







1.对流量原始日志进行流量统计,将不同省份的用户统计结果输出到不同文件
2.需要自定义改造两个机制:
**1、改造分区的逻辑,自定义一个partitioner
**2、自定义reduer task的并发任务数
3.代码如下:
public class FlowSortMR {
public static class FlowSumAreaMapper extends Mapper<LongWritable, Text, Text, FlowBean>{
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
//拿一行数据
String line = value.toString();
//切分成各个字段
String[] fields = StringUtils.split(line, "\t");
//拿到我们需要的字段
String phoneNB = fields[1];
long u_flow = Long.parseLong(fields[7]);
long d_flow = Long.parseLong(fields[8]);
//封装数据为kv并输出
context.write(new Text(phoneNB), new FlowBean(phoneNB,u_flow,d_flow));
}
}
public static class FlowSumAreaReducer extends Reducer<Text, FlowBean, Text, FlowBean>{
@Override
protected void reduce(Text key, Iterable<FlowBean> values,Context context)
throws IOException, InterruptedException {
long up_flow_counter = 0;
long d_flow_counter = 0;
for(FlowBean bean: values){
up_flow_counter += bean.getU_load();
d_flow_counter += bean.getD_load();
}
context.write(key, new FlowBean(key.toString(), up_flow_counter, d_flow_counter));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(FlowSortMR.class);
job.setMapperClass(FlowSumAreaMapper.class);
job.setReducerClass(FlowSumAreaReducer.class);
//设置我们自定义的分组逻辑定义
job.setPartitionerClass(AreaPartitioner.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
//设置reduce的任务并发数,应该跟分组的数量保持一致
job.setNumReduceTasks(6);
FileInputFormat.setInputPaths(job, new Path("F:/hadoop/flow/input"));
FileOutputFormat.setOutputPath(job, new Path("F:/hadoop/flow/output6"));
System.exit(job.waitForCompletion(true)?0:1);
}
}
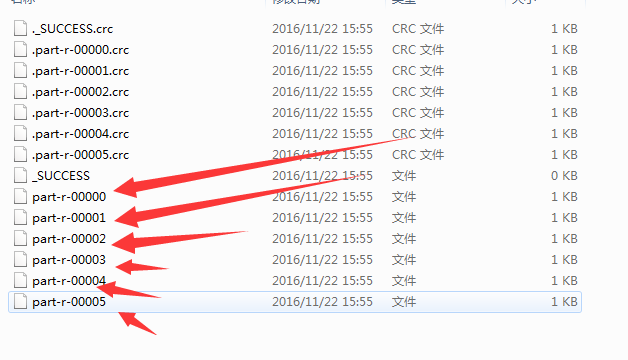
4.运行结果:
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









