







 本文介绍CUDA如何与OpenGL、Direct3D交互,实现图形资源的共享和处理,包括资源注册、映射、核函数调用等关键步骤。同时,讨论了多GPU系统中SLI配置的注意事项,以及CUDA版本兼容性和计算模式的设定。
本文介绍CUDA如何与OpenGL、Direct3D交互,实现图形资源的共享和处理,包括资源注册、映射、核函数调用等关键步骤。同时,讨论了多GPU系统中SLI配置的注意事项,以及CUDA版本兼容性和计算模式的设定。
运行时
图形交互
一些来自其他软件的资源, 如OpenGL, Direct3D 可以映射至CUDA的地址空间。 这样CUDA 就可读取由其他程序所写的数据, 同时也能产出可以供它们使用的数据。
在将资源映射至CUDA的地址空间之前,它必须使用一些API中的函数来先进行注册。这些函数会返回一个指向CUDA图形资源struct cudaGraphicsResource的指针。注册资源会有很高的overhead,因此每个资源最好只注册一次。CUDA图形资源也可以使用cudaGraphicsUnregistrerResource()来使之变成未注册。每个CUDA context试图使用的资源都必须对它进行单独注册。
被注册至CUDA的资源,在必要的时候它可以通过APIcudaGraphicsMapResource()和cudaGraphicsUnmapResource()映射或者取消映射多次。cudaGraphicsResourceSetMapFlags()可以用来指定一些标志(只读、只写), 这样有利于CUDA 驱动来有优化资源的管理。核函数可以对 被映射的资源进行读写,它需要借助cudaGraphicsResourcdeGetMappedPointer()获取的buffer的指针; cudaGraphicsSubResourcdeGetMappedArray()获取CUDA数组。
OpenGL 交互
OpenGL的资源可以映射至CUDA地址空间的资源有:buffer、texture_和_renderbuffer 对象。buffer__对象可以使用cudaGraphicsGLRegisterBuffer()来进行注册。在CUDA中,它表现的和一个设备指针一样, 因此可以通过cudaMemcpy()来进行读写。texture 和_renderbuffer 对象需要使用cudaGraphicsGLRegisterImage()来进行注册。在CUDA中,它表现的像CUDA 数组。核函数可以对绑定至纹理引用或者表面引用的“数组”进行读取,也可以通过表面函数对在注册时使用了cudaGraohicwRegistrerFlagsSurfaceLoadStore标志的资源进行写操作。这些数组也可以通过cudaMemcpy2D来进行读写操作。cudaGraphicsGLRegisterImage()支持所有的纹理格式(1, 2,4分量或者内置类型,归一化整数,非归一化整数)。
共享资源的OpenGL上下文必须是进行任何OpenGL互操作API调用的主机线程的最新上下文。需要注意的是,当一个OpenGL的纹理被设置成不可绑定时,它就不能被CUDA注册。
下示代码是利用一个核函数来动态的修改一个存储于顶点buffer的2D网格对象:
GLuint positionsVBO;
struct cudaGraphicsResource* positionsVBO_CUDA;
int main()
{
// Initialize OpenGL and GLUT for device 0
// and make the OpenGL context current
...
glutDisplayFunc(display);
// Explicitly set device 0
cudaSetDevice(0);
// Create buffer object and register it with CUDA
glGenBuffers(1, &positionsVBO);
glBindBuffer(GL_ARRAY_BUFFER, positionsVBO);
unsigned int size = width * height * 4 * sizeof(float);
glBufferData(GL_ARRAY_BUFFER, size, 0, GL_DYNAMIC_DRAW);
glBindBuffer(GL_ARRAY_BUFFER, 0);
cudaGraphicsGLRegisterBuffer(&positionsVBO_CUDA,
positionsVBO,
cudaGraphicsMapFlagsWriteDiscard);
// Launch rendering loop
glutMainLoop();
...
}
void display()
{
// Map buffer object for writing from CUDA
float4* positions;
cudaGraphicsMapResources(1, &positionsVBO_CUDA, 0);
size_t num_bytes;
cudaGraphicsResourceGetMappedPointer((void**)&positions,
&num_bytes,
positionsVBO_CUDA));
// Execute kernel
dim3 dimBlock(16, 16, 1);
dim3 dimGrid(width / dimBlock.x, height / dimBlock.y, 1);
createVertices<<<dimGrid, dimBlock>>>(positions, time,
width, height);
// Unmap buffer object
cudaGraphicsUnmapResources(1, &positionsVBO_CUDA, 0);
// Render from buffer object
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
glBindBuffer(GL_ARRAY_BUFFER, positionsVBO);
glVertexPointer(4, GL_FLOAT, 0, 0);
glEnableClientState(GL_VERTEX_ARRAY);
glDrawArrays(GL_POINTS, 0, width * height);
glDisableClientState(GL_VERTEX_ARRAY);
// Swap buffers
glutSwapBuffers();
glutPostRedisplay();
}
void deleteVBO()
{
cudaGraphicsUnregisterResource(positionsVBO_CUDA);
glDeleteBuffers(1, &positionsVBO);
}
__global__ void createVertices(float4* positions, float time,
unsigned int width, unsigned int height)
{
unsigned int x = blockIdx.x * blockDim.x + threadIdx.x;
unsigned int y = blockIdx.y * blockDim.y + threadIdx.y;
// Calculate uv coordinates
float u = x / (float)width;
float v = y / (float)height;
u = u * 2.0f - 1.0f;
v = v * 2.0f - 1.0f;
// calculate simple sine wave pattern
float freq = 4.0f;
float w = sinf(u * freq + time)
* cosf(v * freq + time) * 0.5f;
// Write positions
positions[y * width + x] = make_float4(u, w, v, 1.0f);
}
Direct3D交互
Direct3D 交互支持 Direct3D 9Ex, Direct3D 10 以及Direct3D 11。CUDA 上下文可以交互的Direct3D 设备必须有一些设置: Direct3D 9Ex 设备必须在创建时将DeivceType设置为D3DDEVTYPE_HAL, BehaviorFlags设置为D3DCREATE_HARDWARE_VERTESPROCESSING; Direct3D 10 和 Direct3D 11 的设备在创建时需将DeivceType设置为D3D_DRIVER_TYPE_HARDWARE。
Direct3D 可以映射至CUDA空间的资源包括: Direct3D buffer、textures, surface。这些资源可以通过cudaGraphicsD3D9RegisterResource()、cudaGraphicsD3D10RegisterResource()、cudaGraphicsD3D11RegisterResource()。
下示代码是利用一个核函数来动态的修改一个存储于顶点buffer的2D网格对象:
// Direct3D 9 Version
IDirect3D9* D3D;
IDirect3DDevice9* device;
struct CUSTOMVERTEX {
FLOAT x, y, z;
DWORD color;
};
IDirect3DVertexBuffer9* positionsVB;
struct cudaGraphicsResource* positionsVB_CUDA;
int main()
{
int dev;
// Initialize Direct3D
D3D = Direct3DCreate9Ex(D3D_SDK_VERSION);
// Get a CUDA-enabled adapter
unsigned int adapter = 0;
for (; adapter < g_pD3D->GetAdapterCount(); adapter++) {
D3DADAPTER_IDENTIFIER9 adapterId;
g_pD3D->GetAdapterIdentifier(adapter, 0, &adapterId);
if (cudaD3D9GetDevice(&dev, adapterId.DeviceName)
== cudaSuccess)
break;
}
// Create device
...
D3D->CreateDeviceEx(adapter, D3DDEVTYPE_HAL, hWnd,
D3DCREATE_HARDWARE_VERTEXPROCESSING,
¶ms, NULL, &device);
// Use the same device
cudaSetDevice(dev);
// Create vertex buffer and register it with CUDA
unsigned int size = width * height * sizeof(CUSTOMVERTEX);
device->CreateVertexBuffer(size, 0, D3DFVF_CUSTOMVERTEX,
D3DPOOL_DEFAULT, &positionsVB, 0);
cudaGraphicsD3D9RegisterResource(&positionsVB_CUDA,
positionsVB,
cudaGraphicsRegisterFlagsNone);
cudaGraphicsResourceSetMapFlags(positionsVB_CUDA,
cudaGraphicsMapFlagsWriteDiscard);
// Launch rendering loop
while (...) {
...
Render();
...
}
...
}
void Render()
{
// Map vertex buffer for writing from CUDA
float4* positions;
cudaGraphicsMapResources(1, &positionsVB_CUDA, 0);
size_t num_bytes;
cudaGraphicsResourceGetMappedPointer((void**)&positions,
&num_bytes,
positionsVB_CUDA));
// Execute kernel
dim3 dimBlock(16, 16, 1);
dim3 dimGrid(width / dimBlock.x, height / dimBlock.y, 1);
createVertices<<<dimGrid, dimBlock>>>(positions, time,
width, height);
// Unmap vertex buffer
cudaGraphicsUnmapResources(1, &positionsVB_CUDA, 0);
// Draw and present
...
}
void releaseVB()
{
cudaGraphicsUnregisterResource(positionsVB_CUDA);
positionsVB->Release();
}
__global__ void createVertices(float4* positions, float time,
unsigned int width, unsigned int height)
{
unsigned int x = blockIdx.x * blockDim.x + threadIdx.x;
unsigned int y = blockIdx.y * blockDim.y + threadIdx.y;
// Calculate uv coordinates
float u = x / (float)width;
float v = y / (float)height;
u = u * 2.0f - 1.0f;
v = v * 2.0f - 1.0f;
// Calculate simple sine wave pattern
float freq = 4.0f;
float w = sinf(u * freq + time)
* cosf(v * freq + time) * 0.5f;
// Write positions
positions[y * width + x] =
make_float4(u, w, v, __int_as_float(0xff00ff00));
}
SLI 交互
在一个多GPU的系统中,所有的可以使用CUDA的GPU都可以通过CUDA 驱动进行访问。但是当系统在SLI模式下,有一些特殊问题需要考虑。
第一:在一个GPU上进行内存的分配时会在其他的GPU上也会消耗内存, 会被消耗内存的GPU是通过Direct3D 或者 OpenGL设备进行SLI 配置过的。因此,有时候内存的分配会失败。
第二:应用程序需要创建多个CUDA 上下文,每个SLI配置中的GOU都需要有一个。尽管这并不是非常必须的需求,但是它能避免在设备间发生不必要的数据迁移。应用程序可以对于Direct3D使用cudaD3D[9|10|11]GetDevice()和OpenGL使用cudaGLGetDevices() 来识别正在执行渲染的CUDA设备的句柄。应用程序会使用这些给定的信息来选择合适的设备来映射Direct3D 或 OpenGL 资源至CUDA 设备空间。
版本与兼容性
在开发CUDA应用程序的时候,需要关注两个版本数字:计算力版本和CUDA 驱动API 版本。前者描述了计算设备的通用说明和特性;后者描述了驱动API 和运行时所支持的特性。
驱动API的版本CUDA_VERSION定义在驱动的头文件中。它允许开发者去对其进行核对。驱动API是向后兼容的,这意味着应用程序、插件、库在之前的驱动上进行编译后仍旧可以在最新的驱动下进行使用。但是驱动API并不会进行前向兼容。
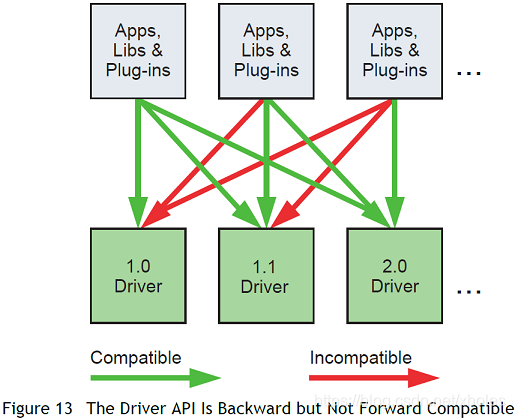
值得注意的是,一些混合匹配的版本是得到支持的:
- 因为在一个系统中只能安装一份CUDA 驱动,因此安装的驱动版本必须不低于系统中任何应用程序所需的最低驱动版本。
-应用程序所使用的所有的插件或者库必须使用相同版本的CUDA 运行时,除非它们静态的连接运行时,此时就会有多个版本的运行时同时存在同一个程序空间中。如果使用NVCC来链接应用程序, 默认会使用静态版本的CUDA 运行时,且所有的CUDA Toolkit 库都会静态的链接CUDA 运行时。 - 应用程序所使用的所有的插件或者库 所使用的其他库必须使用相同版本的CUDA 运行时, 除非进行静态链接。
计算模式
关于运行在Windows Server 2008及其之后的系统或linux下的Tesla 解决方案, 用户可以通过NVIDIA 的系统管理接口nvidia-smi设置系统的任意设备计算模式。 计算模式主要分为三种:
-_default_计算模式。主机端的多线程可以同时使用同一设备。
-Exclusive-process 计算模式。 只会创建一个CUDA 上下文,设备上的所有进程共享一个上下文。上下文可以是创建该上下文的进程中所需的任意多个线程的当前上下文。
-Prohibited 计算模式。不会在设备上创建CUDA context。
也就是说, 当设备0倍设置成_Prohibited_模式或者_exclusive_process_时,主机端线程在调用运行时API时不显式的调用cudaSetDevice()可能会关联到一个其他的设备上。cudaSetValidDevices()可以用来设定设备的优先级。

















 7209
7209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









