







1 Introduction
对象识别和分类是计算机视觉中的核心问题。许多流行的识别方法可以看作是实现标准处理流程:(1)密集局部特征提取,(2)特征编码,(3)编码局部特征的空间汇集构造特征向量描述符,以及(4)将得到的描述符呈现给分类器。
池化的作用是产生图像区域的全局描述 - 单个描述符总结了区域内的局部特征,并且可以作为标准分类器的输入。
在本文中,我们介绍和探索使用以对称矩阵形式捕获的二阶信息的汇集方法
contributions
- 二阶特征汇集方法利用了计算差分几何的最新进展[8]。特别地,我们利用对称正定矩阵空间的黎曼结构来构造自由形式区域内的局部特征集,同时保留关于它们成对相关的信息。所提出的池化过程在没有任何编码阶段和线性分类器的情况下表现良好,允许在特征数量和示例数量方面具有很大的可扩展性
- 通过在多个重叠自由形式区域的共享区域上缓存池化输出,在大量区域上有效执行二阶池化的新方法
- 二阶池的局部特征丰富方法。我们使用原始图像信息以及区域空间支持内局部特征的相对位置和比例来增强标准局部描述符,例如SIFT [9]。
令人惊讶的是,与线性分类器串联使用的二阶池优于与非线性内核分类器一起使用的一阶池。
2 Second-Order Pooling
- Log-Euclidean Tangent Space Mapping
- Power Normalization
3 Local Feature Enrichment
与一阶池化方法不同,我们通过直接在原始局部描述符(例如SIFT)上使用二阶池化来观察到良好的性能(例如,没有任何编码)。这可能是由于这样一种事实,即通过这种类型的池,保留了描述符维度的所有交互对之间的信息。
我们使用区域内的相对坐标以及其他原始图像信息来丰富局部描述符,而不是编码。
3.1 Multiple Local Descriptors
在实践中,我们使用了三个不同的局部描述符:SIFT [9],一种称为掩蔽SIFT(MSIFT)和局部二值模式(LBP)[25]的变体,用于生成四个不同的全局区域描述符。
4 Efficient Pooling over Free-Form Regions
我们提出了两种方法来加速多个重叠自由形态区域的局部特征汇集。
- Caching over Region Intersections缓存区域交叉点
- Favorable Region Complements有利的区域补充
5 Experiments
我们分析了我们的方法在Pascal VOC 2011分段数据集的清洁地面实况对象区域的几个方面。这使我们能够从识别段选择和推理问题中分离出识别效果,并且易于与未来的工作进行比较。我们还通过对基于超基于像素的地面真实区域重构进行识别来评估分割“噪声”存在下的识别准确度。使用公开可用的包VLFEAT [26],在多个尺度上进行局部特征提取,所有涉及线性分类的结果都是通过幂归一化获得的。我们邀请读者参考我们可用的实施方案,了解有关这些操作的详细信息。
我们首先使用SIFT和丰富的SIFT(enriched SIFT descriptors)描述符比较一阶和二阶最大和平均池。(max and average pooling)
我们使用LIBLINEAR训练20个Pascal类的一对一SVM模型[31]
5.1 Semantic Segmentation in the Wild - Pascal VOC 2011
为了全面评估识别性能,我们在没有地面真值掩模的Pascal VOC 2011分割数据集上尝试了最好的汇集方法。我们遵循类似于SVR-SEGM的前馈架构。首先,我们使用公共可用的Constrained Parametric Min-Cuts约束参数最小割(CPMC)实现计算每个图像最多150个排名靠前的对象分割候选池[30]。然后我们在每个候选中提取前面详述的特征组合,并将它们提供给每个类别的linearsupport矢量回归量(SVR)。训练回归量以预测每个片段与来自每个类别的对象之间的最高重叠[18,19]。
- Learning.
我们在“分割Segmentation”和“主要Main”数据子集中使用了所有12,031个可用的训练图像,用于学习,如挑战规则所允许的,以及在线提供的附加分段注释[32],类似于Arbelaez等人最近的实验[20]。]。考虑到所有那些图像的CPMC段导致总共大约178万个段描述符,CPMC描述符集。此外,我们收集了与地面实况和镜像地面真实段相对应的描述符,以及与每个地面实况对象分段最佳重叠的CPMC段,以形成“正”描述符集。我们使用非中心PCA将描述符组合的维度从33,800维度减少到12,500 [33],将CPMC的描述符分为4个块,这些块分别位于32 GB的可用RAM内存上。非中心PCA明显优于标准PCA(在相同数量的目标维度下,VOC分割得分提高约2%),这表明不同维度的相对平均幅度是信息性的,不应通过平均减法来计算。我们在减少的地面真实段以及它们的镜像版本(59,000个示例)上学习了PCA基础,这些版本只需要大约20分钟。我们采用类似于目标检测[13]的学习方法,其中训练数据也很少进入主记忆。我们使用“正”集和CPMC描述符集的第一个块训练每个类别的初始模型。我们存储了来自CPMC集的所有描述符,这些描述符都是支持向量,并使用学习的模型快速筛选下一个CPMC描述符块,同时收集硬实例(在SVRε边界之外)。然后,我们使用正集和硬反面示例的缓存重新训练模型,并迭代直到所有块都被处理。我们通过重复使用前面所有示例的先前的α参数并初始化α的值来热启动新模型的训练,使新示例为零。我们观察到1.5-4倍的加速
每个图像使用150个段,高度依赖于形状的eMSIFT-F描述符每个图像需要2秒才能计算出来。 我们评估了其他3个区域描述符的拟议加速,它们适用。缓存将计算时间缩短到仅3秒,并利用有利的段补充减少了2.4秒的时间,比原始池化naive pooling加速4.8倍。本小节中报告的时间是在具有32GB RAM的台式PC和具有6个内核的i7-3.20GHzCPU上获得的。
Inference
应用简单的推理过程来计算偏向于具有相对较少对象的标签。它通过顺序选择具有高于“背景”阈值的最高分数的分段和类来操作。每次选择新段时,该阈值都会线性增加,因此每个新段需要更大的存储余量。然后,按照得分的顺序将选定的片段“粘贴”到图像上,以便将较高得分的片段叠加在分数较低的片段之上。初始阈值自动设置,以便每个图像的所选片段的平均数量等于训练集上每个图像的平均对象数,即2.2,并且线性增量设置为0.02。本文的重点不在于推理,而在于特征提取和简单的线性分类。可以插入更复杂的推理程序[18,19,34,35]
Results.
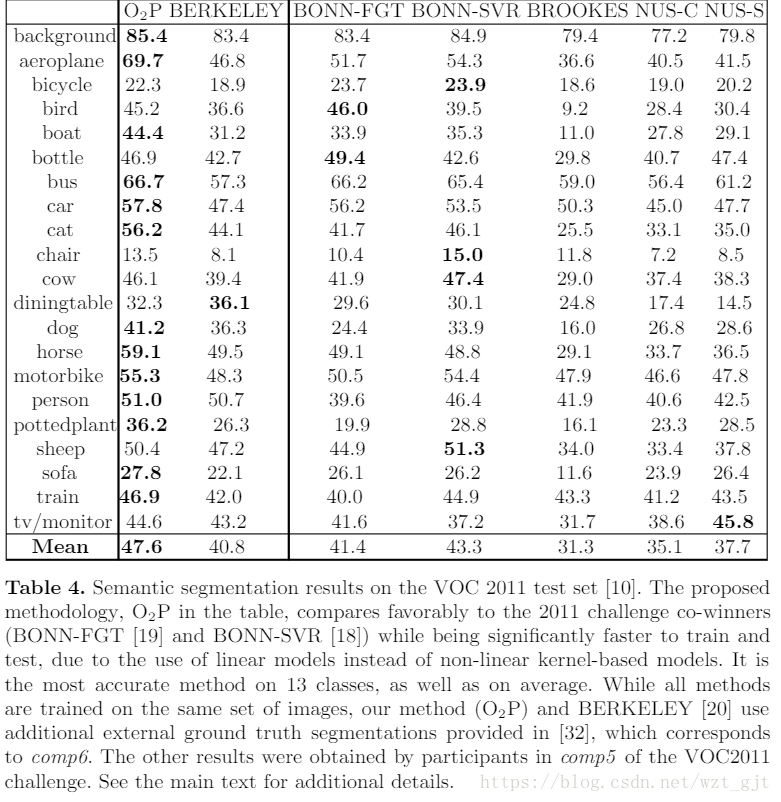
表4中报告了测试集的结果。建议的方法获得的平均得分为47.6,比2011年挑战赛的两种获胜方法提高了10%和15%,两种方法都使用了相同的非线性回归量,但只能使用在训练期间,其余9,808张图像中有2,223个地面真相分割和边界框。相比之下,我们的模型使用了所有训练图像的分割掩模。除了更高的识别性能之外,我们的模型在训练和测试方面要快得多,如表3中的并排比较所示。所提出的方法的报告学习时间包括PCA计算和特征投影(但非特征提取,类似于两者例)。在学习之后,我们将学习的重量矢量投影到原始空间,以便在测试时不需要昂贵的投影。我们观察到,重新投射学习的权重向量并没有改变识别准确性

- Efficiency of Feature Extraction
5.2 Caltech101
语义分割是一个重要问题,但更广泛地评估二阶汇集也很有意义。我们使用Caltech101 [11]来实现这一目的,因为尽管与Pascal VOC相比有其局限性,但迄今为止它一直是编码和汇集技术的重要测试平台。关于局部特征提取,编码和汇集的大部分文献已经报道了Catech101的结果。许多方法使用特定的特征编码方法[3,36,37]在空间金字塔上使用最大或平均汇集。在这里,我们使用theraw SIFT描述符(例如,没有编码)和我们在空间金字塔上提出的二阶平均池。由于空间金字塔中每个单元格的全局描述符的串联,得到的图像描述符有点高维(使用SIFT为173.376维),但是因为线性分类器使用和训练样例的数量很少,学习只需几秒钟。我们还使用带有RBF内核的SVM进行了实验,但没有观察到线性内核的任何改进。我们提出的池化使用30个训练样例和标准评估协议,在单个特征的聚合方法中获得最佳准确性。它还与其他表现最好,但显着较低的替代品竞争。我们的方法实现起来非常简单,高效,可扩展,无需编码阶段。结果和其他细节可以在表5中找到。
6 Conclusion
我们提出了一个自由形态区域二阶池的框架,并将其应用于对象类别识别和语义分割。该提出的池化程序实现起来非常简单,涉及少量参数,并且与线性分类器一起获得高识别性能,并且没有任何编码阶段,只处理原始特征。我们还提出了局部描述符丰富的方法,导致性能提高,全局区域描述符维度仅略有增加,并提出了一种加速任意自由形态区域汇集的技术。实验结果表明我们的方法优于Pascal VOC 2011语义分割数据集的最新技术,使用的回归量比最精确的方法快4个数量级[18]。我们还通过直接汇集原始SIFT描述符,使用单个描述符并且没有任何特征编码在Caltech101上获得最先进的结果。在未来的工作中,我们计划探索除乘法之外的不同类型的对称成对特征交互,例如最大和最小。资源实现本文所介绍技术的代码可从我们的网站公开获取。http://www.maths.lth.se/matematiklth/personal/sminchis/code/o2pCode.html
参考:Carreira J, Rui C, Batista J, et al. Semantic Segmentation with Second-Order Pooling[J]. 2012, 7578(1):430-443.















 4040
4040











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









