






神经网络的训练主要使用反向传播算法,模型预测值(logits)与正确标签(label)送入损失函数(loss function)获得loss,然后进行反向传播计算,求得梯度(gradients),最终更新至模型参数(parameters)。
本章主要讲MindSpore中自动微分接口grad和value_and_grad的使用。
函数与计算图:
如下图,构建基于一般图计算的计算函数和神经网络模型。
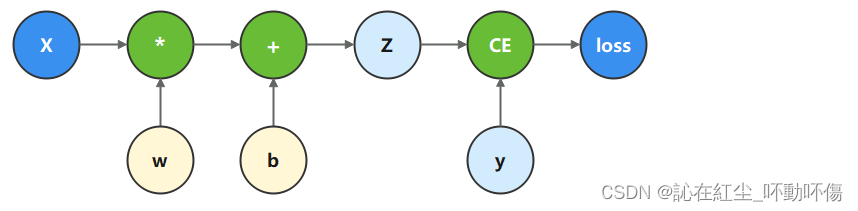
import numpy as np
import mindspore
from mindspore import nn
from mindspore import ops
from mindspore import Tensor, Parameter
x = ops.ones(5, mindspore.float32) # input tensor
y = ops.zeros(3, mindspore.float32) # expected output
w = Parameter(Tensor(np.random.randn(5, 3), mindspore.float32), name='w') # 权重值
b = Parameter(Tensor(np.random.randn(3,), mindspore.float32), name='b') # 偏置值
## 构建图计算函数
def function(x, y, w, b):
z = ops.matmul(x, w) + b
loss = ops.binary_cross_entropy_with_logits(z, y, ops.ones_like(z), ops.ones_like(z))
return loss
loss = function(x, y, w, b)
print(loss)![]()
微分函数与梯度计算:
调用mindspore.grad函数,来获得function的微分函数。
这里使用了grad函数的两个入参,分别为:
fn:待求导的函数。grad_position:指定求导输入位置的索引。
grad_fn = mindspore.grad(function, (2, 3))
## 获得w,b对应梯度
grads = grad_fn(x, y, w, b)
print(grads)
Stop Gradient:
用于实现对某个输出项的梯度截断,或消除某个Tensor对梯度的影响。
## 定义loss,z两个返回参数
def function_with_logits(x, y, w, b):
z = ops.matmul(x, w) + b
loss = ops.binary_cross_entropy_with_logits(z, y, ops.ones_like(z), ops.ones_like(z))
return loss, z
grad_fn = mindspore.grad(function_with_logits, (2, 3), has_aux=True)
grads, (z,) = grad_fn(x, y, w, b)
print(grads, z)
## 定义截断z的函数
def function_stop_gradient(x, y, w, b):
z = ops.matmul(x, w) + b
loss = ops.binary_cross_entropy_with_logits(z, y, ops.ones_like(z), ops.ones_like(z))
return loss, ops.stop_gradient(z)
grad_fn = mindspore.grad(function_stop_gradient, (2, 3))
grads = grad_fn(x, y, w, b)
print(grads)
可以看到多参数造成的梯度影响,在截断z后,求导结果恢复。
Auxiliary data:
辅助数据,是函数除第一个输出项外的其他输出。通常我们会将函数的loss设置为函数的第一个输出,其他的输出即为辅助数据。grad和value_and_grad提供has_aux参数,当其设置为True时,可以自动实现前文手动添加stop_gradient的功能,满足返回辅助数据的同时不影响梯度计算的效果。
grad_fn = mindspore.grad(function_with_logits, (2, 3), has_aux=True)
grads, (z,) = grad_fn(x, y, w, b)
print(grads, z)
输出z的同时,梯度计算结果不受影响。
神经网络梯度计算:
利用函数式自动微分来实现反向传播。
## 定义神经网络模型
class Network(nn.Cell):
def __init__(self):
super().__init__()
self.w = w
self.b = b
def construct(self, x):
z = ops.matmul(x, self.w) + self.b
return z
## 实例化模型和损失函数
model = Network()
loss_fn = nn.BCEWithLogitsLoss()
## 定义前向函数
def forward_fn(x, y):
z = model(x)
loss = loss_fn(z, y)
return loss
## 获得微分函数
grad_fn = mindspore.value_and_grad(forward_fn, None, weights=model.trainable_params())
## 求损失值和梯度
loss, grads = grad_fn(x, y)
print(grads)
可见与前面function梯度求值一致。















 448
448











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









