







Problem
如下图所示,求这三个graph的公共边,也即是途中有色粗线所示
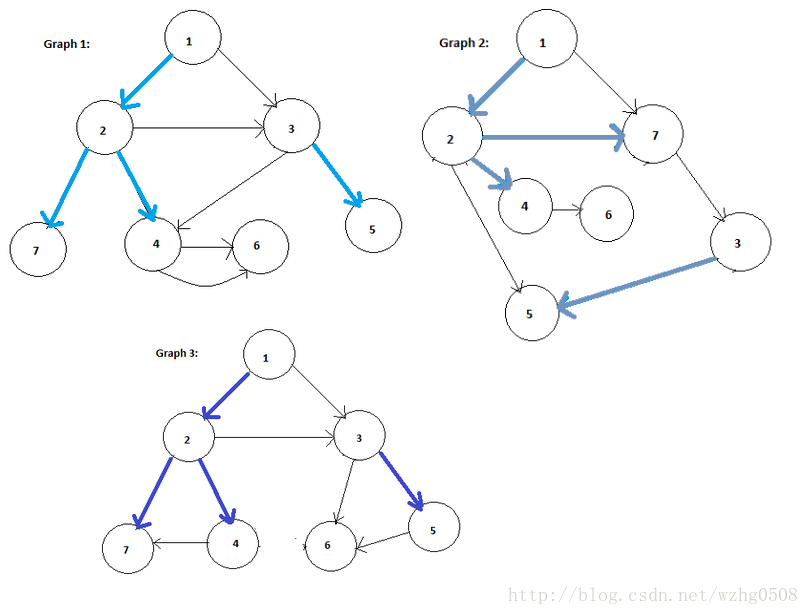
Input
输入格式:
Graph_id<tab>source<tab>destination
上图数据输入格式例子:
graph1<tab>node1<tab>node3
graph1<tab>node1<tab>node2
graph1<tab>node2<tab>node3
graph1<tab>node2<tab>node7
graph1<tab>node2<tab>node4
graph1<tab>node3<tab>node4
graph1<tab>node3<tab>node5
graph1<tab>node4<tab>node6
graph1<tab>node4<tab>node6
graph2<tab>node1<tab>node2
graph2<tab>node1<tab>node2
graph2<tab>node1<tab>node7
graph2<tab>node2<tab>node4
graph2<tab>node2<tab>node5
graph2<tab>node2<tab>node7
graph2<tab>node3<tab>node5
graph2<tab>node4<tab>node6
graph2<tab>node7<tab>node3
graph3<tab>node1<tab>node3
graph3<tab>node1<tab>node2
graph3<tab>node2<tab>node4
graph3<tab>node2<tab>node7
graph3<tab>node3<tab>node5
graph3<tab>node3<tab>node6
graph3<tab>node4<tab>node7
graph3<tab>node5<tab>node6
Output
node1:node2<tab>graph3^graph2^graph1
node2:node4<tab>graph3^graph2^graph1
node2:node7<tab>graph3^graph2^graph1
node3:node5<tab>graph3^graph2^graph1
Hadoop Code
import package HadoopGTK;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.ma 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









