






概要和简介
Google Chrome是为现代互联网用户和占主导地位的网络应用程序而设计的开源的浏览器。浏览器的基本任务包括浏览网页,共享和发送信息,在线存储信息。然而,互联网在不断发展,变得更加动态,更具交互性,浏览器的基准功能也随之不断增强。现代浏览器不仅仅需要加载静态HTML网页,还要处理其它的事情,比如严重依赖Javascript和Flash的视频和应用程序。因此,Google认识到了这一重大需求并为此开发了一个浏览器,它的功能不断完善,始终坚持如下品质:简单、高效、稳定、安全。
Google Chrome提供简单的用户界面。简单性使用户可以以高效、自然的方式进行操作。从而,能够提供良好的用户体验,隐藏底层架构的复杂性,把焦点放在用户的目标和任务上。
Google Chrome多进程的架构使它区别于其它浏览器。每一个tab页面有它自己的进程,并独立于浏览器运行。这样,一个tab进程可以专注于一个单独的web应用,从而提升了浏览器性能。多进程架构是Chrome适应以应用为主的不断增加的复杂性的一个关键因素。例如,当大量对内存要求苛刻的应用共享一个堆时,就会产生性能问题。如果应用有自己的进程和内存池,就不会有这个问题。
多进程架构也使浏览器变得更稳定,因为它提供了隔离机制。一旦一个进程遇到bug崩溃了,浏览器本身和其它并行运行的应用仍然可以继续。从功能上讲,这是相对于其它浏览器的一个改进,因为其它tabs的那些很有价值的信息能够在有页面奔溃是得以保存。
Chrome的开发者很关心安全性。浏览器不断面临着那些利用系统漏洞的攻击者的挑战。Chrome架构使用沙盒原则解决安全问题。这一机制通过限制渲染引擎实例对操作系统的访问来降低它们的特权。
概念模型
推导过程
在我们推导Chrome的概念架构的过程中,我们首先研究了致力于解释Chrome背后的主要目标的资料,包括Google Chrome Book, YouTube视频“The Story Behind Chrome", 维基百科网页,大量的博客和文章,以得到关于它的开发理由的大概理解。这些资料帮助我们了解到Chrome是一种新的浏览器,旨在迎合今天以应用为主的网络。对照而言,以前说到浏览网页,就是显示静态的HTML页面。我们了解到Chrome开发者着手创建在下面四个方面表现卓越的浏览器:性能、可用性、稳定性、安全性。
在我们对Chrome背后的原则有了可靠的理解之后,我们发现Chromium开发者文档,特别是设计文档是最好的确定概念模型的资料。作为一个开源项目,Google的开发者已经创建了很多文档,旨在帮助第三方开发者给Chrome添加功能,以改善Chrome。这是些比较底层的文档,想要从它们推导出概念模型是比较困难的,但这已经是我们能找到的最好的资料了。它们更有助于确定具体的架构和给Chrome添加新功能。
在我们得到最终结果之前,对于Chrome的架构,我们有一些初始的想法。最初,我们觉得Chrome可能是完全面向对象的,在高层对数据进行抽象,广泛使用APIs。之后,我们意识到,在最高层,情况不是这样的。我们还觉得,可能还存在一些不太明显的调用架构,因为要对浏览器UI和网页中的事件进行处理。然而,对进程间通信做深入研究之后,我们对此更加确信了。
最终结果
浏览器参考架构可以很容易映射到Google Chrome的子系统,因为它包含了浏览器领域的所有组件,如图1所示。
然而,在依赖关系方面,Chrome和参考架构有显著不同。我们发现最主要的区别是,Chrome把browser engine和data persistence集成为browser subsystem。此外,网络和渲染引擎彼此不直接进行交互,而是通过browser来沟通。所以,在做进一步研究,并映射了子系统的交互关系之后,我们得出结论,从最宏观的角度来讲,总体的概念模型的确不是严格意义上的层次结构。
不过,当你深入到底层系统的实现细节时,你将会发现由于交互代理耦合导致的object-orientated行为。举个例子,使用JavaScript自动配置代理将耦合V8 JS 引擎和browser。
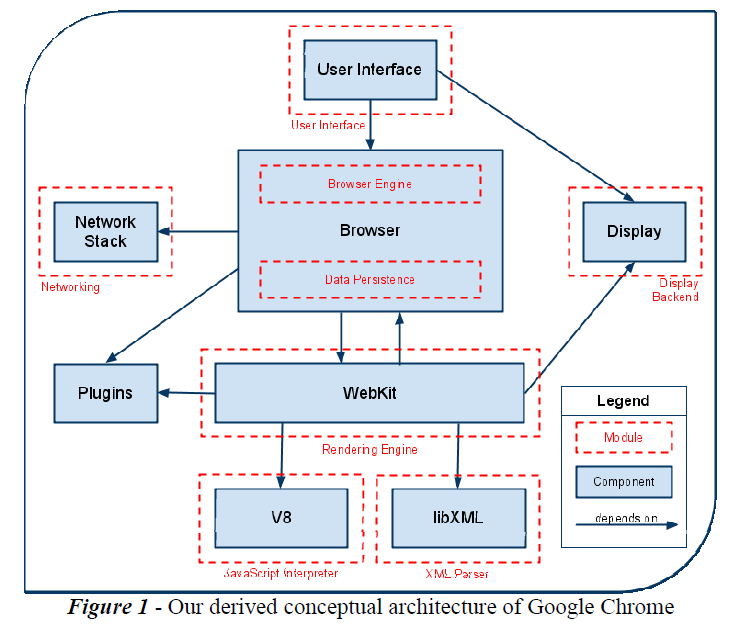
通常,所谓的层次架构是指,使用能够按层次归类的相互区别的服务类的应用所具有的架构。因此,理想情况下,层次结构底层的子系统是不与层次结构中不毗邻的层进行交互的。这样做的优点是子系统的内部改善变得容易的多。此外,无法从一个单独的层次了解到其它更高层次之间的交互和依赖关系。因此,在我们的Chrome架构图中,我们把这些都描绘出来了。浏览器的主要部分包括UI,browser and renderer hierachy。是典型的自上而下依赖的系统。
Chrome的子系统具有很好的内聚性,因为它们的内部实现不直接依赖于其它层,而且它们之间的交互是通过像brower和renderers之间的进程通信器来完成的。因此,得于保留连接器和过程调用的受限可见性。最后,内聚的结果是,层可以被重用。这样,特定层次中具有相同接口的不同实现可以相互替换。例如,可以用另一个JavaScript解释器,比如SpiderMonkey来替换V8,而且还不会对渲染引擎造成重大影响。
子系统功能
我们有了Chrome的高层架构,现在可以开始研究各种不同的组件和它们的功能,以及它们交互的方式了。
用户界面(User Interface)
用户界面是用户明确看到的子系统。它是允许用户访问浏览器功能的那一层,好的用户界面应该是提供用户一种容易理解和使用浏览器的方法。在最高层,UI分为客户端和非客户区域。非客户区域是指用户不能与之交互的区域,通常包括标题栏和窗口边界。
相反的,那些可以交互的元素,例如窗口、按钮、菜单、确认对话框、文本框被归为客户区域。当一个用户与一个客户端区域交互时,一个消息会被传递给browser engine以处理事件。例如,点击“Back”按钮将会请求浏览器获取上次访问的网页,它很可能还在网络缓存中。
Chrome使用自定义UI,没有明显的客户/非客户区域划分。例如,工具条中呈现标签小部件的功能。

Browser
在管理不同的子系统方面,browser是Chrome最核心的组件。the browser负责下列任务:
· 产生新的标签 · 磁盘缓存
· 与网络通信 · Cookie数据库
· 处理用户输入 · 历史数据库
· 窗口管理 · 密码数据库
· 地址栏
在典型的浏览器架构中,渲染引擎拥有对操作系统充分的访问权限,特别是对网络和显示后端。然而,在Chrome中,渲染引擎必须同browser通信才能获得渲染之外的服务。从安全角度看,浏览器保持与用户相同的系统权限。创建渲染引擎实例的同时,the browser也为实例定义安全策略,即定义赋予给渲染引擎的权利。
数据持久化(Data Persitence)
数据持久化定义所有可能超过Chrome运行期的数据,包括如下组件:cookie数据库、历史数据库、密码数据库。数据持久化通过browser实现 -- 大多数情况下是与文件系统通信。不太确切的说包括文件上传和文件下载(file uploads and downloads)。当上传文件时,the browser进程代理访问文件的渲染引擎,使它能够访问文件。一旦渲染引擎实例被关闭,这些被许可文件就不能再访问了,以阻止其它tabs访问这些文件。下载文件时,渲染引擎告诉browser把它们保存在指定目录,这有助于保护文件系统的完整性。
网络 -- Networking(Network Stack)
网络堆栈对Chrome其余部分的依赖很小,它位于browser之外。网络堆栈的既定目标是保持可移植性,并独立于WinInet和WinHTTP。目前为止,网络堆栈已经被Google完全重写了两次。
网络堆栈处理所有URL请求(来自browser),从网络获取资源,还可以请求对结果进行缓存以供将来使用。这个子系统只依赖于Chrome的三个部分:the browser, V8, GoogleURL库。这种低层次的依赖使网络子系统可以很容易的被移植到其它操作系统。线程方面,网络堆栈主要在I/O线程上运行,而且通常是单线程的。
JavaScript解释器(V8)
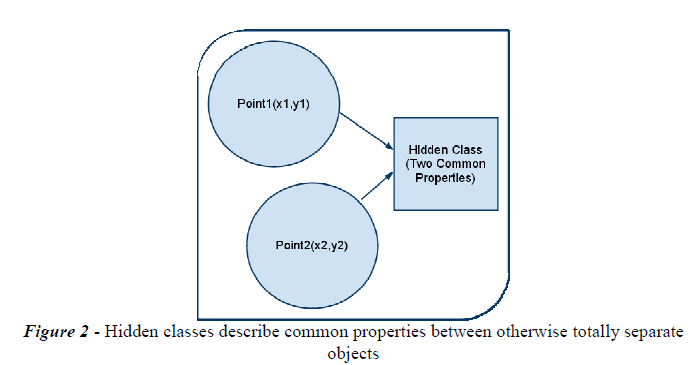
Chrome中的JavaScript解释器是V8, 由在丹麦的Google团队开发,目前作为一个开源项目进行维护。V8与其它JS解释器的不同之处主要在于3个功能点。第一个是隐藏类。通常,在JavaScript中,如果你有两个或多个分离但相似的对象时,它们是不可能共用一个通用结构的。隐藏类就是用于解决这个问题。隐藏类作为一个额外的对象,它声明了其它相互区别的对象之间共用属性的数量(如图2)。V8的第二个独特功能是它把js编译成机器码,而不是解释执行。这提升了JavaScript执行的速度。最后一个功能是V8有精确的垃圾回收。为了在JavaScript与浏览器中的应用交互时提供流畅体验,垃圾回收被设计的很轻巧。
渲染引擎(Webkit)
Webkit是一个用于排版网页的开源项目,来源于Apple。WebKit包括三个部分:WebCore, JavaScriptCore and WebKit(围绕前两部分的API层)。然而,Chrome只用了WebCore部分,所有的JavaScript都由Chrome的V8执行,而且Chrome团队创建了他们自己的“glue"替代API层。WebCore提供服务于Chrome的渲染引擎,处理CSS, DOM, HTML, and XHTML这些网页组件。一个称之为WebKit glue的API用于与渲染器进行通信,同时允许Chromium应用程序使用它自己的编码风格、代码布局、和命名系统(目的在于降低对WebKit的依赖)。
显示后端(views, WTL, Skia & GDI)
显示后端负责3个主要任务:窗体小部件的创建,图形渲染,字体渲染。在我们的概念模型中,我们把这些都归为一个子系统。通过阅读Chromium文档,我们发现这些是由不同的组件来处理的,这些组件基于不同的用户实现还不一样。后面的两个任务 - 图形和前端渲染 - 是显示网页必不可少的。
显示后端由四个组件构成 - views, Windows Template Library, Skia, and GDI。Views 是Chrome用于自定义UI的高层widget框架。WTL是win32程序中用于创建GUI的Microsoft API。GDI是一个过时的Windows渲染器,Chrome只是用它来做Windows系统的文本渲染。Skia是Google的内部图形渲染器,它为出文本外的东西提供高性能的渲染。
当WebKit解析一个网页的HTML时,它会调起显示后端组件来渲染网页内容,这样它才能产生并显示一幅位图。这里,Skia处理图片的绘画,并创建来自某个网站的矢量图形。很多网页的主要内容还是文本。GDI得到从WebKit传递过来的未格式化的普通文本,并以合适的字体,风格,尺寸将其渲染在位图上。
用户界面还依赖显示后端创建并管理它的UI元素,或widgets。views框架调用WTL产生基本的widgets,例如文本框,复选框、单选按钮等等。这个工具包提供了Win32库的高层封装。Chrome外观独特,views框架负责创建那些复杂的小部件,它们一般没有平台相关的外观或实现。例如:窗口、菜单、和按钮。还包括,在工具条中显示tab widgets(传统上,这是非客户区域),这一Chrome的卓越UI功能之一。当views创建这些widgets时,它请求Skia生成矢量图形,请求GDI绘制文本到元素本身上。















 2225
2225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









