







HBase之五:hbase的region分区
一、Region 概念
Region是表获取和分布的基本元素,由每个列族的一个Store组成。对象层级图如下:
Table (HBase table)
Region (Regions for the table)
Store (Store per ColumnFamily for each Region for the table)
MemStore (MemStore for each Store for each Region for the table)
StoreFile (StoreFiles for each Store for each Region for the table)
Block (Blocks within a StoreFile within a Store for each Region for the table)
Region 大小
Region的大小是一个棘手的问题,需要考量如下几个因素。
- Region是HBase中分布式存储和负载均衡的最小单元。不同Region分布到不同RegionServer上,但并不是存储的最小单元。
- Region由一个或者多个Store组成,每个store保存一个columns family,每个Strore又由一个memStore和0至多个StoreFile 组成。memStore存储在内存中, StoreFile存储在HDFS上。
- HBase通过将region切分在许多机器上实现分布式。也就是说,你如果有16GB的数据,只分了2个region, 你却有20台机器,有18台就浪费了。
- region数目太多就会造成性能下降,现在比以前好多了。但是对于同样大小的数据,700个region比3000个要好。
- region数目太少就会妨碍可扩展性,降低并行能力。有的时候导致压力不够分散。这就是为什么,你向一个10节点的HBase集群导入200MB的数据,大部分的节点是idle的。
- RegionServer中1个region和10个region索引需要的内存量没有太多的差别。
最好是使用默认的配置,可以把热的表配小一点(或者受到split热点的region把压力分散到集群中)。如果你的cell的大小比较大(100KB或更大),就可以把region的大小调到1GB。region的最大大小在hbase配置文件中定义:
<property>
<name>hbase.hregion.max.filesize</name>
<value>10 * 1024 * 1024 * 1024</value>
</property>
说明:
- 当region中的StoreFile大小超过了上面配置的值的时候,该region就会被拆分,具体的拆分策略见下文。
- 上面的值也可以针对每个表单独设置,例如在hbase shell中设置:
create 't','f' disable 't' alter 't', METHOD => 'table_att', MAX_FILESIZE => '134217728' enable 't'
Region 拆分策略
Region的分割操作是不可见的,因为Master不会参与其中。RegionServer拆分region的步骤是,先将该region下线,然后拆分,将其子region加入到META元信息中,再将他们加入到原本的RegionServer中,最后汇报Master。
执行split的线程是CompactSplitThread。
自定义拆分策略
可以通过设置RegionSplitPolicy的实现类来指定拆分策略,RegionSplitPolicy类的实现类有:
ConstantSizeRegionSplitPolicy
IncreasingToUpperBoundRegionSplitPolicy
DelimitedKeyPrefixRegionSplitPolicy
KeyPrefixRegionSplitPolicy
对于split,并不是设置了hbase.hregion.max.filesize(默认10G)为很大就保证不split了,需要有以下的算法:
- IncreasingToUpperBoundRegionSplitPolicy,0.94.0默认region split策略。根据公式min(r^2*flushSize,maxFileSize)确定split的maxFileSize,其中r为在线region个数,maxFileSize由
hbase.hregion.max.filesize指定。 - ConstantSizeRegionSplitPolicy,仅仅当region大小超过常量值(
hbase.hregion.max.filesize大小)时,才进行拆分。 - DelimitedKeyPrefixRegionSplitPolicy,保证以分隔符前面的前缀为splitPoint,保证相同RowKey前缀的数据在一个Region中
- KeyPrefixRegionSplitPolicy,保证具有相同前缀的row在一个region中(要求设计中前缀具有同样长度)。指定rowkey前缀位数划分region,通过读取
table的prefix_split_key_policy.prefix_length属性,该属性为数字类型,表示前缀长度,在进行split时,按此长度对splitPoint进行截取。此种策略比较适合固定前缀的rowkey。当table中没有设置该属性,或其属性不为Integer类型时,指定此策略效果等同与使用IncreasingToUpperBoundRegionSplitPolicy。
IncreasingToUpperBoundRegionSplitPolicy
这是0.94.0默认region split策略。根据根据公式min(r^2*flushSize,maxFileSize)确定split的maxFileSize,这里假设flushSize为128M:
第一次拆分大小为:min(10G,1*1*128M)=128M
第二次拆分大小为:min(10G,3*3*128M)=1152M
第三次拆分大小为:min(10G,5*5*128M)=3200M
第四次拆分大小为:min(10G,7*7*128M)=6272M
第五次拆分大小为:min(10G,9*9*128M)=10G
第五次拆分大小为:min(10G,11*11*128M)=10G
可以看到,只有在第五次之后的拆分大小才为10G
配置拆分策略
你可以在hbase配置文件中定义全局的拆分策略,设置hbase.regionserver.region.split.policy的值即可,也可以在创建和修改表时候指定:

// 更新现有表的split策略
HBaseAdmin admin = new HBaseAdmin( conf);
HTable hTable = new HTable( conf, "test" );
HTableDescriptor htd = hTable.getTableDescriptor();
HTableDescriptor newHtd = new HTableDescriptor(htd);
newHtd.setValue(HTableDescriptor. SPLIT_POLICY, KeyPrefixRegionSplitPolicy.class.getName());// 指定策略
newHtd.setValue("prefix_split_key_policy.prefix_length", "2");
newHtd.setValue("MEMSTORE_FLUSHSIZE", "5242880"); // 5M
admin.disableTable( "test");
admin.modifyTable(Bytes. toBytes("test"), newHtd);
admin.enableTable( "test");
说明:
- 上面的不同策略可以在不同的业务场景下使用,特别是第三种和第四种一般关注和使用的比较少。
- 如果想关闭自动拆分改为手动拆分,建议同时修改
hbase.hregion.max.filesize和hbase.regionserver.region.split.policy值。
二、hbase预分区示例
步骤:
1.规划hbase预分区
首先就是要想明白数据的key是如何分布的,然后规划一下要分成多少region,每个region的startkey和endkey是多少,然后将规划的key写到一个文件中。比如,key的前几位字符串都是从0001~0010的数字,这样可以分成10个region,划分key的文件如下:
0001| 0002| 0003| 0004| 0005| 0006| 0007| 0008| 0009|
为什么后面会跟着一个”|”,是因为在ASCII码中,”|”的值是124,大于所有的数字和字母等符号,当然也可以用“~”(ASCII-126)。分隔文件的第一行为第一个region的stopkey,每行依次类推,最后一行不仅是倒数第二个region的stopkey,同时也是最后一个region的startkey。也就是说分区文件中填的都是key取值范围的分隔点,如下图所示:

2.hbase shell中建分区表,指定分区文件
在hbase shell中直接输入create,会看到如下的提示:
Create a table with namespace=ns1 and table qualifier=t1
hbase> create 'ns1:t1', {NAME => 'f1', VERSIONS => 5}
Create a table with namespace=default and table qualifier=t1
hbase> create 't1', {NAME => 'f1'}, {NAME => 'f2'}, {NAME => 'f3'}
hbase> # The above in shorthand would be the following:
hbase> create 't1', 'f1', 'f2', 'f3'
hbase> create 't1', {NAME => 'f1', VERSIONS => 1, TTL => 2592000, BLOCKCACHE => true}
hbase> create 't1', {NAME => 'f1', CONFIGURATION => {'hbase.hstore.blockingStoreFiles' => '10'}}
Table configuration options can be put at the end.
Examples:
hbase> create 'ns1:t1', 'f1', SPLITS => ['10', '20', '30', '40']
hbase> create 't1', 'f1', SPLITS => ['10', '20', '30', '40']
hbase> create 't1', 'f1', SPLITS_FILE => 'splits.txt', OWNER => 'johndoe'
hbase> create 't1', {NAME => 'f1', VERSIONS => 5}, METADATA => { 'mykey' => 'myvalue' }
hbase> # Optionally pre-split the table into NUMREGIONS, using
hbase> # SPLITALGO ("HexStringSplit", "UniformSplit" or classname)
hbase> create 't1', 'f1', {NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}
hbase> create 't1', 'f1', {NUMREGIONS => 15, SPLITALGO => 'HexStringSplit', CONFIGURATION => {'hbase.hregion.scan.loadColumnFamiliesOnDemand' => 'true'}}
hbase> create 't1', {NAME => 'f1'}, {NAME => 'if1', LOCAL_INDEX=>'COMBINE_INDEX|INDEXED=f1:q1:8|rowKey:rowKey:10,UPDATE=true'}
可以通过指定SPLITS_FILE的值指定分区文件,如果分区信息比较少,也可以直接用SPLITS分区。我们可以通过如下命令建一个分区表,指定第一步中生成的分区文件:
假如我还想对hbase表做一个SNAPPY压缩,应该怎么写呢?
-
create 'split_table_test',{NAME =>'cf', COMPRESSION => 'SNAPPY'}, {SPLITS_FILE => 'region_split_info.txt'}
这里注意,一定要将分区的参数指定单独用一个大括号扩起来,因为分区是针对全表,而不是针对某一个column family。
下面,我们登陆一下master的web页面<Hmaster:60010>,查看一下hbase的表信息,找到刚刚新建的预分区表,进入查看region信息:
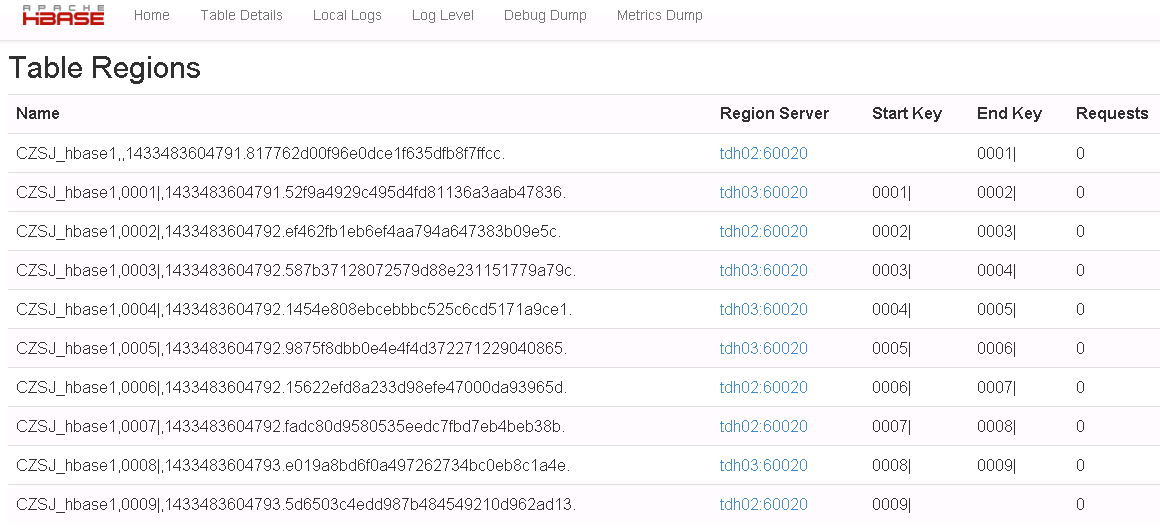
我们看到第一个region是没有startkey的,最后一个region是没有stopkey的。
三、hbase预分区方案
在HBase中,表会被划分为1…n个Region,被托管在RegionServer中。Region二个重要的属性:StartKey与EndKey表示这个Region维护的rowKey范围,当我们要读/写数据时,如果rowKey落在某个start-end key范围内,那么就会定位到目标region并且读/写到相关的数据。
1、由于业务数据一般都是从小到大增长的,根据上面hbase的region规则,就会出现“热点写”问题,随着系统的运营,数据总是会往最大的start-key所在的region里写,因为我们的rowkey总是会比之前的大,并且hbase的是按升序方式排序的。所以写操作总是被定位到无上界的那个region中。
2、其次,由于写热点,我们总是往最大start-key的region写记录,之前分裂出来的region不会再被写数据,有点被打进冷宫的赶脚,它们都处于半满状态,这样的分布也是不利的。
如果在写比较频率的场景下,数据增长快,split的次数也会增多,由于split是比较耗时耗资源的,所以我们并不希望这种事情经常发生。
看到这些缺点,我们知道,在集群的环境中,为了得到更好的并行性,我们希望有好的load blance,让每个节点提供的请求处理都是均等的。我们也希望,region不要经常split,因为split会使server有一段时间的停顿,如何能做到呢?
随机散列与预分区
随机散列与预分区:二者结合起来,是比较完美的,预分区一开始就预建好了一部分region,这些region都维护着自已的start-end keys,再配合上随机散列,写数据能均等地命中这些预建的region,就能解决上面的那些缺点,大大地提高了性能。
提供2种思路: hash与partition.
- hash就是rowkey前面由一串随机字符串组成,随机字符串生成方式可以由SHA或者MD5等方式生成,只要region所管理的start-end keys范围比较随机,那么就可以解决写热点问题。
long currentId = 1L; byte [] rowkey = Bytes.add(MD5Hash.getMD5AsHex(Bytes.toBytes(currentId)).substring(0, 8).getBytes(), Bytes.toBytes(currentId));
假设rowKey原本是自增长的long型,可以将rowkey转为hash再转为bytes,加上本身id 转为bytes,组成rowkey,这样就生成随便的rowkey。那么对于这种方式的rowkey设计,如何去进行预分区呢?
1.取样,先随机生成一定数量的rowkey,将取样数据按升序排序放到一个集合里
2.根据预分区的region个数,对整个集合平均分割,即是相关的splitKeys.
3.HBaseAdmin.createTable(HTableDescriptor tableDescriptor,byte[][] splitkeys)可以指定预分区的splitKey,即是指定region间的rowkey临界值.
首先是热点写,我们总是会往最大的start-key所在的region写东西,因为我们的rowkey总是会比之前的大,并且hbase的是按升序方式排序的。所以写操作总是被定位到无上界的那个region中。
其次,由于写热点,我们总是往最大start-key的region写记录,之前分裂出来的region不会再被写数据,有点被打进冷宫的赶脚,它们都处于半满状态,这样的分布也是不利的。
如果在写比较频率的场景下,数据增长快,split的次数也会增多,由于split是比较耗时耗资源的,所以我们并不希望这种事情经常发生。
…………
看到这些缺点,我们知道,在集群的环境中,为了得到更好的并行性,我们希望有好的load blance,让每个节点提供的请求处理都是均等的。我们也希望,region不要经常split,因为split会使server有一段时间的停顿,如何能做到呢?
随机散列与预分区。二者结合起来,是比较完美的,预分区一开始就预建好了一部分region,这些region都维护着自已的start-end keys,再配合上随机散列,写数据能均等地命中这些预建的region,就能解决上面的那些缺点,大大地提高了性能。
提供2种思路: hash 与 partition.
一、hash思路
hash就是rowkey前面由一串随机字符串组成,随机字符串生成方式可以由SHA或者MD5等方式生成,只要region所管理的start-end keys范围比较随机,那么就可以解决写热点问题。
long currentId = 1L;
byte [] rowkey = Bytes.add(MD5Hash.getMD5AsHex(Bytes.toBytes(currentId)).substring(0, 8).getBytes(),
Bytes.toBytes(currentId));
假设rowKey原本是自增长的long型,可以将rowkey转为hash再转为bytes,加上本身id 转为bytes,组成rowkey,这样就生成随便的rowkey。那么对于这种方式的rowkey设计,如何去进行预分区呢?
1.取样,先随机生成一定数量的rowkey,将取样数据按升序排序放到一个集合里
2.根据预分区的region个数,对整个集合平均分割,即是相关的splitKeys.
3.HBaseAdmin.createTable(HTableDescriptor tableDescriptor,byte[][] splitkeys)可以指定预分区的splitKey,即是指定region间的rowkey临界值.
如果知道Hbase数据表的key的分布情况,就可以在建表的时候对hbase进行region的预分区。这样做的好处是防止大数据量插入的热点问题,提高数据插入的效率。
步骤:
1.创建split计算器,用于从抽样数据中生成一个比较合适的splitKeys
public class HashChoreWoker implements SplitKeysCalculator{
//随机取机数目
private int baseRecord;
//rowkey生成器
private RowKeyGenerator rkGen;
//取样时,由取样数目及region数相除所得的数量.
private int splitKeysBase;
//splitkeys个数
private int splitKeysNumber;
//由抽样计算出来的splitkeys结果
private byte[][] splitKeys;
public HashChoreWoker(int baseRecord, int prepareRegions) {
this.baseRecord = baseRecord;
//实例化rowkey生成器
rkGen = new HashRowKeyGenerator();
splitKeysNumber = prepareRegions - 1;
splitKeysBase = baseRecord / prepareRegions;
}
public byte[][] calcSplitKeys() {
splitKeys = new byte[splitKeysNumber][];
//使用treeset保存抽样数据,已排序过
TreeSet<byte[]> rows = new TreeSet<byte[]>(Bytes.BYTES_COMPARATOR);
for (int i = 0; i < baseRecord; i++) {
rows.add(rkGen.nextId());
}
int pointer = 0;
Iterator<byte[]> rowKeyIter = rows.iterator();
int index = 0;
while (rowKeyIter.hasNext()) {
byte[] tempRow = rowKeyIter.next();
rowKeyIter.remove();
if ((pointer != 0) && (pointer % splitKeysBase == 0)) {
if (index < splitKeysNumber) {
splitKeys[index] = tempRow;
index ++;
}
}
pointer ++;
}
rows.clear();
rows = null;
return splitKeys;
}
}
KeyGenerator及实现
//interface
public interface RowKeyGenerator {
byte [] nextId();
}
//implements
public class HashRowKeyGenerator implements RowKeyGenerator {
private long currentId = 1;
private long currentTime = System.currentTimeMillis();
private Random random = new Random();
public byte[] nextId() {
try {
currentTime += random.nextInt(1000);
byte[] lowT = Bytes.copy(Bytes.toBytes(currentTime), 4, 4);
byte[] lowU = Bytes.copy(Bytes.toBytes(currentId), 4, 4);
return Bytes.add(MD5Hash.getMD5AsHex(Bytes.add(lowU, lowT)).substring(0, 8).getBytes(),
Bytes.toBytes(currentId));
} finally {
currentId++;
}
}
}
unit test case测试
@Test
public void testHashAndCreateTable() throws Exception{
HashChoreWoker worker = new HashChoreWoker(1000000,10);
byte [][] splitKeys = worker.calcSplitKeys();
HBaseAdmin admin = new HBaseAdmin(HBaseConfiguration.create());
TableName tableName = TableName.valueOf("hash_split_table");
if (admin.tableExists(tableName)) {
try {
admin.disableTable(tableName);
} catch (Exception e) {
}
admin.deleteTable(tableName);
}
HTableDescriptor tableDesc = new HTableDescriptor(tableName);
HColumnDescriptor columnDesc = new HColumnDescriptor(Bytes.toBytes("info"));
columnDesc.setMaxVersions(1);
tableDesc.addFamily(columnDesc);
admin.createTable(tableDesc ,splitKeys);
admin.close();
}
查看建表结果:执行 scan ‘hbase:meta’

以上我们只是显示了部分region的信息,可以看到region的start-end key 还是比较随机散列的。同样可以查看hdfs的目录结构,的确和预期的38个预分区一致:

以上,就已经按hash方式,预建好了分区,以后在插入数据的时候,也要按照此rowkeyGenerator的方式生成rowkey,有兴趣的话,也可以做些试验,插入些数据,看看数据的分布。
二、partition
partition故名思义,就是分区式,这种分区有点类似于mapreduce中的partitioner,将区域用长整数(Long)作为分区号,每个region管理着相应的区域数据,在rowKey生成时,将id取模后,然后拼上id整体作为rowKey.这个比较简单,不需要取样,splitKeys也非常简单,直接是分区号即可。直接上代码吧:
public class PartitionRowKeyManager implements RowKeyGenerator,
SplitKeysCalculator {
public static final int DEFAULT_PARTITION_AMOUNT = 20;
private long currentId = 1;
private int partition = DEFAULT_PARTITION_AMOUNT;
public void setPartition(int partition) {
this.partition = partition;
}
public byte[] nextId() {
try {
long partitionId = currentId % partition;
return Bytes.add(Bytes.toBytes(partitionId),
Bytes.toBytes(currentId));
} finally {
currentId++;
}
}
public byte[][] calcSplitKeys() {
byte[][] splitKeys = new byte[partition - 1][];
for(int i = 1; i < partition ; i ++) {
splitKeys[i-1] = Bytes.toBytes((long)i);
}
return splitKeys;
}
}
calcSplitKeys方法比较单纯,splitKey就是partition的编号,我们看看测试类:
@Test
public void testPartitionAndCreateTable() throws Exception{
PartitionRowKeyManager rkManager = new PartitionRowKeyManager();
//只预建10个分区
rkManager.setPartition(10);
byte [][] splitKeys = rkManager.calcSplitKeys();
HBaseAdmin admin = new HBaseAdmin(HBaseConfiguration.create());
TableName tableName = TableName.valueOf("partition_split_table");
if (admin.tableExists(tableName)) {
try {
admin.disableTable(tableName);
} catch (Exception e) {
}
admin.deleteTable(tableName);
}
HTableDescriptor tableDesc = new HTableDescriptor(tableName);
HColumnDescriptor columnDesc = new HColumnDescriptor(Bytes.toBytes("info"));
columnDesc.setMaxVersions(1);
tableDesc.addFamily(columnDesc);
admin.createTable(tableDesc ,splitKeys);
admin.close();
}
同样我们可以看看meta表和hdfs的目录结果,其实和hash类似,region都会分好区,在这里就不上图了。
三、总结
通过partition实现的loadblance写的话,当然生成rowkey方式也要结合当前的region数目取模而求得,大家同样也可以做些实验,看看数据插入后的分布。
在这里也顺提一下,如果是顺序的增长型原id,可以将id保存到一个数据库,传统的也好,redis的也好,每次取的时候,将数值设大1000左右,以后id可以在内存内增长,当内存数量已经超过1000的话,再去load下一个,有点类似于oracle中的sqeuence.
随机分布加预分区也不是一劳永逸的。因为数据是不断地增长的,随着时间不断地推移,已经分好的区域,或许已经装不住更多的数据,当然就要进一步进行split了,同样也会出现性能损耗问题,所以我们还是要规划好数据增长速率,观察好数据定期维护,按需分析是否要进一步分行手工将分区再分好,也或者是更严重的是新建表,做好更大的预分区然后进行数据迁移。小吴只是菜鸟,运维方面也只是自已这样认为而已,供大家作简单的参考吧。如果数据装不住了,对于partition方式预分区的话,如果让它自然分裂的话,情况分严重一点。因为分裂出来的分区号会是一样的,所以计算到partitionId的话,其实还是回到了顺序写年代,会有部分热点写问题出现,如果使用partition方式生成主键的话,数据增长后就要不断地调整分区了,比如增多预分区,或者加入子分区号的处理.(我们的分区号为long型,可以将它作为多级partition)
OK,写到这里,基本已经讲完了防止热点写使用的方法和防止频繁split而采取的预分区。但rowkey设计,远远也不止这些,比如rowkey长度,然后它的长度最大可以为char的MAXVALUE,但是看过之前我写KeyValue的分析知道,我们的数据都是以KeyValue方式存储在MemStore或者HFile中的,每个KeyValue都会存储rowKey的信息,如果rowkey太大的话,比如是128个字节,一行10个字段的表,100万行记录,光rowkey就占了1.2G+所以长度还是不要过长,另外设计,还是按需求来吧。
最后题外话是我想分享我在github中建了一个project,希望做一些hbase一些工具:https://github.com/bdifn/hbase-tools,如果本地装了git的话,可以执行命令: git clone https://github.com/bdifn/hbase-tools.git目前加了一个region-helper子项目,也是目前唯一的一个子项目,项目使用maven管理,主要目的是帮助我们设计rowkey做一些参考,比如我们设计的随机写和预分区测试,提供了抽样的功能,提供了检测随机写的功能,然后统计按目前rowkey设计,随机写n条记录后,统计每个region的记录数,然后显示比例等。
测试仿真模块我程为simualtor,主要是模拟hbase的region行为,simple的实现,仅仅是上面提到的预测我们rowkey设计后,建好预分区后,写数据的的分布比例,而emulation是比较逼真的仿真,设想是我们写数据时,会统计数目的大小,根据我们的hbase-site.xml设定,模拟memStore行为,模拟hfile的行为,最终会生成一份表的报表,比如分区的数据大小,是否split了,等等,以供我们去设计hbase表时有一个参考,但是遗憾的是,由于时间关系,我只花了一点业余时间简单搭了一下框架,目前没有更一步的实现,以后有时间再加以完善,当然也欢迎大家一起加入,一起学习吧。

项目使用maven管理,为了方便测试,一些组件的实例化,我使用了java的SPI,download源码后,如果想测试自已的rowKeyGeneator的话,打开com.bdifn.hbasetools.regionhelper.rowkey.RowKeyGenerator文件后,替换到你们的ID生成器就可以了。如果是hash的话,抽样和测试等,都是可以复用的。
如测试代码:

public class HBaseSimulatorTest {
//通过SPI方式获取HBaseSimulator实例,SPI的实现为simgple
private HBaseSimulator hbase = BeanFactory.getInstance().getBeanInstance(HBaseSimulator.class);
//获取RowKeyGenerator实例,SPI的实现为hashRowkey
private RowKeyGenerator rkGen = BeanFactory.getInstance().getBeanInstance(RowKeyGenerator.class);
//初如化苦工,去检测100w个抽样rowkey,然后生成一组splitKeys
HashChoreWoker worker = new HashChoreWoker(1000000,10);
@Test
public void testHash(){
byte [][] splitKeys = worker.calcSplitKeys();
hbase.createTable("user", splitKeys);
//插入1亿条记录,看数据分布
TableName tableName = TableName.valueOf("user");
for(int i = 0; i < 100000000; i ++) {
Put put = new Put(rkGen.nextId());
hbase.put(tableName, put);
}
hbase.report(tableName);
}
@Test
public void testPartition(){
//default 20 partitions.
PartitionRowKeyManager rkManager = new PartitionRowKeyManager();
byte [][] splitKeys = rkManager.calcSplitKeys();
hbase.createTable("person", splitKeys);
TableName tableName = TableName.valueOf("person");
//插入1亿条记录,看数据分布
for(int i = 0; i < 100000000; i ++) {
Put put = new Put(rkManager.nextId());
hbase.put(tableName, put);
}
hbase.report(tableName);
}
}
执行结果:
Execution Reprort:[StartRowkey:puts requsts:(put ratio)] :9973569:(1.0015434) 1986344a\x00\x00\x00\x00\x00\x01\x0E\xAE:9999295:(1.0041268) 331ee65f\x00\x00\x00\x00\x00\x0F)g:10012532:(1.005456) 4cbfd4f6\x00\x00\x00\x00\x00\x00o0:9975842:(1.0017716) 664c6388\x00\x00\x00\x00\x00\x02\x1Du:10053337:(1.0095537) 800945e0\x00\x00\x00\x00\x00\x01\xADV:9998719:(1.0040689) 99a158d9\x00\x00\x00\x00\x00\x0BZ\xF3:10000563:(1.0042541) b33a2223\x00\x00\x00\x00\x00\x07\xC6\xE6:9964921:(1.000675) ccbcf370\x00\x00\x00\x00\x00\x00*\xE2:9958200:(1.0) e63b8334\x00\x00\x00\x00\x00\x03g\xC1:10063022:(1.0105262) total requests:100000000 Execution Reprort:[StartRowkey:puts requsts:(put ratio)] :5000000:(1.0) \x00\x00\x00\x00\x00\x00\x00\x01:5000000:(1.0) \x00\x00\x00\x00\x00\x00\x00\x02:5000000:(1.0) \x00\x00\x00\x00\x00\x00\x00\x03:5000000:(1.0) \x00\x00\x00\x00\x00\x00\x00\x04:5000000:(1.0) \x00\x00\x00\x00\x00\x00\x00\x05:5000000:(1.0) \x00\x00\x00\x00\x00\x00\x00\x06:5000000:(1.0) \x00\x00\x00\x00\x00\x00\x00\x07:5000000:(1.0) \x00\x00\x00\x00\x00\x00\x00\x08:5000000:(1.0) \x00\x00\x00\x00\x00\x00\x00\x09:5000000:(1.0) \x00\x00\x00\x00\x00\x00\x00\x0A:5000000:(1.0) \x00\x00\x00\x00\x00\x00\x00\x0B:5000000:(1.0) \x00\x00\x00\x00\x00\x00\x00\x0C:5000000:(1.0) \x00\x00\x00\x00\x00\x00\x00\x0D:5000000:(1.0) \x00\x00\x00\x00\x00\x00\x00\x0E:5000000:(1.0) \x00\x00\x00\x00\x00\x00\x00\x0F:5000000:(1.0) \x00\x00\x00\x00\x00\x00\x00\x10:5000000:(1.0) \x00\x00\x00\x00\x00\x00\x00\x11:5000000:(1.0) \x00\x00\x00\x00\x00\x00\x00\x12:5000000:(1.0) \x00\x00\x00\x00\x00\x00\x00\x13:5000000:(1.0) total requests:100000000


<div class="postDesc">posted on <span id="post-date">2013-06-25 13:10</span> <a href="http://www.cnblogs.com/duanxz/">duanxz</a> 阅读(<span id="post_view_count">2342</span>) 评论(<span id="post_comment_count">0</span>) <a href="https://i.cnblogs.com/EditPosts.aspx?postid=3154487" rel="nofollow">编辑</a> <a href="#" onclick="AddToWz(3154487);return false;">收藏</a></div>















 4374
4374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









