







线性回归是机器学习算法中最为简单的分类法。一来是学习过线性代数的人都能理解,二来没有复杂的数学处理方式,代码实现起来也比较容易。下面用尽量简单的语言来介绍它到底是个什么概念,以及在什么情况下能够加以使用。
回归分析是一种预测性的建模技术,它是研究自变量(预测器)与因变量(目标)之间的关系。通常使用曲线/线来拟合数据点(也就是回归),使曲线到数据点的距离差异最小。
线性回归只是众多回归问题中的一种,是假设目标值与特征之间线性相关,满足一个多元一次方程。通过构建损失函数,来求解损失函数最小时的参数w和b。通常可以表达为:
![]()
式中,y^为预测值,自变量x和因变量y是已知的,实现y^与y之间的最小差值。为了求解最佳参数,需要一个标准来对结果进行衡量,为此我们需要定量化一个目标函数式,这里在统计学里有个指标是均方误差(mean square error),通过获得预测值与真实值之间的平均的平方距离最小值,那么这个回归就是最有效,最可行的。
针对任何模型求解问题,最终都可以得到一组预测值y^ ,对比已有的真实值 y ,数据组数为 n ,这样就可以将损失函数(均方误差)定义为:
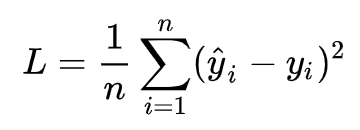
把之前的函数式代入损失函数,并且将需要求解的参数w和b看做是函数L的自变量,可得
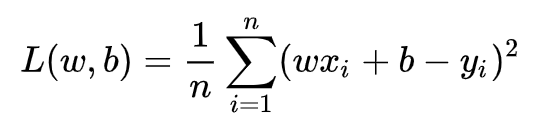
求解最小化L时w和b的值,核心目标优化式为
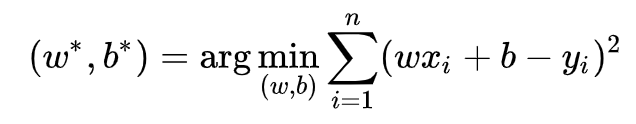
数学上,求解方式有两种:
1)最小二乘法(least square method)
求解 w 和 b 是使损失函数最小化的过程,也称为线性回归模型的最小二乘“参数估计”(parameter estimation),这应该是高等数学里比较常用的方法了。我们可以将 L(w,b) 分别对 w 和 b 求导,得到
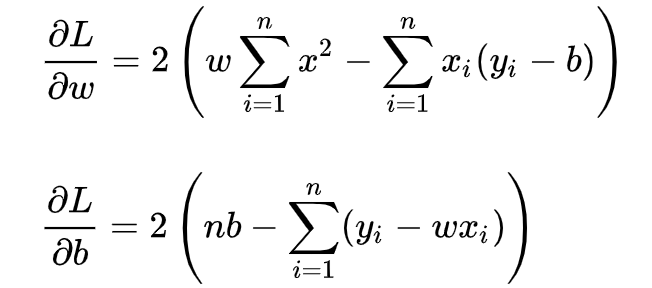
令上述两式为0,可得到 w 和 b 最优解:
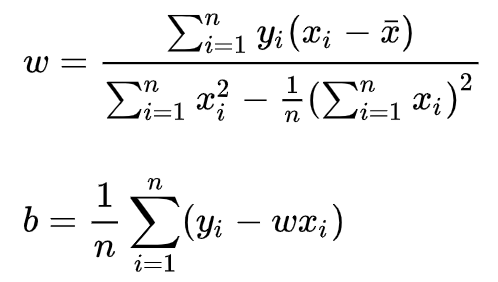
2)梯度下降(gradient descent)
梯度下降核心内容是对自变量进行不断的更新(针对w和b求偏导),使得目标函数不断逼近最小值的过程

这其实是一个不断逼近的过程,每一步朝着最终方向进行微调,最终达到目标值。
以上就是线性回归的全部内容,是不是很简单?没错。那么,代码是如何实现的呢?以梯度下降为例:
import numpy as np
class LinerRegression(object):
def __init__(self, learning_rate=0.01, max_iter=100, seed=None):
np.random.seed(seed)
self.lr = learning_rate
self.max_iter = max_iter
self.w = np.random.normal(1, 0.1)
self.b = np.random.normal(1, 0.1)
self.loss_arr = []
def fit(self, x, y):
self.x = x
self.y = y
for i in range(self.max_iter):
self._train_step()
self.loss_arr.append(self.loss())
# print('loss: \t{:.3}'.format(self.loss()))
# print('w: \t{:.3}'.format(self.w))
# print('b: \t{:.3}'.format(self.b))
def _f(self, x, w, b):
return x * w + b
def predict(self, x=None):
if x is None:
x = self.x
y_pred = self._f(x, self.w, self.b)
return y_pred
def loss(self, y_true=None, y_pred=None):
if y_true is None or y_pred is None:
y_true = self.y
y_pred = self.predict(self.x)
return np.mean((y_true - y_pred)**2)
def _calc_gradient(self):
d_w = np.mean((self.x * self.w + self.b - self.y) * self.x)
d_b = np.mean(self.x * self.w + self.b - self.y)
return d_w, d_b
def _train_step(self):
d_w, d_b = self._calc_gradient()
self.w = self.w - self.lr * d_w
self.b = self.b - self.lr * d_b
return self.w, self.b
regr = LinerRegression(learning_rate=0.01, max_iter=10, seed=314)
regr.fit(x, y)这其中我们需要设定好学习率(learning_rate),以及总的迭代次数(max_iter)。当然,如果你使用sklearn包,里面也有对应的线性回归模块。这样,一个简单的线性回归算法搭建就算完成了,不过具体使用则需要结合实际情况来定。















 725
725











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









