




喜蛋生文本生成系统雏形 - 句模筑基篇
深秋的寒意已然浸透城市,实验室的窗户上凝结了一层薄薄的水汽。距离我们初步驯服了那个桀骜不驯的时序依赖组件,又过去了一段时间。然而,胜利的喜悦是短暂的。我们很快意识到,仅仅在生成的“后期”去纠正语序,如同在洪流下游筑坝,事倍功半。问题的根源,必须追溯到系统对语言“基本结构”认知的缺失上。

一个大胆的,甚至有些偏执的念头在我心中成型。既然大人的语言世界过于复杂、充满例外和噪音,那么,何不从源头开始?我回到家中,做了一件让家人颇为不解的事——我将孩子从一年级到六年级的所有语文课本、练习册、课外读本,通通搬回了实验室。
“我们要让‘喜蛋生’,从牙牙学语开始,重新学起。”我对团队宣布。我们的目标,不再是直接生成华丽的篇章,而是构建最基础、最稳固的 “句子模型”——我们内部称之为 “句模”。
第一阶段:数据炼金——从课本到“句模”原料
这堆散发着油墨和童年气息的课本,就是我们新的“矿藏”。预处理工作繁重而精细。
我们首先利用光学字符识别技术,将纸质书本数字化。接着,是繁琐之极的清洗与标注。我们制定了一套极其严格的规则:
· 只保留叙述清晰、语法绝对正确的句子。
· 将诗歌、谚语、歌词等具有特殊韵律的文本单独归类,暂不纳入初期训练。
· 对每一个句子进行人工核验与结构标注,标记出主、谓、宾、定、状、补等核心成分。
这个过程本身,就是一次对汉语之美的再发现。我们看到语言如何从“我爱卫生”这样的主谓宾单句,逐步演进到“勤劳的蜜蜂在花丛中快乐地采蜜”这样包含多重修饰的复杂结构。每一个句子,都是一个完美的“句模”实例。
第二阶段:技术路径探索——“蒸馏”、“掩码”与“填空”
拥有了高质量的“句模”语料库,下一步是如何让系统有效地学习它们。我们尝试了多条技术路径,每一条都伴随着失败与洞察。
1. 知识蒸馏法的尝试与局限:
· 思路: 我们最初设想,用一个庞大的、预训练好的复杂模型作为“教师”,让它对我们精选的课本语料进行深度分析,提炼出句法规则,再让一个小巧的“学生”模型(喜蛋生的核心)去学习这些规则。
· 实施: 我们尝试让“教师”模型为每一个句子生成“结构注意力图谱”,标示出词与词之间的语法依赖强度。
· 挫折: 我们发现,“教师”模型自身的偏见会被放大。它倾向于关注统计上高频的搭配,而对于课本中那些结构简单但语义纯净的句子,其分析有时反而过于复杂,引入了噪音。“蒸馏”出的知识并不纯净。这就像请一位文学评论家去教小学生造句,反而把孩子弄糊涂了。
· 经验收获: 我们意识到,对于基础学习,“巨人”的肩膀未必好站。直接、纯粹的数据本身,可能比经过复杂模型二次加工的知识更有效。
2. 掩码语言模型的转向与深化:
· 思路: 放弃复杂的“教师”,我们回归到经典的马斯克语言模型方法。随机遮盖句子中的一个或多个词,让系统根据上下文进行预测。
· 实施: 我们对“春天来了,小草发芽了”这样的句子进行随机掩码,变成“春天[MASK],小草发芽了”或“[MASK]来了,小草[MASK]了”。
· 挫折与演进: 单纯的掩码预测,系统很快学会了填词,但依然对结构不敏感。它可能填出“春天走了,小草发芽了”这种语法正确但逻辑突兀的句子。
· 灵感迸发(填空法): 某天,我看着孩子做语文作业里的“看图说话”和“句型填空”,突然有了灵感。我们为什么不把掩码法升级为更具结构引导性的“填空法”?
· 结构性填空: 我们不再随机掩码,而是有目的地遮盖特定语法成分。例如,固定遮盖谓语:“小马[MASK]过河”。系统必须学习在这个位置填入一个动词。
· 成分替换: 更进一步,我们进行关键词替换。将“高大的杨树”替换为“[形容词]的杨树”,让系统学会形容词与名词的搭配;将“他飞快地跑”替换为“他[副词]地跑”,训练其对副词的理解。
· 这一步,我们开始从“填词”走向“填角色”,初步触及了句法结构的核心。
第三阶段:矩阵与查并——构建“句模”索引库
尽管神经网络表现出了学习能力,但我们希望有一种更稳定、可解释的方式来固化这些“句模”。这促使我们构建了一套基于矩阵的辅助系统。
· 样例短句矩阵: 我们将成千上万个经典“句模”实例,以其核心动词为索引,构建了一个矩阵。矩阵的每一行代表一个核心动词(如“吃”、“跑”、“是”),每一列代表该动词可能出现的句型结构(如“主谓”、“主谓宾”、“主谓间宾直宾”)。矩阵元素则是该动词在该句型下的经典例句集合。
· 并查机制: 当系统需要生成一个表达时(例如:表达“获取”某物),它会先在矩阵中通过并查操作,快速找到核心动词“获取”所关联的所有合法句型,以及对应的例句。这为生成过程提供了一个强大的、绝不会出错的“模板库”和“校验库”。
这个矩阵系统,成了“喜蛋生”学习过程中的“习题集”和“标准答案”。
第四阶段:时序卷积网络(TCN)的精准赋能
为了将以上所有数据和方法整合起来,并让系统真正掌握“语序”,我们为我们的小型序列到序列模型配备了一个关键组件——时序卷积网络。
· 为何是TCN: 相比于RNN的序列依赖和Transformer的全局注意力,TCN以其固定的卷积核和分层结构,能非常稳定、高效地捕捉序列中的局部模式和层级结构。这正符合学习“句模”的需求——句子的结构往往是局部成分(如定中结构“美丽的家园”)一层层嵌套组合而成的。
· 实现方法:
1. 分层卷积: 底层卷积核识别词性搭配(如“形容词+名词”),高层卷积核识别更大的语法块(如“状语+谓语动词”)。
2. 因果约束: 确保在生成当前词时,只依赖于已生成的词,符合自回归生成的逻辑。
3. 空洞卷积: 少量层数即可获得较大的感受野,能捕捉短句中词与词之间的长程依赖(如主语和谓语动词的一致性)。
我们将TCN作为编码器的核心,让它在海量的“填空”和“替换”任务中进行训练。训练的目标很明确:当你看到“他[MASK]地唱歌”这个结构时,你应该能精准地预测出这个位置需要一个副词,并且这个副词需要与“唱歌”这个动作在语义和情感上相匹配。
这个过程是缓慢的。TCN模型需要反复消化那些看似简单的句子。有时,它会固执地在一个只能填动词的位置上塞进一个名词,有时又会生成“非常地奔跑”这样搭配不当的短语。每一个错误,都需要我们调整模型结构、学习率或数据批次。
然而,随着训练轮数的增加,变化开始悄然发生。系统在“填空”任务上的准确率稳步提升。更可喜的是,当我们撤掉“填空”的提示,让它进行自由生成时,它产出诸如“太阳从东方升起”、“小朋友在草地上做游戏”这类句子的比例显著提高了。这些句子朴实无华,但它们结构完整、语序正确。
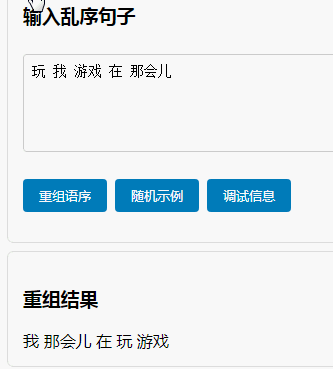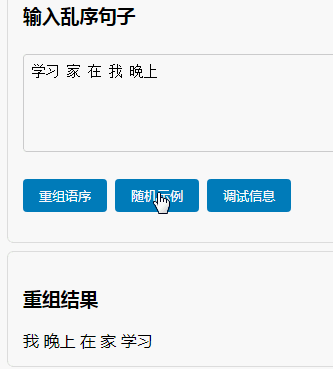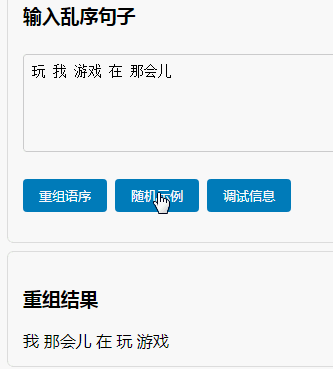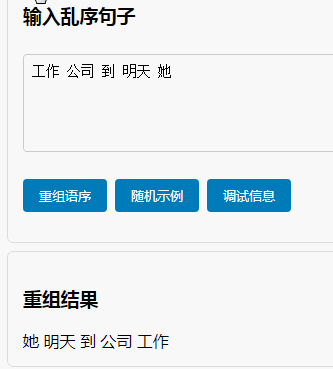
我们没有创造奇迹,没有让系统一夜之间变得文采斐然。我们只是像一位耐心的启蒙老师,通过 “课本语料”的纯净输入、“填空与替换”的刻意练习、“句模矩阵”的范式参考,以及 “TCN”对局部结构的稳健学习,为“喜蛋生”系统打下了第一块,也是最关键的一块基石——对汉语基本句子模型的认知。
看着系统又一次稳定地输出“小鸟在天空中自由地飞翔”时,我心中没有狂喜,只有一种历经漫长跋涉后,终于望见前方营地篝火的平静。我们知道,这远未成功,汉语的省略、虚实、意合等精妙之处,依然是横亘在前方的巨大挑战。
但这一次,我们终于不是在流沙上盖楼了。我们拥有了第一层坚实的地基。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









