







搜索引擎
整体系统介绍
搜索引擎大致可以分为四个部分:搜集、分析、索引、查询。
- 搜集,就是我们常说的利用爬虫爬取网页。
- 分析,主要负责网页内容抽取、分词,构建临时索引,计算 PageRank 值这几部分工作。
- 索引,主要负责通过分析阶段得到的临时索引,构建倒排索引。
- 查询,主要负责响应用户的请求,根据倒排索引获取相关网页,计算网页排名,返回查询结果给用户。
搜集
- 待爬取网页链接文件:links.bin
- 网页判重文件:bloom_filter.bin
- 原始网页存储文件:doc_raw.bin
- 网页链接及其编号的对应文件:doc_id.bin
爬虫在爬取网页的过程中,涉及的四个重要的文件,我就介绍完了。其中,links.bin 和 bloom_filter.bin 这两个文件是爬虫自身所用的。另外的两个(doc_raw.bin、doc_id.bin)是作为搜集阶段的成果,供后面的分析、索引、查询用的。
分析
- 抽取网页文本信息
- 分词并创建临时索引
经过分析阶段,我们得到了两个重要的文件。它们分别是临时索引文件(tmp_index.bin)和单词编号文件(term_id.bin)。
索引
索引阶段主要负责将分析阶段产生的临时索引,构建成倒排索引。倒排索引( Inverted index)中记录了每个单词以及包含它的网页列表。
解决这个问题的方法有很多。考虑到临时索引文件很大,无法一次性加载到内存中,搜索引擎一般会选择使用***多路归并排序***的方法来实现。
经过索引阶段的处理,我们得到了两个有价值的文件,它们分别是倒排索引文件(index.bin)和记录单词编号在索引文件中的偏移位置的文件(term_offset.bin)。
查询
前面三个阶段的处理,只是为了最后的查询做铺垫。因此,现在我们就要利用之前产生的几个文件,来实现最终的用户搜索功能。
- doc_id.bin:记录网页链接和编号之间的对应关系。
- term_id.bin:记录单词和编号之间的对应关系。
- index.bin:倒排索引文件,记录每个单词编号以及对应包含它的网页编号列表。
- term_offsert.bin:记录每个单词编号在倒排索引文件中的偏移位置。
这四个文件中,除了倒排索引文件(index.bin)比较大之外,其他的都比较小。为了方便快速查找数据,我们将其他三个文件都加载到内存中,并且组织成散列表这种数据结构。
- 当用户在搜索框中,输入某个查询文本的时候,我们先对用户输入的文本进行分词处理。假设分分词之后,我们得到 k 个单词。
- 我们拿这 k 个单词,去 term_id.bin 对应的散列表中,查找对应的单词编号。经过这个查询之后,我们得到了这 k 个单词对应的单词编号。
- 我们拿这 k 个单词编号,去 term_offset.bin 对应的散列表中,查找每个单词编号在倒排索引文件中的偏移位置。经过这个查询之后,我们得到了 k 个偏移位置。
- 我们拿这 k 个偏移位置,去倒排索引(index.bin)中,查找 k 个单词对应的包含它的网页编号列表。经过这一步查询之后,我们得到了 k 个网页编号列表。
- 我们针对这 k 个网页编号列表,统计每个网页编号出现的次数。具体到实现层面,我们可以借助散列表来进行统计。统计得到的结果,我们按照出现次数的多少,从小到大排序。出现次数越多,说明包含越多的用户查询单词(用户输入的搜索文本,经过分词之后的单词)。
- 经过这一系列查询,我们就得到了一组排好序的网页编号。我们拿着网页编号,去 doc_id.bin 文件中查找对应的网页链接,分页显示给用户就可以了。
搜索引擎背后的经典数据结构和算法
数据结构和算法有:图、散列表、Trie 树、布隆过滤器、单模式字符串匹配算法、AC 自动机、广度优先遍历、归并排序等。
搜索引擎的设计框架
之前在讲解向量空间模型的时候,我们介绍了信息检索的基础知识,而我们平时经常使用的搜索引擎,就是一种典型的信息检索系统。在讲解如何结合倒排索引和向量空间模型之前,我们先来看,常见的文本搜索引擎都由哪些模块组成。
文本搜索系统的框架通常包括 2 个重要模块:离线的预处理和在线的查询。离线预处理也就是我们通常所说的“索引”阶段,包括数据获取、文本预处理、词典和倒排索引的构建、相关性模型的数据统计等。数据的获取和相关性模型的数据统计这两步,根据不同的应用场景,必要性和处理方式有所不同。可是,文本预处理和倒排索引构建这两个步骤,无论在何种应用场景之中都是必不可少的,所以它们是离线阶段的核心。之前我们讲过,常规的文本预处理是指针对文本进行分词、移除停用词、取词干、归一化、扩充同义词和近义词等操作。
在文本的离线处理完毕后,我们来看在线的文本查询。查询一般都会使用和离线模块一样的预处理,词典也是沿用离线处理的结果。当然,也可能会出现离线处理中未曾出现过的新词,我们一般会忽略或给予非常小的权重。在此基础上,系统根据用户输入的查询条件,在倒排索引中快速检出文档,并进行相关性的计算。
不同的相关性模型,有不同的计算方式。最简单的布尔模型只需要计算若干匹配条件的交集,向量空间模型 VSM,则需要计算查询向量和待查文档向量的余弦夹角,而语言模型需要计算匹配条件的贝叶斯概率等等。
综合上述的介绍,我使用下面这张图来展示搜索引擎的框架设计。
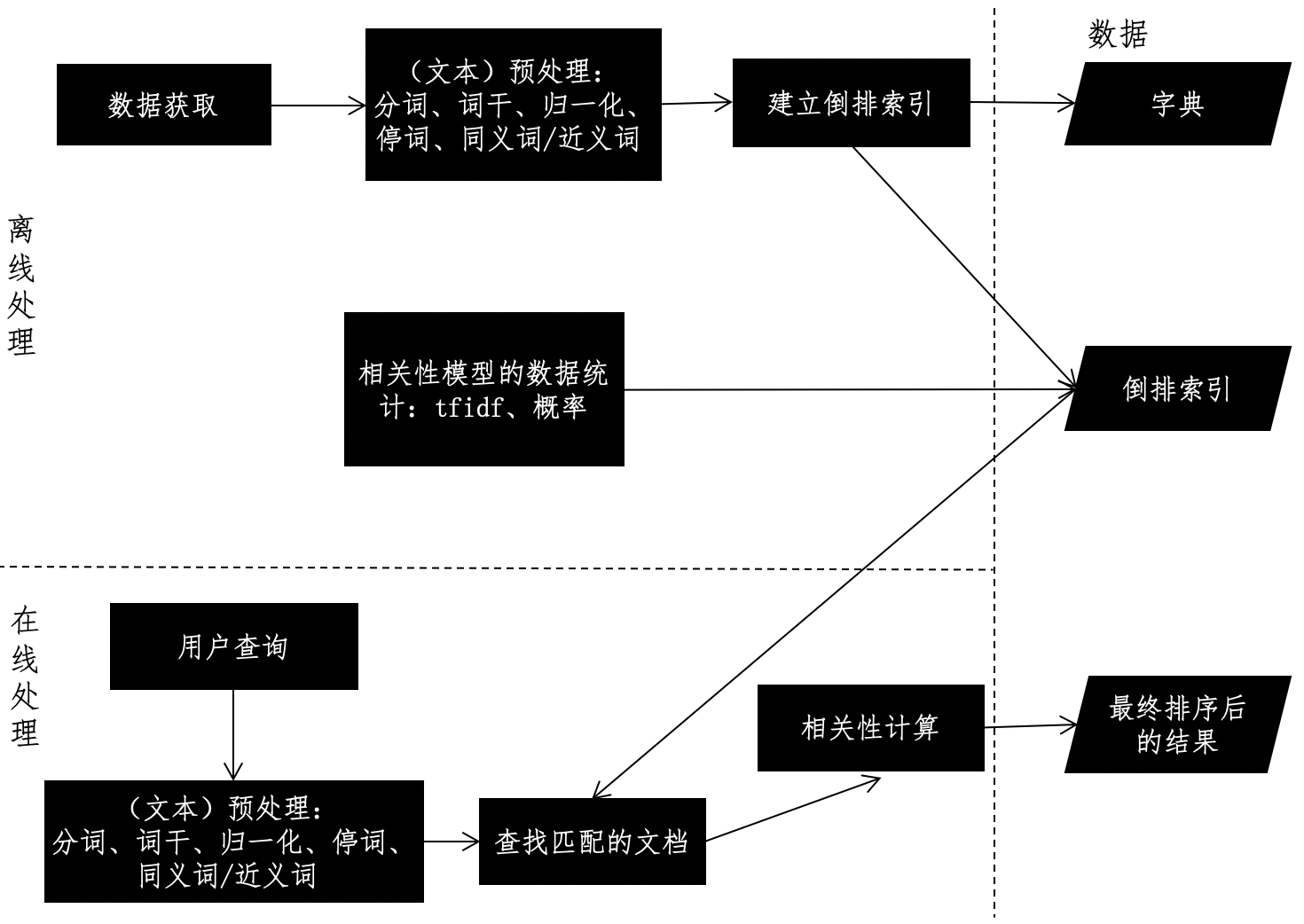
倒排索引的设计
我们之前已经把倒排索引的概念讲清楚了。不过到具体设计的时候,除了从关键词到文档这种“倒排”的关系,还有其它两个要点值得考虑:
- 第一个是倒排索引里具体存储什么内容,
- 第二个就是多个关键词的查询结果如何取交集。
首先我们来聊聊倒排索引里具体存放的内容。
从倒排索引的概念,我们很容易就想到使用哈希表、尤其是基于链式地址法的哈希表来实现倒排索引。哈希的键(key)就是文档词典的某一个词条,值(value)就是一个链表,链表是出现这个词条的所有文档之集合,而链表的每一个结点,就表示出现过这个词条的某一篇文档。这种最简单的设计能够帮助我们判断哪些文档出现过给定的词条,因此它可以用于布尔模型。但是,如果我们要实现向量空间模型,或者是基于概率的检索模型,就需要很多额外的信息,比如词频(tf)、词频 - 逆文档频率(tf-idf)、词条出现的条件概率等等。
另外,有些搜索引擎需要返回匹配到的信息摘要(nippet),因此还需要记住词条出现的位置。这个时候,最简单的倒排索引就无法满足我们的需求了。我们要在倒排索引中加入更多的信息。每个文档列表中,存储的不仅仅是文档的 ID,还有其他额外的信息。我使用下面这张图展示了一个示例,帮助你理解这种新的设计。
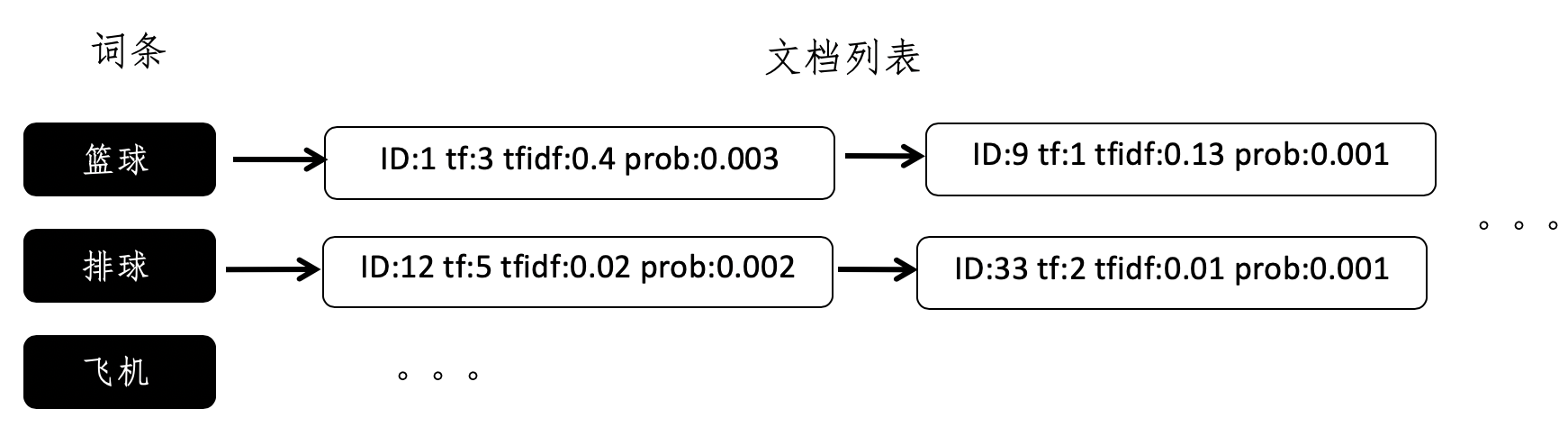
其中,ID 字段表示文档的 ID,tf 字段表示词频,tfidf 字段表示词频 - 逆文档频率,而 prob 表示这个词条在这篇文档中出现的条件概率。
好了,下面我们来看,如何确定出现所有多个关键词的文档。
由于倒排索引本身的特性,我们可以很快知道某一个词条对应的文档,也就是说查找出现某一个词条的所有文档是很容易的。可是,如果用户的查询包含多个关键词,那么该如何利用倒排索引,查找出现多个词条的所有文档呢?
还记得我讲解分治法时,所提到的归并排序吗?在这里,我们可以借鉴其中的合并步骤。假设有两个词条 a 和 b,a 对应的文档列表是 A,b 对应的文档列表是 B,而 A 和 B 这两个列表中的每一个元素都包含了文档的 ID。
首先,我们根据文档的 ID,分别对这两个列表进行从小到大的排序,然后依次比较两个列表的文档 ID,如果当前的两个 ID 相等,就表示这个 ID 所对应的文档同时包含了 a 和 b 两个关键词,所以是符合要求的,进行保留,然后两个列表都拿出下一个 ID 进行之后的对比。如果列表 A 的当前 ID 小于列表 B 的当前 ID,那么表明 A 中的这个 ID 一定不符合要求,跳过它,然后拿出 A 中的下一个 ID 和 B 进行比较。同样,如果是列表 B 的第一个 ID 更小,那么就跳过 B 中的这个 ID,拿出 B 中的下一个 ID 和 A 进行比较。依次类推,直到遍历完所有 A 和 B 中的 ID。
我画了张图来进一步解释这个过程。
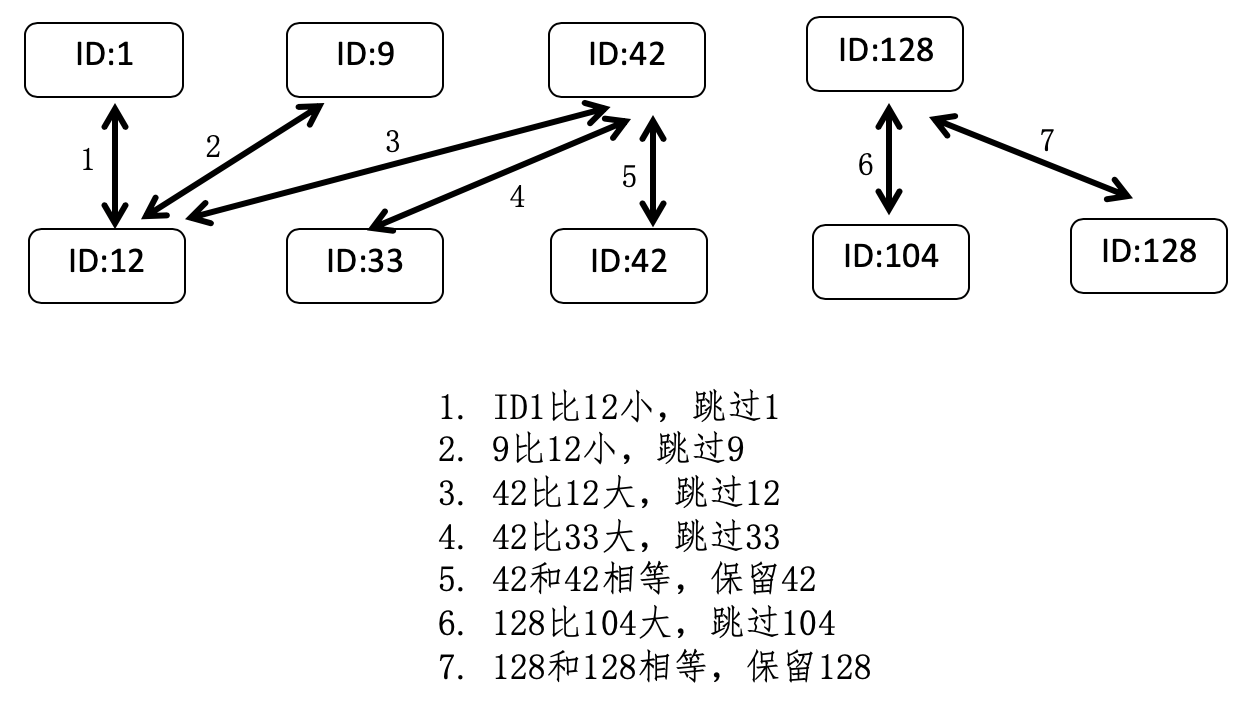
基于这种两两比较的过程,我们可以推广到比较任意多的列表。此外,在构建倒排索引的时候,我们可以事先对每个词条的文档列表进行排序,从而避免了查询时候的排序过程,达到提升搜索效率的目的。
向量空间和倒排索引的结合
有了倒排索引的高效查询,向量空间的实现就不难了。还记得之前我们讲解的向量空间模型吗?这个模型假设所有的对象都可以转化为向量,然后使用向量间的距离(通常是欧氏距离)或者是向量间的夹角余弦来表示两个对象之间的相似程度。
在文本搜索引擎中,我们使用向量来表示每个文档以及用户的查询,而向量的每个分量由每个词条的 tf-idf 构成,最终用户查询和文档之间的相似度或者说相关性,由文档向量和查询向量的夹角余弦确定。如果能获取这个查询和所有文档之间的相关性得分,那么我们就能对文档进行排序,返回最相关的那些。不过,当文档集合很大的时候,这个操作的复杂度会很高。你可以观察一下这个夹角余弦的公式。
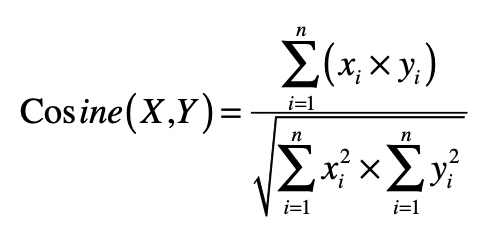
如果文档中词条的平均数量是 n,查询中词条的平均数量是 m,那么计算某个查询和某个文档之间的夹角余弦,时间复杂度是 O(n×m)。如果整个被索引的文档集合有 k 个文档,那么计算某个查询和所有文档之间的夹角余弦,时间复杂度就变为 O(n×m×k)。
实际上,很多文档并没有出现查询中的关键词条,所以计算出来的夹角余弦都是 0,而这些计算都是可以完全避免的,解决方案就是倒排索引。通过倒排索引,我们挑选出那些出现过查询关键词的文档,并仅仅针对这些文档进行夹角余弦的计算,那么计算量就会大大减少。
此外,我们之前设计的倒排索引也已经保存了 tf-idf 这种信息,因此可以直接利用从倒排索引中取出的 tf-idf 值计算夹角余弦公式的分子部分。至于分母部分,它包含了用户查询向量的和文档向量的 L2 范数。通常,查询向量所包含的非 0 分量很少,L2 范数计算是很快的。而每篇文档的 L2 范数,在文档没有更新的情况下是不变的,因此我们可以在索引阶段,就计算好并保持在额外的数据结构之中。
电商搜索的难题
问题:
曾经参与过一个电商的商品搜索项目。有段时间,用户时常反馈这么一个问题,那就是关键词搜索的结果非常不精准。比如搜索“牛奶”,会出现很多牛奶巧克力,甚至连牛奶色的连衣裙,都跑到搜索结果的前排了,用户体验非常差。但是,巧克力和连衣裙这种商品标题里确实存在“牛奶”的字样,如果简单地把“牛奶”字眼从巧克力和服饰等商品标题里去除,又会导致搜索“牛奶巧克力”或者“牛奶连衣裙”时无法展示相关的商品,这肯定也是不行的。
这种搜索不精确的情况十分普遍,还有很多其他的例子,比如搜索“橄榄油”的时候会返回热门的“橄榄油发膜”或“橄榄油护手霜”,搜索“手机”的时候会返回热门的“手机壳”和“手机贴膜”。另外,商品的品类也在持续增加,因此也无法通过人工运营来解决。
原因:
为了解决这个问题,首先我们来分析一下产生问题的主要原因。目前多数的搜索引擎实现,所采用都是类似向量空间模型的相关性模型。所以在进行相关性排序的时候,系统主要考虑的因素都是关键词的 tf-idf、文档的长短、查询的长短等因素。这种方式非常适合普通的文本检索,在各大通用搜索引擎里也被证明是行之有效的方法之一。但是,经过我们的分析,这种方式并不适合电子商务的搜索平台,主要原因包括这样几点:
- 第一点,商品的标题都非常短。电商平台上的商品描述,包含的内容太多,有时还有不少广告宣传,这些不一定是针对产品特性的信息,如果进入了索引,不仅加大了系统计算的时间和空间复杂度,还会导致较低的相关性。所以,商品的标题、名称和主要的属性成为搜索索引关注的对象,而这些内容一般短小精悍,不需要考虑其长短对于相关性衡量的影响。
- 第二点,关键词出现的位置、词频对相关性意义不大。如上所述,正是由于商品搜索主要关注的是标题等信息浓缩的字段,因此某个关键词出现的位置、频率对于相关性的衡量影响非常小。如果考虑了这些,反而容易被别有用心的卖家利用,进行不合理的关键词搜索优化(SEO),导致最终结果的质量变差。
- 第三点,用户的查询普遍比较短。在电商平台上,顾客无需太多的关键词就能定位大概所需,因此查询的字数多少对于相关性衡量也没有太大意义。
因此,电商的搜索系统不能局限于关键词的词频、出现位置等基础特征,更应该从其他方面来考虑。
既然最传统的向量空间模型无法很好的解决商品的搜索,那么我们应该使用什么方法进行改进呢?回到我们之前所发现的问题,实际上主要纠结在一个“分类”的问题上。例如,顾客搜索“牛奶”字眼的时候,系统需要清楚用户是期望找到饮用的牛奶,还是牛奶味的巧克力或饼干。从这个角度出发考虑,我们很容易就考虑到了,是不是可以首先对用户的查询,进行一个基于商品目录的分类呢?如果可以,那么我们就能知道把哪些分类的商品排在前面,从而提高返回商品的相关性。
说到查询的分类,我们有两种方法可以尝试。
- 第一种方法是在商品分类的数据上,运用朴素贝叶斯模型构建分类器。
- 第二种方法是根据用户的搜索行为构建分类器。
在第一种方法中,商品分类数据和朴素贝叶斯模型是关键。电商平台通常会使用后台工具,让运营人员构建商品的类目,并在每个类目中发布相应的商品。这个商品的类目,就是我们分类所需的类别信息。由于这些商品属于哪个类目是经过人工干预和确认的,因此数据质量通常比较高。我们可以直接使用这些数据,构造朴素贝叶斯分类器。这里我们快速回顾一下朴素贝叶斯的公式。
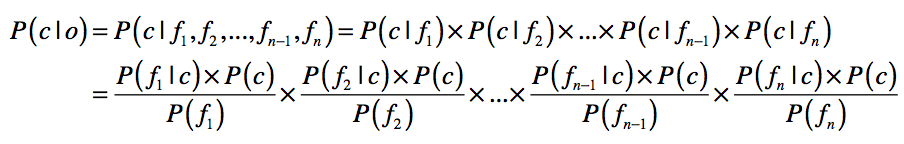
之前我们提到过,商品文描中噪音比较多,因此通常我们只看商品的标题和重要属性。所以,上述公式中的 f1,f2,……,fk,表示来自商品标题和属性的关键词。
相对于第一种方法,第二种方法更加巧妙。它的核心思想是观察用户在搜词后的行为,包括点击进入的详情页、把商品加入收藏或者是添加到购物车,这样我们就能知道,顾客最为关心的是哪些类目。
举个例子,当用户输入关键词“咖啡”,如果经常浏览和购买的品类是国产冲饮咖啡、进口冲饮咖啡和咖啡饮料,那么这 3 个分类就应该排在更前面,然后将其它虽然包含咖啡字眼,但是并不太相关的分类统统排在后面。需要注意的是,这种方法可以直接获取 P(C|f),而无需通过贝叶斯理论推导。
上述这两种方法各有优劣。第一种方法的优势在有很多的人工标注作为参考,因此不愁没有可用的数据。可是分类的结果受到商品分布的影响太大。假设服饰类商品的数量很多,而且有很多服饰都用到了“牛奶”的字眼,那么根据朴素贝叶斯分类模型的计算公式,“牛奶”这个词属于服饰分类的概率还是很高。第二种方法正好相反,它的优势在于经过用户行为的反馈,我们可以很精准地定位到每个查询所期望的分类,甚至在一定程度上解决查询季节性和个性化的问题。但是这种方法过度依赖用户的使用,面临一个“冷启动”的问题,也就说在搜索系统投入使用的初期,无法收集足够的数据。
考虑到这两个方法的特点,我们可以把它们综合起来使用,最简单的就是线性加和。
P(C|query)=w1·P1(C|query)+w2·P2(C|query)
其中,P1 和 P2 分别表示根据第一种方法和第二种方法获得的概率,而权重 w1 和 w2 分别表示第一种方法和第二种方法的权重,可以根据需要设置。通常在一个搜索系统刚刚起步的时候,可以让 w1 更大。随着用户不断的使用,我们就可以让 w2 更大,让用户的参与使得系统更智能。
解决:查询分类和搜索引擎的结合
一旦我们可以对商品查询进行更加准确地分类,那么就可以把这个和普通的搜索引擎结合起来。我使用下面的框架图来展示整个流程。
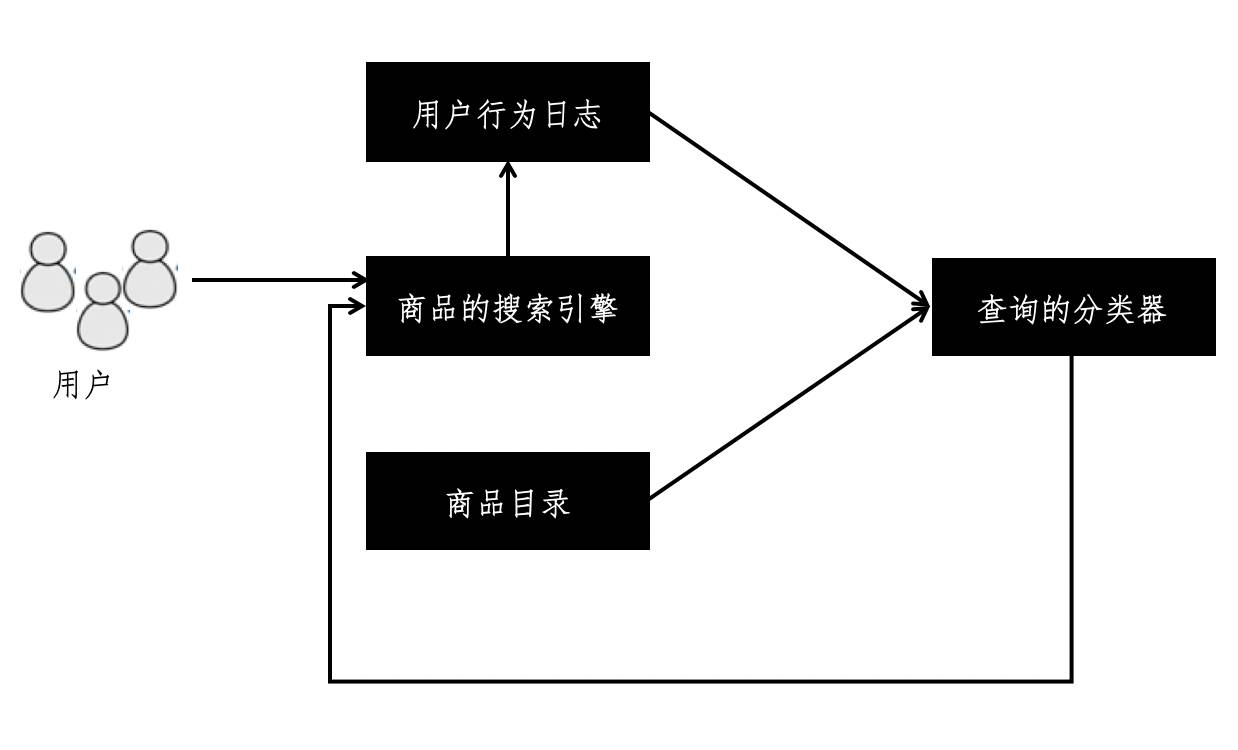
从这张图可以看到,我们使用商品目录打造一个初始版本的查询分类器。随着用户不断的使用这个搜索引擎,我们收集用户的行为日志,并使用这个日志改善查询的分类器,让它变得更加精准,然后再进一步优化搜索引擎的相关性。
以 Elasticsearch 为例,讲一下如何利用分类的结果改变搜索的排序。
Elasticsearch 是一个基于 Lucene 的搜索服务器,是流行的企业级搜索引擎之一,目前最新版已经更新到 6.6.x。Elasticsearch 是基于 Lucene 的架构,很多要素都是一脉相承的,例如文档和字段的概念、相关性的模型、各种模式的查询等。也正是这个原因,Elasticsearch 默认的排序也采取了类似向量空间模型的方式。如果这种默认排序并不适用于商品搜索,那么我们要如何修改呢?
为了充分利用查询分类的结果,首先要达到这样的目标:对于给定的查询,所有命中的结果的得分都是相同的。至少有两种做法:修改默认的 Similarity 类的实现,或者是使用过滤查询(Filter Query)。
统一了基本的排序得分之后,我们就可以充分利用用户的行为数据,指导搜索引擎进行有针对性的排序改变,最终提升相关性。这里需要注意的是,由于这里排序的改变依赖于用户每次输入的关键词,因此不能在索引的阶段完成。
例如,在搜索“牛奶巧克力”的时候,理想的是将巧克力排列在前,而搜索“巧克力牛奶”的时候,理想的是将牛奶排列在前,所以不能简单地在索引阶段就利用文档提升(Document Boosting)或字段提升(Field Boosting)。
对于 Elasticsearch 而言,它有个强大的 Boost 功能,这个功能可以在查询阶段,根据某个字段的值,动态地修改命中结果的得分。假设我们有一个用户查询“米”,根据分类结果,我们知道“米”属于“大米”分类的概率为 0.85,属于“饼干”和“巧克力”分类的概率都为 0.03。根据这个分类数据,下面我使用了一段伪代码,展示了加入查询分类后的 Elasticsearch 查询。
{
"query": {
"bool": {
"must": {
"match_all": {
}
},
"should": [
{
"match": {
"category_name": {
"query": " 大米 ",
"boost": 0.85
}
}
},
{
"match": {
"category_name": {
"query": " 饼干 ",
"boost": 0.03
}
}
},
{
"match": {
"category_name": {
"query": " 巧克力 ",
"boost": 0.03
}
}
}
],
"filter": {
"term": {"listing_title" : " 米 "}
}
}
}
}
其中最主要的部分是增加了 should 的查询,针对最主要的 3 个相关分类进行了 boost 操作。如果使用这个查询进行搜索,你就会发现属于“大米”分类的商品排到了前列,更符合用户的预期,而且这完全是在没有修改索引的前提下实现的。














 3238
3238











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









