






LinkedList类 第六课 d
·LinkedList类是采用双向循环链表实现的
·利用LinkedList实现栈stack 队列queue 双向队列double-ended queue
栈 队列是数据结构知识 第六课d 900
链表 栈(8300) 队列(第六课E 1100)
ArrayList与LinkedList的比较:
1 ArrayList底层采用数组完成,而LinkedList以一般的双向链表完成,其内每个元素除了数据本身之外,还有两个引用,分别指向前一个元素和后一个元素
2 如果我们不是经常在List的开始处增加元素或者在List中删除插入操作,那我们就应该使用ArrayList,否则使用LinkedList更快。
HashSet:第六课E 7400
HashSet是实现Set接口的hash表(也叫散列表),依靠HashMap来实现。
我们应该为要存放到散列表中的各个对象定义hashCode()和equals()
因为HashSet类实现的是Set接口,所以其中的元素不能有重复。但是看下面这个例子:
import java.util.*;
public class HashSetTest
{
public static void main(String[] args)
{
HashSet ha = new HashSet();
ha.add("one");
ha.add("two");
ha.add("three");
ha.add("two");
//如何访问哈希表中的元素呢,因为她没有get方法,所以只能使用迭代器
Iterator it = ha.iterator();
while(it.hasNext())
{
System.out.println(it.next());
}
//这里我们定义几个Studentd类对象,并且其中有两个是相同的对象,这时哈希表要打
//印出这两个相同的对象,不是说HashSet元素不能有重复的吗???
HashSet ha2 =new HashSet();
ha2.add(new Student(1,"zhangshan"));
ha2.add(new Student(2,"lisi"));
ha2.add(new Student(3,"wangwu"));
ha2.add(new Student(2,"lisi"));
Iterator it2= ha2.iterator();
while(it2.hasNext())
{
System.out.println(it2.next().toString());
}
}
}
class Student
{
int num;
String name;
Student(int num,String name)
{
this.num=num;
this.name=name;
}
} 运行结果为:
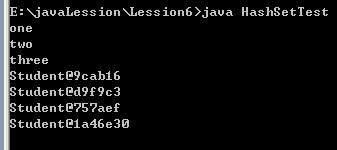
如果出现上面这种16进制的,那就需要重写Student类的toString()方法咯:像这样写:
public String toString()
{
return "num="+num+"; name="+name;
}
这时运行结果为:
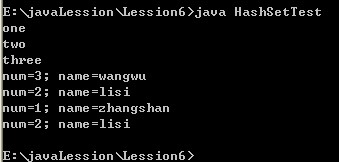
为什么前面定义的ha.add("two");只打印了一个,而后边ha2.add(new Student(2,"lisi"));两个都打印出来了???那是因为我们的哈希表计算元素存放位置时是通过散列码计算出来的,而散列码又是通过Object类中的hashcode()方法获取的,而hashcode()又是通过对象的内存地址来得到一个散列码,而通过new产生的对象java认为那是两个不同对象,需要分配不同内存空间。而两个相同的two为什么会被看成是相同的呢???目前我认为是因为two字符串是存在对象池中,第一个two和第二个two都是对象池中的同一个。
也正是由于这种情况,要求我们重写哈希表对象的hashCode()方法。第六课F 900
好,我们来重写一下Student类的hashCode()方法:
class Student
{
int num;
String name;
Student(int num,String name)
{
this.num=num;
this.name=name;
}
public String toString()
{
return "num="+num+"; name="+name;
}
public int hashCode()
{
return num; //我们以学号作为唯一标识,当然也可以这样return num*name.hashCode()
}
}
这时呢 运行还是要打印出4个Student对象,为什么呢 ?不是已经重写了hashCode()方法了吗?
因为如果我们想用哈希表保存元素,那其中的每一个对象元素都要求实现hashCode()方法,同时还要求实现public boolean equals(Object o)这个方法才行。也就是说要求我们同时要覆盖父类的这两个方法才有效。所以Student类应该这样写:
import java.util.*;
public class HashSetTest
{
public static void main(String[] args)
{
HashSet ha = new HashSet();
ha.add("one");
ha.add("two");
ha.add("three");
ha.add("two");
//如何访问哈希表中的元素呢,因为她没有get方法,所以只能使用迭代器
Iterator it = ha.iterator();
while(it.hasNext())
{
System.out.println(it.next());
}
//这里我们定义几个Studentd类对象,并且其中有两个是相同的对象,这时哈希表要打
//印出这两个相同的对象,不是说HashSet元素不能有重复的吗???
HashSet ha2 =new HashSet();
ha2.add(new Student(1,"zhangshan"));
ha2.add(new Student(2,"lisi"));
ha2.add(new Student(3,"wangwu"));
ha2.add(new Student(2,"lisi"));
Iterator it2= ha2.iterator();
while(it2.hasNext())
{
System.out.println(it2.next().toString());
}
}
}
class Student
{
int num;
String name;
Student(int num,String name)
{
this.num=num;
this.name=name;
}
public String toString()
{
return "num="+num+"; name="+name;
}
public int hashCode()
{
return num; //我们以学号作为唯一标识,当然也可以这样return num*name.hashCode()
}
public boolean equals(Object o)
{
Student st =(Student)o;
return num==st.num&&name.equals(st.name);
}
} 这时运行就正常了,结果如下:
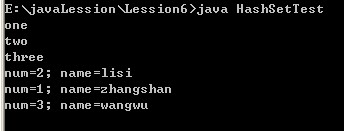















 333
333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









