









缘起
在学习著名的Graphviz的工具中dot时,看到这篇语言描述,不长,就翻译了一下。翻译方法依然是带监督的机器学习,可惜的就是这个监督是不可反馈的。
正文
1. Introduction
The following is an abstract grammar defining the DOT language. Terminals are shown in bold font and nonterminals in italics. Literal characters are given in single quotes. Parentheses ( and ) indicate grouping when needed. Square brackets [ and ] enclose optional items. Vertical bars | separate alternatives.
下面是一个抽象的语法定义了DOT的语言。 终结符以粗体字体表示和非终结符用斜体表示,文字字符在单引号中给出,圆括号表示在需要的时候进行分组,方括号包含可选项目,竖线|分隔可选项。备注:下面的这种定义语言语法的表达式称为扩展巴科斯范式(Extended Backus–Naur Form,EBNF),关于EBNF的介绍可以参考编译原理相关的书籍(国外的龙书,虎书,鲸书,国内的看陈火旺或冯博琴的),当然,如果仅仅是了解的话,可以看看wikipedia中的介绍(Extended Backus–Naur Form)。
| graph | : | [ strict ] (graph | digraph) [ ID ] '{' stmt_list '}' |
| stmt_list | : | [ stmt [ ';' ] [ stmt_list ] ] |
| stmt | : | node_stmt |
|
| | | edge_stmt |
|
| | | attr_stmt |
|
| | | ID '=' ID |
|
| | | subgraph |
| attr_stmt | : | (graph | node | edge) attr_list |
| attr_list | : | '[' [ a_list ] ']' [ attr_list ] |
| a_list | : | ID [ '=' ID ] [ ',' ] [ a_list ] |
| edge_stmt | : | (node_id | subgraph) edgeRHS [ attr_list ] |
| edgeRHS | : | edgeop (node_id | subgraph) [ edgeRHS ] |
| node_stmt | : | node_id [ attr_list ] |
| node_id | : | ID [ port ] |
| port | : | ':' ID [ ':' compass_pt ] |
|
| | | ':' compass_pt |
| subgraph | : | [ subgraph [ ID ] ] '{' stmt_list '}' |
| compass_pt | : | (n | ne | e | se | s | sw | w | nw | c | _) |
The keywords node, edge, graph, digraph, subgraph, and strict are case-independent. Note also that the allowed compass point values are not keywords, so these strings can be used elsewhere as ordinary identifiers and, conversely, the parser will actually accept any identifier。
关键字node,edge,graph,digraph,subgraph以及strict说是case-independent。需要注意的是允许compass点值不是关键字,因此这些字符串可在其他地方用作普通的标识符,并且相反地,解析器实际上接受任何标识符。(这里不是很明白在说什么)
An ID is one of the following:
- l Any string of alphabetic ([a-zA-Z\200-\377]) characters, underscores ('_') or digits ([0-9]), not beginning with a digit;
- l ID标识符可为下列之一:字母表([\ 377 A-ZA-Z \ 200])中的任何字符串,下划线(“_”)或数字([0-9]),但不可以数字开头; 注:这里的定义和C/C++中关于标识符的定义类似,实际上dot语言就是使用的一种类似C的语法,注释,标识符都很相似,而且dot语言(GraphViz)就是由C和C++的发明者所在的AT&T开发的。
- l a numeral [-]?(.[0-9]+ | [0-9]+(.[0-9]*)? );
- l 数字[-]?(.[0-9]+ | [0-9]+(.[0-9]*)? );
- l any double-quoted string ("...") possibly containing escaped quotes (\");
- l 可能包含转义引号(\”)的任意双引号引用的字符串
- l HTML字符串(<...>)an HTML string (<...>).
(备注:上面的内容中包含正则表达式,?表示0或1个,+表示一个或多个,*表示0个或多个)
An ID is just a string; the lack of quote characters in the first two forms is just for simplicity. There is no semantic difference between abc_2 and "abc_2", or between 2.34 and "2.34". Obviously, to use a keyword as an ID, it must be quoted. Note that, in HTML strings, angle brackets must occur in matched pairs, and unescaped newlines are allowed. In addition, the content must be legal XML, so that the special XML escape sequences for ", &, <, and > may be necessary in order to embed these characters in attribute values or raw text.
ID只是一个字符串; 第一二种不使用引号形式仅仅是为了简单起见。还有就是,abc_2和“abc_2”或2.34和“2.34”之间没有语义差异 。很显然,使用关键字作为ID时,则必须使用引号。需要注意的是,在HTML中的字符串,尖括号必须成对出现,并且允许未转义的换行符。此外,其内容必须是合法的XML,此时特殊的XML转义序列“,&,<和>可能是必要的,以便在属性值或原始文本中嵌入这些字符。
Both quoted strings and HTML strings are scanned as a unit, so any embedded comments will be treated as part of the strings.
引号字符串和HTML字符串都被视为一个单元,所以任何嵌入的注释将被当作字符串的一部分。
An edgeop is -> in directed graphs and -- in undirected graphs.
edgop为->时表示有向图,--表示无向图。
The language supports C++-style comments: /* */ and //. In addition, a line beginning with a '#' character is considered a line output from a C preprocessor (e.g., # 34 to indicate line 34 ) and discarded.
dot语言支持C++风格的注释:/**/和//。此外,以'#'字符开头的行被看作C预处理器的输出(例如,#34表示第34行),dot将忽视它。
Semicolons aid readability but are not required except in the rare case that a named subgraph with no body immediately preceeds an anonymous subgraph, since the precedence rules cause this sequence to be parsed as a subgraph with a heading and a body. Also, any amount of whitespace may be inserted between terminals.
分号可以提高可读性,但不是必需的,除非在极少数情况下,一个没有”身体“的命名子图立刻被处理为匿名子图,因为优先级规则导致该序列被解析为一个带有标题和身体的子图。此外,在终结符之间可以插入任意数量的空白符。
As another aid for readability, dot allows single logical lines to span multiple physical lines using the standard C convention of a backslash immediately preceding a newline character. In addition, double-quoted strings can be concatenated using a '+' operator. As HTML strings can contain newline characters, they do not support the concatenation operator.
另一个增强可读性的是dot允许单个逻辑行使用标准C中\加换行来跨越多个物理行。此外,双引号字符串可以使用“+”操作符来串连。由于HTML字符串可以包含换行符,所以HTML不支持连接运算符。
2. 子图和群集 Subgraphs and Clusters
Subgraphs play three roles in Graphviz. First, a subgraph can be used to represent graph structure, indicating that certain nodes and edges should be grouped together. This is the usual role for subgraphs and typically specifies semantic information about the graph components.
子图在Graphviz中发挥的三个作用。首先,将子图可用于表示某些节点和边应该被组合在一起的图形结构。这是子图通常被指定关于图形元件的语义信息。
In the second role, a subgraph can provide a context for setting attributes. For example, a subgraph could specify that blue is the default color for all nodes defined in it. In the context of graph drawing, a more interesting example is:
在第二个角色,子图可以提供设置属性的上下文。例如,子图可以对其中定义的所有节点将蓝色用作默认颜色。在图形绘制的上下文中,一个更有趣的例子是:
subgraph {
rank = same; A; B; C;
}
This (anonymous) subgraph specifies that the nodes A, B and C should all be placed on the same rank if drawn using dot.
这(匿名)子图指定dot绘制的节点A,B和C都应该放在在同一等级。
The third role for subgraphs directly involves how the graph will be laid out by certain layout engines. If the name of the subgraph begins with cluster, Graphviz notes the subgraph as a special cluster subgraph. If supported, the layout engine will do the layout so that the nodes belonging to the cluster are drawn together, with the entire drawing of the cluster contained within a bounding rectangle. Note that, for good and bad, cluster subgraphs are not part of the DOT language, but solely a syntactic convention adhered to by certain of the layout engines.
子图的第三个角色直接涉及图形将如何被某些布局引擎布局。如果子图命令以cluster开头,Graphviz将子图作为一种特殊的集群子图(cluster subgraph)。如果布局引擎支持集群子图,引擎在执行的布局时,将属于该集群中的节点绘制在一起并将其包含在一个矩形边框中。注意集群子图不是DOT语言的一部分,仅仅是该语法约定被某些布局引擎的坚持。
3. 词法和语义注释 Lexical and Semantic Notes
If a default attribute is defined using a node, edge, or graph statement, or by an attribute assignment not attached to a node or edge, any object of the appropriate type defined afterwards will inherit this attribute value. This holds until the default attribute is set to a new value, from which point the new value is used. Objects defined before a default attribute is set will have an empty string value attached to the attribute once the default attribute definition is made.
如果在节点,边,图形语句或没有附加到任何到节点或边上属性赋值语句中定义了默认属性,此后,任何适当的类型的对象都将继承这个属性值。在被设置为一个新的值前,默认属性将一直保持。对象在默认属性被设置前定义时,对象的该属性为空的字符串值,在默认属性设置后,被覆盖为新值
Note, in particular, that a subgraph receives the attribute settings of its parent graph at the time of its definition. This can be useful; for example, one can assign a font to the root graph and all subgraphs will also use the font. For some attributes, however, this property is undesirable. If one attaches a label to the root graph, it is probably not the desired effect to have the label used by all subgraphs. Rather than listing the graph attribute at the top of the graph, and the resetting the attribute as needed in the subgraphs, one can simple defer the attribute definition if the graph until the appropriate subgraphs have been defined.
请注意,特别是子图在定义时接收父图的属性设置。这很有用的; 例如,在根图中指定字体,所有子图也将使用该字体。然而,对于某些属性,这是不可取的。如果一个标签附加到根图中,没必要所有子图都使用这个标签。与其在图的顶部列出的图表属性,不如根据需要在子图中设置属性。简单的延迟属性定义,直到适当的子图中定义。
If an edge belongs to a cluster, its endpoints belong to that cluster. Thus, where you put an edge can effect a layout, as clusters are sometimes laid out recursively.
如果边属于群集,其端点也属于该集群。因此,由于集群有时会递归布局,将边缘放到其中可以影响布局。
There are certain restrictions on subgraphs and clusters. First, at present, the names of a graph and it subgraphs share the same namespace. Thus, each subgraph must have a unique name. Second, although nodes can belong to any number of subgraphs, it is assumed clusters form a strict hierarchy when viewed as subsets of nodes and edges.
在子图和集群中存在一些限制。 首先,目前,图的名称和它的子图共享同一命名空间。因此,每个子图必须有一个唯一的名称。第二,虽然节点可以属于任意数量的子图,当集群被看作节点和边的子集,假设集群形成严格的层次结构。
4. 字符编码 Character encodings
The DOT language assumes at least the ascii character set. Quoted strings, both ordinary and HTML-like, may contain non-ascii characters. In most cases, these strings are uninterpreted: they simply serve as unique identifiers or values passed through untouched. Labels, however, are meant to be displayed, which requires that the software be able to compute the size of the text and determine the appropriate glyphs. For this, it needs to know what character encoding is used.
DOT的语言假定至少是ASCII字符集。带引号的字符串(包括普通和类似HTML的字符串)可能包含非ASCII字符。在大多数情况下,这些字符串是不解释:他们只是充当唯一标识符或传递中不变的值。但是,标签必须要显示,这就要求该软件能够计算的文本的大小,并确定适当的字形。为此,它需要知道使用的字符编码。
By default, DOT assumes the UTF-8 character encoding. It also accepts the Latin1 (ISO-8859-1) character set, assuming the input graph uses the charset attribute to specify this. For graphs using other character sets, there are usually programs, such as iconv, which will translate from one character set to another.
默认情况下,dot假设使用UTF-8字符编码。在输入图中使用的字符集属性指定时,dot也接受了拉丁文(ISO-8859-1)字符集。使用其他字符集的图,存在一些如iconv的软件,可以将转换字符集。
Another way to avoid non-ascii characters in labels is to use HTML entities for special characters. During label evaluation, these entities are translated into the underlying character. This table shows the supported entities, with their Unicode value, a typical glyph, and the HTML entity name. Thus, to include a lower-case Greek beta into a string, one can use the ascii sequence β. In general, one should only use entities that are allowed in the output character set, and for which there is a glyph in the font.
另一种方式避免在标签中使用非ASCII字符是使用HTML实体的特殊字符。在标签的计算中,这些实体被翻译成、底层字符。 下表显示了支持的实体,表中展示了Unicode值,典型的字形和HTML实体名称。因此,为包括小写希腊的β成一个字符串,可以使用ASCII字符序列&beta。一般情况下,应该只使用被允许在输出字符集中以及在在字体的字形中的。
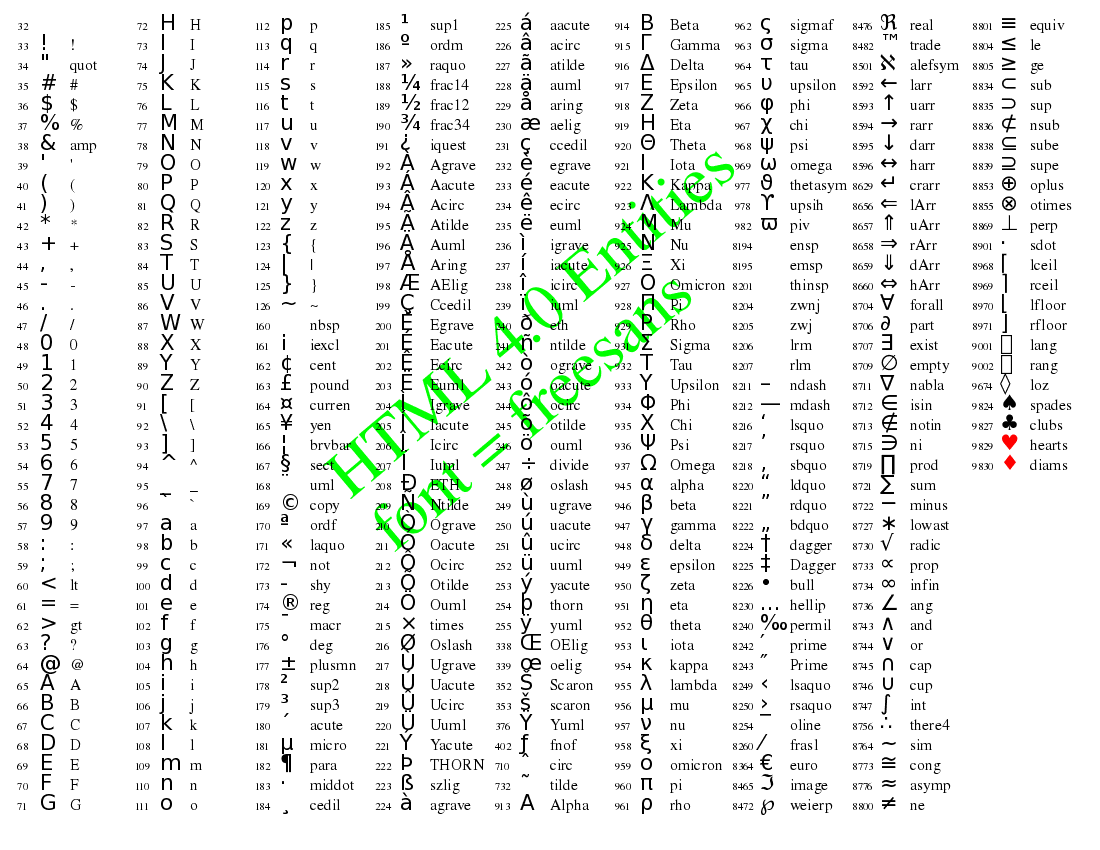
In quoted strings in DOT, the only escaped character is double-quote ("). That is, in quoted strings, the dyad \" is converted to "; all other characters are left unchanged. In particular, \\ remains \\. Layout engines may apply additional escape sequences.
在dot中带引号的字符串,唯一的转义字符是双引号(“),也就是说,在带引号的字符串,\“转换为”;所有其它字符都保持不变。特别是,\\依然是\\。布局引擎可能会应用额外转义序列。
后记
Dot语言来自http://hughesbennett.co.uk/Graphviz的引用文档,除了dot语言外,还有一系列的文档,例如结点和边的属性,结点的形状,颜色的名字,此外hughesbennet网站本身很有趣,国外作者还真是热心加性情。后来发现,hughesbennet上的dot语言及其相关属性的文档来自GraphViz官方,但是,官方的文档的排版不如hughesbennet中的简洁大方。
Graphviz的中文处理问题:
1.保存为UTF8格式
2.设置中文字体,一些中文字体的对应的名字如下:
黑体:SimHei 宋体:SimSun 新宋体:NSimSun 仿宋:FangSong 楷体:KaiTi
仿宋_GB2312:FangSong_GB2312 楷体_GB2312:KaiTi_GB2312
此外,Ubuntu中系统安装了那些字体可以通过命令fc-list查看。
参考文献:
维基百科Graphviz:http://en.wikipedia.org/wiki/Graphviz
Graphviz项目的主页:http://graphviz.org/
官方文档地址: http://www.graphviz.org/Documentation.php
Graphviz:http://hughesbennett.co.uk/Graphviz
使用 Graphviz 生成自动化系统图:http://www.ibm.com/developerworks/cn/aix/library/au-aix-graphviz/















 378
378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









