







Segmentation Guided Attention Network for Crowd Counting via Curriculum Learning

贡献
作者主要从网络结构的角度出发,之前SANet论文只简单用了inception module,这里作者充分利用inception的网络结构.
1)用inception-v3的结构更好学习scale的信息;
2)并且加入分割区分前后景,减少背景带来的误;
3)最后作者采用curriculum learning, 从易到难学习更加(crowd的区域loss权重更大)
方法
网络结构
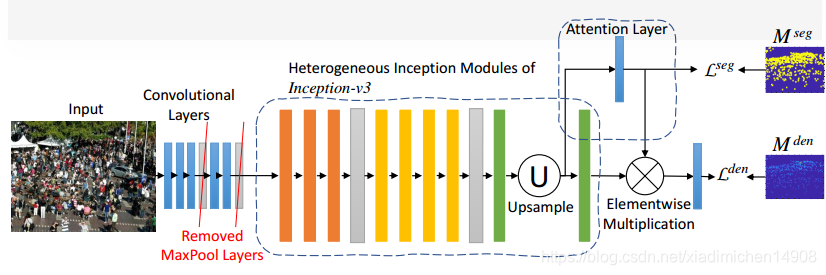
- 对inception-v3通过一个stride-2的卷积,2个maxpooling,2个 inception module对网络降采样,最后的feature map是原图输入的 1 2 5 \frac{1}{2^5 } 251, 作者通过去掉所有的max pool和全连接网络并在最后一个inception模块加入上采样,这样使得最后的feature map降采样 1 4 \frac{1}{4} 41
- 作者直接将分割的结果作为最终的attention map来让网络计算所有前景的人数, 从倒数第二个个inception的特征添加一个卷积,在跟一个sigmoid,这样attention map就和density map有同样大小的空间分辨率,直接用人头点为1,其他为0作为分割的ground truth
损失函数
对于分割部分采用的是BCELoss, counting部分采用的L2Loss
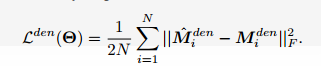
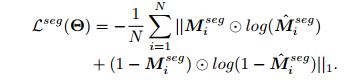
Loss是二者之间加权求和
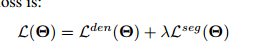
课程学习
课程学习是一种学习策略, 作者认为拥挤的区域密度预测更加难,但是稀疏的区域预测其实也是有问题的,但是因为作者这里加入segmentaion map去掉了backgroud的影响,所以就认为现在crowd的区域预测更难了. 这里课程学习的方式就是将密集区域和稀疏区域的loss设置不同的权重,这样网络关注就不同了.
具体来说权重矩阵
W
W
W, 阈值为T
W
=
T
m
a
x
{
M
d
e
n
−
T
,
0
}
+
T
W = \frac{T}{max\{M^{den}-T,0\} + T}
W=max{Mden−T,0}+TT
M
d
e
n
M ^{den}
Mden就是预测的density map, 如果密度小于T,那么权重为1;如果密度大于T,那么
W
=
T
M
d
e
n
W=\frac{T}{M^{den}}
W=MdenT, 小于1. 这样训练酒鬼更加关注简单的样本,也就是稀疏的区域
阈值T作为训练epoch e的函数,随着epoch数目增加,T也逐渐增加,这样网络密度高的就逐渐权重增加,越来容易学习
T
(
e
)
=
k
e
+
b
T(e) = k e +b
T(e)=ke+b
k,b可以根据先验知识density map的ground truth得到,b为初始epoch的threshold,为表示单个人头点区域最大的density map. k控制学习难度增加的速度,可以通过不用课程学习训练的学习曲线来决定.
最终的损失函数
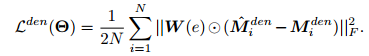
实现细节
Adam, 初始学习率1e-4每50个epoch变为原来0.5一共训练500个epoch,采用随机从原图crop 128* 128 图片,每一个batch包含8张图,每张图4个patch,一共32张图
Ablation study
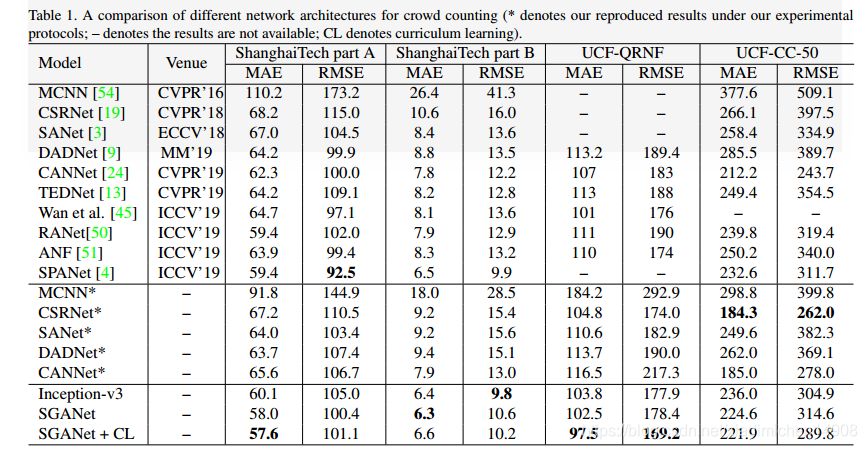
首先inception-v3这个backbone就已经很强SHA到60.1,SHB到6.4,backbone就已经很强,加上segmentation后SHA下降了2个点,其他的变化不大
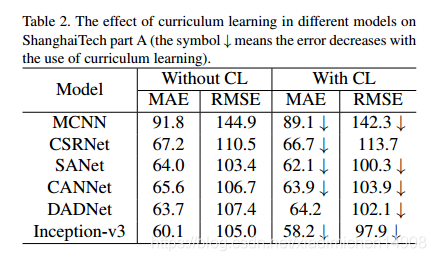
采用这种课程学习,在5个网络都得到验证,网络学习的更好
感想
counting任务中,除了自己提出的网络框架外,backbone大家基本都是选择vgg, resnet这篇文章选了inception-v3
- ResNet,为了保证密度图的大小不至于过小(不小于原图尺寸的1/8),我们修改了res.layer3中第一层stride的大小(将原本的2改为1),以此当做encoder。本着简单的原则,decoder由两层卷积构成。
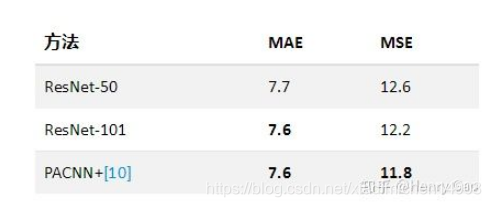
- 我们完全采用了VGG-16模型的前10个卷积层。其中,VGG采用了最为简单的decoder,而VGG+decoder则是简单设计了一个含有三个反卷积的模块
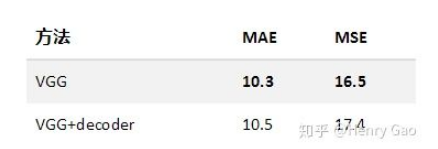
可以看出不同模型设计理念在人群计数任务的影响,确实inception这种更适应人群,可能是对scale 提取特征更加合适在这里插入图片描述














 5300
5300











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









