







代码:https://github.com/simon20010923/DDAMFN/tree/main
此算法是当前的第一名:https://paperswithcode.com/paper/a-dual-direction-attention-mixed-feature
文章目录
介绍
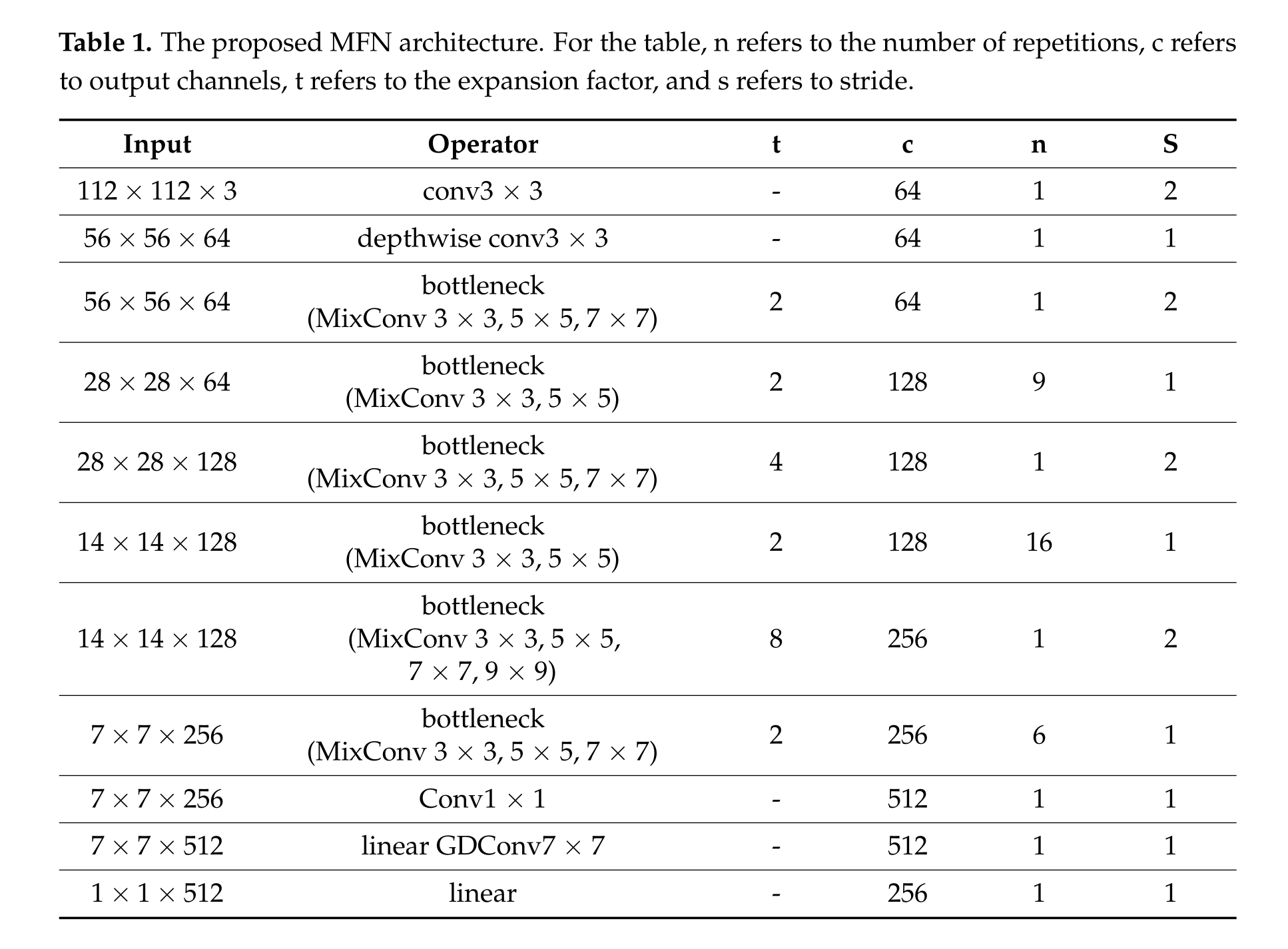
面部表情在人类交流中起着重要作用,是理解情绪和态度的关键信号。因此,计算机需要获得辨识和解释面部表情的能力。[1–3]已经清楚地阐明了视觉感知、环境映射算法与基于生物识别认证计算机视觉的面部表情识别(FER)之间的关系,因此使用深度学习方法解决FER问题是有意义的。FER网络的主流架构通常由主干和头部组成。然而,最近的方法主要集中在头部或颈部区域,并仅使用VGG [4]或ResNet [5]作为其主干。值得注意的是,这些主干最初是为更大的数据集而设计的,可能会从图像中提取冗余信息,在相对较小的数据集中导致过度拟合。本文提出了一种创新的主干网络,称为混合特征网络(MFN)。MFN建立在MobileFaceNets [6]的基础上,这是一个专门为面部验证任务量身定制的轻量级网络。通过引入混合深度卷积核 [7]来增强MFN,这些卷积核利用了不同尺寸卷积核的优势。此外,坐标注意 [8]被引入到MFN架构中,以促进对长距离依赖的捕捉。因此,提取了用于FER的有意义的特征。
此外,FER面临着两个重要挑战:类间差异小和类内差异大。要解决这些挑战,建立各种面部区域之间的连接,如嘴巴、眼睛、鼻子等,至关重要。在这方面,注意机制提供了潜在的解决方案。具体来说,提出了双向注意(DDA)头,该头应用于所提出的方法,旨在根据提取的特征信息构建注意图。根据以前的工作 [8],设计了从垂直和水平方向生成注意图的注意头。随后,将从双向注意网络(DDAN)获得的注意图与输入特征图相乘,得到一个新的特征图。该特征图经过线性全局深度卷积(GDConv)层 [6],然后进行重塑操作。采用全连接层生成最终结果。通过集成所提出的DDA头和后续处理步骤,可以增强模型的能力。
最后,本文将MFN和DDAN集成在一起,提出了一种名为双向注意混合特征网络(DDAMFN)的新模型。
为了直观地展示DDAMFN的有效性,进行了涉及ResNet_50、MFN和DDAMFN模型的比较分析。所有模型都在AffectNet-7数据集上进行了训练,并在相同的测试数据上进行了测试。Grad-CAM [9]被应用于捕获各自主干架构提取的特征的见解。该技术通过基于梯度的定位,促进了通过热图突出显示图像中的重要区域进行预测。该分析的结果在图1中呈现。对结果的综合评估展示了模型之间注意焦点的明显模式。很明显,MFN关注的区域比ResNet_50更特定。对于DDAMFN,DDAN允许MFN定位更合适的区域。
图1。七张图像的热图:中性(第1行),快乐(第2行),悲伤(第3行),惊讶(第4行),恐惧(第5行),厌恶(第6行)和愤怒(第7行)。列1:原始图像。列2:ResNet_50。列3:MFN。列4:DDAMFN(MFN + DDAN)。很明显,MFN关注的区域比ResNet_50更特定。DDAN允许MFN定位更合适的区域。
此外,当在各种基准数据集上进行了大量实验时,DDAMFN模型表现出了显着的性能,将其确立为FER领域的当前最先进网络。我们研究的贡献可以总结如下:
(1)为了增强FER的提取特征的质量,本研究提出了一种名为MFN的新型主干网络。MFN利用不同内核尺寸的利用,从而有助于获得强大的特征。此外,在MFN架构中包含坐标注意层,可以捕捉长距离依赖性,进一步增强了其在FER任务中的有效性。
(2)为了有效检测不同面部表情之间的细微变化,引入了DDAN。通过从两个不同方向生成关注,DDAN旨在全面捕捉相关的面部区域,并提高FER的区分能力。
(3)应用了一种新颖的注意力损失机制,以确保DDAN的注意头聚焦在不同区域,从而显著提高了模型的整体性能和区分能力。
(4)对著名的FER数据集进行了广泛的评估,包括A
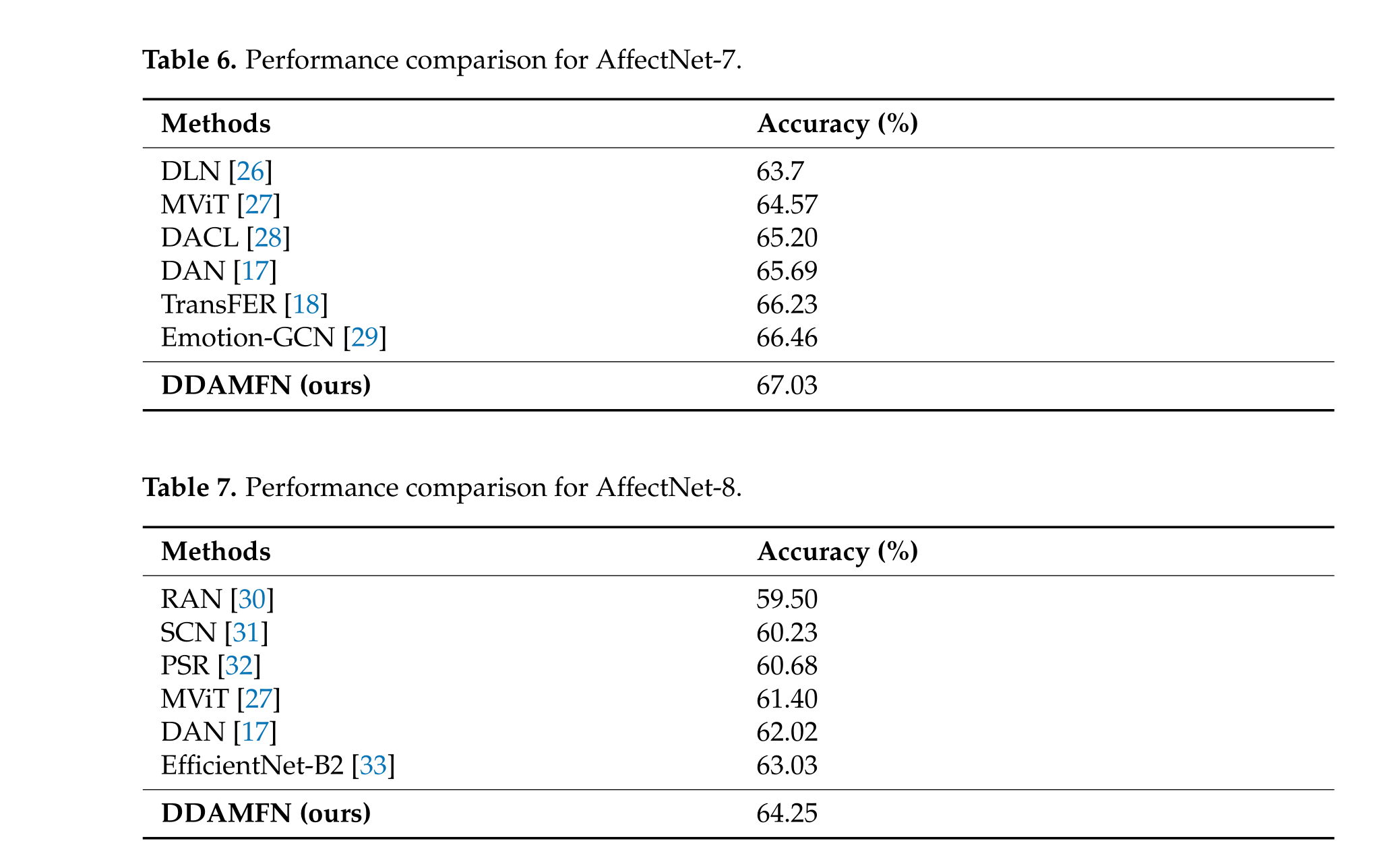
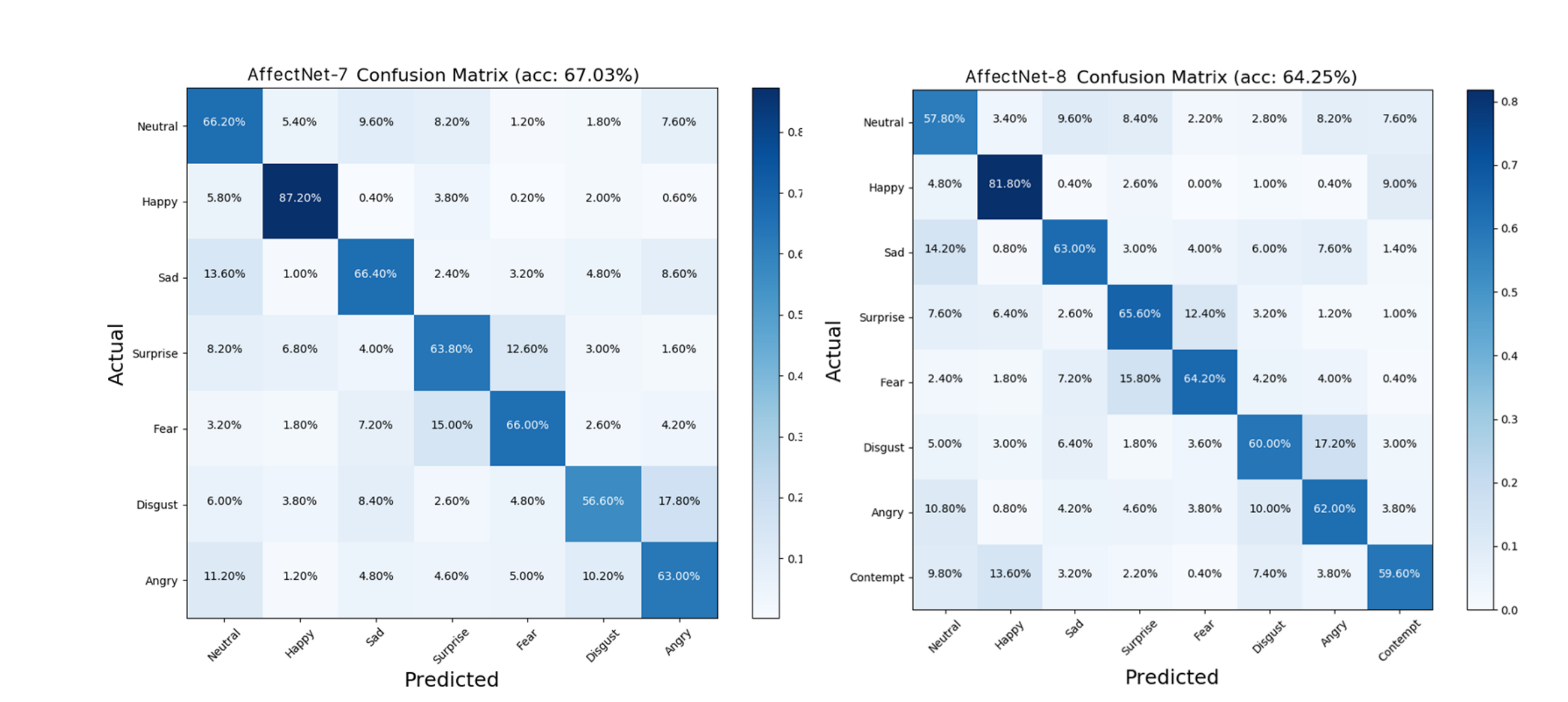
ffectNet、RAF-DB和FERPlus,以评估DDAMFN的性能。实验结果表明,其在AffectNet-7上的准确率为67.03%,在AffectNet-8上为64.25%,在RAF-DB上为91.35%,在FERPlus上为90.74%。这些出色的结果突显了DDAMFN在FER领域的有效性和优越性。
网络结构
DDAMFN的架构概述如图2所示,包括两个主要组件:MFN和DDAN。首先,面部图像被输入到MFN中,产生基本的特征图作为输出。随后,通过DDAN在垂直和水平方向生成注意力图。最终,注意力图被重塑为特定维度,并通过全连接层预测图像的表情类别。
DDAMFN框架有效地结合了MFN的特征提取能力和DDAN的注意机制的判别力。通过整合这些组件,DDAMFN可以在FER任务中实现改善的性能。
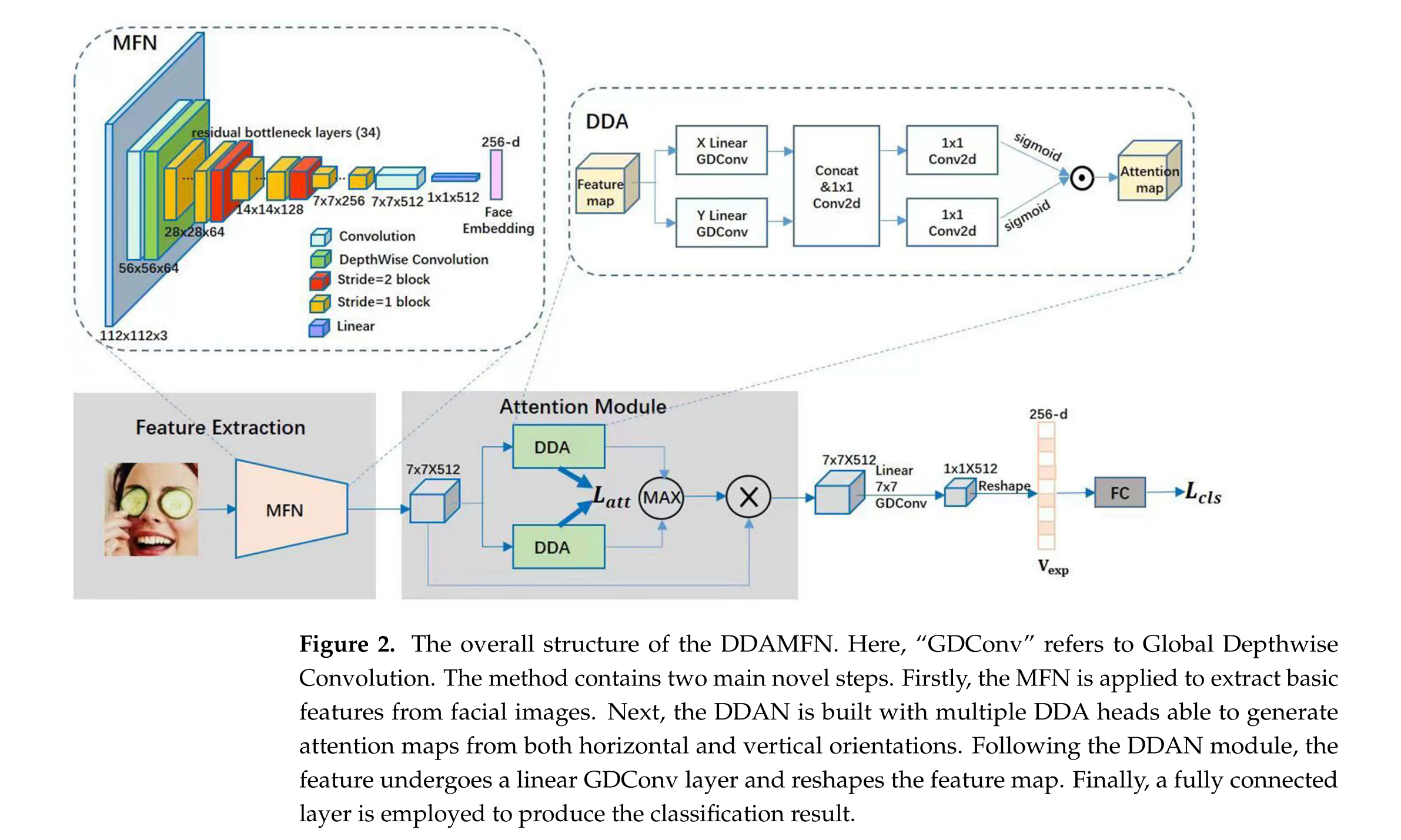
MFN结构:
损失
如图2所示,从DDAN获得的大小为7×7×512的特征图经过线性GDConv层和线性层处理。然后,将转换后的特征图重新形状为一个512维的向量。通过全连接层获得类别置信度。在损失函数方面,训练过程中采用标准的交叉熵损失。该损失函数有效地衡量了预测类别概率与真实标签之间的差异,有助于优化模型的参数。整体损失函数可以表示为:
L = L_cls + λ_a * L_att,(3)
其中,L_cls代表标准交叉熵损失,L_att是注意力损失。λ_a是一个超参数,默认值为0.1。
指标比较
处理数据
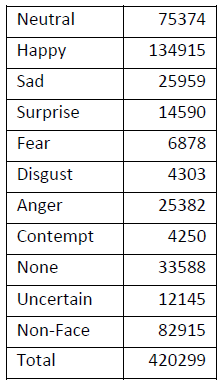
在DDAMFN中,只有前8个类别是重要的。我将后面三个类别都归位负样本类别。
使用此代码处理数据,将原始数据集进行转换:
import os
import shutil
import pandas as pd
from tqdm import tqdm
root = r"/ssd/xiedong/src_data/Manually_Annotated_Images/"
# training.csv
training_csv = r"/ssd/xiedong/src_data/training.csv"
# validation.csv
validation_csv = r"/ssd/xiedong/src_data/validation.csv"
dst_train = r"/ssd/xiedong/src_data/new_datasets_ImageFolder/train"
os.makedirs(dst_train, exist_ok=True)
dst_val = r"/ssd/xiedong/src_data/new_datasets_ImageFolder/val"
os.makedirs(dst_val, exist_ok=True)
# subDirectory_filePath列是图片的路径,expression列是标签
# 用标签创建子文件夹,然后对应图片移动到对应文件夹
df_train = pd.read_csv(training_csv)
df_train = df_train[["subDirectory_filePath", "expression"]]
for i in tqdm(range(len(df_train 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









