机器学习与深度学习笔记
 关注
关注
 分享
分享
文章平均质量分 92
让更多人了解机器学习,学习算法的核心思想;关注机器学习/深度学习/增强学习等各类学习算法,以及高性能计算硬件架构,异构计算等主题
大饼博士X
关注机器学习/深度学习算法与硬件加速
展开
-
深度学习方法(二十一):常用权重初始化方法Xavier,He initialization的推导
文章目录交叉熵目标函数更陡峭Xavier initialization [1][4]He initialization [2][3]He init 考虑ReLU函数He init 考虑Leaky ReLU函数结束语参考资料交叉熵目标函数更陡峭在论文[1]中给了一个图示,一定程度上说明了为什么Cross Entropy用的很多,效果很好。图中上面的曲面表示的是交叉熵代价函数,下面的曲面表示的是二次代价函数,W1和W2分别表示层与层之间的连接权值。)在1986年 Rumelhart 已经发现:logi原创 2020-08-09 18:01:02 · 5059 阅读 · 2 评论 -
今天开始学Convex Optimization:第3章 Convex Sets and Convex functions
第3章 Convex Sets and Convex functions原创 2020-04-05 22:58:11 · 2322 阅读 · 0 评论 -
入门神经网络优化算法(六):二阶优化算法K-FAC
上一篇介绍了二阶优化算法Natural Gradient Descent(自然梯度算法),虽然可以避免计算Hessian,但是依然在计算代价上极高,对于大型的神经网络参数规模依然不可能直接计算。本篇继续介绍自然梯度算法后续的一个近似计算方法K-FAC原创 2020-03-29 22:27:55 · 5913 阅读 · 0 评论 -
深度学习方法(二十):Hinton组最新无监督学习方法SimCLR介绍,以及Momentum Contrastive(MoCo)
本篇文章记录一下最近发表的两个比较类似的无监督representation learning工作: - SimCLR——Hinton组的工作,第一作者Ting Chen - MoCo v2——He Kaiming组的工作,第一作者Xinlei Chen原创 2020-03-21 21:13:41 · 11889 阅读 · 0 评论 -
深度学习方法(十九):一文理解Contrastive Loss,Triplet Loss,Focal Loss
我们平时ML任务的时候,用的最多的是cross entropy loss或者MSE loss。需要有一个明确的目标,比如一个具体的数值或者是一个具体的分类类别。但是ranking loss实际上是一种metric learning,他们学习的相对距离,相关关系,而对具体数值不是很关心。ranking loss 有非常多的叫法,但是他们的公式实际上非常一致的。大概有两类,一类是输入pair 对,另外一种是输入三元组结构。原创 2020-03-08 21:21:53 · 27545 阅读 · 4 评论 -
入门神经网络优化算法(五):一文看懂二阶优化算法Natural Gradient Descent(Fisher Information)
二阶优化算法Natural Gradient Descent,是从分布空间推导最速梯度下降方向的方法,和牛顿方法有非常紧密的联系。Fisher Information Matrix往往可以用来代替牛顿法的Hessian矩阵计算。下面详细道来。原创 2020-03-03 00:51:11 · 6932 阅读 · 2 评论 -
深度学习/机器学习入门基础数学知识整理(八):中心极限定理,一元和多元高斯分布
高斯分布Gaussian distribution,也叫正太分布Normal distribution,是一个在数学、物理及工程等领域都非常重要的概率分布,在统计学的许多方面有着重大的影响力。原创 2020-02-13 22:59:45 · 3845 阅读 · 0 评论 -
深度学习/机器学习入门基础数学知识整理(七):数学上sup、inf含义,和max、min的区别
经常在文献中看到inf和sup,很多人不知道是什么意思。其实这两个概念是来自于“数学分析”中的上确界和下确界:inf: infimum 或 infima,中文叫下确界或最大下界。 inf(S), S表示一个集合, inf(S)是指集合S的下确界, 即小于或等于S中所有元素的最大值, 这个数不一定在集合S中。sup:supremum,中文叫上确界。sup(S)是指集合S的上确界,即大于或等于S的所有元素的最小值, 这个数不一定在集合S中。原创 2020-02-11 23:27:51 · 50210 阅读 · 0 评论 -
今天开始学Convex Optimization:引言、第1章基本概念介绍
Convex Optimization 凸优化书第一节,introduction。凸优化问题:本书主要介绍凸优化问题,定义是:对于目标函数以及约束函数都是convex的优化问题,称为convex optimization问题原创 2020-02-09 23:33:12 · 4712 阅读 · 2 评论 -
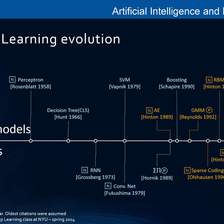
大饼博士的神经网络/机器学习算法收录合集:2020年整理,持续更新ing
本文用于随手记录一些Neural Network论文,主要是关注一些我觉得有趣的AI算法、网络结构。比较杂,随时看到随时记录,自己mark用。原创 2020-02-07 23:05:39 · 2892 阅读 · 0 评论 -
三十分钟在Windows10安装Anaconda+Pytorch+Cuda,老式Nvidia GTX游戏显卡实测可用
这几天捣鼓了一下在自己老式的台式机上安装Pytorch,打算稍微有空的时候玩(学习)一下。我的机器是Windows10系统+Nvidia GTX960显卡,采用Anaconda安装,解决几个小问题后基本上可以说是一键安装使用,非常方便。记录一下,方便同学们查用。我安装的版本没有选择最新版本,最后安装下来的是CUDA9.0+Pytorch1.1,我想也基本够用了。原创 2020-02-01 22:59:11 · 5836 阅读 · 2 评论 -
深度学习/机器学习入门基础数学知识整理(五):Jensen不等式简单理解,共轭函数
Jensen不等式及其延伸 [1]凸函数最基本的不等式性质,又称Jensen不等式 f(θx+(1−θ)y)≤θ f(x)+(1−θ) f(y)f(θx+(1−θ)y)≤θ f(x)+(1−θ) f(y)f(\theta x+(1-\theta)y)\leq \theta\ f(x)+ (1-\theta)\ f(y) 许多著名的不等式都是由Je...原创 2018-07-30 00:33:41 · 3670 阅读 · 0 评论 -
深度学习/机器学习入门基础数学知识整理(四):拟牛顿法、BFGS、L-BFGS、DFP、共轭梯度法
参考资料https://blog.csdn.net/batuwuhanpei/article/details/51979831 https://blog.csdn.net/u011722133/article/details/53518134 无约束优化方法(梯度法-牛顿法-BFGS- L-BFGS) 优化算法——拟牛顿法之DFP算法 牛顿法与拟牛顿法 牛顿法,拟牛顿法, 共轭梯度法...原创 2018-07-15 01:39:23 · 4447 阅读 · 0 评论 -
深度学习/机器学习入门基础数学知识整理(三):凸优化,Hessian,牛顿法
凸优化理论本身非常博大,事实上我也只是了解了一个皮毛中的皮毛,但是对于广大仅仅想要了解一下机器学习或者深度学习的同学来说,稍微了解一点凸优化也就够了。在实际工程问题中,比如现在我们用的最多的深度神经网络的求解优化问题,都是非凸的,因此很多凸优化理论中非常有价值的定理和方法,在非凸优化问题中不适用,或者说并没有收敛保证等。但是,作为知识的基础,依然有必要来理解和学习一下凸优化,本篇整理了非常基础的一...原创 2018-01-20 21:05:27 · 19212 阅读 · 3 评论 -
深度学习/机器学习入门基础数学知识整理(二):梯度与导数,矩阵求导,泰勒展开等
导数与梯度导数:一个一元函数函数在某一点的导数描述了这个函数在这一点附近的变化率。 f′(a)=limh→0f(a+h)−f(a)hf'(a) = \lim_{h \rightarrow 0} \frac{f(a+h)-f(a)}{h}梯度:多元函数的导数就是梯度。一阶导数,即梯度(gradient):∇f(X)=∂f(X)∂X=⎡⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢∂f(X)∂原创 2018-01-19 23:17:48 · 7955 阅读 · 2 评论 -
深度学习/机器学习入门基础数学知识整理(一):线性代数基础,矩阵,范数等
前面大概有2年时间,利用业余时间断断续续写了一个机器学习方法系列,和深度学习方法系列,还有一个三十分钟理解系列(一些趣味知识);新的一年开始了,今年给自己定的学习目标——以补齐基础理论为重点,研究一些基础课题;同时逐步继续写上述三个系列的文章。最近越来越多的研究工作聚焦研究多层神经网络的原理,本质,我相信深度学习并不是无法掌控的“炼金术”,而是真真实实有理论保证的理论体系;本篇打算摘录整理原创 2018-01-14 14:08:39 · 27798 阅读 · 17 评论 -
三十分钟理解计算图上的微积分:Backpropagation,反向微分
神经网络的训练算法,目前基本上是以Backpropagation (BP) 反向传播为主(加上一些变化),NN的训练是在1986年被提出,但实际上,BP 已经在不同领域中被重复发明了数十次了(参见 Griewank (2010)[1])。更加一般性且与应用场景独立的名称叫做:反向微分 (reverse-mode differentiation)。本文是看了资料[2]中的介绍,写的蛮好,自己记录一下,原创 2017-03-04 22:33:04 · 9962 阅读 · 4 评论 -
深度学习方法(十四):轻量级CNN网络设计——MobileNet,ShuffleNet,文末有思考
本系列前面介绍了非常多卷积网络结构设计,事实上,在inception和resnet网络提出并相对完善以后,网络结构的设计就不再爆发式出现了,这两大类网路涵盖了大部分应用的卷积网络结构。在本文中,我们来一起看一些最近一年研究较多的轻量级卷积网络结构,这些网络主要的设计目标是——在保证一定的识别精度情况下,尽可能减少网络规模(参数量、计算量)。最直接的设计目标就是用于手机等移动终端中(CPU),让原创 2017-08-25 22:16:54 · 25029 阅读 · 1 评论 -
分布式机器学习系统笔记(一)——模型并行,数据并行,参数平均,ASGD
模型并行( **model parallelism** ):分布式系统中的不同机器(GPU/CPU等)负责网络模型的不同部分 —— 例如,神经网络模型的不同网络层被分配到不同的机器,或者同一层内部的不同参数被分配到不同机器;[14] - 数据并行( **data parallelism** ):不同的机器有同一个模型的多个副本,每个机器分配到不同的数据,然后将所有机器的计算结果按照某种方式合并。原创 2017-07-29 21:45:48 · 39772 阅读 · 12 评论 -
深度学习方法(十三):卷积神经网络结构变化——可变形卷积网络deformable convolutional networks
上一篇我们介绍了:深度学习方法(十二):卷积神经网络结构变化——Spatial Transformer Networks,STN创造性地在CNN结构中装入了一个可学习的仿射变换,目的是增加CNN的旋转、平移、缩放、剪裁性。为什么要做这个很奇怪的结构呢?原因还是因为CNN不够鲁棒,比如把一张图片颠倒一下,可能就不认识了(这里mark一下,提高CNN的泛化能力,值得继续花很大力气,STN是一个思路,读者原创 2017-04-19 22:44:10 · 19592 阅读 · 1 评论 -
深度学习方法(十二):卷积神经网络结构变化——Spatial Transformer Networks
今天具体介绍一个Google DeepMind在15年提出的Spatial Transformer Networks,相当于在传统的一层Convolution中间,装了一个“插件”,可以使得传统的卷积带有了[裁剪]、[平移]、[缩放]、[旋转]等特性;理论上,作者希望可以减少CNN的训练数据量,以及减少做data argument,让CNN自己学会数据的形状变换。这篇论文我相信会启发很多新的改进,也就是对卷积结构作出原创 2017-04-03 23:45:44 · 24318 阅读 · 15 评论 -
自组织神经网络介绍:自组织特征映射SOM(Self-organizing feature Map),第一部分
自组织神经网络介绍:自组织特征映射SOM(Self-organizing feature Map),第一部分 自组织神经网络介绍:自组织特征映射SOM(Self-organizing feature Map),第二部分 自组织神经网络介绍:自组织特征映射SOM(Self-organizing feature Map),第三部分本文详细介绍一下自组织神经网络概念和原理,并重点介绍一下自组织特征映射原创 2016-03-07 23:21:05 · 57612 阅读 · 8 评论 -
自组织神经网络介绍:自组织特征映射SOM(Self-organizing feature Map),第二部分
上一篇介绍了一些自组织神经网络的基本概念,第一部分,这一篇讲下SOM的概念和原理,是本文的第二部分。1、SOM背景1981年芬兰Helsink大学的T.Kohonen教授提出一种自组织特征映射网,简称SOM网,又称Kohonen网。Kohonen认为:一个神经网络接受外界输入模式时,将会分为不同的对应区域,各区域对输入模式具有不同的响应特征,而且这个过程是自动完成的。自组织特征映射正是根据这一看法提原创 2016-03-08 22:50:56 · 29269 阅读 · 2 评论 -
自组织神经网络介绍:自组织特征映射SOM(Self-organizing feature Map),第三部分
前面介绍了SOM的基本概念和算法,第一部分,第二部分,本篇具体展开一下应用中的一些trick设定。SOM设计细节输出层设计 输出层神经元数量设定和训练集样本的类别数相关,但是实际中我们往往不能清除地知道有多少类。如果神经元节点数少于类别数,则不足以区分全部模式,训练的结果势必将相近的模式类合并为一类;相反,如果神经元节点数多于类别数,则有可能分的过细,或者是出现“死节点”,即在训练过程中,某个节点原创 2016-03-15 00:21:08 · 21114 阅读 · 3 评论 -
[重磅]Deep Forest,非神经网络的深度模型,周志华老师最新之作,三十分钟理解!
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld。 技术交流QQ群:433250724,欢迎对算法、技术感兴趣的同学加入。深度学习最大的贡献,个人认为就是表征学习(representation learning),通过端到端的训练,发现更好的features,而后面用于分类(或其他任务)的输出function,往往也只是普通的softmax(或者其他一些经原创 2017-03-06 00:03:08 · 25083 阅读 · 5 评论 -
深度学习方法(十一):卷积神经网络结构变化——Google Inception V1-V4,Xception(depthwise convolution)
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld。 技术交流QQ群:433250724,欢迎对算法、机器学习技术感兴趣的同学加入。上一篇讲了深度学习方法(十):卷积神经网络结构变化——Maxout Networks,Network In Network,Global Average Pooling,本篇讲一讲Google的Inception系列net,以及原创 2017-03-15 23:30:28 · 25174 阅读 · 1 评论 -
机器学习方法:回归(一):线性回归Linear regression
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld。开一个机器学习方法科普系列:做基础回顾之用,学而时习之;也拿出来与大家分享。数学水平有限,只求易懂,学习与工作够用。周期会比较长,因为我还想写一些其他的,呵呵。 content: linear regression, Ridge, Lasso Logistic Regression, Softmax ...原创 2015-03-19 22:18:47 · 85259 阅读 · 3 评论 -
机器学习方法:回归(二):稀疏与正则约束ridge regression,Lasso
本篇内容讲述回归问题中最常用的ridge regression与Lasso,同时深入浅出地探讨稀疏约束,正则,分析了Lasso稀疏的原因。原创 2015-03-26 22:02:58 · 47245 阅读 · 12 评论 -
机器学习方法:回归(三):最小角回归Least Angle Regression(LARS),forward stagewise selection
前面两篇回归(一)(二)复习了线性回归,以及L1与L2正则——lasso和ridge regression。特别描述了lasso的稀疏性是如何产生的。在本篇中介绍一下和lasso可以产生差不多效果的两种方法:stagewise和LARS原创 2015-04-06 13:40:00 · 42791 阅读 · 14 评论 -
机器学习方法(四):决策树Decision Tree原理与实现技巧
前面三篇写了线性回归,lasso,和LARS的一些内容,这篇写一下决策树这个经典的分类算法,后面再提一提随机森林。关于决策树的内容主要来自于网络上几个技术博客,本文中借用的地方我都会写清楚出处,写这篇[整理文章]的目的是对决策树的原创 2015-04-06 13:33:52 · 73346 阅读 · 8 评论 -
机器学习方法(六):随机森林Random Forest,bagging
前面[机器学习方法(四)决策树](http://blog.csdn.net/xbinworld/article/details/44660339)讲了经典的决策树算法,我们讲到决策树算法很容易过拟合,因为它是通过最佳策略来进行属性分裂的,这样往往容易在train data上效果好,但是在test data上效果不好。随机森林random forest算法,本质上是一种ensemble的方法,可以有效的降低过拟合,本文原创 2016-01-03 21:47:11 · 32894 阅读 · 0 评论 -
机器学习方法(七):Kmeans聚类K值如何选,以及数据重抽样方法Bootstrapping
本篇介绍了聚类如何选择K的一种方法(实际上,除了kmeans以外,还可以用于很多其他的聚类方法,如果他们也要确定k。)。该方法使用的Parametric bootstrap来抽样,是统计中bootstrap方法的一种类型。我们还介绍了基本的bootstrap方法,有放回的抽取,以及更平滑的smooth bootstrap方法,这些算法都是简单而有道理原创 2016-02-15 22:42:30 · 27336 阅读 · 4 评论 -
机器学习方法(八):随机采样方法整理(MCMC、Gibbs Sampling等)
转载请注明出处:Bin的专栏,http://blog.csdn.net/xbinworld本文是对参考资料中多篇关于sampling的内容进行总结+搬运,方便以后自己翻阅。其实参考资料中的资料写的比我好,大家可以看一下!好东西多分享!PRML的第11章也是sampling,有时间后面写到PRML的笔记中去:)背景随机模拟也可以叫做蒙特卡罗模拟(Monte Carlo Sim原创 2015-02-07 22:20:29 · 29448 阅读 · 7 评论 -
深度学习方法:受限玻尔兹曼机RBM(一)基本概念
最近在复习经典机器学习算法的同时,也仔细看了一些深度学习的典型算法。深度学习是机器学习的“新浪潮”,它的成功主要得益于深度“神经网络模型”的优异效果。这个小系列打算深入浅出地记录一下深度学习中常用的一些算法。第一篇先写一下“受限玻尔兹曼机“RBM。原创 2015-04-17 07:53:18 · 30522 阅读 · 1 评论 -
深度学习方法:受限玻尔兹曼机RBM(二)网络模型
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld。 技术交流QQ群:433250724,欢迎对算法、技术、应用感兴趣的同学加入。上解上一篇RBM(一)基本概念,本篇记叙一下RBM的模型结构,以及RBM的目标函数(能量函数),通过这篇就可以了解RBM到底是要求解什么问题。在下一篇(三)中将具体描述RBM的训练/求解方法,包括Gibbs sampling和对比原创 2015-04-22 00:20:57 · 15472 阅读 · 3 评论 -
深度学习方法:受限玻尔兹曼机RBM(四)对比散度contrastive divergence,CD
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld。 技术交流QQ群:433250724,欢迎对算法、技术、应用感兴趣的同学加入。上篇讲到,如果用Gibbs Sampling方法来训练rbm会非常慢,本篇中介绍一下对比散度contrastive divergence, CD算法。我们希望得到P(v)P(\textbf{v})分布下的样本,而我们有训原创 2015-12-31 22:29:08 · 16085 阅读 · 5 评论 -
机器学习方法(五):逻辑回归Logistic Regression,Softmax Regression
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld。 技术交流QQ群:433250724,欢迎对算法、技术、应用感兴趣的同学加入。逻辑回归可以说是最为常用的机器学习算法之一,最经典的场景就是计算广告中用于CTR预估,是很多广告系统的核心算法。原创 2015-05-12 22:56:53 · 13575 阅读 · 2 评论 -
深度学习方法:受限玻尔兹曼机RBM(三)模型求解,Gibbs sampling
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld。 技术交流QQ群:433250724,欢迎对算法、技术、应用感兴趣的同学加入。本篇重点讲一下RBM模型求解方法,其实用的依然是梯度上升方法,但是求解的方法需要用到随机采样的方法,常见的有:Gibbs Sampling和对比散度(contrastive divergence, CD)算法。RBM原创 2015-12-19 08:56:56 · 16521 阅读 · 2 评论 -
深度学习方法(五):卷积神经网络CNN经典模型整理Lenet,Alexnet,Googlenet,VGG,Deep Residual Learning
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld。 技术交流QQ群:433250724,欢迎对算法、技术感兴趣的同学加入。关于卷积神经网络CNN,网络和文献中有非常多的资料,我在工作/研究中也用了好一段时间各种常见的model了,就想着简单整理一下,以备查阅之需。如果读者是初接触CNN,建议可以先看一看“Deep Learning(深度学习)学习笔记整理系原创 2016-01-02 11:18:40 · 106572 阅读 · 12 评论 -
深度学习方法(六):神经网络weight参数怎么初始化
神经网络,或者深度学习算法的参数初始化是一个很重要的方面,传统的初始化方法从高斯分布中随机初始化参数。甚至直接全初始化为1或者0。这样的方法暴力直接,但是往往效果一般。本篇文章的叙述来源于一个国外的讨论帖子[1],下面就自己的理解阐述一原创 2016-02-12 17:27:51 · 26984 阅读 · 1 评论