







本着对技术的追求,开始涉猎大数据相关书籍,第一个看到的就是Hadoop,本文对自己学习Hadoop中所解,所悟进行总结。
第一本书籍是《Hadoop权威指南》第二版,可是这本书给人一种头重脚轻的赶脚,开篇就是很深入的技术,比较不易读,随即,选择了这本《Hadoop in Action》这本书在我看来也是基本摘抄权威指南的,这两本书目录结构基本相同,但是后者明显继承了In Action系列书籍的特色,以实践为特色,所以读起来较为轻松。
1.初识Hadoop
Hadoop的项目结构图:
| Pig | Chukwa | Hive | Hbase | ||
| MapReduce | HDFS | Zookeeper | |||
| Common | Avro | ||||
其核心项目为MapReduce和HDFS,HDFS在MapReduce任务处理过程中提供了对文件操作和存储等的支持,MapReduce在HDFS的基础上实现了任务的分发、跟踪、执行等工作,并收集结果,二者相互作用,完成了Hadoop分布式集群的主要任务。
2.分布式
通常我们所说的分布式系统是分布式软件系统,即支持分布式处理的软件系统。它包括分布式操作系统,分布式程序设计语言及编译系统,分布式文件系统和分布式数据库等。
Hadoop是分布式软件系统中的文件系统层的软件,它实现了分布式文件系统和部分分布式数据库系统的功能。
3.MapReduce核心原理概述:
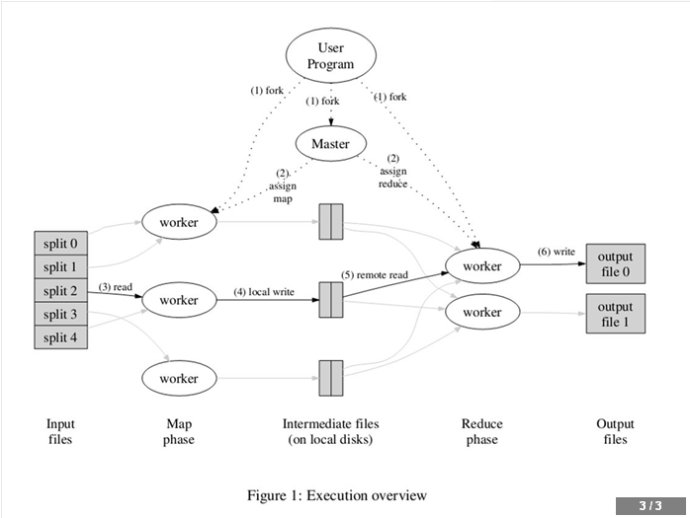
MapReduce分为两个阶段,Map Task,Reduce Task。需要区分出Map函数和Reduce函数。Map阶段做的事情就是将输入数据切成片(Split),如下图中的Split1,2,3,4.就像我们在使用榨汁机的时候,将大数据对象苹果先切成小丁通常是R份,这样可以保证某一段范围内的key一定是由一个Reduce任务来处理的。那么接下来的Reduce Task也很好理解它实际上就是在Map任务的中间结果执行完合并和分区后,以文件形式存储于本地磁盘上。中间结果的位置由TaskTracker汇报给JobTracker,也就是Master通知Reduce Task到哪一个区上去读取数据,然后再调用Reduce函数进行计算,将计算结果在保存到R个文件结果中,当然这些R个结果又可以作为另一个计算任务的输入,开始另一个并行计算任务,这也就是任务管道。
未完待续。。。















 114
114











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









