本文介绍基于Realtek 8139芯片PCI接口的网卡驱动程序。我选择了Realtek芯片有两个原因:首先,Realtek提供免费的芯片技术手册; 第二,芯片相当便宜。
本文介绍的驱动程序是最基本的,它只有发送和接收数据包功能,和做一些简单的统计。对于一个全面和专业级的驱动程序,请参阅Linux源码。
本文代码是基于Linux2.4.18上测试的,建议编译一个内核,此内核没有任何形式RealTek8139驱动程序,以避免有莫名的BUG。最后,你将网卡插入PCI插槽,我们可以开始了。
目录
网络设备驱动程序的开发,分解成以下步骤:
上:
- 1.检测设备
- 2.启用设备
- 3.认识网络设备
- 4.总线无关的设备访问
- 5.理解PCI配置空间
- 6.初始化网络设备(net_device)
中:
下:
- 8.编写网络设备的发包功能
- 9.编写网络设备的收包功能
1.设备检测
第一步,我们需要检测的网卡设备。 Linux内核提供了丰富的API检测PCI总线上的设备,我们这只用其中最简单的一个API——pci_find_device。
- #define REALTEK_VENDER_ID 0x10EC
- #define REALTEK_DEVICE_ID 0x8139
-
- #include <linux/kernel.h>
- #include <linux/module.h>
- #include <linux/stddef.h>
- #include <linux/pci.h>
- int init_module(void)
- {
- struct pci_dev *pdev;
- pdev = pci_find_device(REALTEK_VENDER_ID, REALTEK_DEVICE_ID, NULL);
- if(!pdev)
- printk("<1>Device not found\n");
- else
- printk("<1>Device found\n");
- return 0;
- }
Table 1: Detecting the device
PCI标准为每个供应商分配一个唯一的Vendor ID,供应商会为每一个特定类型的设备分配一个唯一的Device ID。宏REALTEK_VENDER_ID、REALTEK_DEVICE_ID表示这些ID。你可以在RealTek8139规范的“PCI配置空间表”找到这些值。
2.设备启用(Enabling)
检测到设备后,我们使用设备之前,我必须先激活设备,这个步骤称为[启用设备]。表2所示的代码片段是[设备检测]和[设备启用]合并的代码。
∨Table 2: Detecting and Enabling the Device
- #define REALTEK_VENDER_ID 0x10EC
- #define REALTEK_DEVICE_ID 0X8139
-
- static struct pci_dev* probe_for_realtek8139(void)
- {
- struct pci_dev *pdev = NULL;
-
-
-
-
-
-
-
- pdev = pci_find_device(REALTEK_VENDER_ID, REALTEK_DEVICE_ID, NULL);
- if(pdev) {
-
- if(pci_enable_device(pdev)) {
- LOG_MSG("Could not enable the device\n");
- return NULL;
- }
- else
- LOG_MSG("Device enabled\n");
- }
- else {
- LOG_MSG("device not found\n");
- return pdev;
- }
- return pdev;
- }
-
- int init_module(void)
- {
- struct pci_dev *pdev;
- pdev = probe_for_realtek8139();
- if(!pdev)
- return 0;
-
- return 0;
- }
在表2,函数probe_for_realtek8139执行以下任务:
- 确保系统支持PCI总线
- 检测Realtek8139设备
- 如果发现设备,则启用的设备(通过调用pci_enable_device)
现在,为了更好地理解代码,我们先暂停一下驱动程序代码的研究,转而看一下Linux内核是怎样[处理]设备和设备驱动的。我们将着眼于[网络设备的定义],内存映射I/O和独立端口I/O之间的差异,还有PCI配置空间的概念。
3.理解何为网络设备
我们是检测到了PCI设备,并启用它,但它只是一支硬件设备(网卡设备),而Linux的网络协议栈只认得[网络设备]。[网络设备]是一支逻辑设备,由结构net_device表征。也就是说,网络协议栈向[网络设备]发出命令,而[网络设备]的驱动将这些命令传递到PCI[网卡设备]。表3列出了结构net_device的一些重要数据域,这将在本文稍后使用。
- struct net_device
- {
- char *name;
- unsigned long base_addr;
- unsigned char addr_len;
- unsigned char dev_addr[MAX_ADDR_LEN];
- unsigned char broadcast[MAX_ADDR_LEN];
- unsigned short hard_header_len;
- unsigned char irq;
- int (*open) (struct net_device *dev);
- int (*stop) (struct net_device *dev);
- int (*hard_start_xmit) (struct sk_buff *skb, struct net_device *dev);
- struct net_device_stats* (*get_stats)(struct net_device *dev);
- void *priv;
- };
Table 3: Structure net_device
上表只列出C结构net_device部分成员,不过,对于我们最小驱动程序,这些成员已经足够。以下简介这些成员的用途:
- name – 设备的名称。如果名称的第一个字符是null,那么register_netdev分配给它取名为“ethN”,其中N是合适的数字。例如,如果您的系统已经有eth0和eth1,您的设备将被命名的eth2。
- base_addr – I/O基地址。 I/O地址在本文后面,我们将更深入的讨论。
- addr_len – 硬件地址(MAC地址)的长度。以太网接口地址长度为6字节。
- dev_addr – 硬件地址(以太网地址或MAC地址)
- broadcast – 设备的广播地址。以太网接口的广播地址是FF:FF:FF:FF:FF:FF
- hard_header_len – “硬件头的长度”是数据包硬件头的八位位组(octets)的数量。 以太网接口的hard_header_len的值是14
- IRQ – 分配的中断号
- open – 这是打开设备函数的指针。这个函数在用ifconfig命令激活设备时被调用,例如“ifconfig eth0 up”。 open函数负责向系统申请所需的系统资源需求(I/O端口,IRQ,DMA等),启用硬件和递增模块的使用计数。
- stop – 这是停止设备函数的指针。这个函数在用ifconfig命令停用设备时被调用,例如“ifconfig eth0 down”。 stop函数释放所有open函数获得的资源。
- hard_start_xmit – 此函数在传输线路上发送一个给定的数据包。该函数的第一个参数是指向结构sk_buff指针。结构sk_buff的是通过Linux网络协议栈的数据包。本文并不需要详细了解有关的sk_buff的结构的细节,你可以在下网址获得更多的结构sk_buff的信息:http://www.tldp.org/LDP/khg/HyperNews/get/net/net-intro.html。
- get_stats – 此函数提供了接口统计信息。命令“ifconfig eth0”的很多输出内容来自get_stats。
- priv – 驱动程序的私有数据域。驱动程序拥有这一数据域,并可以使用它。我们稍后会看到,我们的驱动程序使用这一数据域保存与PCI设备相关的数据。
请特别注意,net_device没有接收数据包的成员函数,这是因为接收数据包是由设备的[中断处理程序]负责的,我们将在本文后面看到。
4.总线无关的设备访问(Bus-Independent)
Linux提供了一个API集(下文称为[设备操作API]),抽象所有总线和设备的I/O操作,使设备驱动程序的编写独立于总线类型。
4.1 内存映射的I/O
最广泛支持的I/O的操作是[内存映射I/O]。[内存映射I/O]是指,部分的CPU地址空间被解释为访问设备,而不是访问内存。一些体系结构为[内存映射I/O]的设备定义了固定的地址,但大多数体系提供了检测设备地址的方法。 PCI总线是很好的例子。本文不教你如何获得一个设备地址,假设你已经知道设备地址。
物理地址是unsigned long类型,你不能直接使用这些地址。你应该调用ioremap,来获得一个适合(传递给下面函数)的虚拟地址。当你使用完的设备(比如模块卸载),必须调用iounmap以返还虚拟地址给内核。
4.2 访问设备
在Linux提供[设备操作API]中,驱动程序最常用的接口是访问的设备寄存器的读和写函数。 Linux提供了读取和写入8位,16位,32位和64位量的函数,分别为 byte, word, long, 和 quad,函数命名readb,readw,readl,readq,writeb,writew,writel和writeq。
有些设备(如帧缓冲)更倾向一次内发起超过8个字节的传输。对于这些设备,可使用memcpy_toio,memcpy_fromio和memset_io功能。不要使用memset或memcpy对I/O地址操作,因为它们不能保证[按顺序]复制数据。
[设备操作API]中的读写函数是假设严格[按照源码字面顺序]执行的,编译器不能对它进行乱序优化。如果希望设备读写有一定的优化,可使用原始的__readb函数(等原始无抽象的函数)。 但是要非常小心,要在适当的地方插入内存屏障指令——rmb()/wmb()。
4.3 独立端口IO
另外一种常用的IO操作是[独立端口IO]。端口IO的地址是独立于内存地址空间的,端口IO的访问速度不如内存映射I/O,地址空间也小很多。不过,不像内存映射I/O,访问端口IO的设备相对直观,不需要考虑以上提到的一些问题。
[设备操作API]中提供了访问端口IO的函数,分别操作字节(byte)、双字(word)和四字(long):inb, inw, inl, outb, outw 和 outl。
以上函数还有提供给慢速设备的变种:后加一“_p”;还有类似memcpy功能的ins 和 outs。
5.理解PCI配置空间
RTL8139是一支PCI接口设备,PCI是一种通用的扩展总线,而非与CPU体系相关的本地总线(local bus),从而CPU不能直接对RTL8139寻址访问,必须经PCI总线控制器转译。PCI总线设计实现的核心是PCI总线控制器(有的地方译为PIC主桥,PCI Host Bridge),它将整个系统划分两个数字通信域,两个域独立编址。一个是原来CPU与内存和设备通信的[CPU域],一个是PCI总线控制器的(因它本身就是一CPU),这里称为[PCI总线域]。为了跨越两域通信,系统将CPU域划出一个“window”——将CPU部分寻址空间划给PCI总线用。PCI总线控制器对这部分地址进行管理,实现即插即用等一些现代总线功能。而所谓的[配置空间]只是配合PCI总线控制器实现地址管理提供必要的状态信息[注]。
[配置空间]是每支PCI设备(包括PCI桥)集成一集寄存器,[配置空间]是面向PCI总线控制器而言的,此空间的基地址是PCI设备的拓扑位置(总线号/设备号/功能号)。PCI定义每支PCI设备的[配置空间]为256字节,如下图,其中最前面的64个字节已由标准定义,余下的空间由设备自定义。
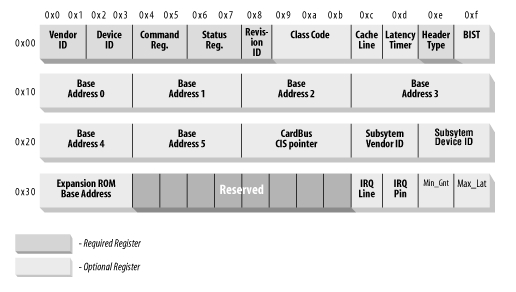
围绕[配置空间]有两种事务和三种操作角色,事务是[配置]和[使用配置],角色有静态配置的厂商和动态配置的操作系统,还有使用配置的设备驱动。静态配置的例子,如厂商在设备生产时配置其Vendor ID和Device ID;动态配置的例子,如操作系统初始化代码根据PCI设备的拓扑位置,配置设备的基地址(Base Address0~5)[注]。
使用配置的例子,如设备驱动的初始接口函数读取基地址寄存器(Base Address Registers),确定设备接口的基地址,下面的RTL8139设备初始化时你可以看到具体例子。
6.初始化net_device
现在我们回到驱动程序代码的开发上来。刚才我们已经讨论了设备驱动模块初始化中的设备检测和启用的任务,还有网络设备的表征结构,接下来我们先看看逻辑设备的初始化任务。
6.1 rtl8139_private
首先,作为一支特殊的网络设备,除了有标准的net_device表征,8139有其特殊数据,这是由C结构rtl8139_private 表征,由net_device->priv指向。rtl8139_private的定义如下:
- struct rtl8139_private
- {
- struct pci_dev *pci_dev;
- void *mmio_addr;
- unsigned long regs_len;
- };
Table 4: rtl8139_private structure
6.2 init_module
现在我们扩展init_module 函数,添加逻辑设备的初始化的任务。先看代码:
- int init_module(void)
- {
- struct pci_dev *pdev;
-
- unsigned long mmio_start, mmio_end, mmio_len, mmio_flags;
- void *ioaddr;
-
- struct rtl8139_private *tp;
- int i;
-
- pdev = probe_for_realtek8139( );
-
- if(!pdev)
- return 0;
-
- if(rtl8139_init(pdev, &rtl8139_dev)) {
-
- LOG_MSG("Could not initialize device\n");
- return 0;
- }
-
- tp = rtl8139_dev->priv;
首先probe_for_realtek8139函数检测和启用设备后返回一个PCI设备——pdev,然后rtl8139_init用pdev初始化rtl8139_private,转而初始化网络设备rtl8139_dev。
我们下一个目标是得到(初始化)设备的基地址——net_device的base_addr域。这是设备寄存器的内存映射的起始地址。本设备驱动程序只使用内存映射IO。
-
- mmio_start = pci_resource_start(pdev, 1);
-
- mmio_end = pci_resource_end(pdev, 1);
- mmio_len = pci_resource_len(pdev, 1);
-
- mmio_flags = pci_resource_flags(pdev, 1);
-
-
-
- if(!(mmio_flags & I/ORESOURCE_MEM)) {
- LOG_MSG("region not MMI/O region\n");
-
- goto cleanup1;
- }
-
-
- if(pci_request_regions(pdev, DRIVER)) {
-
- LOG_MSG("Could not get PCI region\n");
- goto cleanup1;
- }
-
- pci_set_master(pdev);
为了取得基地址,我们利用了内核PCI总线子系统提供的API:pci_resource_start, pci_resource_end, pci_resource_len, pci_resource_flags。注意这些API函数的第二个参数——BAR号1。PCI规定PCI设备最多可以申请6个PCI总线地址区,这些空间区的基地址分别保存在6个BAR里。在RealTek8139手册定义里,RTL只申请了两个区,第一个BAR(编号为0)是I/OAR,第二个 BAR(编号为1)是MEMAR。由于本设备驱动程序只使用内存映射IO,故BAR选用1。
现在,在使用这些地址之前,我们还有两件事要做。
-
- ioaddr = ioremap(mmio_start, mmio_len);
-
- if(!ioaddr) {
- LOG_MSG("Could not ioremap\n");
-
- goto cleanup2;
- }
-
- rtl8139_dev->base_addr = (long)ioaddr;
-
- tp->mmio_addr = ioaddr;
- tp->regs_len = mmio_len;
这两个事就是,第一,为设备驱动保留这些地址(调用pci_request_regions函数),以免被误用;第二,将这些物理地址重映射(remap);这在前面“内存映射的I/O”小节已经提到,驱动代码不能用直接使用物理地址。重映射后的地址io_addr填入 net_device的base_addr域后,我们可以读定设备的寄存器了。
剩下的代码比较直观和易理解了。
-
-
- for(i = 0; i < 6; i++) {
-
- rtl8139_dev->dev_addr[i] = readb(rtl8139_dev->base_addr+i);
-
- rtl8139_dev->broadcast[i] = 0xff;
- }
- rtl8139_dev->hard_header_len = 14;
-
- memcpy(rtl8139_dev->name, DRIVER, sizeof(DRIVER));
-
- rtl8139_dev->irq = pdev->irq;
- rtl8139_dev->open = rtl8139_open;
-
- rtl8139_dev->stop = rtl8139_stop;
- rtl8139_dev->hard_start_xmit = rtl8139_start_xmit;
-
- rtl8139_dev->get_stats = rtl8139_get_stats;
-
-
- if(register_netdev(rtl8139_dev)) {
-
- LOG_MSG("Could not register netdevice\n");
- goto cleanup0;
- }
-
- return 0;
- }
我们用了一个for循环来读取设备的硬件地址和广播地址(注意这回是直接用内核[设备操作API]的readb,而不是 PCI总线系统API),设备的硬件地址位于基地址的最前面。另外值得注意的是几个网络设备的接口函数指针,如open,hard_start_xmit 等,它们指向还没有实现的函数。为了编译驱动模块并进行测试,到此暂时为这些接口函数写一些Dummy测试代码。
6.3 逻辑设备的其它接口
- static int rtl8139_open(struct net_device *dev) {
- LOG_MSG("rtl8139_open iscalled\n");
- return 0;
- }
-
- static int rtl8139_stop(struct net_device *dev)
- {
- LOG_MSG("rtl8139_open is called\n");
- return 0;
- }
-
- static int rtl8139_start_xmit(struct sk_buff *skb, struct net_device *dev)
- {
- LOG_MSG("rtl8139_start_xmit is called\n");
- return 0;
- }
-
- static struct net_device_stats* rtl8139_get_stats(struct net_device *dev)
- {
- LOG_MSG("rtl8139_get_stats is called\n");
- return 0;
- }
Table 6: Dummy functions
6.4 注销函数
最后是注销函数:
- void cleanup_module(void)
- {
- struct rtl8139_private *tp;
- tp = rtl8139_dev->priv;
-
- iounmap(tp->mmio_addr);
- pci_release_regions(tp->pci_dev);
-
- unregister_netdev(rtl8139_dev);
- pci_disable_device(tp->pci_dev);
- return;
- }
Table 7: Function cleanup_module
6.5 编译测试
到此,一支完整的8139网卡设备驱动基本完成了,当然目前还只是一个模板,没有实质性的功能。我们可以编译并安装它了。
- $ gcc -c rtl8139.c -D__KERNEL__ -DMODULE -I /usr/src/linux-2.4.18/include
- $ insmod rtl8139.o
Table 8: Compiling the driver
安装不出问题的话,我们可以用SHELL命令进行测试:”ifconfig”, “ifconfig – a”, “ifconfig rtl8139 up”, “ifconfig” 和 “ifconfig rtl8139 down”。如无意外,”ifconfig – a” 会列出设备rtl8139;执行 “ifconfig rtl8139 up”会返回消息”function rtl8139_open called”等等……
好了,通过测试后,下一步是实现网络设备真正的数据收发了。为了更好理解实现代码,我们还是需要一些背景知识——理解RTL8139收发原理。
8.实现网络设备的发包功能
8.1 扩展rtl8139_private
在实现网络设备的打开和发送接口前,我必须先扩展我们的设备私有数据结构——rtl8139_private。
- #define NUM_TX_DESC 4
- struct rtl8139_private
- {
- struct pci_dev *pci_dev;
- void *mmio_addr;
- unsigned long regs_len;
- unsigned int tx_flag;
- unsigned int cur_tx;
- unsigned int dirty_tx;
- unsigned char *tx_buf[NUM_TX_DESC];
- unsigned char *tx_bufs;
- dma_addr_t tx_bufs_dma;
- };
Table 9: rtl8139_private structure
rtl8139_private为实现发包功能新添6个成员,我们一一介绍它们。tx_flag 成员从名字可知,发送状态字,它是《收发原理》中的TSD在主机方的一个副本,用来启动发送,下面代码中你将会看到;cur_tx成员和dirty_tx成员是《收发原理》中发包原理部分提到的两个全局变量——write_buff(记录最新可用缓冲区号)和read_buff(记录最后发送缓冲区号)的实现。tx_bufs是缓冲区的起始地址,tx_buf是地址数组,分别记录四块缓冲区的起始地址,它是《收发原理》中的TSAD在主机方的一个副本。注意这两种地址都是逻辑地址,在配置TSAD前必须转换为物理地址(转换方法在代码中可以看到)。转换的根据就是下一个成员,tx_bufs_dma。tx_bufs_dma保存缓冲区的物理地址。
8.2 扩展open接口
改写了rtl8139_private后,我们看open接口的新实现:
- static int rtl8139_open(struct net_device *dev)
- {
- int retval;
- struct rtl8139_private *tp = dev->priv;
-
-
-
-
-
- retval = request_irq(dev->irq, rtl8139_interrupt, 0, dev->name, dev);
- if(retval)
- return retval;
-
-
-
-
- tp->tx_bufs = pci_alloc_consistent(
- tp->pci_dev, TOTAL_TX_BUF_SIZE, &tp->tx_bufs_dma);
-
- if(!tp->tx_bufs) {
- free_irq(dev->irq, dev);
- return -ENOMEM;
- }
-
- tp->tx_flag = 0;
- rtl8139_init_ring(dev);
- rtl8139_hw_start(dev);
-
- return 0;
- }
-
- static void rtl8139_init_ring (struct net_device *dev)
- {
- struct rtl8139_private *tp = dev->priv;
- int i;
-
- tp->cur_tx = 0;
- tp->dirty_tx = 0;
-
- for (i = 0; i < NUM_TX_DESC; i++)
- tp->tx_buf[i] = &tp->tx_bufs[i * TX_BUF_SIZE];
-
- return;
- }
Table 11: Writing the open function
现在简要分析一下,open函数首先通过API(request_irq)向系统申请绑定IRQ号(KEMIN:逻辑中断号是怎么得到的?)和中断处理函数(rtl8139_interrupt);接着向PCI子系统申请内存空间给发送缓冲区(tp->tx_bufs),注意,pci_alloc_consistent直接返回的是虚拟地址,物理地址通过第三个参数返回。然后在rtl8139_init_ring 函数中将缓冲区分为四段(tp->tx_buf[i])。
- static void rtl8139_chip_reset (void *ioaddr)
- {
- int i;
-
-
- writeb(CmdReset, ioaddr + CR);
-
-
- for (i = 1000; i > 0; i--) {
- barrier();
- if ((readb(ioaddr + CR) & CmdReset) == 0)
- break;
- udelay (10);
- }
- return;
- }
缓冲区分配好后,rtl8139_hw_start函数可以启动硬件了。我们首先做是的重置(reset)设备——向设备命令寄存器(CR)写入重置值,让RTL8139回到预定状态;rtl8139_chip_reset函数使用了一个循环来检测重置操作,注意循环开始用了一个内存防护(barrier)操作,确保内核每次循环确切读取设备,而不作优化去读缓存。
- static void rtl8139_hw_start (struct net_device *dev)
- {
- struct rtl8139_private *tp = dev->priv;
- void *ioaddr = tp->mmio_addr;
- u32 i;
-
- rtl8139_chip_reset(ioaddr);
-
-
- writeb(CmdTxEnb, ioaddr + CR);
-
-
- writel(0x00000600, ioaddr + TCR);
-
-
- for (i = 0; i < NUM_TX_DESC; i++) {
- writel(tp->tx_bufs_dma + (tp->tx_buf[i] - tp->tx_bufs),ioaddr + TSAD0 + (i * 4));
- }
-
-
- writew(INT_MASK, ioaddr + IMR);
-
- netif_start_queue (dev);
- return;
- }
完成重置操作后,我们启用设备的发送功能——向设备命令寄存器(CR)写入启用值。然后,我们配置发送模式—— TCR (Transmission Configuration Register),这里我们只配置了“DMA突发传输的最大值”(Max DMA Burst Size per Tx DMA Burst),其它使用默认配置。接着我们把刚分配好四段缓冲区地址(转为物理地址后)写入四个发送描述符(TSAD),最后打开所有中断——将IMR (Interrupt Mask Register)全部位置1;
至此,设备使用前配置基本完成,最后调用netif_start_queue,把设备挂到系统活动的网络设备列表,供网络协议栈使用。
8.3 发送接口hard_start_xmit
我们现在可以进一点充实发包接口了。代码如下:
- #define ETH_MIN_LEN 60 /* minimum Ethernet frame size */
-
- static int rtl8139_start_xmit(struct sk_buff *skb, struct net_device *dev)
- {
- struct rtl8139_private *tp = dev->priv;
- void *ioaddr = tp->mmio_addr;
- unsigned int entry = tp->cur_tx;
- unsigned int len = skb->len;
-
- if (len < TX_BUF_SIZE) {
- if(len < ETH_MIN_LEN)
- memset(tp->tx_buf[entry], 0, ETH_MIN_LEN);
- skb_copy_and_csum_dev(skb, tp->tx_buf[entry]);
- dev_kfree_skb(skb);
- } else {
- dev_kfree_skb(skb);
- return 0;
- }
-
- writel(tp->tx_flag | max(len, (unsigned int)ETH_MIN_LEN),
- ioaddr + TSD0 + (entry * sizeof (u32)));
- entry++;
- tp->cur_tx = entry % NUM_TX_DESC;
-
- if(tp->cur_tx == tp->dirty_tx) {
- netif_stop_queue(dev);
- }
- return 0;
- }
Table 12: Writing start_xmit function
发送接口函数还是比较直观的。首先,函数检查数据包大小,确保不大于缓冲区,亦不小于以太网帧最小值(60字节);然后调用skb_copy_and_csum_dev函数将其拷入第cur_tx号缓冲区。完了后,配置tx_flag(这里只配置了数据包的大小,不限阀值)后调用writel将其写TSD,启动发送。接着,更新cur_tx,代码用模操作(%)来实现缓冲区循环制使用。最后判断缓冲区是否满,然则通知协议栈停止发送。
8.4 发包完成中断处理
数据包发走后还需要后续处理,处理在中断处理函数内完成。设备驱动只有一支中断处理函数,设备的中断事件需在函数内进一步区分。
rtl8139_interrupt
- static void rtl8139_interrupt (int irq, void *dev_instance, struct pt_regs *regs)
- {
- struct net_device *dev = (struct net_device*)dev_instance;
- struct rtl8139_private *tp = dev->priv;
- void *ioaddr = tp->mmio_addr;
- unsigned short isr = readw(ioaddr + ISR);
-
-
-
-
-
-
- writew(0xffff, ioaddr + ISR);
-
- if((isr & TxOK) || (isr & TxErr))
- {
- while((tp->dirty_tx != tp->cur_tx) || netif_queue_stopped(dev))
- {
- unsigned int txstatus =
- readl(ioaddr + TSD0 + tp->dirty_tx * sizeof(int));
-
- if(!(txstatus & (TxStatOK | TxAborted | TxUnderrun)))
- break;
-
- if(txstatus & TxStatOK) {
- LOG_MSG("Transmit OK interrupt\n");
- tp->stats.tx_bytes += (txstatus & 0x1fff);
- tp->stats.tx_packets++;
- }
- else {
- LOG_MSG("Transmit Error interrupt\n");
- tp->stats.tx_errors++;
- }
-
- tp->dirty_tx++;
- tp->dirty_tx = tp->dirty_tx % NUM_TX_DESC;
-
- if((tp->dirty_tx == tp->cur_tx) & netif_queue_stopped(dev))
- {
- LOG_MSG("waking up queue\n");
- netif_wake_queue(dev);
- }
- }
- }
- .......
- }
代码中我们可以看到,中断处理首先将8139的中断状态复制到本地,然后重置中断状态;接着判断是什么中断事件,如果是发包完成(TxOK),则取得发送状态信息,然后作一些统计。最后更新读指针(dirty_tx),并唤醒发包队列。
值得注意的是,统计和更新操作在一个while循环内完成的,那是因为8139不是在成功发送一个包后发出中断,而是将缓冲区上所有包发走后才发出中断的。可以想像一下发包情形,由于相对于8139,主机CPU较快,它会在很短的时间内(或在发完第一个包之前)[注]将发包缓冲区填满而停掉发包队列,等待缓冲区再次可用,而8139在处理完所有TSD.OWN为0的缓冲区后,发出中断,唤醒发包队列,如此循环往复。
现在我们的驱动程序已经具有发包功能了。你可以编译并安装它,尝试ping一个远程主机,如无意外,你将在远程主机看到有ARP数据包收到;不过在本地,我们看不到远程主机发回的ARP应答包,因为我们还没有实现收包功能。
9.实现网络设备的收包功能
接下来,我们实现网络设备的收包功能,与发包功能实现相似,我们需要扩展现有打开接口和设备私有数据。
9.1 扩展rtl8139_private
- struct rtl8139_private
- {
- struct pci_dev *pci_dev;
- void *mmio_addr;
- unsigned long regs_len;
- unsigned int tx_flag;
- unsigned int cur_tx;
- unsigned int dirty_tx;
- unsigned char *tx_buf[NUM_TX_DESC];
- unsigned char *tx_bufs;
- dma_addr_t tx_bufs_dma;
-
- struct net_device_stats stats;
- unsigned char *rx_ring;
- dma_addr_t rx_ring_dma;
- unsigned int cur_rx;
- };
Table 13: Extending rtl8139_private structure
rtl8139_private为实现收包功能新添4个成员。stats成员是net_device_stats实例[注],记录设备运作的统计信息(如大部分通过ifconfig查询到的统计信息来源此成员)。rx_ring成员是收包缓冲区(环形缓冲区)的逻辑地址,rx_ring_dma成员是对应的物理地址。cur_rx成员是环缓冲的读指针,不过它的类型不是指针,因为它是一个16位偏移值。
9.2 扩展open接口
扩展的第一步是分配收包缓冲区。
-
- #define RX_BUF_LEN_IDX 2 /* 0==8K, 1==16K, 2==32K, 3==64K */
- #define RX_BUF_LEN (8192 << RX_BUF_LEN_IDX)
- #define RX_BUF_PAD 16 /* see 11th and 12th bit of RCR: 0x44 */
- #define RX_BUF_WRAP_PAD 2048 /* spare padding to handle pkt wrap */
- #define RX_BUF_TOT_LEN (RX_BUF_LEN + RX_BUF_PAD + RX_BUF_WRAP_PAD)
-
-
- tp->tx_bufs = pci_alloc_consistent(tp->pci_dev, TOTAL_TX_BUF_SIZE, &tp->tx_bufs_dma);
-
-
- tp->rx_ring = pci_alloc_consistent(tp->pci_dev, RX_BUF_TOT_LEN,
- &tp->rx_ring_dma);
-
- if((!tp->tx_bufs) || (!tp->rx_ring)) {
- free_irq(dev->irq, dev);
-
- if(tp->tx_bufs) {
- pci_free_consistent(tp->pci_dev, TOTAL_TX_BUF_SIZE, tp->tx_bufs, tp->tx_bufs_dma);
- p->tx_bufs = NULL;
- }
- if(tp->rx_ring) {
- pci_free_consistent(tp->pci_dev, RX_BUF_TOT_LEN, tp->rx_ring,
- tp->rx_ring_dma);
- tp->rx_ring = NULL;
- }
- return -ENOMEM;
- }
Table 14: Extending rtl8139_open function
代码14首先算得收包缓冲区所需大小。RX_BUF_TOT_LEN 的值取决于收包配置(RCR寄存器)。我将在下面扩展的rtl8139_hw_start函数看到,我们配置了RCR的位12-11为10,位7为1;前者意为收包缓冲区大小为32K+16,后者意为当写入收到的数据包写到了缓冲区的末端,而数据包还没有收完时,剩下的数据继续往下写,而不写到缓冲区的始端,因此我们为收包缓冲区分配了2K额外的附加区。
现在我们扩展rtl8139_hw_start:
- static void rtl8139_hw_start (struct net_device *dev)
- {
- struct rtl8139_private *tp = dev->priv;
- void *ioaddr = tp->mmio_addr;
- u32 i;
-
- rtl8139_chip_reset(ioaddr);
-
-
- writeb(CmdTxEnb | CmdRxEnb, ioaddr + CR);
-
-
- writel(0x00000600, ioaddr + TCR);
-
-
- writel(((1 << 12) | (7 << 8) | (1 << 7) |
- (1 << 3) | (1 << 2) | (1 << 1)), ioaddr + RCR);
-
-
- for (i = 0; i < NUM_TX_DESC; i++) {
- writel(tp->tx_bufs_dma + (tp->tx_buf[i] - tp->tx_bufs),
- ioaddr + TSAD0 + (i * 4));
- }
-
-
- writel(tp->rx_ring_dma, ioaddr + RBSTART);
-
-
- writel(0, ioaddr + MPC);
-
-
- writew((readw(ioaddr + MULINT) & 0xF000), ioaddr + MULINT);
-
-
- writew(INT_MASK, ioaddr + IMR);
-
- netif_start_queue (dev);
- return;
- }
Table 15: Extending rtl8139_hw_start function
代码15中,首先改动的是写入CR寄存器值 CmdTxEnb | CmdRxEnb,意为同时开启收包和发包功能;接着配置了收包功能,我在代码没有使用macros作配置值,但意思已经很明白了,RCR的配置位意思如下:
- Bit 1 – 接受物理匹配的包
- Bit 2 – 接受组播包
- Bit 3 – 接受广播包
- Bit 7 – WRAP,当写入收到的数据包写到了缓冲区的末端,而数据包还没有收完时,剩下的数据继续往下写,还是截断写到始端
- Bit 8-10 – 最大DMA单次突发传输量,我们配置为111,即无限制
- Bit 11-12 – 收包缓冲区大小,我们配置为10,即32K+16 bytes
接着的改动是配置了8139的RBSTART寄存器,告诉8139收包缓冲区的起始地址;最后初始化了MPC (Missed Packet Counter)寄存和屏蔽了预收包中断(early rx interrupts)。
9.3 收包中断处理函数
收包功能最后一步是收包中断处理。
- static void rtl8139_interrupt (int irq, void *dev_instance, struct pt_regs *regs)
- {
- struct net_device *dev = (struct net_device*)dev_instance;
- struct rtl8139_private *tp = dev->priv;
- void *ioaddr = tp->mmio_addr;
- unsigned short isr = readw(ioaddr + ISR);
-
-
-
-
-
-
- writew(0xffff, ioaddr + ISR);
-
- if(isr & RxOK) {
- LOG_MSG("receive interrupt received\n");
- while((readb(ioaddr + CR) & RxBufEmpty) == 0)
- {
- unsigned int rx_status;
- unsigned short rx_size;
- unsigned short pkt_size;
- struct sk_buff *skb;
-
- if(tp->cur_rx > RX_BUF_LEN)
- tp->cur_rx = tp->cur_rx % RX_BUF_LEN;
-
-
-
-
- rx_status = *(unsigned int*)(tp->rx_ring + tp->cur_rx);
- rx_size = rx_status >> 16;
-
-
-
-
- pkt_size = rx_size - 4;
-
-
- skb = dev_alloc_skb (pkt_size + 2);
- if (skb) {
- skb->dev = dev;
- skb_reserve (skb, 2);
-
- eth_copy_and_sum(
- skb, tp->rx_ring + tp->cur_rx + 4, pkt_size, 0);
-
- skb_put (skb, pkt_size);
- skb->protocol = eth_type_trans (skb, dev);
- netif_rx (skb);
-
- dev->last_rx = jiffies;
- tp->stats.rx_bytes += pkt_size;
- tp->stats.rx_packets++;
- }
- else {
- LOG_MSG("Memory squeeze, dropping packet.\n");
- tp->stats.rx_dropped++;
- }
-
-
-
-
-
- writew(tp->cur_rx, ioaddr + CAPR);
- }
- }
-
- }
Table 16: Interrupt Handler
代码中我们可以看到,中断处理首先将8139的中断状态复制到本地,然后重置中断状态;接着判断收包中断事件(RxOK)。收包处理使用了一个while循环,可见收包与发包类似,都不是每包一次中断,而每缓冲区一次中断,这样降低的中断次数,提高收发效率。收包循环第一件事是判断读指针(cur_rx)是否越出缓冲区边界(从前面的收包功能配置可知,收包缓冲区可配置附加区的),如果越出,则wrap回来。完了后开始正式的收包操作,如取得收包状态、分析包大小、分配skb、对skb作一些链路层处理后将其交与内核的收包接口netif_rx,最后统计。
收包处理最后一步是更新读指针,包括主机CPU副本cur_rx和8139的CAPR。更新8139的CAPR还有一个重要的副作用,就是如果CAPR==CBA时,8139置CR.RxBufEmpty为1,表示缓冲为空,8139对外发出消除暂停控制帧,驱动程序退出while循环,完成收包中断处理。
9.4 统计
最后实现的接口是rtl8139_get_stats,它只是简单地返回tp->stats:
- static struct net_device_stats* rtl8139_get_stats(struct net_device *dev)
- {
- struct rtl8139_private *tp = dev->priv;
- return &(tp->stats);
- }
Table 17: rtl8139_get_stats function
到此,网卡设备驱动基本完成,你可以再次编译并安装它,尝试ping一个远程主机,如无意外,你将在远程主机看到有ARP数据包收到;在本地,亦可以收到远程主机发回的ARP应答包。























 7358
7358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









