







之前看到的资料,拿出来分享下,
说明:本实例是以 SQL Server 2005 为运行环境的。
准备工作:创建一个名为 DB 的数据库(CREATE DATABASE DB)。
一、T-SQL 行转列
1、创建如下表
CREATE TABLE [Scores] (
[ID] INT IDENTITY(1,1), --自增标识
[StuNo] INT, --学号
[Subject] NVARCHAR(30), --科目
[Score] FLOAT --成绩
)
GO
INSERT INTO [Scores]
SELECT 100, '语文', 80 UNION
SELECT 100, '数学', 75 UNION
SELECT 100, '英语', 70 UNION
SELECT 100, '生物', 85 UNION
SELECT 101, '语文', 80 UNION
SELECT 101, '数学', 90 UNION
SELECT 101, '英语', 70 UNION
SELECT 101, '生物', 85
CREATE TABLE [Student] (
[ID] INT IDENTITY(100,1), --自增标识,学号
[StuName] NVARCHAR(30), --姓名
[Sex] NVARCHAR(30), --性别
[Age] CHAR(2) --年龄
)
GO
INSERT INTO [Student]
SELECT '张三', '男', 80 UNION
SELECT '李四', '女', 75
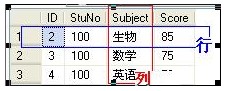
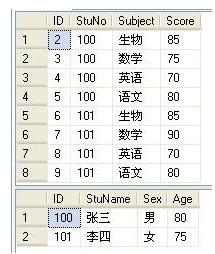
两表的数据如下图:
2、通过CASE…WHEN 语句和GROUP BY…聚合函数 来实现行转列
SELECT
StuNo AS '学号',
MAX(CASE Subject WHEN '语文' THEN Score ELSE 0 END) AS '语文',
MAX(CASE Subject WHEN '数学' THEN Score ELSE 0 END) AS '数学',
MAX(CASE Subject WHEN '英语' THEN Score ELSE 0 END) AS '英语',
MAX(CASE Subject WHEN '生物' THEN Score ELSE 0 END) AS '生物',
SUM(Score) AS '总分',
AVG(Score) AS '平均分'
FROM dbo.[Scores]
GROUP BY StuNo
ORDER BY StuNo ASC
结果如下图:

3、通过 JOIN…ON 实现两表联接,显示出学生姓名
SELECT
MAX(StuNo) AS '学号',
StuName AS '姓名',
MAX(CASE Subject WHEN '语文' THEN Score ELSE 0 END) AS '语文',
MAX(CASE Subject WHEN '数学' THEN Score ELSE 0 END) AS '数学',
MAX(CASE Subject WHEN '英语' THEN Score ELSE 0 END) AS '英语',
MAX(CASE Subject WHEN '生物' THEN Score ELSE 0 END) AS '生物',
SUM(Score) AS '总分',
AVG(Score) AS '平均分'
FROM dbo.[Scores] A join [Student] B on (A.StuNo=B.ID)
GROUP BY StuName
ORDER BY StuName ASC
结果如下图:

4、通过 PIVOT 实现行转列
SELECT
StuNo AS '学号',
StuName AS '姓名',
AVG(语文) AS '语文',
AVG(数学) AS '数学',
AVG(英语) AS '英语',
AVG(生物) AS '生物'
FROM [Scores]
PIVOT(
AVG(Score) FOR Subject IN
(语文,数学,英语,生物)
) AS NewScores
JOIN [Student] ON (NewScores.StuNo=Student.ID)
GROUP BY NewScores.StuNo,StuName
ORDER BY StuName ASC
结果如下图:

二、T-SQL列转行
1、创建数据表并插入 4 条数据
CREATE TABLE [StudentScores] (
[ID] INT IDENTITY(1,1), --自增标识
[StuNo] INT, --学号
[Chinese] NVARCHAR(30), --语文
[Mathematics] NVARCHAR(30), --数学
[English] NVARCHAR(30), --英语
[Biology] NVARCHAR(30) --生物
)
GO
INSERT INTO [StudentScores]
SELECT 100, 80, 85, 75, 80 UNION
SELECT 101, 90, 80, 70, 75 UNION
SELECT 102, 95, 90, 80, 70 UNION
SELECT 103, 60, 70, 80, 85
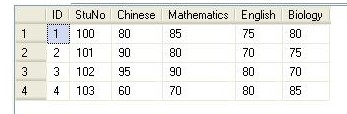
数据如下图:
2、通过 UNION ALL…MAX 实现列转行
SELECT StuNo, 'Chinese' AS Subject,
MAX(Chinese) AS 'Score'
FROM [StudentScores]
GROUP BY [StuNo]
UNION ALL
SELECT StuNo, 'Mathematics' AS Subject,
MAX(Mathematics) AS 'Score'
FROM [StudentScores]
GROUP BY [StuNo]
UNION ALL
SELECT StuNo, 'English' AS Subject,
MAX(English) AS 'Score'
FROM [StudentScores]
GROUP BY [StuNo]
UNION ALL
SELECT StuNo, 'Biology' AS Subject,
MAX(Biology) AS 'Score'
FROM [StudentScores]
GROUP BY [StuNo]
结果如下图:

3、用 UNPIVOT 实现列转行
SELECT StuNo, Subject, Score
FROM [StudentScores]
UNPIVOT
(
Score FOR Subject IN
([Chinese], [Mathematics], [English], [Biology])
) AS NewStudentScores
三、T-SQL 分页
1、创建数据库并插入 40000 条数据
CREATE TABLE [Pagin] (
[ID] INT IDENTITY(1,1), --自增标识
[Number] INT, --编号
[Type] NVARCHAR(30), --类型
[Count] INT --数量
)
GO
declare @i int
set @i = 0
while(@i<10000)
begin
INSERT INTO [Pagin] SELECT 10000+@i, 'A类', 80+@i%5
INSERT INTO [Pagin] SELECT 10000+@i, 'B类', 60+@i%10
INSERT INTO [Pagin] SELECT 10000+@i, 'C类', 70+@i%8
INSERT INTO [Pagin] SELECT 10000+@i, 'D类', 90+@i%3
set @i = @i + 1
end
2、通过 TOP 实现分页
方案一:两次 TOP 实现,原型如下
SELECT * FROM (
SELECT TOP 5 * FROM (
SELECT TOP 25 * FROM [Pagin] WHERE ID>0 ORDER BY ID ASC
) AS TEMPTABLE1 ORDER BY ID DESC
) AS TEMPTABLE2 ORDER BY ID ASC
SELECT TOP 5 * FROM (
SELECT TOP 25 * FROM [Pagin] WHERE ID>0 ORDER BY ID ASC
) AS TEMPTABLE1 ORDER BY ID DESC
说明:第一个 TOP 表示页面容量,第二个 TOP 表示页面容量*当前页码数。
弊病: 1、强制排序,否则不能分页,虽然目前基本上查询表都要排序。
2、排序字段不能有空值即null,否则分页结果不符实际情况。
3、多次order by 速度会快吗,有待我进一步大数据量测试。
方案二:两次 TOP 基于NOT IN 实现,原型如下
select top 5 * from [Pagin]
where ID not in (select top 25 ID from [Pagin] order by ID)
order by ID
说明:第一个 TOP 表示页面容量,第二个 TOP 表示页面容量*当前页码数。
弊病: 1、强制排序。
2、排序列必须是唯一列,否则分页情况不符实际。
3、使用not in,速度慢。
方案三:两次 TOP 基于MAX 或 MIN 实现,原型如下
select top 5 * from [Pagin]
where ID > (select max(p.ID) from (select top 25 ID from [Pagin] order by id) as p)
order by ID
说明:第一个 TOP 表示页面容量,第二个 TOP 表示页面容量*当前页码数。
弊病: 1、强制排序。
2、排序列必须是唯一列,否则分页情况不符实际。
最后总结:在 sqlserver 分页中,第二第三种方案基本上是淘汰掉的,因为现在基本上什么表都是根据添加时间来排序,所以那两种方案没有用,真亏作者也敢发布出来,只有第一种方案还是稍微能用一下,但还是要复杂的拼sql 语句,不方便,要通用于所有表有点难度,象oracle 就很方便了,基于rownum ,传入一个sql 查询语句,这个查询语句爱怎么写就怎么写,反正保证它得到一个结果集就行,不像sqlserver又是要求唯一健又是要求必须排序,把一个结果集颠来倒去,不慢才怪呢。
方案一的简单存储过程如下:
CREATE PROCEDURE proc_page
@pageIndex INT = 0, --页索引
@pageSize INT = 10, --页大小
@recordCount INT = 0 OUTPUT, --返回纪录总数
@pageCount INT = 0 OUTPUT --返回页总数
AS
DECLARE @sql NVARCHAR(1300) --主sql语句
--得到记录总数--
BEGIN
DECLARE @recordTotal INT
SET @sql = N'SELECT @recordTotal=COUNT(ID) FROM [Pagin] WHERE ID>0'
EXEC SP_EXECUTESQL @sql,N'@recordTotal INT OUTPUT',@recordTotal OUTPUT --@recordTotal = @recordCount OUTPUT
SET @recordCount = @recordTotal
END
--计算页总数--
IF(@recordCount%@pageSize=0)--如果记录总数除以页大小的余数为零
SET @pageCount = @recordCount/@pageSize
ELSE--如果记录总数除以页大小的余数不为零
SET @pageCount = @recordCount/@pageSize + 1
--根据页索引执行分页查询--
IF(@pageIndex<=1 OR @pageIndex>@pageCount)--如果是第一页,或者该页不存在,则默认也索引为1,即第一页
BEGIN
SET @pageIndex = 1
SET @sql = 'SELECT TOP '+STR(@pageSize)+' * FROM [Pagin] WHERE ID>0 ORDER BY ID ASC'
EXEC SP_EXECUTESQL @sql
END
ELSE--如果不是第一页,即其它页
BEGIN
SET @sql = 'SELECT * FROM (SELECT TOP '+STR(@pageSize)+' * FROM (SELECT TOP '+STR(@pageSize*@pageIndex)+' * FROM [Pagin] WHERE ID>0 ORDER BY ID ASC) AS TB1 ORDER BY ID DESC) AS TB2 ORDER BY ID ASC'
EXEC SP_EXECUTESQL @sql
END
PRINT @sql--打印SQL 语句
GO
--测试
DECLARE @recordCount INT,@pageCount INT
EXEC proc_page 0,5,@recordCount OUTPUT,@pageCount OUTPUT
PRINT @recordCount
PRINT @pageCount
注意:该存储过程是扩展的,还可以改为万能分页存储过程,只需再加上一些参数,再改改就好了。















 1290
1290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









