







开发工具:python2.7
主要是用的库:urllib2
爬取对象:12306购票系统
1、首先我们的任务是选取合适的网页入口,打开12306官网:
我们先试试进入余票查询:
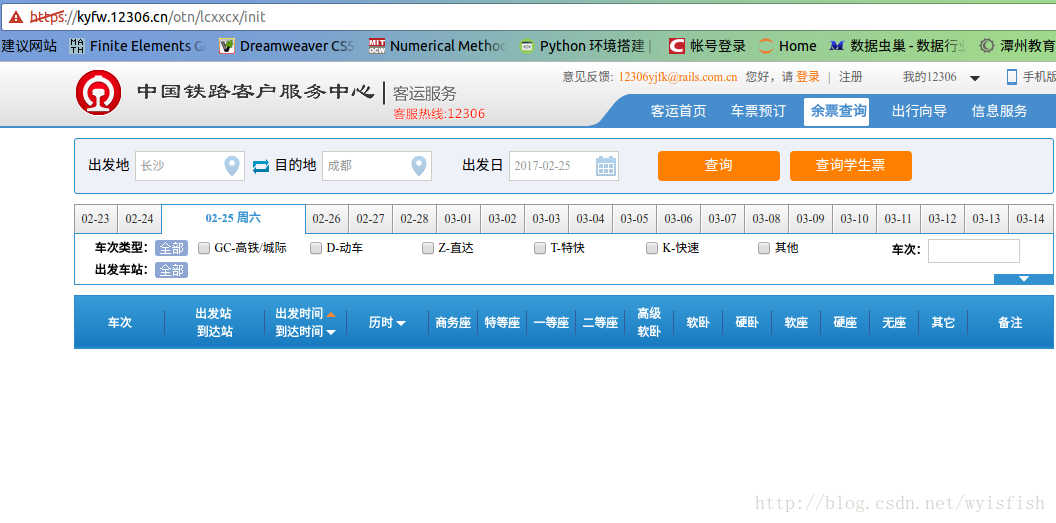
第一次进入这个网站我们发现报错了,在网址http处红色显示证书不符合要求,我们暂时忽略。点击查询按钮,这时候我们看到页面并没有变化。我们按F12进入开发者工具看看:
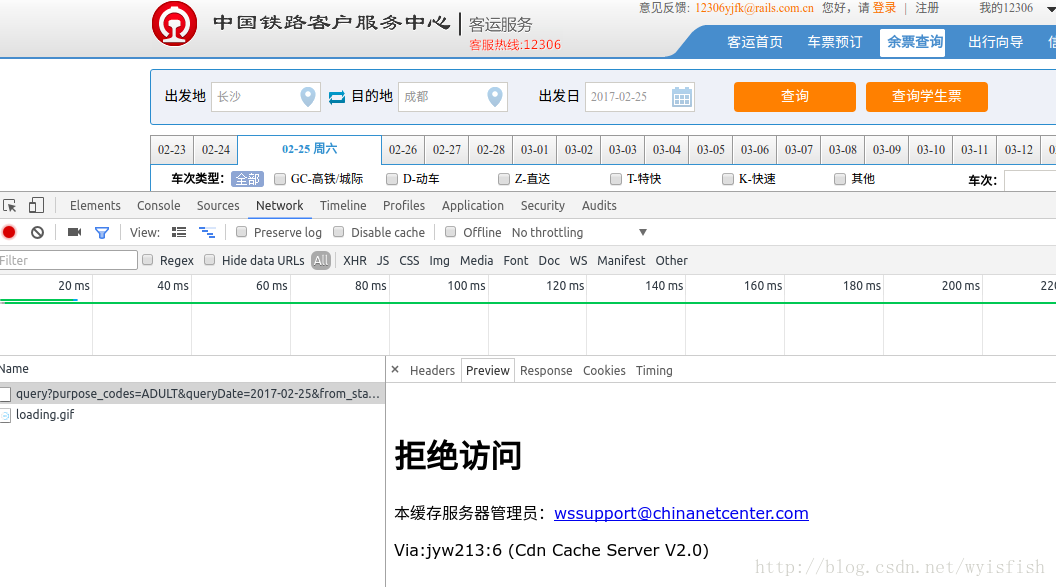
我们进入Network选项,再次点击查询发现下方显示拒绝访问,看来我们无法从这个接口进入网站。
我们返回之前的页面点击购票:
再次点击查询,这下我们看到了我们查询的结果,url=https://kyfw.12306.cn/otn/leftTicket/init。
然后我们用代码来抓取一下这个url:
import urllib2
#我们定义一个函数来抓取这个网站
def getList():
url='https://kyfw.12306.cn/otn/leftTicket/init'
req = urllib2.urlopen(url)
html = req.read()#获取网站源代码数据
#print html
getList() #我们尝试打印出来看看
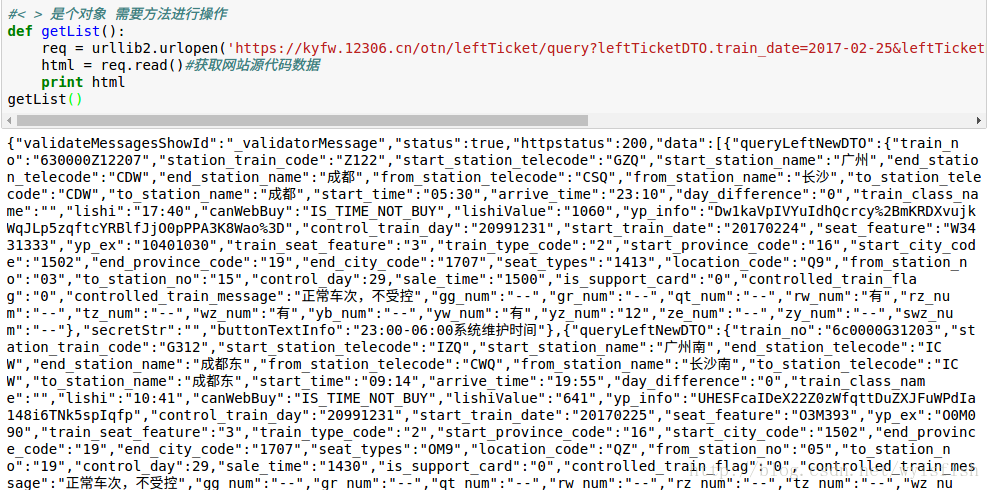
显示是一大长串的json文件。
print type(html)
type ‘str’
我们现在把str转换成python能处理的dict
import json
dict = json.loads(html)下面我们通过F12开发者工具查看我们需要的车辆信息在什么地方。
通过一番查找我们发现我们需要的信息:
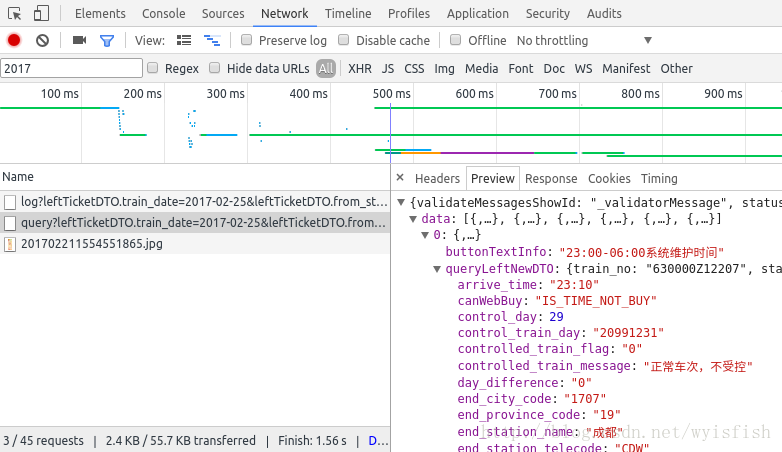
我们通过对比可以看到我们为难刚才打印出来的网页信息与我们在F12中找到的是吻合的。我们想要的信息都在data里的键值对里。
2、我们提取我们想要的信息:
import urllib2
import ssl
import json
import time
ssl._create_default_https_context = ssl._create_unverified_context
#关闭证书验证
#< > 是个对象 需要方法进行操作
def getList():
req = urllib2.urlopen('https://kyfw.12306.cn/otn/leftTicket/query?leftTicketDTO.train_date=2017-02-25&leftTicketDTO.from_station=CSQ&leftTicketDTO.to_station=CDW&purpose_codes=ADULT')#打开网页
html = req.read()#获取网站源代码数据
dict = json.loads(html)#把str转换成python能处理的dict
return dict['data']
list_s = getList()
#for i in list_s:
print i['queryLeftNewDTO']['station_train_code'] + '*********' + i['queryLeftNewDTO']['swz_num']+'*****' +i['queryLeftNewDTO']['start_time'] 打印出车辆信息、票数以及发车时间ps:这里需要提到一点,我们在运行代码过程中可能无法打开网页,主要是证书无法识别的原因,我们用ssl库关掉证书认证就可以正常访问网页了。
运行结果:

3、实现电话短信提醒
4、完成验证登陆,自动购买车票
上面两点还没完成,待续。。。















 3528
3528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









