







针对文章,有不同意见,欢迎评论区交流
代码链接:https://github.com/jhljx/GKT
中文解读
基于图的知识追踪:利用图神经网络对学生能力进行建模
ABSTRACT
计算机辅助学习系统的最新进展导致了知识追踪研究的增加,其中学生在课程作业上的表现是随着时间的推移预测的。从数据结构的观点来看,课程作业可以潜在地构建为一个图表。将这种图结构的性质作为关系归纳偏差引入知识追踪模型,可以提高知识追踪模型的性能;然而,以往的方法,如深度知识追踪,并没有考虑这种潜在的图结构。受近年来图神经网络(GNN)成功的启发,我们提出了一种基于GNN的知识追踪方法,即基于图的知识追踪。将知识结构转化为图形,使我们能够将知识追踪任务重新表述为GNN中的时间序列节点级分类问题。由于知识图结构在大多数情况下没有明确提供,我们提出了各种知识图结构的实现方法。在两个开放数据集上的经验验证表明,我们的方法可以潜在地提高学生成绩的预测,并显示了更多的可解释的预测,而不需要任何额外的信息。
1 INTRODUCTION
计算机辅助学习系统的最新进展导致了对的知识追踪[5]研究的增加,在这种研究中,学生在课程作业上的表现会随着时间的推移而预测。准确的预测可以帮助学生找到适合自己个人知识水平的内容,从而促进更高效的学习。这对在线学习平台和教师来说尤其重要,因为他们可以提高学生的参与度,也可以防止学生辍学。尽管已经提出了各种各样的知识追踪方法,Piech等人[17]报道了一种称为深度知识追踪(DKT)的方法,它利用了递归神经网络(RNNs)[24],其性能明显优于以前的任何方法。
从数据结构的观点来看,课程作业可以潜在地构造为一个图。掌握课程作业的要求分为知识概念,称为节点,这些概念共享依赖关系,称为边。让我们考虑这样一个例子。课程知识分为三个概念
v
=
{
v
1
,
v
2
,
v
3
}
v = \{v1,v2,v3\}
v={v1,v2,v3},对
v
1
v1
v1的理解取决于对
v
2
v2
v2的理解。同时,
v
2
v2
v2依赖
v
3
v3
v3(如:
v
1
表
示
二
次
方
程
求
解
,
v
2
表
示
线
性
方
程
求
解
,
v
3
v1表示二次方程求解,v2表示线性方程求解,v3
v1表示二次方程求解,v2表示线性方程求解,v3表示项的转置)。在这里,概念和它们的依赖关系可以分别被理解为一个图的节点和边,其中边是指向,
v
3
指
向
v
2
和
v
2
指
向
v
1
v3指向v2和v2指向v1
v3指向v2和v2指向v1。众所周知,将有关(数据的图结构性质)的先验知识整合到模型中可以提高它们的性能和可解释性[2]。因此,结合课程知识的图结构特性可以有效地改进知识追踪模型;然而,以前基于深度学习的方法,如DKT,并没有考虑到这一性质。以往基于深度学习的方法的架构,如RNN,对顺序数据的处理效果一般较好,但不能有效地处理图结构数据。
近年来,通过深度学习处理图结构数据的图神经网络(GNN)[8]的研究引起了人们的关注。尽管对现有的机器学习方法来说,在这些不规则的领域数据上操作具有挑战性,但各种泛化框架和重要操作已经开发出来[2,7,23],并在各个研究领域取得了成功的结果。Battaglia等人[2]从关系归纳偏差的角度解释了GNN的表达能力,该方法通过整合人类关于数据性质的先验知识,提高了机器学习模型的样本效率。为了将这些好处整合到知识追踪中,我们将其重新定义为GNN应用,并提出了一种新的模型,可以在考虑潜在知识结构的同时预测课程作业熟练度的过程。
使用GNN执行知识跟踪时遇到的一个挑战是潜在图结构的定义。GNN在建模图形结构化数据方面具有相当强的表达能力;然而,在一些知识跟踪设置的情况下,图结构本身,即相关的概念和关系的强度,没有明确地提供。人类专家可以启发式地、手动地注释内容关系;然而,它需要深入的领域知识和大量的时间;因此,很难预先定义e-learning平台中所有内容的图形结构。我们称这个问题为隐式图结构问题。一个简单的解决方案是使用简单的统计数据来定义图形结构,这些统计数据可以从数据中自动导出,比如概念回答的转移概率。另一种解决方案是在学习图结构本身的同时优化主要任务。在最近的GNN研究中,一个相关的主题是边缘特征学习,针对这一主题已经提出了几种方法。尽管这些技术不能直接应用于我们的问题,但可以对它们进行扩展,使其能够应用于我们的案例。
在本文中,我们提出了一种基于 GNN 的知识跟踪方法,即基于图的知识跟踪(GKT)。 我们的模型将知识追踪重新定义为GNN中的时间序列节点级分类问题。该提法基于三个假设:1)将课程知识分解为若干知识概念。2)学生有自己的时间知识状态,这代表他们对课程概念的熟练程度。3)课程的知识结构作为一个图,影响学生知识的更新状态:如果学生回答一个概念,正确或错误,他/她的知识状态是影响不仅对回答的概念,而且其他相关概念表示为图中相邻节点。
利用数学练习日志的两个开放数据集的子集,我们对我们的方法进行了实证验证。在预测性能方面,我们的模型优于以往基于深度学习的方法,这表明我们的模型在提高学生成绩预测方面具有很大的潜力。此外,通过分析训练模型的预测模式,学生熟练的过程,也就是说,学生获得的概念的理解,和所需要的时间相同,可以清楚地解释模型的预测,而前面的方法证明了劣质的可解释性。这意味着我们的模型比以前的模型提供了更多可解释的预测。在假设目标课程作业为图形结构的情况下,所得结果验证了我们的模型在提高知识追踪在真实教育环境中应用的效能和适用性方面的潜力。
我们的贡献如下:
• 我们证明,在不需要任何额外信息的情况下,将知识追踪制定为GNN的应用可以改善学生的表现预测。通过更精确的内容个性化,学生可以更有效地掌握课程作业。电子学习平台可以提供更高质量的服务,以保持高用户参与度。
• 我们的模型提高了模型预测的可解释性。教师和学生可以更准确地认识到学生的知识状态,学生也可以通过理解为什么要推荐这些练习题来激发自己去做这些练习题。电子学习平台和教师可以通过分析学生在哪个点上失败,更容易地重新设计课程。
• 为了解决隐式图结构问题,我们提出了各种实现方案,并通过经验验证了它们的有效性。研究人员可以从性能提升中受益,而不需要专家对概念之间的关系进行昂贵的注释。教育专家可以有一个新的标准来考虑什么是好的知识结构,以改进课程设计。
2 RELATED WORK
2.1 Knowledge Tracing
知识追踪是一项基于一段时间的课程作业来预测学生表现的任务。它可以定义为
y
t
=
K
T
(
x
1
,
⋅
⋅
⋅
,
x
t
)
,
其
中
x
t
=
{
q
t
,
r
t
}
y^t= KT(x^1,···,x^t),其中 x^t = \{q^t, r^t\}
yt=KT(x1,⋅⋅⋅,xt),其中xt={qt,rt}是一个元组,认为在时间步
t
t
t,
q
t
q^t
qt是回答t时刻的练习,
r
t
r^t
rt代表问题是否回答正确,
y
t
y^t
yt是学生在下一个时间步(
t
+
1
t+1
t+1)回答每个练习正确的概率,
K
T
KT
KT是知识跟踪模型。
自从Piech等人[17]首先提出了基于深度学习的知识追踪方法DKT,并展示了RNN的强大表达能力后,许多研究者都采用了RNN或其扩展作为KT。这些模型定义了一个隐藏的状态,或学生的瞬时知识状态,
h
t
h^t
ht,并随着时间的推移根据学生的运动表现不断更新它。基于RNN的模型
x
x
x 必须表示为一个固定大小的向量,在许多情况下,
x
t
x^t
xt通过连接两个二进制向量来表示,这两个向量分别表示哪个练习是回答正确的和回答错误的。因此,对于有
N
N
N个唯一练习的数据集,
x
t
∈
{
0
,
1
}
2
N
x^t∈\{0,1\}^{2N}
xt∈{0,1}2N。输出向量
y
t
y^t
yt的长度与练习的数量相同,其中每个元素代表学生正确回答特定练习的预测概率。训练目标是最小化模型下观察到的学生反应序列的负对数似然(NLL)。
2.2 GNN
GNN[8]是一种可以对图结构数据进行操作的神经网络。图是一种数据结构,它分别用节点和边表示对象及其关系。尽管对现有的机器学习方法来说,在这种不规则的领域数据上操作是一个挑战,但图的相当大的表达能力增加了对GNN的研究,近年来,开发了各种泛化框架和重要的操作[2,7,23],在社会科学[9,14]和自然科学[1,6,18]等多个研究领域取得了成功成果。
我们使用GNN的主要动机是卷积神经网络[15]的成功。CNN采用局部连接、权重共享和多层架构,可以提取多尺度的局部空间特征,并将其组合成具有表达性的表示,从而在计算机视觉等多个研究领域取得突破。然而,CNNs只能对常规的欧几里德数据(如图像和文本)进行操作,而现实世界中的一些应用产生非欧几里德数据。而GNN则将这些非欧几里德的数据结构视为图表,并将CNN的同样优势体现在这些高度多样化的数据上。Battaglia等人[2]从关系归纳偏差的角度解释了GNN和CNN如此强大的表达能力,通过整合人类关于数据本质的先验知识,提高了机器学习模型的样本效率。
在GNN的诸多研究课题中,边缘特征学习[1,3,7]与我们的工作关系最为密切。图注意网络(Graph attention networks, GATs)[21]将多头注意机制[20]应用于GNN,在训练过程中无需预先定义边缘权值即可实现学习。神经关系推理(NRI)[13]利用变分自编码器(VAE)[12]以无监督方式学习潜在图结构。我们的方法假定在课程知识概念基础上有一个潜在的图结构,并使用图运算符模拟学生在每个概念上的熟练程度的时间过渡。 然而,在许多情况下,图结构本身并没有明确提供。我们通过设计模型来解决这个问题,通过扩展这些边缘特征学习机制,在优化学生表现预测的同时,也同时学习边缘连接本身。我们将在Section3.3中详细解释这一点。
3 GRAPH-BASED KNOWLEDGE TRACING
3.1 Problem Definition
我们假设课程作业的结构可能是一个图 G = ( V , E ) G = (V,E) G=(V,E);对掌握该课程的要求被分解为N个知识概念,称为节点集合 V = { v 1 , ⋅ ⋅ ⋅ , v N } V = \{v_1,···,v_N\} V={v1,⋅⋅⋅,vN},这些概念共享依赖关系,称为边集 E ⊆ V × V E \subseteq V \times V E⊆V×V基于三角形数据压缩的实例此外,我们假设一个学生在时间步长 t t t 时对每个概念都有一个独立的时间知识状态, h t = h i ∈ V t h^t= {h^t_{i \in V}} ht=hi∈Vt,该知识状态随着时间的推移而更新如下:当学生解决与概念 v i v_i vi 相关的练习时,学生对所回答的概念本身 h i t h^t_i hit 和其相关概念 h j t ∈ N i h^t_j \in N_i hjt∈Ni 的知识状态就会更新。这里, N i N_i Ni一组邻近 v i v_i vi 的节点。
3.2 Proposed Method
GKT将GNN应用于知识跟踪任务,并利用知识的图结构特性。我们在图1中展示了GKT的体系结构。下面的段落将详细解释这些过程。
3.2.1聚合。首先,该模型对已回答的概念 i i i 及其邻近概念 j ∈ N i j \in N_i j∈Ni进行了隐态和嵌入的聚合:
h k ′ t = { [ h k ′ t , x t E x h k ′ t , E c ( k ) ] ( k = i ) ( k ≠ i ) h^{\prime t}_k=\left\{\begin{bmatrix}h_k^{\prime t}, & x^{t}E_x\\h_k^{\prime t}, &E_c(k)\end{bmatrix}\begin{array}{c}(k=i)\\(k\neq i)\end{array}\right. hk′t={[hk′t,hk′t,xtExEc(k)](k=i)(k=i)
其中
x
t
∈
{
0
,
1
}
x_t \in \{ 0,1\}
xt∈{0,1} 是一个输入向量代表练习回答正确和不正确的时间步
t
t
t ,
E
x
∈
R
(
2
(
N
∗
e
)
E_x \in R^(2(N*e)
Ex∈R(2(N∗e)矩阵嵌入的概念指数和响应的答案,Ec∈RN×eis矩阵嵌入了指数概念,
E
c
(
k
)
E_c (k)
Ec(k)代表的k行Ec和e是嵌入大小。
3.2.2更新。然后,基于聚合特征和知识图结构对隐藏状态进行更新:
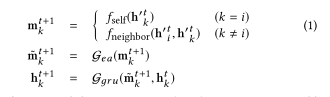
其中,
f
s
e
l
f
f_{self}
fself是多层感知器(MLP),
G
e
a
G_ea
Gea是张等人的[25]中使用的擦加门,
G
g
r
u
G_gru
Ggru是门控循环单元(GRU)门[4]。
f
n
e
i
g
h
b
o
r
f_neighbor
fneighbor是一个任意函数,它基于知识图结构定义了信息向相邻节点的传播。我们在第3.3节中提出了
f
n
e
i
g
h
b
o
r
f_neighbor
fneighbor的各种实现。
3.2.3预测。最后,模型输出学生在下一个时间步正确回答每个概念的预测概率:
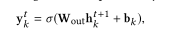
其中
W
o
u
t
W_out
Wout 是所有节点共同的权重矩阵,
b
k
b_k
bk 是节点
k
k
k 的偏差项,σ是一个sigmoid函数。该模型被训练为最小化观测值的NLL。
我们可以利用边缘信息收集相邻概念的知识状态;但我们证实仅基于目标概念
h
k
t
h^t_k
hkt的知识状态预测
y
k
t
y^t_k
ykt 较好;因此,我们将图结构信息的使用限制在更新阶段。
3.3 Implementation of Latent Graph Structure and fneighbor
(潜在图结构和f_neighbor的实现)
GKT可以利用知识的图结构特性来进行知识追踪;但是,在大多数情况下,没有显式地提供结构本身。为了实现潜在图结构和f_neighborin(方程1),我们引入了两种方法。
3.3.1基于统计的方法。基于统计的方法是根据一定的统计信息实现邻接矩阵A,并将其应用于fneighbors:
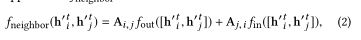
其中f_out和f_in是MLPs。在这里,我们介绍三种类型的图。
Dense graph是一个简单的密连通图
Transition graph是一个转移概率矩阵
DKT graph是由Piech等人提出的基于训练后的DKT模型的条件预测概率生成的图。
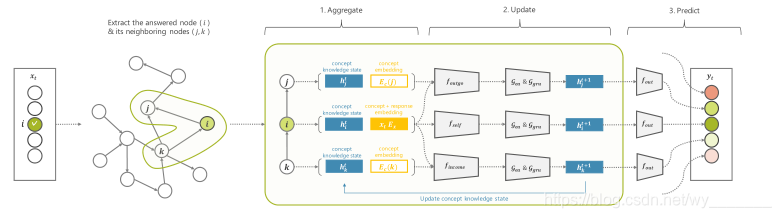
图1:GKT的架构。当一个学生回答一个概念时,GKT首先聚合与回答的概念相关的节点特征,然后更新学生仅相关概念的知识状态,最后预测学生在下一个时间步中正确回答每个概念的概率。
3.3.2 基于学习的方法。在该方法中,图形结构的学习与性能预测的优化并行进行。在这里,我们介绍三种学习图结构的方法。
Parametric adjacency matrix (PAM) 简单地对邻接矩阵A进行参数化,并在一定的约束条件下与其他参数进行优化,使A满足邻接矩阵的性质。
f
n
e
i
g
h
b
o
r
f_{neighbor}
fneighbor的定义类似于方程 2。
Multi-head Attention (MHA) 利用多头关注机制[20],根据两个节点的特征推断两个节点之间的边权值。
f
n
e
i
g
h
b
o
r
f_{neighbor}
fneighbor的定义如下:
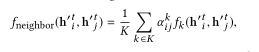
其中k是总共k个头中的头指数,α注意权重,f_k是神经网络,用于第k个头。
Variational autoencoder (VAE) 假设离散潜在变量表示边缘的类型,并根据节点特征推断它们。fneighbor的定义如下:
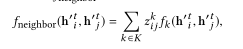
其中k是k种类型中的边缘类型,zk是从Gumbel-Softmax分布[16]采样的潜在变量,f_k是针对第k种边缘类型的神经网络。VAE最小化了编码分布q(z|x)和先验分布p(z)之间的NLL和kullback - lebler散度。使用一个边缘类型来表示“非边缘”类意味着没有消息沿着这个边缘类型传递;此外,在“非边缘”标签上设置高概率鼓励生成稀疏图。
基于学习的方法与边缘特征学习的概念相近[1,3,7],MHA和V AE分别由GAT[21]和NRI[13]驱动;但是,我们从两个方面对它们进行了修改。首先,我们基于静态特征(如概念和响应的嵌入)来计算边缘权值,而不是基于动态特征。这使得学习知识图的结构对学生不变性和时间步长更自然,考虑到实际的知识追踪设置。其次,对于VAE,我们限制了每个时间步中与答案相关的节点的边类型推断。这符合知识追踪的情况,即学生在每个时间步只回答概念的一个小子集,从而减少计算成本从原来NRI的O(KN2)到O(KN)。
我们将在第5.1节中讨论这三种基于学习的方法之间的区别
4.4 Interpretability of the Prediction
接下来,我们可视化模型如何预测学生的知识状态随时间的变化,并评估其预测的可解释性。这种可视化有助于学生和教师有效、直观地认识前者的知识状态;因此,它的可解释性是重要的。在这里,我们基于以下两点来评估可解释性:1)模型在每个时间步中是否只更新相关概念到被回答的概念。2)给定图结构,更新是否合理。虽然之前的研究[17,25]进行了类似的分析,但我们的研究将这种方法扩展如下,以更精确地分析时间变迁:
(1)随机抽取一个学生日志,直到时间步长
t
t
t。
(2)去掉训练模型输出层的偏差向量。
(3)将学生的答题日志
x
t
x_t
xt
≤
\leq
≤
T
T
T输入到训练的模型中,输出
y
t
y_t
yt
≤
\leq
≤
T
T
T。
(4)将每一次从0到1的输出值规格化。
我们在图
3
a
3a
3a和图
3
b
3b
3b中随机抽取了一个学生,并将学生的知识状态描述为概念的子集。
x
x
x轴和
y
y
y轴分别表示时间步长和概念指数,单元格颜色表示时间步长时熟练程度的变化程度。绿色表示增加,红色表示减少。我们分别用“✓”和“×”填充正确和错误的元素。
如图
3
a
3a
3a所示,GKT只更新相关概念的知识状态,而DKT不清晰地更新所有概念的状态,不能对相关概念的变化进行建模。另外,图3b显示,虽然概念29没有回答,但它的知识状态在t = 28和t = 75时明显更新了。在这些时间步中,概念4被正确回答,给定的图形显示了概念4和29之间的一条边,如图右侧所示。这表明,GKT基于给定的图表确定地模拟了学生的知识状态。然而,DKT没有表现出这种行为。这些结果表明,GKT能够清晰而合理地模拟学生对每个概念的熟练程度,并提供更多可解释的预测。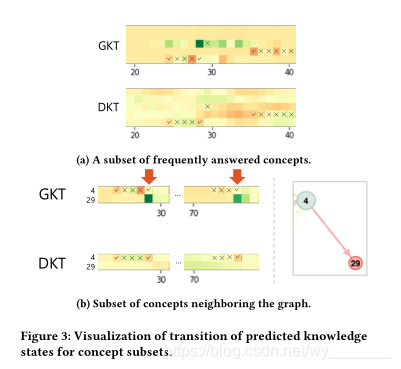
4.5 Network Analysis
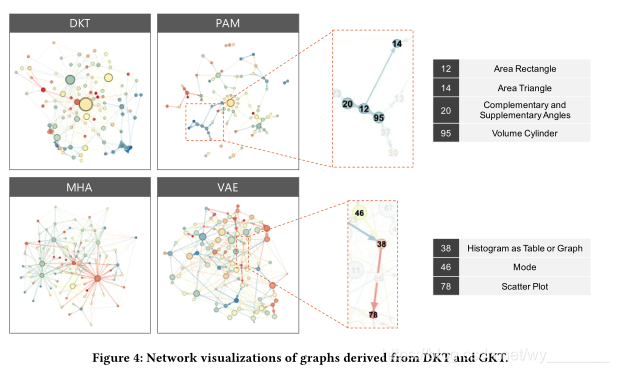
最后,我们从训练的GKT模型中提取学习到的图结构并进行分析。在基于学习的方法中,GKT学习有助于预测学生表现的图结构。因此,从模型中提取的具有高预测性能的图可以为良好的知识结构提供洞见。
图4描述了网络,左边显示了网络概览,右边显示了图的本地连接。节点的颜色从蓝色分级到红色,越早回答一个练习,越蓝的是阴影。节点的大小与其出度成正比,说明节点越大影响节点越多。
首先,在用于比较的可视化DKT图中,颜色相似的节点相互连接,从而生成集群。由于DKT模型中所有概念的隐藏状态都使用同一个隐藏向量,因此很难对概念之间的长期依赖关系进行建模。因此,模型倾向于学习节点之间的依赖关系,这些节点是按时间关闭顺序回答的。从PAM中提取的图显示了与DKT图类似的结构,其中构建了集群;从图的右上角,我们可以看到一些几何概念是相连的。从MHA中提取的图显示了某些节点的几个输出边。虽然模型可能已经学习了一些不同于其他图中的概念之间的特殊依赖关系,但它的预测可能是有偏差的。因此,我们必须评估这种结构对预测性能的影响。从VAE中提取的图与其他图的不同之处在于,它形成了一个密集图,几个节点相互连接。尽管这些联系很难解释,但从图的右下角,我们可以确定一些统计概念是相互联系的。
5 DISCUSSION
5.1 Differences Between Learning-based Approaches
为解决隐式图结构问题,我们提出了两种实现方法,并在基于学习的方法中发展了三种实现方法,即PAM、MHA和VAE。下面,我们将讨论它们之间的区别。
PAM方法与其他两种方法的区别在于识别边缘特征估计是否有条件。 在PAM中,邻接矩阵是直接优化的,不存在估计边缘特征的条件。而在MHA和VAE中,可以选择用于预测边缘特征的特征;在这里,我们选择了概念嵌入
E
c
E_c
Ec作为输入,这样学生就可以学习到一个单一的稳定的概念图不变量,这也是知识追踪中最相同、最简单的设置。
MHA和VAE的区别在于计算边缘权值的方法。 在MHA中,当一个概念
i
i
i 被回答时,就会计算注意力得分,并对所有相邻的概念进行归一化。此外,MHA可以利用多头注意力学习每条边的
k
k
k 个边权值。而在VAE中,基于回答的概念对及其邻近的概念,每个边缘特征是独立计算的;Gumbel Softmax函数只呈现
k
k
k 边权值中接近1的一个,其他接近0的。此外,VAE可以定义一些先验分布,从而可以定义整个图的稀疏性。
因此,每种方法学习不同的图结构,如第4.5节所示;然而,我们发现他们的预测性能有微小的差异。在边缘估计中加入一些约束可能会导致预测性能的不同。因此,基于学习的方法的选择的影响必须作为未来工作的一部分进行调查。
5.2 Dataset Generalizability
在本研究中,为了验证我们模型的性能,我们使用了原始数据集的一个子集,其中学生和低数据的概念被排除,以减少噪音,如4.1节所述。虽然实验证明了我们的模型在提高预测性能和可解释性方面的潜力,但我们必须放松约束,以证明我们的模型的好处可以更清楚地显示在相同的设置下的以前的研究。
此外,我们必须验证我们的方法在不同的主题数据集的适用性。我们使用的数据集的主题仅限于数学,就像Piech等人[17]的情况一样。鉴于DKT在编程教育领域的应用有[22]的报道,而GKT是一个通用算法,它完成了之前的算法,如DKT, GKT也可以在各种学科中有效。然而,不同的学科可以表现出不同的潜在图结构;因此,我们必须将主体的影响与我们的模型进行比较,例如,哪种类型的图适合于预测学生的表现,或者可以从基于学习的方法中获得。
5.3 Incorporating Richer GNN Architectures
(5.3整合更丰富的GNN架构)
我们提出了第一个基于gnn的知识追踪方法,并验证了相对简单的体系结构。接下来,我们将讨论三个方向来改进我们的模型。
一种是根据节点的边缘类型对节点之间的信息传播施加适当的约束。 在这项研究中,为了公平的比较,我们定义了两种类型的边基于统计和学习的方法。然而,我们没有对每个节点类型施加任何约束;因此,对于每个节点类型,如依赖方向和因果关系,意义可能很小,特别是对于学习到的边。一个解决方案是根据节点的边缘类型对节点之间的信息传播施加一些约束,例如定义边的方向,并将传播限制在从源节点到目标节点的一个方向上。此外,这可以作为一种关联归纳偏差,提高GKT的样本效率和可解释性。
另一个是将所有概念(如DKT)共同的隐藏状态合并到GKT中。 虽然仅采用单一的隐含向量来表示学生的知识状态,使得DKT中概念之间复杂交互的建模变得复杂,但在GKT中加入这种类型的表示可以作为全局特征[2]来提高性能。全局特征是指每个节点共有的特征,可以表示变量概念之间共有的知识状态,也可以表示学生对个体概念理解的原始智力不变。
最后一个可能的解决方案是实现多跳传播。 在本研究中,我们将传播限制为单跳,即在一个时间步长内,响应某一节点的信息只传播到其邻近节点。然而,为了有效地建模人类学习机制,使用多跳将会更合适。此外,这可以使模型学习稀疏连接,因为模型可以传播特征到遥远的节点,而不连接到其他节点。
6 CONCLUSION
我们提出了一种基于GNN的知识追踪方法GKT,该方法考虑了以往基于深度学习方法忽略的潜在知识结构。将知识结构转化为图,将知识追踪任务作为GNN的一个应用加以重构。在两个开放数据集上的实证验证表明,与以前的方法相比,我们的方法可以潜在地提高学生的水平预测,并表现出高度可解释的预测。这些结果证实了我们的方法在提高知识追踪性能方面的潜力和其应用于真实教育环境的可能性。我们相信这项工作可以帮助改善学生在不同环境下的学习体验。
代码讲解,针对部分函数
train.py
其中的train函数
def train(epoch, best_val_loss):
t = time.time()
loss_train = []
kt_train = []
vae_train = []
auc_train = []
acc_train = []
if graph_model is not None:
graph_model.train()
model.train()
for batch_idx, (features, questions, answers) in enumerate(train_loader):
t1 = time.time()
if args.cuda:
features, questions, answers = features.cuda(), questions.cuda(), answers.cuda()
ec_list, rec_list, z_prob_list = None, None, None
if args.model == 'GKT':
pred_res, ec_list, rec_list, z_prob_list = model(features, questions)
elif args.model == 'DKT':
pred_res = model(features, questions)
else:
raise NotImplementedError(args.model + ' model is not implemented!')
loss_kt, auc, acc = kt_loss(pred_res, answers)
kt_train.append(float(loss_kt.cpu().detach().numpy()))
if auc != -1 and acc != -1:
auc_train.append(auc)
acc_train.append(acc)
if args.model == 'GKT' and args.graph_type == 'VAE':
if args.prior:
loss_vae = vae_loss(ec_list, rec_list, z_prob_list, log_prior=log_prior)
else:
loss_vae = vae_loss(ec_list, rec_list, z_prob_list)
vae_train.append(float(loss_vae.cpu().detach().numpy()))
print('batch idx: ', batch_idx, 'loss kt: ', loss_kt.item(), 'loss vae: ', loss_vae.item(), 'auc: ', auc, 'acc: ', acc, end=' ')
loss = loss_kt + loss_vae
else:
loss = loss_kt
print('batch idx: ', batch_idx, 'loss kt: ', loss_kt.item(), 'auc: ', auc, 'acc: ', acc, end=' ')
loss_train.append(float(loss.cpu().detach().numpy()))
loss.backward()
optimizer.step()
scheduler.step()
optimizer.zero_grad()
del loss
print('cost time: ', str(time.time() - t1))
loss_val = []
kt_val = []
vae_val = []
auc_val = []
acc_val = []
if graph_model is not None:
graph_model.eval()
model.eval()
with torch.no_grad():
for batch_idx, (features, questions, answers) in enumerate(valid_loader):
if args.cuda:
features, questions, answers = features.cuda(), questions.cuda(), answers.cuda()
ec_list, rec_list, z_prob_list = None, None, None
if args.model == 'GKT':
pred_res, ec_list, rec_list, z_prob_list = model(features, questions)
elif args.model == 'DKT':
pred_res = model(features, questions)
else:
raise NotImplementedError(args.model + ' model is not implemented!')
loss_kt, auc, acc = kt_loss(pred_res, answers)
loss_kt = float(loss_kt.cpu().detach().numpy())
kt_val.append(loss_kt)
if auc != -1 and acc != -1:
auc_val.append(auc)
acc_val.append(acc)
loss = loss_kt
if args.model == 'GKT' and args.graph_type == 'VAE':
loss_vae = vae_loss(ec_list, rec_list, z_prob_list)
loss_vae = float(loss_vae.cpu().detach().numpy())
vae_val.append(loss_vae)
loss = loss_kt + loss_vae
loss_val.append(loss)
del loss
if args.model == 'GKT' and args.graph_type == 'VAE':
print('Epoch: {:04d}'.format(epoch),
'loss_train: {:.10f}'.format(np.mean(loss_train)),
'kt_train: {:.10f}'.format(np.mean(kt_train)),
'vae_train: {:.10f}'.format(np.mean(vae_train)),
'auc_train: {:.10f}'.format(np.mean(auc_train)),
'acc_train: {:.10f}'.format(np.mean(acc_train)),
'loss_val: {:.10f}'.format(np.mean(loss_val)),
'kt_val: {:.10f}'.format(np.mean(kt_val)),
'vae_val: {:.10f}'.format(np.mean(vae_val)),
'auc_val: {:.10f}'.format(np.mean(auc_val)),
'acc_val: {:.10f}'.format(np.mean(acc_val)),
'time: {:.4f}s'.format(time.time() - t))
else:
print('Epoch: {:04d}'.format(epoch),
'loss_train: {:.10f}'.format(np.mean(loss_train)),
'auc_train: {:.10f}'.format(np.mean(auc_train)),
'acc_train: {:.10f}'.format(np.mean(acc_train)),
'loss_val: {:.10f}'.format(np.mean(loss_val)),
'auc_val: {:.10f}'.format(np.mean(auc_val)),
'acc_val: {:.10f}'.format(np.mean(acc_val)),
'time: {:.4f}s'.format(time.time() - t))
if args.save_dir and np.mean(loss_val) < best_val_loss:
print('Best model so far, saving...')
torch.save(model.state_dict(), model_file)
torch.save(optimizer.state_dict(), optimizer_file)
torch.save(scheduler.state_dict(), scheduler_file)
if args.model == 'GKT' and args.graph_type == 'VAE':
print('Epoch: {:04d}'.format(epoch),
'loss_train: {:.10f}'.format(np.mean(loss_train)),
'kt_train: {:.10f}'.format(np.mean(kt_train)),
'vae_train: {:.10f}'.format(np.mean(vae_train)),
'auc_train: {:.10f}'.format(np.mean(auc_train)),
'acc_train: {:.10f}'.format(np.mean(acc_train)),
'loss_val: {:.10f}'.format(np.mean(loss_val)),
'kt_val: {:.10f}'.format(np.mean(kt_val)),
'vae_val: {:.10f}'.format(np.mean(vae_val)),
'auc_val: {:.10f}'.format(np.mean(auc_val)),
'acc_val: {:.10f}'.format(np.mean(acc_val)),
'time: {:.4f}s'.format(time.time() - t), file=log)
del kt_train
del vae_train
del kt_val
del vae_val
else:
print('Epoch: {:04d}'.format(epoch),
'loss_train: {:.10f}'.format(np.mean(loss_train)),
'auc_train: {:.10f}'.format(np.mean(auc_train)),
'acc_train: {:.10f}'.format(np.mean(acc_train)),
'loss_val: {:.10f}'.format(np.mean(loss_val)),
'auc_val: {:.10f}'.format(np.mean(auc_val)),
'acc_val: {:.10f}'.format(np.mean(acc_val)),
'time: {:.4f}s'.format(time.time() - t), file=log)
log.flush()
res = np.mean(loss_val)
del loss_train
del auc_train
del acc_train
del loss_val
del auc_val
del acc_val
gc.collect()
if args.cuda:
torch.cuda.empty_cache()
return res
processing.py
数据预处理部分:
1.1、删除没有对应skill是question
1.2、删除答题少于一题的学生记录
2、给skill重新编号,将skill_id排序后用0、1…编号
3、交叉技能id与答案形成综合特征,
df[‘skill_with_answer’] = df[‘skill’] * 2 + df[‘correct’]
(偶数代表答错,奇数代表答对)
(此处若用为编码,则表示回答情况的编码,就可利用one-hot编码,每两位代表一个skill的掌握情况,用1标记相符合,0标记不符合,所以统计奇数位为1的情况,即可判断学生未掌握的知识点,具体分析每个奇数位,就可以知道学生的具体未掌握的skill。------有点绕)
| skill(n个) | incorrect(回答错误,均是偶数记录,但是是处于奇数位) | correct |
|---|---|---|
| 0 | skill_with_answer:0 | skill_with_answer:1 |
| 1 | skill_with_answer:2 | skill_with_answer:3 |
| 2 | skill_with_answer:4 | skill_with_answer:5 |
| n-1 | skill_with_answer:2(n-1) | skill_with_answer:2(n-1)+1 |
def load_dataset(file_path, batch_size, graph_type, dkt_graph_path=None, train_ratio=0.7, val_ratio=0.2, shuffle=True, model_type='GKT', use_binary=True, res_len=2, use_cuda=True):
r"""
Parameters:
file_path: input file path of knowledge tracing data
batch_size: the size of a student batch
graph_type: the type of the concept graph
shuffle: whether to shuffle the dataset or not
use_cuda: whether to use GPU to accelerate training speed
Return:
concept_num: the number of all concepts(or questions)
graph: the static graph is graph type is in ['Dense', 'Transition', 'DKT'], otherwise graph is None
train_data_loader: data loader of the training dataset
valid_data_loader: data loader of the validation dataset
test_data_loader: data loader of the test dataset
NOTE: stole some code from https://github.com/lccasagrande/Deep-Knowledge-Tracing/blob/master/deepkt/data_util.py
"""
df = pd.read_csv(file_path)
if "skill_id" not in df.columns:
raise KeyError(f"The column 'skill_id' was not found on {file_path}")
if "correct" not in df.columns:
raise KeyError(f"The column 'correct' was not found on {file_path}")
if "user_id" not in df.columns:
raise KeyError(f"The column 'user_id' was not found on {file_path}")
# if not (df['correct'].isin([0, 1])).all():
# raise KeyError(f"The values of the column 'correct' must be 0 or 1.")
# Step 1.1 - Remove questions without skill
df.dropna(subset=['skill_id'], inplace=True)
# Step 1.2 - Remove users with a single answer
df = df.groupby('user_id').filter(lambda q: len(q) > 1).copy()
# Step 2 - Enumerate skill id
# assisment_test15.csv中有 74 种skills
df['skill'], _ = pd.factorize(df['skill_id'], sort=True) # we can also use problem_id to represent exercises 将技能从0开始编号
# Step 3 - Cross skill id with answer to form a synthetic feature
# use_binary: (0,1); !use_binary: (1,2,3,4,5,6,7,8,9,10,11,12). Either way, the correct result index is guaranteed to be 1
if use_binary:
df['skill_with_answer'] = df['skill'] * 2 + df['correct']
else:
df['skill_with_answer'] = df['skill'] * res_len + df['correct'] - 1
# Step 4 - Convert to a sequence per user id and shift features 1 timestep
feature_list = []
question_list = []
answer_list = []
seq_len_list = []
def get_data(series):
feature_list.append(series['skill_with_answer'].tolist())
question_list.append(series['skill'].tolist())
answer_list.append(series['correct'].eq(1).astype('int').tolist())
seq_len_list.append(series['correct'].shape[0])
df.groupby('user_id').apply(get_data) # 按照‘user_id’聚类(即将一类的按照顺序排好,然后针对相关列数据应用 函数‘get_data’)
max_seq_len = np.max(seq_len_list)
print('max seq_len: ', max_seq_len)
student_num = len(seq_len_list)
print('student num: ', student_num)
feature_dim = int(df['skill_with_answer'].max() + 1)
print('feature_dim: ', feature_dim)
question_dim = int(df['skill'].max() + 1)
print('question_dim: ', question_dim)
concept_num = question_dim
# print('feature_dim:', feature_dim, 'res_len*question_dim:', res_len*question_dim)
# assert feature_dim == res_len * question_dim
kt_dataset = KTDataset(feature_list, question_list, answer_list) # 此处的数据格式的转换,是为了放到DataLoader里
# 拓:参考链接 https://blog.csdn.net/kahuifu/article/details/108654421
# pytorch中加载数据的顺序是:
# ①创建一个dataset对象
# ②创建一个dataloader对象
# ③循环dataloader对象,将data,label拿到模型中去训练
train_size = int(train_ratio * student_num)
val_size = int(val_ratio * student_num)
test_size = student_num - train_size - val_size
train_dataset, val_dataset, test_dataset = torch.utils.data.random_split(kt_dataset, [train_size, val_size, test_size])
print('train_size: ', train_size, 'val_size: ', val_size, 'test_size: ', test_size)
# 分别将数据格式转换(加载),上面两行用torch划分了数据集
train_data_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=shuffle, collate_fn=pad_collate)
valid_data_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=shuffle, collate_fn=pad_collate)
test_data_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=shuffle, collate_fn=pad_collate)
graph = None
if model_type == 'GKT':
if graph_type == 'Dense':
graph = build_dense_graph(concept_num) # 初始化图,初始化为对角线为0,其他位置均相同的邻接矩阵
elif graph_type == 'Transition':
graph = build_transition_graph(question_list, seq_len_list, train_dataset.indices, student_num, concept_num)
elif graph_type == 'DKT':
graph = build_dkt_graph(dkt_graph_path, concept_num)
if use_cuda and graph_type in ['Dense', 'Transition', 'DKT']:
graph = graph.cuda()
return concept_num, graph, train_data_loader, valid_data_loader, test_data_loader
GKT+Dense的初始图构建
def build_dense_graph(node_num):
graph = 1. / (node_num - 1) * np.ones((node_num, node_num))
np.fill_diagonal(graph, 0)
graph = torch.from_numpy(graph).float()
return graph
models.py
class GKT(nn.Module):
def __init__(self, concept_num, hidden_dim, embedding_dim, edge_type_num, graph_type, graph=None, graph_model=None, dropout=0.5, bias=True, binary=False, has_cuda=False):
super(GKT, self).__init__()
# 上句理解参考链接:https://blog.csdn.net/zyh19980527/article/details/107206483/
# super(GKT, self).__init__() 中GKT类继承nn.Module,对继承自父类nn.Module的属性进行初始化,而且是用nn.Module的初始化方法来初始化继承的属性。
self.concept_num = concept_num
self.hidden_dim = hidden_dim
self.embedding_dim = embedding_dim
self.edge_type_num = edge_type_num
self.res_len = 2 if binary else 12 # 此处res_len初始化为12了,processing.py中的加载数据中有相关注释,但是不清楚什么意思
self.has_cuda = has_cuda
assert graph_type in ['Dense', 'Transition', 'DKT', 'PAM', 'MHA', 'VAE']
self.graph_type = graph_type
if graph_type in ['Dense', 'Transition', 'DKT']:
assert edge_type_num == 2
assert graph is not None and graph_model is None # ?
self.graph = nn.Parameter(graph) # [concept_num, concept_num]
# nn.Parameter参考链接:https://www.jianshu.com/p/d8b77cc02410
# 使用这个函数的目的也是想让某些变量在学习的过程中不断的修改其值以达到最优化。
# 首先可以把这个函数理解为类型转换函数,将一个不可训练的类型Tensor转换成可以训练的类型parameter并将这个parameter绑定到这个module里面(net.parameter()中就有这个绑定的parameter,所以在参数优化的时候可以进行优化的),所以经过类型转换这个self.v变成了模型的一部分,成为了模型中根据训练可以改动的参数了。
self.graph.requires_grad = False # fix parameter
self.graph_model = graph_model
else: # ['PAM', 'MHA', 'VAE']
assert graph is None
self.graph = graph # None
if graph_type == 'PAM':
assert graph_model is None
self.graph = nn.Parameter(torch.rand(concept_num, concept_num))
else:
assert graph_model is not None
self.graph_model = graph_model
# one-hot feature and question
one_hot_feat = torch.eye(self.res_len * self.concept_num)
self.one_hot_feat = one_hot_feat.cuda() if self.has_cuda else one_hot_feat
self.one_hot_q = torch.eye(self.concept_num, device=self.one_hot_feat.device)
zero_padding = torch.zeros(1, self.concept_num, device=self.one_hot_feat.device)
self.one_hot_q = torch.cat((self.one_hot_q, zero_padding), dim=0) # 此处拼接是行的叠加
# concept and concept & response embeddings
self.emb_x = nn.Embedding(self.res_len * concept_num, embedding_dim)
# nn.embedding的维度的定义
# 参考链接:https://blog.csdn.net/a845717607/article/details/104752736
# 前两位代表嵌入的矩阵,行代表原始tensor维度,列代表嵌入维度,后续如果有其他要求,还有参数限定
# nn.Embedding的实操案例:https://www.jianshu.com/p/63e7acc5e890
# last embedding is used for padding, so dim + 1
self.emb_c = nn.Embedding(concept_num + 1, embedding_dim, padding_idx=-1) # 指定了padding_idx,注意这个padding_idx也是在num_embeddings尺寸内的,比如符号总共有500个,指定了padding_idx,那么num_embeddings应该为501
# f_self function and f_neighbor functions
mlp_input_dim = hidden_dim + embedding_dim
self.f_self = MLP(mlp_input_dim, hidden_dim, hidden_dim, dropout=dropout, bias=bias)
self.f_neighbor_list = nn.ModuleList()
# nn.ModuleList和普通list不一样,它和torch的其他机制结合紧密,继承了nn.Module的网络模型class可以使用nn.ModuleList并识别其中的parameters参考链接:https://zhuanlan.zhihu.com/p/75206669 https://blog.csdn.net/weixin_36670529/article/details/105910767
if graph_type in ['Dense', 'Transition', 'DKT', 'PAM']:
# f_in and f_out functions
self.f_neighbor_list.append(MLP(2 * mlp_input_dim, hidden_dim, hidden_dim, dropout=dropout, bias=bias)) # 2 * mlp_input_dim:因为包括当前节点输入和其邻居节点
self.f_neighbor_list.append(MLP(2 * mlp_input_dim, hidden_dim, hidden_dim, dropout=dropout, bias=bias))
else: # ['MHA', 'VAE']
for i in range(edge_type_num):
self.f_neighbor_list.append(MLP(2 * mlp_input_dim, hidden_dim, hidden_dim, dropout=dropout, bias=bias))
# Erase & Add Gate
self.erase_add_gate = EraseAddGate(hidden_dim, concept_num)
# Gate Recurrent Unit
self.gru = nn.GRUCell(hidden_dim, hidden_dim, bias=bias)
# prediction layer
self.predict = nn.Linear(hidden_dim, 1, bias=bias)
# Aggregate step, as shown in Section 3.2.1 of the paper
def _aggregate(self, xt, qt, ht, batch_size):
r"""
Parameters:
xt: input one-hot question answering features at the current timestamp
qt: question indices for all students in a batch at the current timestamp
ht: hidden representations of all concepts at the current timestamp
batch_size: the size of a student batch
Shape:
xt: [batch_size]
qt: [batch_size]
ht: [batch_size, concept_num, hidden_dim]
tmp_ht: [batch_size, concept_num, hidden_dim + embedding_dim]
Return:
tmp_ht: aggregation results of concept hidden knowledge state and concept(& response) embedding
"""
qt_mask = torch.ne(qt, -1) # [batch_size], qt != -1
x_idx_mat = torch.arange(self.res_len * self.concept_num, device=xt.device)
x_embedding = self.emb_x(x_idx_mat) # [res_len * concept_num, embedding_dim]
masked_feat = F.embedding(xt[qt_mask], self.one_hot_feat) # [mask_num, res_len * concept_num]
res_embedding = masked_feat.mm(x_embedding) # [mask_num, embedding_dim]
mask_num = res_embedding.shape[0]
concept_idx_mat = self.concept_num * torch.ones((batch_size, self.concept_num), device=xt.device).long()
concept_idx_mat[qt_mask, :] = torch.arange(self.concept_num, device=xt.device)
concept_embedding = self.emb_c(concept_idx_mat) # [batch_size, concept_num, embedding_dim]
index_tuple = (torch.arange(mask_num, device=xt.device), qt[qt_mask].long())
concept_embedding[qt_mask] = concept_embedding[qt_mask].index_put(index_tuple, res_embedding)
tmp_ht = torch.cat((ht, concept_embedding), dim=-1) # [batch_size, concept_num, hidden_dim + embedding_dim]
return tmp_ht
# GNN aggregation step, as shown in 3.3.2 Equation 1 of the paper
def _agg_neighbors(self, tmp_ht, qt):
r"""
Parameters:
tmp_ht: temporal hidden representations of all concepts after the aggregate step
qt: question indices for all students in a batch at the current timestamp
Shape:
tmp_ht: [batch_size, concept_num, hidden_dim + embedding_dim]
qt: [batch_size]
m_next: [batch_size, concept_num, hidden_dim]
Return:
m_next: hidden representations of all concepts aggregating neighboring representations at the next timestamp
concept_embedding: input of VAE (optional)
rec_embedding: reconstructed input of VAE (optional)
z_prob: probability distribution of latent variable z in VAE (optional)
"""
qt_mask = torch.ne(qt, -1) # [batch_size], qt != -1
masked_qt = qt[qt_mask] # [mask_num, ]
masked_tmp_ht = tmp_ht[qt_mask] # [mask_num, concept_num, hidden_dim + embedding_dim]
mask_num = masked_tmp_ht.shape[0]
self_index_tuple = (torch.arange(mask_num, device=qt.device), masked_qt.long())
self_ht = masked_tmp_ht[self_index_tuple] # [mask_num, hidden_dim + embedding_dim]
self_features = self.f_self(self_ht) # [mask_num, hidden_dim]
expanded_self_ht = self_ht.unsqueeze(dim=1).repeat(1, self.concept_num, 1) #[mask_num, concept_num, hidden_dim + embedding_dim]
neigh_ht = torch.cat((expanded_self_ht, masked_tmp_ht), dim=-1) #[mask_num, concept_num, 2 * (hidden_dim + embedding_dim)]
concept_embedding, rec_embedding, z_prob = None, None, None
if self.graph_type in ['Dense', 'Transition', 'DKT', 'PAM']:
adj = self.graph[masked_qt.long(), :].unsqueeze(dim=-1) # [mask_num, concept_num, 1]
reverse_adj = self.graph[:, masked_qt.long()].transpose(0, 1).unsqueeze(dim=-1) # [mask_num, concept_num, 1]
# self.f_neighbor_list[0](neigh_ht) shape: [mask_num, concept_num, hidden_dim]
neigh_features = adj * self.f_neighbor_list[0](neigh_ht) + reverse_adj * self.f_neighbor_list[1](neigh_ht)
else: # ['MHA', 'VAE']
concept_index = torch.arange(self.concept_num, device=qt.device)
concept_embedding = self.emb_c(concept_index) # [concept_num, embedding_dim]
if self.graph_type == 'MHA':
query = self.emb_c(masked_qt)
key = concept_embedding
att_mask = Variable(torch.ones(self.edge_type_num, mask_num, self.concept_num, device=qt.device))
for k in range(self.edge_type_num):
index_tuple = (torch.arange(mask_num, device=qt.device), masked_qt.long())
att_mask[k] = att_mask[k].index_put(index_tuple, torch.zeros(mask_num, device=qt.device))
graphs = self.graph_model(masked_qt, query, key, att_mask)
else: # self.graph_type == 'VAE'
sp_send, sp_rec, sp_send_t, sp_rec_t = self._get_edges(masked_qt)
graphs, rec_embedding, z_prob = self.graph_model(concept_embedding, sp_send, sp_rec, sp_send_t, sp_rec_t)
neigh_features = 0
for k in range(self.edge_type_num):
adj = graphs[k][masked_qt, :].unsqueeze(dim=-1) # [mask_num, concept_num, 1]
if k == 0:
neigh_features = adj * self.f_neighbor_list[k](neigh_ht)
else:
neigh_features = neigh_features + adj * self.f_neighbor_list[k](neigh_ht)
if self.graph_type == 'MHA':
neigh_features = 1. / self.edge_type_num * neigh_features
# neigh_features: [mask_num, concept_num, hidden_dim]
m_next = tmp_ht[:, :, :self.hidden_dim]
m_next[qt_mask] = neigh_features
m_next[qt_mask] = m_next[qt_mask].index_put(self_index_tuple, self_features)
return m_next, concept_embedding, rec_embedding, z_prob
# Update step, as shown in Section 3.3.2 of the paper
def _update(self, tmp_ht, ht, qt):
r"""
Parameters:
tmp_ht: temporal hidden representations of all concepts after the aggregate step
ht: hidden representations of all concepts at the current timestamp
qt: question indices for all students in a batch at the current timestamp
Shape:
tmp_ht: [batch_size, concept_num, hidden_dim + embedding_dim]
ht: [batch_size, concept_num, hidden_dim]
qt: [batch_size]
h_next: [batch_size, concept_num, hidden_dim]
Return:
h_next: hidden representations of all concepts at the next timestamp
concept_embedding: input of VAE (optional)
rec_embedding: reconstructed input of VAE (optional)
z_prob: probability distribution of latent variable z in VAE (optional)
"""
qt_mask = torch.ne(qt, -1) # [batch_size], qt != -1
mask_num = qt_mask.nonzero().shape[0]
# GNN Aggregation
m_next, concept_embedding, rec_embedding, z_prob = self._agg_neighbors(tmp_ht, qt) # [batch_size, concept_num, hidden_dim]
# Erase & Add Gate
m_next[qt_mask] = self.erase_add_gate(m_next[qt_mask]) # [mask_num, concept_num, hidden_dim]
# GRU
h_next = m_next
res = self.gru(m_next[qt_mask].reshape(-1, self.hidden_dim), ht[qt_mask].reshape(-1, self.hidden_dim)) # [mask_num * concept_num, hidden_num]
index_tuple = (torch.arange(mask_num, device=qt_mask.device), )
h_next[qt_mask] = h_next[qt_mask].index_put(index_tuple, res.reshape(-1, self.concept_num, self.hidden_dim))
return h_next, concept_embedding, rec_embedding, z_prob
# Predict step, as shown in Section 3.3.3 of the paper
def _predict(self, h_next, qt):
r"""
Parameters:
h_next: hidden representations of all concepts at the next timestamp after the update step
qt: question indices for all students in a batch at the current timestamp
Shape:
h_next: [batch_size, concept_num, hidden_dim]
qt: [batch_size]
y: [batch_size, concept_num]
Return:
y: predicted correct probability of all concepts at the next timestamp
"""
qt_mask = torch.ne(qt, -1) # [batch_size], qt != -1
y = self.predict(h_next).squeeze(dim=-1) # [batch_size, concept_num]
y[qt_mask] = torch.sigmoid(y[qt_mask]) # [batch_size, concept_num]
return y
def _get_next_pred(self, yt, q_next):
r"""
Parameters:
yt: predicted correct probability of all concepts at the next timestamp
q_next: question index matrix at the next timestamp
batch_size: the size of a student batch
Shape:
y: [batch_size, concept_num]
questions: [batch_size, seq_len]
pred: [batch_size, ]
Return:
pred: predicted correct probability of the question answered at the next timestamp
"""
next_qt = q_next
next_qt = torch.where(next_qt != -1, next_qt, self.concept_num * torch.ones_like(next_qt, device=yt.device))
one_hot_qt = F.embedding(next_qt.long(), self.one_hot_q) # [batch_size, concept_num]
# dot product between yt and one_hot_qt
pred = (yt * one_hot_qt).sum(dim=1) # [batch_size, ]
return pred
# Get edges for edge inference in VAE
def _get_edges(self, masked_qt):
r"""
Parameters:
masked_qt: qt index with -1 padding values removed
Shape:
masked_qt: [mask_num, ]
rel_send: [edge_num, concept_num]
rel_rec: [edge_num, concept_num]
Return:
rel_send: from nodes in edges which send messages to other nodes
rel_rec: to nodes in edges which receive messages from other nodes
"""
mask_num = masked_qt.shape[0]
row_arr = masked_qt.cpu().numpy().reshape(-1, 1) # [mask_num, 1]
row_arr = np.repeat(row_arr, self.concept_num, axis=1) # [mask_num, concept_num]
col_arr = np.arange(self.concept_num).reshape(1, -1) # [1, concept_num]
col_arr = np.repeat(col_arr, mask_num, axis=0) # [mask_num, concept_num]
# add reversed edges
new_row = np.vstack((row_arr, col_arr)) # [2 * mask_num, concept_num]
new_col = np.vstack((col_arr, row_arr)) # [2 * mask_num, concept_num]
row_arr = new_row.flatten() # [2 * mask_num * concept_num, ]
col_arr = new_col.flatten() # [2 * mask_num * concept_num, ]
data_arr = np.ones(2 * mask_num * self.concept_num)
init_graph = sp.coo_matrix((data_arr, (row_arr, col_arr)), shape=(self.concept_num, self.concept_num))
init_graph.setdiag(0) # remove self-loop edges
row_arr, col_arr, _ = sp.find(init_graph)
row_tensor = torch.from_numpy(row_arr).long()
col_tensor = torch.from_numpy(col_arr).long()
one_hot_table = torch.eye(self.concept_num, self.concept_num)
rel_send = F.embedding(row_tensor, one_hot_table) # [edge_num, concept_num]
rel_rec = F.embedding(col_tensor, one_hot_table) # [edge_num, concept_num]
sp_rec, sp_send = rel_rec.to_sparse(), rel_send.to_sparse()
sp_rec_t, sp_send_t = rel_rec.T.to_sparse(), rel_send.T.to_sparse()
sp_send = sp_send.to(device=masked_qt.device)
sp_rec = sp_rec.to(device=masked_qt.device)
sp_send_t = sp_send_t.to(device=masked_qt.device)
sp_rec_t = sp_rec_t.to(device=masked_qt.device)
return sp_send, sp_rec, sp_send_t, sp_rec_t
def forward(self, features, questions):
r"""
Parameters:
features: input one-hot matrix
questions: question index matrix
seq_len dimension needs padding, because different students may have learning sequences with different lengths.
Shape:
features: [batch_size, seq_len]
questions: [batch_size, seq_len]
pred_res: [batch_size, seq_len - 1]
Return:
pred_res: the correct probability of questions answered at the next timestamp
concept_embedding: input of VAE (optional)
rec_embedding: reconstructed input of VAE (optional)
z_prob: probability distribution of latent variable z in VAE (optional)
"""
batch_size, seq_len = features.shape
ht = Variable(torch.zeros((batch_size, self.concept_num, self.hidden_dim), device=features.device))
pred_list = []
ec_list = [] # concept embedding list in VAE
rec_list = [] # reconstructed embedding list in VAE
z_prob_list = [] # probability distribution of latent variable z in VAE
for i in range(seq_len):
xt = features[:, i] # [batch_size]
qt = questions[:, i] # [batch_size]
qt_mask = torch.ne(qt, -1) # [batch_size], next_qt != -1 确保问题是存在的,ne-not equal(参考链接:https://blog.csdn.net/flyfish1986/article/details/106388548/)
tmp_ht = self._aggregate(xt, qt, ht, batch_size) # [batch_size, concept_num, hidden_dim + embedding_dim]
h_next, concept_embedding, rec_embedding, z_prob = self._update(tmp_ht, ht, qt) # [batch_size, concept_num, hidden_dim]
ht[qt_mask] = h_next[qt_mask] # update new ht
yt = self._predict(h_next, qt) # [batch_size, concept_num]
if i < seq_len - 1:
pred = self._get_next_pred(yt, questions[:, i + 1])
pred_list.append(pred)
ec_list.append(concept_embedding)
rec_list.append(rec_embedding)
z_prob_list.append(z_prob)
pred_res = torch.stack(pred_list, dim=1) # [batch_size, seq_len - 1]
return pred_res, ec_list, rec_list, z_prob_list
介绍DKT中的forward()部分
class DKT(nn.Module):
def _get_next_pred(self, yt, questions):
r"""
Parameters:
y: predicted correct probability of all concepts at the next timestamp
questions: question index matrix
Shape:
y: [batch_size, seq_len - 1, output_dim]
questions: [batch_size, seq_len]
pred: [batch_size, ]
Return:
pred: predicted correct probability of the question answered at the next timestamp
"""
one_hot = torch.eye(self.output_dim, device=yt.device)
one_hot = torch.cat((one_hot, torch.zeros(1, self.output_dim, device=yt.device)), dim=0)
next_qt = questions[:, 1:]
next_qt = torch.where(next_qt != -1, next_qt, self.output_dim * torch.ones_like(next_qt, device=yt.device)) # [batch_size, seq_len - 1]
one_hot_qt = F.embedding(next_qt, one_hot) # [batch_size, seq_len - 1, output_dim]
# dot product between yt and one_hot_qt
pred = (yt * one_hot_qt).sum(dim=-1) # [batch_size, seq_len - 1]
return pred
def forward(self, features, questions):
r"""
Parameters:
features: input one-hot matrix
questions: question index matrix
seq_len dimension needs padding, because different students may have learning sequences with different lengths.
Shape:
features: [batch_size, seq_len]
questions: [batch_size, seq_len]
pred_res: [batch_size, seq_len - 1]
Return:
pred_res: the correct probability of questions answered at the next timestamp
concept_embedding: input of VAE (optional)
rec_embedding: reconstructed input of VAE (optional)
z_prob: probability distribution of latent variable z in VAE (optional)
"""
feat_one_hot = torch.eye(self.feature_dim, device=features.device)
feat_one_hot = torch.cat((feat_one_hot, torch.zeros(1, self.feature_dim, device=features.device)), dim=0)
feat = torch.where(features != -1, features, self.feature_dim * torch.ones_like(features, device=features.device)) # torch.where()函数的作用是按照一定的规则合并两个tensor类型,
# torch.where(condition, x, y):
# condition:判断条件
# x:若满足条件,则取x中元素
# y:若不满足条件,则取y中元素
# 参考链接:https://blog.csdn.net/tszupup/article/details/108130366
# torch.ones_like:返回一个填充了标量值1的张量
# 参考链接:https://blog.csdn.net/weixin_42797179/article/details/86773923
features = F.embedding(feat, feat_one_hot)
feature_lens = torch.ne(questions, -1).sum(dim=1) # padding value = -1
# Pytorch中的RNN之pack_padded_sequence()和pad_packed_sequence() 参考链接:https://www.cnblogs.com/sbj123456789/p/9834018.html
x_packed = pack_padded_sequence(features, feature_lens, batch_first=True, enforce_sorted=False)
output_packed, _ = self.rnn(x_packed) # [batch, seq_len, hidden_dim]
output_padded, output_lengths = pad_packed_sequence(output_packed, batch_first=True) # [batch, seq_len, hidden_dim]
yt = self.f_out(output_padded) # [batch, seq_len, output_dim]
yt = torch.sigmoid(yt)
yt = yt[:, :-1, :] # [batch, seq_len - 1, output_dim]
pred_res = self._get_next_pred(yt, questions) # [batch, seq_len - 1]
return pred_res
layers.py
class MLP(nn.Module):
"""Two-layer fully-connected ReLU net with batch norm."""
def __init__(self, input_dim, hidden_dim, output_dim, dropout=0., bias=True):
super(MLP, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim, bias=bias)
self.fc2 = nn.Linear(hidden_dim, output_dim, bias=bias)
self.norm = nn.BatchNorm1d(output_dim)
# the paper said they added Batch Normalization for the output of MLPs, as shown in Section 4.2
self.dropout = dropout
self.output_dim = output_dim
self.init_weights()
# 自定义初始化参数,效率会比较高
# 参考链接:https://blog.csdn.net/weixin_41680653/article/details/93977189
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Linear):
# 使用isinstance来判断m属于什么类型
nn.init.xavier_normal_(m.weight.data)
# xavier和其它初始化的介绍:https://blog.csdn.net/mzpmzk/article/details/79839047
m.bias.data.fill_(0.1)
elif isinstance(m, nn.BatchNorm1d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def batch_norm(self, inputs):
if inputs.numel() == self.output_dim or inputs.numel() == 0:
# batch_size == 1 or 0 will cause BatchNorm error, so return the input directly
return inputs
if len(inputs.size()) == 3:
x = inputs.view(inputs.size(0) * inputs.size(1), -1)
x = self.norm(x)
return x.view(inputs.size(0), inputs.size(1), -1)
else: # len(input_size()) == 2
return self.norm(inputs)
def forward(self, inputs):
x = F.relu(self.fc1(inputs))
x = F.dropout(x, self.dropout, training=self.training) # pay attention to add training=self.training
x = F.relu(self.fc2(x))
return self.batch_norm(x)














 3859
3859











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









