







激活函数
神经元建模
在生物界中的生物内部信息的传递基本都是通过神经元来进行的。神经细胞通过突触结构获取其他细胞传递过来的信息。神经细胞具有非常多的突触,因此可以同时获取多个信息。神经细胞接收到信息后进行处理,如果处理的结果满足一定的要求就能激活神经细胞经信息传递给其他的神经细胞。
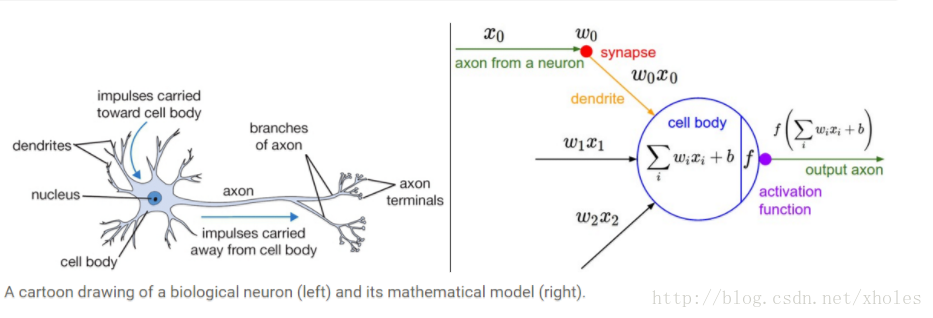
上图就是模仿生物神经细胞的信息传输过程,可以构建神经元模型。左边是神经细胞的结构示意图,右边是对其进行建立的模型。模型中用连接表示神经细胞之间的突触;用
X=[x1,x2,cdots,xn]
表示神经细胞获取周围细胞的信息;
∑iwixi+b
表示神经元对所接受信息的处理结果,
wi
为每条突触信息的权重,
b
为偏置量;
激活函数的重要性
如果不用激活函数,每一层的输出都是上一层的线性组合,从而导致整个神经网络的输出为神经网络输入的线性组合,无法逼近任意函数。
激活函数有以下特性:
1)非线性
2)可微性:当优化方法是基于梯度时,此性质是必须的
3)单调性:当激活函数是单调时,可保证单层网络是凸函数
4)输出值的范围:当激活函数输出值是 有限 的时候,基于梯度的优化方法会更加稳定,因为特征的表示受有限权值的影响更显著;当激活函数的输出是无限时,模型的训练会更加高效,不过在这种情况小,一般需要更小的Learning Rate.
常见的激活函数
sigmoid函数
最经典的莫过于sigmoid函数,它是一个非线性函数,在逻辑回归这个二分类器中就被使用过。它的特点是函数值在0到1之间,在0的时候函数值为0.5,且在0周围函数值变化剧烈,在两端变化非常缓慢。函数表达式如下:
函数曲线如下:
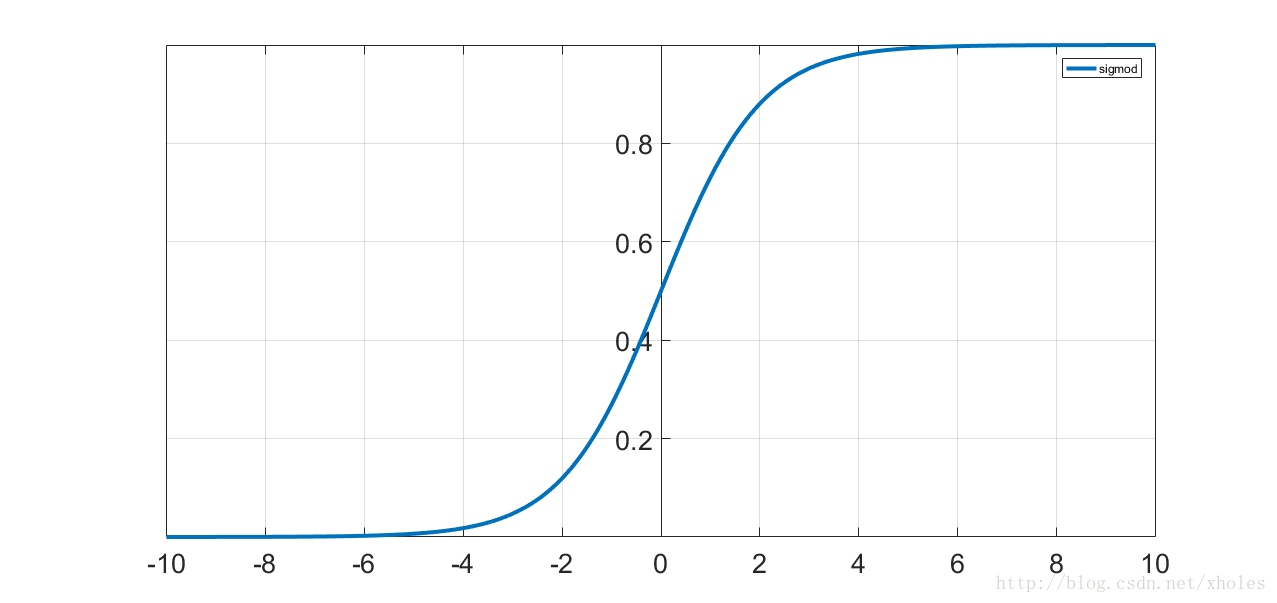
从数学上来看,非线性的Sigmoid函数对中央区的信号增益较大,对两侧区的信号增益小,在信号的特征空间映射上,有很好的效果,通过对加权的输入进行非线性组合产生非线性决策边界.从神经科学上来看,中央区酷似神经元的兴奋态,两侧区酷似神经元的抑制态,因而在神经网络学习方面,可以将重点特征推向中央区,将非重点特征推向两侧区.
它有两个主要缺点:
(1)Sigmoid函数饱和使梯度消失。sigmoid神经元有一个不好的特性,就是当神经元的激活在接近0或1处时会饱和:在这些区域,梯度几乎为0。回忆一下,在反向传播的时候,这个(局部)梯度将会与整个损失函数关于该门单元输出的梯度相乘。因此,如果局部梯度非常小,那么相乘的结果也会接近零,这会有效地“杀死”梯度,几乎就有没有信号通过神经元传到权重再到数据了。还有,为了防止饱和,必须对于权重矩阵初始化特别留意。比如,如果初始化权重过大,那么大多数神经元将会饱和,导致网络就几乎不学习了。
(2)Sigmoid函数的输出不是零中心的。这个性质并不是我们想要的,因为在神经网络后面层中的神经元得到的数据将不是零中心的。这一情况将影响梯度下降的运作,因为如果输入神经元的数据总是正数,那么w关于的梯度在反向传播的过程中,将会要么全部是正数,要么全部是负数(具体依整个表达式f而定)。这将会导致梯度下降权重更新时出现z字型的下降。然而,可以看到整个批量的数据的梯度被加起来后,对于权重的最终更新将会有不同的正负,这样就从一定程度上减轻了这个问题。因此,该问题相对于上面的神经元饱和问题来说只是个小麻烦,没有那么严重。
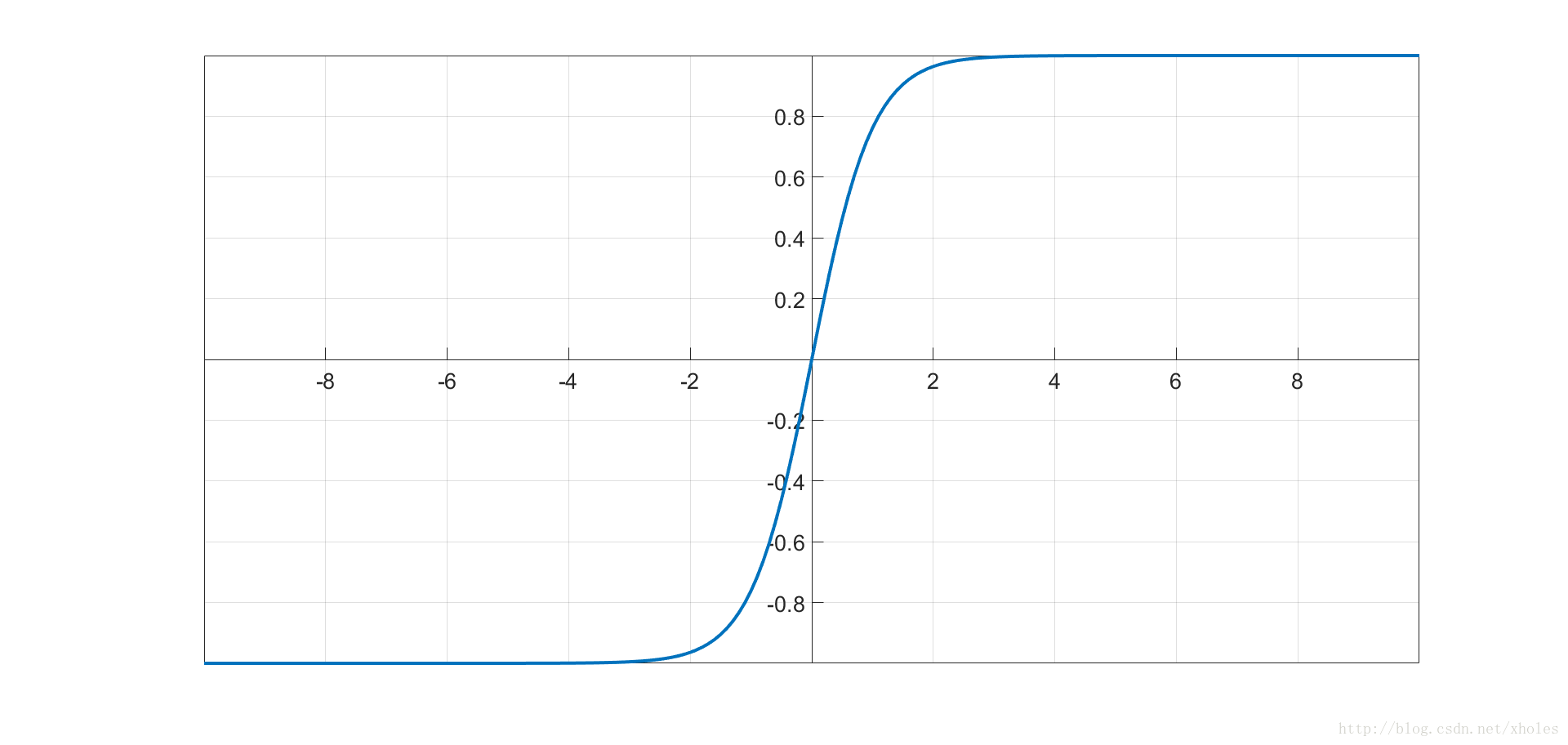
tanh函数
tanh函数和sigmoid函数类似,不过其函数输出取值范围为-1到1。和sigmoid神经元一样,它也存在饱和问题,但是和sigmoid神经元不同的是,它的输出是零中心的。因此,在实际操作中,tanh非线性函数比sigmoid非线性函数更受欢迎。tanh的输出和输入能够保持非线性单调上升和下降关系,符合BP网络的梯度求解,容错性好,有界,渐进于0、1,符合人脑神经饱和的规律,但比sigmoid函数延迟了饱和期。
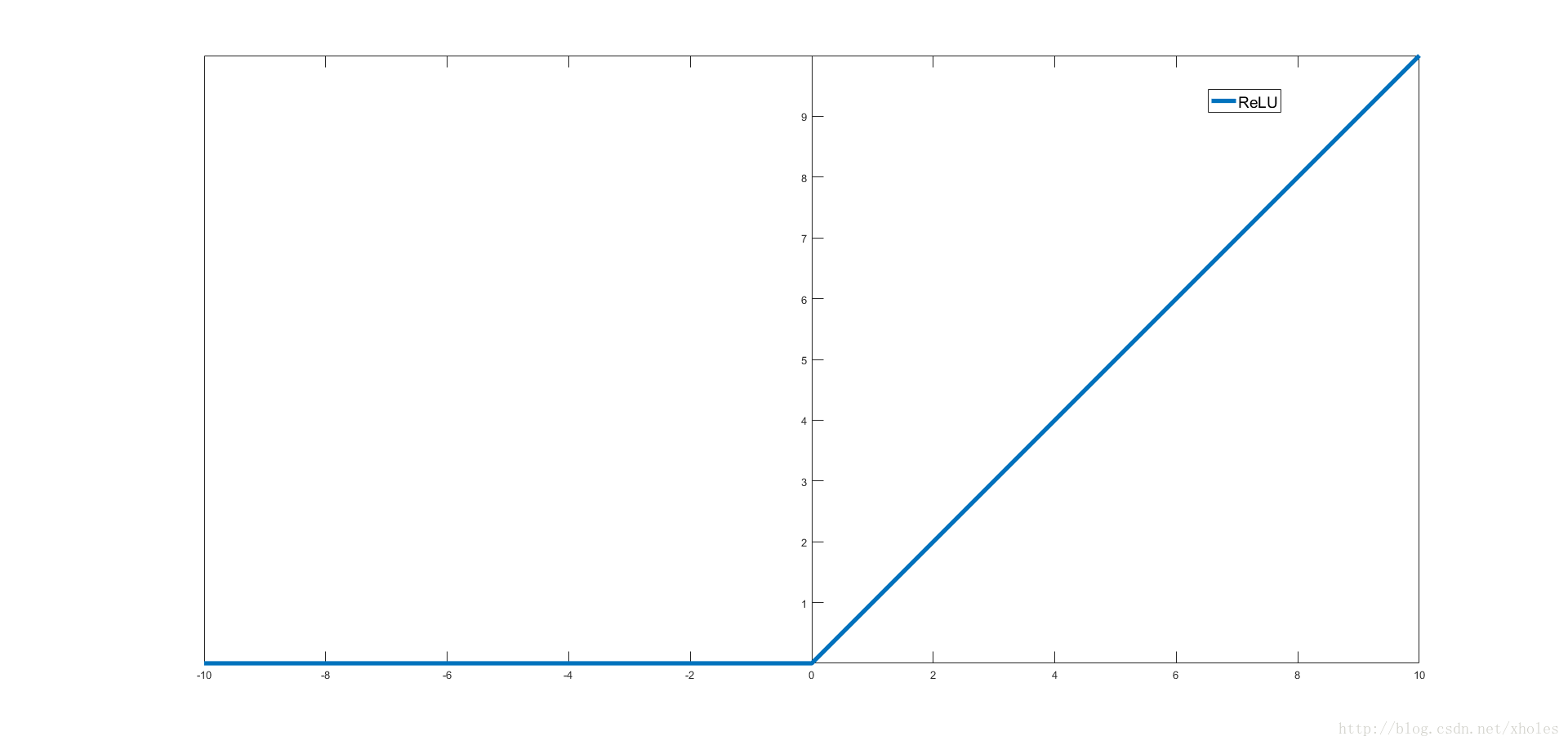
ReLU函数
Relu函数为现在深度学习使用比较广泛的激活函数,相比前面两个,其优点在于计算简单,导数简单,收敛快,单侧抑制 ,相对宽阔的兴奋边界 ,稀疏激活性;缺点在于在训练的时候,网络很脆弱,很容易出现很多神经元值为0,从而再也训练不动.一般将学习率设置为较小值来避免这种情况的发生.
ReLU的优缺点:
优点:相较于sigmoid和tanh函数,ReLU对于随机梯度下降的收敛有巨大的加速作用;sigmoid和tanh神经元含有指数运算等耗费计算资源的操作,而ReLU可以简单地通过对一个矩阵进行阈值计算得到。
缺点:在训练的时候,ReLU单元比较脆弱并且可能“死掉”。举例来说,当一个很大的梯度流过Re LU的神经元的时候,可能会导致梯度更新到一种特别的状态,在这种状态下神经元将无法被其他任何数据点再次激活。如果这种情况发生,那么从此所以流过这个神经元的梯度将都变成0。也就是说,这个ReLU单元在训练中将不可逆转的死亡,因为这导致了数据多样化的丢失。例如,如果学习率设置得太高,可能会发现网络中40%的神经元都会死掉(在整个训练集中这些神经元都不会被激活)。通过合理设置学习率,这种情况的发生概率会降低。
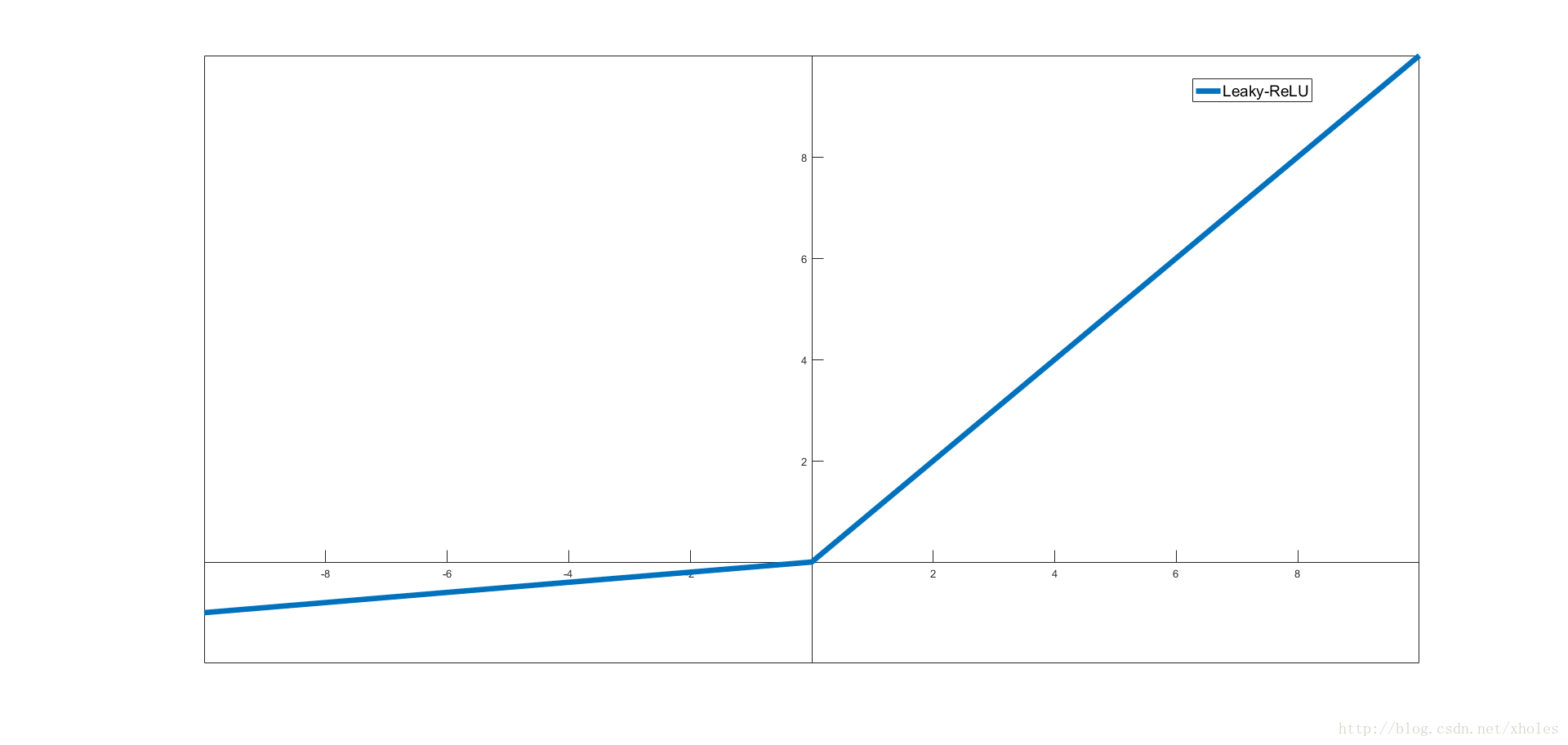
Leaky-ReLU
Leaky ReLU是为解决“Re LU死亡”问题的尝试。ReLU 中当 x<0 时,函数值为 0。而 Leaky ReLU 则是给出一个很小的负数梯度值,比如 0.01。激活函数表现很不错但效果并不稳定。
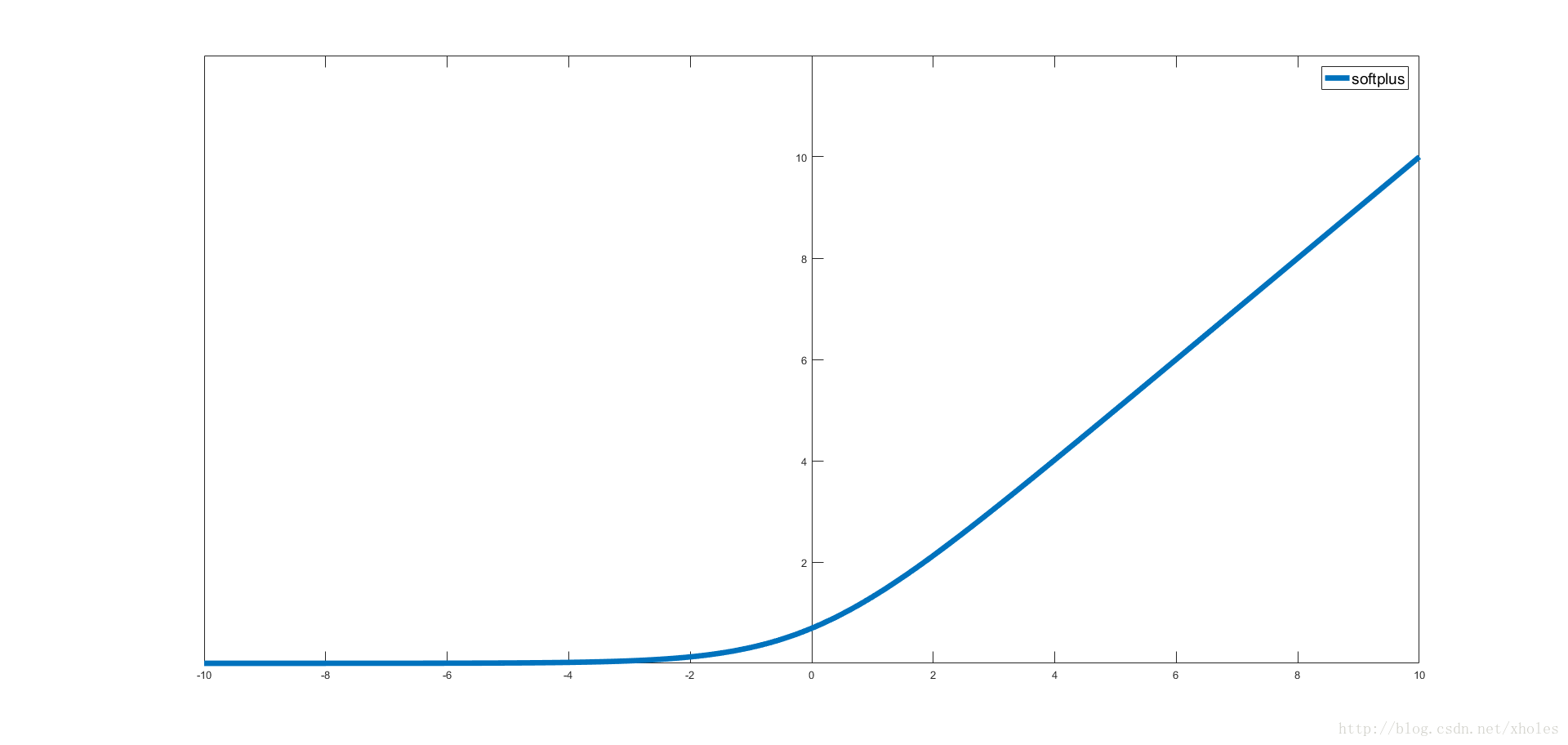
softplus函数
softplus是一个圆滑型的ReLU函数。
maxout函数
References:
[1]神经网络与深度学习之激活函数














 665
665











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









