







0. 论文信息
标题:Unlocking Generalization Power in LiDAR Point Cloud Registration
作者:Zhenxuan Zeng, Qiao Wu, Xiyu Zhang, Lin Yuanbo Wu, Pei An, Jiaqi Yang, Ji Wang, Peng Wang
单位:西北工业大学,斯旺西大学,华中科技大学
项目地址:https://github.com/peakpang/UGP
1. 摘要
在现实环境中,具有强大泛化能力(跨越不同距离和数据集)的LiDAR点云配准方法对于确保自动驾驶和其他基于LiDAR的应用的安全性至关重要。然而,现有方法在实现这种泛化水平方面存在不足。为了解决这些局限性,我们提出了UGP,一个旨在增强LiDAR点云配准泛化能力的剪枝框架。UGP的核心见解是消除交叉注意力机制以提高泛化能力,使网络能够专注于帧内特征提取。此外,我们引入了一个渐进式自注意力模块,以减少大规模场景中的歧义,并集成了鸟瞰图(BEV)特征以融入场景元素的语义信息。这些增强措施共同显著提升了网络的泛化性能。我们通过在多个室外场景中的各种泛化实验验证了我们的方法。在KITTI和nuScenes上的跨距离泛化实验中,UGP分别实现了94.5%和91.4%的最先进平均配准召回率。在从nuScenes到KITTI的跨数据集泛化中,UGP实现了 的最先进平均配准召回率。代码将在https://github.com/peakpang/UGP提供。
2. 当前learning-based方法存在哪些问题?
近年来,基于学习的点云配准方法逐渐受到关注。然而,这些方法大多专注于在相同距离或相同数据集条件下提升性能,仅有少数方法涉及跨数据集的泛化问题。据我们所知,现有方法尚未系统性地研究激光雷达(LiDAR)点云配准的泛化性能。
与均匀分布的室内RGB-D点云不同,激光雷达点云表现出不均匀分布,点密度随着与传感器距离的增加而显著降低。这带来了独特的挑战:
-
跨距离变化会改变点云对之间的重叠率,并导致重叠区域内的密度变化
-
跨数据集变化会导致数据特征(例如,64线激光雷达与32线激光雷达)和特征分布(例如,环境变化)的差异
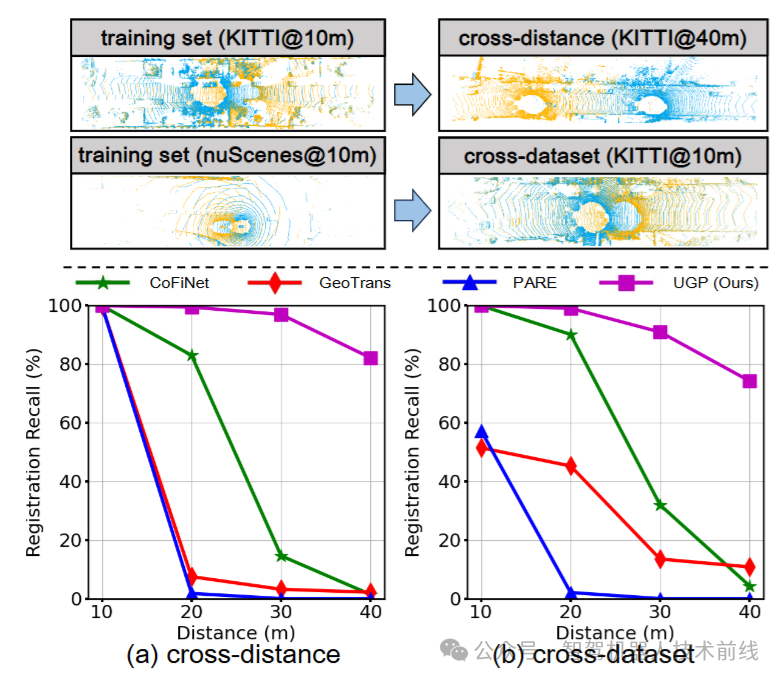
观察到,在跨距离和跨数据集条件下,最先进(SOTA)方法的性能显著下降。如下图所示,CoFiNet [39]、GeoTrans [28] 和 PARE [38] 是采用从粗到细的方法,利用Transformer在相同距离或相同数据集条件下提升配准性能。在这些方法中,交叉注意力被广泛用于建模两个点云之间的几何一致性。然而,该模块的有效性依赖于一个隐含假设:两个点云中相同结构的表示是一致的。在跨距离和跨数据集泛化挑战出现的动态场景中,由于激光雷达点云的密度分布不一致,这一隐含假设通常不成立。
3. 如何解决点云配准泛化性差的问题
本文提出了一种具有强大泛化能力的激光雷达点云配准框架(UGP)。该框架的核心思想是消除交叉注意力模块,以解锁泛化能力,并使网络专注于帧内特征提取。首先,为了减少帧间几何表示不一致的影响,移除了交叉注意力模块。这促使网络专注于帧内空间信息。其次,为了减少激光雷达场景中的特征模糊性并捕捉更精细的局部特征关联,本文引入了一个渐进式自注意力模块。该模块逐步增加超点的注意力范围,使其优先关注局部空间信息,并构建多尺度空间表示。最后,认识到场景元素级别(例如,道路、角落)语义信息在减少场景模糊性中的重要性,本文引入了鸟瞰图(BEV)特征,以提高粗匹配阶段的准确性。本文的贡献如下:
-
揭示了激光雷达场景中几何表示的不一致性导致交叉注意力模块限制了网络的泛化能力。消除交叉注意力模块是解锁这一能力的有效方法。
-
提出了一个渐进式自注意力模块和一个BEV特征提取模块,以更有效地关注精细的局部空间关联并捕捉语义丰富的信息,减少点云的模糊性并增强泛化能力。
-
在从到的跨距离泛化中,UGP在KITTI数据集上实现了的配准召回率(RR),在nuScenes数据集上实现了72.3%(+57.1%)的RR,优于BUFFER [2]。在从nuScenes到KITTI的跨数据集泛化中,我们的方法实现了的平均RR,超过了BUFFER [2]。
4. 核心算法详解
给定两组部分重叠的点云P ∈ R^{N×3} 和 Q ∈ R^{M×3},我们的目标是恢复它们之间的最优刚体变换,表示为T = {R ∈ SO(3), t ∈ R^3},其中R表示旋转,t表示平移。如下图所示,我们采用从粗到细的策略,并消除了交叉注意力模块。首先,点云被直接投影以获得BEV图像。然后,使用点编码器和BEV编码器提取点云和BEV图像的尺度特征。接下来,将点云和图像的块特征融合以获得超点特征。超点匹配模块消除了交叉注意力模块,仅利用渐进式自注意力来提取超点特征,从而获得超点对应关系。最后,我们遵循GeoTransformer [28],使用相同的点匹配模块来细化超点匹配,并使用LGR [28]方法恢复对齐变换(附录第7节)。
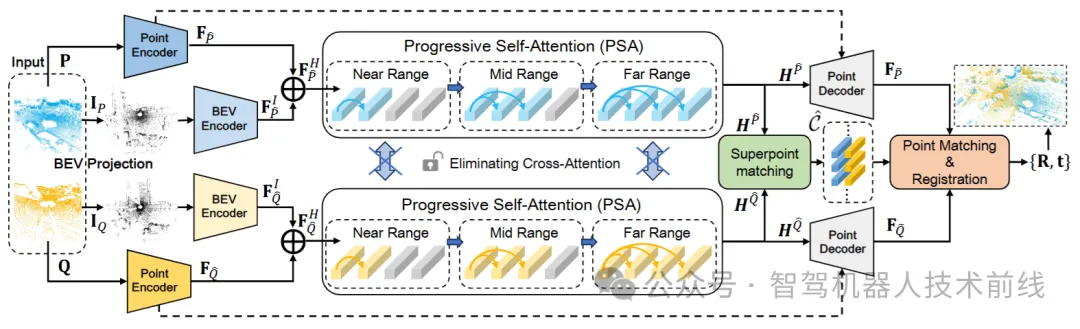
4.1. BEV投影
在LiDAR点云配准中,显著的全局边缘和纹理特征对于超点匹配非常重要。从二维角度来看,点云的BEV表示提供了环境的全局视图,并提供了关于场景元素的重要语义信息。这些显著特征减少了场景的模糊性,并提高了特征一致性。
给定一个点云,其中
表示每个点的坐标,我们将其投影到BEV图像
中,其中H和W分别表示BEV图像的高度和宽度。假设该鸟瞰图覆盖的地面区域为
和
,投影过程可以用以下公式表示:
其中是点
在BEV图像中的像素坐标。为了捕捉全局结构,我们用
的灰度值填充每个像素位置。
4.2. 超点特征提取与融合
我们的特征提取模块由点编码器和BEV编码器组成。点编码器采用多级KPConv结构[32],在每一层应用体素下采样以减少点的数量,最终提取超点特征。BEV编码器使用多级ResNet结构[15],在每一层应用2D最大池化来下采样图像并提取块级特征。最后,我们将这两个特征融合以获得更丰富的超点特征表达。
具体来说,给定输入点云和
,以及它们对应的BEV图像
和
,点编码器输出下采样的超点
和
,以及它们对应的特征
和
,其中
表示每个超点的特征维度。同时,BEV编码器生成补丁特征
和
,其中
和
表示下采样BEV图像的高度和宽度,
表示BEV图像中每个补丁的特征维度。随后,基于超点和BEV补丁之间的索引关系进行特征融合,其中特征被连接以结合3D几何信息和2D纹理信息。这分别生成了超点
和
的融合特征
和
。
4.3. 超点匹配模块
对于从粗到细的方法,超点匹配的准确性直接决定了最终的配准性能。
消除交叉注意力以专注于帧内特征学习。LiDAR数据的分布特性与室内RGB-D点云不同,导致跨距离和数据集的几何表示不一致,限制了网络的泛化能力。为了提高框架的泛化性能,基于观察采用了一种简单有效的方法:消除交叉注意力模块并保留自注意力,以专注于帧内特征提取,从而增强泛化能力。
接下来,我们描述了使用自注意力计算超点特征的过程,这同样适用于
。给定输入特征矩阵
,其中$d_t$表示每个输入特征的维度,输出特征矩阵
作为投影输入特征的加权和获得:
其中注意力权重通过对注意力分数
应用逐行softmax获得,而注意力分数
计算如下:
这里,指的是GeoTransformer[28]中提出的几何结构嵌入。术语
分别是查询、键、值和几何结构嵌入的投影矩阵。
渐进式自注意力模块。在实际场景中,局部上下文信息在点云特征提取中起着至关重要的作用。现有方法[6, 28, 38, 39, 41]直接将全局自注意力应用于输入的点云特征。尽管自注意力能够捕捉长距离的全局依赖关系,但这种方法在大规模场景中更容易受到噪声的影响,从而加剧了特征匹配的模糊性。为了减少LiDAR场景中的匹配模糊性,我们引入了一个渐进式自注意力模块,如下图所示。该模块基于每个点与全局上下文中其他点之间的距离,以渐进的方式动态调整注意力范围。在初始层,该模块通过聚焦于附近的超点(superpoints)来优化局部关联,有效减少了初始全局注意力可能带来的模糊性。在后续层,注意力范围逐渐扩大,使模型能够构建超点的多尺度空间表示。这种逐步方法增强了超点特征的鲁棒性。
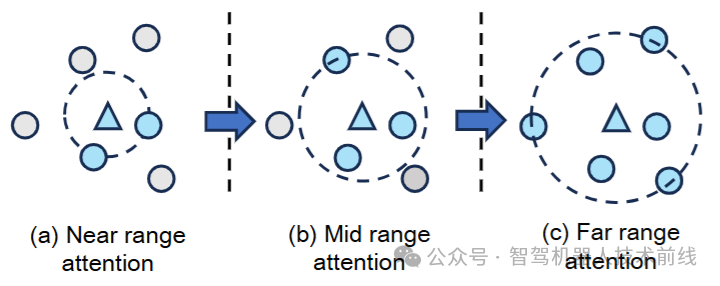
计算如下:
其中是一个特定于层的掩码,用于根据点之间的欧几里得距离过滤注意力分数。掩码
通过将超起点
与P中所有其他超点
之间的最大距离划分为S段来计算。对于给定层L=k,掩码定义为:
其中, k表示段索引,k=1对应最小距离范围,k=S对应最大距离范围。这使得模型能够逐步扩展感受野,早期关注更精细的局部空间,减少远距离噪声,然后学习多尺度空间特征表达。在执行S次注意力迭代后,获得混合超点特征
和
。
超点匹配。为了获得超点对应关系,我们遵循[28]。首先,将粗阶段获得的特征和
归一化到单位球面,得到特征
和
。接下来,我们计算一个高斯相关矩阵
,其中包含
和
。随后,我们对
进行双重归一化,得到
。最后,基于归一化结果,选择具有最高相关分数的前k个点对作为超点对应关系
5. 实验
5.1. 实验设置
数据集。本文在两个室外LiDAR数据集上评估了所提出的方法:KITTI(64线LiDAR)[12]和nuScenes(32线LiDAR)[4]。按照之前的工作[8, 16, 39],序列0-5用于训练,6-7用于验证,8-10用于测试,且扫描对之间的间隔至少为。为了评估跨距离和跨数据集的泛化能力,我们将测试集扩展到包括间隔为和的扫描对。目标是在KITTI@10m数据集上训练,并在KITTI@20m、KITTI@30m和KITTI@40m上测试泛化能力。对于nuScenes,我们遵循通用协议[4],将其分为训练、验证和测试子集。采用相同的方法,我们在nuScenes 上训练和验证,并在nuScenes@20m、nuScenes@30m和nuScenes@40m上测试。为了验证跨数据集的泛化能力,我们在nuScenes@10m上训练,并在KITTI@10m、KITTI@20m、KITTI@30m和KITTI@40m上测试。更多实验见附录第9节。
评估指标。我们遵循之前的工作,使用五个评估指标:Patch Inlier Ratio (PIR)、Inlier Ratio (IR)、Relative Rotation Error (RRE)、Relative Translation Error (RTE)、Registration Recall (RR)和mean Registration Recall (mRR)。所有实验中的RR基于标准和。指标的定义见附录第8节。
5.2. 泛化实验
跨距离泛化。我们将提出的UGP与其他最先进的方法在KITTI和nuScenes上进行比较。实验结果如表1所示。我们的方法在KITTI和nuScenes数据集上的RR均超过了上述所有方法,特别是优于BUFFER。与BUFFER相比,我们的方法将KITTI mRR提高了,并将KITTI@40m RR提高了。此外,在更为稀疏的nuScenes数据集上,我们的方法显著优于所有其他方法。我们的方法在nuScenes 上达到了SOTA,随后在nuScenes 上相比Geo-Trans提高了,相比BUFFER提高了14.7%,相比FCGF提高了15%。在上,我们的方法仍保持,并比BUFFER高出。在具有挑战性的上,我们的方法相比BUFFER提高了57.1%。
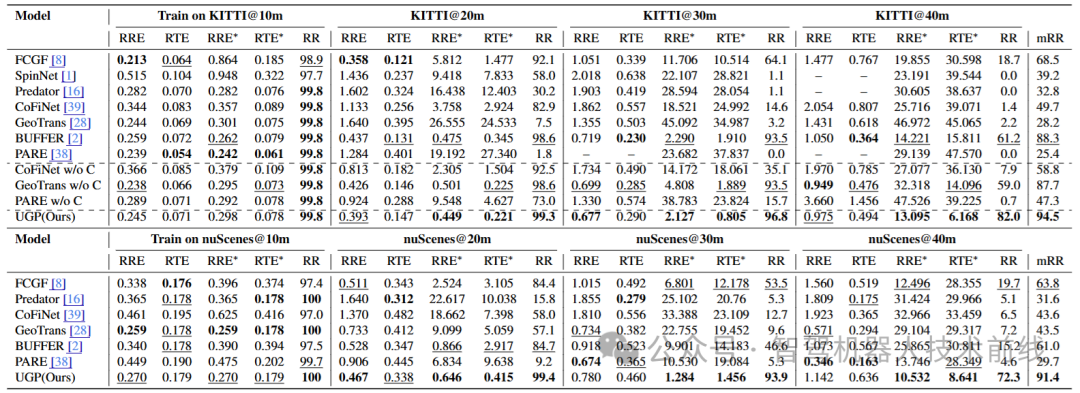
我们进一步分析了点云对距离变化对不同方法的影响。对于从粗到细的方法(CoFiNet、GeoTransformer和PARE),随着点云对距离的变化,性能显著下降。即使在泛化到相对较简单的数据子集时,GeoTransformer的RR下降到,而PARE的RR下降到1.8%,并且随着距离的增加,它们的性能继续下降。相比之下,点级或块级方法(FCGF和BUFFER)在网络设计中避免了帧间信息交换,保留了其泛化能力。当消除交叉注意力时(表1中的CoFiNet.w/o C、GeoTrans.w/o C和PARE.w/o C),泛化能力被解锁。这进一步验证了消除交叉注意力模块在增强LiDAR场景泛化能力中的关键作用。
为了评估我们方法的整体性能,我们还为所有测试点对包含了平均误差指标和。我们的方法在和距离泛化实验中,在所有测试点对的平均RRE和RTE方面达到了最高精度。我们在下图中展示了两个数据集上不同RRE和RTE阈值的跨距离泛化注册召回率。根据这一结果,虽然BUFFER在KITTI@30m中的某些阈值下表现优于我们的方法,但在更大的nuScenes数据集测试中,我们在所有阈值上都显示出非常大的改进。
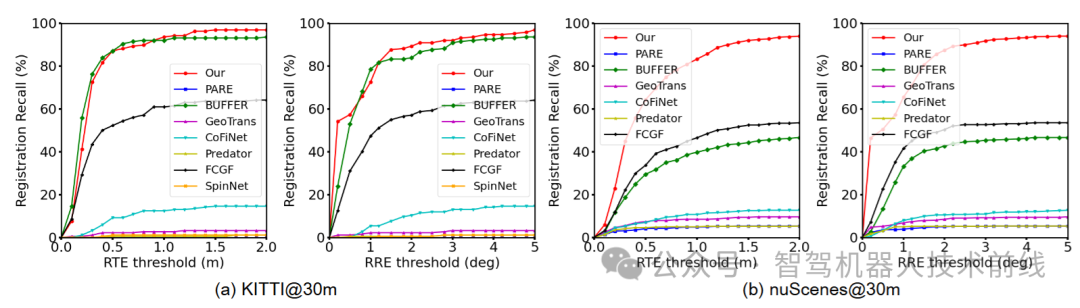
跨数据集泛化。为了评估所提出的UGP的跨数据集泛化能力,我们进行了以下实验:1)从nuScenes到KITTI@(10m,20m,30m和40m),2)从KITTI到nuScenes。如表2所示,所提出的UGP方法在KITTI@10m上实现了的注册召回率。同样在KITTI@20m、KITTI@30m和KITTI@40m上,与BUFFER相比,取得了最佳结果和(+20.9%)。可以发现,我们的方法在较长距离上具有显著优势。最后,我们比较了使用GCL预训练权重的GCL [19]方法在nuScenes中的表现。可以发现,尽管GCL在训练过程中利用了点云帧,但我们的方法在跨数据集泛化方面也有显著提升。如表3所示,尽管传感器光束存在差异(KITTI:64线,nuScenes:32线),我们的方法仍取得了最佳结果。与次优的BUFFER相比,我们的方法的RR提高了4.1%。

5.3. 消融实验
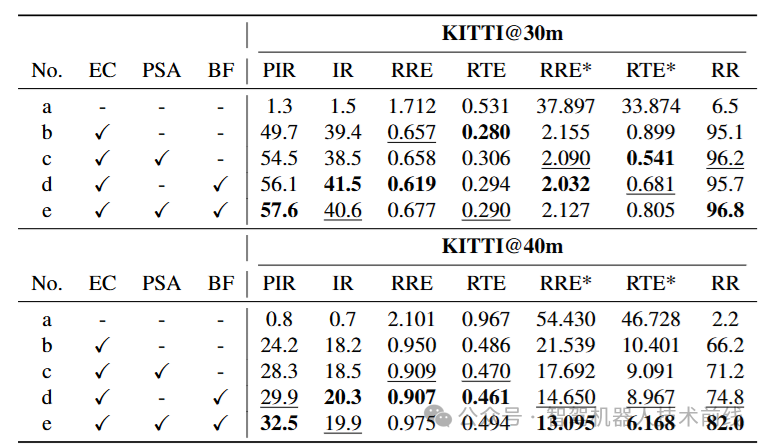
主干网络消融。首先,我们对方法的核心组件进行了消融研究,以证明每个部分的有效性,如表4所示。通过比较表4中的行,我们可以看到EC显著提高了网络的泛化能力。通过比较行,我们观察到PSA将PIR提高了,并在KITTI@30m上将RR提高了,在更远距离(40m)上提高了,与普通自注意力模块相比。我们进一步可视化了消融PSA的匹配结果,如图6所示。可以看出,图中长距离错误匹配的数量显著减少,证明我们的PSA可以有效解决普通自注意力中的特征模糊问题。通过比较行和,可以观察到BEV提供了场景元素的语义信息,减少了场景模糊性。因此,框架的PIR和RR都有所提高。表中的列代表我们提出的完整方法,在关键指标RR上取得了最佳性能。
估计器的消融实验。我们评估了不同估计器对配准结果的影响,如表5所示。使用RANSAC [11]时,我们方法的mRR为92.4%,使用MAC [42]时为94.9%,使用LGR [28]时为94.5%。

6. 总结
本文揭示了LiDAR场景中不一致的几何表示导致交叉注意力模块限制了网络的泛化能力。基于这一发现,我们提出了UGP,一种剪枝框架,旨在增强LiDAR点云配准的泛化能力。UGP消除了交叉注意力,引入了渐进式自注意力模块和BEV特征提取模块,使网络能够优先考虑局部空间关联并捕捉场景元素的语义信息。这减少了点云中的歧义,并提升了泛化性能。大量实验表明,我们的方法有效应对了不同数据分布带来的挑战,包括跨距离和跨数据集场景。

















 325
325

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









