






【GaussDB】在duckdb中查询GaussDB的数据
网上好像搜不到openGauss/GaussDB和duckdb配合使用的例子,我就自己来测了下。
环境说明
本文使用的数据库版本
duckdb 1.4.1
GaussDB 5.0.6.0.0 SPC0100
均在同一台虚拟机上,使用的CPU是:
[root@ky10-sp3 linux_amd64]# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 45 bits physical, 48 bits virtual
CPU(s): 8
On-line CPU(s) list: 0-7
Thread(s) per core: 1
Core(s) per socket: 2
Socket(s): 4
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 158
Model name: Intel(R) CC150 CPU @ 3.50GHz
Stepping: 13
CPU MHz: 3504.000
BogoMIPS: 7008.00
Hypervisor vendor: xxx
Virtualization type: full
L1d cache: 256 KiB
L1i cache: 256 KiB
L2 cache: 2 MiB
L3 cache: 64 MiB
NUMA node0 CPU(s): 0-7
Vulnerability Itlb multihit: KVM: Vulnerable
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Vulnerable: Clear CPU buffers attempted, no microcode; SMT Host state unknown
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, IBRS_FW, STIBP disabled, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Unknown: Dependent on hypervisor status
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp
lm constant_tsc arch_perfmon nopl xtopology tsc_reliable nonstop_tsc cpuid pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic
movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single ssbd ibrs ibpb stibp
fsgsbase tsc_adjust bmi1 avx2 smep bmi2 invpcid rdseed adx smap clflushopt xsaveopt xsavec xgetbv1 xsaves arat md_clear flush_l1d
arch_capabilities
注意:因为使用的是postgres_scanner,且原版是打包了postgresql的libpq,因此GaussDB的密码验证方式要改成md5 (password_encryption_type=1 和 hba配置)。如果要连接openGauss及MogDB等基于openGauss的数据库也是一样的,这个不再赘述。
安装duckdb并安装postgres_scanner插件
在线安装
[root@ky10-sp3 duckdb-demo]# curl https://install.duckdb.org | sh
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 3507 100 3507 0 0 4179 0 --:--:-- --:--:-- --:--:-- 4175
https://install.duckdb.org/v1.4.1/duckdb_cli-linux-amd64.gz
*** DuckDB Linux/MacOS installation script, version 1.4.1 ***
.;odxdl,
.xXXXXXXXXKc
0XXXXXXXXXXXd cooo:
,XXXXXXXXXXXXK OXXXXd
0XXXXXXXXXXXo cooo:
.xXXXXXXXXKc
.;odxdl,
######################################################################## 100.0%
Successfully installed DuckDB binary to /root/.duckdb/cli/1.4.1/duckdb
with a link from /root/.duckdb/cli/latest/duckdb
Hint: Append the following line to your shell profile:
export PATH='/root/.duckdb/cli/latest':$PATH
To launch DuckDB now, type
/root/.duckdb/cli/latest/duckdb
[root@ky10-sp3 duckdb-demo]#
其实duckdb发行产物本质上是个数据库客户端(但集成了管理功能),这里我安装的是cli工具,即命令行工具。官方这个命令把可执行程序存放在了/root/.duckdb/cli/latest/duckdb,
直接启动这个客户端,默认是创建了一个内存数据库,直接就能执行SQL了
[root@ky10-sp3 linux_amd64]# /root/.duckdb/cli/latest/duckdb
DuckDB v1.4.1 (Andium) b390a7c376
Enter ".help" for usage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database.
D select 1;
┌───────┐
│ 1 │
│ int32 │
├───────┤
│ 1 │
└───────┘
在duckdb内存库里,安装postgres_scanner插件,并且连接到gaussdb,将这个连接的库命名成db
INSTALL postgres_scanner;
ATTACH 'dbname=testdb user=admin password=gauss@123 host=192.168.1.131 port=8000 ' AS db (TYPE postgres, READ_ONLY);
测试查询gaussdb里的表
报错了
> select * from db.sys.dual
SQL 错误: IO Error: Postgres scanner - out of buffer in ReadInteger
用postgres_query查也是相同的报错
SELECT * FROM postgres_query('db', 'select * from sys.dual');
但是用postgres_execute则不报错,不过这种调用方式只返回成功/失败/报错,不会返回查询的结果
CALL postgres_execute('db', ' select * from sys.dual');
开始分析问题:
克隆了源码,找到了"out of buffer in ReadInteger",
inline T ReadInteger() {
if (buffer_ptr + sizeof(T) > end) {
throw IOException("Postgres scanner - out of buffer in ReadInteger");
}
return ReadIntegerUnchecked<T>();
}
让Copilot分析了下
Dark-Athena: 用中文说下 “buffer_ptr + sizeof(T) > end” 这个代码具体是什么意思
GitHub Copilot: 正在解析这行表达式并用中文说明它的含义。
buffer_ptr + sizeof(T) > end的意思是:把当前缓冲区指针buffer_ptr再往前移动sizeof(T)个字节之后,如果位置超过了缓冲区结尾end,就说明剩余可读数据不足以读取一个类型T的完整值。换句话说,这个判断是在确认缓冲区里是否还保有足够的字节可以安全地读取一个T类型的数据,避免越界访问。Dark-Athena: 我在使用duckdb的postgres_scanner插件访问openGauss数据库中的表,我发现postgres_execute都是可以执行成功的,但是postgres_query都会执行报错,报错都是“Postgres scanner - out of buffer in ReadInteger”,我猜测可能是openGauss返回的数据格式可能和postgresql存在一些差异,你知道具体差异在哪么?
GitHub Copilot: 注意到你是在
postgres_query路径上碰到"Postgres scanner - out of buffer in ReadInteger"。这个路径会改写查询成COPY (SELECT …) TO STDOUT WITH (FORMAT binary)并且用PostgresBinaryReader逐字段解析 Postgres 二进制 COPY 流;而postgres_execute只走普通文本协议,所以没问题。反常点在于:openGauss 对外虽然兼容很多 libpq 协议,但它的
COPY … FORMAT binary并没有遵循 PostgreSQL 的字节布局——它实际返回的还是文本编码(对 bool、int、timestamp 等类型都会以字符串形式写出),只是给客户端照旧标记了“二进制格式”。DuckDB 这边看到 format=1 就会按 PostgreSQL 规范,试图用ReadInteger<uint32_t>()、ReadInteger<uint64_t>()去读固定字节;可字段里只有"2024-01-01"这样的若干字符,于是读到行末就触发了buffer_ptr + sizeof(T) > end这条越界检查,从而抛出你看到的异常。总结一下关键差异:
- 协议层差异:openGauss 的
CopyData报文里没有使用 PostgreSQL 规定的二进制布局,而是仍旧发送 UTF‑8 文本,却把字段格式码设置成 1(binary)。这违反了 DuckDBpostgres_binary_reader.hpp中的假设。- 触发条件:任何走到 binary-copy fast path 的查询(
postgres_query、postgres_scan等)在读取第一个需要固定字节长度的字段时都会报错。- 旁证:如果抓包或在 psql/libpq 中请求
COPY … FORMAT binary,你会看到 openGauss 返回的 payload 仍是一串可读文本;而在 PostgreSQL 下则是固定字节结构。想要规避这个问题,有两个思路:
- 强制切回文本 COPY:在 DuckDB 里把 Postgres 扩展的二进制 fast path 关掉(例如设置扩展参数
SET postgres_binary_transfer = false;,或在连接时加binary_transfer=false,具体依据扩展版本提供的选项),让postgres_query回到与postgres_execute相同的文本解析途径。- 补充兼容层:如果必须走 openGauss 的 binary 输出,就得在 DuckDB 侧编写专门的 reader,按 openGauss 的实际格式解析;不过目前 openGauss 并没有公开一套稳定的二进制协议规范,因此不建议这么做。
因此,这个异常确实来源于 openGauss 在“二进制” COPY 上与 PostgreSQL 的差异:它报告的是 binary,但发送的仍是文本,所以 DuckDB 的二进制解码器会读到缓冲区末尾而抛出 “out of buffer”。
AI 的思路是对的,但是参数名称给错了,不过因为源码很少,肉眼扫了一下源码,很快就找到了一个这样的判断
if (!reader) {
if (bind_data.use_text_protocol) {
reader = make_uniq<PostgresTextReader>(context, connection, column_ids, bind_data);
} else {
reader = make_uniq<PostgresBinaryReader>(connection, column_ids, bind_data);
}
}
然后找 use_text_protocol,就得到了
config.AddExtensionOption("pg_use_text_protocol",
"Whether or not to use TEXT protocol to read data. This is slower, but provides better "
"compatibility with non-Postgres systems",
LogicalType::BOOLEAN, Value::BOOLEAN(false));
看到这个备注真是呵呵哒了,瞅了下pr,是为了支持AWS Redshift,2025年6月份合入的,还算新鲜
Add support for text protocol #335
Please add support for AWS Redshift (based on PostgreSQL 8.0.2) #181
这个参数在duckdb官方文档上还没看到(20251021)
https://duckdb.org/docs/stable/core_extensions/postgres#settings
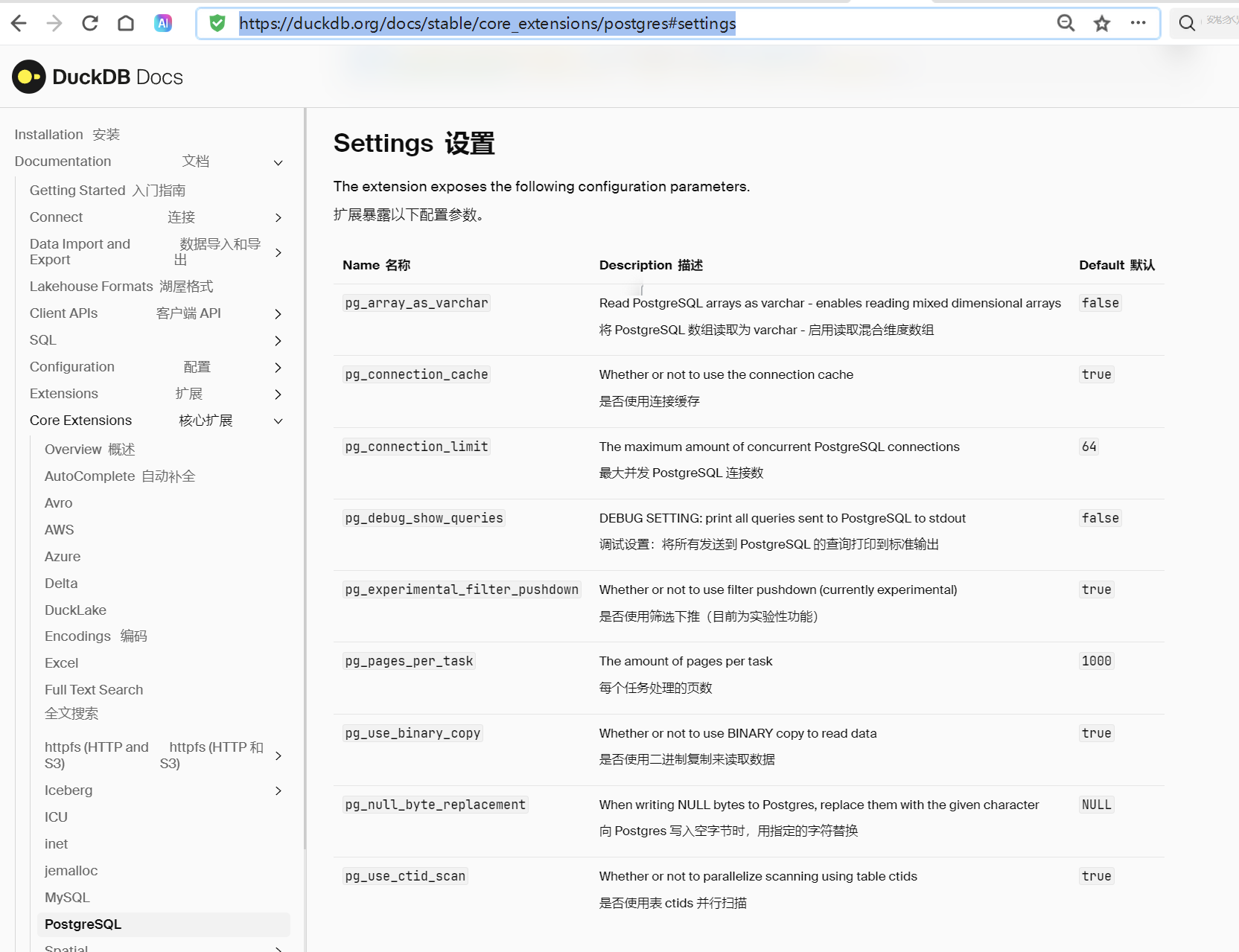
设置一下参数再查询,的确可以了
set pg_use_text_protocol=true;
> select * from db.sys.dual
dummy|
-----+
X |
1 row(s) fetched.
构造应用场景
可能有人要问,弄这个有啥用?下面我用AI造了一个比较经典的业务场景,模拟仓库间调拨的批次库存分摊逻辑。200个分仓向中心仓发起调拨申请,按分仓申请的先到先得和中心仓库存批次先进先出的原则进行分配。
表结构
-- 机构表
drop table if exists organization cascade;
CREATE TABLE IF NOT EXISTS organization (
org_code VARCHAR(10) PRIMARY KEY, -- 机构编码
org_name VARCHAR(100), -- 机构名称
org_type VARCHAR(10) -- 机构类型:CENTER(中心仓), BRANCH(分仓)
);
-- 库存表(批次库存)
drop table if exists inventory cascade;
CREATE TABLE IF NOT EXISTS inventory (
id BIGINT PRIMARY KEY, -- 主键ID
org_code VARCHAR(10), -- 机构编码
product_code VARCHAR(20), -- 商品编码
batch_no VARCHAR(8), -- 批次号(YYYYMMDD格式)
quantity DECIMAL(18, 2), -- 库存数量
FOREIGN KEY (org_code) REFERENCES organization(org_code)
);
-- 创建索引以提升查询性能
CREATE INDEX IF NOT EXISTS idx_inventory_org ON inventory(org_code);
CREATE INDEX IF NOT EXISTS idx_inventory_product ON inventory(product_code);
CREATE INDEX IF NOT EXISTS idx_inventory_batch ON inventory(batch_no);
-- 调拨需求单表
drop table if exists transfer_order cascade;
CREATE TABLE IF NOT EXISTS transfer_order (
order_id VARCHAR(32) PRIMARY KEY, -- 需求单号
order_seq INTEGER, -- 需求单顺序号(用于先到先得)
from_org_code VARCHAR(10), -- 调出机构编码
to_org_code VARCHAR(10), -- 调入机构编码
product_code VARCHAR(20), -- 商品编码
demand_quantity DECIMAL(18, 2), -- 需求数量
order_status VARCHAR(20), -- 订单状态:PENDING(待处理)、FULFILLED(已满足)、REJECTED(已拒绝)
allocated_quantity DECIMAL(18, 2), -- 实际分配数量
FOREIGN KEY (from_org_code) REFERENCES organization(org_code),
FOREIGN KEY (to_org_code) REFERENCES organization(org_code)
);
-- 创建索引
CREATE INDEX IF NOT EXISTS idx_transfer_order_seq ON transfer_order(order_seq);
CREATE INDEX IF NOT EXISTS idx_transfer_order_product ON transfer_order(product_code);
数据构造:
package com.demo.service;
import com.demo.model.Inventory;
import com.demo.model.Organization;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.math.BigDecimal;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
/**
* 数据初始化服务
*/
public class DataInitService {
private static final Logger logger = LoggerFactory.getLogger(DataInitService.class);
// 配置常量
private static final String CENTER_ORG_CODE = "100";
private static final int BRANCH_START = 101;
private static final int BRANCH_COUNT = 200;
private static final int PRODUCT_START = 10001;
private static final int PRODUCT_COUNT = 10000;
// 批次配置:2000个商品各有1-5个批次
private static final int PRODUCTS_PER_BATCH_GROUP = 2000;
// 使用固定种子确保可重复性
private static final long SEED = 12345L;
private final Random random = new Random(SEED);
/**
* 初始化所有数据
*/
public void initializeAllData(Connection conn) throws SQLException {
logger.info("开始初始化数据...");
// 清空已有数据
clearAllData(conn);
// 初始化机构
initOrganizations(conn);
// 初始化中心仓库存
initCenterInventory(conn);
logger.info("数据初始化完成");
}
/**
* 清空所有数据表
*/
private void clearAllData(Connection conn) throws SQLException {
logger.info("清空已有数据...");
try (PreparedStatement stmt = conn.prepareStatement("truncate table allocation_result")) {
stmt.executeUpdate();
}
try (PreparedStatement stmt = conn.prepareStatement("truncate table transfer_order")) {
stmt.executeUpdate();
}
try (PreparedStatement stmt = conn.prepareStatement("truncate table inventory")) {
stmt.executeUpdate();
}
try (PreparedStatement stmt = conn.prepareStatement("truncate table organization")) {
stmt.executeUpdate();
}
}
/**
* 初始化机构数据:1个中心仓 + 200个分仓
*/
private void initOrganizations(Connection conn) throws SQLException {
logger.info("初始化机构数据...");
List<Organization> organizations = new ArrayList<>();
// 中心仓
organizations.add(new Organization(CENTER_ORG_CODE, "中心仓库", "CENTER"));
// 200个分仓
for (int i = 0; i < BRANCH_COUNT; i++) {
String code = String.valueOf(BRANCH_START + i);
organizations.add(new Organization(code, "分仓-" + code, "BRANCH"));
}
// 批量插入
String sql = "INSERT INTO organization (org_code, org_name, org_type) VALUES (?, ?, ?)";
try (PreparedStatement pstmt = conn.prepareStatement(sql)) {
for (Organization org : organizations) {
pstmt.setString(1, org.getOrgCode());
pstmt.setString(2, org.getOrgName());
pstmt.setString(3, org.getOrgType());
pstmt.addBatch();
}
pstmt.executeBatch();
}
logger.info("机构初始化完成: {} 个机构", organizations.size());
}
/**
* 初始化中心仓库存
* 10000个商品,30000个批次记录
* 2000个商品各有1个批次,2000个商品各有2个批次,依此类推到5个批次
*/
private void initCenterInventory(Connection conn) throws SQLException {
logger.info("初始化中心仓库存...");
List<Inventory> inventories = new ArrayList<>();
long idCounter = 1;
// 生成批次号的基础日期(从2023年1月1日开始)
int baseDate = 20230101;
for (int batchGroup = 1; batchGroup <= 5; batchGroup++) {
// 每组2000个商品
int startProduct = PRODUCT_START + (batchGroup - 1) * PRODUCTS_PER_BATCH_GROUP;
int endProduct = startProduct + PRODUCTS_PER_BATCH_GROUP;
for (int productCode = startProduct; productCode < endProduct; productCode++) {
// 该商品有 batchGroup 个批次
for (int batchIdx = 0; batchIdx < batchGroup; batchIdx++) {
// 批次号:基础日期 + 批次索引 * 30天(模拟不同日期)
String batchNo = String.valueOf(baseDate + batchIdx * 30);
// 每个批次的库存量:使用固定算法确保可重复性
// 基础量100 + 根据商品编码和批次索引计算的偏移量
int baseQuantity = 100;
int offset = ((productCode * 7 + batchIdx * 11) % 200);
BigDecimal quantity = BigDecimal.valueOf(baseQuantity + offset);
Inventory inv = new Inventory(
idCounter++,
CENTER_ORG_CODE,
String.valueOf(productCode),
batchNo,
quantity
);
inventories.add(inv);
}
}
}
// 批量插入
String sql = "INSERT INTO inventory (id, org_code, product_code, batch_no, quantity) " +
"VALUES (?, ?, ?, ?, ?)";
try (PreparedStatement pstmt = conn.prepareStatement(sql)) {
for (Inventory inv : inventories) {
pstmt.setLong(1, inv.getId());
pstmt.setString(2, inv.getOrgCode());
pstmt.setString(3, inv.getProductCode());
pstmt.setString(4, inv.getBatchNo());
pstmt.setBigDecimal(5, inv.getQuantity());
pstmt.addBatch();
// 每1000条提交一次
if (inventories.indexOf(inv) % 1000 == 0) {
pstmt.executeBatch();
}
}
pstmt.executeBatch();
}
logger.info("中心仓库存初始化完成: {} 条记录", inventories.size());
// 验证总库存
verifyTotalInventory(conn);
}
/**
* 验证并记录总库存
*/
private void verifyTotalInventory(Connection conn) throws SQLException {
String sql = "SELECT COUNT(*) as count, SUM(quantity) as total FROM inventory WHERE org_code = ?";
try (PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setString(1, CENTER_ORG_CODE);
var rs = pstmt.executeQuery();
if (rs.next()) {
long count = rs.getLong("count");
BigDecimal total = rs.getBigDecimal("total");
logger.info("中心仓库存统计 - 记录数: {}, 总数量: {}", count, total);
}
}
}
}
package com.demo.service;
import com.demo.model.TransferOrder;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.math.BigDecimal;
import java.math.RoundingMode;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.*;
/**
* 调拨需求生成服务
*/
public class TransferOrderService {
private static final Logger logger = LoggerFactory.getLogger(TransferOrderService.class);
private static final String CENTER_ORG_CODE = "100";
private static final int BRANCH_START = 101;
private static final int BRANCH_COUNT = 200;
// 使用固定种子确保可重复性
private static final long SEED = 54321L;
private final Random random = new Random(SEED);
/**
* 生成调拨需求单
* 策略:每个分仓产生多个需求单,总需求量大于中心仓总库存(约120%)
*/
public void generateTransferOrders(Connection conn) throws SQLException {
logger.info("开始生成调拨需求单...");
// 清空已有的调拨单
clearTransferOrders(conn);
// 获取中心仓所有商品的库存信息
Map<String, BigDecimal> productInventory = getProductInventory(conn);
logger.info("中心仓共有 {} 种商品", productInventory.size());
// 生成调拨需求单(总需求量约为库存的120%)
List<TransferOrder> orders = generateOrders(productInventory);
// 插入数据库
insertOrders(conn, orders);
logger.info("调拨需求单生成完成: {} 个需求单", orders.size());
// 验证总需求量
verifyTotalDemand(conn, productInventory);
}
/**
* 清空调拨需求单
*/
private void clearTransferOrders(Connection conn) throws SQLException {
try (PreparedStatement stmt = conn.prepareStatement("DELETE FROM transfer_order")) {
stmt.executeUpdate();
}
}
/**
* 获取中心仓每个商品的总库存
*/
private Map<String, BigDecimal> getProductInventory(Connection conn) throws SQLException {
Map<String, BigDecimal> inventory = new HashMap<>();
String sql = "SELECT product_code, SUM(quantity) as total " +
"FROM inventory WHERE org_code = ? " +
"GROUP BY product_code";
try (PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setString(1, CENTER_ORG_CODE);
ResultSet rs = pstmt.executeQuery();
while (rs.next()) {
String productCode = rs.getString("product_code");
BigDecimal total = rs.getBigDecimal("total");
inventory.put(productCode, total);
}
}
return inventory;
}
/**
* 生成调拨需求单
* 策略:
* 1. 将每个商品的库存分配给随机的分仓
* 2. 每个分仓可以有多个需求单(针对不同商品)
* 3. 总需求量约为总库存的120%(让需求大于供应)
*/
private List<TransferOrder> generateOrders(Map<String, BigDecimal> productInventory) {
List<TransferOrder> orders = new ArrayList<>();
int orderSeq = 1;
// 将所有商品打乱顺序
List<String> products = new ArrayList<>(productInventory.keySet());
Collections.shuffle(products, random);
// 为每个商品生成调拨需求
for (String productCode : products) {
BigDecimal totalQuantity = productInventory.get(productCode);
// 将需求量设置为库存的120%
BigDecimal targetDemand = totalQuantity.multiply(BigDecimal.valueOf(1.2));
BigDecimal remainingDemand = targetDemand;
// 随机决定这个商品会被分配给几个分仓(1-6个)
int branchCount = 1 + random.nextInt(6);
for (int i = 0; i < branchCount; i++) {
// 随机选择一个分仓
int branchCode = BRANCH_START + random.nextInt(BRANCH_COUNT);
BigDecimal demandQuantity;
if (i == branchCount - 1) {
// 最后一个分仓,分配剩余所有数量
demandQuantity = remainingDemand;
} else {
// 随机分配一部分(10%-50%的剩余量)
double ratio = 0.1 + random.nextDouble() * 0.4;
demandQuantity = remainingDemand.multiply(BigDecimal.valueOf(ratio))
.setScale(2, RoundingMode.DOWN);
// 确保至少分配1
if (demandQuantity.compareTo(BigDecimal.ONE) < 0) {
demandQuantity = BigDecimal.ONE;
}
// 确保不会超过剩余量
if (demandQuantity.compareTo(remainingDemand) > 0) {
demandQuantity = remainingDemand;
}
}
remainingDemand = remainingDemand.subtract(demandQuantity);
// 生成需求单号
String orderId = String.format("TO%08d", orderSeq);
TransferOrder order = new TransferOrder(
orderId,
orderSeq,
CENTER_ORG_CODE,
String.valueOf(branchCode),
productCode,
demandQuantity
);
orders.add(order);
orderSeq++;
// 如果剩余量为0,提前结束
if (remainingDemand.compareTo(BigDecimal.ZERO) <= 0) {
break;
}
}
}
// 按订单序号排序(模拟先到先得)
orders.sort(Comparator.comparing(TransferOrder::getOrderSeq));
return orders;
}
/**
* 批量插入调拨需求单
*/
private void insertOrders(Connection conn, List<TransferOrder> orders) throws SQLException {
String sql = "INSERT INTO transfer_order (order_id, order_seq, from_org_code, to_org_code, product_code, demand_quantity, order_status, allocated_quantity) " +
"VALUES (?, ?, ?, ?, ?, ?, ?, ?)";
try (PreparedStatement pstmt = conn.prepareStatement(sql)) {
for (TransferOrder order : orders) {
pstmt.setString(1, order.getOrderId());
pstmt.setInt(2, order.getOrderSeq());
pstmt.setString(3, order.getFromOrgCode());
pstmt.setString(4, order.getToOrgCode());
pstmt.setString(5, order.getProductCode());
pstmt.setBigDecimal(6, order.getDemandQuantity());
pstmt.setString(7, "PENDING");
pstmt.setBigDecimal(8, BigDecimal.ZERO);
pstmt.addBatch();
// 每1000条提交一次
if (orders.indexOf(order) % 1000 == 0) {
pstmt.executeBatch();
}
}
pstmt.executeBatch();
}
}
/**
* 验证总需求量是否大于总库存
*/
private void verifyTotalDemand(Connection conn, Map<String, BigDecimal> productInventory) throws SQLException {
// 计算总库存
BigDecimal totalInventory = productInventory.values().stream()
.reduce(BigDecimal.ZERO, BigDecimal::add);
// 计算总需求
String sql = "SELECT SUM(demand_quantity) as total FROM transfer_order";
BigDecimal totalDemand = BigDecimal.ZERO;
try (PreparedStatement pstmt = conn.prepareStatement(sql)) {
ResultSet rs = pstmt.executeQuery();
if (rs.next()) {
totalDemand = rs.getBigDecimal("total");
}
}
logger.info("总库存: {}, 总需求: {}", totalInventory, totalDemand);
if (totalDemand.compareTo(totalInventory) > 0) {
BigDecimal shortage = totalDemand.subtract(totalInventory);
double shortagePercent = shortage.divide(totalInventory, 4, RoundingMode.HALF_UP)
.multiply(BigDecimal.valueOf(100)).doubleValue();
logger.info(String.format("✓ 验证通过: 总需求大于总库存,缺口: %s (%.2f%%)",
shortage, shortagePercent));
} else {
logger.warn("验证失败: 总需求应该大于总库存");
}
}
}
这种分摊逻辑比较常见的就是用两个游标去循环,中间去判断批次够不够,不够就再减下一个批次,但是需要执行大量的判断和update sql。其实这种逻辑用一个SQL查询就能完成,即构造笛卡尔积使用分析函数滑动窗口
WITH ordered_demand AS (
-- 获取所有需求单,按顺序排序
SELECT
order_id,
order_seq,
from_org_code,
to_org_code,
product_code,
demand_quantity,
SUM(demand_quantity) OVER (
PARTITION BY product_code
ORDER BY order_seq
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS cumulative_demand,
SUM(demand_quantity) OVER (
PARTITION BY product_code
ORDER BY order_seq
ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING
) AS prev_cumulative_demand
FROM transfer_order
),
ordered_inventory AS (
-- 获取所有库存,按批次号排序(FIFO)
SELECT
org_code,
product_code,
batch_no,
quantity,
SUM(quantity) OVER (
PARTITION BY product_code
ORDER BY batch_no
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS cumulative_supply,
SUM(quantity) OVER (
PARTITION BY product_code
ORDER BY batch_no
ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING
) AS prev_cumulative_supply
FROM inventory
WHERE org_code = '100'
),
matched_allocation AS (
-- 匹配需求和供应
SELECT
d.order_id,
d.from_org_code,
d.to_org_code,
d.product_code,
i.batch_no,
-- 计算分配数量
CASE
-- 如果这个批次的累计供应量 <= 之前需求的累计量,说明这个批次已被之前的需求消耗完
WHEN COALESCE(i.cumulative_supply, 0) <= COALESCE(d.prev_cumulative_demand, 0) THEN 0
-- 如果这个批次的起始供应量 >= 当前需求的累计量,说明这个批次还没轮到当前需求
WHEN COALESCE(i.prev_cumulative_supply, 0) >= d.cumulative_demand THEN 0
-- 正常分配情况
ELSE
LEAST(
-- 当前需求还需要的量
d.cumulative_demand - GREATEST(COALESCE(d.prev_cumulative_demand, 0), COALESCE(i.prev_cumulative_supply, 0)),
-- 当前批次还剩余的量
i.cumulative_supply - GREATEST(COALESCE(d.prev_cumulative_demand, 0), COALESCE(i.prev_cumulative_supply, 0))
)
END AS allocated_quantity
FROM ordered_demand d
INNER JOIN ordered_inventory i ON d.product_code = i.product_code
)
SELECT
ROW_NUMBER() OVER () AS id,
order_id,
from_org_code,
to_org_code,
product_code,
batch_no,
allocated_quantity
FROM matched_allocation
WHERE allocated_quantity > 0
ORDER BY order_id, batch_no;
测试复杂SQL
测试gaussdb执行时长
id | operation | A-time | A-rows | E-rows | Peak Memory | A-width | E-width | E-costs
----+-------------------------------------------------+---------+--------+---------+-------------+---------+---------+------------------------
1 | -> Sort | 644.745 | 53329 | 1741600 | 9889KB | | 378 | 776717.987..781071.987
2 | -> WindowAgg | 580.841 | 53329 | 1741600 | 53KB | | 378 | 975.000..165033.720
3 | -> Hash Join (4,9) | 464.150 | 53329 | 1741600 | 53KB | | 378 | 975.000..125847.720
4 | -> CTE Scan on ordered_demand d | 185.528 | 34832 | 34832 | 5923KB | | 280 | 0.000..696.640
5 | -> WindowAgg [4, CTE ordered_demand] | 158.732 | 34832 | 34832 | 1398KB | | 35 | 3270.068..4576.268
6 | -> WindowAgg | 103.591 | 34832 | 34832 | 1394KB | | 35 | 3270.068..3966.708
7 | -> Sort | 41.511 | 34832 | 34832 | 4818KB | | 35 | 3270.068..3357.148
8 | -> Seq Scan on transfer_order | 9.114 | 34832 | 34832 | 38KB | | 35 | 0.000..642.320
9 | -> Hash | 138.386 | 30000 | 30000 | 2097KB | | 156 | 600.000..600.000
10 | -> CTE Scan on ordered_inventory i | 126.452 | 30000 | 30000 | 3084KB | | 156 | 0.000..600.000
11 | -> WindowAgg [10, CTE ordered_inventory] | 104.716 | 30000 | 30000 | 1208KB | | 24 | 2802.901..3927.901
12 | -> WindowAgg | 68.127 | 30000 | 30000 | 1205KB | | 24 | 2802.901..3402.901
13 | -> Sort | 26.521 | 30000 | 30000 | 3599KB | | 24 | 2802.901..2877.901
14 | -> Seq Scan on inventory | 10.443 | 30000 | 30000 | 60KB | | 24 | 0.000..572.000
(14 rows)
Predicate Information (identified by plan id)
-------------------------------------------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------------------------------------------------------------------------
--------------------------------------------------------------------
14 --Seq Scan on inventory
Filter: ((org_code)::text = '100'::text), (Expression Flatten Optimized)
3 --Hash Join (4,9)
Hash Cond: ((d.product_code)::text = (i.product_code)::text), (Expression Flatten Optimized)
Join Filter: (CASE WHEN (COALESCE(i.cumulative_supply, 0::numeric) <= COALESCE(d.prev_cumulative_demand, 0::numeric)) THEN 0::numeric WHEN (COALESCE(i.pre
v_cumulative_supply, 0::numeric) >= d.cumulative_demand) THEN 0::numeric ELSE LEAST((d.cumulative_demand - GREATEST(COALESCE(d.prev_cumulative_demand, 0::numeric),
COALESCE(i.prev_cumulative_supply, 0::numeric))), (i.cumulative_supply - GREATEST(COALESCE(d.prev_cumulative_demand, 0::numeric), COALESCE(i.prev_cumulative_suppl
y, 0::numeric)))) END > 0::numeric), (Expression Flatten Optimized)
Rows Removed by Join Filter: 51276
(6 rows)
Memory Information (identified by plan id)
---------------------------------------------------
1 --Sort
Sort Method: quicksort Memory: 9869kB
7 --Sort
Sort Method: quicksort Memory: 4802kB
13 --Sort
Sort Method: quicksort Memory: 3581kB
Buckets: 32768 Batches: 1 Memory Usage: 1622kB
(7 rows)
====== Query Summary =====
----------------------------------------
Datanode executor start time: 0.344 ms
Datanode executor run time: 648.656 ms
Datanode executor end time: 1.557 ms
Planner runtime: 1.223 ms
Query Id: 14355223812873493
Total runtime: 650.575 ms
(6 rows)
将表复制到duckdb(或者用上面的SQL脚本和JAVA代码连到duckdb重新初始化)
TIPS:
SELECT * FROM XXX可以简化成FROM XXX
ATTACH 'dbname=testdb user=ogadmin password=Mogdb@123 host=192.168.163.131 port=8000 ' AS db (TYPE postgres, READ_ONLY);
set pg_use_text_protocol=true;
create table transfer_order as from db.transfer_order;
create table inventory as from db.inventory;
测试duckdb执行时长
┌─────────────────────────────────────┐
│┌───────────────────────────────────┐│
││ Query Profiling Information ││
│└───────────────────────────────────┘│
└─────────────────────────────────────┘
┌────────────────────────────────────────────────┐
│┌──────────────────────────────────────────────┐│
││ Total Time: 0.0988s ││
│└──────────────────────────────────────────────┘│
└────────────────────────────────────────────────┘
┌───────────────────────────┐
│ QUERY │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ EXPLAIN_ANALYZE │
│ ──────────────────── │
│ 0 rows │
│ (0.00s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ PROJECTION │
│ ──────────────────── │
│ #0 │
│__internal_decompress_strin│
│ g(#1) │
│__internal_decompress_strin│
│ g(#2) │
│__internal_decompress_strin│
│ g(#3) │
│__internal_decompress_strin│
│ g(#4) │
│__internal_decompress_strin│
│ g(#5) │
│ #6 │
│ │
│ 53,329 rows │
│ (0.00s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ ORDER_BY │
│ ──────────────────── │
│ matched_allocation │
│ .order_id ASC │
│ matched_allocation │
│ .batch_no ASC │
│ │
│ 53,329 rows │
│ (0.01s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ PROJECTION │
│ ──────────────────── │
│ #0 │
│__internal_compress_string_│
│ uhugeint(#1) │
│__internal_compress_string_│
│ uinteger(#2) │
│__internal_compress_string_│
│ uinteger(#3) │
│__internal_compress_string_│
│ ubigint(#4) │
│__internal_compress_string_│
│ uhugeint(#5) │
│ #6 │
│ │
│ 53,329 rows │
│ (0.00s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ PROJECTION │
│ ──────────────────── │
│ id │
│ order_id │
│ from_org_code │
│ to_org_code │
│ product_code │
│ batch_no │
│ allocated_quantity │
│ │
│ 53,329 rows │
│ (0.00s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ PROJECTION │
│ ──────────────────── │
│ #0 │
│ #1 │
│ #2 │
│ #3 │
│ #4 │
│ #5 │
│ #6 │
│ │
│ 53,329 rows │
│ (0.00s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ STREAMING_WINDOW │
│ ──────────────────── │
│ Projections: │
│ ROW_NUMBER() OVER () │
│ │
│ 53,329 rows │
│ (0.00s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ PROJECTION │
│ ──────────────────── │
│ order_id │
│ from_org_code │
│ to_org_code │
│ product_code │
│ batch_no │
│ allocated_quantity │
│ │
│ 53,329 rows │
│ (0.00s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ PROJECTION │
│ ──────────────────── │
│ order_id │
│ from_org_code │
│ to_org_code │
│ product_code │
│ batch_no │
│ cumulative_supply │
│ COALESCE │
│ (prev_cumulative_demand, 0│
│ .00) │
│ prev_cumulative_supply │
│ cumulative_demand │
│ │
│ 53,329 rows │
│ (0.00s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ FILTER │
│ ──────────────────── │
│ (CASE WHEN ((COALESCE │
│ (cumulative_supply, 0.00) │
│ <= COALESCE │
│ (prev_cumulative_demand, 0│
│ .00))) THEN (0.00) WHEN ( │
│ (COALESCE │
│ (prev_cumulative_supply, 0│
│ .00) >= cumulative_demand)│
│ ) THEN (0.00) ELSE least( │
│ (cumulative_demand - │
│ greatest(COALESCE │
│ (prev_cumulative_demand, 0│
│ .00), COALESCE │
│ (prev_cumulative_supply, 0│
│ .00))), (cumulative_supply│
│ - greatest(COALESCE │
│ (prev_cumulative_demand, 0│
│ .00), COALESCE │
│ (prev_cumulative_supply, 0│
│ .00)))) END > 0.00) │
│ │
│ 53,329 rows │
│ (0.01s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ HASH_JOIN │
│ ──────────────────── │
│ Join Type: INNER │
│ │
│ Conditions: ├──────────────┐
│product_code = product_code│ │
│ │ │
│ 104,605 rows │ │
│ (0.01s) │ │
└─────────────┬─────────────┘ │
┌─────────────┴─────────────┐┌─────────────┴─────────────┐
│ PROJECTION ││ PROJECTION │
│ ──────────────────── ││ ──────────────────── │
│ order_id ││ product_code │
│ from_org_code ││ batch_no │
│ to_org_code ││ cumulative_supply │
│ product_code ││ prev_cumulative_supply │
│ cumulative_demand ││ │
│ prev_cumulative_demand ││ │
│ ││ │
│ 34,832 rows ││ 30,000 rows │
│ (0.00s) ││ (0.00s) │
└─────────────┬─────────────┘└─────────────┬─────────────┘
┌─────────────┴─────────────┐┌─────────────┴─────────────┐
│ PROJECTION ││ PROJECTION │
│ ──────────────────── ││ ──────────────────── │
│ #0 ││ #0 │
│ #1 ││ #1 │
│ #2 ││ #2 │
│ #3 ││ #3 │
│ #4 ││ #4 │
│ #5 ││ │
│ #6 ││ │
│ #7 ││ │
│ ││ │
│ 34,832 rows ││ 30,000 rows │
│ (0.00s) ││ (0.00s) │
└─────────────┬─────────────┘└─────────────┬─────────────┘
┌─────────────┴─────────────┐┌─────────────┴─────────────┐
│ WINDOW ││ WINDOW │
│ ──────────────────── ││ ──────────────────── │
│ Projections: ││ Projections: │
│ sum(demand_quantity) OVER ││ sum(quantity) OVER │
│ (PARTITION BY product_code││ (PARTITION BY product_code│
│ ORDER BY order_seq ASC ││ ORDER BY batch_no ASC │
│ NULLS LAST ROWS BETWEEN ││ NULLS LAST ROWS BETWEEN │
│ UNBOUNDED PRECEDING AND ││ UNBOUNDED PRECEDING AND │
│ CURRENT ROW) ││ CURRENT ROW) │
│ sum(demand_quantity) OVER ││ sum(quantity) OVER │
│ (PARTITION BY product_code││ (PARTITION BY product_code│
│ ORDER BY order_seq ASC ││ ORDER BY batch_no ASC │
│ NULLS LAST ROWS BETWEEN ││ NULLS LAST ROWS BETWEEN │
│ UNBOUNDED PRECEDING AND 1││ UNBOUNDED PRECEDING AND 1│
│ PRECEDING) ││ PRECEDING) │
│ ││ │
│ 34,832 rows ││ 30,000 rows │
│ (0.03s) ││ (0.04s) │
└─────────────┬─────────────┘└─────────────┬─────────────┘
┌─────────────┴─────────────┐┌─────────────┴─────────────┐
│ TABLE_SCAN ││ TABLE_SCAN │
│ ──────────────────── ││ ──────────────────── │
│ Table: transfer_order ││ Table: inventory │
│ Type: Sequential Scan ││ Type: Sequential Scan │
│ ││ │
│ Projections: ││ Projections: │
│ order_id ││ product_code │
│ order_seq ││ batch_no │
│ from_org_code ││ quantity │
│ to_org_code ││ │
│ product_code ││ Filters: │
│ demand_quantity ││ org_code='100' │
│ ││ │
│ 34,832 rows ││ 30,000 rows │
│ (0.00s) ││ (0.00s) │
└───────────────────────────┘└───────────────────────────┘
Run Time (s): real 0.101 user 0.196882 sys 0.029491
650.575 ms VS 98.8ms
可见这种复杂的分析型SQL在duckdb是具有相当大的优势的,在GaussDB中光进行全表扫描这一步就已经超过了在duckdb中的总执行时间,就算在GaussDB中开启htap功能,对这两张表启用imcv,耗时(596.007 ms)也只减少了一点,相距duckdb仍然远
id | operation | A-time | A-rows | E-rows | Peak Memory | A-width | E-width | E-costs
----+-------------------------------------------------+---------+--------+---------+-------------+---------+---------+------------------------
1 | -> Sort | 590.213 | 53329 | 1741600 | 9881KB | | 378 | 776134.499..780488.499
2 | -> WindowAgg | 532.243 | 53329 | 1741600 | 45KB | | 378 | 975.000..165033.720
3 | -> Hash Join (4,10) | 422.537 | 53329 | 1741600 | 45KB | | 378 | 975.000..125847.720
4 | -> CTE Scan on ordered_demand d | 167.112 | 34832 | 34832 | 5915KB | | 280 | 0.000..696.640
5 | -> WindowAgg [4, CTE ordered_demand] | 143.050 | 34832 | 34832 | 1390KB | | 35 | 2956.580..4262.780
6 | -> WindowAgg | 93.959 | 34832 | 34832 | 1386KB | | 35 | 2956.580..3653.220
7 | -> Sort | 40.688 | 34832 | 34832 | 4810KB | | 35 | 2956.580..3043.660
8 | -> Row Adapter | 8.227 | 34832 | 34832 | 104KB | | 35 | 328.832..328.832
9 | -> Imcv Scan on transfer_order | 2.041 | 34832 | 34832 | 1427KB | | 35 | 0.000..328.832
10 | -> Hash | 123.881 | 30000 | 30000 | 2089KB | | 156 | 600.000..600.000
11 | -> CTE Scan on ordered_inventory i | 113.095 | 30000 | 30000 | 3076KB | | 156 | 0.000..600.000
12 | -> WindowAgg [11, CTE ordered_inventory] | 93.193 | 30000 | 30000 | 1200KB | | 24 | 2532.901..3657.901
13 | -> WindowAgg | 58.251 | 30000 | 30000 | 1197KB | | 24 | 2532.901..3132.901
14 | -> Sort | 19.070 | 30000 | 30000 | 3591KB | | 24 | 2532.901..2607.901
15 | -> Row Adapter | 6.479 | 30000 | 30000 | 77KB | | 24 | 302.000..302.000
16 | -> Imcv Scan on inventory | 2.590 | 30000 | 30000 | 1053KB | | 24 | 0.000..302.000
(16 rows)
Predicate Information (identified by plan id)
-------------------------------------------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------------------------------------------------------------------------
--------------------------------------------------------------------
16 --Imcv Scan on inventory
Filter: ((org_code)::text = '100'::text)
3 --Hash Join (4,10)
Hash Cond: ((d.product_code)::text = (i.product_code)::text), (Expression Flatten Optimized)
Join Filter: (CASE WHEN (COALESCE(i.cumulative_supply, 0::numeric) <= COALESCE(d.prev_cumulative_demand, 0::numeric)) THEN 0::numeric WHEN (COALESCE(i.pre
v_cumulative_supply, 0::numeric) >= d.cumulative_demand) THEN 0::numeric ELSE LEAST((d.cumulative_demand - GREATEST(COALESCE(d.prev_cumulative_demand, 0::numeric),
COALESCE(i.prev_cumulative_supply, 0::numeric))), (i.cumulative_supply - GREATEST(COALESCE(d.prev_cumulative_demand, 0::numeric), COALESCE(i.prev_cumulative_suppl
y, 0::numeric)))) END > 0::numeric), (Expression Flatten Optimized)
Rows Removed by Join Filter: 51276
(6 rows)
Memory Information (identified by plan id)
---------------------------------------------------
1 --Sort
Sort Method: quicksort Memory: 9869kB
7 --Sort
Sort Method: quicksort Memory: 4802kB
14 --Sort
Sort Method: quicksort Memory: 3581kB
Buckets: 32768 Batches: 1 Memory Usage: 1622kB
(7 rows)
User Define Profiling
-----------------------------------------------------------
Plan Node id: 9 Track name: DeltaScan Init
(actual time=[0.023, 0.023], calls=[36, 36])
Plan Node id: 9 Track name: DeltaScan Fill Batch
(actual time=[0.008, 0.008], calls=[1, 1])
Plan Node id: 9 Track name: IMCVScan Run Scan
(actual time=[1.949, 1.949], calls=[36, 36])
Plan Node id: 9 Track name: load CU desc
(actual time=[0.027, 0.027], calls=[36, 36])
Plan Node id: 9 Track name: fill vector batch
(actual time=[1.832, 1.832], calls=[35, 35])
Plan Node id: 9 Track name: get CU data
(actual time=[0.104, 0.104], calls=[175, 175])
Plan Node id: 9 Track name: apply projection and filter
(actual time=[0.026, 0.026], calls=[35, 35])
Plan Node id: 9 Track name: fill later vector batch
(actual time=[0.003, 0.003], calls=[35, 35])
Plan Node id: 16 Track name: DeltaScan Init
(actual time=[0.009, 0.009], calls=[31, 31])
Plan Node id: 16 Track name: DeltaScan Fill Batch
(actual time=[0.007, 0.007], calls=[1, 1])
Plan Node id: 16 Track name: IMCVScan Run Scan
(actual time=[1.058, 1.058], calls=[31, 31])
Plan Node id: 16 Track name: load CU desc
(actual time=[0.016, 0.016], calls=[31, 31])
Plan Node id: 16 Track name: fill vector batch
(actual time=[0.988, 0.988], calls=[30, 30])
Plan Node id: 16 Track name: apply projection and filter
(actual time=[1.491, 1.491], calls=[30, 30])
Plan Node id: 16 Track name: fill later vector batch
(actual time=[0.422, 0.422], calls=[30, 30])
Plan Node id: 16 Track name: get cu data for later read
(actual time=[0.052, 0.052], calls=[90, 90])
(32 rows)
====== Query Summary =====
----------------------------------------
Datanode executor start time: 0.791 ms
Datanode executor run time: 593.755 ms
Datanode executor end time: 1.437 ms
Planner runtime: 1.370 ms
Query Id: 14636698788954457
Total runtime: 596.007 ms
(6 rows)
如果在duckdb里直接使用GaussDB里的表(两个数据库在同一个机器上,不跨网)
┌─────────────────────────────────────┐
│┌───────────────────────────────────┐│
││ Query Profiling Information ││
│└───────────────────────────────────┘│
└─────────────────────────────────────┘
┌────────────────────────────────────────────────┐
│┌──────────────────────────────────────────────┐│
││ Total Time: 0.168s ││
│└──────────────────────────────────────────────┘│
└────────────────────────────────────────────────┘
┌───────────────────────────┐
│ QUERY │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ EXPLAIN_ANALYZE │
│ ──────────────────── │
│ 0 rows │
│ (0.00s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ ORDER_BY │
│ ──────────────────── │
│ matched_allocation │
│ .order_id ASC │
│ matched_allocation │
│ .batch_no ASC │
│ │
│ 53,329 rows │
│ (0.01s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ PROJECTION │
│ ──────────────────── │
│ id │
│ order_id │
│ from_org_code │
│ to_org_code │
│ product_code │
│ batch_no │
│ allocated_quantity │
│ │
│ 53,329 rows │
│ (0.00s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ PROJECTION │
│ ──────────────────── │
│ #0 │
│ #1 │
│ #2 │
│ #3 │
│ #4 │
│ #5 │
│ #6 │
│ │
│ 53,329 rows │
│ (0.00s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ STREAMING_WINDOW │
│ ──────────────────── │
│ Projections: │
│ ROW_NUMBER() OVER () │
│ │
│ 53,329 rows │
│ (0.00s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ PROJECTION │
│ ──────────────────── │
│ order_id │
│ from_org_code │
│ to_org_code │
│ product_code │
│ batch_no │
│ allocated_quantity │
│ │
│ 53,329 rows │
│ (0.00s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ PROJECTION │
│ ──────────────────── │
│ order_id │
│ from_org_code │
│ to_org_code │
│ product_code │
│ batch_no │
│ cumulative_supply │
│ COALESCE │
│ (prev_cumulative_demand, 0│
│ .00) │
│ prev_cumulative_supply │
│ cumulative_demand │
│ │
│ 53,329 rows │
│ (0.00s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ FILTER │
│ ──────────────────── │
│ (CASE WHEN ((COALESCE │
│ (cumulative_supply, 0.00) │
│ <= COALESCE │
│ (prev_cumulative_demand, 0│
│ .00))) THEN (0.00) WHEN ( │
│ (COALESCE │
│ (prev_cumulative_supply, 0│
│ .00) >= cumulative_demand)│
│ ) THEN (0.00) ELSE least( │
│ (cumulative_demand - │
│ greatest(COALESCE │
│ (prev_cumulative_demand, 0│
│ .00), COALESCE │
│ (prev_cumulative_supply, 0│
│ .00))), (cumulative_supply│
│ - greatest(COALESCE │
│ (prev_cumulative_demand, 0│
│ .00), COALESCE │
│ (prev_cumulative_supply, 0│
│ .00)))) END > 0.00) │
│ │
│ 53,329 rows │
│ (0.01s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ HASH_JOIN │
│ ──────────────────── │
│ Join Type: INNER │
│ │
│ Conditions: ├──────────────┐
│product_code = product_code│ │
│ │ │
│ 104,605 rows │ │
│ (0.01s) │ │
└─────────────┬─────────────┘ │
┌─────────────┴─────────────┐┌─────────────┴─────────────┐
│ PROJECTION ││ PROJECTION │
│ ──────────────────── ││ ──────────────────── │
│ order_id ││ product_code │
│ from_org_code ││ batch_no │
│ to_org_code ││ cumulative_supply │
│ product_code ││ prev_cumulative_supply │
│ cumulative_demand ││ │
│ prev_cumulative_demand ││ │
│ ││ │
│ 34,832 rows ││ 30,000 rows │
│ (0.00s) ││ (0.00s) │
└─────────────┬─────────────┘└─────────────┬─────────────┘
┌─────────────┴─────────────┐┌─────────────┴─────────────┐
│ PROJECTION ││ PROJECTION │
│ ──────────────────── ││ ──────────────────── │
│ #0 ││ #0 │
│ #1 ││ #1 │
│ #2 ││ #2 │
│ #3 ││ #3 │
│ #4 ││ #4 │
│ #5 ││ #5 │
│ #6 ││ │
│ #7 ││ │
│ ││ │
│ 34,832 rows ││ 30,000 rows │
│ (0.00s) ││ (0.00s) │
└─────────────┬─────────────┘└─────────────┬─────────────┘
┌─────────────┴─────────────┐┌─────────────┴─────────────┐
│ WINDOW ││ WINDOW │
│ ──────────────────── ││ ──────────────────── │
│ Projections: ││ Projections: │
│ sum(demand_quantity) OVER ││ sum(quantity) OVER │
│ (PARTITION BY product_code││ (PARTITION BY product_code│
│ ORDER BY order_seq ASC ││ ORDER BY batch_no ASC │
│ NULLS LAST ROWS BETWEEN ││ NULLS LAST ROWS BETWEEN │
│ UNBOUNDED PRECEDING AND ││ UNBOUNDED PRECEDING AND │
│ CURRENT ROW) ││ CURRENT ROW) │
│ sum(demand_quantity) OVER ││ sum(quantity) OVER │
│ (PARTITION BY product_code││ (PARTITION BY product_code│
│ ORDER BY order_seq ASC ││ ORDER BY batch_no ASC │
│ NULLS LAST ROWS BETWEEN ││ NULLS LAST ROWS BETWEEN │
│ UNBOUNDED PRECEDING AND 1││ UNBOUNDED PRECEDING AND 1│
│ PRECEDING) ││ PRECEDING) │
│ ││ │
│ 34,832 rows ││ 30,000 rows │
│ (0.03s) ││ (0.05s) │
└─────────────┬─────────────┘└─────────────┬─────────────┘
┌─────────────┴─────────────┐┌─────────────┴─────────────┐
│ TABLE_SCAN ││ TABLE_SCAN │
│ ──────────────────── ││ ──────────────────── │
│ Table: transfer_order ││ Table: inventory │
│ ││ │
│ Projections: ││ Projections: │
│ order_id ││ org_code │
│ order_seq ││ product_code │
│ from_org_code ││ batch_no │
│ to_org_code ││ quantity │
│ product_code ││ │
│ demand_quantity ││ Filters: │
│ ││ org_code='100' │
│ ││ │
│ 34,832 rows ││ 30,000 rows │
│ (0.00s) ││ (0.00s) │
└───────────────────────────┘└───────────────────────────┘
神奇吧,就算是查的GaussDB的数据,这速度比GaussDB自己查还快,竟然也只要168ms。对比了SQL的查询结果,也是一致的(当然这个例子不涉及浮点计算,不能说明所有场景的一致性)。
| duckdb查自己的表 | gaussdb查自己的表 | duckdb查gaussdb的表 | gaussdb查自己的imcv表 |
|---|---|---|---|
| 98.8ms | 650.575 ms | 168ms | 596.007 ms |
测试简单SQL
duckdb性能一定就快么?当然不,如果是TP型业务,客户端和数据库之间有大量交互,GaussDB可能会比duckdb要快。下面仍然是模拟上面的业务场景,只是实现方式改成用两个游标循环逐行判断,执行简单SQL
package com.demo.service;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.math.BigDecimal;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
/**
* JAVA循环执行SQL
* 使用Java + JDBC实现类似存储过程的逻辑,模拟多次交互的性能
*/
public class GaussDBAllocationService {
private static final Logger logger = LoggerFactory.getLogger(GaussDBAllocationService.class);
private static final String CENTER_ORG_CODE = "100";
/**
* 执行库存分配(模拟存储过程的多次数据库交互)
*/
public void allocateInventory(Connection conn) throws SQLException {
logger.info("开始执行GaussDB风格的库存分配(模拟存储过程)...");
long startTime = System.currentTimeMillis();
// 清空分配结果
clearAllocationResults(conn);
// 使用游标风格的逻辑,模拟存储过程
allocateWithCursorStyle(conn);
// 更新需求单状态
updateOrderStatus(conn);
// 更新分仓库存
updateBranchInventory(conn);
long endTime = System.currentTimeMillis();
long duration = endTime - startTime;
logger.info("GaussDB风格库存分配完成,耗时: {} ms", duration);
}
/**
* 获取分配执行时间
*/
public long getAllocationTime(Connection conn) throws SQLException {
long startTime = System.currentTimeMillis();
// 清空分配结果
clearAllocationResults(conn);
// 执行分配
allocateWithCursorStyle(conn);
// 更新需求单状态
updateOrderStatus(conn);
// 更新分仓库存
updateBranchInventory(conn);
long endTime = System.currentTimeMillis();
return endTime - startTime;
}
/**
* 清空分配结果
*/
private void clearAllocationResults(Connection conn) throws SQLException {
try (PreparedStatement stmt = conn.prepareStatement("DELETE FROM allocation_result")) {
stmt.executeUpdate();
}
}
/**
* 使用游标风格进行分配(模拟存储过程的逐行处理)
* 这种方式会产生大量的数据库往返
*/
private void allocateWithCursorStyle(Connection conn) throws SQLException {
long resultId = 1;
// 查询所有需求单(按顺序)
String orderSql = "SELECT order_id, product_code, to_org_code, demand_quantity " +
"FROM transfer_order ORDER BY order_seq";
try (PreparedStatement orderStmt = conn.prepareStatement(orderSql);
ResultSet orderRs = orderStmt.executeQuery()) {
while (orderRs.next()) {
String orderId = orderRs.getString("order_id");
String productCode = orderRs.getString("product_code");
String toOrgCode = orderRs.getString("to_org_code");
BigDecimal demandQuantity = orderRs.getBigDecimal("demand_quantity");
BigDecimal remainingDemand = demandQuantity;
// 为当前需求单分配库存
String inventorySql = "SELECT batch_no, quantity " +
"FROM inventory " +
"WHERE org_code = ? AND product_code = ? AND quantity > 0 " +
"ORDER BY batch_no";
try (PreparedStatement invStmt = conn.prepareStatement(inventorySql)) {
invStmt.setString(1, CENTER_ORG_CODE);
invStmt.setString(2, productCode);
try (ResultSet invRs = invStmt.executeQuery()) {
while (invRs.next() && remainingDemand.compareTo(BigDecimal.ZERO) > 0) {
String batchNo = invRs.getString("batch_no");
BigDecimal availableQuantity = invRs.getBigDecimal("quantity");
// 计算本次分配数量
BigDecimal allocatedQuantity = availableQuantity.compareTo(remainingDemand) >= 0
? remainingDemand
: availableQuantity;
// 插入分配结果(每次都是一次数据库交互)
String insertSql = "INSERT INTO allocation_result " +
"(id, order_id, from_org_code, to_org_code, product_code, batch_no, allocated_quantity) " +
"VALUES (?, ?, ?, ?, ?, ?, ?)";
try (PreparedStatement insertStmt = conn.prepareStatement(insertSql)) {
insertStmt.setLong(1, resultId++);
insertStmt.setString(2, orderId);
insertStmt.setString(3, CENTER_ORG_CODE);
insertStmt.setString(4, toOrgCode);
insertStmt.setString(5, productCode);
insertStmt.setString(6, batchNo);
insertStmt.setBigDecimal(7, allocatedQuantity);
insertStmt.executeUpdate();
}
// 更新中心仓库存(每次都是一次数据库交互)
String updateSql = "UPDATE inventory SET quantity = quantity - ? " +
"WHERE org_code = ? AND product_code = ? AND batch_no = ?";
try (PreparedStatement updateStmt = conn.prepareStatement(updateSql)) {
updateStmt.setBigDecimal(1, allocatedQuantity);
updateStmt.setString(2, CENTER_ORG_CODE);
updateStmt.setString(3, productCode);
updateStmt.setString(4, batchNo);
updateStmt.executeUpdate();
}
// 更新剩余需求
remainingDemand = remainingDemand.subtract(allocatedQuantity);
}
}
}
}
}
logger.info("生成分配结果: {} 条记录", resultId - 1);
}
/**
* 更新需求单状态和实际分配数量
*/
private void updateOrderStatus(Connection conn) throws SQLException {
// 更新已分配的需求单
String updateFulfilledSql = """
UPDATE transfer_order
SET order_status = 'FULFILLED',
allocated_quantity = (
SELECT COALESCE(SUM(allocated_quantity), 0)
FROM allocation_result
WHERE allocation_result.order_id = transfer_order.order_id
)
WHERE order_id IN (
SELECT DISTINCT order_id FROM allocation_result
)
""";
try (PreparedStatement pstmt = conn.prepareStatement(updateFulfilledSql)) {
pstmt.executeUpdate();
}
// 标记未分配的需求单为拒绝
String updateRejectedSql = """
UPDATE transfer_order
SET order_status = 'REJECTED',
allocated_quantity = 0
WHERE order_status = 'PENDING'
""";
try (PreparedStatement pstmt = conn.prepareStatement(updateRejectedSql)) {
pstmt.executeUpdate();
}
}
/**
* 更新分仓库存
*/
private void updateBranchInventory(Connection conn) throws SQLException {
String sql = """
INSERT INTO inventory (id, org_code, product_code, batch_no, quantity)
SELECT
(SELECT COALESCE(MAX(id), 0) FROM inventory) + ROW_NUMBER() OVER () AS id,
to_org_code,
product_code,
batch_no,
SUM(allocated_quantity) AS quantity
FROM allocation_result
GROUP BY to_org_code, product_code, batch_no
""";
try (PreparedStatement pstmt = conn.prepareStatement(sql)) {
int rows = pstmt.executeUpdate();
logger.info("为分仓创建库存记录: {} 条", rows);
}
}
}
| duckdb java循环执行简单SQL | gaussdb java循环执行简单sql |
|---|---|
| 324815 ms | 208174 ms |
不过这个场景受客户端和数据库端之间网络的影响很大,上面这个测试是没有跨网络的,一旦网络环境稍微复杂点,gaussdb执行的时间会成倍增长,也就是说,如果瓶颈在于客户端和数据库间的频繁网络交互,可以尝试把gaussdb的数据拉到应用本地内存的duckdb里,算完再一次性写回gaussdb。不过如果本来网络就差,用于计算的源表数据量又很大,数据查到duckdb里也会很耗时,算完再把数据推回gaussdb,又增加了耗时,还不如在GaussDB里直接用存储过程。所以对于类似TP型的大量频繁简单SQL执行,在通用场景下,还是不建议改成用duckdb。
总结
duckdb本身的定位就是嵌入式分析型数据库,利用内存中的列式存储和向量化查询,简化非常多的算子,以实现高效的复杂SQL查询性能。把一些复杂的分析型的SQL从GaussDB转到duckdb中执行,实测的确能大幅减少执行耗时,不过这毕竟存在数据传输,如果源表数据量极大,那么数据传输的时间仍然是不可忽略的。另外,业务形态若是频繁地执行单行DML,也不适合使用duckdb。
最后贴一下duckdb官网的 为什么选择DuckDB
- 本文作者: DarkAthena
- 本文链接: https://www.darkathena.top/archives/query-gaussdb-with-duckdb
- 版权声明: 本博客所有文章除特别声明外,均采用CC BY-NC-SA 3.0 许可协议。转载请注明出处


















 2979
2979

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











