userInfo.setRealName(updateBO.getRealName()); userInfo.setMobile(updateBO.getMobile()); userInfo.setCreateTime(new Date()); userInfo.setUpdateTime(new Date()); userInfo.setRemark(updateBO.getRemark()); userInfoMapper.updateByUserIdSelective(userInfo); logger.info("[ 修改人员信息 ] end userId:{},userName:{}", updateBO.getUserId(), updateBO.getUserName()); } /** * 查询所有 人员信息 * * @return 人员信息 列表 */ @Override @TargetDataSource(DataSourceTypeEnum.SLAVE1) public ListgetAll() { logger.info("[ 查询所有人员列表 ] 指定使用从库1 "); return userInfoMapper.getAll(); } /** * 根据业务主键ID查询 * * @param userId 业务主键 */ @Override @TargetDataSource(DataSourceTypeEnum.SLAVE2) public UserInfo getByUserId(String userId) { logger.info("[ 根据业务主键ID查询 ] 指定使用从库2 userId:{}", userId); return userInfoMapper.getByUserId(userId); }}4.7测试controller
/** * 读写分离-Demo人员测试接口 * * @author 程序员小强 */@RestController@RequestMapping("/user")public class UserInfoController { @Resource private UserService userService; /** * 新增人员 * * @param addBO */ @PostMapping("/add") public Object addUser(@RequestBody UserAddBO addBO) { userService.addUser(addBO); return "success"; } /** * 修改人员 * * @param updateBO */ @PostMapping("/update") public Object updateUser(@RequestBody UserUpdateBO updateBO) { userService.updateUser(updateBO); return "success"; } /** * 查询所有 人员信息 * * @return 人员信息 列表 */ @RequestMapping("/listAll") public List getAll() { return userService.getAll(); } /** * 根据业务主键ID查询 * * @param userId 业务主键 */ @RequestMapping("/getByUserId") public UserInfo getByUserId(@RequestParam("userId") String userId) { return userService.getByUserId(userId); }}4.8测试结果
4.8.1新增人员接口
由于新增人员指定了主数据源,从下图中日志可以看到,拦截起作用了
 日志:
日志:

4.8.2查询人员接口

代码示例:
日志

4.8附录其它配置
4.8.1配置文件
注:主从数据库由于Demo项目,仅使用了本地的同一个数据库,实际生产环境需要搭建主从集群自动同步的环境
server.port=8081# jackson时间格式化(解决时区问题)spring.jackson.time-zone=GMT+8spring.jackson.date-format=yyyy-MM-dd HH:mm:ss#主数据源 >> 配置#连接地址spring.datasource.master.url=jdbc:mysql://localhost:3306/db_test2?useUnicode=true&characterEncoding=utf8&autoReconnect=true&serverTimezone=Asia/Shanghai&allowMultiQueries=true#用户名spring.datasource.master.username=root#密码spring.datasource.master.password=123456#驱动spring.datasource.master.driver-class-name=com.mysql.cj.jdbc.Driver#连接池其它设置#初始化时建立物理连接的个数spring.datasource.master.initial-size=10#最小连接池数量spring.datasource.master.min-idle=10#最大连接池数量spring.datasource.master.max-active=30#获取连接时最大等待时间,单位毫秒spring.datasource.master.max-wait=60000#申请连接检测,空闲时间大于检测的间隔时间,执行validationQuery检测spring.datasource.master.test-while-idle=true#检测的间隔时间spring.datasource.master.time-between-eviction-runs-millis=60000#销毁线程时检测当前连接的最后活动时间和当前时间差大于该值时,关闭当前连接spring.datasource.master.min-evictable-idle-time-millis=30000#用来检测连接是否有效spring.datasource.master.validation-query=SELECT 1 FROM DUAL #申请连接时会执行validationQuery检测连接是否有效,开启会降低性能,默认为truespring.datasource.master.test-on-borrow=false#归还连接时会执行validationQuery检测连接是否有效,开启会降低性能,默认为truespring.datasource.master.test-on-return=false#从数据源1 >> 配置#连接地址spring.datasource.slave1.url=jdbc:mysql://localhost:3306/db_test2?useUnicode=true&characterEncoding=utf8&autoReconnect=true&serverTimezone=Asia/Shanghai&allowMultiQueries=true#用户名spring.datasource.slave1.username=root#密码spring.datasource.slave1.password=123456#驱动spring.datasource.slave1.driver-class-name=com.mysql.cj.jdbc.Driver#连接池其它设置#初始化时建立物理连接的个数spring.datasource.slave1.initial-size=10#最小连接池数量spring.datasource.slave1.min-idle=10#最大连接池数量spring.datasource.slave1.max-active=30#获取连接时最大等待时间,单位毫秒spring.datasource.slave1.max-wait=60000#申请连接检测,空闲时间大于检测的间隔时间,执行validationQuery检测spring.datasource.slave1.test-while-idle=true#检测的间隔时间spring.datasource.slave1.time-between-eviction-runs-millis=60000#销毁线程时检测当前连接的最后活动时间和当前时间差大于该值时,关闭当前连接spring.datasource.slave1.min-evictable-idle-time-millis=30000#用来检测连接是否有效spring.datasource.slave1.validation-query=SELECT 1 FROM DUAL #申请连接时会执行validationQuery检测连接是否有效,开启会降低性能,默认为truespring.datasource.slave1.test-on-borrow=false#归还连接时会执行validationQuery检测连接是否有效,开启会降低性能,默认为truespring.datasource.slave1.test-on-return=false#从数据源2 >> 配置#连接地址spring.datasource.slave2.url=jdbc:mysql://localhost:3306/db_test2?useUnicode=true&characterEncoding=utf8&autoReconnect=true&serverTimezone=Asia/Shanghai&allowMultiQueries=true#用户名spring.datasource.slave2.username=root#密码spring.datasource.slave2.password=123456#驱动spring.datasource.slave2.driver-class-name=com.mysql.cj.jdbc.Driver#连接池其它设置#初始化时建立物理连接的个数spring.datasource.slave2.initial-size=10#最小连接池数量spring.datasource.slave2.min-idle=10#最大连接池数量spring.datasource.slave2.max-active=30#获取连接时最大等待时间,单位毫秒spring.datasource.slave2.max-wait=60000#申请连接检测,空闲时间大于检测的间隔时间,执行validationQuery检测spring.datasource.slave2.test-while-idle=true#检测的间隔时间spring.datasource.slave2.time-between-eviction-runs-millis=60000#销毁线程时检测当前连接的最后活动时间和当前时间差大于该值时,关闭当前连接spring.datasource.slave2.min-evictable-idle-time-millis=30000#用来检测连接是否有效spring.datasource.slave2.validation-query=SELECT 1 FROM DUAL #申请连接时会执行validationQuery检测连接是否有效,开启会降低性能,默认为truespring.datasource.slave2.test-on-borrow=false#归还连接时会执行validationQuery检测连接是否有效,开启会降低性能,默认为truespring.datasource.slave2.test-on-return=false#日志配置logging.level.root=WARNlogging.level.com.example=INFO4.8.2Maven依赖
<parent> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-parentartifactId> <version>2.2.0.RELEASEversion>parent><properties> <java.version>1.8java.version> <alibaba.druid.version>1.1.14alibaba.druid.version> <mysql-connector.version>8.0.13mysql-connector.version> <lombok.version>1.18.10lombok.version> <mybatis-spring-boot.version>1.3.2mybatis-spring-boot.version> <project.build.sourceEncoding>UTF-8project.build.sourceEncoding>properties><dependencies> <dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-webartifactId> dependency> <dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-aopartifactId> dependency> <dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-jdbcartifactId> dependency> <dependency> <groupId>org.mybatis.spring.bootgroupId> <artifactId>mybatis-spring-boot-starterartifactId> <version>${mybatis-spring-boot.version}version> dependency> <dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-testartifactId> <scope>testscope> dependency> <dependency> <groupId>mysqlgroupId> <artifactId>mysql-connector-javaartifactId> <version>${mysql-connector.version}version> dependency> <dependency> <groupId>com.alibabagroupId> <artifactId>druidartifactId> <version>${alibaba.druid.version}version> dependency> <dependency> <groupId>org.projectlombokgroupId> <artifactId>lombokartifactId> <version>${lombok.version}version> dependency>dependencies>5.优缺点分析
5.1优点
-
降低主数据库压力
-
增强数据安全性,读写分离有个好处就是数据近乎实时备份,一旦某台服务器硬盘发生了损坏,从库的数据可以无限接近主库
-
可以实现高可用,当然只是配置了读写分离并不能实现高可用,最多就是在Master(主库)宕机了还能进行查询操作,具体高可用还需要其他操作
5.2缺点
-
增大成本,多台数据库的成本
-
增大代码复杂度
-
增大写入成本,虽然降低了读取成本,但是写入成本却是一点也没有降低,还有从库一直在向主库请求数据
6.源码地址
源码地址
https://github.com/xqiangme/spring-boot-example/tree/master/spring-boot-read-and-write-datasource














 269
269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









