









这是一次在 defrag 2014的演讲。

长期处于科技之中的一点优势是你会看到多种技术从开始到结束。你会明白这些突破性进展是如何取得的。如果你看到的只是历史的一部分,那么很难正确地去推断。你要么经历了短期的进展,要么依旧处于长期落后。令人吃惊得不是瞬息万变的事物,而是一点一滴工程实践的突破。这是一台 Strowger 交换机,以一种自动化的方式去连接电话线路,它被发明于 1891 年。

1951 年,数字交换设备是当时的尖端技术,这个典型的中央交换机从根本上说是维多利亚时代技术的放大版。每个转接过来的电话都有自己单独的 strowger 交换机。
从时间的角度,这是当时最高的科技。当然,从我们的角度,这是世界上最大的蒸汽朋克(译者注:蒸汽是代表了以蒸汽机作为动力的大型机械。朋克则是一种非主流的边缘文化)设施。

你可能会错误地感觉它是卓越的。这是因为集成电路已经发明 65 年了,但现在我们仍有数十亿这家伙在嗡嗡咔咔的运行着。现在我们才处于全固态计算的转折点。
技术变更中最令人兴奋的是当一项新的技术最终变得可行,或当一项旧的限制被去除,这两种正在我们的行业中上演。

分布式计算正在成为整个软件行业的主导编程模型。所谓的“核心部分”不再是核心了,甚至仅是一个单元。它仅仅算是大数据上爬行的群虫中的一只。数据库是最后的堡垒。
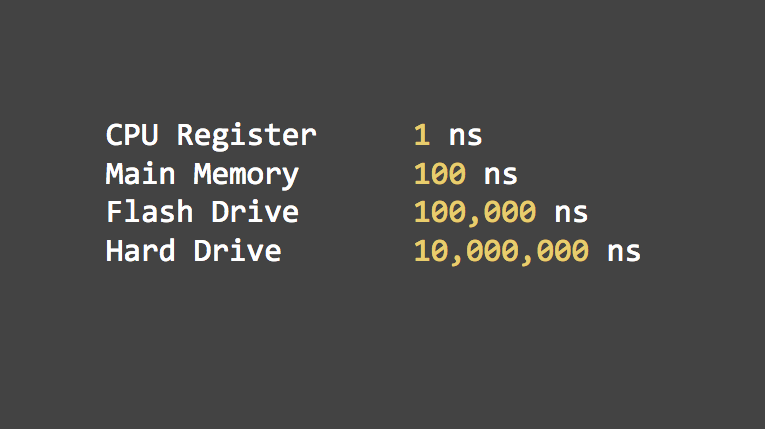
于此同时,内存与硬盘存储空间上的潜在差距正在变得无关紧要。30 年来关键的是,采用随机访问数据的内存与硬盘在时间上产生了巨大差距。现在,通过将整个数据放置到内存中来解决这些问题是可行的。当然这没有那么简单。你不能仅仅采用 b-tree,mmap 来管理它就完事了。在完全基于内存的设计方案推出之前还有很多相关的东西要解决。
这两种趋势产生了一种全新的方式去思考,设计,以及构建应用程序。所以,让我们谈谈我们是如何达到的,我们是如何做的,以及未来带给我们的启示。

早些时候,体系结构图中的每一个部件都有一个确定的描述与之相关。每一部分是一个独立的功能:“数据库”和“web服务器”就像一间房(指机房)中不同的人物。顺便说一句,这就是术语“云”的由来。蓬松的云是外部广域网的一种标准象征,这不用我们关心。
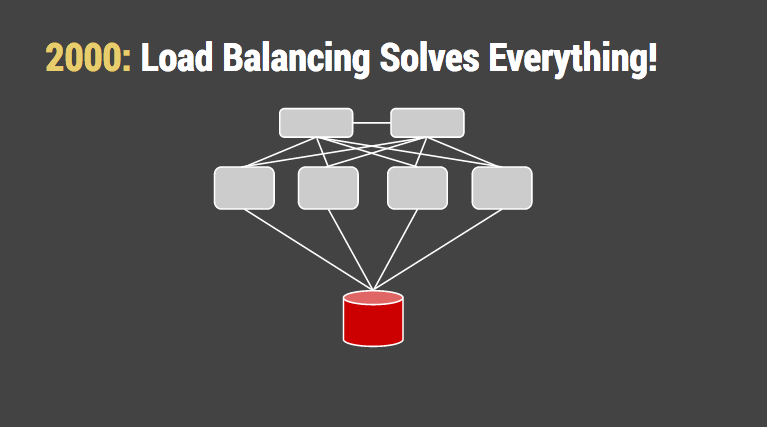
分布式计算因容易实现已成为主流。多个相同的应用程序服务器,都隐藏在一台平均分配任务的“负载均衡器”后。负载均衡无状态位的架构回避了很多哲学问题。由于系统规模的增长,这些部件包含并且最终围绕着“数据库”。我们告诉我们自己使用最快的磁盘和更快的CPU在数据库上是正常的,毕竟只在一台机器上。硬件厂商很高兴的赚着我们的钱。
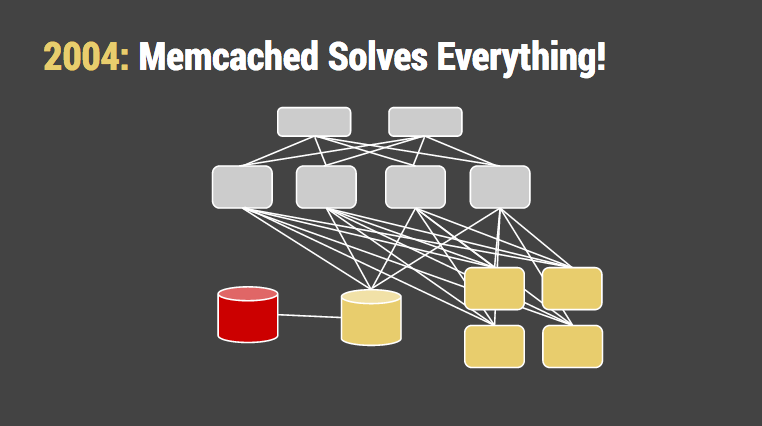
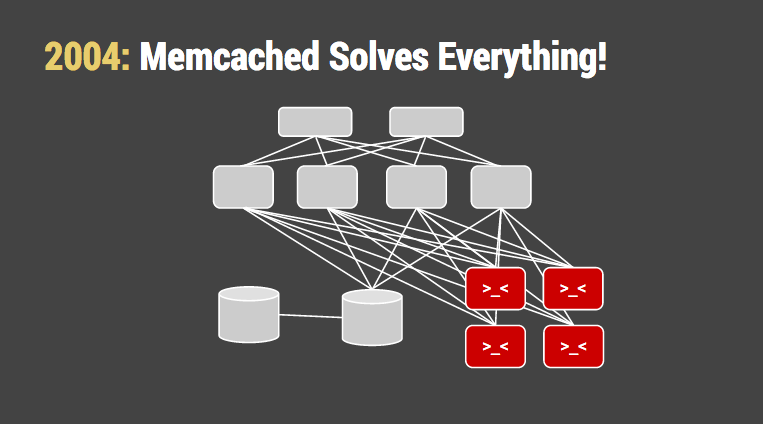
值得称道的是,memcached 的设计方案使我们受益很长时间。它使用多个内存随机 IO 操作来替换硬盘随机 IO 操作。即使这样,运行数据库的机器依然变得更大,更加忙碌。我们认识到,缓存的开销至少是由许多内存组成的工作集(否则是无效的),加上令人难以忍受的缓存一致性问题。但我们告诉我们自己,这是“网络规模”所带来的成本。
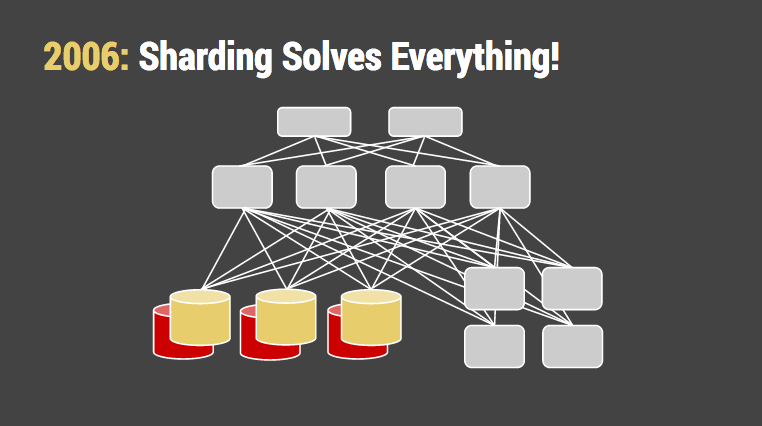
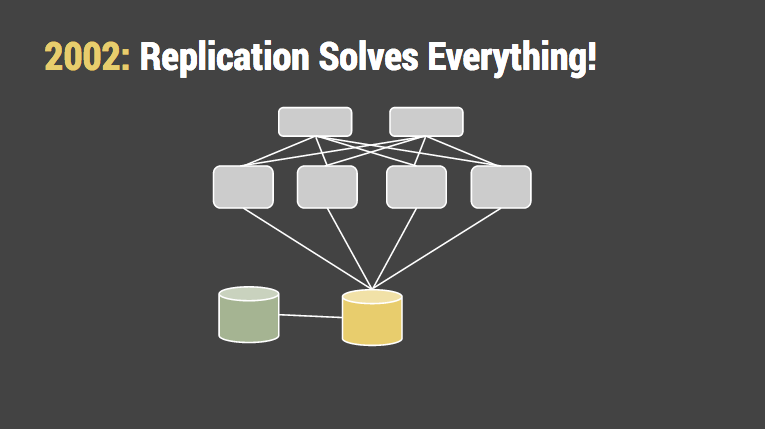
更令人担忧的是应用程序变得越来越复杂和即时性。几乎每次访问数据库都会有多个写操作。是写成为了瓶颈而不是读。这时我们开始严肃的对待数据库拆分。Facebook 最初通过大学字段来拆分用户数据,并且带着“哈佛数据库”概念维持了很长的时间。Flickr 是一个好例子。他们亲手创建基于 Php 的系统并通过哈希用户 ID 来拆分数据库,与 memcached 切分键值的方式相同。在研讨会上,他们提到不得不对数据进行去规范化,以及一些对象如评论,消息,喜爱进行两次写操作。
但是,要无限伸缩总要付出点代价,对吗?
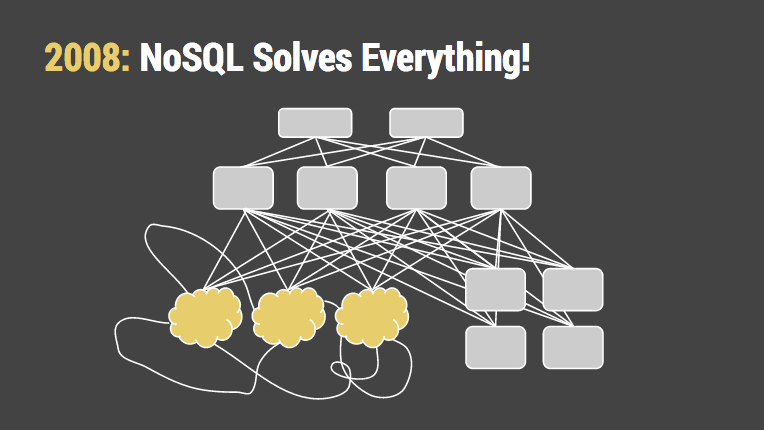

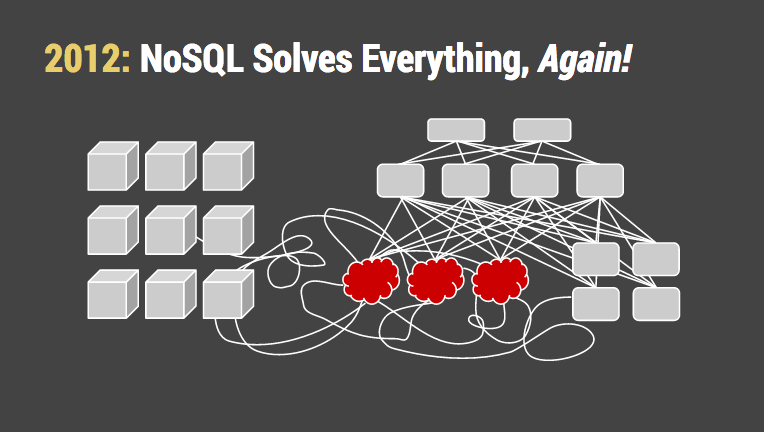

套用 Paul Graham's 难以忍受 Lisp 的俏皮言论:一旦你添加了 group by, filter, &join,你不能再声明你发明了一种新的查询语言。仅仅是新的SQL方言。带着糟糕的语法,还没有优化器。
因为我们对 SQL 采取这种奇怪的绕路走方式,大多数系统缺失一个存储引擎和围绕关系集理论设计的查询优化器。而这些都是基于关系型集合理论设计的。拖延到后期去实现导致了严重的性能问题。即使解决了性能问题(或这以驻留在内存中来掩盖问题),也缺少了其他东西。比如备份。
我知道一个你肯定听说过极度成功的 web 互联网公司使用4个独立的NoSQL系统来解决问题。
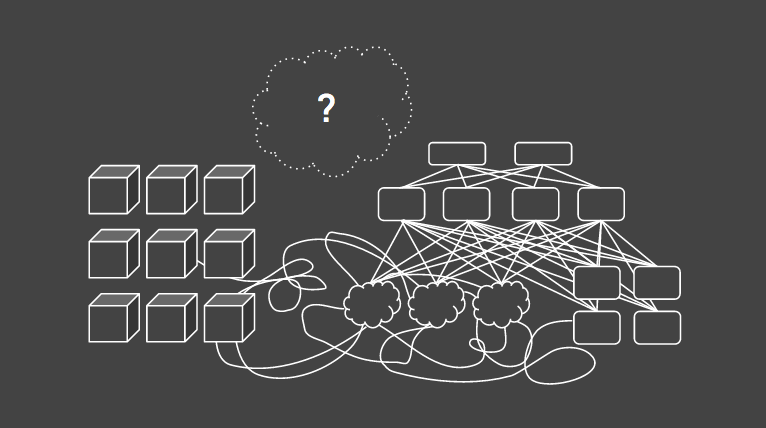
比如内存:你的“数据库”机器上有很多内存,用作缓存和计算。Memcached 机器上也有许多的内存。这些内存的总和至少和你的工作集数据大小一样,如果不是那么你赚到了。另外,我非常怀疑缓存层是否是 100% 有效。我敢和你打赌,你的大量数据缓存再擦除前你从不会读取。我还敢打赌,你甚至不跟踪这些数据,这不意味着你是一个坏人,它意味着缓存相对与它的价值,带来更多的常常是麻烦。
这些组件提供的很多特性看起来是可以组合及互补的。如果我们可以合理的安排。

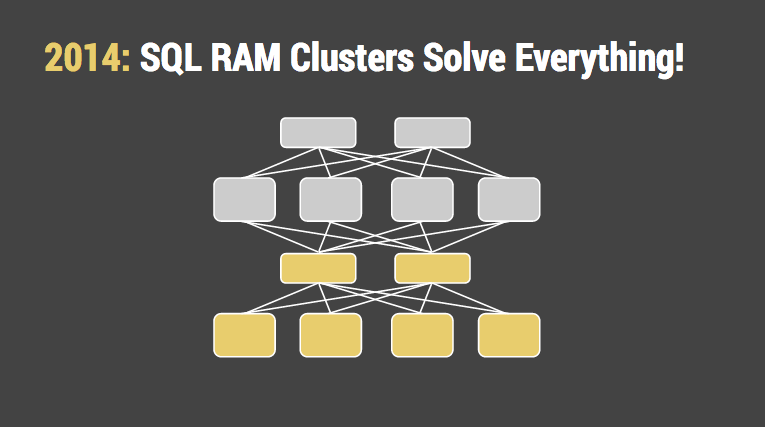



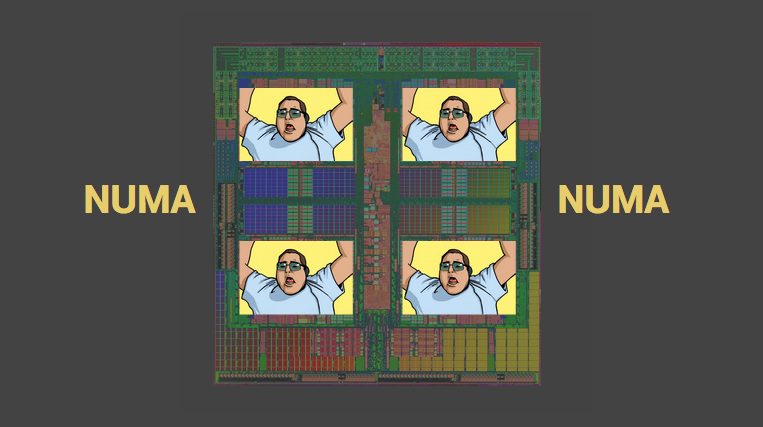
事实上数据库性能的关键常常是内存和磁盘之间的延迟。我们自己开玩笑说 CPU 缓存和内存的延迟不是一类问题。但是的确是。



好消息是分布式数据库物理结构基本成型,数据客户端不再需要处理 4 个或 5 个独立的子系统内部细节。这还不完美,甚至也不是主流,但突破总是需要一些时间来取得。
但如果下一次瓶颈是内存局部性,这意味着其余部分已趋于成熟,新的创新将倾向于数据结构与算法。也很少会有清理架构的改动来承诺一次解决全部问题。如果我们幸运,接下来15年,SQL 数据库会慢慢变得更快更高效,而 API 却是相同的。
但话又说回来,我们这个行业从来没有安静过。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









