







目录
攻防世界的csaw2013reversing2:(运行乱码、int3断点考察、函数积累、不能直接运行)
攻防世界parallel-comparator-200:(.c文件、大小写字符转换算法、函数积累、相同异或为0算法积累、线程操作积累、不能直接运行)
攻防世界tt3441810:(实际TXT文件、不能直接运行、出人意料的flag、可打印字符过滤算法积累)
攻防世界open-source:(argv[]外部调用输入参数)
攻防世界Reversing-x64Elf-100:(函数逻辑封装、地址小端存放与正向、二维数组算法积累)
攻防世界EasyRE:(栈地址连续小字符串变量、栈中过渡变量反序字符串、/x7f截断字符串、运算符优先级注意)
攻防世界IgniteMe:(函数逻辑封装、大小写字符转换算法)
攻防世界notsequence:(杨辉三角算法、函数逻辑封装、IDA对char型(byte)的4*计数)
攻防世界Newbie_calculations:(非预期行为、不能直接运行、题目描述暗示、栈地址连续小数组、c语言写脚本、不同系统的特殊数、负数作循环条件)
攻防世界的no-strings-attached:(函数名称暗示,GDB动态调试,小端)
攻防世界answer_to_everything:(函数名称暗示、函数逻辑封装、出人意料的flag、题目描述暗示)
攻防世界secret-galaxy-300:(函数名称暗示、题目描述暗示、字符串拆分算法积累)
攻防世界simple-check-100:(IDA动态调试、GDB动态调试)
攻防世界re1-100:(函数逻辑封装、出人意料的flag、非预期行为)
攻防世界elrond32:(argv[]外部调用输入参数符合条件、函数逻辑封装、递归调用算法)
攻防世界dmd-50:(函数积累、地址小端存放与正向、涉及加密、出人意料的flag)
攻防世界crazy:(函数名称暗示、地址赋值算法积累、非预期行为、出人意料的flag)
攻防世界Mysterious:(地址小端存放与正向,出人意料的flag)
攻防世界流浪者:(多层交叉引用查看、函数逻辑封装、范围算法积累、函数积累)
攻防世界hackme:(可变参数混淆、随机抽取比较、取特定位数算法)
攻防世界Windows_Reverse1:(工具脱壳、不能直接运行、寄存器传参、地址差值+数组组合遍历字符串、字符ASCII码做索引、ASCII码表相关)
攻防世界Replace:(工具脱壳、解题逆向模板、>> 和 % 运算符算法积累、正向爆破)
攻防世界BABYRE:(函数名称暗示、IDA热键重新反汇编、IDA动态调试、栈地址连续小数组)
2021年10月广东强网杯,REVERSE的simplere:(迷宫结合、涉及加密、)
系统函数函数自修改:(HOOK,通常两次修改系统函数,一次改成自定义机器码,一次改回正常)
攻防世界EASYHOOK:(非预期行为、函数积累、手动机器码)
CTF 逆向总结
工具脱壳:
值传统的用工具压缩的文件,可以直接用工具来解压缩,即脱壳。
非预期行为:
指解题中出现与预想结果不符合的一系列非预期行为,这基本说明了在中间或前面存在其他自己还没分析的操作。
线程操作积累:
指解题代码中设计多线程的交叉,阻塞,共享内存等操作,由于线程知识积累较少,所以每次都要积累。
不同系统的特殊数:
指解题中遇到考察特定位数系统中特定的数的真实值的时候,需要辨认出对应的值才能继续解题。如:32位系统中100000000就是0了
题目类型总结:
题目描述暗示:
指题目给出的描述中有解题的大方向思路,以及对解题过程中出现的一些疑惑点的解释。
不能直接运行:
指解题中下载的附件无法正常运行,可能是对外界本机环境又要求,需要文件相关操作等。也可能是脱壳后地址混乱,需要修复导入表或梳理地址,还有可能是算法混淆,增加了运算时间。
游戏通关数生成flag:
指与游戏相关的可执行文件中,不是存储型flag,而是与用户输入相关的生成型flag,且以通关数生成flag。通常这种类型的题目改一下判断条件就可以全部通关获取flag了。
迷宫结合:
指解题过程中有类似于迷宫的每一步不能碰点或每一步必须符合在1维或多为字符串上的落点,如:*A**********.***.....**.....***.*********..*********B**
这称之为与迷宫结合类型。算法走迷宫过于耗时,通常整理出迷宫维数后手动来走。
汇编操作类总结:
int3断点考察:
int 3是断点的一种,代码执行到此次会抛出异常,因为这不是我们在OD之类的调试器下的断点,所以OD之类的调试器不会处理该断点的异常,而是交给系统处理,而系统的处理方式往往是强制退出。所以我们在动态调试中要改为nop,不然后面的代码就没法执行。
手动机器码:
指解题过程中遇到类似自修改代码的操作。
如HOOK原型:
byte_40C9BC = 0351;
dword_40C9BD = (char *)sub_401080 - (char *)lpAddress - 5; ;跳转到sub_401080地址处
这样写是因为汇编语言JMP address被编译后会变成机器指令码,E9 偏移地址,偏移地址=目标地址-当前地址-5(jmp和其后四位地址共占5个字节)。所以前面直接用E9,这里直接用偏移地址就省去编译生成机器码那一步。
ASCII码表类总结:
字符ASCII码做索引:
指解题中遇到如:*v1 = byte_402FF8[(char)v1[v4]]; 之类的字符做数组索引的表达式。
其中v1[v4]逐个取input_flag的单个字符,这个字符的ascii码作为偏移继续在byte_402FF8[]数组中寻址。(PS:这不是Python中list.index()函数可以用字符查找对应索引!)
ASCII码表相关:
指解题中遇到.data数据节中跟踪变量数组时显示的有大量0FFh这种不可识别字符后又有连续的可打印字符。
因为ASCII编码表里的可视字符就得是32往后了, 所以凡是位于32以前的数统统都是迷惑项,都会被显示成0FFh甚至乱码,不会被索引到的。然后后面32之后就有连续的字符串,这种就是ASCII码表。
逆向、脚本类总结:
解题逆向模板:
第一步确定Flag字符数量,第一个红框处得到flag数量是35。
第二步找到已确定的比较字符串作为基点来反推flag字符。
第三步找出逻辑中与flag直接相关的部分,该部分可以正向爆破或者从尾到头的反向逻辑。然后找到与flag没有直接关联的部分,该部分无需逆向逻辑,直接正向流程复现即可。
正向爆破:
指解题中采用枚举正向爆破的方法,让flag中的每一个字符遍历常用的字符(ascii码表中32-126),带入原伪代码中加密算法(不用逆向),如果成功,就把这个flag存入。
C语言写脚本:
指解题中对于不需要逆向逻辑的单纯去除冗余代码算法的题目,需要仿写去除冗余代码后的逻辑,由于只是仿写,所以原本的伪代码很难用python复现,这时就需要复制粘贴修改成C语言脚本了。
代码截断重写:
指解题中flag生成与用户输入无关,可以单独截断提取出flag生成的函数或逻辑,然后运行截断程序输出flag。
出人意料的flag:
指在题目中获取到了flag,但是这个flag可能长得不像flag,或者flag还要经过进一步的脑洞处理,而不是常规的解密处理。
栈、参数、内存、寄存器类总结:
栈地址连续小数组:
指一些本来应该是大数组的变量被IDA识别成分割成两个或多个连续地址的小数组来使用,可以通过查看栈中的地址排列或循环中的循环数大于单个数组空间来发现,也是需要更加细致才能分析出来。
栈地址连续小字符串变量:
指一些本来应该是大字符串的单个变量被IDA识别成分割成两个或多个连续地址的小字符串变量来使用,可以通过查看栈中的地址排列来发现,也是需要更加细致才能分析出来。
栈中过渡变量反序字符串:
指一些题目本来取输入的字符串变量的最后一位,但是IDA插入了过渡变量来使分析变得困难,如v5 = (char *)&v11 + 7;这里v11就是过渡变量,指向输入字符串input_flag的第16位,所以这里v5指向输入字符串input_flag的最后一位,栈中地址又是从下到上,高位到低位的,所以反序操作标志是v6 = *v5--;
地址小端存放与正向:
指字符串数字等在内存中是反向存放的,如v7 = ‘ebmarah’,如果用地址来取的话要反向,如果用数组下标来取的话才是正向。
高低位分割数:
指一些本来应该是两个小类型变量的数被IDA识别成一个大类型然后分成高位和低位来使用,需要更加细致才能分析出来。
可变参数混淆:
指解题中IDA伪代码显示出来的参数数量超出,不符合逻辑,也不知道多附加了什么操作。查看反汇编才发现并没有传入那么多的参数,原伪代码中之所以有那么多参数是因为C语言的可变参数的特性,有些参数显示了但是并没有用上。
地址差值+数组组合遍历字符串:
指解题中遇到地址减地址的操作如:v4 = input_flag - v1; 然后通过数组组合如:v1[v4]。
这里V1作为地址和v4作为数组v1[v4]执行的是v1+v4的操作,就是v4+v1=input_flag。因为数组a[b]本质就是在数组头地址a加上偏移量b来遍历数组的,所以这里是一种遍历input_flag的新操作。
寄存器传参:
指解题中涉及寄存器作为参数传入,但是有时候IDA无法反汇编出寄存器参数的传入。解题中发现异常如:传入参数为input_flag,但是比较的却是另一个变量,这时就可能是寄存器传参了,要通过查看汇编代码来发现。
/x7f截断字符串:
/x7f可以阻断字符串,在IDA中会把一个长字符串分隔成两行的短字符串。如:xIrCj~<r|2tWsv3PtI /x7f zndka
argv[]外部调用输入参数符合条件:
指解题中需要使用命令行传入参数。
如:int main( int argc, char *argv[] )
$./a.out testing1 testing2
应当指出的是,argv[0] 存储程序的名称,argv[1] 是一个指向第一个命令行参数的指针,*argv[n] 是最后一个参数。如果没有提供任何参数,argc 将为 1,否则,如果传递了一个参数,argc 将被设置为 2。
函数类总结:
函数逻辑封装:
指关键逻辑被封装成自定义函数,需要自己双击跟进并总结出函数作用,需要通过动态调试验证猜想的作用。
函数名称暗示:
指题目给出的自定义函数名称有含义,可以概括该函数的大致作用,来给总结函数作用提出一些方向性的指导。
函数积累:
指题目中有没做笔记的函数需要终点重温和积累一下。
IDA等软件类总结:
GDB动态调试:
指使用GDB来进行ELF文件的动态调试。
IDA动态调试:
指使用IDA来进行ELF或windows文件的动态调试。
IDA热键重新反汇编:
指解题中必须使用IDA热键对处理过或未处理的的错误反汇编代码重新分析,以至生成新的正确的反汇编代码,多用在混淆和花指令区。
IDA热键a生成数组:
指解题中对IDA零散的单个字符可以使用热键a生成数组,即长字符串。如果中间没有截断,则可以正常生成字符串。
IDA对char型(byte)的4*计数:
指解题中虽然IDA伪代码显示的 i 是 int 型,但是计算的时候通常会变成 4*i ,这通常会具有干扰性,所以我们要知道这是IDA默认把 i 当成byte类型即可,4*i 和 int 型的 i 是一样的。
单层交叉引用查看:
指在解题中只能确定一些少量的被调用函数,这些函数可能是自定义函数也可能系统函数。通过IDA的function call或Ctrl+x操作来查看改函数被谁调用,从而找到主逻辑所在的函数。
多层交叉引用查看:
指在解题中一开始获得的是比较深层次的被调用函数,需要多次查看交叉引用才能锁定最终的主逻辑所在函数。
算法类总结:
main算法逻辑平铺:
指主要算法代码都在main函数中,不涉及解题算法之外的其它操作,而且代码逻辑平铺、显而易见,没有把关键逻辑分成自定义函数形式,不需要频繁跟进函数。
范围算法积累:
指解题中有涉及用户输入的范围内判断以及逆向算法时对于范围处理的过程中值得注意和积累的地方。
地址赋值算法积累:
指解题中涉及对关键字符串如用户输入字符串的操作,原代码中会先把输入字符的地址赋值给变量,即让一个变量指向输入字符串然后再开始修改,这是两步操作,需要辨认。
二维数组算法积累:
指解题中涉及二维数组,用户输入与二维数组要取的下标相关,逆向时要明确是二维数组逻辑以及一维在哪里确定,举例如: *(char *)(v3[i % 3] + 2 * (i / 3)) - *(char *)(i + a1) != 1
字符串拆分算法积累:
指解题中IDA对多个连续的字符串按打乱的顺序以下标的方式分别按多组赋值,这种字符串拆分赋值的方式需要动态调试或耐性的一个个跟踪分析才能梳理清楚。
相同异或为0算法积累:
指解题中遇到特定异或为0的条件则可以采用上面的定律。如: *result = (108+argument[1]) ^ argument[2] = 0 即 argument[2]=(108+argument[1]) 因为相同异或才为0
可打印字符过滤算法积累:
指解题中遇到flag等关键字符在内的混杂的大量字符中,要通过多层过滤来一步步生成flag的算法,可打印字符范围内可用算法如:if ord(i)>=32 and ord(i)<=125:
大小写字符转换算法:
指解题中有一些算法范围波动比较少,看似逻辑相关,实际上只是大小写的ASCII值转换而已。
递归调用算法:
指解题中遇到函数内递归调用自己,传入参数也会在调用时修改的算法,当需要用python仿写递归算法时可以通过超范围的循环来实现递归,因为设置同样的条件,递归不满足时仿写的循环也会退出。
杨辉三角算法:
指解题中遇到对传统数学算法的代码实现,辨认的特征是通过关键代码判断是否符合杨辉三角算法的特性,如:在一维中用(n*(n+1)/2的前n行总数来遍历到特定行,又如:2^n来求第n行的和等。通常涉及等差、等比数列。
>> 和 % 运算符算法积累:
指解题中遇到 >> 和 % 运算符的操作。>> 运算符其实是不带余数的除法 / 算法,单取整数部分。% 运算符其实是不带整数的求余运算,单取余数部分。
如: v6 = (v5 >> 4) % 16 是除以16后的整数部分, v7 = ((16 * v5) >> 4) % 16 是乘16后除16再取16内的余数,也就是直接取16内的余数。一个取整数,一个取余数,所以他们的逆向算法就是16 * v6 + v7
运算符优先级注意:
指解题中应该要准确判断长运算式的优先级顺序,写脚本中也应该尽可能使用括号来固定优先级,否则会出现结果的错误。
负数作循环条件:
指解题中遇到负数作循环条件的情景需要明白这不是死循环,而是正数大循环。如:while(-1) ,在32位里 -1 就是 FFFFFFFF,就是100000000 - 1。所以这一下子就转正了!如果是while(-a2),所以就循环100000000 - a2次。
涉及加密:
指题目中存在加密,可能是传统的MD5、RSA或base64等,也可能是非传统的加密方式。
随机抽取比较:
指在解题中以随机数做基准,取各个对应的字符进行比较。其实就是在相同的字符中取随机但同样的位来比较,所以逆向是要顺序取。
取特定位数算法:
指解题中遇到源代码有__int8这样的限制,这是取前8位,python中可以使用&0xff这种方法,因为&在Python中是逻辑与运算,所以与的时候就保留了前8位,如:flag+=chr((v12^v15)&0xff)。取前16,32位都可以套用这个方法。
main函数主逻辑分析(C语言)
不能正常运行的exe文件类型:
bugku 逆向入门:(实际TxT文件、不能直接运行)

直接去掉.exe后缀用记事本打开,直接搜索bugku,无果。看到文件开头:
是base64加密的图片,于是用在线网址(http://tool.chinaz.com/tools/imgtobase/)解密得到二维码:(扫码即得flag)
攻防世界的csaw2013reversing2:(运行乱码、int3断点考察、函数积累、不能直接运行)
win32无壳,那么既然是windows的直接双击运行一下看看:
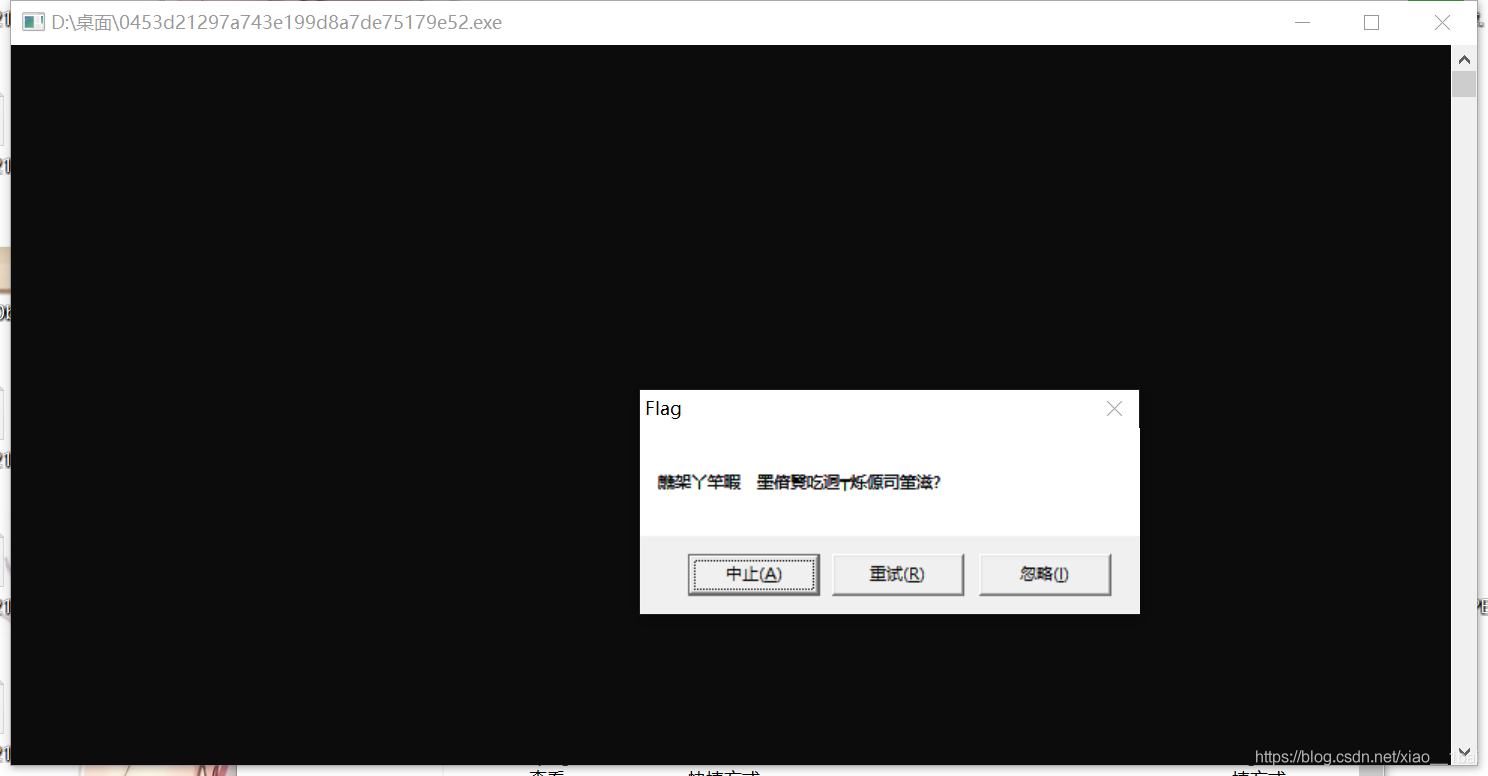
这个就是乱码的flag了,乱码有好多种,base64加密等等这些,我们一个个排除,先扔入IDA中查看伪代码。要先看C或C++伪代码再分析反汇编结构图最后才看反汇编文本!!!!
main主函数伪代码如图:

那么解题关键就在前面了:
memcpy_s(lpMem, MaxCount, &unk_409B10, MaxCount);//这个是复制函数,把&unk_409B10处的字符串赋值给lpMem,分析后可知这是乱码的flag,双击跟踪&unk_409B10也可以看到是弹框中输出的乱码。
if ( sub_40102A() || IsDebuggerPresent() ) //这是判断函数,如果判断是调试器运行就执行这个解密
{
__debugbreak();
sub_401000(v3 + 4, lpMem);//这个双击跟踪进去后发现是一个运算函数,那么只能是解密算法所在了
ExitProcess(0xFFFFFFFF); //解密后就退出了,就没有后面的弹框了,需要我们自己想办法。
}
分析完了,我们开始解题,也是好几种方法:
1:静态调试:根据sub_401000的解密算法自己仿照C语言或python脚本解密,因为参数都可以跟踪到。
2:动态调试:在onllydbg中进入解密流程内,解密后查看寄存器或跳转到messageboxA中进行弹出即可。
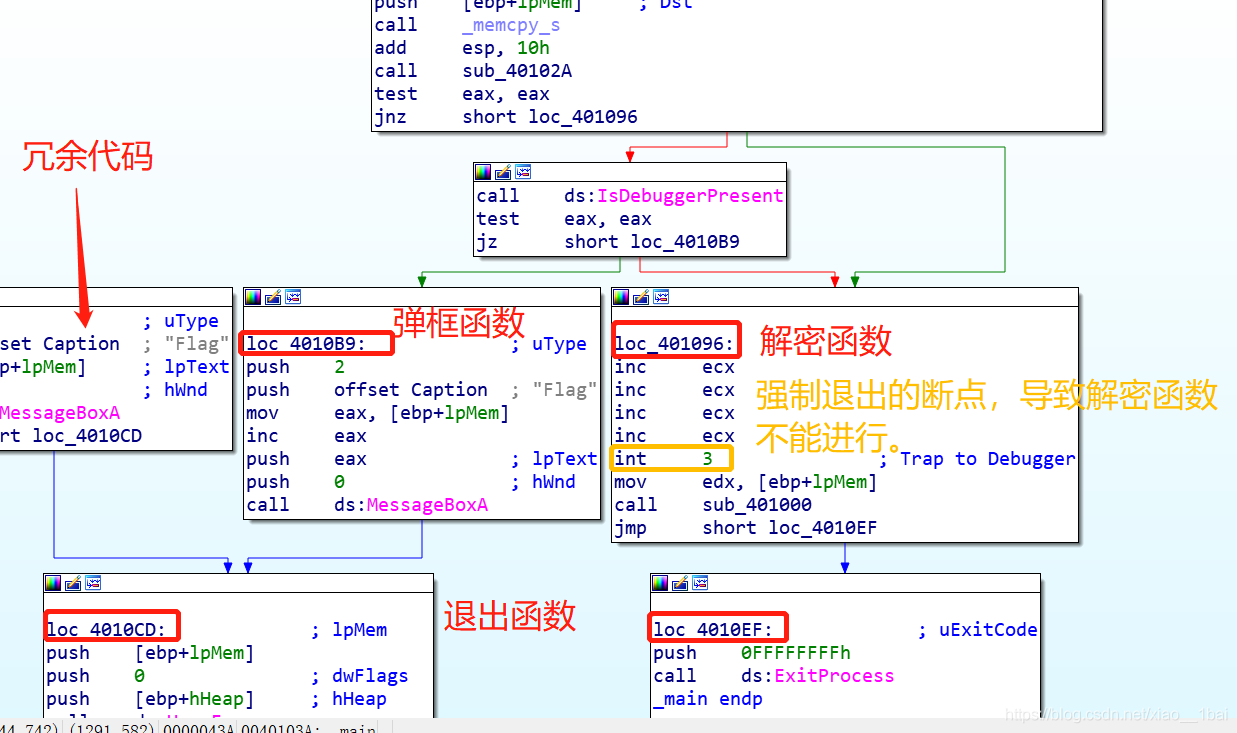
这里我用的动态调试:按照流程看完C语言伪代码后我们来看反汇编结构图:
有了前面分析基础就看懂得多了:loc_4010B9:是弹框函数所在,loc_401096:是解密函数所在,最左边那个应该是冗余代码,loc_4010EF和loc_4010CD: 都是退出函数所在。
注意这里loc_401096有个int 3;这是断点的一种,代码执行到此次会抛出异常,因为这不是我们在OD之类的调试器下的断点,所以OD之类的调试器不会处理该断点的异常,而是交给系统处理,而系统的处理方式往往是强制退出。所以我们在动态调试中要改为nop,不然后面的代码就没法执行
那么我们上onllydbg修改int 3;断点为nop:
可以看到我改了几个地方:
1:
002B1094的 jz short loc_4010B9改成jnz short loc_4010B9,虽然我也不知道为什么我用onllydbg调试还是进不去解密函数,可能onllydbg被认为不是调试器吧。
2:
002B109A 的int 3;断点强制退出被我改成了002B109A nop,标识空操作,避免退出。
3:
002B10A3的 jmp 0453d212.002B10EF改成jmp 0453d212.002B10B9 因为这里原来解完密后就退出的,我把它转到原来loc_4010B9:的messageboxA函数去作为弹框内容输出了。(ps:我本来是跳转到最IDA反汇编结构图的左边那个冗余函数的,因为我看它也是MessageboxA函数,结果弹出个空框,对比后才发现它比第二个MessageboxA少了几行代码,原来是个坑,难怪。),当然也可以解完密之后下断点读取寄存器内容也行。
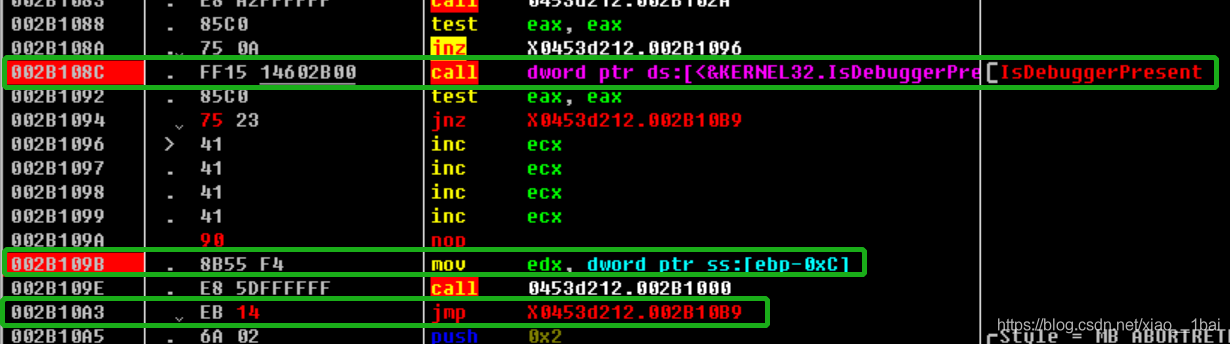
这样就弹出flag了:
攻防世界parallel-comparator-200:(.c文件、大小写字符转换算法、函数积累、相同异或为0算法积累、线程操作积累、不能直接运行)
下载附件,一个.c后缀的文件,devc++中查看代码。
这里犯下第一个错误:混淆代码太多,线程一开始没学,简单学了后发现也和解题逻辑没有太大关系,可以把线程划分为系统函数这一块:
#include <stdlib.h>
#include <stdio.h>
#include <pthread.h> //linux的线程库 ,所以要在linux中才可运行
#define FLAG_LEN 20
void * checking(void *arg) {
char *result = malloc(sizeof(char));
char *argument = (char *)arg;
*result = (argument[0]+argument[1]) ^ argument[2]; //对 first_letter、 differences[i]、 user_string[i]进行简单操作
return result;
}
int highly_optimized_parallel_comparsion(char *user_string)
{
int initialization_number;
int i;
char generated_string[FLAG_LEN + 1];
generated_string[FLAG_LEN] = '\0';
while ((initialization_number = random()) >= 64); //无用循环
int first_letter;
first_letter = (initialization_number % 26) + 97; //initialization_number从0~25取值 +97后ASCII对应小写的a~z
pthread_t thread[FLAG_LEN]; //创建数组型的线程标识符 ,20线程句柄
char differences[FLAG_LEN] = {0, 9, -9, -1, 13, -13, -4, -11, -9, -1, -7, 6, -13, 13, 3, 9, -13, -11, 6, -7}; //定义20个元素的char数组
char *arguments[20]; //定义20个char型的指针数组
for (i = 0; i < FLAG_LEN; i++) {
arguments[i] = (char *)malloc(3*sizeof(char)); //每个指针指向3个char字节划分的数组头
arguments[i][0] = first_letter; //first_letter由于 initialization_number = random()而未确定
arguments[i][1] = differences[i]; //已确定
arguments[i][2] = user_string[i]; //用户输入字符,未确定
pthread_create((pthread_t*)(thread+i), NULL, checking, arguments[i]); //调用上面checking函数对arguments三字节数组进行简单操作
}
void *result; //定义一个数组,用上面的异步线程赋值
int just_a_string[FLAG_LEN] = {115, 116, 114, 97, 110, 103, 101, 95, 115, 116, 114, 105, 110, 103, 95, 105, 116, 95, 105, 115}; //定义一个20个元素的数组
for (i = 0; i < FLAG_LEN; i++) {
pthread_join(*(thread+i), &result); //阻塞线程,让线程一个个执行
generated_string[i] = *(char *)result + just_a_string[i]; //把 just_a_string数组加到result中 赋值给 generated_string数组
free(result);
free(arguments[i]);
}
int is_ok = 1;
for (i = 0; i < FLAG_LEN; i++) {
if (generated_string[i] != just_a_string[i]) //这里比较generated_string和 just_a_string数组,而generated_string数组在前面赋值中= *(char *)result + just_a_string[i],所以result等于0才行
return 0;
}
return 1;
}
int main()
{
char *user_string = (char *)calloc(FLAG_LEN+1, sizeof(char)); //分配21个字符空间,除去0结尾就是20个字符
fgets(user_string, FLAG_LEN+1, stdin); //获取用户输入
int is_ok = highly_optimized_parallel_comparsion(user_string);
if (is_ok)
printf("You win!\n");
else
printf("Wrong!\n");
return 0;
}
关键代码判断有两条:(所以result是要为0了,因为0加任何数都为0。)
generated_string[i] = *(char *)result + just_a_string[i];
if (generated_string[i] != just_a_string[i])
给result赋值的语句中唯一不确定的就是argument[0],也就是 first_letter = (initialization_number % 26) + 97:
*result = (argument[0]+argument[1]) ^ argument[2]; //对 first_letter、 differences[i]、 user_string[i]进行简单操作
在这里我查了很多资料,很多人直接用108代替argument[0],也有人用first_letter的范围97~122来批量计算,这里我两种都说:
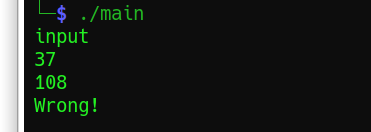
第一种:108,这里也是犯下的第二个错误,以前就听过rand是伪随机数,要用srand生成随机数种子才行,不然产生的随机数列表都是一样的,而单独产生的随机数也不会在随机数列表用随意取值,而是固定的第一次这个值,第二次那个值。所以这里我们可以直接修改源代码调试,打印出first_letter的值。
(PS:linux中C语言要使用gcc main.c -lpthread -o main编译方法来编译带pthread.h库的文件)
while ((initialization_number = random()) >= 64);
printf("%d\n",initialization_number); //打印initialization_number
int first_letter;
first_letter = (initialization_number % 26) + 97;
printf("%d\n",first_letter); //打印first_letter
结果可以看到,一个37,一个108,所以108就是调试过来的:
知道108后写脚本,这里犯下第三个错误:
因为源代码是*result = (argument[0]+argument[1]) ^ argument[2] = 0 即 *result = (108+argument[1]) ^ argument[2] = 0 即 argument[2]=(108+argument[1]) 因为相同异或才为0.(一开始我并不清楚这个逻辑,这里也可以说是一个算法积累了)
first_letter=108
differences=[0, 9, -9, -1, 13, -13, -4, -11, -9, -1, -7, 6, -13, 13, 3, 9, -13, -11, 6, -7]
flag=""
print(''.join([chr(first_letter+i) for i in differences])) //这里借鉴了别人的博客,用的是列表的[ ]解析式,的确不错!也可以作为总结!
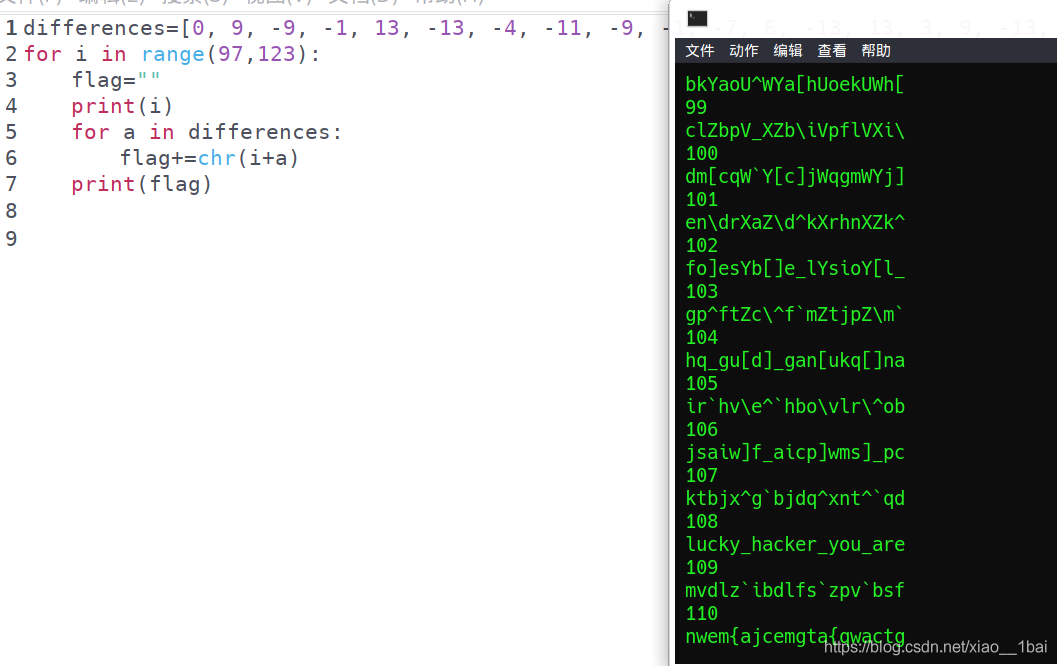
第二种方法就是从97~122的first_letter开始批量爆破计算,脚本:
differences=[0, 9, -9, -1, 13, -13, -4, -11, -9, -1, -7, 6, -13, 13, 3, 9, -13, -11, 6, -7]
for i in range(97,123):
flag=""
print(i)
for a in differences:
flag+=chr(i+a)
print(flag)
可以看到,能形成有文字含义字符串的就是108了:
攻防世界tt3441810:(实际TXT文件、不能直接运行、出人意料的flag、可打印字符过滤算法积累)
下载附件,照例扔入exeinfope中查看信息:
说是TXT文件,???记事本打开看一下:
一下子懵住了,脑袋没转过来,查看了资料说Flag就混杂在这些十六进制里,winhex64打开看一下:
结果winhex64的文本显示不了字符,我还是看不出来什么。(换ASCII编码也是一样)
结果发现他们使用IDA打开的:
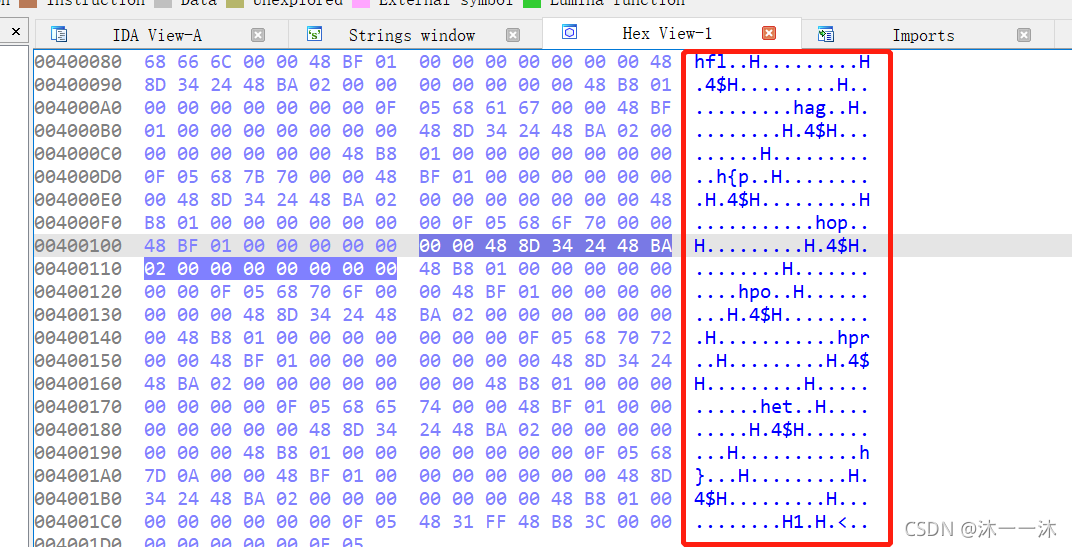
终于有一点字符了,之前了解过点字符是因为IDA识别不了不可打印字符,所以这里要写脚本过滤,像杂项或密码学一样的:(32~125是可显示字符)
key1=''' //这里积累第一个经验,多行的字符串可以用三引号,虽然我知道这个三引号,但是我要用时我还真想不到它。
hfl..H.........H
.4$H.........H..
.........hag..H.
........H.4$H...
......H.........
..h{p..H........
.H.4$H.........H
...........hop..
H.........H.4$H.
........H.......
....hpo..H......
...H.4$H........
.H...........hpr
..H.........H.4$
H.........H.....
......het..H....
.....H.4$H......
...H...........h
}...H.........H.
4$H.........H...
........H1.H.<..
.......
'''
flag=""
for i in key1:
if ord(i)>=32 and ord(i)<=125: //过滤在可打印字符范围内的字符
flag+=i
print(flag.replace('.','').replace('HH4$','').replace('HHh','')) //这里是我一层层看逻辑过滤的,因为出现多个. 、HH4$和HHh,所以这些都要过滤掉。
结果:

可以看到flag了,但是提交时说只提交{}内的部分,就是poppopret。这种提交方式已经见怪不怪了。
main算法逻辑平铺类型:
攻防世界逆向入门题Hello, CTF:(简单比较)
对汇编不太熟悉,只能分析伪代码:
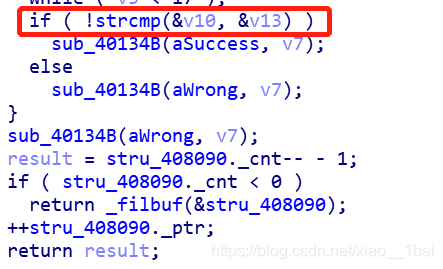
伪代码显示用用户输入的v10和v13比较,sub_40134B是我在OD中认定的字符串输出函数puts。
所以终于找到了v13这个被比较变量了,查看与它相关的操作:
![]()
一个复制函数,那么那个a4~开头的就是我们要找的了,双击跟踪:

数据域发现一串十六进制字符,解码得到flag。
攻防世界open-source:(argv[]外部调用输入参数)
#include <stdio.h>
#include <string.h>
int main(int argc, char *argv[]) {//外部调用输入参数
if (argc != 4) {//输入三个参数,因为第一个是程序自己的名称
printf("what?\n");
exit(1);
}
unsigned int first = atoi(argv[1]);
if (first != 0xcafe) {//第一个参数的十六进制为0xcafe
printf("you are wrong, sorry.\n");
exit(2);
}
unsigned int second = atoi(argv[2]);
if (second % 5 == 3 || second % 17 != 8) {//第二个参数满足条件我口算有42,余数是不足才补的数,不是整除后剩的数。也就是5*9余3
printf("ha, you won't get it!\n");
exit(3);
}
if (strcmp("h4cky0u", argv[3])) {//第三个参数直接就是h4cky0u
printf("so close, dude!\n");
exit(4);
}
printf("Brr wrrr grr\n");
unsigned int hash = first * 31337 + (second % 17) * 11 + strlen(argv[3]) - 1615810207;//这里的结果hash与前面输入参数有关,鄙人不才,曾一度想修改源码不输入参数直接输出这句话,当然,没有参数的这句话就会报错。
printf("Get your key: ");
printf("%x\n", hash);
return 0;
}
一开始第二个条件停了会,毕竟做题经验太少了,atoi返回的是字符串的整形,0xcafe是十六进制,整形和十六进制比较C语言内部会进行进制转换:
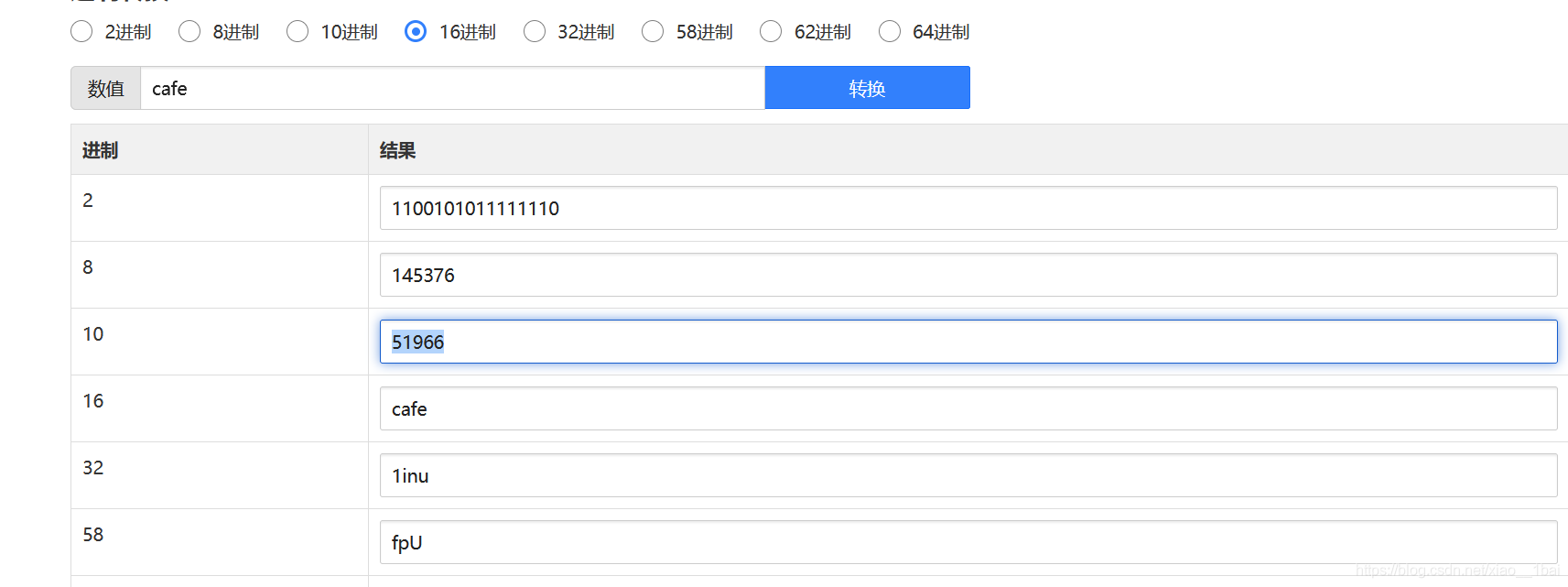
所以到此所有参数都解出来了,第一个是51966,第二个是42,第三个是h4cky0u.在kali虚拟机中编译,命令行接受参数执行即可:
gcc 1.c
./1.c 51966 42 h4cky0u
后来看别人做法还发现了其他解法,第一个是直接修改源码,其实也对,源码在手当然是充分利用源码的优势才对,直接把hash输出语句替换成:
unsigned int hash = 0xcafe * 31337 + (second % 17) * 11 + strlen(argv[3]) - 1615810207;
即可,反正C语言内部会自己转换,记得把第二个0xcafe处的判断语句用/**/注释掉即可。
攻防世界logmein:(地址小端存放与正向)
ELF的linux文件,在kali虚拟机中查看位数,是64位,扔到64位IDA中查看信息,主要查看伪代码:

很常规的题型,关键输入判断如下:
![]()
在IDA中v7按R键转换为v7 = ‘ebmarah’; (_BYTE *)&v7表示将原本是_int64类型的v7转换地址形式,转成byte型地址形式来实现1位一位读取字符串。
这里还要注意的是这里的内存是小端存放的,也就是说我们要逆着来比较v7的字符串,然后直接上python脚本:
key1=":\"AL_RT^L*.?+6/46"
key2="ebmarah"[::-1]
key3=""
for i in range(len(key1)):
key3+=chr(ord(key2[i%7]) ^ ord(key1[i]))
print(key3)
BUUCTF的reverse2:(原flag简单操作)
一进门看到这个,还以为真的这么简单,认为offset flag就是flag地址,直接跟踪结果是假的flag,一开始还以为是提交格式有问题,比如多了个空格或者复制错了什么啊,果然还是太年轻了,见识少,就是假的flag。
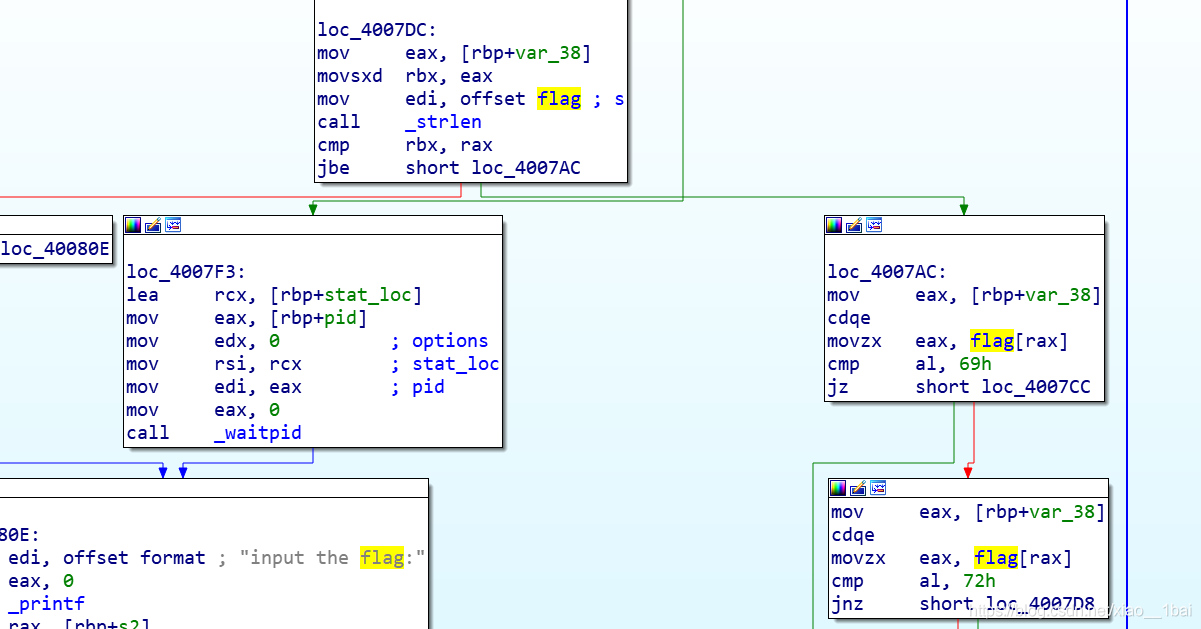
查看伪代码(由于汇编能力比较差):
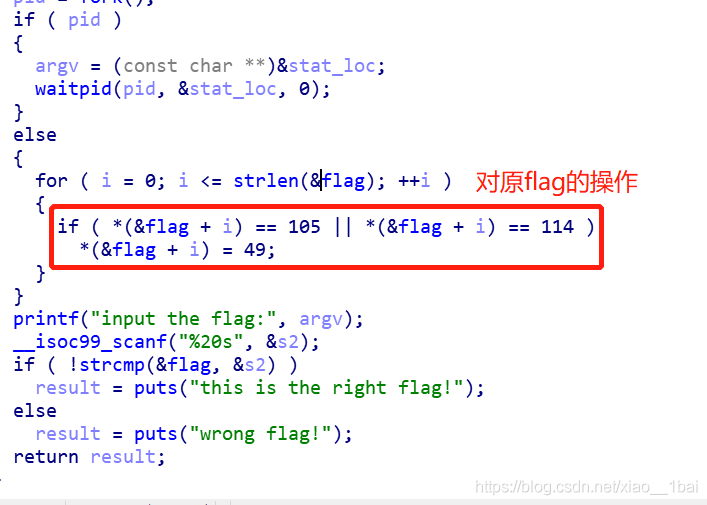
可以看到前面有对flag内容的替换,就是把ASCII码等于105和114的替换成ASCII码49。直接写脚本:
flag="{hacking_for_fun}"
for i in range(len(flag)):
if((ord(flag[i])==105) or (ord(flag[i])==114)):
flag=flag.replace(flag[i],chr(49))
print(flag)
写脚本时一开始还有点问题,顺便记在这里提醒一下自己:
一开始写成flag="{hacking_for_fun}"[::-1],受了以前的小端顺序影响,这里我们看到的就是从601081到601091的地址顺序,也就是已经按小端的来了,所以不用再反序,还有就是flag.replace()这种python字符串内置函数都是暂时的,要想保留改变还是要用赋值语句赋值成:flag=flag.replace(flag[i],chr(49))
攻防世界666:(函数逻辑封装,函数名称暗示)
64位ELF文件,无壳,扔入IDA64中查看伪代码,因为有main函数,所以直接main函数:
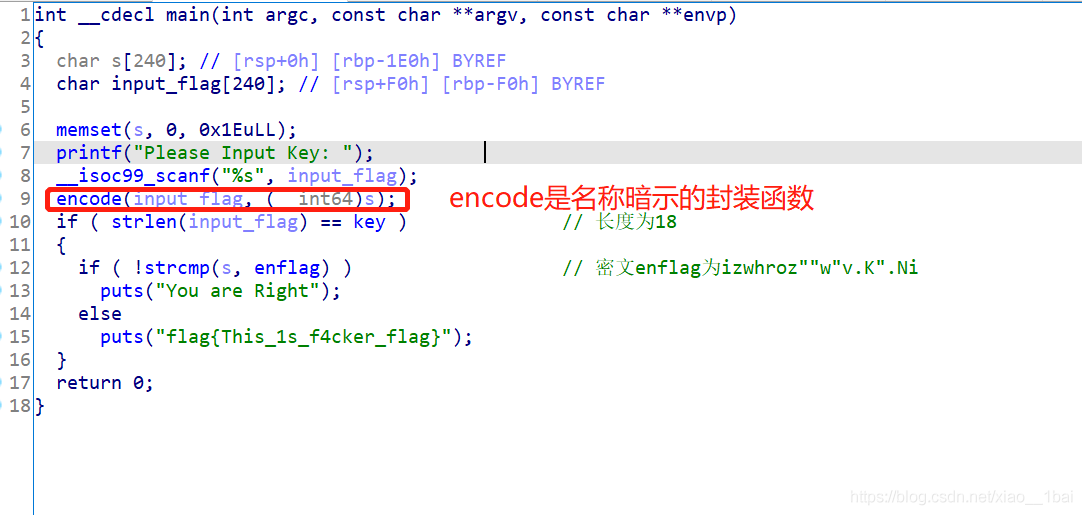
判断题目类型,flag是与用户输入有关的明文密文加密型,给了密文(双击跟踪),那么根据加密逻辑函数用密文逆向逻辑解出明文即可,加密逻辑如下:
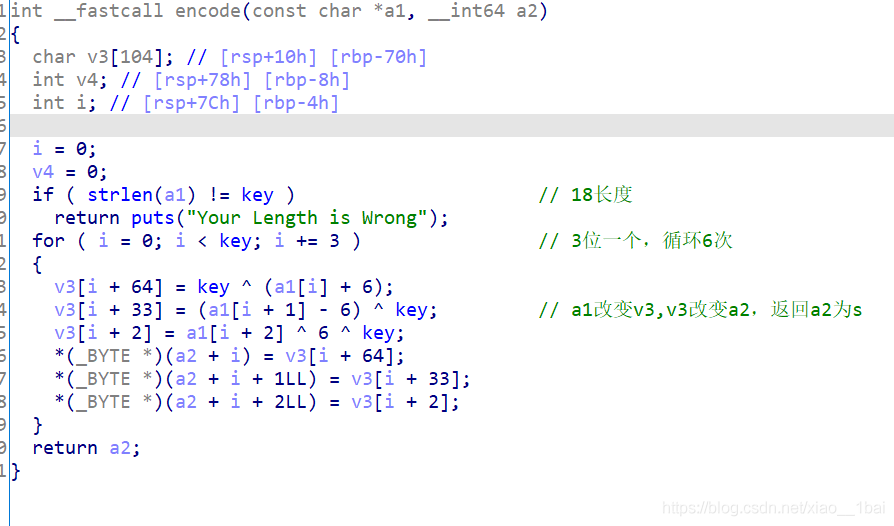
这逻辑挺简单的,所以直接上脚本即可:
a2="izwhroz\"\"w\"v.K\".Ni"
key=18
v3=""
flag=""
#print(len(a2))
for i in range(0,18,3):
v3=a2[i]
flag+=chr((ord(v3)^key) - 6)
v3=a2[i+1]
flag+=chr((ord(v3)^key) +6)
v3=a2[i+2]
flag+=chr((ord(v3)^key)^6)
print(flag)
攻防世界Reversing-x64Elf-100:(函数逻辑封装、地址小端存放与正向、二维数组算法积累)
64位ELF文件,无壳,扔入64位IDA中,有主函数从主函数开始:(PS:这里犯下第一个错误,我一开始以为没有主函数,跳到start函数中去分析了,结果有个栈指针错误,但是我还不会调,迷惘了,后来一看才发现原来有主函数)

跟踪进入判断函数并分析代码:
__int64 __fastcall sub_4006FD(__int64 a1)
{
int i; // [rsp+14h] [rbp-24h]
__int64 v3[4]; // [rsp+18h] [rbp-20h]
v3[0] = (__int64)"Dufhbmf"; //这里犯下第二个错误,我以为是普通字符串,在内存中应该小端顺序反序才对,结果是数组,数组的话从首地址开始的确是正序的了,吸取经验,以后要是不确定是不是反序就直接双击跟踪看内存即可。
v3[1] = (__int64)"pG`imos";
v3[2] = (__int64)"ewUglpt";
for ( i = 0; i <= 11; ++i )
{
if ( *(char *)(v3[i % 3] + 2 * (i / 3)) - *(char *)(i + a1) != 1 ) //这里犯下第三个错误,一开始没看见最左边的取地址符*的范围是一整个(char *)(v3[i % 3] + 2 * (i / 3)),搞到脚本编写出来障碍,这里应该这样理解,(char *)(v3[i % 3]取这v3[0]、v3[1]、v3[2]、中的第几个完整数组,+ 2 * (i / 3)是为了在确定的v3[0]、v3[1]、v3[2]中继续深入取对应数组的字符进行操作,这里的逆向逻辑也简单,就是*(char *)(v3[i % 3] + 2 * (i / 3)) - 1 = *(char *)(i + a1)
return 1LL;
}
return 0LL;
}
分析完毕,脚本:
key1="Dufhbmf"
key2="pG`imos"
key3="ewUglpt"
flag=""
key4=[key1,key2,key3]
for i in range(12):
flag+=chr(ord(key4[i%3][(2*int(i/3))]) -1)
print(flag)
攻防世界EasyRE:(栈地址连续小字符串变量、栈中过渡变量反序字符串、/x7f截断字符串、运算符优先级注意)
64位ELF文件,无壳,照例扔入IDA64中查看信息,有Main函数就看main函数:(PS:下面被我注释了一下内容,不过不影响)
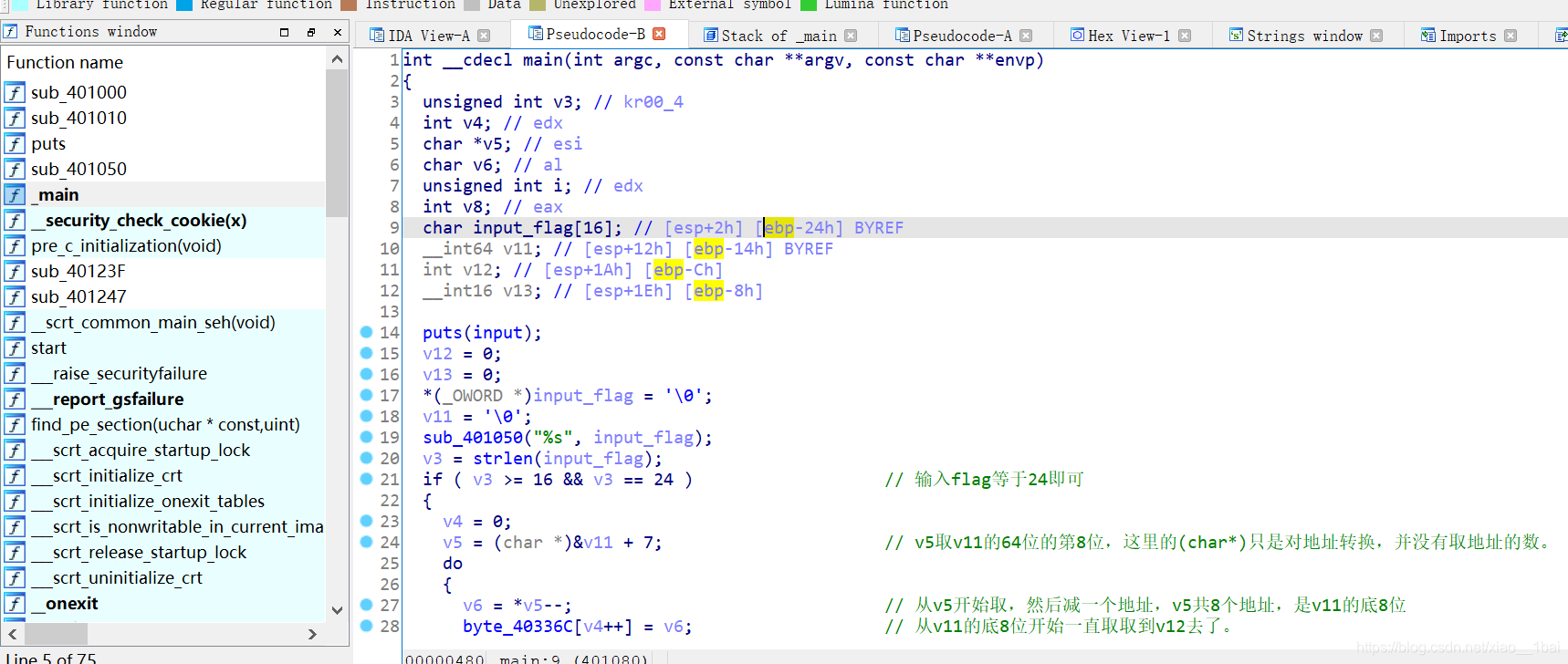
照例分析代码:
puts(input); //这里名称被我重命名过,判断依据是程序运行时的Input字符串在这里被引用,所以这里是输出函数
v12 = 0;
v13 = 0;
*(_OWORD *)input_flag = '\0';
v11 = '\0';
sub_401050("%s", input_flag);
v3 = strlen(input_flag);
if ( v3 >= 16 && v3 == 24 ) // 这里两个条件其实是多余的,输入flag等于24即可
{
v4 = 0;
v5 = (char *)&v11 + 7; // v5取v11的64位地址下面的7位地址处,这里的(char*)只是对地址转换,并没有取地址的数,也就是说v5还是地址,而且是以char类型8位为单位的地址。而且后7位刚好是input_flag开始的24个字节范围的末尾,就是我们输入24字节flag的最后一个。(一个字符8位)
PS:这里之所以是v11地址的下面7位处是因为这是在main函数内的栈,栈是从下到上的(从高地址到底地址),栈变量都是从第一个分配地址往下划分内存的,后面会再讲~
do
{
v6 = *v5--; // 从v5开始取,然后减一个地址(一次减8位),v5现在是input_flag的起始地址开始的24字节的末尾指针了,也就是指向用户输入字符串的最后一个字符,这里循环24次,符合前面我们输入input_flag长度为24的判断条件。
byte_40336C[v4++] = v6; //这里把v6的值也就是我们inpu_flag末尾位置的值开始,一个个赋值给v4开头,这就造成了v4是我们输入24位flag的反向字符,后续对v4数组操作也是对用户输入的24字符flag的反向操作。
}
while ( v4 < 24 );
for ( i = 0; i < 24; ++i )
byte_40336C[i] = (byte_40336C[i] + 1) ^ 6;// 赋完值之后有对自身进行异或操作,进一步修改,注意这里是我们输入的24位字符的反向数组
v8 = strcmp(byte_40336C, aXircjR2twsv3pt); // 异或完后简单的比较,aXircjR2twsv3pt双击跟踪后一个被/x7f截断的字符串,前18位是xIrCj~<r|2tWsv3PtI,发现不满足24位后再查看才发现后面还有,第19位是/x7f,20~24是zndka。这里留个心眼,/x7f可以阻断字符串
if ( v8 )
v8 = v8 < 0 ? -1 : 1;
if ( !v8 )
{
puts("right\n");
system("pause");
}
}
return 0;
}
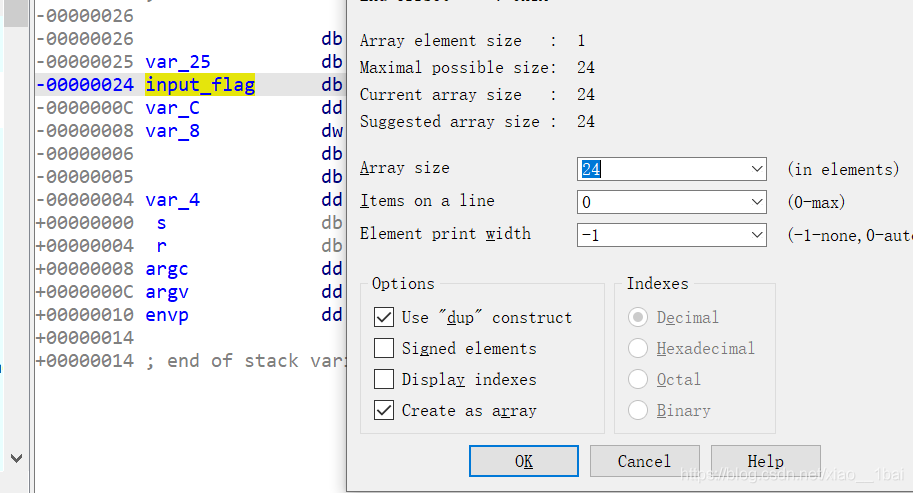
分析完了,附上图回顾一下以前犯错的思路,给自己日后提个醒:
犯下第一个错误是对关键数组地址修改的地方不敏感,一开始我只看到了对v4数组异或的代码,没有注意到前面的反序操作:
for ( i = 0; i < 24; ++i )
byte_81336C[i] = (byte_81336C[i] + 1) ^ 6;
结果逆向逻辑出来后的flag是反的,大概长这样:}NsDkw9sy3qPto4UqNx{galf,可能还是能看出来是反的flag,单要是换其他字符串就不一定了。所以我们应该要注意前面还有对v4操作的代码,也要分析:(分析在前面)
if ( v3 >= 16 && v3 == 24 )
{
v4 = 0;
v5 = (char *)&v11 + 7;
do
{
v6 = *v5--;
byte_81336C[v4++] = v6;
}
while ( v4 < 24 );
犯下第二个错误就是对栈不熟练,就是基于对前面v4数组操作的分析,才发现这里有个栈操作让v4数组反向获取用户输入的字符串:
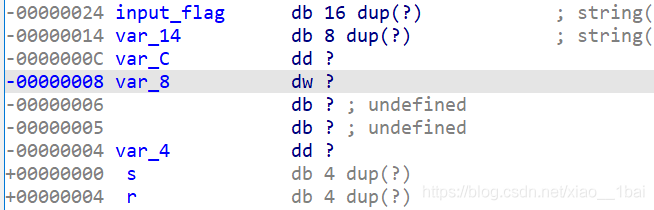
之前在IDA权威指南中了解过栈视图,这里v11是var_14,input_flag就是我们输入24位字符串的首地址,这里给了一个混淆就是v11,前面v5 = (char *)&v11 + 7;就是在v11地址往下取7位char类型,就是0D地址了,刚好在var_C前面。
input_flag首地址24到var_C前面0D处就是完整的24位input_flag地址,所以v5就是取input_flag最后一个字符,这里v11的过渡作用混淆了我,我们可以直接在栈中把v11删除,改input_flag为24位字符串,这里也就解释了v4数组取input_flag反向字符的原因了:
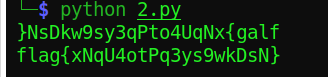
犯下第三个错误是在写脚本中发现的,减号的优先级高于^符号:
下面脚本中 flag+=chr((ord(data[i]) ^ 6)-1) #要是写成chr((ord(data[i]) ^ 6 - 1)那就GG了,由于优先级不同所以结果会不同,给的警示是最好什么都用括号括起来,毕竟这种优先级问题是很难发现的,还以为是自己逻辑梳理错误呢。
data="xIrCj~<r|2tWsv3PtI\x7Fzndka"
flag=""
for i in range(24):
flag+=chr((ord(data[i])^6)-1)
print(flag)
print(flag[::-1])
结果:
攻防世界re-for-50-plz-50:
32位ELF文件,无壳,照例扔入IDA32中查看伪代码,有main函数看main函数:(图中有点注释。不过不影响)
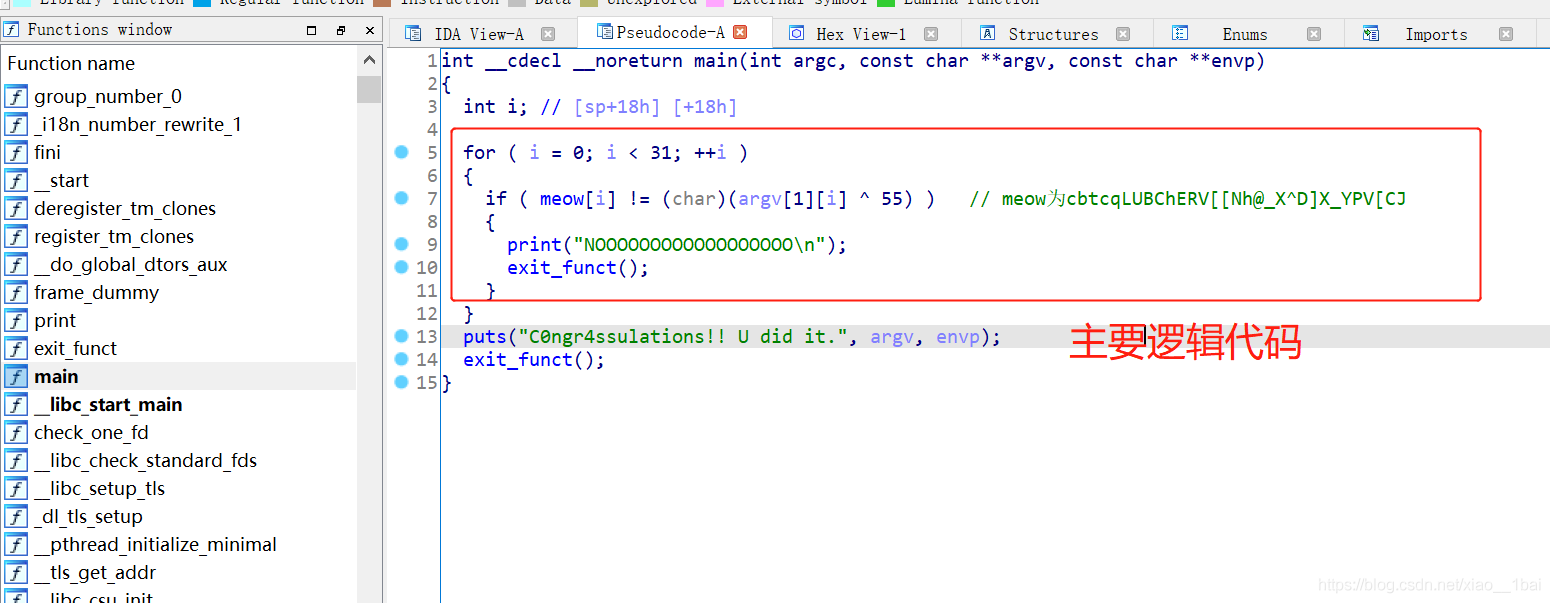
meow双击跟踪是cbtcqLUBChERV[[Nh@_X^D]X_YPV[CJ ,右边 argv[ 1 ][ i ]是命令行传入的参数:(下面是我以前的笔记)
int main( int argc, char *argv[] ) :
(还可以写成int main( int test_argc, char *test_argv[] ) )
调用时:
$./a.out testing1 testing2
应当指出的是,argv[0] 存储程序的名称,argv[1] 是一个指向第一个命令行参数的指针,*argv[n] 是最后一个参数。如果没有提供任何参数,argc 将为 1,否则,如果传递了一个参数,argc 将被设置为 2。
所以逻辑很简单,就是传入参数后异或的值与本身存在的数组比较,也就是说题目类型是与用户输入相关的非存储型flag:
key1="cbtcqLUBChERV[[Nh@_X^D]X_YPV[CJ"
flag=""
for i in range(len(key1)):
flag+=chr(ord(key1[i])^55)
print(flag)
![]()
攻防世界IgniteMe:(函数逻辑封装、大小写字符转换算法)
32位windows文件,无壳,照例扔入IDA32中查看伪代码信息,有Mian函数看Main:
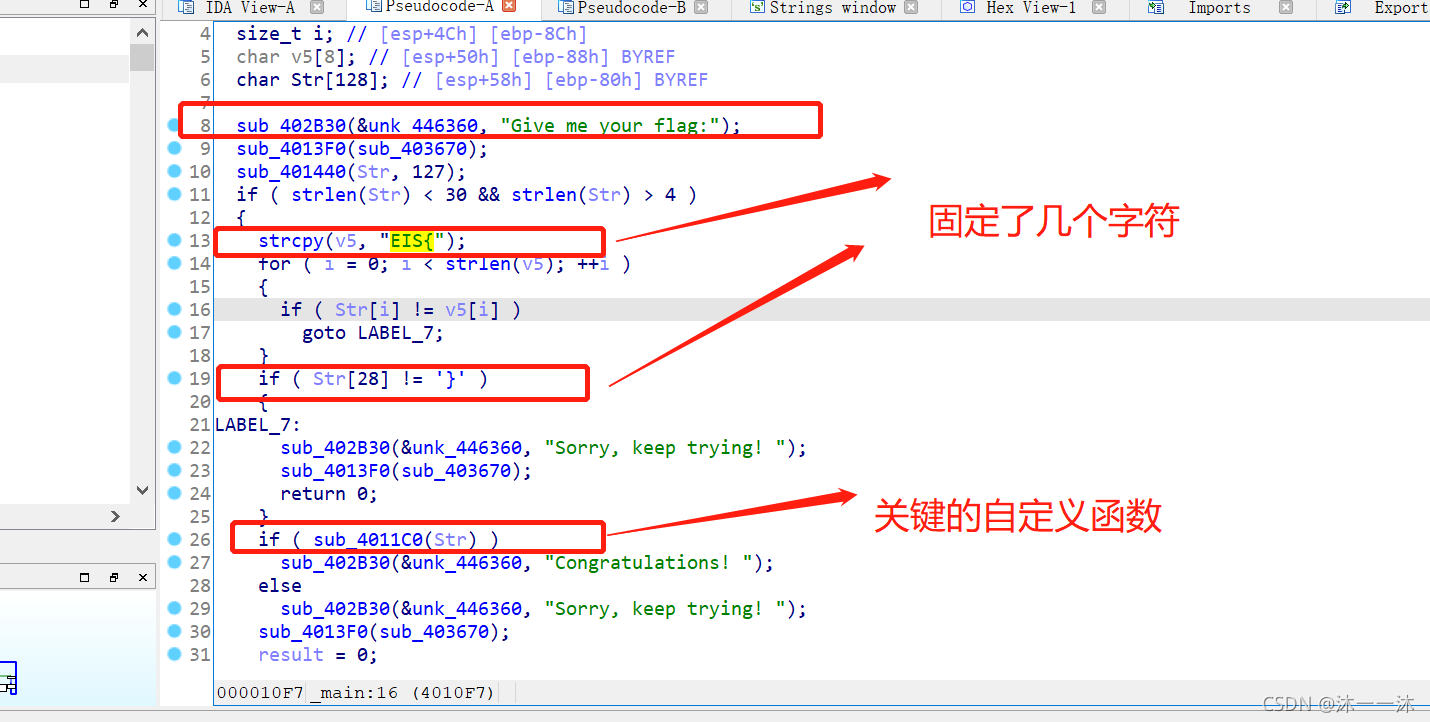
由初始信息可以知道,前4个是EIS{ ,最后一个是 },判断函数在 if 那里,双击跟踪sub_4011C0(Str)函数:
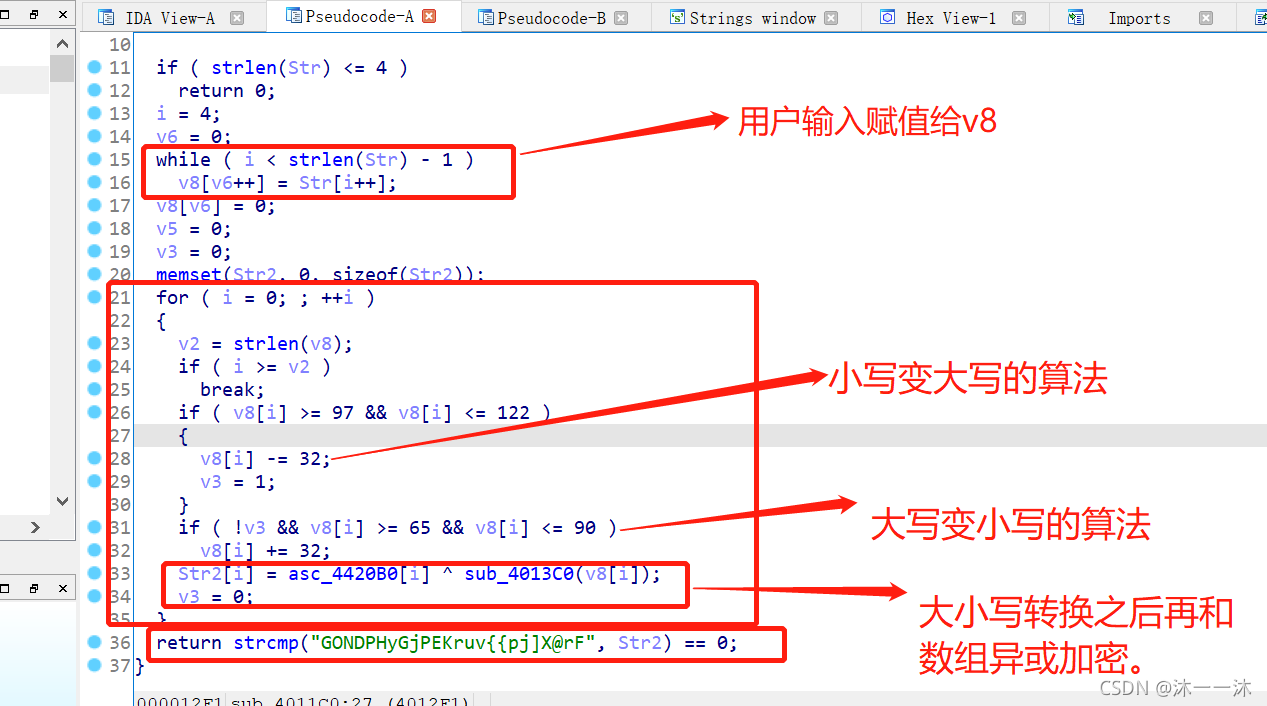
可以看到结果字符串有了,是GONDPHyGjPEKruv{{pj]X@rF,逆向逻辑有了,是简单的一次循环加判断,这里注意一下不带花括号的判断是只判断紧接着的下一条语句而已。
最后这里Str2[i] = asc_4420B0[i] ^ sub_4013C0(v8[i]);用到了asc_4420B0[i]数组来异或,在IDA中嵌入脚本打印一下:
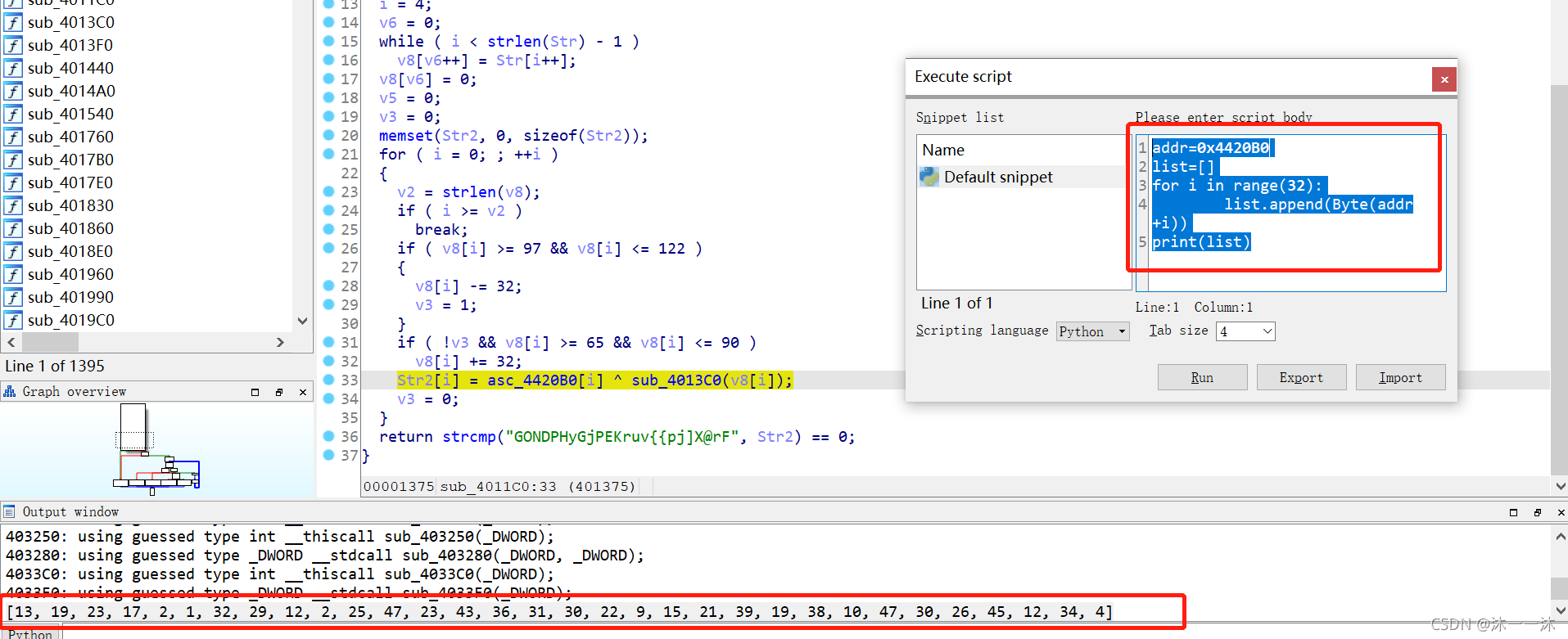
写逆向逻辑脚本:
key1="GONDPHyGjPEKruv{{pj]X@rF"
list1=[13, 19, 23, 17, 2, 1, 32, 29, 12, 2, 25, 47, 23, 43, 36, 31, 30, 22, 9, 15, 21, 39, 19, 38, 10, 47, 30, 26, 45, 12, 34, 4]
flag=[]
v3=0
for i in range(len(key1)):
flag.append(((ord(key1[i])^list1[i])-72)^85)
if flag[i] >= 65 and flag[i] <= 90:
flag[i]+=32
elif flag[i] >= 97 and flag[i] <=122:
flag[i]-=32
print(''.join([chr(i) for i in flag]))
print(len(''.join([chr(i) for i in flag]))) #也可以用map(chr,flag)递归装换成字符
main函数与迷宫结合类型:
攻防世界maze:(高低位分割数、函数逻辑封装、迷宫结合)
64位ELF文件,无壳,先扔入IDA中查看伪代码:
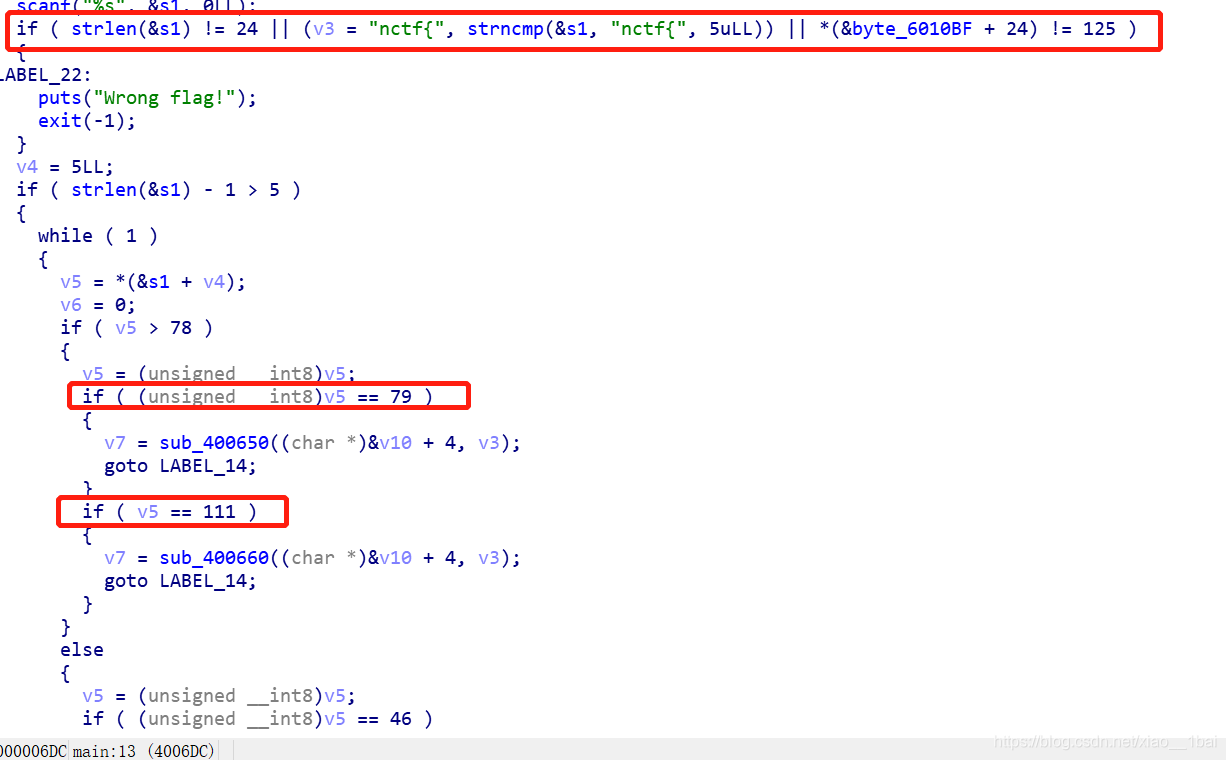
从这里犯下第一个错误,我竟然对第一个判断语句的!=125的125不知所云,还去查了ASCII表,对后面的79,46这些竟然也想查。真的得给自己个一巴掌,flag基本都是字符和数字混合,而且在IDA里数字转ASCII字符直接快捷键R啊!!!!
然后判断题目类型是本身就有的存储型flag还是用用户输入一个个生成的生成型flag。答案是后者,那gdb调试就没法用了,直接静态分析代码即可。
转了字符后基本就明白了,现在开始代码分析了:
puts("Input flag:");
scanf("%s", &input_flag, 0LL);
if ( strlen(&input_flag) != 24 || strncmp(&input_flag, "nctf{", 5uLL) || *(&byte_6010BF + 24) != '}' ) //这里要求输入的flag是24个字符,且前5个和最后一个都确定了,一开始的125真的搞得我都不知道啥意思。后面的Oo.0也是如此
{
LABEL_22:
puts("Wrong flag!");
exit(-1);
}
v3 = 5LL;
if ( strlen(&input_flag) - 1 > 5 )
{
while ( 1 )
{
singleflag = *(&input_flag + v3); // 这里v3是从5开始递增的数,目的是从第5个字符开始判断是否符合下述条件
v5 = 0;
if ( singleflag > 78 ) //这里给个范围,ASCII码大于78的划为第一类
{
singleflag = (unsigned __int8)singleflag;
if ( (unsigned __int8)singleflag == 'O' ) //如果第一个取O
{
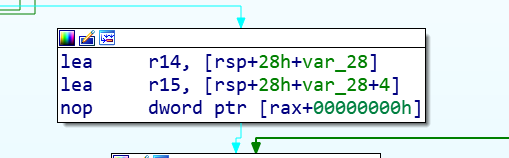
v6 = sub_400650((_DWORD *)&v9 + 1); // 这里犯下第二个错误,64位的v9分成取高底32字节其实是分到r14和r15两个寄存器的,底32位在r14,高32位在r15才有后面根据寄存器的分开操作,因为在两个不同寄存器中。
goto LABEL_14;
}
if ( singleflag == 'o' )//如果第一个取o
{
v6 = sub_400660((int *)&v9 + 1); // 有符号32位高字节操作,r15寄存器,_DWORD就是int就是32位。
goto LABEL_14;
}
}
else
{
singleflag = (unsigned __int8)singleflag;
if ( (unsigned __int8)singleflag == '.' )//如果取到.
{
v6 = sub_400670(&v9); // 无符号底字节32位操作,r14寄存器
goto LABEL_14;
}
if ( singleflag == '0' )
{
v6 = sub_400680((int *)&v9); // 有符号底字节32位,r14寄存器
LABEL_14:
v5 = v6;
goto LABEL_15;
}
}
LABEL_15:
if ( !(unsigned __int8)sub_400690((__int64)asc_601060, SHIDWORD(v9), v9) )
goto LABEL_22;
if ( ++v3 >= strlen(&input_flag) - 1 ) //在flag范围内v3加1,对应前面singleflag取第6、7、8~个一个个比较
{
if ( v5 ) //如果flag取完了,且sub_这些函数没有返回flase,也就是没有越界,就可以判断是否抵达终点了
break;
LABEL_20:
v7 = "Wrong flag!";
goto LABEL_21;
}
}
}
if ( asc_601060[8 * (signed int)v9 + SHIDWORD(v9)] != '#' ) //判断是否为#这个终点。
goto LABEL_20;
v7 = "Congratulations!";
LABEL_21:
puts(v7);
return 0LL;
}
第二个错误看IDA反汇编结构图,底双字在r14寄存器,高双字在r15寄存器:
这里犯下的第三个错误就是对sub_400650、sub_400660、sub_400670、sub_400680、sub_400690、asc_601060、这些IDA自己命名的函数不敢去看!总是觉得自己看不懂,害怕!!!后来才发现其实不应该害怕的!!要逼自己一把!!!
bool __fastcall sub_400650(_DWORD *a1)
{
int v1; // eax
v1 = (*a1)--;
return v1 > 0;
}
bool __fastcall sub_400660(int *a1)
{
int v1; // eax
v1 = *a1 + 1;
*a1 = v1;
return v1 < 8;
}
bool __fastcall sub_400670(_DWORD *a1)
{
int v1; // eax
v1 = (*a1)--;
return v1 > 0;
}
bool __fastcall sub_400680(int *a1)
{
int v1; // eax
v1 = *a1 + 1;
*a1 = v1;
return v1 < 8;
}
这四个函数点开之后是对传入参数+1 -1操作而已,真的不难,而且附带返回的比较后来查资料说是判断有没有越出迷宫边界,false就是越出了,就不用玩了,为true就是没越出,继续玩。
(unsigned __int8)sub_400690((__int64)asc_601060, SHIDWORD(v9), v9) //主函数中的样式
__int64 __fastcall sub_400690(__int64 a1, int a2, int a3) //双击后中的函数样式
{
__int64 result; // rax
result = *(unsigned __int8 *)(a1 + a2 + 8LL * a3);
LOBYTE(result) = (_DWORD)result == ' ' || (_DWORD)result == '#';
return result;
}

这里sub_400690点进去分析后的(__int64)asc_601060如图是一串字符串,后来知道了是迷宫的图,sub_400690函数里传入v9的有符号高双字r15寄存器,和v9底双字的r14寄存器,然后运算表达式result = *(unsigned __int8 )(a1 + a2 + 8LL * a3); 就是在asc_601060字符串数组内取字符而已。
可以看出a3*8,所以这是8个字符为一行,也就是说r14寄存器的底双字表示行,r15高双字表示列,+1-1分别对应着向上向下,向左向右移动。(因为这里把2维的迷宫平铺成1维了,所以向上向下走要变*8才行)
O是左移,o是右移,0是下移,.是上移
所以这里可以写出asc_601060的迷宫图形:
******
* * *
*** * **
** * **
* *# *
** *** *
** *
********
现在分析最后一段:
这里就是看最后跳出的flag末尾时是不是到了#这个字符,如果是就表示通关。
所以是:右下右右下下左下下下右右右右上上左左
就是o0oo00O000oooo…OO
main函数与游戏结合类型:
攻防世界gametime:(游戏通关生成flag、)
32位无壳,运行一下程序看看主要信息:
说实话我一开始没看懂怎么玩,所以扔入IDA32中查看伪代码信息,有main函数看Main函数:
哇,眼花缭乱,代码太多了。
这里积累第一个经验,游戏题一定要玩懂才行:
没那么难玩的,如果游戏文字跳转太快看不清,很难玩,就看着反汇编代码来玩。用OD等动态调试器在游戏结束时保持最后界面,以此来用最后结束时的界面信息根据伪代码判断在哪里退出的,从而找到第一个判断函数。
上OD动态调试:
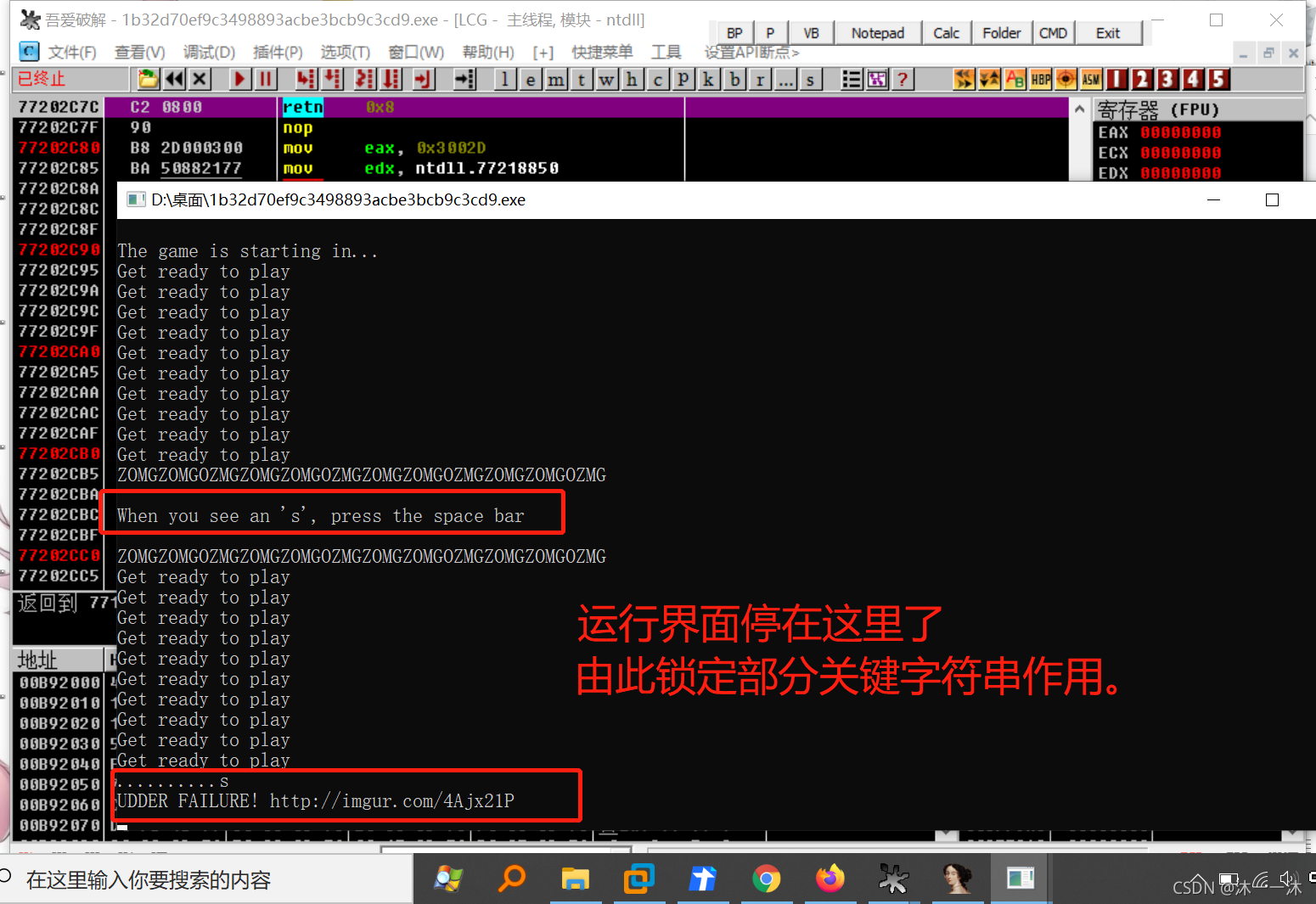
终于可以看清游戏规则了,出现s就按空格,不然就退出:(后面还有按x和m的),在IDA伪代码中查看对应信息:

结合刚才结束界面的回显信息,进一步缩小了判断函数的范围。
然后这里积累第二个经验:
游戏类题目,有些是存储型flag,就是flag本来就在那里,你解出游戏就会显示。而有一些是与用户输入相关的生成型flag,就是用户通关的每一步影响着flag的生成,比如通一关给一部分flag这样。
这道题明显是后者,但是生成型flag中又要看输入到底怎么影响flag生成,如果是那种以通关数生成flag的话,我们改一下判断条件就可以全部通关了。但如果是那种通关的时候要靠用户输入字符,并考输入的对应字符来生成甚至是加密后再生成一部分flag的话,这种题就要一个个找到对应的通关字符然后再逆向逻辑才行。
而这题比较简单,是只判断通关数即可生成flag,为什么我会知道呢,其实我猜的。(笑~) 所以我们用OD修改判断条件即可。
看判断函数的反汇编代码:
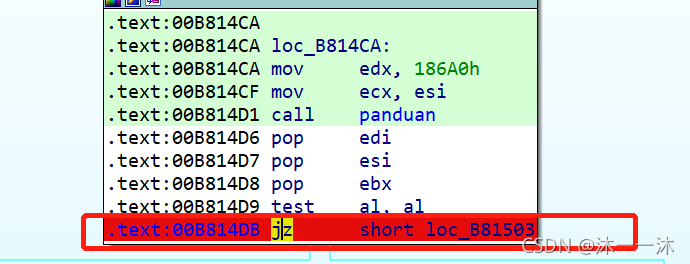
在OD中修改对应内存地址的反汇编代码,你也可以直接用IDA修补反汇编代码调试:

前面一切正常,因为但是后面出了问题:
前面正常是因为下面三个都是同一个判断函数:
后面出错就去后面找,发现还有三个判断函数:
老样子双击跟踪找汇编代码:
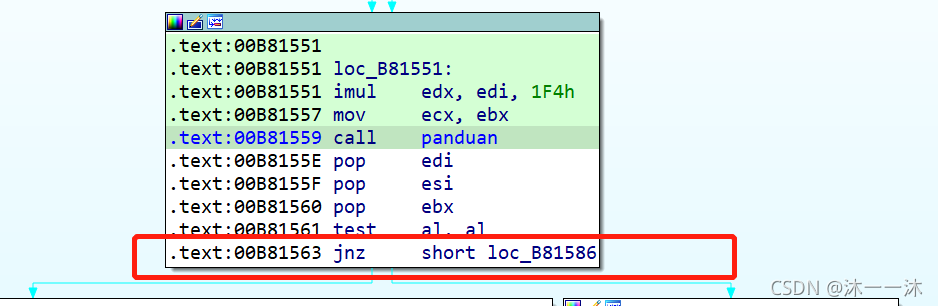
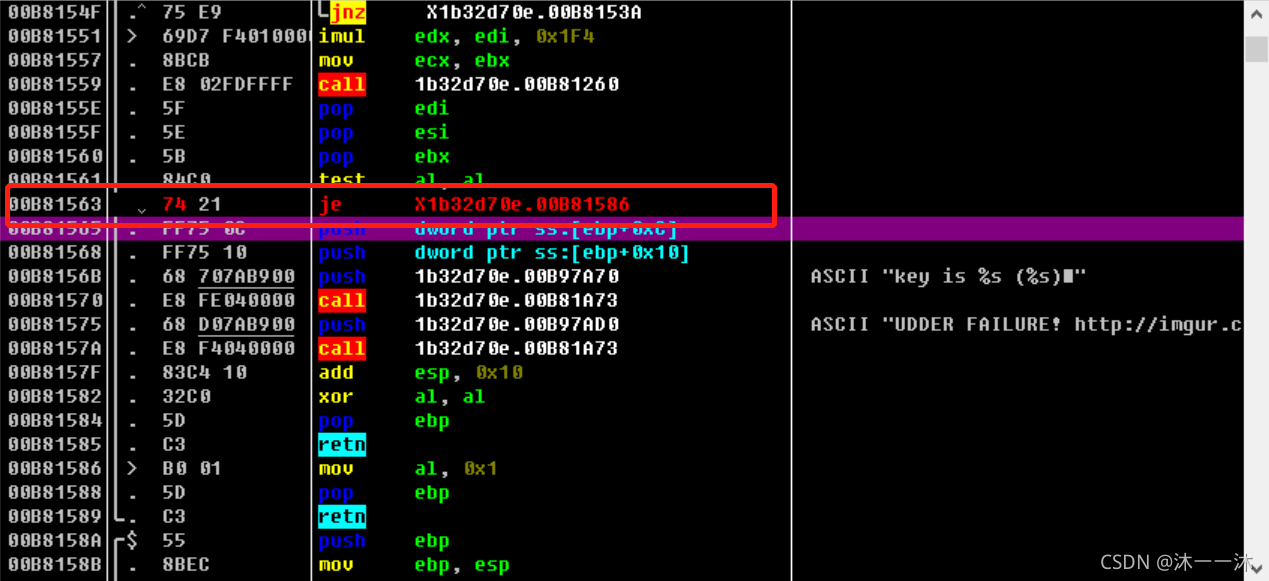
继续运行程序,成功输出:
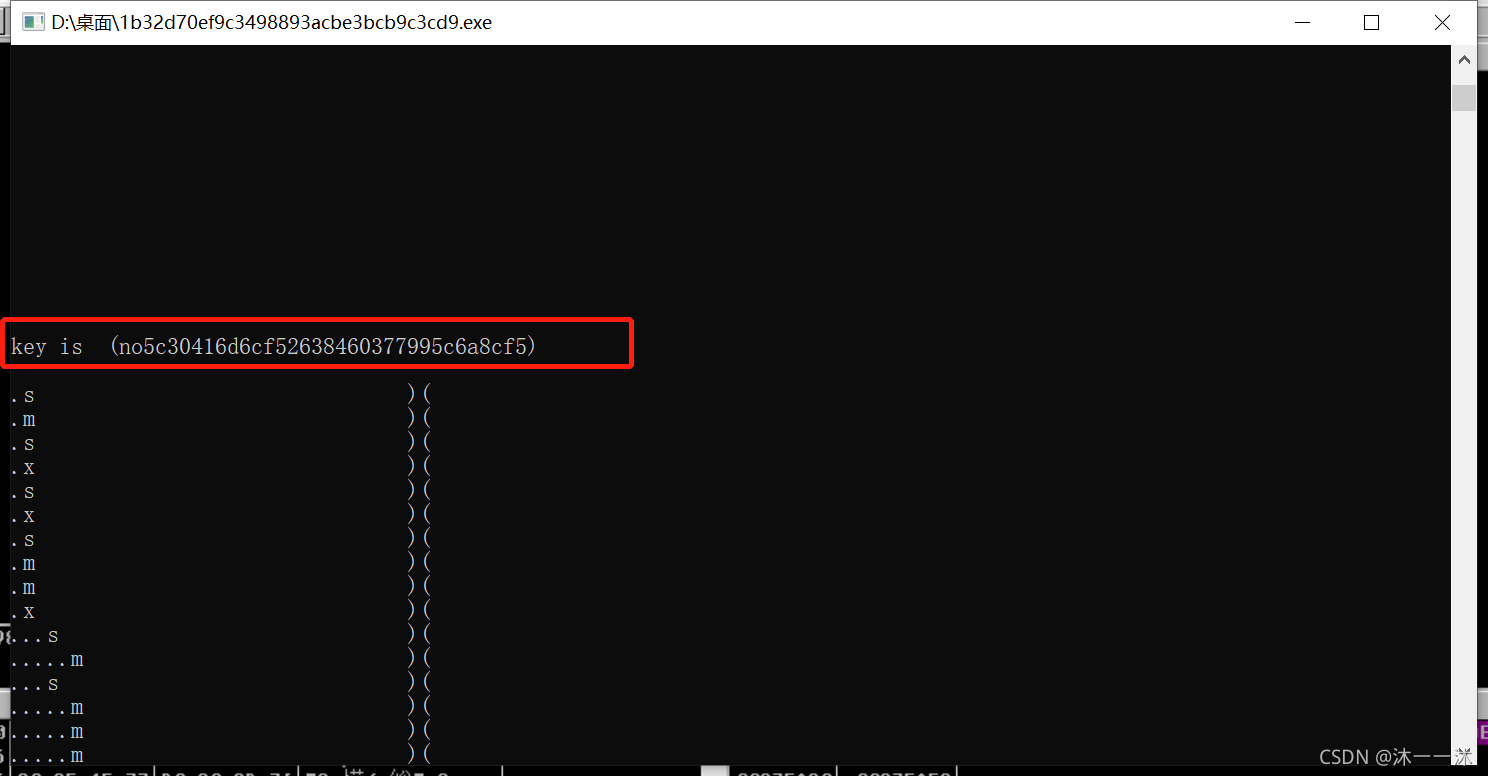
main函数与数学算法结合:
攻防世界notsequence:(杨辉三角算法、函数逻辑封装、IDA对char型(byte)的4*计数)
无壳,32位ELF文件,照例扔入32位IDA中查看伪代码,有Main函数看main函数:
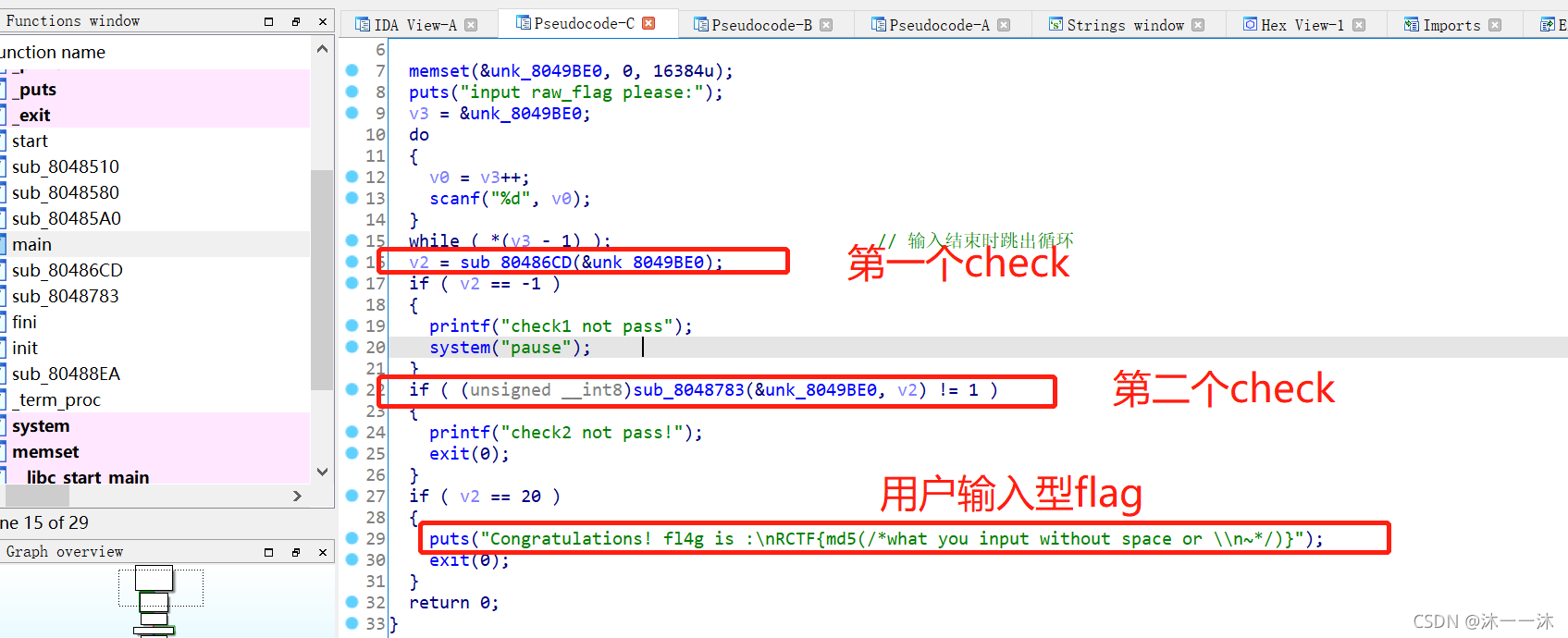
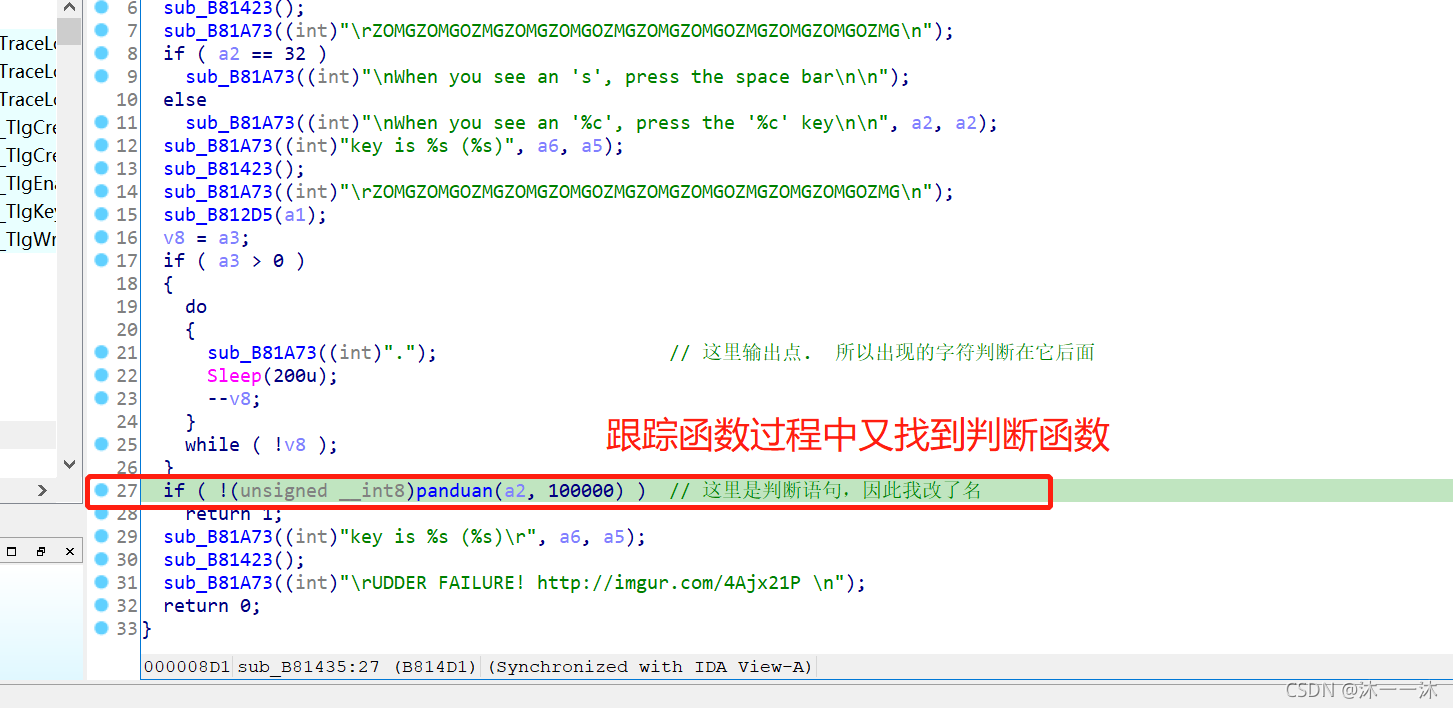
题型是与用户输入有关的生成型flag,逻辑是经过两个check,分析第一个check函数v2 = sub_80486CD(&unk_8049B
E0):
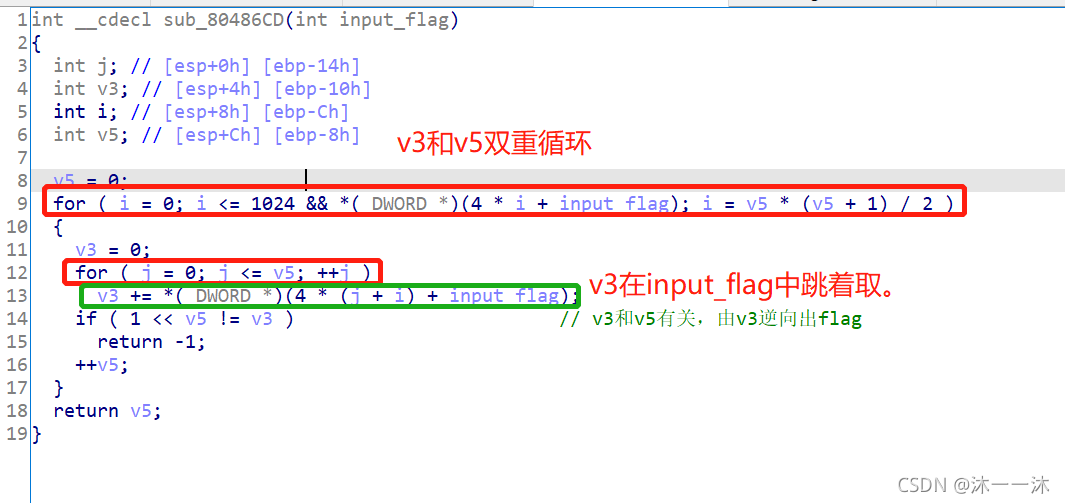
这里一开始我没看懂,按照反向逆向逻辑来看双重循环的话我得知道v5的值,但是这里并没有,所以我在主函数处发现了v2=20,但是又不确定v2在第二个check函数里有没有改变过,结果是没有。
所以v5=v2=20,有了v5的值就可以进行反向第一个check中双层循环中的 for ( j = 0; j <= v5; ++j )循环了。

可是之后我还是逆向不了,我知道v3的个数和v5一样,可是v3 += *(_DWORD *)(4 * (j + i) + input_flag)这句代码标识v3是在input_flag中跳着取的啊,那这个逻辑逆向起来就相当麻烦了,我不会。(哭~)
查了资料才发现这是杨辉三角,算法逆向题,没办法,只能跟着wp走了,并附上我自己的见解:
首先这里积累第一个经验,附上杨辉三角解析:
[1] #0 /1 |2^0=1
[1, 1] #1 /2 |2^1=2
[1, 2, 1] #3 /3 |2^2=4
[1, 3, 3, 1] #6 /4 |2^3=8
[1, 4, 6, 4, 1] #10 /5 |2^4=16
[1, 5, 10, 10, 5, 1]
[1, 6, 15, 20, 15, 6, 1]
[1, 7, 21, 35, 35, 21, 7, 1]
[1, 8, 28, 56, 70, 56, 28, 8, 1]
[1, 9, 36, 84, 126, 126, 84, 36, 9, 1]
[1, 10, 45, 120, 210, 252, 210, 120, 45, 10, 1]
.
.
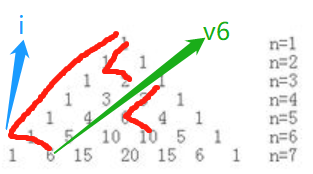
这样来看杨辉三角第一批特征:(n是行号且从0开始)
(1)最左边代表行号,0就是第0行。(行号从0开始)
(2)第1个字符在数组(第一行到当前行组成的数组)中的位置,#后的数字。(n*(n+1)/2,n是行号且从0开始)
(3)一行的有几个数字 /后的内容。(n+1,n是行号从0开始)
(4)整行的和。|后的内容,是2的行号次方。(2^n,n是行号且从0开始)
.
.

.
.
这样来看杨辉三角第二批特征:
第n行数字的和为2^(n) ,行号从0开始
1=2^(0-0), 1+1=2^(1-0), 1+2+1=2^(2-0), 1+3+3+1=2^(3-0) ,1+4+6+4+1=2^(4-0), 1+5+10+10+5+1=2^(5-0)。
.
.
斜线上数字的和等于其向左(从左上方到右下方的斜线),拐角上的数字。(在图中以用红线标好)
1+1=2,1+1+1=3,1+1+1+1=4,1+2=3,1+2+3=6,1+2+3+4=10,1+3=4,1+3+6=10,1+4=5
接下来重新分析check1函数代码:(考察杨辉三角第二批特性中的第n行数字和)
这段代码check1函数的作用是检测每一行求和结果是否为2^k(k从0开始),可以抽象成一个二维结构,有[k] 行(第一行k=0),每行开头为第k*(k+1)/2个数。
int __cdecl sub_80486CD(int input_flag)
{
int j; // [esp+0h] [ebp-14h]
int v3; // [esp+4h] [ebp-10h]
int i; // [esp+8h] [ebp-Ch]
int v5; // [esp+Ch] [ebp-8h]
v5 = 0; //这里积累第二个经验:通过v5的0、1、2、3……然后退出循环中 i 表达式的前几个值0、1、3、6、10……可以发现问题,因为这不是遍历或者有规律的遍历(每次检查第四个),而且v5 * (v5 + 1) / 2 是等差数列的公式,结合前面的逻辑逆向麻烦性,由此要知道考的是算法。
for ( i = 0; i <= 1024 && *(_DWORD *)(4 * i + input_flag); i = v5 * (v5 + 1) / 2 ) //等差数列公式 i,这里4*i应该只是为了迎合int类型,IDA可能默认i是char的byte类型了。
{
v3 = 0;
for ( j = 0; j <= v5; ++j ) //这里积累第三个经验:在杨辉三角那里,每一行的数的总和等于2的以该行号的次方,行号从0开始算起。
v3 += *(_DWORD *)(4 * (j + i) + input_flag);
if ( 1 << v5 != v3 ) // 所以这里v5是行上数的个数,这里1 << v5就表示2的v5次方,就是2的行号次方(从0开始)。 v3 += *(_DWORD *)(4 * (j + i) + input_flag)中i是v5行前的杨辉三角的个数,因为我们是一维排列杨辉三角的,所以只能用(4 * (j + i)这种表达式来遍历第v5行上的v5+1个数(杨辉三角行从0开始!),这里4*i应该只是为了迎合int类型,IDA可能默认i是char的byte类型了。
return -1;
++v5; //v5的0、1、2、3,是杨辉三角对应行上的个数,递增数列。
}
return v5;
}
接着分析check2函数的代码:(考察杨辉三角第二批特性中的斜线上的数字和)
int __cdecl sub_8048783(int input_flag, int k_20)
{
int v3; // [esp+10h] [ebp-10h]
int v4; // [esp+14h] [ebp-Ch]
int i; // [esp+18h] [ebp-8h]
int v6; // [esp+1Ch] [ebp-4h]
v6 = 0;
for ( i = 1; i < k_20; ++i ) //这里i总0、1、2……这样连续递增
{
v4 = 0;
v3 = i - 1; //这里v3从0、1、2、这样连续递增,
if ( !*(_DWORD *)(4 * i + input_flag) ) //这里4*i应该只是为了迎合int类型,IDA可能默认i是char的byte类型了。
return 0;
while ( k_20 - 1 > v3 )
{
v4 += *(_DWORD *)(4 * (v3 * (v3 + 1) / 2 + v6) + input_flag); //这里积累第四个经验:这里等差数列表达式v3 * (v3 + 1) / 2前面说过了,是杨辉三角的第一批特征中第N行前面的个数,v6从0开始递增,表示取杨辉三角v3行的v6列的值,而在这个循环中v3是变换的,也就是取得杨辉三角的行是变化的,而v6在此一个该循环中是固定的,所以可以看成是取每一行(v3)的同一个列(v6)
++v3;
}
if ( *(_DWORD *)(4 * (v3 * (v3 + 1) / 2 + i) + input_flag) != v4 ) //这里由于前面循环++v3后表明行号向下了一行,而 i 从1开始,v6从0开始,所以 i 永远比 v6大1,v6 比 i 多一列。所以这里可以看作[0]-[k-1]行的 [v6] 列求和等于[k]行的 [i]
return 0;
++v6;
}
return 1;
}
所以答案很明显了,是杨辉三角的前20行就是答案,这里积累第5个经验,写杨辉三角生成脚本:(代码标注很详细了,希望对自己日后有帮助!)
def triangles():
s=[1] #这里s[1]作为杨辉三角函数起始值
while True: #无限循环生成杨辉三角
yield s #每次返回一行的杨辉三角列表
s.append(0) #给杨辉三角下一列扩充一个数的空间,因为每一行比上一行多1个
s=[s[i-1]+s[i] for i in range(len(s))] #覆盖生成杨辉三角行列表,满足杨辉三角的下一行的第n个数等于上一行的第n和n-1的和
n=0 #设置计数器,因为只打印前20行
flag=''
for i in triangles(): #每次获取从triangels函数的yield返回的一行列表
#print(i) #打印每一行杨辉三角
flag+=''.join(map(str,i)) #返回通过指定字符连接序列中元素后生成的新字符串,以str为间隔,默认为逗号。而列表就是逗号间隔的
n+=1
if n==20:
break
import hashlib
flag=hashlib.md5(flag.encode()).hexdigest() #这里把flag的列表流变成了字节流,就去掉了列表保留了每个元素了,然后直接加密
print("RCTF{"+flag+"}")
结果:

main函数中嵌入大量冗余代码,拆分代码混淆:
攻防世界Newbie_calculations:(非预期行为、不能直接运行、题目描述暗示、栈地址连续小数组、c语言写脚本、不同系统的特殊数、负数作循环条件)
32位无壳,照例扔入IDA32中查看信息:

浮上眼前的是一堆自定义函数,而且数量很多,吓傻了,快速浏览并随便点进函数看来一下,函数代码还多,以为是混淆,但是又想不出是什么混淆。
运行程序看一下:
输入也输入不了,还以为是程序的什么限制,更慌了,后来查了资料才决定定下心来好好分析。
首先回顾一下以前积累的经验:
复杂代码本质应该是简洁的,这样才叫出题。
仔细一看,发现繁多的代码结果只有三个函数,sub_401100函数、sub_401000函数、sub_401220函数。
加上运行程序时输入不了不是因为程序有问题,每一个意料之外的事情都有它存在的道理和过程,不要总是怀疑题目本身。繁多的代码和巨大的数字大概率是有很多没用的冗余代码占用了程序运行的时间,才导致没有光标可以输入。
最后一行代码应该就是前面运行完后输出的flag:
该伪代码中没有输入,时间到了就会输出flag,但是要修改前面的无用代码。题目是Newbie_calculations,这种题目暗示要注意,表示往运算方面去想函数。
现在开始重新分析,从最开头的显示字符串开始:

分析第一个sub_401100函数:(这里传入参数被我改名了,简单的传入参数相乘)
_DWORD *__cdecl sub_401100(_DWORD *v120, int _1000000000) //返回v120,故只看对v120的操作
{
int v3; // [esp+Ch] [ebp-1Ch]
int v4; // [esp+14h] [ebp-14h]
int v5; // [esp+18h] [ebp-10h]
int v6; // [esp+18h] [ebp-10h]
int v7; // [esp+1Ch] [ebp-Ch]
int v8; // [esp+20h] [ebp-8h] BYREF
v4 = *v120;
v5 = _1000000000;
v3 = -1;
v8 = 0;
v7 = _1000000000 * v4;
while ( _1000000000 ) //这里积累第一个经验:虽然这里循环1000000000次,但是程序返回的是v120,这里有很多和v120没有关系的其它变量,是用来混淆的,找与v120有关的才是关键。
{
v6 = v7 * v4;
sub_401000(&v8, *v120); //由下面代码知道这是一个相加函数,初始值v8=0,循环1000000000次就是1000000000个v120相加,就是v120 * 1000000000 ,就是传入参数a1*a2结果赋值给第一个参数a1。
++v7;
--_1000000000; //其它的与v120无关的不用看它
v5 = v6 - 1;
}
while ( v3 ) //这里v3=-1,负数循环,这里本来要循环FFFFFFFF,就是100000000 - 1次的,但是后面有*v120=v8的赋值操作,所以这部分也是冗余混淆代码。
{
++v7;
++*v120;
--v3;
--v5;
}
++*v120;
*v120 = v8; //这里最后是赋值v8给v120,所以while(v3)循环根本不用管,前面说过这些和v120没有关系的变量是用来混淆的,不用管。
return v120;
}
分析第二个函数 sub_401000,这也是上面的嵌套函数:(简单的传入参数相加)
_DWORD *__cdecl sub_401000(_DWORD *a1, int a2) //返回a1,故只看对a1的操作
{
int v3; // [esp+Ch] [ebp-18h]
int v4; // [esp+10h] [ebp-14h]
int v5; // [esp+18h] [ebp-Ch]
int v6; // [esp+1Ch] [ebp-8h]
v4 = -1;
v3 = -1 - a2 + 1; //v3=-a2
v6 = 1231;
v5 = a2 + 1231;
while ( v3 ) //这里积累第二个经验:负数做循环条件的知识,v3=-a2,然后在循环体里又--v3,一开始我也以为是死循环,因为0才是false。但是查了资料后说在32位里 -1 就是 FFFFFFFF,就是100000000 - 1。所以这一下子就转正了!所以如果while(-1)就循环100000000 - 1次,这里while(-a2),所以就循环100000000 - a2次。
{
++v6;
--*a1; //同样的返回a1我们只关注a1即可,这个循环100000000 - a2次,每次a1-1,所以a1变成a1=a1-(100000000 - a2)
--v3;
--v5;
}
while ( v4 ) //这里while(-1)循环100000000 - 1次
{
--v5;
++*a1; //这里加上上面的循环变成a1=a1-(100000000 - a2) + (100000000 - 1) = a1+a2-1
--v4;
}
++*a1; //这里+1,最后结果就变成a1=a1+a2-1+1=a1+a2
return a1; //所以这个函数的作用就是a1=a1+a2,就是把传入的两个参数相加,结果赋值给第一个参数
}
分析最后一个函数sub_401220函数:(简单的传入参数相加)
_DWORD *__cdecl sub_401220(_DWORD *a1, int a2) //返回a1,故只看对a1的操作
{
int v3; // [esp+8h] [ebp-10h]
int v4; // [esp+Ch] [ebp-Ch]
int v5; // [esp+14h] [ebp-4h]
int v6; // [esp+14h] [ebp-4h]
v4 = -1;
v3 = -1 - a2 + 1;
v5 = -1;
while ( v3 ) //前面说过这里负数循环100000000 - a2次
{
++*a1; //所以这里a1=a1+100000000 - a2
--v3;
--v5;
}
v6 = v5 * v5;
while ( v4 ) //这里负数循环100000000 - 1次
{
v6 *= 123;
++*a1; //这里a1=a1+100000000 - a2+100000000 - 1
--v4;
}
++*a1; //这里a1=a1+100000000 - a2+100000000 - 1+1,这里积累第三个经验,在32位系统中100000000就是0了,所以上面要写成a1=a1-a2,所以在运算题型中,程序的系统位数也是关键内容
return a1; //所以这个函数就是简单的参数相减操作a1-a2,结果赋值给第一个参数
}
那么到这里已经理清程序了,三个函数都可以提取成简单的相乘、相减、相加操作,然后就修改程序了:
第一种手动计算写python脚本:
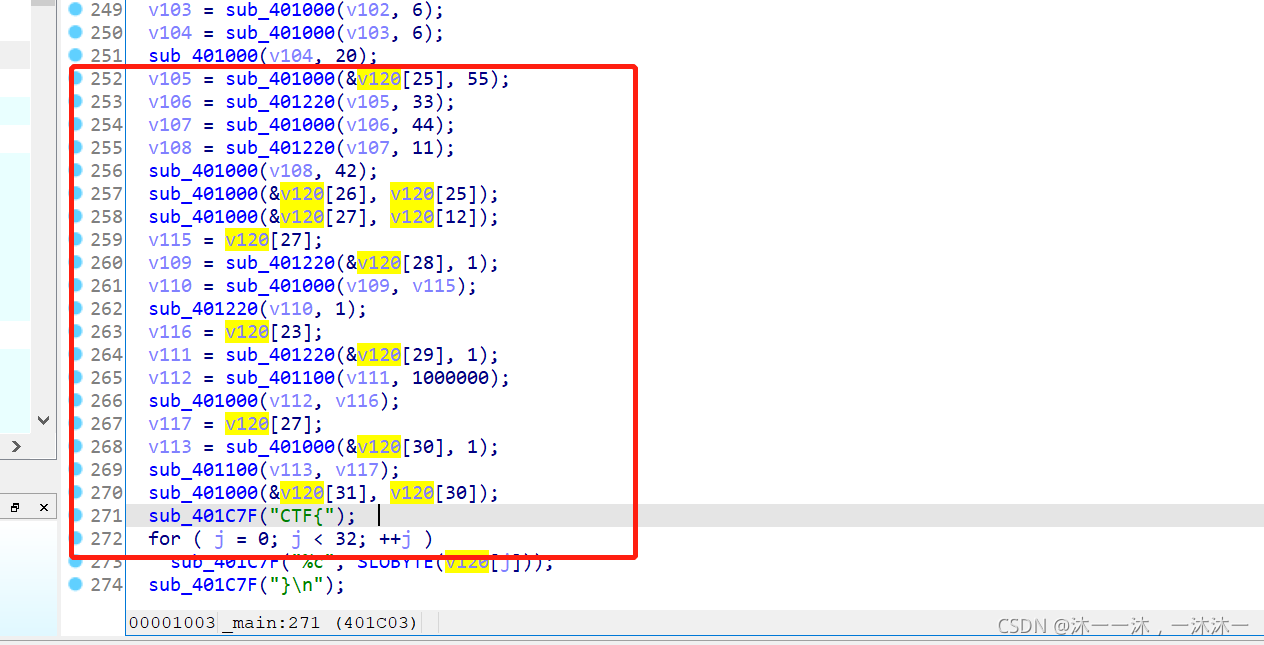
这里积累第4个经验,IDA反汇编代码中可能把一个连续的数组拆成好多个变量,这些变量在函数栈中是连续的。但是后面整理数组时你很难发现和很难梳理他们是不是同一个数组的内容。此时应该在IDA函数栈中修改变量数组大小为它真正的数组大小。
举个例子,下面明明是打印v120[32]数组的:
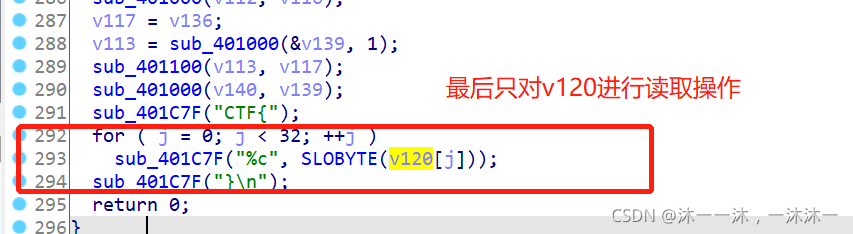
可是IDA变量却只给了V120[12]数组和一堆其它变量,就是它把数组拆分了:

导致的后果就是后面的代码因为用的是连续变量代替数组下标,所以很难理解哪个变量对应哪个下标:(变量的间隔还不同!)
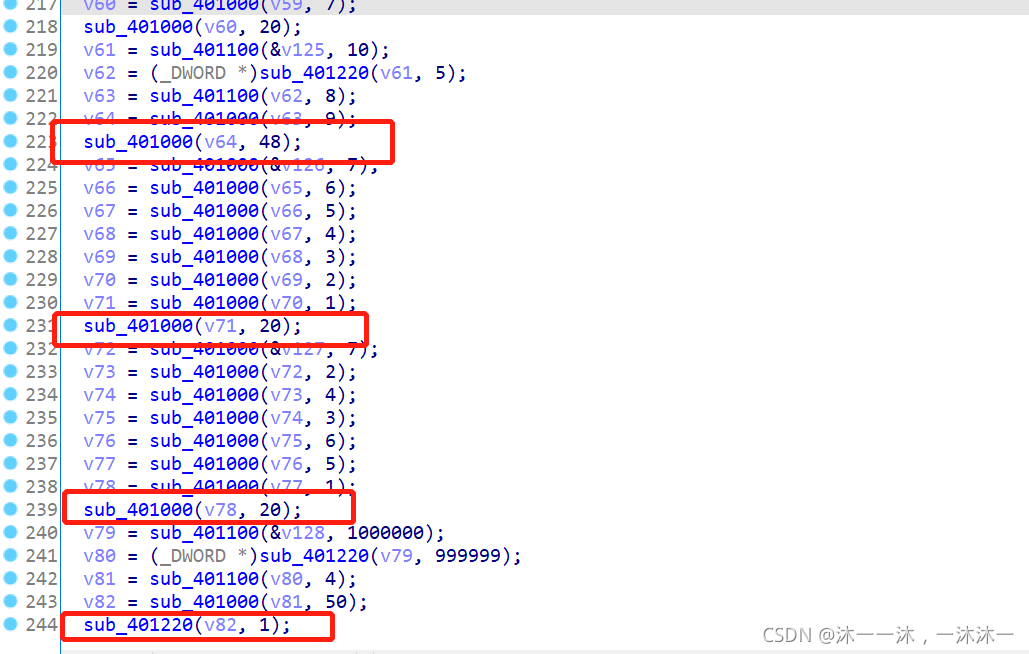
所以我们要在IDA栈中修改v120[12]为v120[32]:
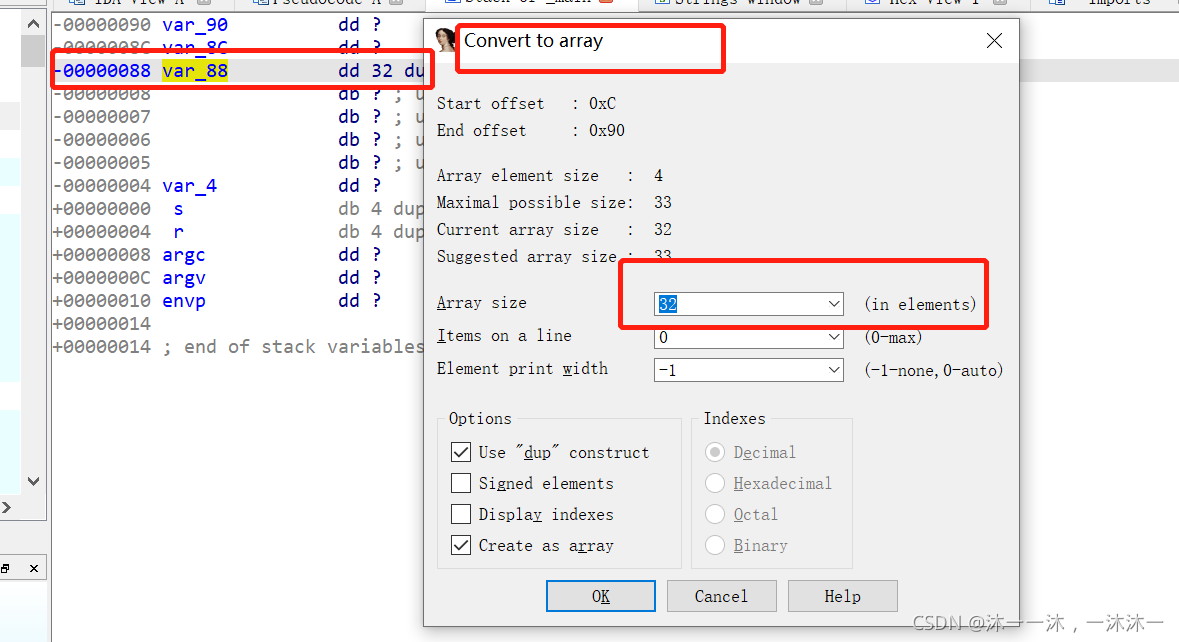
这样修改之后就好看多了,不过手动计算好像还是很麻烦,算了,不手动计算了。(笑~)
第二种方法:直接复制到C语言中修改代码
直接复制到C语言中修改代码吧,很简单的,首先修改_Dword为int,然后把三个函数都改个函数名,打印函数换成Printf就好啦!
(注意!这里如果没有像前面那样修改栈v120[32]数字的话,多个拆分变量在dev中就会造成变量之间的空间不连续,不连续就没法作为一个连续数组输出了,就会输出个四不像出来。):
#include<iostream>
using namespace std;
int *first(int *a1,int a2) //函数题要在Main函数外声明,返回类型是指针,所以int *做返回类型。
{
*a1=*a1*a2;
return a1;
}
int *second(int *a1,int a2)
{
*a1=*a1-a2;
return a1;
}
int *third(int *a1,int a2)
{
*a1=*a1+a2;
return a1;
}
int main(int argc, const char **argv, const char **envp)
{
int *v3; // eax
int *v4; // eax
int *v5; // eax
int *v6; // eax
int *v7; // eax
int *v8; // eax
int *v9; // eax
int *v10; // eax
int *v11; // eax
int *v12; // eax
int *v13; // eax
int *v14; // eax
int *v15; // eax
int *v16; // eax
int *v17; // eax
int *v18; // eax
int *v19; // eax
int *v20; // eax
int *v21; // eax
int *v22; // eax
int *v23; // eax
int *v24; // eax
int *v25; // eax
int *v26; // eax
int *v27; // eax
int *v28; // eax
int *v29; // eax
int *v30; // eax
int *v31; // eax
int *v32; // eax
int *v33; // eax
int *v34; // eax
int *v35; // eax
int *v36; // eax
int *v37; // eax
int *v38; // eax
int *v39; // eax
int *v40; // eax
int *v41; // eax
int *v42; // eax
int *v43; // eax
int *v44; // eax
int *v45; // eax
int *v46; // eax
int *v47; // eax
int *v48; // eax
int *v49; // eax
int *v50; // eax
int *v51; // eax
int *v52; // eax
int *v53; // eax
int *v54; // eax
int *v55; // eax
int *v56; // eax
int *v57; // eax
int *v58; // eax
int *v59; // eax
int *v60; // eax
int *v61; // eax
int *v62; // eax
int *v63; // eax
int *v64; // eax
int *v65; // eax
int *v66; // eax
int *v67; // eax
int *v68; // eax
int *v69; // eax
int *v70; // eax
int *v71; // eax
int *v72; // eax
int *v73; // eax
int *v74; // eax
int *v75; // eax
int *v76; // eax
int *v77; // eax
int *v78; // eax
int *v79; // eax
int *v80; // eax
int *v81; // eax
int *v82; // eax
int *v83; // eax
int *v84; // eax
int *v85; // eax
int *v86; // eax
int *v87; // eax
int *v88; // eax
int *v89; // eax
int *v90; // eax
int *v91; // eax
int *v92; // eax
int *v93; // eax
int *v94; // eax
int *v95; // eax
int *v96; // eax
int *v97; // eax
int *v98; // eax
int *v99; // eax
int *v100; // eax
int *v101; // eax
int *v102; // eax
int *v103; // eax
int *v104; // eax
int *v105; // eax
int *v106; // eax
int *v107; // eax
int *v108; // eax
int *v109; // eax
int *v110; // eax
int *v111; // eax
int *v112; // eax
int *v113; // eax
int v115; // [esp-8h] [ebp-9Ch]
int v116; // [esp-4h] [ebp-98h]
int v117; // [esp-4h] [ebp-98h]
int i; // [esp+4h] [ebp-90h]
int j; // [esp+8h] [ebp-8Ch]
int v120[33]; // [esp+Ch] [ebp-88h] BYREF
for ( i = 0; i < 32; ++i )
v120[i] = 1; // 最后操作的是v120,直接跟踪v120即可,这里赋值v120[32]都为1
v120[32] = 0;
puts("Your flag is:");
v3 = first(v120, 1000000000);
v4 = second(v3, 999999950);
first(v4, 2); // v120=100
v5 = third(&v120[1], 5000000);
v6 = second(v5, 6666666);
v7 = third(v6, 1666666);
v8 = third(v7, 45);
v9 = first(v8, 2);
third(v9, 5); // 97
v10 = first(&v120[2], 1000000000);
v11 = second(v10, 999999950);
v12 = first(v11, 2);
third(v12, 2); // 104
v13 = third(&v120[3], 55);
v14 = second(v13, 3);
v15 = third(v14, 4);
second(v15, 1); // 56
v16 = first(&v120[4], 100000000);
v17 = second(v16, 99999950);
v18 = first(v17, 2);
third(v18, 2); // 102
v19 = second(&v120[5], 1);
v20 = first(v19, 1000000000);
v21 = third(v20, 55);
second(v21, 3); // 58
v22 = first(&v120[6], 1000000);
v23 = second(v22, 999975);
first(v23, 4); // 100
v24 = third(&v120[7], 55);
v25 = second(v24, 33);
v26 = third(v25, 44);
second(v26, 11); // 56
v27 = first(&v120[8], 10);
v28 = second(v27, 5);
v29 = first(v28, 8);
third(v29, 9); // 49
v30 = third(&v120[9], 0);
v31 = second(v30, 0);
v32 = third(v31, 11);
v33 = second(v32, 11);
third(v33, 53); // 54
v34 = third(&v120[10], 49);
v35 = second(v34, 2);
v36 = third(v35, 4);
second(v36, 2); // 50
v37 = first(&v120[11], 1000000);
v38 = second(v37, 999999);
v39 = first(v38, 4);
third(v39, 50); // 54
v40 = third(&v120[12], 1);
v41 = third(v40, 1);
v42 = third(v41, 1);
v43 = third(v42, 1);
v44 = third(v43, 1);
v45 = third(v44, 1);
v46 = third(v45, 10);
third(v46, 32); // 49
v47 = first(&v120[13], 10);
v48 = second(v47, 5);
v49 = first(v48, 8);
v50 = third(v49, 9);
third(v50, 48); // 97
v51 = second(&v120[14], 1);
v52 = first(v51, -294967296);
v53 = third(v52, 55);
second(v53, 3); // 52
v54 = third(&v120[15], 1);
v55 = third(v54, 2);
v56 = third(v55, 3);
v57 = third(v56, 4);
v58 = third(v57, 5);
v59 = third(v58, 6);
v60 = third(v59, 7);
third(v60, 20); // 48
v61 = first(&v120[16], 10);
v62 = second(v61, 5);
v63 = first(v62, 8);
v64 = third(v63, 9);
third(v64, 48); // 97
v65 = third(&v120[17], 7);
v66 = third(v65, 6);
v67 = third(v66, 5);
v68 = third(v67, 4);
v69 = third(v68, 3);
v70 = third(v69, 2);
v71 = third(v70, 1);
third(v71, 20); // 49
v72 = third(&v120[18], 7);
v73 = third(v72, 2);
v74 = third(v73, 4);
v75 = third(v74, 3);
v76 = third(v75, 6);
v77 = third(v76, 5);
v78 = third(v77, 1);
third(v78, 20); // 49
v79 = first(&v120[19], 1000000);
v80 = second(v79, 999999);
v81 = first(v80, 4);
v82 = third(v81, 50);
second(v82, 1); // 53
v83 = second(&v120[20], 1);
v84 = first(v83, -294967296);
v85 = third(v84, 49);
second(v85, 1);
v86 = second(&v120[21], 1); // 48
v87 = first(v86, 1000000000);
v88 = third(v87, 54);
v89 = second(v88, 1);
v90 = third(v89, 1000000000);
second(v90, 1000000000); // 53
v91 = third(&v120[22], 49);
v92 = second(v91, 1);
v93 = third(v92, 2);
second(v93, 1); // 50
v94 = first(&v120[23], 10);
v95 = second(v94, 5);
v96 = first(v95, 8);
v97 = third(v96, 9);
third(v97, 48); // 97
v98 = third(&v120[24], 1);
v99 = third(v98, 3);
v100 = third(v99, 3);
v101 = third(v100, 3);
v102 = third(v101, 6);
v103 = third(v102, 6);
v104 = third(v103, 6);
third(v104, 20); // 49
v105 = third(&v120[25], 55);
v106 = second(v105, 33);
v107 = third(v106, 44);
v108 = second(v107, 11);
third(v108, 42); // 97
third(&v120[26], v120[25]); // 56
third(&v120[27], v120[12]);
v115 = v120[27];
v109 = second(&v120[28], 1);
v110 = third(v109, v115);
second(v110, 1);
v116 = v120[23];
v111 = second(&v120[29], 1);
v112 = first(v111, 1000000);
third(v112, v116);
v117 = v120[27];
v113 = third(&v120[30], 1);
first(v113, v117);
third(&v120[31], v120[30]);
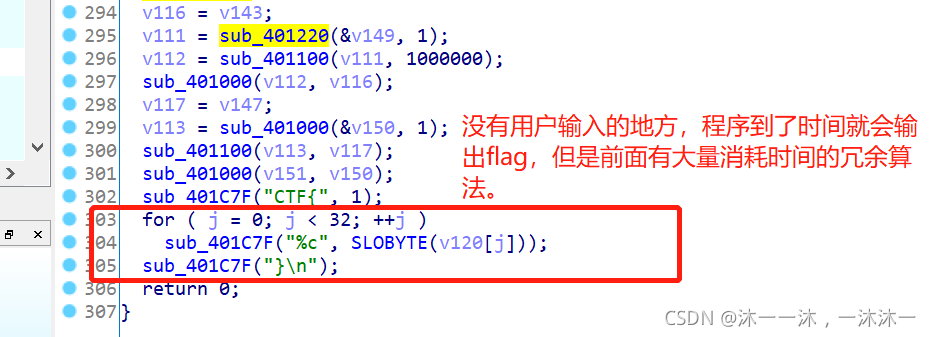
printf("CTF{");
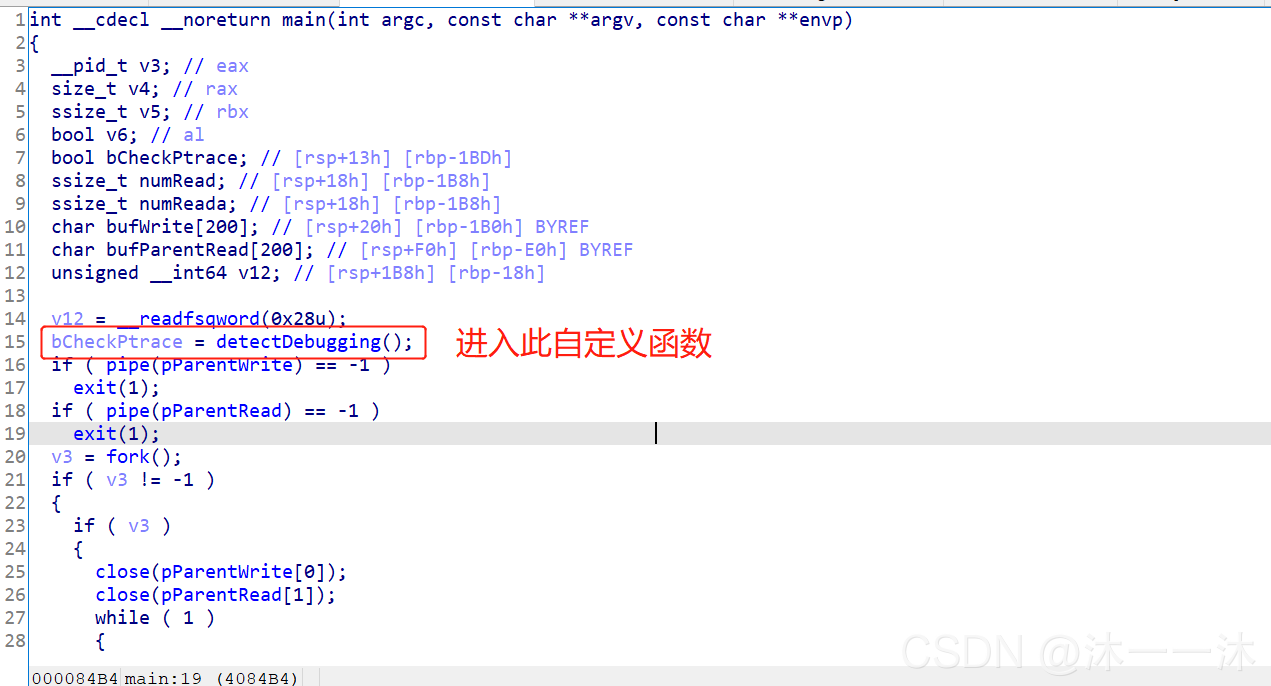
for ( j = 0; j < 32; ++j )
printf("%c", (v120[j]));
printf("}");
return 0;
}
结果:
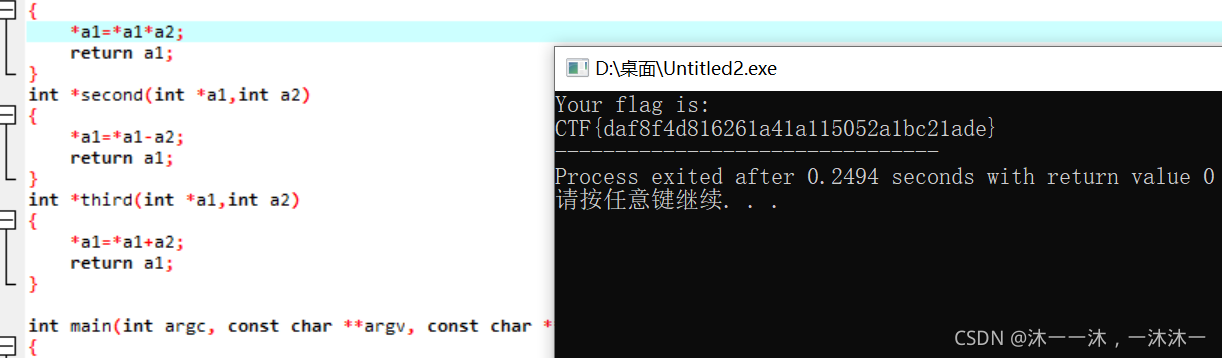
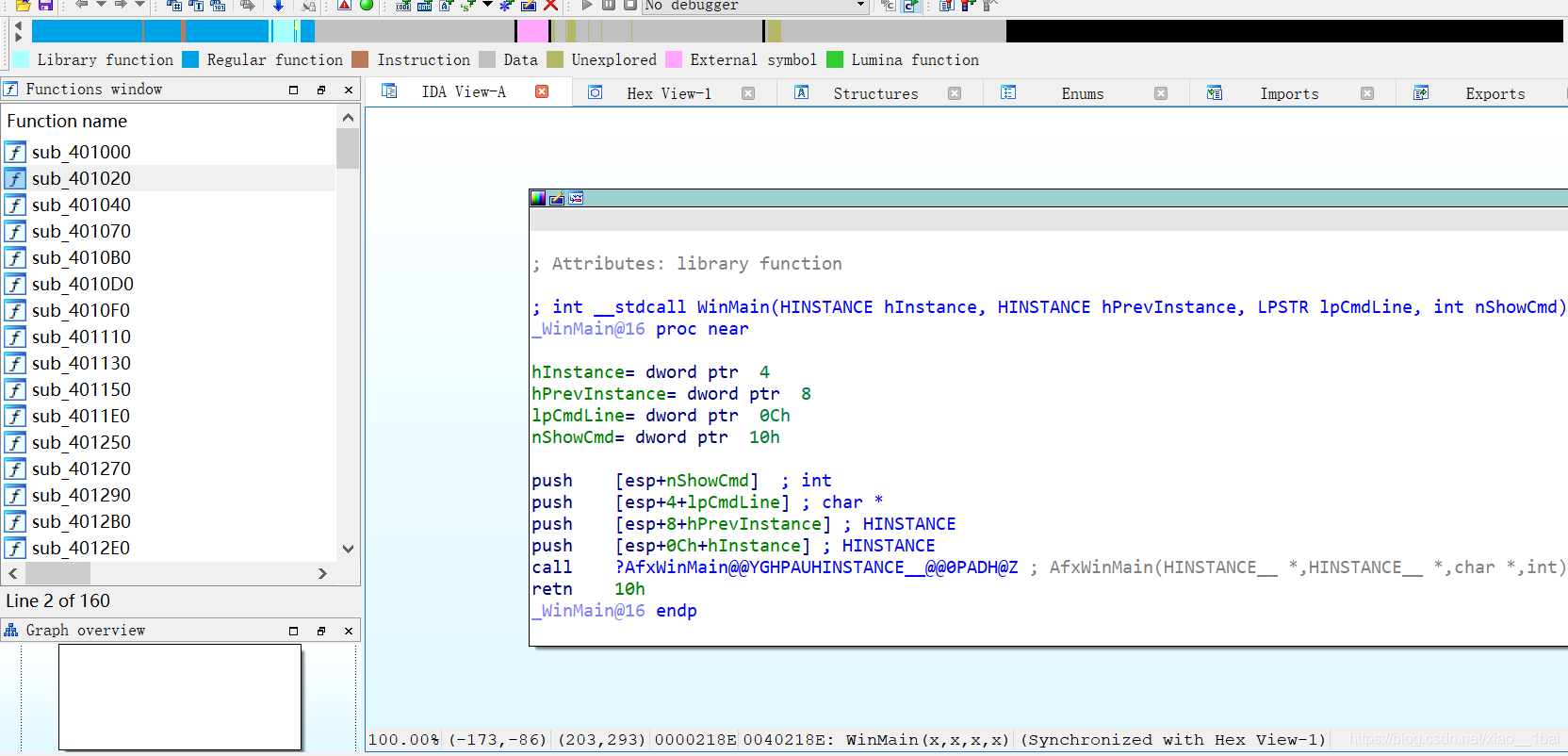
函数逻辑封装类型:
攻防世界的no-strings-attached:(函数名称暗示,GDB动态调试,小端)
32位ELF的linux文件,照例扔如IDA32位中查看代码信息,跟进Main函数:
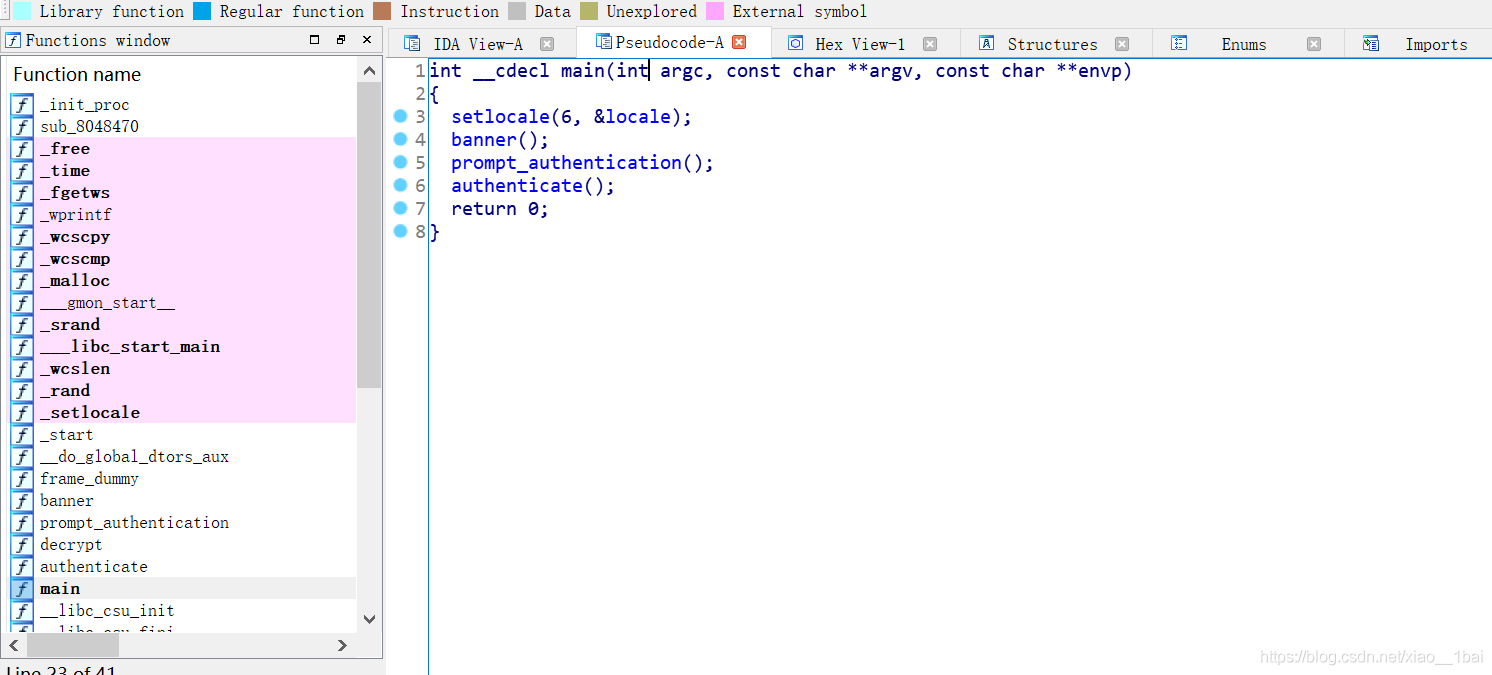
看到四个函数,由于才疏学浅,以为flag不在这里,还去查看了一下strings窗口。也没有flag字眼,有点懵(还是没觉得main的四个函数有问题,还是太菜了啊)。查了查资料,说flag操作就在这四个函数里,于是有回头去看这四个函数。
先看导入表,看那些是自带的函数:
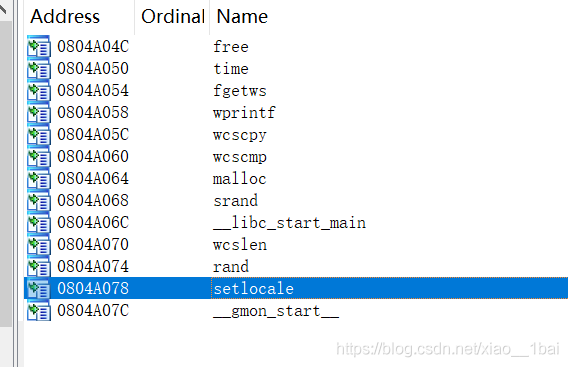
可以看见第一个setlocale是自带的函数,第二第三个双击跟踪进去是打印函数,banner(横幅),猜测应该是打印开头信息的,那么就剩下第四个函数了,双击查看内容:
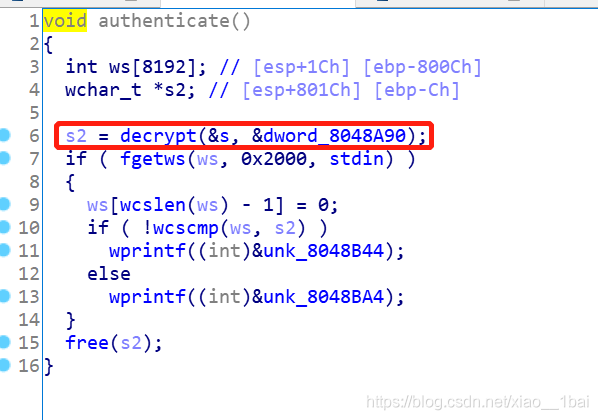
这里有个decrypt函数,中文名是加密,不在导入表中说明不是系统函数,后面的if判断条件是输入,还有个比较的wcscmp函数,后面两个wprintf分别是success 和access这些成功和拒绝的字符串地址。
fgetws函数是从输入流stdin中获取0x2000个字符给ws,也就是说s2是关键了,s2由decrypt函数得出,decrypt是用户自定义函数,在这里学到了非系统函数的英文名会是题目给的暗示,所以这里是加密操作后与输入的比较,只要输入后与加密后的s2一样就会打印success或access这些字符串,那flag自然也在加密函数中了。
由于这种题是和用户输入的比较的,也就是说flag就在s2里面,我们可以在内存调试中提取s2的值,然后解密即可得到flag。(通常s2就是flag,因为如果s2还是加密的flag的话就不用玩了)
我还尝试print s2指令输出变量s2的值,因为我以为和IDA显示的一样,flag赋值给了s2,后来才想起IDA是根据自己的规则给无法解析变量名赋值的,也就是说在IDA里变量是s2这个名字,但是实际上程序里并没有s2这个变量名,所以只能查看寄存器了,毕竟函数是先返回到eax寄存器中再移动到变量中的。
还有就是admin的wp中给的是n指令然后查看eax寄存器的值,可是n指令执行的是一行高级语言命令,而ni和si才是单步执行一条汇编指令,所以不要调着调着跳过对应指令都不知道。
还有就是这里虽然是decrypt产出flag后赋值给了s2,但是双击s2跟踪显示的是s2初始的地址和值,而s2初始并没有什么东西,decrypt函数是用初始有值的&s进行加密操作后才产出flag赋值给s2的,所以不能用双击跟踪s2初始值的方式得到flag。
&s双击后跟进的字符串值:

GDB动态调试:
gdb ./no_strings_attached 将文件加载到GDB中:
之前通过IDA,我们知道关键函数是decrypt,所以我们把断点设置在decrypt处,b在GDB中就是下断点的意思,即在decrypt处下断点:
我们要的是经过decrypt函数,生成的字符串,所以我们这里就需要运行一步,GDB中用n来表示运行一步高级语言代码:
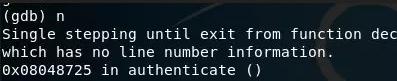
然后我们就需要去查看内存了,去查找最后生成的字符串:
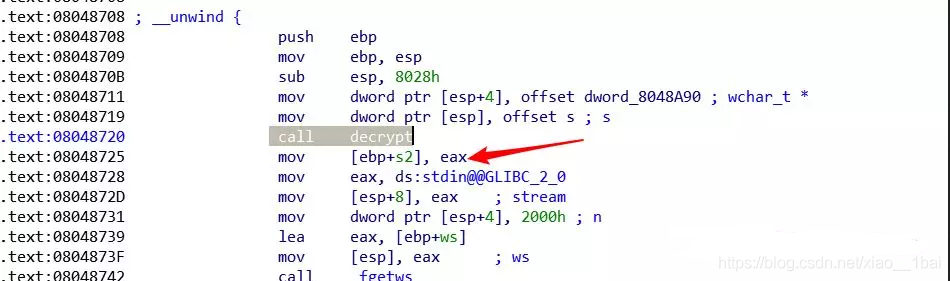
通过IDA生成的汇编指令,我们可以看出进过decrypt函数后,生成的字符串保存在EAX寄存器中,所以,我们在GDB就去查看eax寄存器的值:
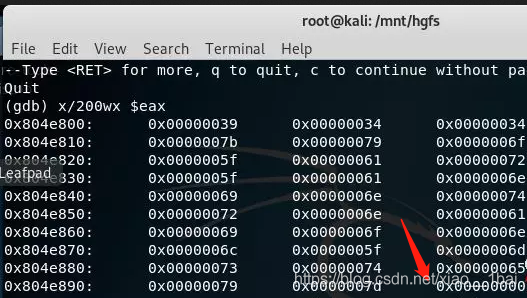
x:就是用来查看内存中数值的,后面的200代表查看多少个
x 代表是以word字节查看看
$ eax代表的eax寄存器中
在这里我们看到0x00000000,这就证明这个字符串结束了,因为,在C中,代表字符串结束的就是"\0",那么前面的就是经过decrypt函数生成的flag。
这里要特别注意一下:操作是面对反汇编低级语言来操作的,所以是对照着内存来操作的!
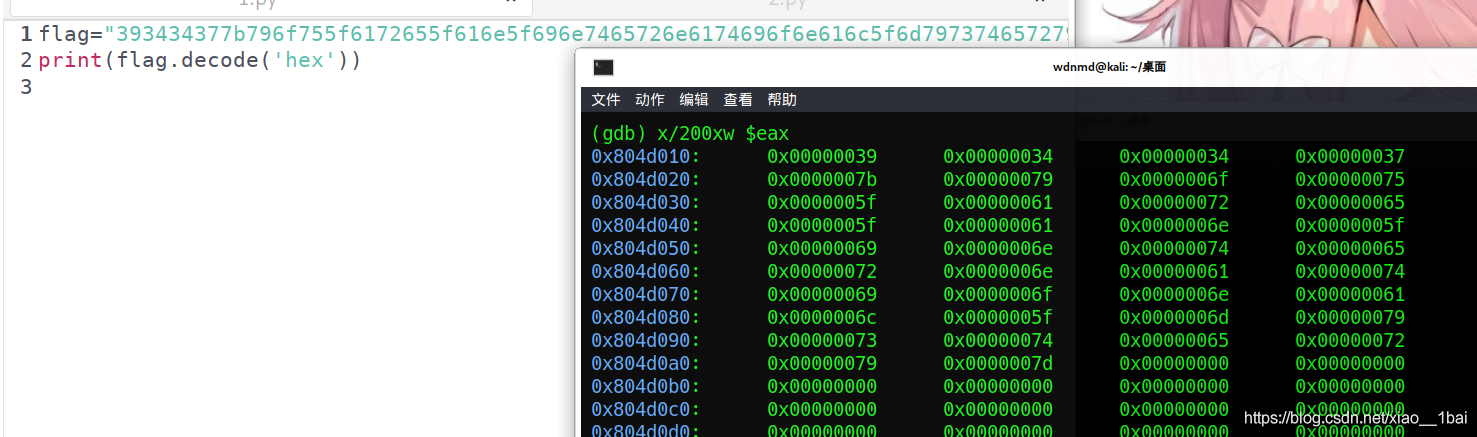
这里是内存数,所以不用像小端一样反过来(可能只有我才会傻到反过来吧~),十六进制数解密后就是flag了:(注意,这里请用python2执行,具体原因看我的Python笔记)
flag="393434377b796f755f6172655f616e5f696e7465726e6174696f6e616c5f6d7973746572797d";
print(flag.decode('hex'))
静态仿写加密流程:
首先回顾前面的话:
由于这种题是和用户输入的比较的,也就是说flag就在s2里面,我们可以在内存调试中提取s2的值,然后解密即可得到flag。
flag在s2内,不用gdb查看内存的话s2就无法得知,但是s2是由decrypt这个加密函数得出的,而这里decrypt传入的加密参数&s和&dword_8048A90都可以双击跟踪内存查看初始值,而且decrypt的内部构造也有,那么我们直接提取出&s和&dword_8048A90这两个参数的值,然后仿照decrypt写个一样加密流程的脚本得出的不也是flag吗?
![]()
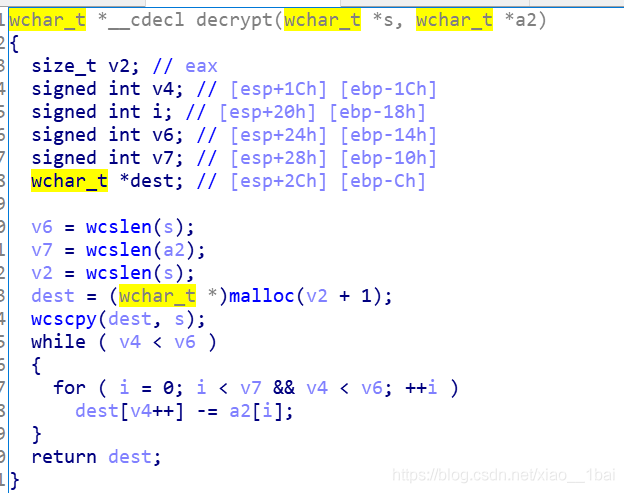
所以我们去提取&s和&dword_8048A90的内容:
addr=0x08048AA8 #数组的地址
arr = []
for i in range(39): #数组的个数
arr.append(Dword(addr+4* i))
print(arr)

提取&dword_8048A90:
addr=0x08048A90 #数组的地址
arr = []
for i in range(6): #数组的个数
arr.append(Dword(addr+4* i))
print(arr)

然后就是用python仿照decrypt加密流程写脚本了:(注意:前面c++中v4++是先赋值后再加,所以到了python中v4+=1就放在赋值后面了)
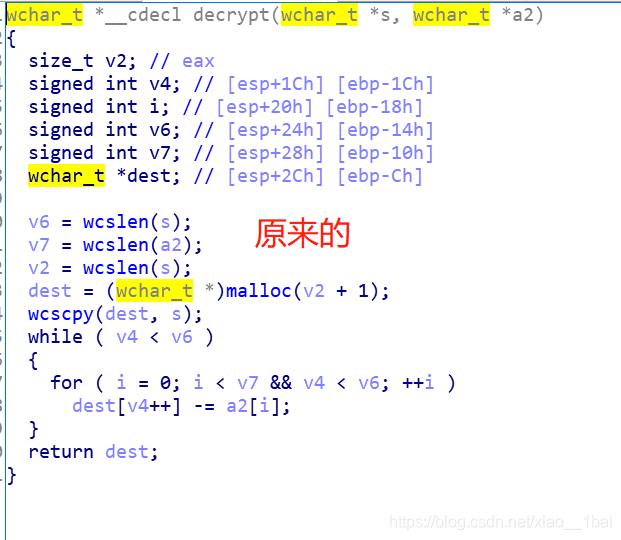
s = [5178, 5174, 5175, 5179, 5248, 5242, 5233, 5240, 5219, 5222, 5235, 5223, 5218, 5221, 5235, 5216, 5227, 5233, 5240, 5226, 5235, 5232, 5220, 5240, 5230, 5232, 5232, 5220, 5232, 5220, 5230, 5243, 5238, 5240, 5226, 5235, 5243, 5248]
a = [5121, 5122, 5123, 5124, 5125]
v6 = len(s)
v7 = len(a )
v2 = len(s)
v4=0
while v4<v6:
for i in range(0,5):
if(i<v7 and v4<v6):
s[v4]-=a[i]
v4 += 1
else:
break
for i in range (38):
print(chr(s[i]),end="")
攻防世界answer_to_everything:(函数名称暗示、函数逻辑封装、出人意料的flag、题目描述暗示)
这里看题目犯下第一个错误:
题目中的人名原来可以包含重要信息的,比如这里的sha1就是sha1加密意思,原谅我年长无知。
IDA静态分析:
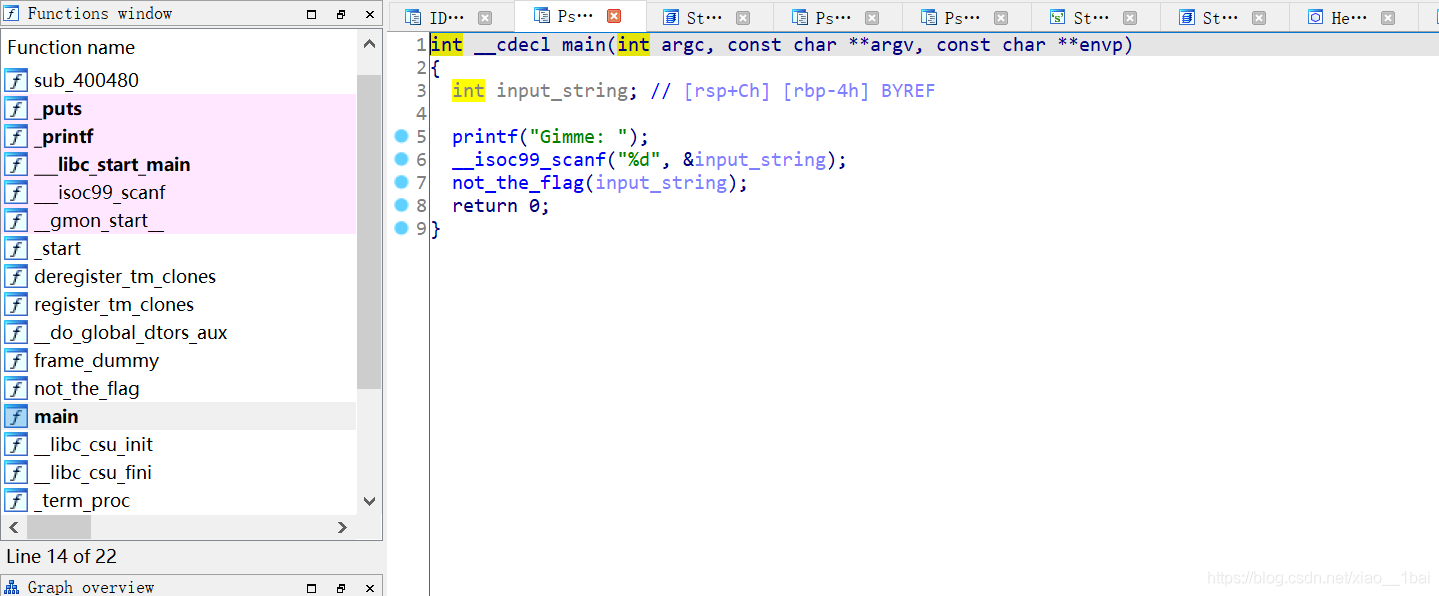
跟踪主函数,看到not_the_flag函数,进去看一下:
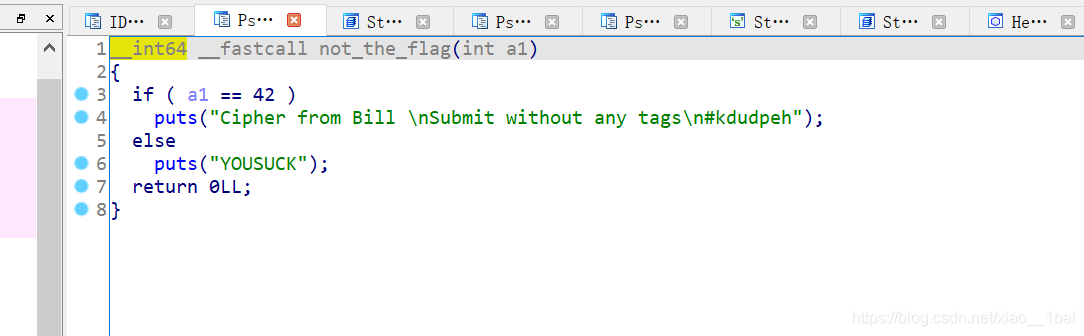
这里犯下第二个错误,我看到字符串以为真的是not_the_flag,然后看了其它函数也没发现有用信息,查了资料才发现这里就是flag,因为我没有把他翻译成中文,所以错过了重要提示!!!!

这里已经提示得很透彻了,提交时不要带标签,就是直接提交kdudpeh即可,结合错误1中的sha1人名,flag就是kdudpeh的sha1加密:
攻防世界secret-galaxy-300:(函数名称暗示、题目描述暗示、字符串拆分算法积累)
下载附件压缩包,解压,得到三个文件:
一开始我很震惊,以为是那种多文件关联的逆向题,结果不是,查看资料后发现这只是三个同一类型文件的三个不同版本而已,一个windows32位exe,另外两个分别是32位和64位的ELF的linux可执行文件,就分析32位的ELF文件吧。
扔入IDA32中查看伪代码,有main函数看main函数:
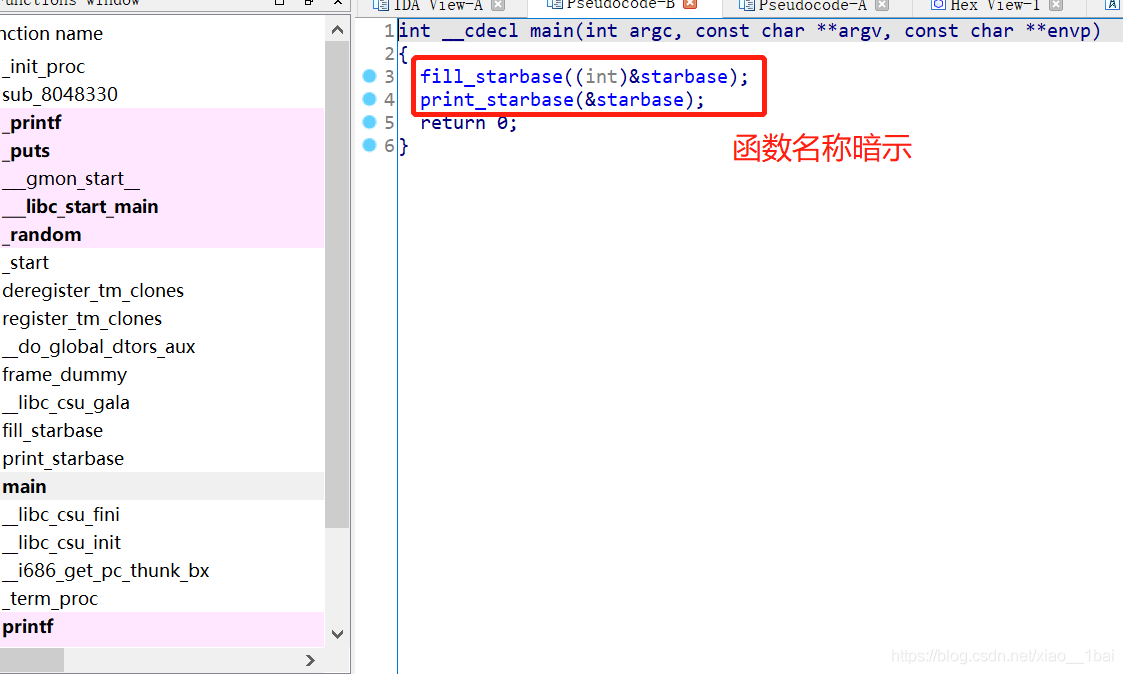
两个函数,一个填充fill_starbase,一个打印print_starbase,打印的函数跟踪进去没啥,打印一些横幅和其它信息,其中v2跟踪不了,看了一下是作为参数传入的:

这里a1跟踪不了,因为是在外部的&starbase传入的,所以前面fill_starbase猜想是填充该数组的,双击跟踪:
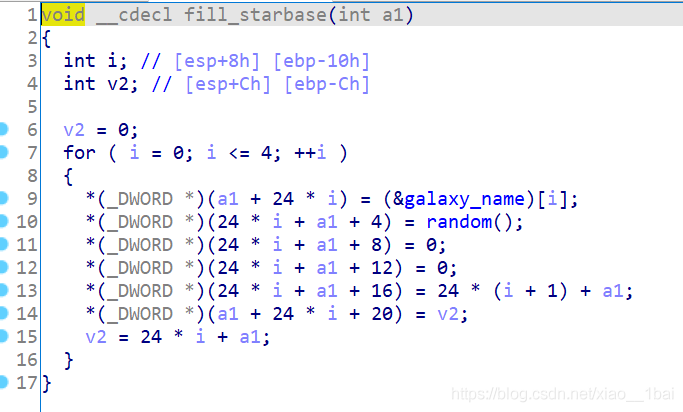
看到一个数组&galaxy_name,还是取地址。后面是对它的一些运算,双击跟踪数组:
看到这里有点不明觉厉,因为至始至终没有flag字眼,想起我还没运行过程序,就去运行一下:
(PS:这里犯下第一个错误:从一开始就运行程序可以帮助我门了解主要显示信息和判断隐藏信息,这里我现在才运行是太后了)

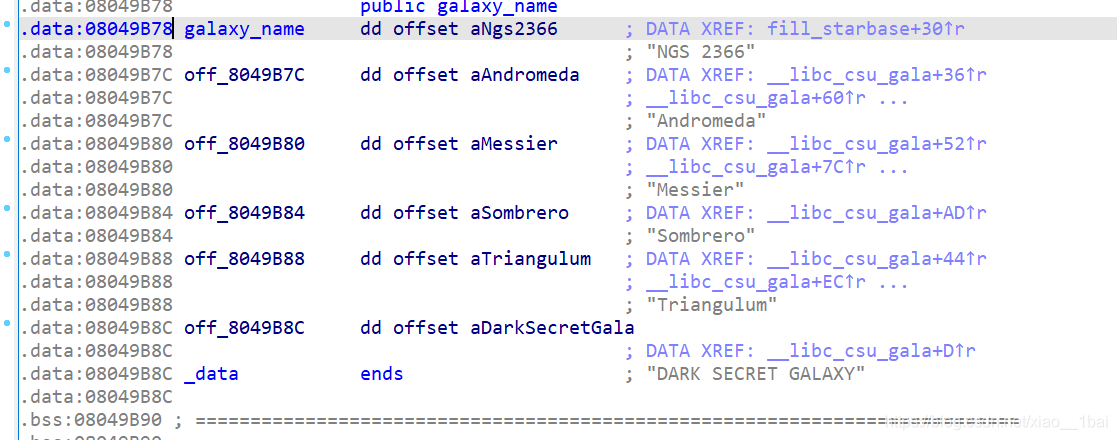
打印的信息在前面分析中都可以看到,这里犯下第二个错误:没有结合题目的暗示,题目是secret-galaxy-300,中文引导型暗示——隐藏的星系,运行结果显示了5个星系,而我前面跟踪的数组有6个星系,少了DARK SECRET GALAXY,那么这个就是关键点!
跟踪DARK SECRET GALAXY的调用,发现一个函数,代码分析如下:(这里是把一个星系字符串拆分成大量的单个字符逐个赋值,可以说是一种算法积累辨识了)
int _libc_csu_gala() //调用DARK SECRET GALAXY的函数
{
int result; // eax
sc[0] = off_8049B8C; // DARK SECRET GALAXY的地址
sc[3] = aAliensAreAroun; //一开始双击跟踪啥也没有,后面是对它的赋值操作
sc[1] = 31337;
sc[2] = 1;
aAliensAreAroun[0] = off_8049B7C[8]; //off_8049B7C处是Andromeda字符串的地址,是第一个星系
aAliensAreAroun[1] = off_8049B88[7]; //off_8049B88处是Triangulum字符串的地址,是第二个星系
aAliensAreAroun[2] = off_8049B80[4]; //off_8049B80是Messier字符串的地址,是第三个星系
aAliensAreAroun[3] = off_8049B7C[6];
aAliensAreAroun[4] = off_8049B7C[1];
aAliensAreAroun[5] = off_8049B80[2];
aAliensAreAroun[6] = 95; //_
aAliensAreAroun[7] = off_8049B7C[8];
aAliensAreAroun[8] = off_8049B7C[3];
aAliensAreAroun[9] = off_8049B84[5]; //off_8049B84是Sombrero的地址,是第四个星系
aAliensAreAroun[10] = 95; //_
aAliensAreAroun[11] = off_8049B7C[8];
aAliensAreAroun[12] = off_8049B7C[3];
aAliensAreAroun[13] = off_8049B7C[4];
aAliensAreAroun[14] = off_8049B88[6];
aAliensAreAroun[15] = off_8049B88[4];
aAliensAreAroun[16] = off_8049B7C[2];
aAliensAreAroun[17] = 95; //_
aAliensAreAroun[18] = off_8049B88[6];
result = (unsigned __int8)off_8049B80[3];
aAliensAreAroun[19] = off_8049B80[3];
aAliensAreAroun[20] = 0;
return result; //这里犯下第三个错误,返回result,可是result是off_8049B80[3],就是Messier的第三个字符s,我醉了,难怪不显示。因为前面一直在用 aAliensAreAroun,结果这里返回别的东西去了。
}
分析完后可以知道 aAliensAreAroun数组大概就是我们要找的flag了:
(PS:可能是我已经运行且调试过IDA了,所以这里的数组名字和我一开始看到的不一样,IDA应该是自己又修改过了)
第一种方法:
手动调试,就这样不同的字符串一个个截取对应的位拼接即可。
第二种方法:
IDA远程动态调试,下断点在return处,运行:

双击跟踪 aAliensAreAroun,按a键生成数组:(a键是IDA生成数组的热键)
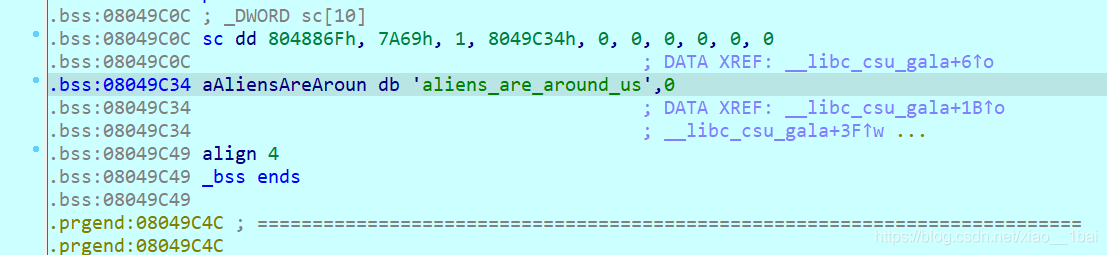
结果就是aliens_are_around_us
GDB动态调试:
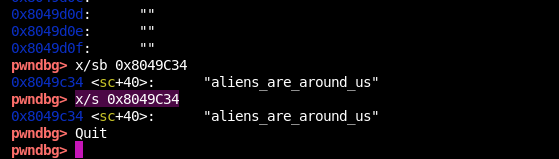
b *0x80485bc //下断点(32位的ELF文件才是这个内存地址啊!其他的不是)
run //运行
x/s 0x8049C34 //查看aAliensAreAroun数组内存
攻防世界simple-check-100:(IDA动态调试、GDB动态调试)
下载附件,又是三个同一类型不同版本的附件,还以为终于遇到了那种关联文件的逆向题:用win32文件,照例扔入IDA32中查看伪代码,有main函数看main函数:

关键代码如上,输入和检查判断是v8,而v8=&v6,也就是说我们是在v6地址上操作。
这里犯下第一个错误:
我看v6栈地址的时候发现编译器给v6留了好多空间,但我竟然以为这题没有这么简单,我以为我么输入的v8会覆盖v7~v35这些地址,如果会覆盖的话题型就变成与用户输入有关的生成型flag了,就不能靠简单修改跳转点来做了,毕竟我们的输入会修改数据,可结果就是v6空间大到我们输入的数据不会覆盖其它变量的数据,真是多想了!
(下图是v6空间,从40~2D,够大了!)
所以我们简单修改跳转条件输出调用后面生成flag的函数即可:

直接用刚学到的IDA本地调试:(修改jz 为 jnz)
额,乱码了:
换linux32位来试,继续扔ELF32位入IDA中查看对应代码在虚拟内存中的位置,好下断点:(在8048719处):

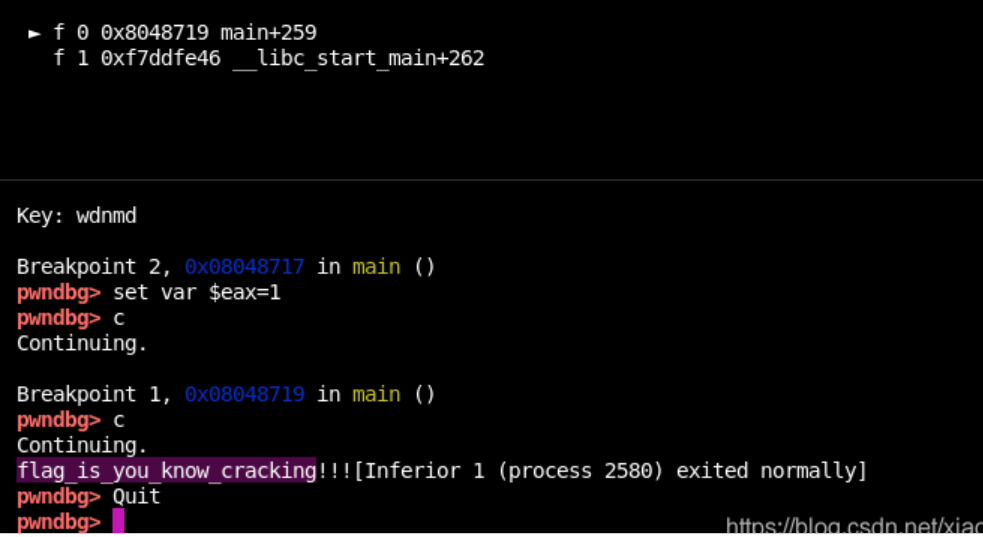
LInux GDB调试,代码如下:
b *0x8048717 //判断位置test eax eax处下断点
r
set var $eax=1 //这里犯下第二个错误:因为前面位运算语句是test eax eax,我们没法直接修改状态标志位ZF=0或修改jz为jnz , 所以我们直接修改eax让test eax eax使ZF=0
c
结果:
攻防世界re1-100:(函数逻辑封装、出人意料的flag、非预期行为)
64位ELF文件,照例扔入IDA64中查看伪代码信息,有main函数看main函数:

这里犯下第一个错误,前面是一堆系统函数,我知道系统函数通常不是关键,但是它系统函数中又混杂了字符串,加上我之前写的HOOK题,还以为藏了什么重要信息在里面,后来才发现关键逻辑代码在后面。
所以以后遇到这种系统函数多的题目先浏览一下全局,看看系统函数外有没有关键逻辑代码:

前面是对&bufParentRead[1]的开头十个赋值,后面&bufParentRead[31]是对倒数十个赋值,但是后面顺序又乱掉了:strncmp(bufParentRead, “{daf29f59034938ae4efd53fc275d81053ed5be8c}”, 42uLL)
所以中间一定有改变,跟踪一下中间的confuseKey(bufParentRead, 42)函数:

前面比较多东西,但是这次我忽然看到后面的关键了,如截图所示,把字符串分成四份,按3、4、1、2、的顺序重新打乱,而且按照主函数最后混乱代码那里{daf29f59034938ae4efd53fc275d81053ed5be8c}也的确是符合4和1的新顺序。
所以之前的函数顺序就是简单的1、2、3、4、:
{53fc275d81053ed5be8cdaf29f59034938ae4efd}
好像很简单,但是提交的时候显示错误:
这里就犯下第二个错误了,既然题目没有flag模板,我加flag变成flag{53fc275d81053ed5be8cdaf29f59034938ae4efd}还是提交错误,那这里就应该去掉花括号啊,结果就是53fc275d81053ed5be8cdaf29f59034938ae4efd
攻防世界elrond32:(argv[]外部调用输入参数符合条件、函数逻辑封装、递归调用算法)
32位ELF文件,无壳,扔入32位IDA中查看伪代码信息,有Main函数看main函数:
额,看上去好像比较简单,int __cdecl main(int a1, char **a2)中a1是命令行传入参数的个数,起始值为1,a2是命令行传入参数的数组,a2[0]存的是程序名称,所以才有a1的起始1。我们传入的参数从a2[1]开始。
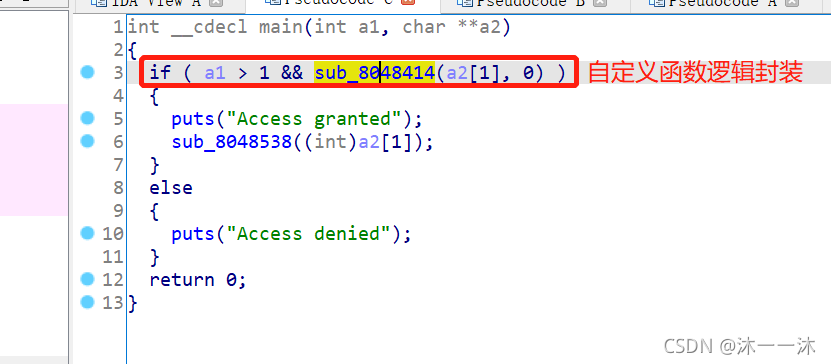
跟踪sub_8048414函数:(递归调用算法)
int __cdecl sub_8048414(_BYTE *input_flag, int a2)
{
int result; // eax
switch ( a2 ) // a2=0,从0开始,然后后面递归重新调用此函数时会对a2重新赋值,每次+1,按顺序对应case的不同情况,以此按顺序锁定flag每个字符。
{
case 0:
if ( *input_flag == 'i' )
goto LABEL_19;
result = 0;
break;
case 1:
if ( *input_flag == 'e' )
goto LABEL_19;
result = 0;
break;
case 3:
if ( *input_flag == 'n' )
goto LABEL_19;
result = 0;
break;
case 4:
if ( *input_flag == 'd' )
goto LABEL_19;
result = 0;
break;
case 5:
if ( *input_flag == 'a' )
goto LABEL_19;
result = 0;
break;
case 6:
if ( *input_flag == 'g' )
goto LABEL_19;
result = 0;
break;
case 7:
if ( *input_flag == 's' )
goto LABEL_19;
result = 0;
break;
case 9:
if ( *input_flag == 'r' )
LABEL_19:
result = sub_8048414(input_flag + 1, 7 * (a2 + 1) % 11); // 修改input_flag的地址,a2重新赋值,递归调用。
else
result = 0;
break;
default:
result = 1;
break;
}
return result;
}
这里我们先写脚本正向逆向(仿写)这个逻辑先,只要保证每个返回的都是1即可,递归调用我们用大量循环来写,反正不符合结果就会跳出:
a2=0
flag=""
for i in range(32):
a=a2
if a==0:
flag+='i'
elif a==1:
flag+='e'
elif a==3:
flag+='n'
elif a==4:
flag+='d'
elif a==5:
flag+='a'
elif a==6:
flag+='g'
elif a==7:
flag+='s'
elif a==9: #python写c语言的
flag+='r'
else:
break
a2=7 * (a2 + 1) % 11
print(flag)
print(len(flag))
结果,生成一个8位的字符串就退出了:
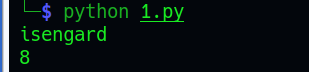
跟踪下一个函数,sub_8048538((int)a2[1]),发现flag要对前面生成的8位字符进一步操作才行。
int __cdecl sub_8048538(int input_flag)
{
int v2[33]; // [esp+18h] [ebp-A0h] BYREF
int i; // [esp+9Ch] [ebp-1Ch]
qmemcpy(v2, &dword_8048760, sizeof(v2));
for ( i = 0; i <= 32; ++i )
putchar(v2[i] ^ *(char *)(input_flag + i % 8)); //一个简单的异或操作然后输出,%8对得上前面输出的8位字符串
return putchar(10);
}
写IDA脚本打印dword_8048760数组内容:
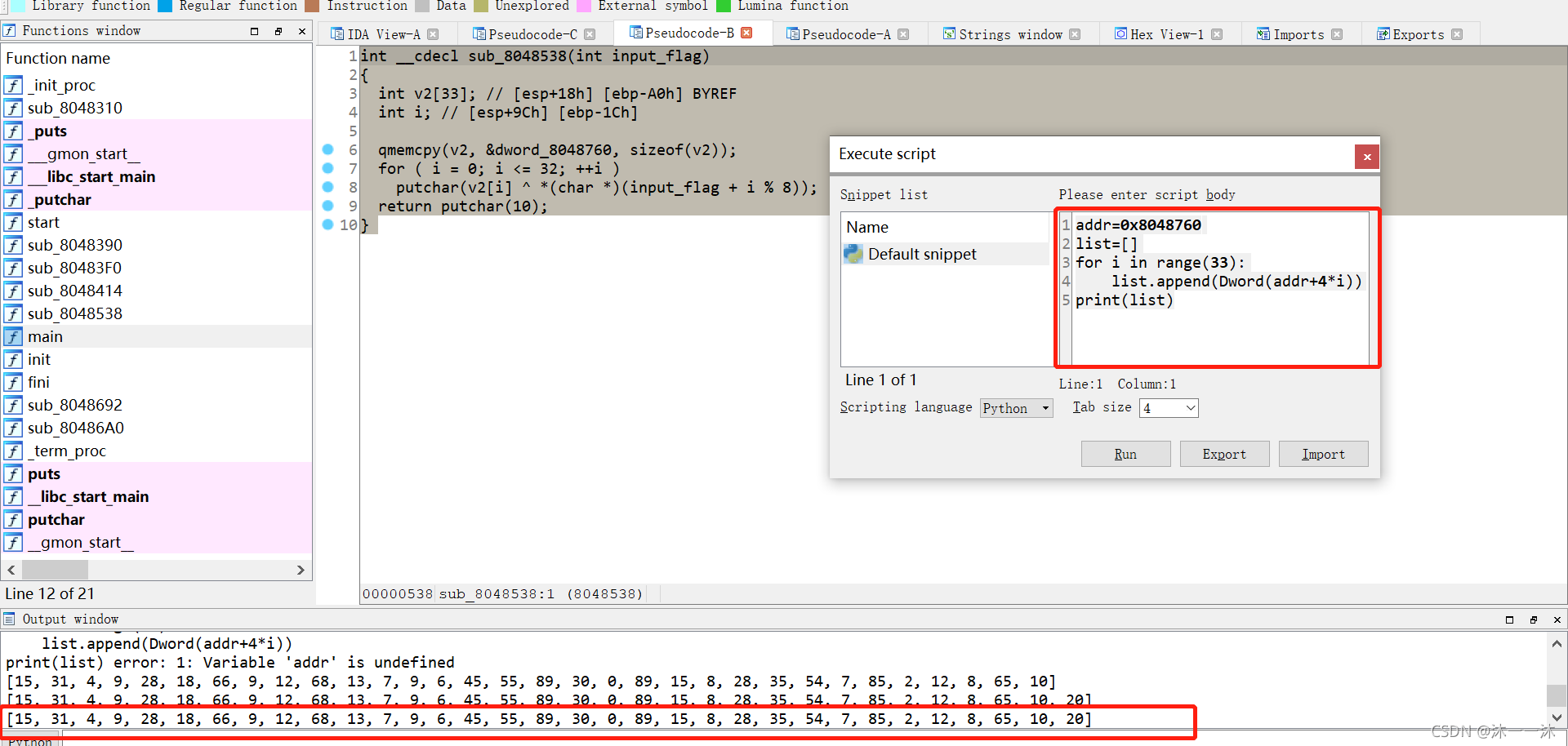
复制粘贴数组,重新修改脚本内容:
a2=0
flag=""
v2=[15, 31, 4, 9, 28, 18, 66, 9, 12, 68, 13, 7, 9, 6, 45, 55, 89, 30, 0, 89, 15, 8, 28, 35, 54, 7, 85, 2, 12, 8, 65, 10,20]
flag2=""
for i in range(32):
a=a2
if a==0:
flag+='i'
elif a==1:
flag+='e'
elif a==3:
flag+='n'
elif a==4:
flag+='d'
elif a==5:
flag+='a'
elif a==6:
flag+='g'
elif a==7:
flag+='s'
elif a==9: #python写c语言的
flag+='r'
else:
break
a2=7 * (a2 + 1) % 11
print(flag)
print(len(flag))
for i in range(33):
flag2+=chr(v2[i]^ord(flag[i%8]))
print(flag2)
结果:

main函数中有与本地文件相关的操作类型:
攻防世界getit:(IDA、GDB动态调试)
64位ELF文件,无壳,然后扔入IDA查看伪代码信息:

这里说写入了/tmp/flag.txt,也因为是tmp文件,所以不是管理员也可以写入,后面显眼的fclose(stream);remove(filename);也说明了一运行完程序就删除文件,所以我们没法在运行完程序后找到该文件
现在分析中间的循环写入语句:
for ( i = 0; i < strlen(&t); ++i ) //我是认为&t是flag的长度
{
fseek(stream, p[i], 0); //定位到开头偏移p[i]位置处,
fputc(*(&t + p[i]), stream); //在上一句的定位处写入&t起始字符串的p[i]偏移的单个字节
fseek(stream, 0LL, 0); //重新定位到0且没有偏移
fprintf(stream, "%s\n", u); //写入完整字符u来覆盖前面写入的一个字符,双击跟踪u发现是*******************************************,就是一个覆盖干扰
}
这里的p[i]双击跟踪长这个样子:(p[i]鼠标长时间停留显示int[43]类型):
可以看到p[i]数组存放的是无序的整数,但是这些整数都是唯一的flag的位数。也就是说每次在/tmp/flag.txt文件中写入的flag是不按顺序写的,且每次只出现一个字符,需要自己排序。
开头的循环判断中的&t在前面出现过,长这个样子:
![]()
后来发现前面的循环才是生成的flag代码,后面的p[i]只是将flag分成单个单个字符写进去而已:
v9 = __readfsqword(40u); //这里我也不清楚,是windows的API函数,从偏移量的指定位置读取内存相对 FS 段开头
LODWORD(v5) = 0; //这里把__in64的v5(longlong型)转地址类型为32为DWORD,即取低32位为0
while ( (signed int)v5 < strlen(s) ) //这里signed int是有符号整形,s双击跟踪是c61b68366edeb7bdce3c6820314b7498这样的无序字符串
{
if ( v5 & 1 ) //这里是v5的1位和1进行与操作,因为后面有LODWORD(v5) = v5 + 1,所以v3在这里会1、-1这样反复横条strlen(s)次
v3 = 1;
else
v3 = -1;
*(&t + (signed int)v5 + 10) = s[(signed int)v5] + v3; //这里是赋值,因为v5一开始是0,所以从&t+10开始赋值,&t双击跟踪是SharifCTF{????????????????????????????????},第10位刚好是第一个?,赋值是从s[0]开始+1,s[1]-1,s[2]+1这样赋值,分别对应不断递增的v5和反复横跳的v3,所以这里也可以手动计算第一个?是b,第二个?是7这样。
LODWORD(v5) = v5 + 1; //v5底32位加1,其实就是v5加1
}
有好几种做题方法,
第一个静态计算,就像我上面分析flag生成代码手动计算一样。
手动计算即可。
第二种动态截停,截止flag生成后的位置,查看寄存器即可。
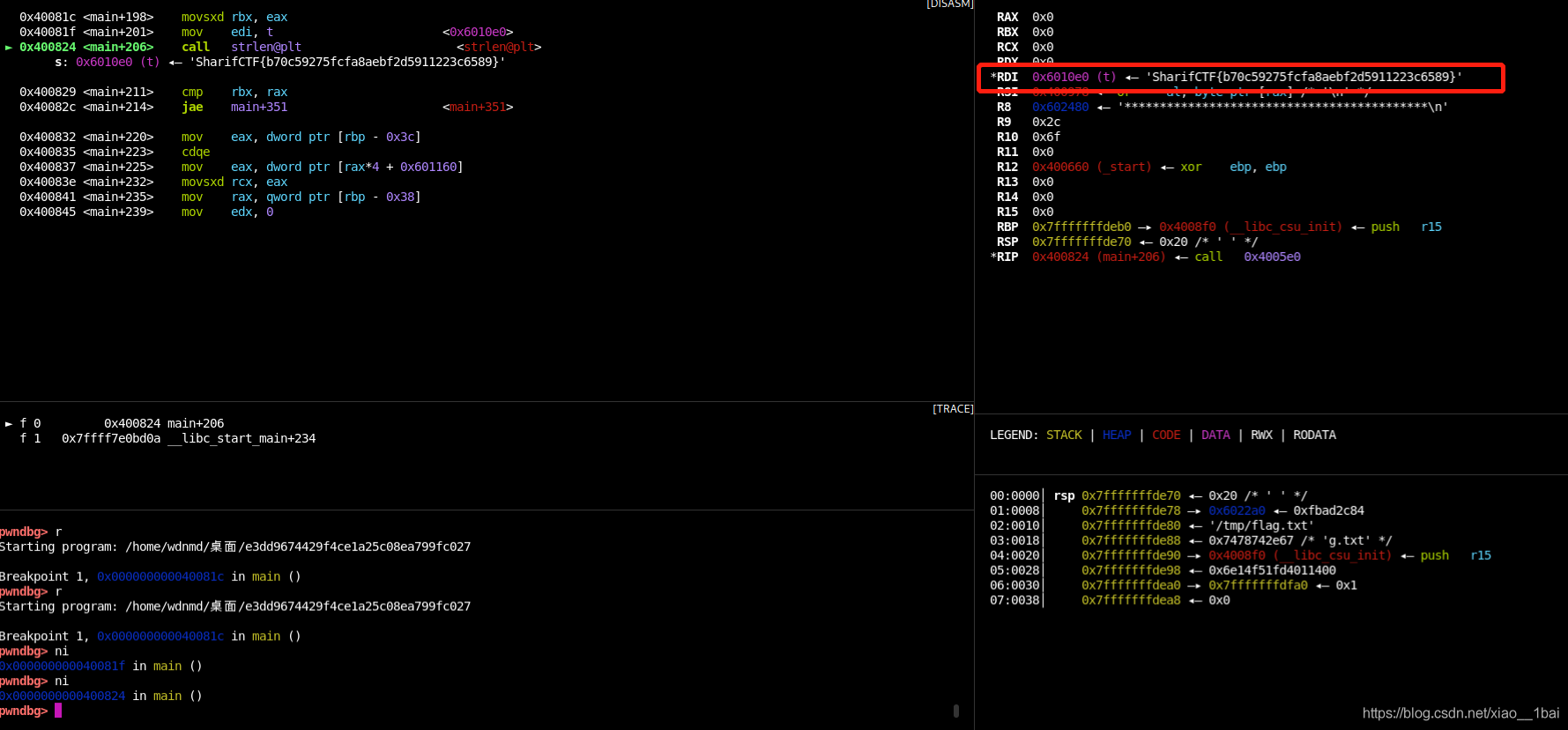
GDB动态调试,首先我们知道了下面strlen(&t)的t是flag程序运行后生成的flag,那我们把鼠标放在那一行上看一下下面的反汇编行数,如下所示是400824,那么我们在反汇编窗口跟上。

可以看到反汇编中400824行的确是_strlen函数,而它上面就是把&t移入了edi,所以在GDB中我们断点400824,然后查看edi寄存器即可。
GDB所需命令:(可以看到flag就在RDI寄存器里)
b *0x400824
r
第三种静态计算,仿写c语言脚本或python脚本安装一样的算法生成flag。
key1="c61b68366edeb7bdce3c6820314b7498"
v5=0
flag=""
while v5 < len(key1):
if v5 & 1:
v3=1
else:
v3=-1
flag+=chr(ord(key1[v5])+v3)
v5+=1
print(flag)
第四种动态截停,在IDA远程调试中截停在remove(filename);最后这里,或者return 0;也行,然后在IDA中写python脚本命令输出&t地址的字符串即可。

直接双击t看到?已经被替换成flag了,这里是断点在return。
第五个动态截停,在linux中用GDB或IDA远程调试断点断在fprintf(stream, “%s\n”, u); 这里,然后每次记录写入的一个flag字符。
嗯~第五种就不演示了,大致像这个样子吧,不过他这个是整理过的,真实的是不按顺序出现的。

main函数主逻辑分析(C++)
main函数中嵌入大量冗余代码,拆分代码混淆:
攻防世界dmd-50:(函数积累、地址小端存放与正向、涉及加密、出人意料的flag)
64位ELF文件,无壳,照例扔入IDA64位中查看伪代码,有main函数看main函数:
看到一堆变量,一堆系统函数,我知道系统函数通常不是考点,可这系统函数多到我都差点找不到主要代码:
突然看见字符串Enter the valid key!\n 猜测题型是与用户输入相关的判断型flag。代码分析:
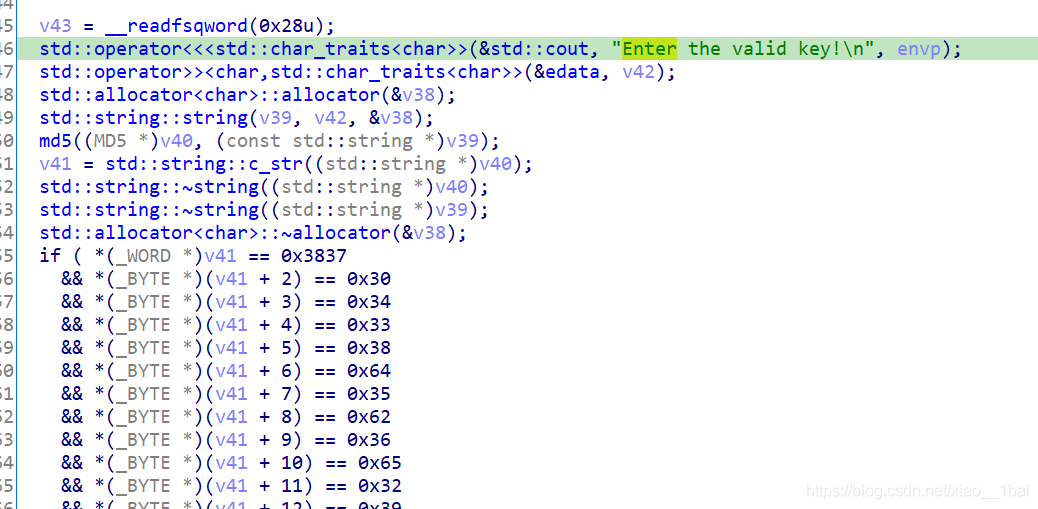
v43 = __readfsqword(0x28u); //一个内存段偏移,无用
std::operator<<<std::char_traits<char>>(&std::cout, "Enter the valid key!\n", envp);
std::operator>><char,std::char_traits<char>>(&edata, v42); //这里应该是输入
std::allocator<char>::allocator(&v38); //内存空间分配,空间分配就是用于输入或复制的
std::string::string(v39, v42, &v38); // v42 输入复制给 v39。这里借鉴了别人的博客,这里犯下第一个错误,因为系统函数太多了,我也就只注意到了下面的md5,没去查这个函数用法,结果这个函数是赋值函数,也是关键
md5((MD5 *)v40, (const std::string *)v39); //一个md5加密函数, 把 v39 进行 MD5 后保存在 v40,我记得C语言没有md5函数的,这里可能是调用了外部的库函数
v41 = std::string::c_str((std::string *)v40);
std::string::~string((std::string *)v40);
std::string::~string((std::string *)v39);
std::allocator<char>::~allocator(&v38);
继续分析判断语句:
if ( *(_WORD *)v41 == 0x3837 //这里犯下第二个错误,这里本来是14390的整数的,这里类型是16位WORD,后面都是8位的BYTE,也就是这里应该分出一个*(_BYTE *)v41和*(_BYTE *)(v41 + 1)的,可是我不会分,想起数在内存中是小端的十六进制数,就改为了十六进制,那么前面(_BYTE *)v41就是0x37,后面*(_BYTE *)(v41 + 1)就是0x38了。
&& *(_BYTE *)(v41 + 2) == 0x30
&& *(_BYTE *)(v41 + 3) == 0x34
&& *(_BYTE *)(v41 + 4) == 0x33
&& *(_BYTE *)(v41 + 5) == 0x38
&& *(_BYTE *)(v41 + 6) == 0x64
&& *(_BYTE *)(v41 + 7) == 0x35
&& *(_BYTE *)(v41 + 8) == 0x62
&& *(_BYTE *)(v41 + 9) == 0x36
&& *(_BYTE *)(v41 + 10) == 0x65
&& *(_BYTE *)(v41 + 11) == 0x32
&& *(_BYTE *)(v41 + 12) == 0x39
&& *(_BYTE *)(v41 + 13) == 0x64
&& *(_BYTE *)(v41 + 14) == 0x62
&& *(_BYTE *)(v41 + 15) == 0x30
&& *(_BYTE *)(v41 + 16) == 0x38
&& *(_BYTE *)(v41 + 17) == 0x39
&& *(_BYTE *)(v41 + 18) == 0x38
&& *(_BYTE *)(v41 + 19) == 0x62
&& *(_BYTE *)(v41 + 20) == 0x63
&& *(_BYTE *)(v41 + 21) == 0x34
&& *(_BYTE *)(v41 + 22) == 0x66
&& *(_BYTE *)(v41 + 23) == 0x30
&& *(_BYTE *)(v41 + 24) == 0x32
&& *(_BYTE *)(v41 + 25) == 0x32
&& *(_BYTE *)(v41 + 26) == 0x35
&& *(_BYTE *)(v41 + 27) == 0x39
&& *(_BYTE *)(v41 + 28) == 0x33
&& *(_BYTE *)(v41 + 29) == 0x35
&& *(_BYTE *)(v41 + 30) == 0x63
&& *(_BYTE *)(v41 + 31) == 0x30 )
再后面判断后的结果按照以前经验转成ASCII字符,发现都是成功失败类的字符串,那这里的系统函数作用应该只是简单的赋值和输出吧,就不用深究了:
所以思路清晰了,对用户输入进行md5加密后一位一位比较,那么我们用md5后的值在在线工具中反向解密即可:
key1=[0x37,0x38,0x30,0x34,0x33,0x38,0x64,0x35,0x62,0x36,0x65,0x32,0x39,0x64,0x62,0x30,0x38,0x39,0x38,0x62,0x63,0x34,0x66,0x30,0x32,0x32,0x35,0x39,0x33,0x35,0x63,0x30]
md=""
for i in key1:
md+=chr(i)
print(len(md))
print(md)
md5结果:
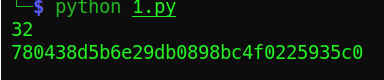
在线解密网址:
https://www.cmd5.com/
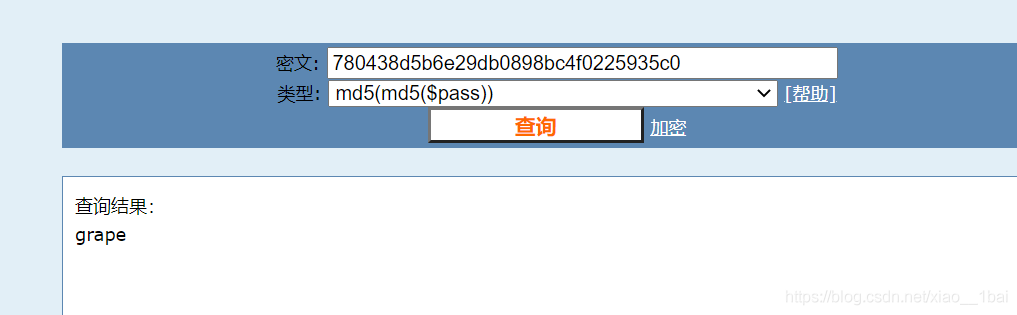
额,我们不需要两次解密,一次就可以了,所以对grape再加密一次:
攻防世界crazy:(函数名称暗示、地址赋值算法积累、非预期行为、出人意料的flag)
64位ELF文件,扔入对应IDA中查看信息,有main函数看main函数:
可以看到,一堆眼花缭乱的系统函数,有些则是用类名调用的普通C++函数。
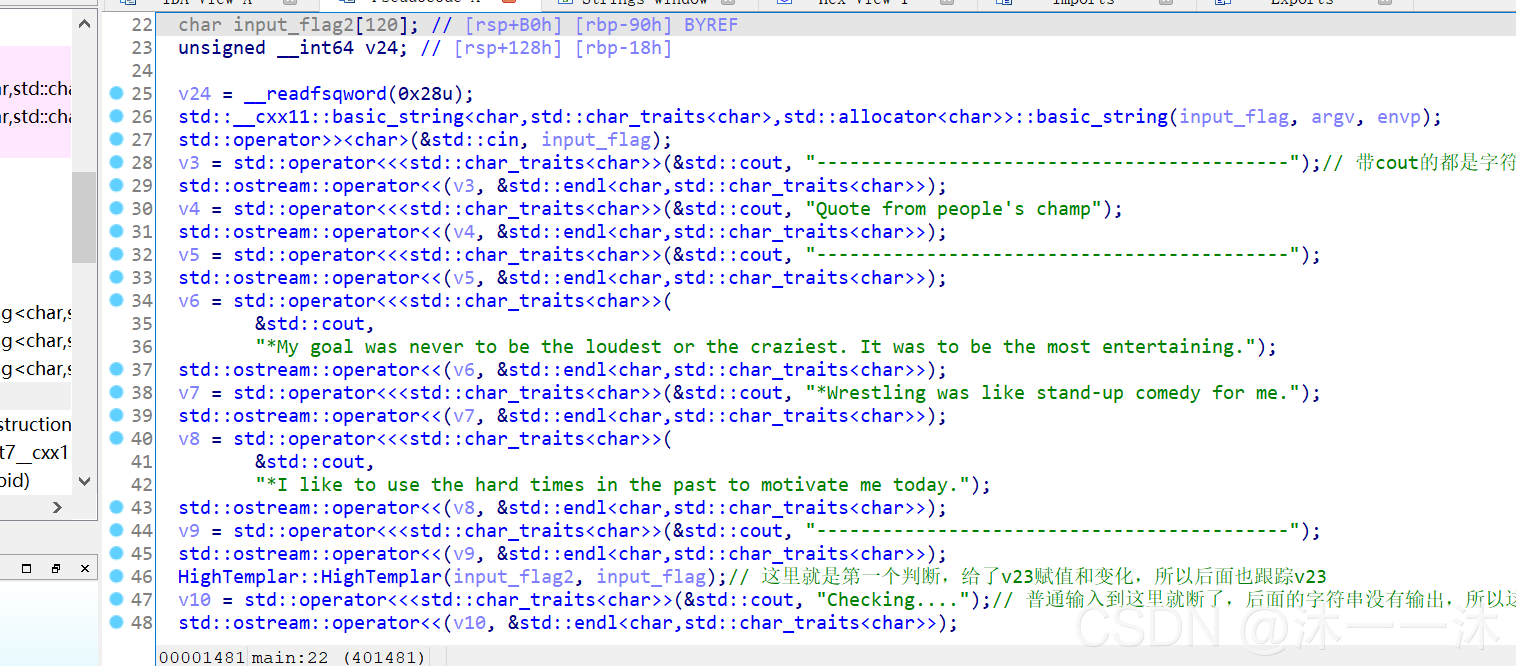
这里积累第一个经验:(别人博客的一句话)
代码看着很乱,有很多很长的命令,解决办法:依据英文意思去猜测。
找关键变量的方法:从后往前找,看flag和输入关系。复杂代码本质应该是简洁的,这样才叫出题。
但是从后往前找与flag的有关变量还是很麻烦,所以我们用运行程序方法不断查看显示信息,锁定关键位置。(调试的话不知道断点下在那里可能要遍历很长时间)
第一次乱输入:
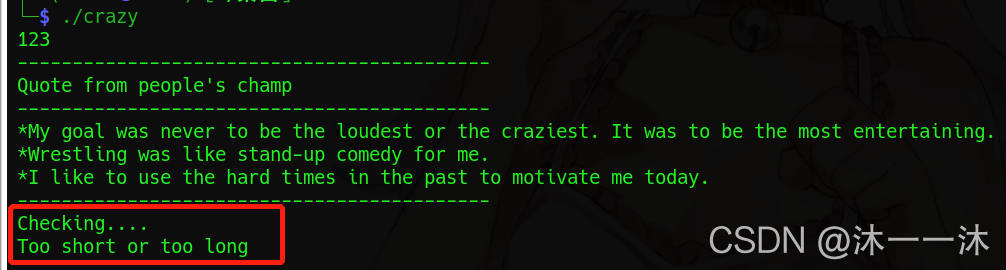
可以看到运行到checking…后显示too short or too long处,还有就是用户输入在字符串输出之前。返回IDA查看代码:
这里有个cin,也是主函数中在其它字符串之前的,cin是c++的输入函数。

从这里积累第二个经验:该程序的长字符传命令中从后往前找到的熟悉的C++函数就是我们要关注的命令,比如这里的cin函数,像下面截图中字符串前面也有cout函数:
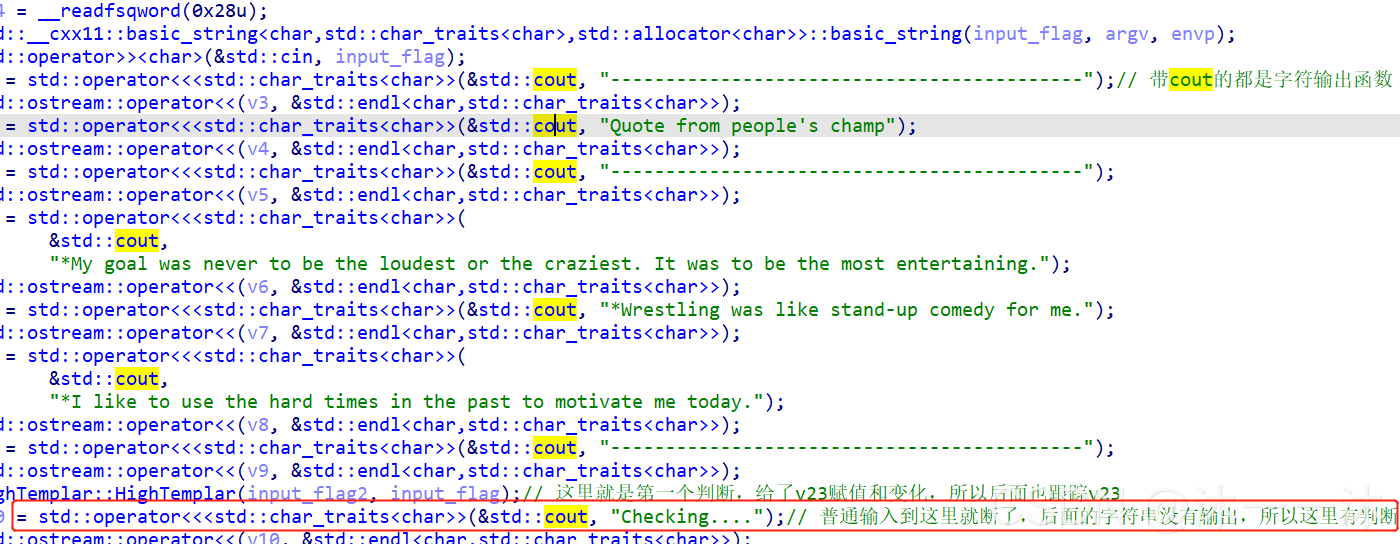
看上图中最后的check…字符串之后的函数:
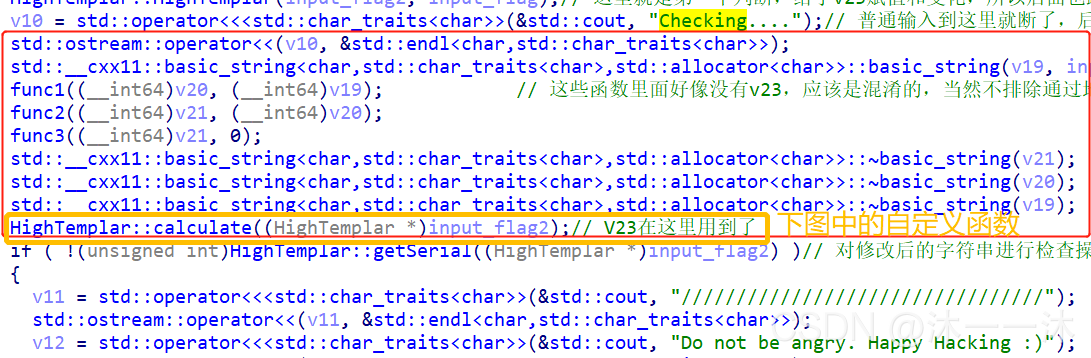
可以看到 checking 到 if 判断语句之间还是有很多函数的,可以用前面的依据英文意思猜测的方法去看函数,也可以在strings窗口查找too short or too long处的函数位置:(我选择后者)
这里跟踪到HighTemplar::calculate函数,根据英文名是计算函数,但是我看不懂这里的this+16,凭借意思我推测是我们输入flag的地址,把我们输入的flag经过两个简单的循环异或加密后输出:
bool __fastcall HighTemplar::calculate(HighTemplar *this) //接受用户输入作为参数
{
__int64 v1; // rax
_BYTE *v2; // rbx
bool result; // al
_BYTE *v4; // rbx
int i; // [rsp+18h] [rbp-18h]
int j; // [rsp+1Ch] [rbp-14h]
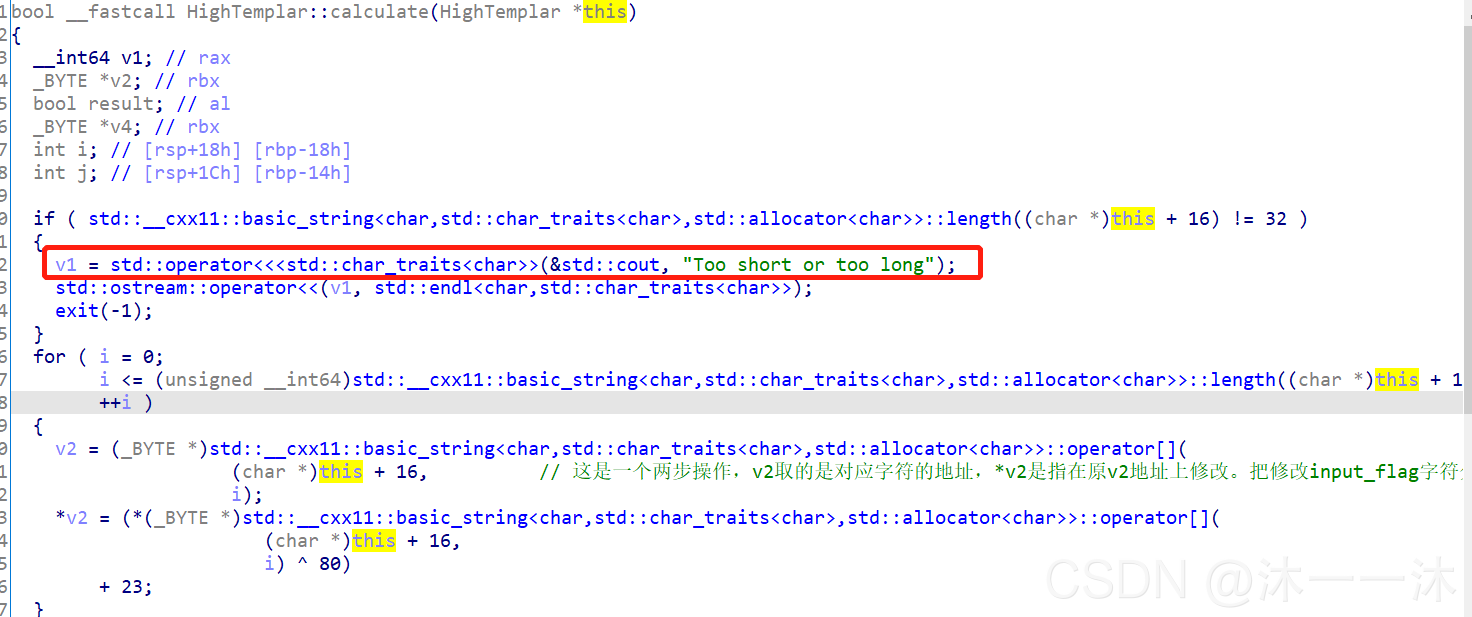
if ( std::__cxx11::basic_string<char,std::char_traits<char>,std::allocator<char>>::length((char *)this + 16) != 32 ) //判断长度
{
v1 = std::operator<<<std::char_traits<char>>(&std::cout, "Too short or too long"); //输出判断结果语句
std::ostream::operator<<(v1, std::endl<char,std::char_traits<char>>);
exit(-1);
}
for ( i = 0;
i <= (unsigned __int64)std::__cxx11::basic_string<char,std::char_traits<char>,std::allocator<char>>::length((char *)this + 16);
++i ) //在长度范围内的for循环操作
{
v2 = (_BYTE *)std::__cxx11::basic_string<char,std::char_traits<char>,std::allocator<char>>::operator[](
(char *)this + 16, // 这里积累第三个经验:这是一个两步操作,v2取的是对应字符的地址,*v2是指在原v2地址上对值进行修改,也就是对Input_flag进行修改。把修改input_flag字符分成了两步做,让不熟悉的我载了跟头。(这里算是地址赋值算法积累)
i);
*v2 = (*(_BYTE *)std::__cxx11::basic_string<char,std::char_traits<char>,std::allocator<char>>::operator[](
(char *)this + 16,
i) ^ 80) //对input_flag每个字符异或80
+ 23;
}
for ( j = 0; ; ++j )
{
result = j <= (unsigned __int64)std::__cxx11::basic_string<char,std::char_traits<char>,std::allocator<char>>::length((char *)this + 16); //又是在input_flag的长度范围内的for语句
if ( !result )
break;
v4 = (_BYTE *)std::__cxx11::basic_string<char,std::char_traits<char>,std::allocator<char>>::operator[](
(char *)this + 16,
j); //简单分配空间,取地址
*v4 = (*(_BYTE *)std::__cxx11::basic_string<char,std::char_traits<char>,std::allocator<char>>::operator[](
(char *)this + 16,
j) ^ 19) 对input_flag每个字符异或19
+ 11;
}
return result;
}
然后由于HighTemplar::calculate函数的下一个就是if判断函数,所以我们只能跟踪if判断函数内的HighTemplar::getSerial了:
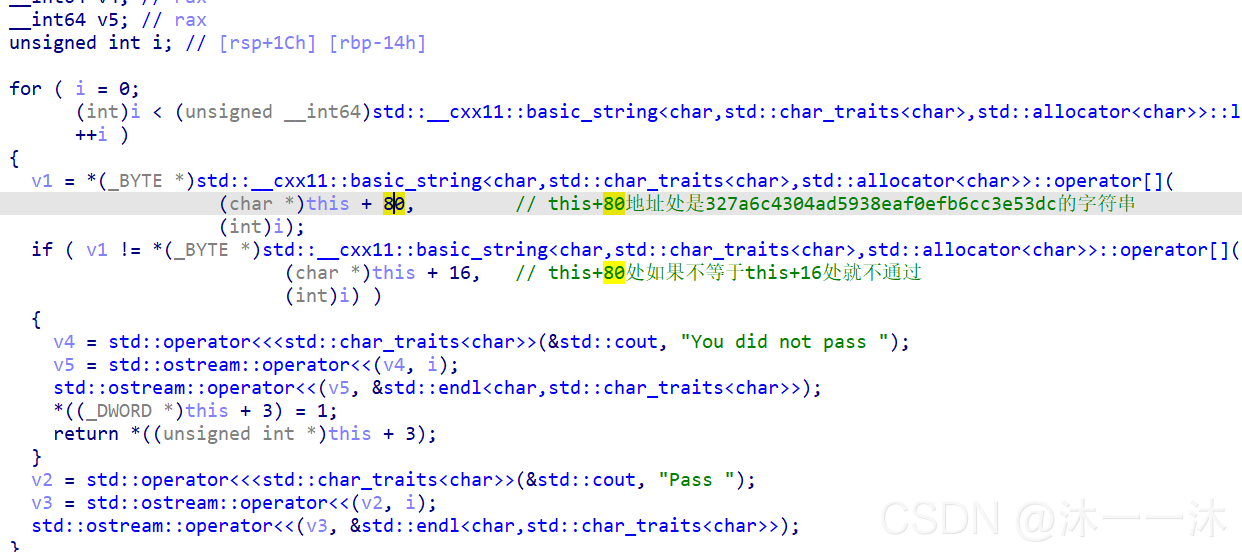
前面this+16我推测是我们输入flag的地方,但是这个this+80存了什么东西我是真不知道了。双击跟踪堆栈也是未赋值的状态。
这里积累第四个经验,逆向中不符合预期的运算结果基本都是中间做了其它操作,如之前遇到的HOOK,这里很多函数我还没跟踪,那说明的确会有未发现的操作。
回到一开始cin函数的地方,表黄输入变量,看哪里还引用过该变量:
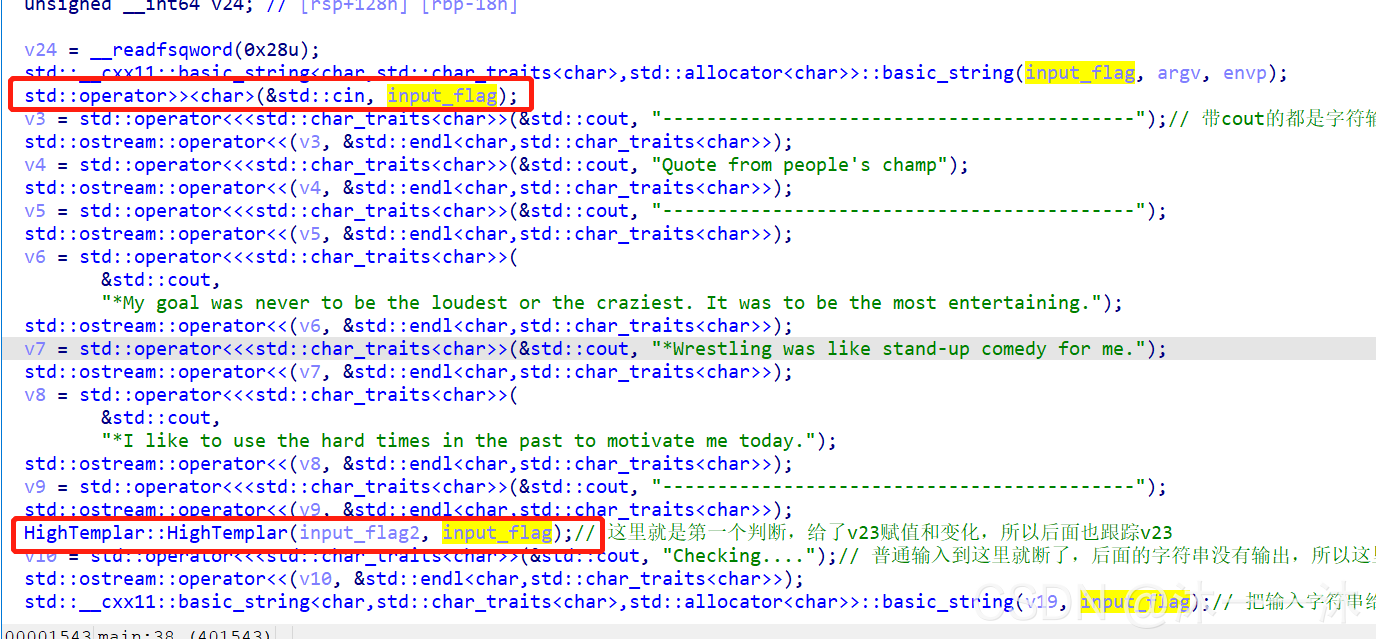
可以看到在checking前面还引用了一下,而该函数我们并没有分析,双击跟踪分析:
这里我们可以看到把输入的flag分别给了this+16和this+48地址处,在this+80地址处给了327a6c4304ad5938ea
f0efb6cc3e53dc这个字符串,那么前面对this+80的疑惑就解释得通了。
unsigned __int64 __fastcall HighTemplar::HighTemplar(DarkTemplar *a1, __int64 input_flag)
{
char v3; // [rsp+17h] [rbp-19h] BYREF
unsigned __int64 v4; // [rsp+18h] [rbp-18h]
v4 = __readfsqword(0x28u);
DarkTemplar::DarkTemplar(a1);
*(_QWORD *)a1 = &off_401EA0;
*((_DWORD *)a1 + 3) = 0;
std::__cxx11::basic_string<char,std::char_traits<char>,std::allocator<char>>::basic_string(
(char *)a1 + 16, // C++函数,basic_string(字符串类模板),不是复制就是比较,这里是复制输入字符串给a1+16开始的地址的数组中
input_flag);
std::__cxx11::basic_string<char,std::char_traits<char>,std::allocator<char>>::basic_string(
(char *)a1 + 48, // C++函数,basic_string(字符串类模板),不是复制就是比较,复制输入字符串给a1+48开始的地址的数组中,与前面隔了32个字符
input_flag);
std::allocator<char>::allocator(&v3);
std::__cxx11::basic_string<char,std::char_traits<char>,std::allocator<char>>::basic_string(
(char *)a1 + 80,
"327a6c4304ad5938eaf0efb6cc3e53dc", // C++函数,basic_string(字符串类模板),不是复制就是比较,复制输入字符串给a1+80开始的地址的数组中,与前面还是隔了32个字符,这个v3不清楚
&v3);
std::allocator<char>::~allocator(&v3);
return __readfsqword(0x28u) ^ v4; //内存操作,暂时不用管
}
现在直接写脚本逆向逻辑即可:
key1="327a6c4304ad5938eaf0efb6cc3e53dc"
flag1=""
flag=""
print(len(key1))
for i in range(len(key1)):
flag1+=chr((ord(key1[i])-11)^19)
for i in range(len(flag1)):
flag+=chr((ord(flag1[i])-23)^80)
print(flag)
结果:(这里积累第5个经验:现在的flag真的是越来越古灵精怪了,还有花括号,我一开始都以为我写错脚本了,现在看来,什么类型的flag都可以!一次不行就修改再交几次)

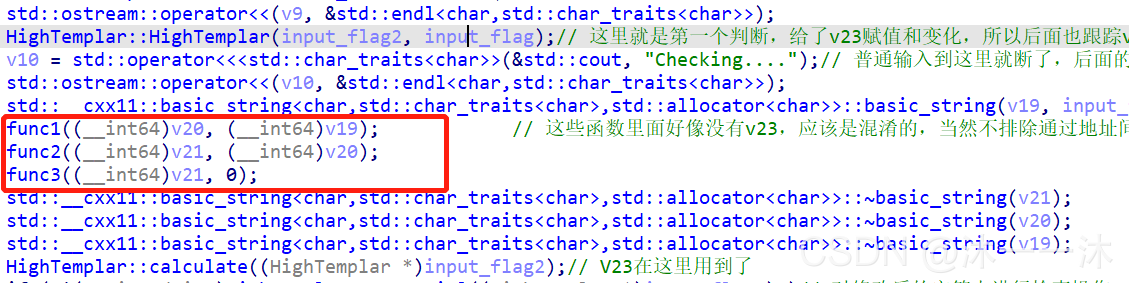
最后,下面这三个函数有什么用呢,我判断它是没什么用的,因为参数没有传入我输入的flag,跟踪里面也没有我输入的flag地址,除非是偏移地址间接引用我输入的flag,不过那样的话题就很难了!
无main函数分析(C语言)
主逻辑平铺一函数内:
攻防世界Mysterious:(地址小端存放与正向,出人意料的flag)
W32可执行文件,无壳,扔入IDA32中看伪代码判断题目类型:
没有主函数,看来是非正常文件,双击程序看看有什么信息可以提取:
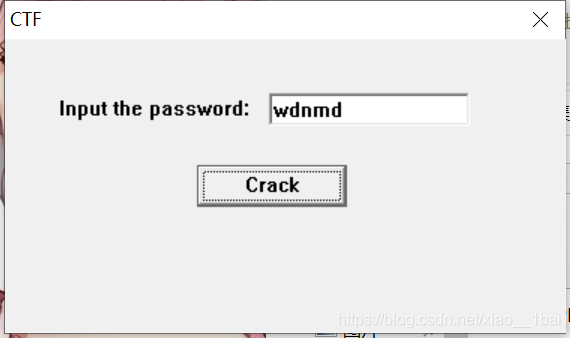
一个输入密码型弹框,Crack按钮按不下去,信息够了,查看IDAstring窗口:
没有发现input the password字眼,应该是隐藏了,想起弹框是用了Messagebox的windowsAPI函数,于是双击跟踪该函数:(要在import窗口才能跟踪,string窗口不行,因为import是导入API外部函数的窗口,string窗口那里可能只是刚好有同名字符串而已)
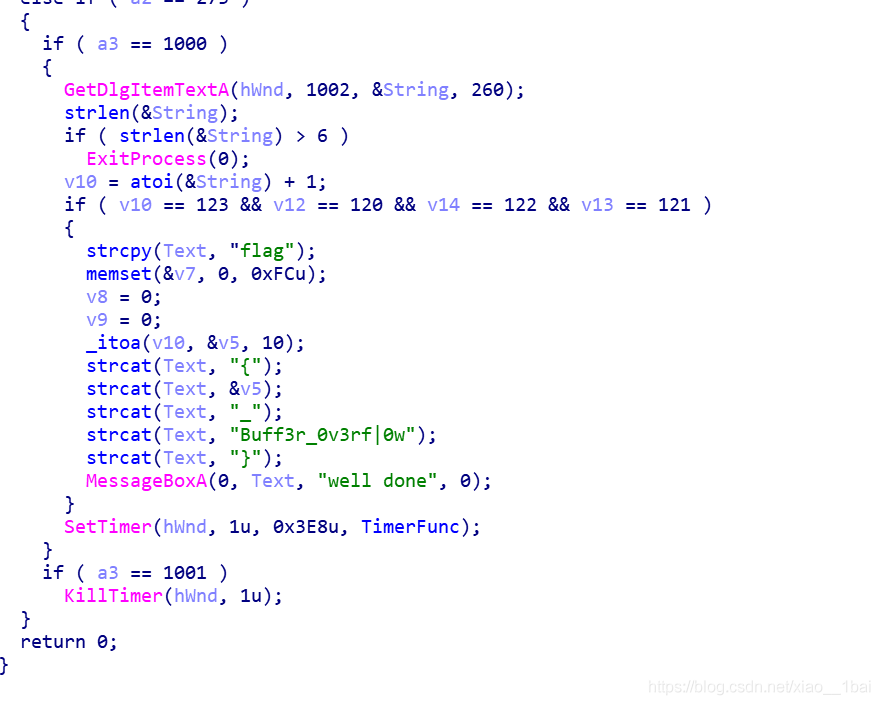
逻辑很简单,真的简单,但我就是错了:
错误1:习惯性的字符串反转,这里不是内存操作,就是打印Text这个字符串,所以不用反转:
MessageBoxA(0, Text, "well done", 0);
错误2:我把v10的123转成ASCII字符了,对应的字符是{,于是我就得到一个神奇的flag:
flag{{_Buff3r_0v3rf|0w}
这个当然是错的,关键是我还直接以为这是假的flag代码而去寻找其它函数去了。
后面就引发了一系列问题,比如设想Crack按钮按不下是不是要动态调整调整跳转等等:
结果是失败的,我都不知道它是从那个函数跳出来的!!!
后来查了资料(WP)才发现,flag的确在这里,关键是{写成123即可,不用转ASCII字符,想想也对flag就是数字字符的结合啊!!!
所以最后flag:
flag{123_Buff3r_0v3rf|0w}
至于那个crack按钮为什么按不下,可能考点不在那吧~
攻防世界流浪者:(多层交叉引用查看、函数逻辑封装、范围算法积累、函数积累)
32位PE文件无壳,照例扔入ida32中查看伪代码:
是没有主函数的题型,那就运行程序提取有用信息:

信息提取完了,一个弹框,一个判断,根据字符串我们可以找到弹框所在函数,弹框是messagebox函数,而import中只有一个messagebox,双击跟踪即可:
发现主要逻辑不在该函数处,查看该函数被谁调用,用IDA权威指南学到的新技巧,function call窗口:

找到比较函数,但是没有找到输入函数,继续查看被谁调用,继续function call窗口:
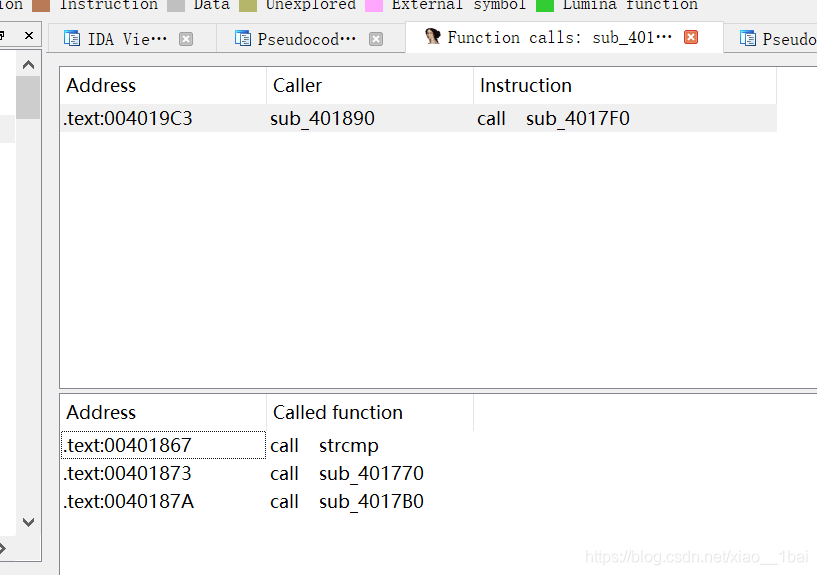
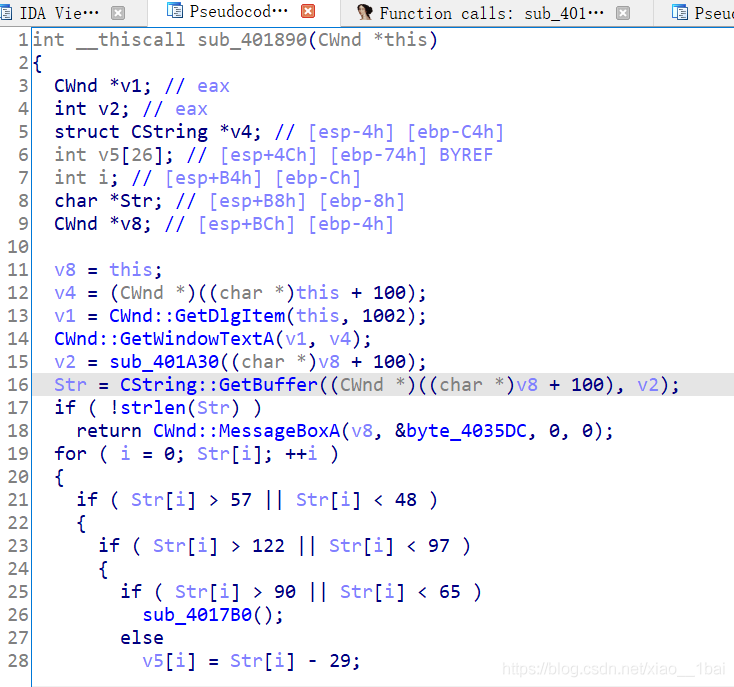
找到函数了,按照流程走,我们要判断是和输入有关的生成型flag还是简单的存储型flag,答案是前者,而且是明文密文对照类型,那就开始代码分析:
v4 = (CWnd *)((char *)this + 100);
v1 = CWnd::GetDlgItem(this, 1002); //这些系统函数一开始吓到我了,虽然系统函数一直不是什么考点,但还是认为这里会有和输入相关的东西,后来下载了API的chm文档查了一下作用,的确,后面的GetBuffer应该就是获取用户输入了,但只是获取而已,相当于scanf,知道即可,还是没什么考点
CWnd::GetWindowTextA(v1, v4);
v2 = sub_401A30((char *)v8 + 100);
Str = CString::GetBuffer((CWnd *)((char *)v8 + 100), v2);
if ( !strlen(Str) )
return CWnd::MessageBoxA(v8, &byte_4035DC, 0, 0); //弹框函数,这里犯下第一个错误,IDA双击进去的数据都是db类型的,而我们一开始看到的弹框显示的是中文,所以我们要改类型为dd类型才可以,不然就显示不了中文,所以&byte_4035DC跟踪进去后要用热键D改为dd类型再转字符。
for ( i = 0; Str[i]; ++i ) //把输入的字符串逐个判断条件并根据不同条件修改,
{
if ( Str[i] > 57 || Str[i] < 48 )
{
if ( Str[i] > 122 || Str[i] < 97 )
{
if ( Str[i] > 90 || Str[i] < 65 )
sub_4017B0(); //有一个不是弹框范围内就返回失败
else
v5[i] = Str[i] - 29; //范围在65~90中,输出结果在36~61中
}
else
{
v5[i] = Str[i] - 87; //范围在97~122中,输出结果在10~35中
}
}
else
{
v5[i] = Str[i] - 48; //范围在48~57中,输出结果在0~9中
}
}
return sub_4017F0((int)v5); //把修改后的数组结果作为参数赋给后面密文对照函数。
密文对照函数:
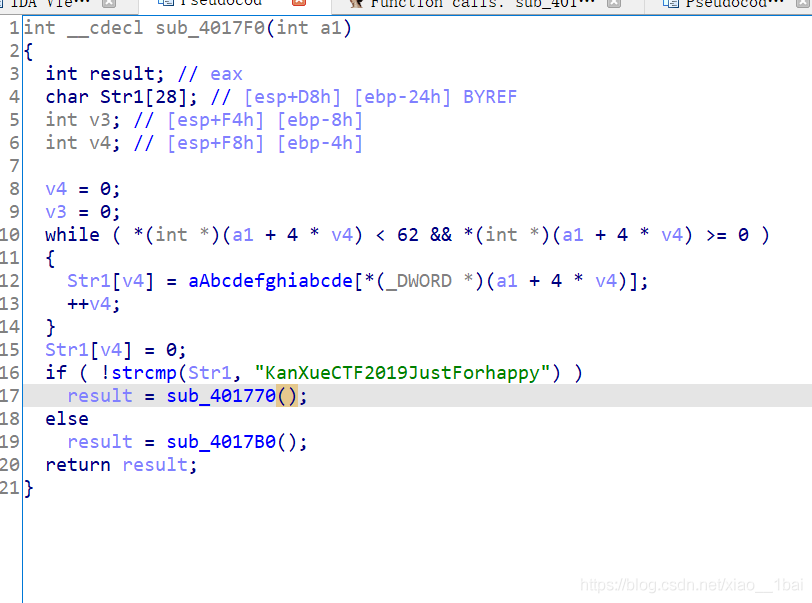
int __cdecl sub_4017F0(int a1)
{
int result; // eax
char Str1[28]; // [esp+D8h] [ebp-24h] BYREF
int v3; // [esp+F4h] [ebp-8h]
int v4; // [esp+F8h] [ebp-4h]
v4 = 0;
v3 = 0;
while ( *(int *)(a1 + 4 * v4) < 62 && *(int *)(a1 + 4 * v4) >= 0 )
{
Str1[v4] = aAbcdefghiabcde[*(_DWORD *)(a1 + 4 * v4)]; //aAbcdefghiabcde双击跟踪是abcdefghiABCDEFGHIJKLMNjklmn0123456789opqrstuvwxyzOPQRSTUVWXYZ'的62位长度字符串,也就不难解释while判断条件的<62了,这里还犯下第二,第三个错误。第二个错误是一开始没看出来这是个数组,*(_DWORD *)(a1 + 4 * v4)是取索引而已,a1是数组头地址,现在要知道带方括号的[]基本都是数组取字符! 第三个错误是这里*(_DWORD *)(a1 + 4 * v4)型我是真的搞不懂,明明a1是int型,还是数组头地址,它前面的(_DWORD *)把它又变成了uint32型地址,先不说这多此一举,关键是int型地址+1就是加4个字节啊!这里直接+4*v4,那不是一下就跳过4个a1数组元素了吗!关键是我调试IDA既然没有问题!!!好吧,只能认为是IDA分析出错了,
++v4;
}
Str1[v4] = 0;
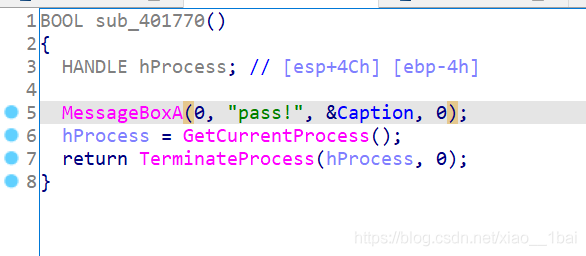
if ( !strcmp(Str1, "KanXueCTF2019JustForhappy") ) //从字典中获取的字符与明文对比,符合就是flag
result = sub_401770();
else
result = sub_4017B0();
return result;
}
所以现在就是字典和明文的加密关系逆向题了,这里犯下第四个错误,这类明文字典密文题目逆向要从密文出发,找到对应的字典下标,再用下标数组反逻辑逆向出明文:
第一步从密文出发,找到对应的字典下标:
key1="abcdefghiABCDEFGHIJKLMNjklmn0123456789opqrstuvwxyzOPQRSTUVWXYZ"
key2="KanXueCTF2019JustForhappy"
suoyin=[]
suoyin2=[]
v4=0
for i in range(len(key2)):
for a in range(len(key1)):
if key2[i] == key1[a]:
suoyin.append(a)
print(suoyin)
#print(len(suoyin))
这是我的做法,逐个对比,找出下标,当然后面还学到更好的.index(str)方法,后面会讲。输出:
[19, 0, 27, 59, 44, 4, 11, 55, 14, 30, 28, 29, 37, 18, 44, 42, 43, 14, 38, 41, 7, 0, 39, 39, 48]
这就是字典索引了,然后后面逆向出明文时就犯错了。逆向,是从底部出发向上走,也是是我们一开始掌握的是结果,要从条件中有关结果的判断往上走,而不是从0~1000这样从上往下加密然后提取出对应条件的下标,虽然结果一样,但是流程就差太多了:
suoyin2=[19, 0, 27, 59, 44, 4, 11, 55, 14, 30, 28, 29, 37, 18, 44, 42, 43, 14, 38, 41, 7, 0, 39, 39, 48]
v5=0
flag=""
for i in suoyin2: //这里的判断条件是从从条件中有关结果的判断往上走,因为前面写出了结果的范围,所以我们应该用结果的范围向上走。
if i >= 0 and i <= 9:
v5=i+48
elif i >= 10 and i <= 35:
v5=i+87
elif i >= 36:
v5=i+29
flag+=chr(v5)
print(flag)
输出:
j0rXI4bTeustBiIGHeCF70DDM
别人更好的利用.index获取索引下标的脚本:
table = "abcdefghiABCDEFGHIJKLMNjklmn0123456789opqrstuvwxyzOPQRSTUVWXYZ"
s = "KanXueCTF2019JustForhappy"
ff = []
for i in s:
ff.append(table.index(i)) //这里我不得不说真的妙,我是一时想不到,用字符串内置函数.index(str)完美输出索引,比我快多了。
flag = ""
for i in ff:
if 0 <= i <= 9:
flag += chr(i + 48)
elif 9 < i <= 35:
flag += chr(i + 87)
elif i > 36:
flag += chr(i + 29)
print (flag)
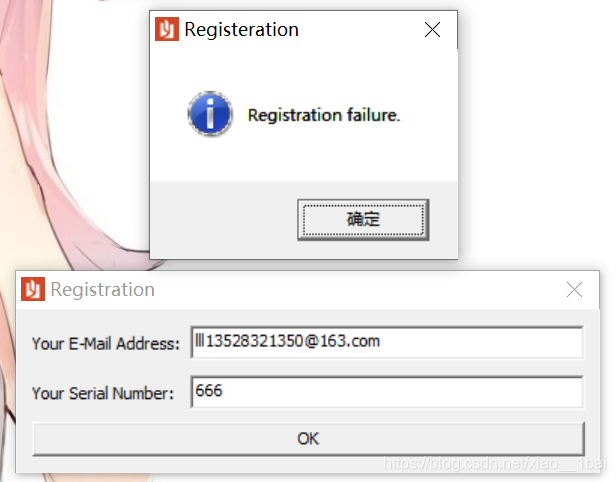
攻防世界srm-50:
windows的32位程序,无壳,运行一下判断主要展示信息,看样子以为是逆向工程核心原理的例题,就是绕过注册条件的,结果后面发现不是:
知道了一些特定字符串,和判断语句,信息够了,照例扔入IDA32中查看伪代码,有main函数看main函数,这里是Winmain函数:

跟踪,无果,照例下一步查看string窗口,锁定一开始展示字符串的位置:
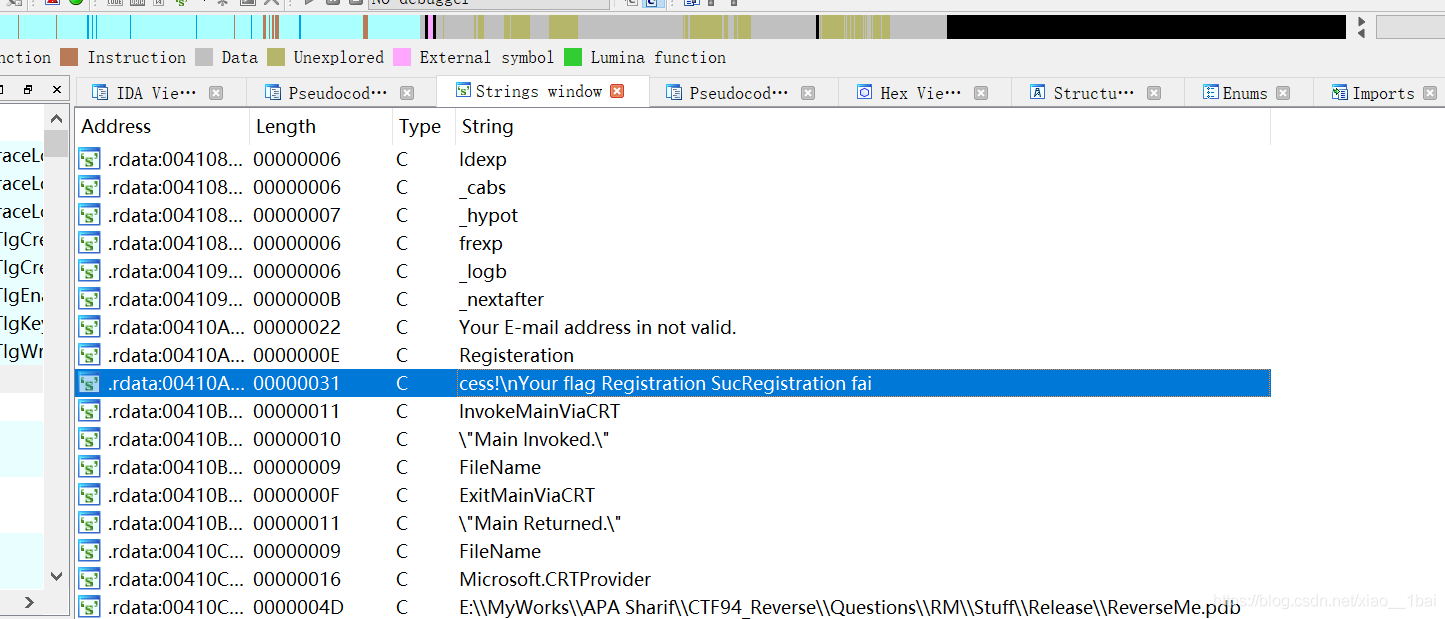
找到了,双击跟踪,然后跟踪到引用它的函数:
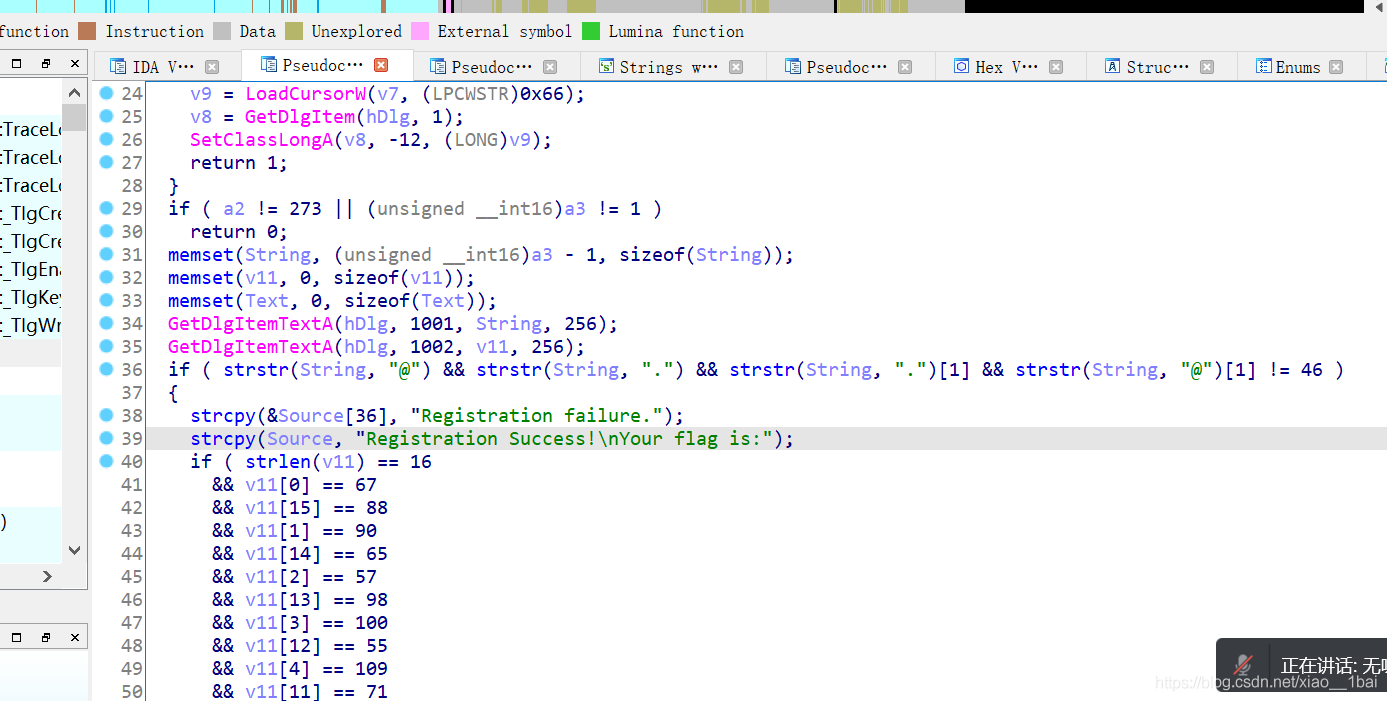
答案很明显了,flag就是Registration Success!\nYour flag is:语句的下面一串字符,转字符后按序号排好即可:
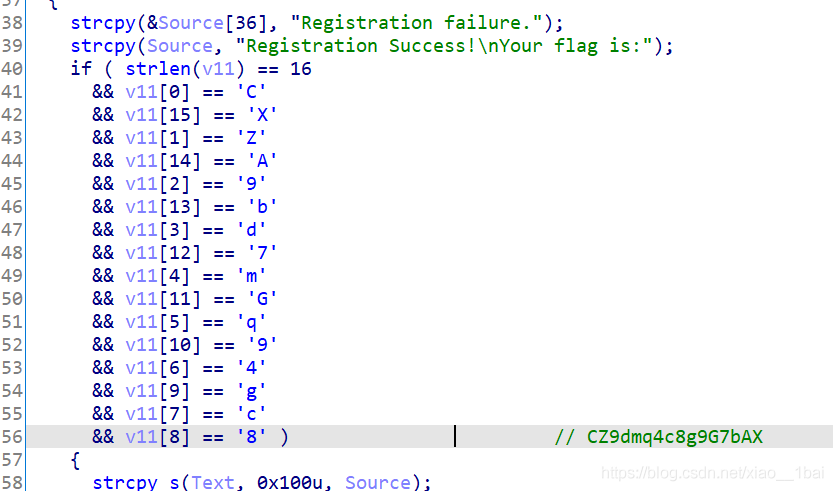
攻防世界hackme:(可变参数混淆、随机抽取比较、取特定位数算法)
64位ELF文件无壳,照例扔入IDA64中查看伪代码信息,有main函数看main函数,结果没有main函数:
没有main函数就运行程序收集显示信息:

找到两个字符串,直接在strings窗口双击跟踪,找到主要逻辑函数:
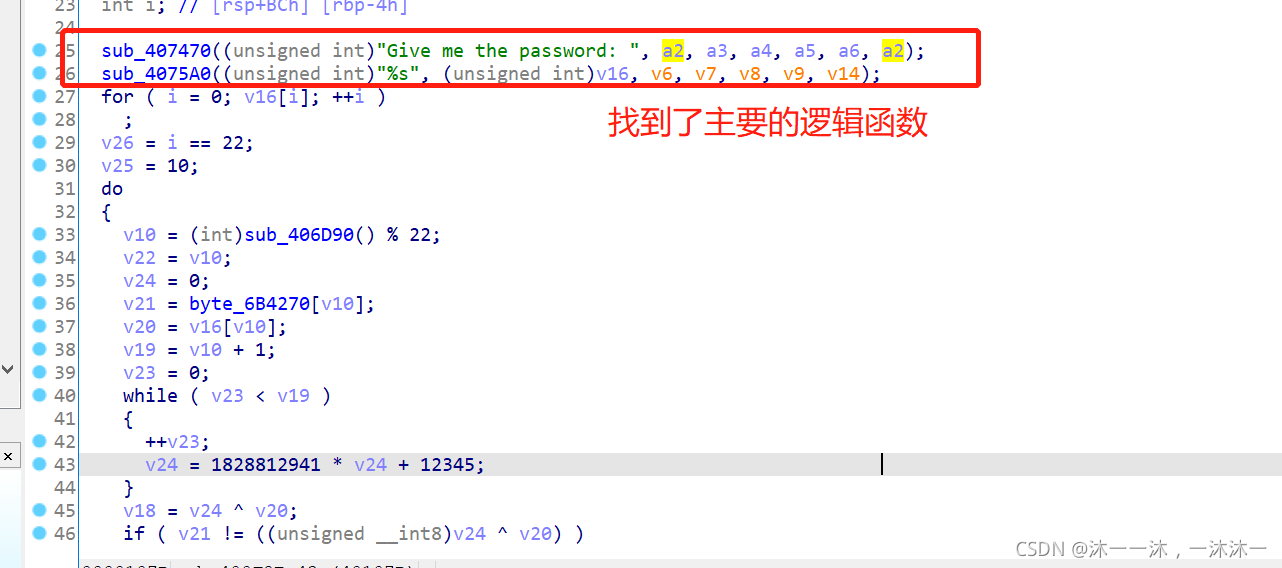
这里积累第一个经验:如上图红框所示
sub_407470((unsigned int)“Give me the password: “, a2, a3, a4, a5, a6, a2);
sub_4075A0((unsigned int)”%s”, (unsigned int)v16, v6, v7, v8, v9, v14);
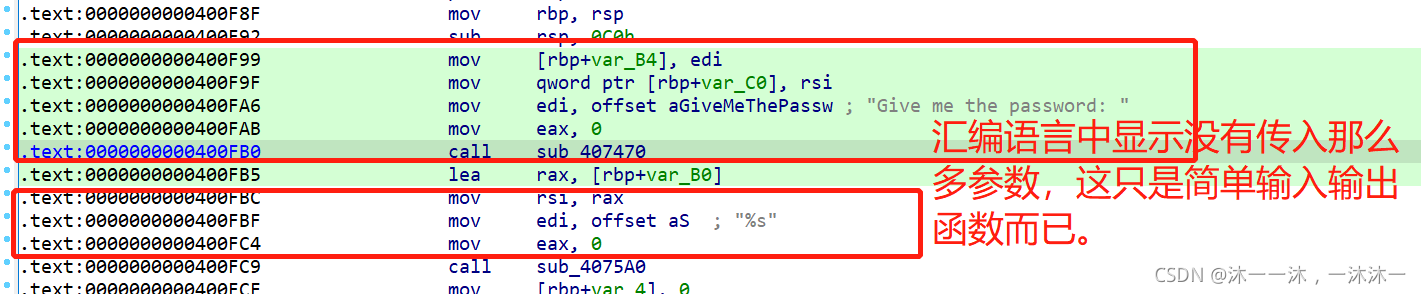
人傻了,这么多个参数。双击跟踪进去不是嵌套就是复杂代码,查看反汇编,好像又没有调用这么多参数。以为是什么复杂的高端函数,开始怕了。结果才发现,这就是根据C语言函数可变参数的特性反汇编出来的,其实就是普通的输出和输入函数而已。果然还是自己经验太少,太菜了~。
跨过这个坎继续往下走,第一个红框v10范围是0~21,第二个红框数组又以v10作为下标,猜测是一个22的遍历数组操作,第三个红框是判断,所以逆向逻辑很简单。关键是最外面的v25的10次循环后面查了资料说是v10是一个随机数,范围也的确是0 ~ 21,但是不是顺序来取值的,结合外面v25的10循环就是随机从数组中抽取10个下标来比较,那我们直接顺序取整个下标操作也是一样的。
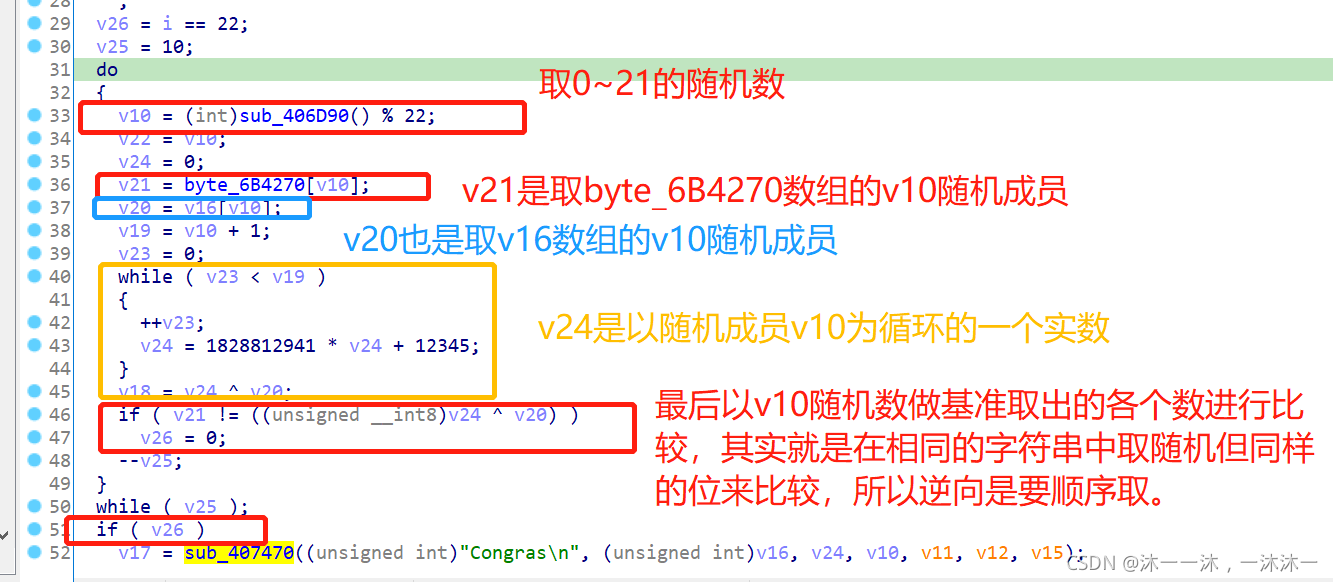
根据前面回顾的逆向解题流程:
第一步确定Flag字符数量。
第二步找到已确定的字符串作为基点来反推falg字符。
第三步找出逻辑中与flag直接相关的部分,该部分可以正向爆破或者从尾到头的反向逻辑。
然后找到与flag没有直接关联的部分,该部分无需逆向逻辑,直接正向流程复现即可。
按照流程来即可写出逆向逻辑脚本:
key1=[95, 242, 94, 139, 78, 14, 163, 170, 199, 147, 129, 61, 95, 116, 163, 9, 145, 43, 73, 40, 147, 103]
flag=""
for i in range(10):
for a in range(22):
v15=0
v12=key1[a]
v10=a+1
v14=0
for i in range(v10):
v14+=1
v15=1828812941*v15+12345
flag+=chr((v12^v15)&0xff)
print(flag)
最后这里积累第二个经验:
一开始我flag+=chr((v12^v15)&0xff)没加 &0xff,然后报错,我以为源程序中会有溢出导致的数重置,但是想起程序是64位的,不应该超范围啊。然后我看到源代码有__int8这个限制,这是取前8位啊,可是python中怎么取前8位呢?查了资料才发现有&0xff这种方法,因为&在Python中是逻辑与运算,所以与的时候就保留了v12 ^ v15的前8位,就达到取前8位的目的了,取前16,32位都可以套用这个方法。

结果:(这里我一开始没理解是随机抽取10次,所以我照搬,结果循环了10次)

带壳题目类型
脱壳后逻辑平铺:
攻防世界simple-unpack脱壳:(工具脱壳)
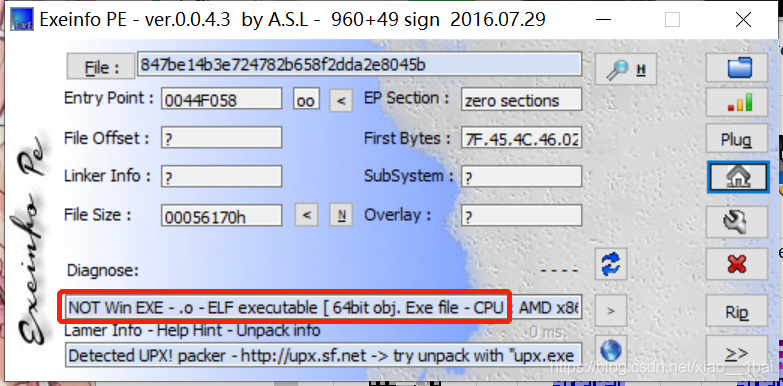
显示说探测到UPX壳,由于第一次做带壳的题目,所以查到了以下资料:
UPX (the Ultimate Packer for eXecutables)是一款先进的可执行程序文件压缩器,压缩过的可执行文件体积缩小50%-70% ,这样减少了磁盘占用空间、网络上传下载的时间和其它分布以及存储费用。 通过 UPX 压缩过的程序和程序库完全没有功能损失和压缩之前一样可正常地运行,对于支持的大多数格式没有运行时间或内存的不利后果。 UPX 支持许多不同的可执行文件格式 包含 Windows 95/98/ME/NT/2000/XP/CE 程序和动态链接库、DOS 程序、 Linux 可执行文件和核心。
UPX是一个压缩工具,好在今天准备看《逆向核心工程原理》这本书的压缩部分,原来这就是压缩,之前也学了一点PE文件格式,知道了一些文件资源的存放位置,那么下一步就是脱壳了。
查到了kali中关于UPX的脱壳命令:
upx -d filename
脱完壳就可以直接IDA查看了,FLAG直接就显示出来了:
IDA等二进制分析器应该都需要完整的文件格式才能分析,压缩后(加壳)的文件由于并没有破坏可执行文件的格式规则,所以还是可以运行的,用IDA分析加壳后的文件就分析不出来了,如图:
攻防世界Windows_Reverse1:(工具脱壳、不能直接运行、寄存器传参、地址差值+数组组合遍历字符串、字符ASCII码做索引、ASCII码表相关)
下载附件,照例扔入exeinfope中查看信息:
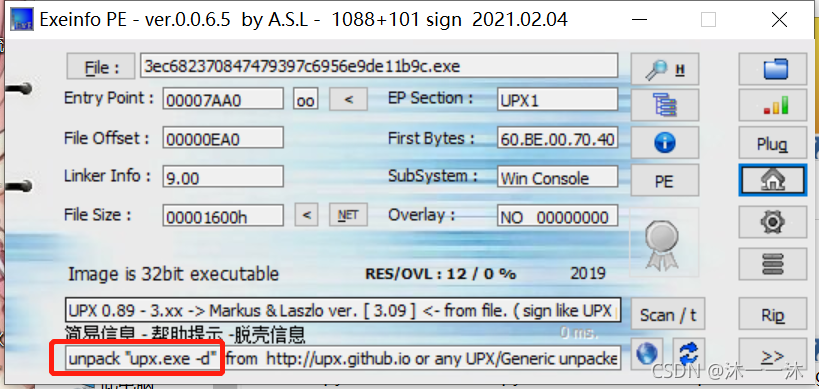
UPX壳,32位windows中,扔入我的kali中先用命令upx -d 文件名 脱壳先:
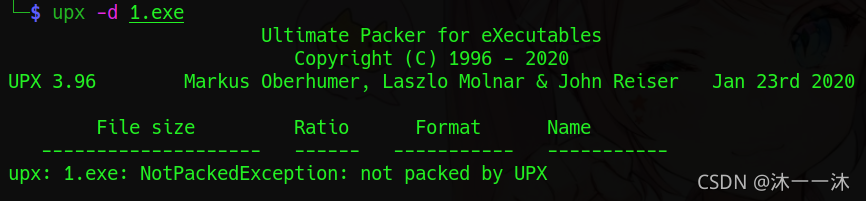
双击运行不了,查看不了起始信息,看了资料说:
UPX的壳,手动脱壳或者脱壳机脱壳,但发现脱完壳的程序在win7下打不开,即使是显示没壳(这里后来查到win7包括以上版本开启了ASLR(地址随机化),winxp就没有,如果程序采用绝对地址,在win7和win10上就运行不了),直接IDA启动,IDA里不爆红就没事。
不管了,IDA分析伪代码:
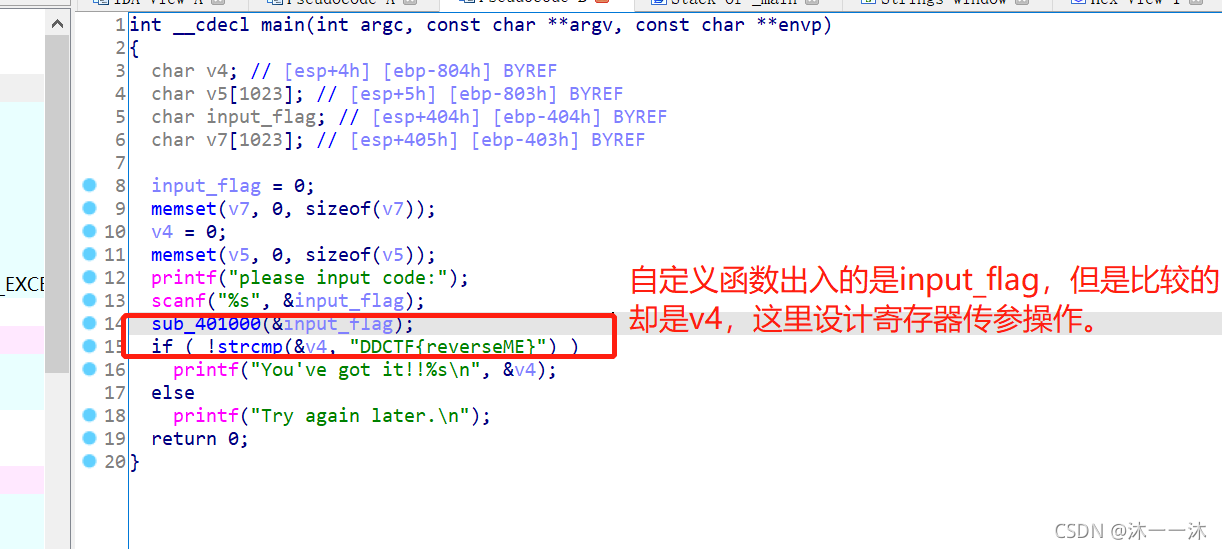
代码一目了然,神奇的是红框框起来的地方。这里积累第一个经验:出入的是input_flag(v6改名而来),结果比较的是v4,一开始我以为是IDA出了错误,后来才发现题目考的就是我以前一直说得地址偏移间接操作。v4存入了寄存器中,寄存器再作为参数传入关键自定义函数中,IDA没有反汇编出寄存器参数,用的是寄存器操作。
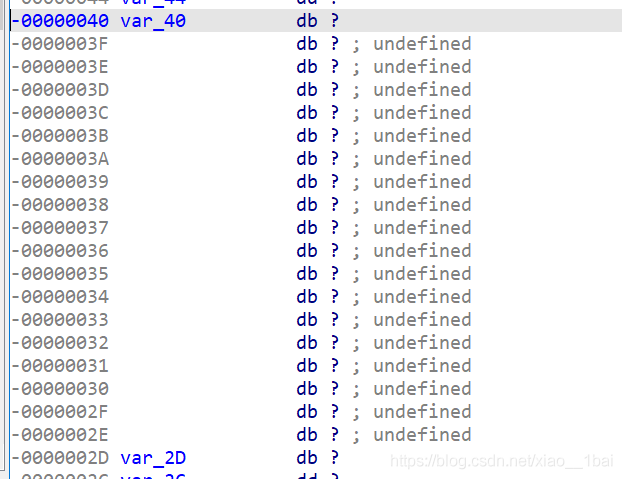
input_flag点进去-00000404 var_404 db ?
v4点进去-00000804 var_804 db ?
这里积累第二个经验:
查看反汇编代码,前面有sub esp, 804h,所以esp+804h处可以说是基址EBP的地方,这里的[esp+82Ch+input_flag]和[esp+830h+v4]只是在esp+804h的EBP基础上加上中间代码的指令字节长度而已,本质就是取input_flag和v4参数。

这里Input_flag和v4分别给了eax和ecx,我们查看sub_401000函数的反汇编代码和函数图都可以发现ECX(v4)被使用了:

所以我们分析逻辑代码:(地址差值+数组组合遍历字符串,单个字符ASCII码作为索引)
unsigned int __cdecl sub_401000(const char *input_flag)
{
_BYTE *v1; // ecx即外部v4,这里用v1来接受寄存器ecx的值,且值为0
unsigned int v2; // edi
unsigned int result; // eax
int v4; // ebx
v2 = 0;
result = strlen(input_flag);
if ( result )
{
v4 = input_flag - v1; //这里积累第三个经验:地址减地址取差值。这里v4是Input_flag和v1(主函数v4)的地址的差值,差值刚好在32,后面梳理完后发现byte_402FF8是ASCII码表,32后是可打印字符
do
{
*v1 = byte_402FF8[(char)v1[v4]]; //这里积累第四个经验:这里V1作为地址和v4作为数组v1[v4]执行的是v1+v4的操作,就是v4+v1=input_flag啊。因为数组a[b]本质就是在数组头地址a加上偏移量b来遍历数组的,所以这里是一种遍历input_flag的新操作,至于最外面的byte_402FF8[]数组框,应该这样理解,v1[v4]逐个取input_flag的单个字符,这个字符的ascii码作为偏移继续在byte_402FF8[]数组中寻址。(PS:这不是Python中list.index()函数可以用字符查找对应索引!),最后ECX寄存器的v1接受了新的flag。
++v2;
++v1;
result = strlen(input_flag);
}
while ( v2 < result );
}
return result;
}
也附上别人博客的解释:(本是字符本身作为索引)
1:a1是通过压栈的方式传递的参数; v1是通过寄存器保存地址的方式传递的参数。
2:最令人迷惑的便是v1[v4]这个地方. v1是一个地址, v4是a1和v1两个地址间的差值. 地址的差值是怎么成为一个数组的索引的呢 ?
3:这里卡了我好长时间, 之后我突然意识到, v1[v4]和v1+v4是等价的, 而在循环刚开始的时候v1+v4等于a1, 随着v1的递增,v1[v4]也会遍历a1数组中的各个元素的地址。
4:而地址又怎么能作为数组的索引呢? 这里就是 IDA 背锅了, 换言之, 做题还是不能太依赖于反编译后的伪代码. 查看了反汇编代码后, 发现其实是将a1字符串中的字符本身作为byte_402FF8的索引, 取值后放入v1数组中。
双击跟踪byte_402FF8[]数组:
可以看到前面乱码的?,后面倒是有字符串,数组地址偏移从0x00402FF8~0x00403078。
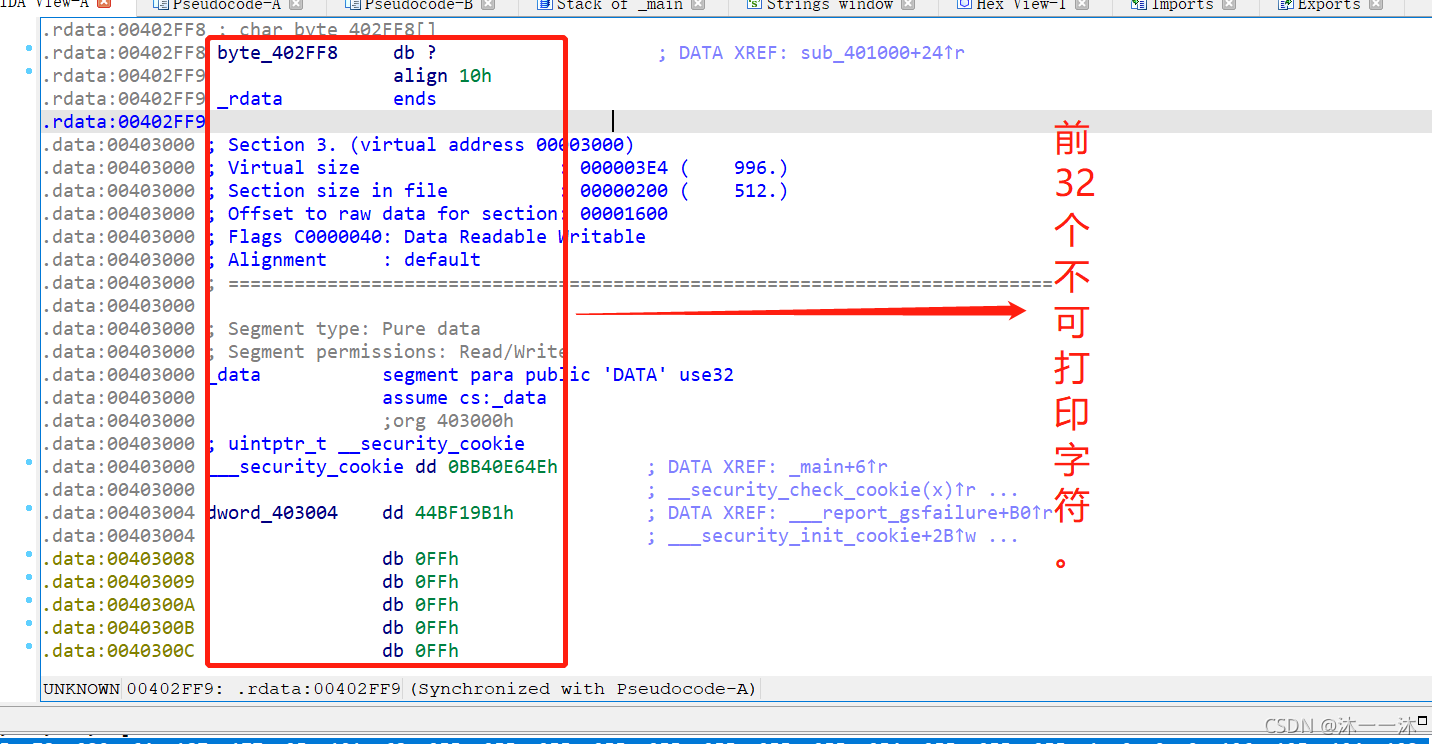

这里积累第5个经验:(ASCII码表可视字符范围)
ASCII编码表里的可视字符就得是32往后了, 所以, byte_402FF8里凡是位于32以前的数统统都是迷惑项. 不会被索引到的,而这里0x00402FF8~0x00403017刚好是32个字符。那么后面有字符串就可以解释通了,它们是连在一起的。
数组有了,逻辑有了,逆向逻辑很简单,先用IDA脚本打印0x00402FF8~0x00403078数组处的地址内容先:
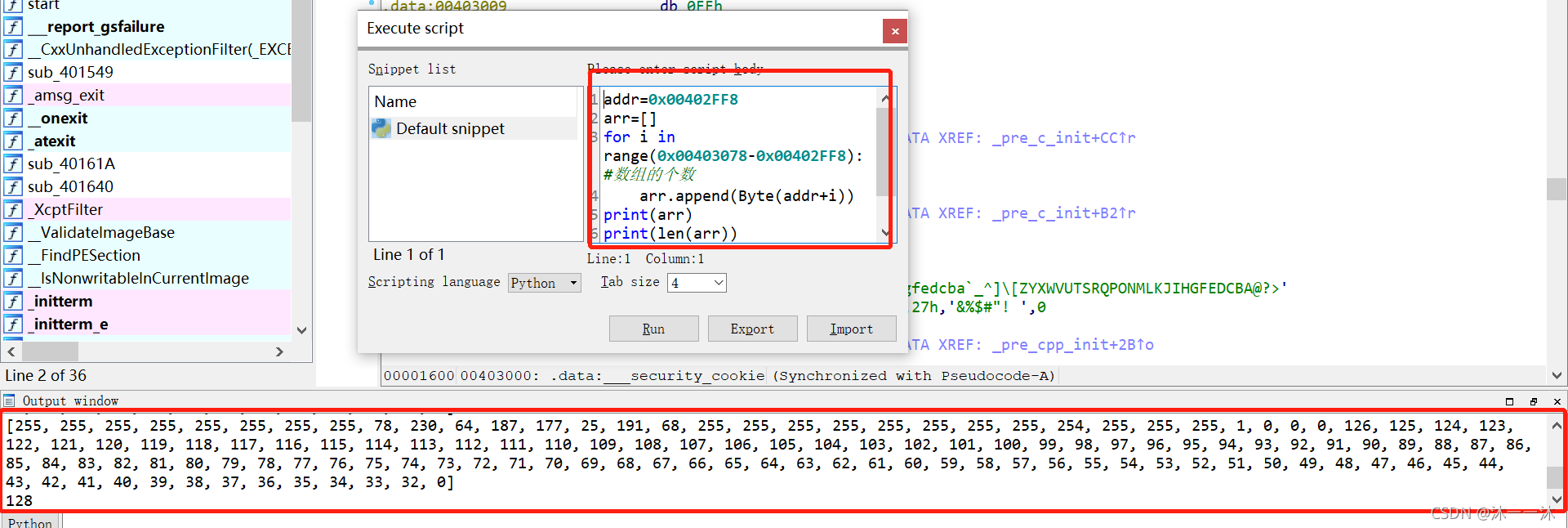
复制数组内容写逆向脚本:
key1=[255, 255, 255, 255, 255, 255, 255, 255, 78, 230, 64, 187, 177, 25, 191, 68, 255, 255, 255, 255, 255, 255, 255, 255, 254, 255, 255, 255, 1, 0, 0, 0, 126, 125, 124, 123, 122, 121, 120, 119, 118, 117, 116, 115, 114, 113, 112, 111, 110, 109, 108, 107, 106, 105, 104, 103, 102, 101, 100, 99, 98, 97, 96, 95, 94, 93, 92, 91, 90, 89, 88, 87, 86, 85, 84, 83, 82, 81, 80, 79, 78, 77, 76, 75, 74, 73, 72, 71, 70, 69, 68, 67, 66, 65, 64, 63, 62, 61, 60, 59, 58, 57, 56, 55, 54, 53, 52, 51, 50, 49, 48, 47, 46, 45, 44, 43, 42, 41, 40, 39, 38, 37, 36, 35, 34, 33, 32, 0]
key2="DDCTF{reverseME}"
flag=""
for i in key2:
flag+=chr(key1[ord(i)]) //字符的ASCII码作为索引
print("flag{"+flag+"}")
结果:

攻防世界Replace:(工具脱壳、解题逆向模板、>> 和 % 运算符算法积累、正向爆破)
有壳,用Kali的upx -d脱壳,然后照例扔入IDA32中查看伪代码,有main函数看main函数:(脱壳后不能运行,因为伪代码信息足够,所以就不用修复了)
直接跟踪第二个红框自定义函数:
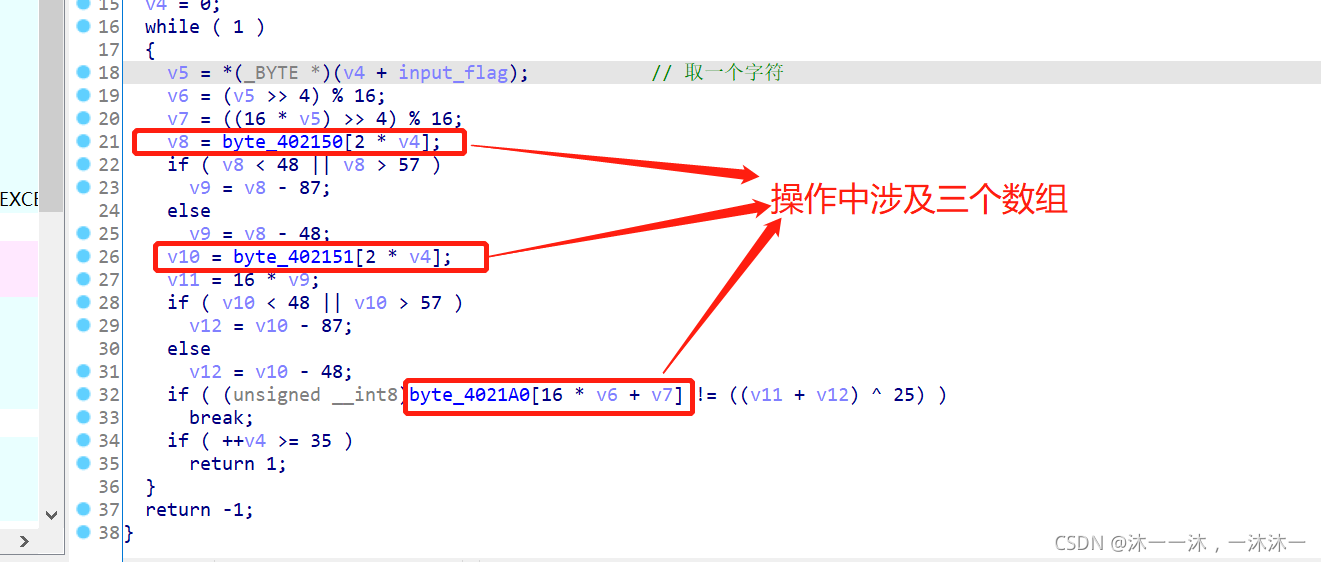
主要逻辑在上面了,涉及三个数组,用IDA内嵌脚本dump下来,这里积累第一个经验:数组dump下载的时候dump到0字符结尾处,不要怕dump多,就怕dump少。
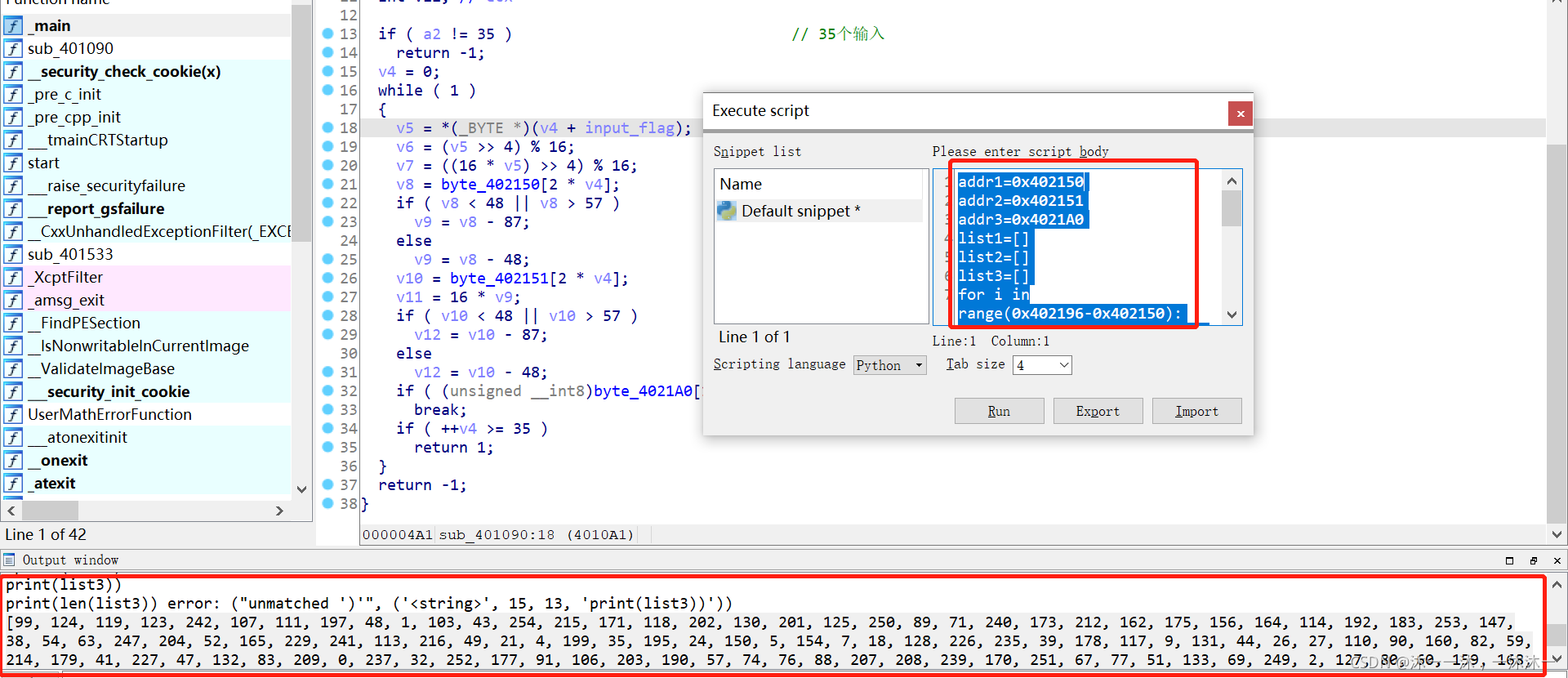
开始编写逆向逻辑脚本,这里积累第二个经验:主要回顾一下每一步的思路,给日后自己增添一些解题模板。
第一步确定Flag字符数量,第一个红框处得到flag数量是35。
第二步找到已确定的比较字符串作为基点来反推flag字符,如第二个红框处。
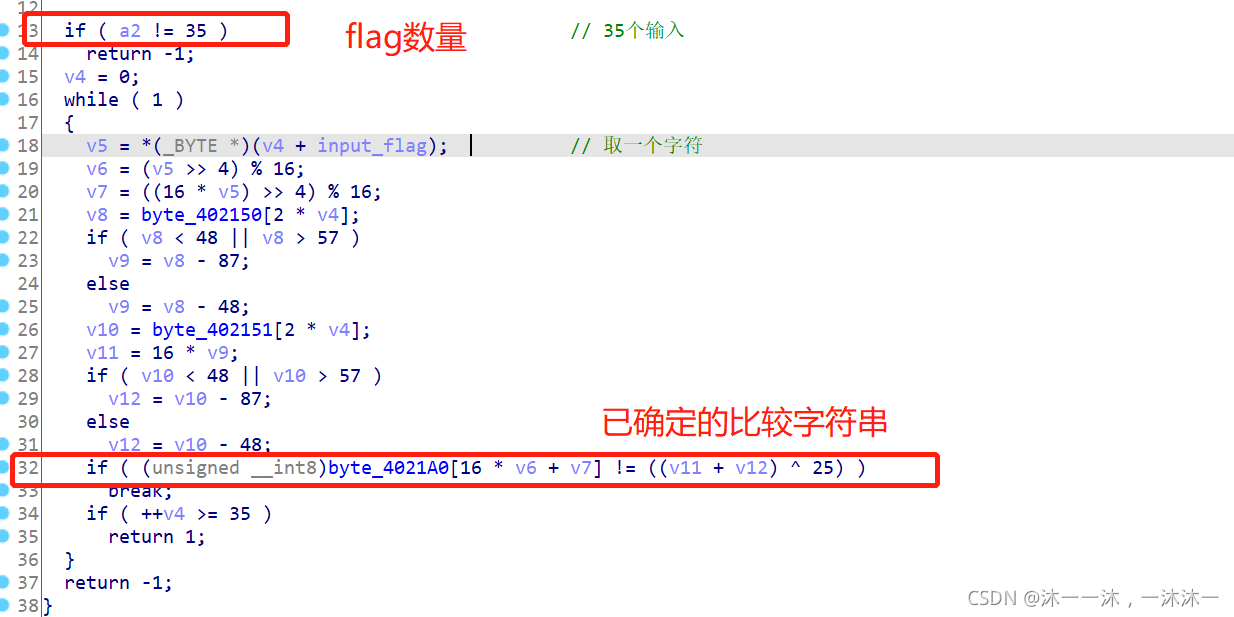
第三步找出逻辑中与flag直接相关的部分,该部分可以正向爆破或者从尾到头的反向逻辑,如第一个红框所示。然后找到与flag没有直接关联的部分,该部分无需逆向逻辑,直接正向流程复现即可,如第二个红框所示。
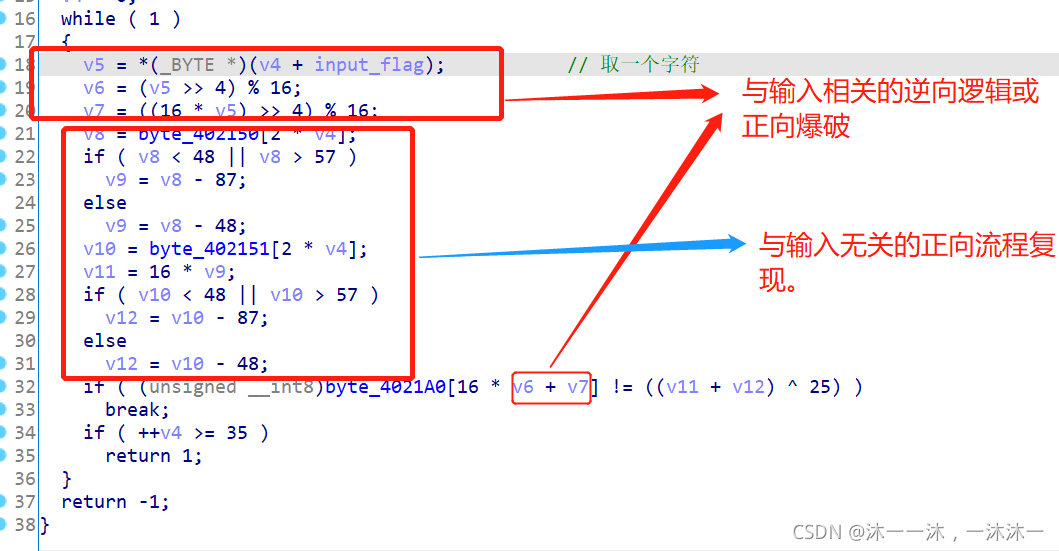
梳理完这些之后就可以写脚本了:
脚本1,爆破。这里积累第三个经验:由于用了取余 % 运算,所以采用枚举正向爆破的方法,让flag中的每一个字符遍历常用的字符(ascii码表中32-126),带入加密算法,如果成功,就把这个flag存入。
list1=[50, 97, 52, 57, 102, 54, 57, 99, 51, 56, 51, 57, 53, 99, 100, 101, 57, 54, 100, 54, 100, 101, 57, 54, 100, 54, 102, 52, 101, 48, 50, 53, 52, 56, 52, 57, 53, 52, 100, 54, 49, 57, 53, 52, 52, 56, 100, 101, 102, 54, 101, 50, 100, 97, 100, 54, 55, 55, 56, 54, 101, 50, 49, 100, 53, 97, 100, 97, 101, 54]
list2=[97, 52, 57, 102, 54, 57, 99, 51, 56, 51, 57, 53, 99, 100, 101, 57, 54, 100, 54, 100, 101, 57, 54, 100, 54, 102, 52, 101, 48, 50, 53, 52, 56, 52, 57, 53, 52, 100, 54, 49, 57, 53, 52, 52, 56, 100, 101, 102, 54, 101, 50, 100, 97, 100, 54, 55, 55, 56, 54, 101, 50, 49, 100, 53, 97, 100, 97, 101, 54]
list3=[99, 124, 119, 123, 242, 107, 111, 197, 48, 1, 103, 43, 254, 215, 171, 118, 202, 130, 201, 125, 250, 89, 71, 240, 173, 212, 162, 175, 156, 164, 114, 192, 183, 253, 147, 38, 54, 63, 247, 204, 52, 165, 229, 241, 113, 216, 49, 21, 4, 199, 35, 195, 24, 150, 5, 154, 7, 18, 128, 226, 235, 39, 178, 117, 9, 131, 44, 26, 27, 110, 90, 160, 82, 59, 214, 179, 41, 227, 47, 132, 83, 209, 0, 237, 32, 252, 177, 91, 106, 203, 190, 57, 74, 76, 88, 207, 208, 239, 170, 251, 67, 77, 51, 133, 69, 249, 2, 127, 80, 60, 159, 168, 81, 163, 64, 143, 146, 157, 56, 245, 188, 182, 218, 33, 16, 255, 243, 210, 205, 12, 19, 236, 95, 151, 68, 23, 196, 167, 126, 61, 100, 93, 25, 115, 96, 129, 79, 220, 34, 42, 144, 136, 70, 238, 184, 20, 222, 94, 11, 219, 224, 50, 58, 10, 73, 6, 36, 92, 194, 211, 172, 98, 145, 149, 228, 121, 231, 200, 55, 109, 141, 213, 78, 169, 108, 86, 244, 234, 101, 122, 174, 8, 186, 120, 37, 46, 28, 166, 180, 198, 232, 221, 116, 31, 75, 189, 139, 138, 112, 62, 181, 102, 72, 3, 246, 14, 97, 53, 87, 185, 134, 193, 29, 158, 225, 248, 152, 17, 105, 217, 142, 148, 155, 30, 135, 233, 206, 85, 40, 223, 140, 161, 137, 13, 191, 230, 66, 104, 65, 153, 45, 15, 176, 84, 187, 22, 72, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
v4=0
flag=""
for i in range(35):
v8=list1[2*i]
if v8 < 48 or v8 > 57:
v9=v8 - 87
else:
v9=v8 - 48
v10=list2[2*i]
v11=16*v9
if v10 <48 or v10 > 57:
v12=v10-87
else:
v12=v10-48
v4=((v11+v12)^25) #这里前面都是与flag没有直接关联的正向流程复现
for a in range(32,127): #取余类型正向爆破,如果符合比较,就获取对应字符。
v5=a
v6=(v5>>4)%16 #逻辑都是一样的,因为是正向爆破
v7=((16*v5)>>4)%16
if list3[16*v6+v7] == v4:
flag+=chr(a)
print(flag)
脚本2:这里积累第四个经验:>> 运算符其实是不带余数的除法 / 算法,单取整数部分。% 运算符其实是不带整数的求余运算,单取余数部分。
所以这里 v6 = (v5 >> 4) % 16 是除以16后的整数部分, v7 = ((16 * v5) >> 4) % 16 是乘16后除16再取16内的余数,也就是直接取16内的余数。一个取整数,一个取余数,所以他们的逆向算法就是16 * v6 + v7,就是最后数组byte_4021A0[16 * v6 + v7]的下标。
(既然v5 >> 4相当于v5除以16取整数部分,是不带余数的除法 / 算法。顺带说一下,v5 & 0xf 相当于v5除以16取余数部分,是完全的求余%算法,这里0xf是4位所以为16。)
所以flag就是由这些下标组成 !
因此如果有些伪代码中前面的运算逻辑如果和后面的运算逻辑如果有相似之处,要试着判断他们是反向逻辑,因为出题者的意图往往如此。
list1=[50, 97, 52, 57, 102, 54, 57, 99, 51, 56, 51, 57, 53, 99, 100, 101, 57, 54, 100, 54, 100, 101, 57, 54, 100, 54, 102, 52, 101, 48, 50, 53, 52, 56, 52, 57, 53, 52, 100, 54, 49, 57, 53, 52, 52, 56, 100, 101, 102, 54, 101, 50, 100, 97, 100, 54, 55, 55, 56, 54, 101, 50, 49, 100, 53, 97, 100, 97, 101, 54]
list2=[97, 52, 57, 102, 54, 57, 99, 51, 56, 51, 57, 53, 99, 100, 101, 57, 54, 100, 54, 100, 101, 57, 54, 100, 54, 102, 52, 101, 48, 50, 53, 52, 56, 52, 57, 53, 52, 100, 54, 49, 57, 53, 52, 52, 56, 100, 101, 102, 54, 101, 50, 100, 97, 100, 54, 55, 55, 56, 54, 101, 50, 49, 100, 53, 97, 100, 97, 101, 54]
list3=[99, 124, 119, 123, 242, 107, 111, 197, 48, 1, 103, 43, 254, 215, 171, 118, 202, 130, 201, 125, 250, 89, 71, 240, 173, 212, 162, 175, 156, 164, 114, 192, 183, 253, 147, 38, 54, 63, 247, 204, 52, 165, 229, 241, 113, 216, 49, 21, 4, 199, 35, 195, 24, 150, 5, 154, 7, 18, 128, 226, 235, 39, 178, 117, 9, 131, 44, 26, 27, 110, 90, 160, 82, 59, 214, 179, 41, 227, 47, 132, 83, 209, 0, 237, 32, 252, 177, 91, 106, 203, 190, 57, 74, 76, 88, 207, 208, 239, 170, 251, 67, 77, 51, 133, 69, 249, 2, 127, 80, 60, 159, 168, 81, 163, 64, 143, 146, 157, 56, 245, 188, 182, 218, 33, 16, 255, 243, 210, 205, 12, 19, 236, 95, 151, 68, 23, 196, 167, 126, 61, 100, 93, 25, 115, 96, 129, 79, 220, 34, 42, 144, 136, 70, 238, 184, 20, 222, 94, 11, 219, 224, 50, 58, 10, 73, 6, 36, 92, 194, 211, 172, 98, 145, 149, 228, 121, 231, 200, 55, 109, 141, 213, 78, 169, 108, 86, 244, 234, 101, 122, 174, 8, 186, 120, 37, 46, 28, 166, 180, 198, 232, 221, 116, 31, 75, 189, 139, 138, 112, 62, 181, 102, 72, 3, 246, 14, 97, 53, 87, 185, 134, 193, 29, 158, 225, 248, 152, 17, 105, 217, 142, 148, 155, 30, 135, 233, 206, 85, 40, 223, 140, 161, 137, 13, 191, 230, 66, 104, 65, 153, 45, 15, 176, 84, 187, 22, 72, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
v4=0
flag=""
for i in range(35):
v8=list1[2*i]
if v8 < 48 or v8 > 57:
v9=v8 - 87
else:
v9=v8 - 48
v10=list2[2*i]
v11=16*v9
if v10 <48 or v10 > 57:
v12=v10-87
else:
v12=v10-48
v4=((v11+v12)^25) #这里前面都是与flag没有直接关联的正向流程复现
flag+=chr(list3.index(v4)) #这里知道逆向算法发现对应下标后,直接Index对要比较的字符v4取索引即可,flag就是索引中下标的内容。
print(flag)
结果:
![]()
花指令题目类型
自定义函数自修改:
攻防世界BABYRE:(函数名称暗示、IDA热键重新反汇编、IDA动态调试、栈地址连续小数组)
这题应该是我第一次接触的花指令题,怪兴奋的!目前我的理解是代码和数据混淆,让IDA误认为是数据而反汇编出错。
64位ELF文件,无壳,扔入IDA64位中查看伪代码:
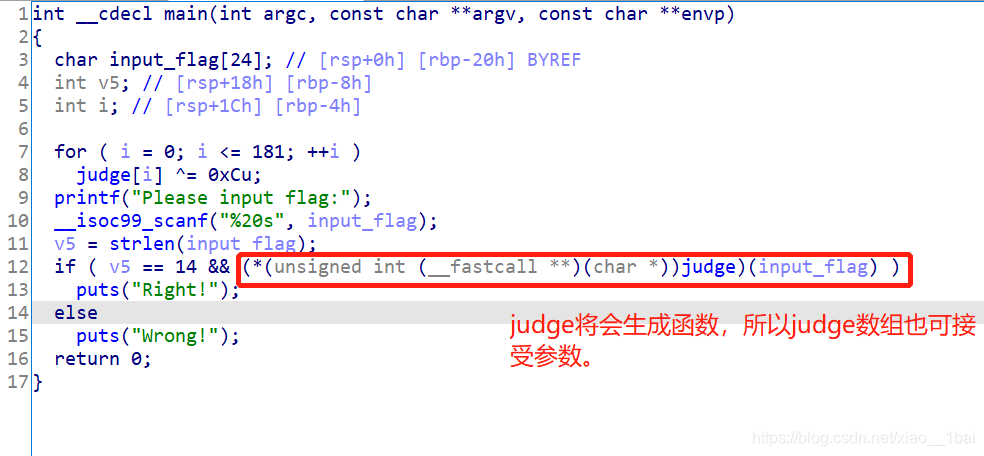
这里犯下第一个错误:
由于是第一次接触花指令,对 (*(unsigned int (__fastcall **)(char *))judge)(input_flag) ) 这一行代码我看了好久愣是没看懂,input_flag是我们输入的字符串,judge中文暗示是判断,根据以前做题这种中文类名字的确是暗示,可前面显示的judge[i] 这摆明是个数组啊,judge(input_flag) 不就变成了数组首地址加Input_flag了吗?还有这种玩法???
然后我就去看wp了(笑~):
他们大概意思了judge是一个函数名,这个judge函数名的函数呢是通过前面逻辑用数据生成出来的。
想起C语言好像有通过字符串拼接生成新命令的技巧,突然就恍然大悟了。
所以这里 (*(unsigned int (__fastcall **)(char *))judge)(input_flag) ) 应该这样分析,unsigned int 是judge函数的返回类型,(__fastcall **)是函数的调用约定,(char *)这个只是提取judge的数组头的一连串字符串做函数名而已。
然后看他们WP中显示judge是双击跟踪跟踪不了的,会报错,我的倒是跟踪得了,长这样:
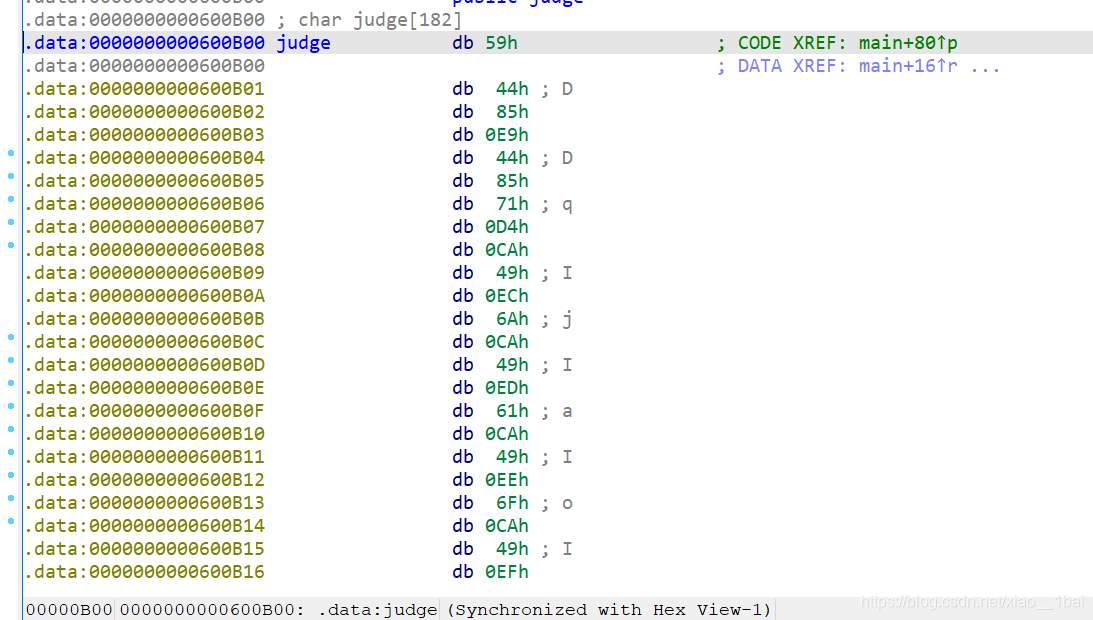
这里犯下第二个错误:
一开始这里也卡了我好一会,后来发现是我用了新版的IDA7.5,这里本来有个指针分析错误,IDA7.5直接把它当成数据去了,如果我用C(汇编),P(创建函数),在judge开头处按一下照样显示指针分析错误:(ps:不按C的话有时IDA会报错函数在指定地址具有未定义的指令/数据,您的请求已放入自动分析队列。按一下C可能是提醒它可以转成数据吧)
知道原理后我们可以开始做题了,第一种方法:直接嵌入脚本在让他把加密流程跑一遍得出真正judge代码逻辑,根据逻辑解密:
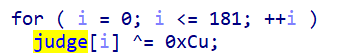
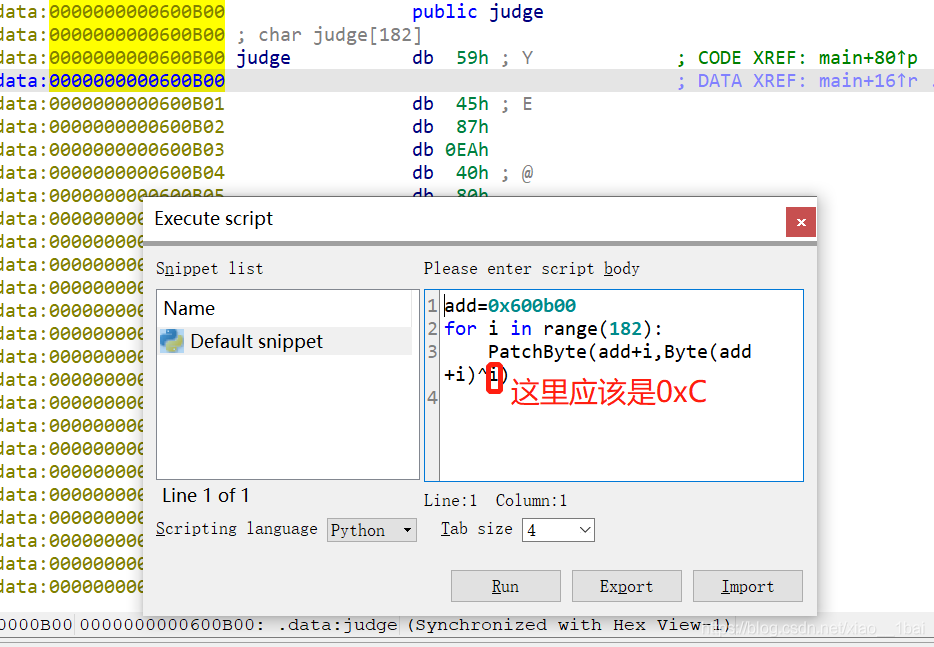
然后C,P键扫描生成函数,如果有红色的行就用U设为未定义再C,P键即可:(C键是为了先转成数据,P键是在转成数据后创建函数)
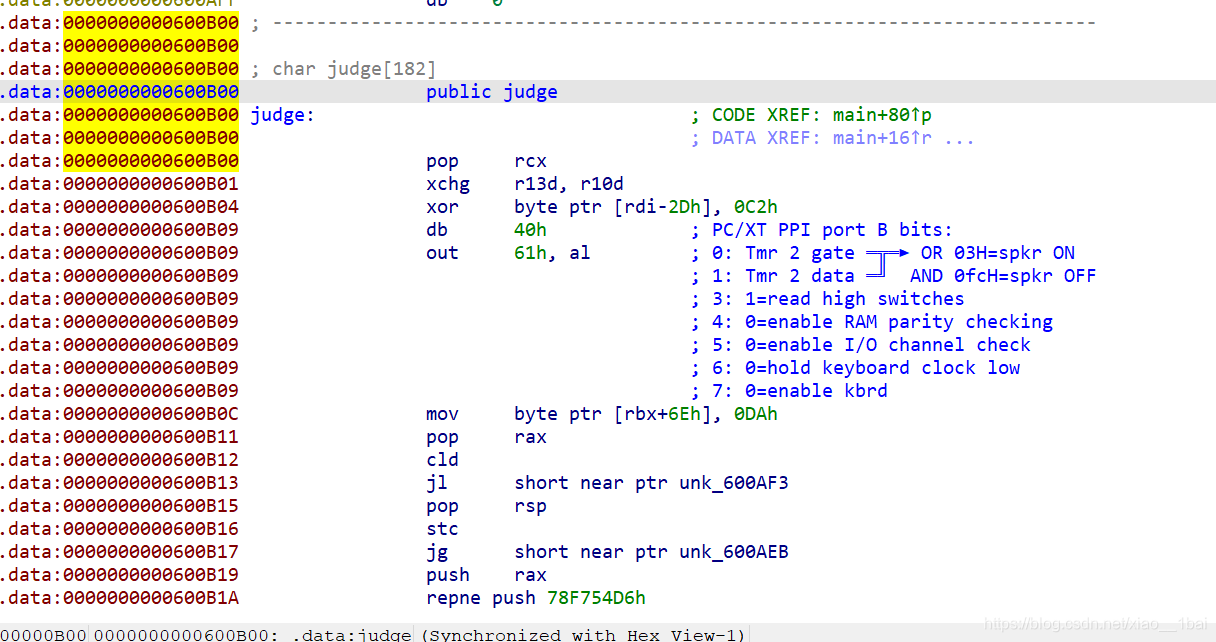
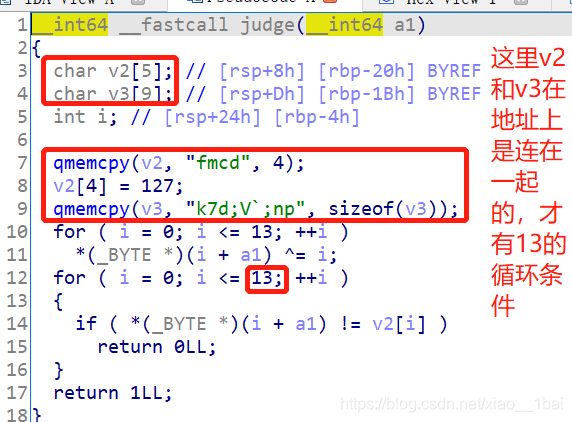
函数逻辑很简单,flag是用户输入有关的生成型flag,对输入的简单的异或然后比较每个字符与预先给的字符串是否相等,等就返回1(true),所以我们直接用预先给的字符串逆逻辑异或即可:
#key1="fmcd"
#key2=chr(0x7f)
#key3="k7d;V`;np"
#key4=key1+key2+key3
key="fmcd\x7Fk7d;V`;np"
flag=""
for i in range(14):
flag+=chr(ord(key[i])^i)
print(flag)
代码如上,犯下的第 3 个错误就是我一开始以为python会把\x7F判断成4个字符,结果是我多虑了,直接就是python自己会解析\x类型,太妙了,结果如图:
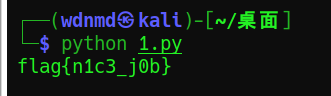
第二种方法:IDA动态调试
直接远程调试,在第12行 if ( v5 == 14 && (unsigned int)judge((__int64)s) )处断下代码,断在这里的话IDA已经把judge解密完了,直接双击跟踪生成函数即可:
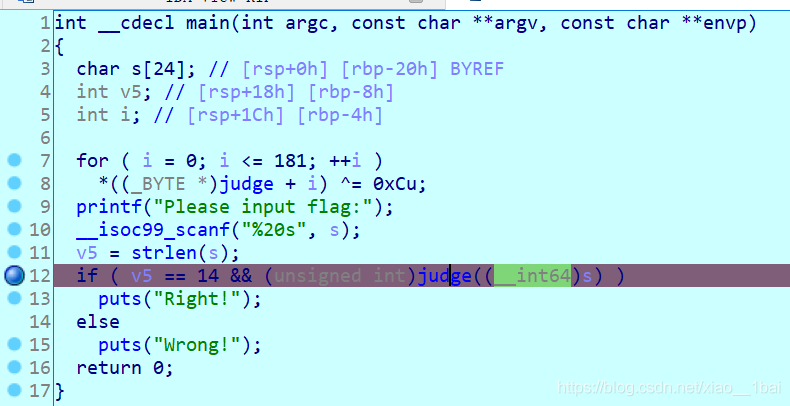

2021年10月广东强网杯,REVERSE的simplere:(迷宫结合、涉及加密、)
64位ELF文件,无壳,照例先运行一下程序,查看主要回显信息:
照例扔入IDA中查看伪代码信息,有main函数看main函数:
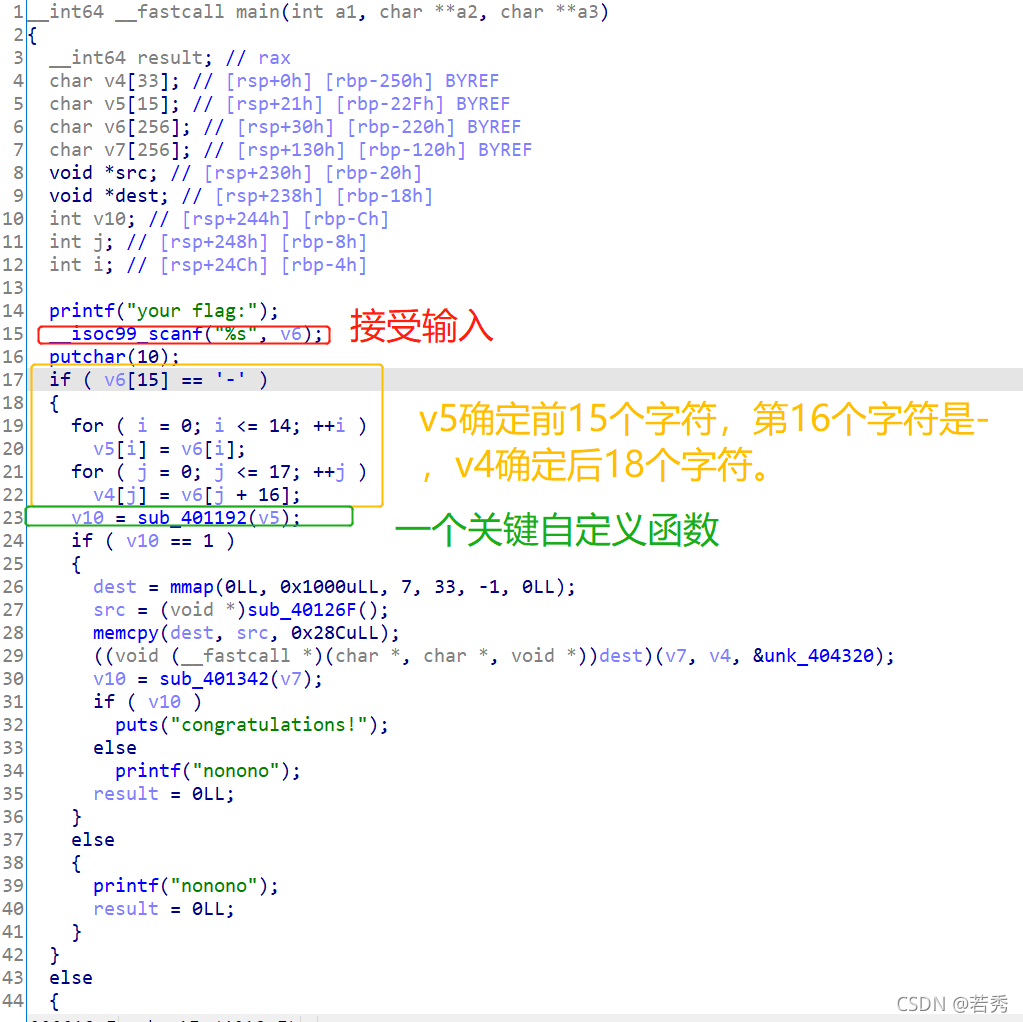
(这里积累第一个经验)
上图分析了前半部分,现在跟踪那个关键自定义函数v10 = sub_401192(v5);这是对前15个字符组成的迷宫进行操作。
点进去查看逻辑,是一个走迷宫,输入15步的wasd,要从A开始走,必须走到.上,最后必须走到B上。
根据11可以判断是二维数组,这也是我第一次学到迷宫的维数判断。因为一个走11步,另一个一步一步走,所以一维字符串最后得出二维迷宫,长11宽5的5*11型,s和w字符一下走11步就是上下移动,a和d一下走1步就是左右移动。也就是说走得多的就是行移动,走得少的就是列移动。
A********
.*…
…*.
*******…
******B
手扒得到ssddddwddddssas
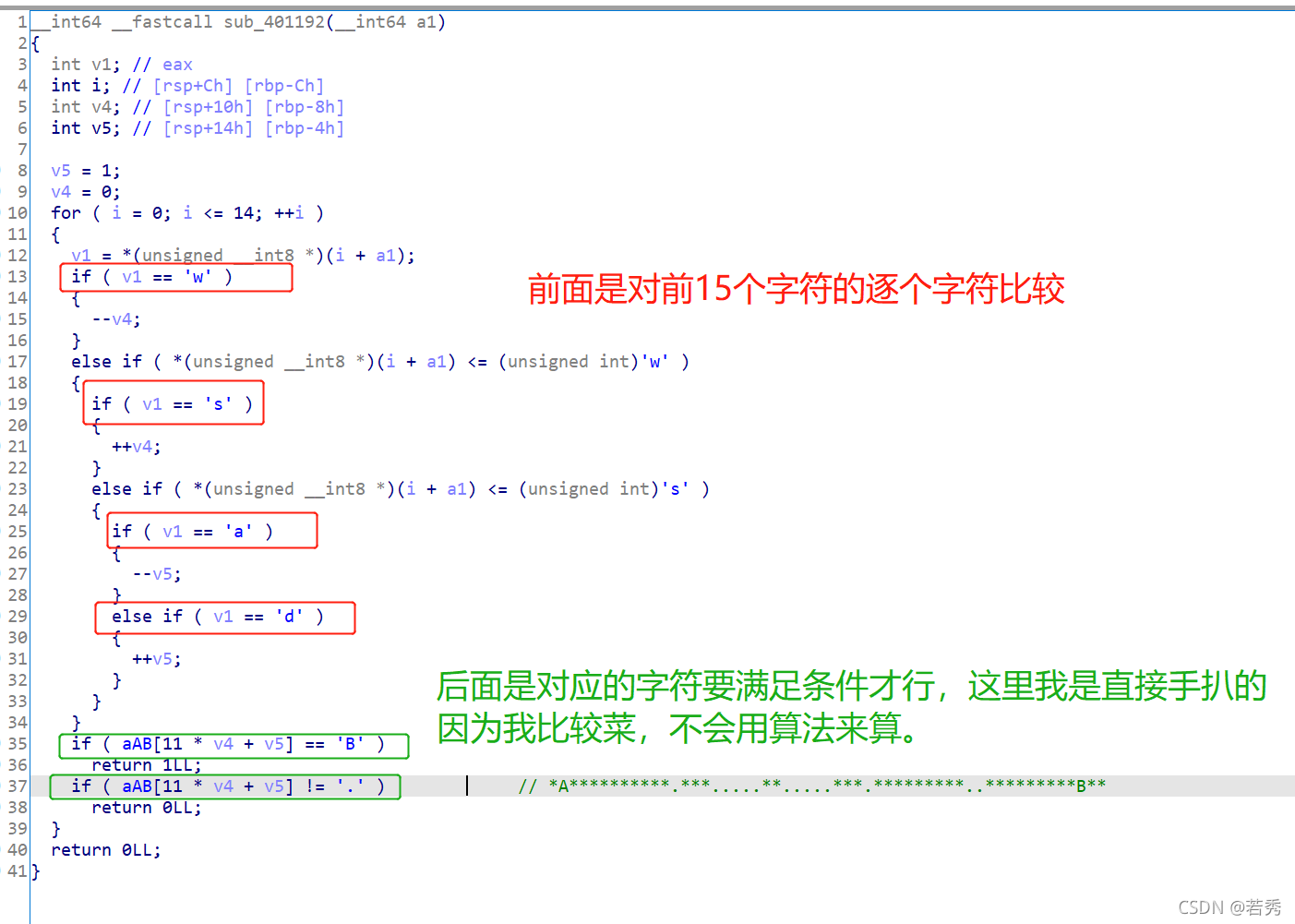
然后上半部分条件就过了,开始分析后半部分:

先跟踪分析src = (void *)sub_40126F();函数:
(这里积累第二个经验)
这里的dest是在内存中的,这里静态修补我不太会,因为dest和src都是在栈中的所以直接用动态调试,用前面得出的前半部分搭配其它字符来运行ssddddwddddssas-666666666666666666:
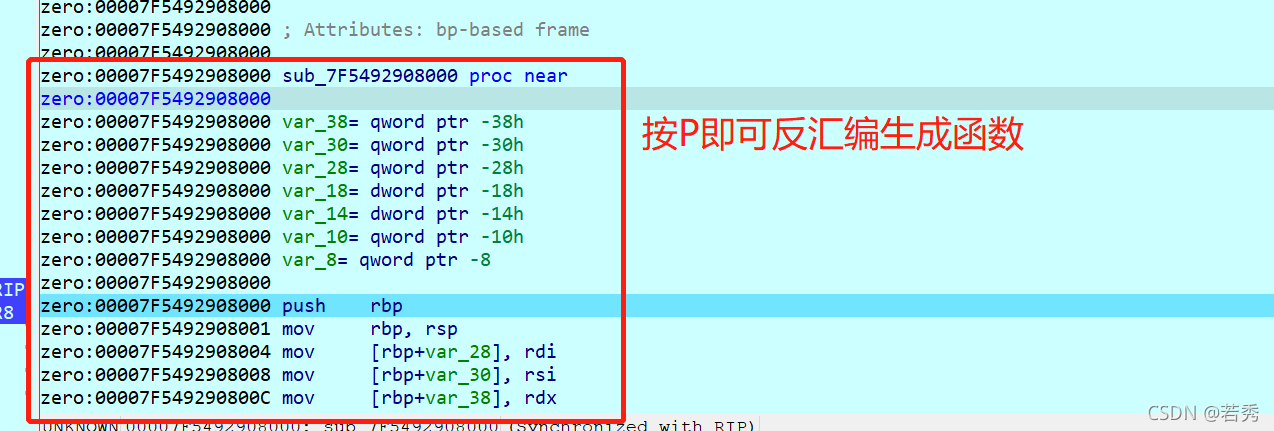
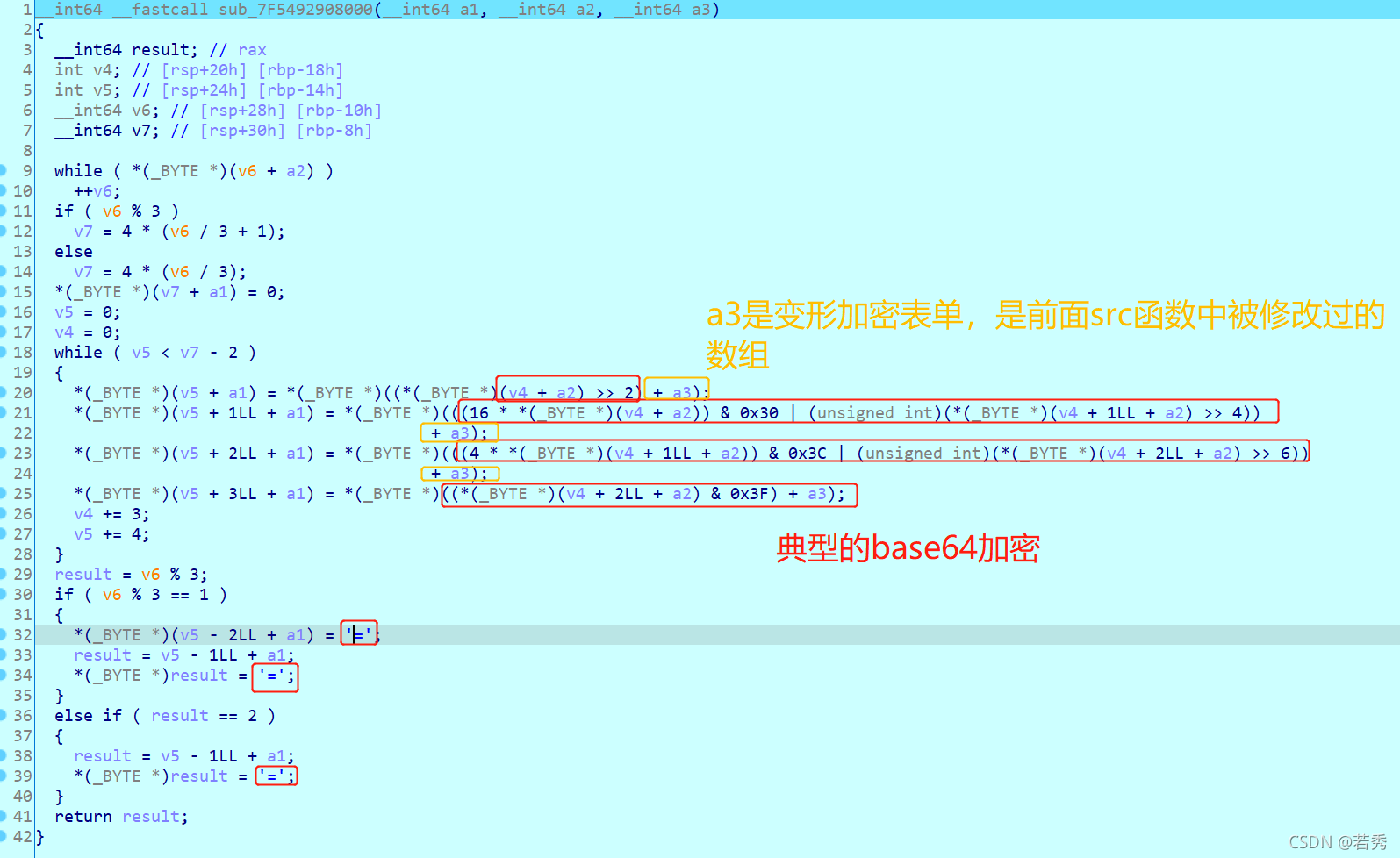
所以这题就是base64变码加密了,继续跟踪最后的自定义函数v10 = sub_401342(v7);
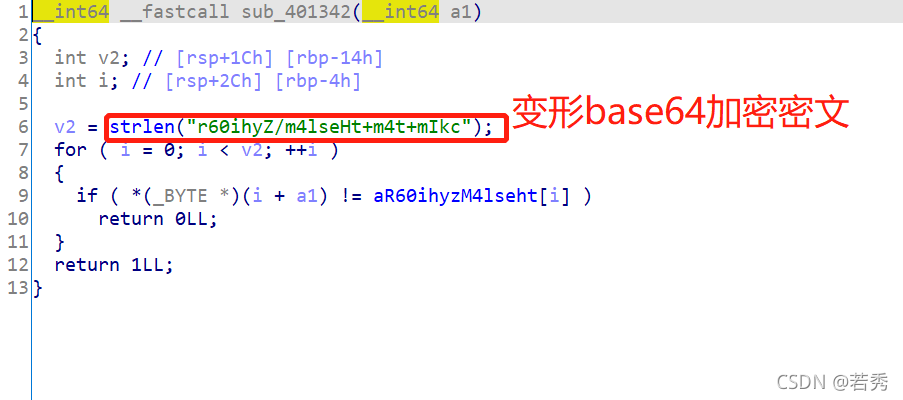
密文也有了,可以写逻辑了,首先求出base64变形码表,从src = (void *)sub_40126F();处导出数组:
key2=[ 0x4D, 0x20, 0x07, 0x05, 0x43, 0x15, 0x7A, 0x73, 0x39, 0x01,
0x7F, 0x53, 0x66, 0x4E, 0x0D, 0x18, 0x60, 0x76, 0x75, 0x00,
0x58, 0x15, 0x00, 0x32, 0x68, 0x3F, 0x78, 0x7F, 0x7B, 0x64,
0x4E, 0x49, 0x0F, 0x2E, 0x3F, 0x0D, 0x0D, 0x0D, 0x64, 0x66,
0x61, 0x53, 0x06, 0x44, 0x34, 0x6E, 0x69, 0x2F, 0x20, 0x14,
0x37, 0x6A, 0x49, 0x55, 0x36, 0x37, 0x23, 0x23, 0x2A, 0x6B,
0x73, 0x06, 0x78, 0x0B]
key3=[ 0x3E, 0x7A, 0x40, 0x64, 0x27, 0x25, 0x48, 0x04, 0x4F, 0x63,
0x19, 0x60, 0x0B, 0x3A, 0x75, 0x5D, 0x11, 0x4E, 0x07, 0x44,
0x30, 0x4C, 0x4B, 0x06, 0x5F, 0x73, 0x0D, 0x1A, 0x38, 0x08,
0x34, 0x78, 0x45, 0x47, 0x58, 0x3B, 0x74, 0x7D, 0x2C, 0x2B,
0x4A, 0x3C, 0x29, 0x13, 0x01, 0x3F, 0x03, 0x61, 0x70, 0x52,
0x65, 0x09, 0x22, 0x00, 0x7F, 0x59, 0x6C, 0x77, 0x72, 0x3D,
0x32, 0x55, 0x41, 0x49]
for i in range(len(key3)):
key2[i]^=key3[i]
print(key2)
print(''.join(map(chr,key2))) #base64变表码
结果:

然后把变形码表替换传统base64加密码表,这里用的是我以前写过的base64python编码实现:(https://blog.csdn.net/xiao__1bai/article/details/120338971)
base64="sZGad02wvbf3mtxEq8rDhYK47LueClz1Jig6ypHM+o/W5QjNPFRckUInOTXVAS9B" #准备好base64的基表
def encryption(inputstring): #定义加密函数
ascii=['{:0>8}'.format(str(bin(ord(i))).replace('0b','')) for i in inputstring] #把每个输入字符保证8位一个,才能3*8变4*6。
#{:0>8}是右对齐8位然后左边补0,因为python是自己判断数据大小类型的,所以必须强制满足8位。bin转化二进制会带0b前缀,所以要用replace('0b','')去掉。
encrystr='' #while外的变量,返回base64加密后的字符串
equalnumber=0 #while外的变量,记录拆分后不足4的倍数时需要补齐的等号个数
while ascii:
subascii=ascii[:3] #用一个子列表subascii每次取输入的三位进行操作,前面操作后每位都是8位
while len(subascii)<3: #这里其实是最后一段截取中才会用上的,不满足3位时要单独取出,记录equalnumber数量用于后期补'='号,然后补齐8位的0免得干扰后面3*8拆分成4*6
equalnumber+=1 #计算要补‘=’的个数
subascii+=['0'*8] #补8个0来填充够3的倍数,这然后面就不会出错。
substring=''.join(subascii)#用substring合并subascii的3个8位,准备进行拆分操作
encrystringlist=[substring[x:x+6] for x in [0,6,12,18]] #开始进行3*8变4*6的拆分,每次拆分一组24位。
encrystringlist=[int(x,2) for x in encrystringlist] #把前面拆分的6位一组转成10进制,就不用进行位数补齐操作了,这是用来后面对应base64基表的下标。
if equalnumber:
encrystringlist=encrystringlist[0:4-equalnumber] #如果前面不足3字符补了0,比如2个8位字符16位,拆分后就要用3个6位共18位,所以有效位是4-equalnumber
encrystr+=''.join(base64[x] for x in encrystringlist) #这里encrystringlist已经在前面拆分成4*6且转换成10进制了,所以对应基表的下标。
ascii=ascii[3:] #每次向后取3个列表元素,对应while循环条件
encrystr+='='*equalnumber #因为前面encrystringlist[0:4-equalnumber]去掉了补0位,所以这里最后补齐'='号
return encrystr
def decryption(inputstring):
ascii=['{0:0>6}'.format(str(bin(base64.index(i))).replace('0b',''))for i in inputstring if i!='=']#从加密字符中取除补位'='之外加密字符,即6位生成的base64基表下标的数,按6位一组排列,准备拆分
decrystr=''#准备while外的解密后的字符
equalnumber=inputstring.count('=')#这里计数补位的'='号的个数,后面不够8位时会根据'='号补加位数。
while ascii:
subascii=ascii[:4]#取加密字符的4个6位一组共24位准备拆分合并成3*8
substring=''.join(subascii)#先连成一串24位
if len(substring)%8!=0:
substring=substring[0:-1*equalnumber*2]
#截取到倒数第equalnumber*2个元素。对不足8位的组补位,因为加密时1个8位要来2个6位,两个'='号,截取到8位就是倒数第4位1*2*2。2个8位要3个6位,要一个'='号,截取到16位就是倒数第2位1*1*2。
decrystringlist=[substring[x:x+8] for x in [0,8,16]]#开始进行4*6变3*8的拆分,每次拆分4个6位一组24位。
decrystringlist=[int(x,2) for x in decrystringlist if x]#把前面拆分的8位一组转成10进制,用来对应十进制ASCII码,if x功能不清楚,但不可缺少,应该是要排除空格吧。
decrystr+=''.join([chr(x) for x in decrystringlist])#这里decrystringlist已经在前面拆分成3*8且转换成10进制了,现在转换成ASCII码。
ascii=ascii[4:]#每次向后取4个列表元素,对应while循环条件
return decrystr
if __name__=="__main__":
#print(encryption('abcd'))
print(decryption('r60ihyZ/m4lseHt+m4t+mIkc'))
结果:
所以最终flag:
flag{ssddddwddddssas-J1aR@j1w@nch1sh3m3}
系统函数函数自修改:(HOOK,通常两次修改系统函数,一次改成自定义机器码,一次改回正常)
Hook 技术又叫做钩子函数,在系统没有调用该函数之前,钩子程序就先捕获该消息,钩子函数先得到控制权,这时钩子函数既可以加工处理(改变)该函数的执行行为,还可以强制结束消息的传递。简单来说,就是把系统的程序拉出来变成我们自己执行代码片段。
攻防世界EASYHOOK:(非预期行为、函数积累、手动机器码)
这是我第一次遇到HOOK类型的题目,我很是兴奋,我也花了相当长的时间才把该HOOK流程全部弄懂,希望能给日后更多经验。
直接入重点,打开IDA查看main函数,具体分析我写在代码里:
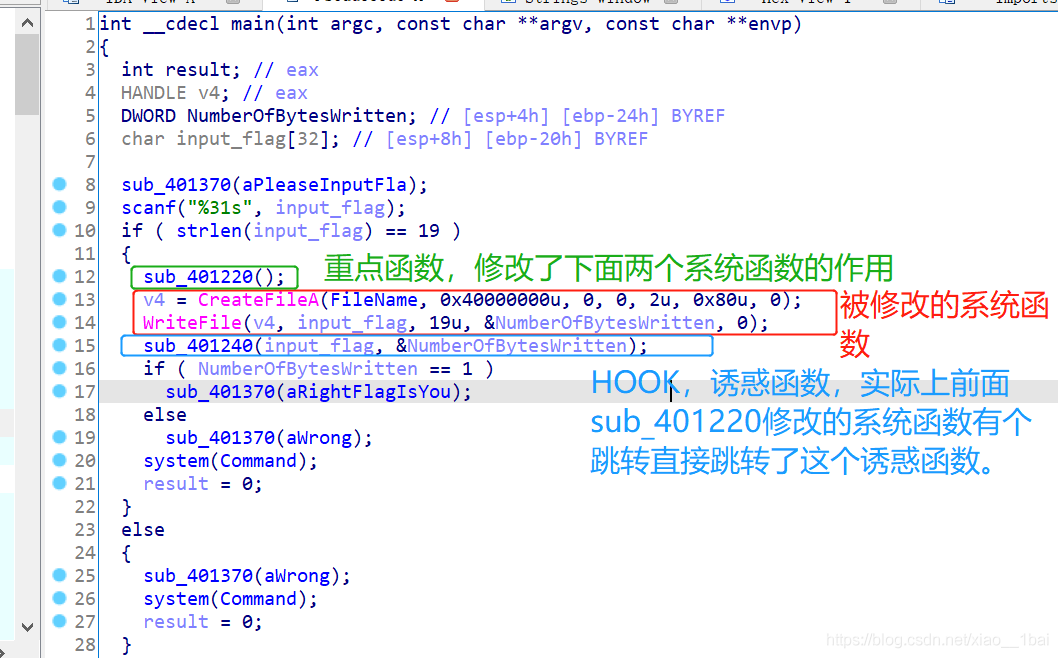
sub_401370(aPleaseInputFla);
scanf("%31s", input_flag);
if ( strlen(input_flag) == 19 )
{
sub_401220(); //未知名函数,一开始当然不会注意
v4 = CreateFileA(FileName, 0x40000000u, 0, 0, 2u, 0x80u, 0); //创建文件函数
WriteFile(v4, input_flag, 19u, &NumberOfBytesWritten, 0); //写入函数,这些系统函数通常不是重点,如果影响理解代码的话直接查API即可, WriteFile(句柄, 写入字符串, 写入字节, 指向写入直接的指针, 0)
sub_401240(input_flag, &NumberOfBytesWritten);
if ( NumberOfBytesWritten == 1 ) //判断函数
sub_401370(aRightFlagIsYou);
else
sub_401370(aWrong);
system(Command);
result = 0;
}
else
{
sub_401370(aWrong);
system(Command);
result = 0;
}
return result;
}
好了,疑惑开始,首先当然直接跟踪sub_401240函数:然后就犯下第一个错误:(被HOOK了):
查看该函数代码让我疑惑的事情发生了,v4[a1 - v4 + result] == v4[result] 这条神仙代码无解啊,a1是我输入的字符串地址,作为下标运算就算了,result还是从0开始的,完全走不通啊!(PS:这题还算好了,给了我一个走不通的HOOK,要是这个HOOK还是走得通的话就更花时间了!)
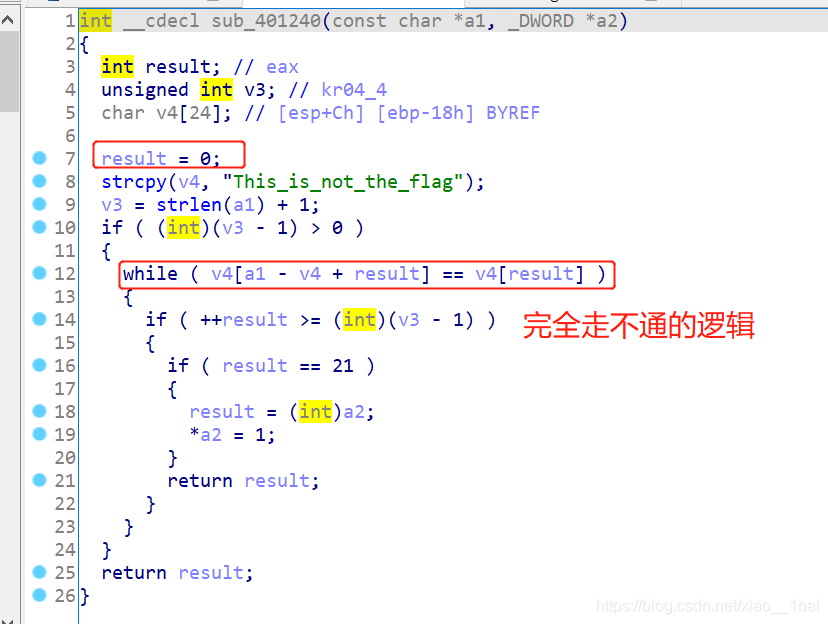
然后我又看了一下生成的Your_input文件,???生成的不是我写入的:

然后就去查资料了,期间学到了很多东西,我们先用静态调试细致分析:首先这一系列非预期行为基本说明了存在其他操作,那前面非系统函数就只剩下sub_401220()了,跟踪加代码分析:
int sub_401220()
{
HMODULE v0; // eax
DWORD v2; // eax
v2 = GetCurrentProcessId(); //系统函数,获取进程ID,就是当前程序的ID
hProcess = OpenProcess(0x1F0FFFu, 0, v2); //系统函数,返回现有进程对象的句柄。
v0 = LoadLibraryA(LibFileName); //系统函数,将指定的可执行模块映射到调用进程的地址空间,这里LibFileName双击跟踪存入的是kernel32.dll模块,就是导入了它
*(_DWORD *)WriteFile_0 = GetProcAddress(v0, ProcName); //系统函数,返回指定的导出动态链接库(DLL)函数的地址。 ProcName存放的是WriteFile函数名,也就是导入WriteFile函数。
lpAddress = *(LPVOID *)WriteFile_0; //获取WriteFile函数地址
if ( !*(_DWORD *)WriteFile_0 ) //无用函数,因为kernel32.dll模块的WriteFile函数一定存在
return sub_401370(&unk_40A044); //sub_401370函数类型puts函数,是通过主函数分析得到的,&unk_40A044处的字符串是获取原API入口地址出错,不用管他。
unk_40C9B4 = *(_DWORD *)lpAddress; //这里获取WriteFile函数的地址
*((_BYTE *)&unk_40C9B4 + 4) = *((_BYTE *)lpAddress + 4); //这里地址后四位也保持一样,不知道有什么用
byte_40C9BC = 0351; //这里连同第二句是我犯下的第二个错误:这里转十六进制不是E9,是JMP的机器码指令,而不一开始并没有机器码的相关知识。
dword_40C9BD = (char *)sub_401080 - (char *)lpAddress - 5; //这里是一个偏移地址,而且还是满足HOOK的连续地址。之所以这样写是因为汇编语言JMP address被编译后会变成机器指令码,E9 偏移地址,偏移地址=目标地址-当前地址-5(jmp和其后四位地址共占5个字节)。所以前面直接用E9,这里直接用偏移地址就省去编译生成机器码那一步。这也是HOOK的原型。
return sub_4010D0(); //返回一个函数,继续跟踪,因为前面并没有什么修改程序的行为,只是创造了一个JMP指令而已。
}
跟踪sub_4010D0()函数:(这里替换了WriteFile函数的5字节为JMP跳转指令)
BOOL sub_4010D0()
{
DWORD v1; // [esp+4h] [ebp-8h] BYREF
DWORD flOldProtect; // [esp+8h] [ebp-4h] BYREF
v1 = 0;
VirtualProtectEx(hProcess, lpAddress, 5u, 4u, &flOldProtect); //这里犯下第三个错误就是我一开始看不懂这三行代码
函数理解:
VirtualProtectEx(进程,修改地址,修改区域大小,[修改其中权限,1,2,4对应执行,写,读],一个保存修改前权限的变量 ),
所以这三行作用是对lpAddress所存储的地址处进行了5字节的权限修改操作,先将关键地址区改成可读写再往此处写入前面E9 偏移量地址处的5个字节(即上面的跳转指令),最后恢复权限,完成修改。
WriteProcessMemory(hProcess, lpAddress, &byte_40C9BC, 5u, 0); //在原WriteFile函数地址处覆盖写入5字节的JMP手动机器码
return VirtualProtectEx(hProcess, lpAddress, 5u, flOldProtect, &v1); //恢复权限
所以这里执行到WriteFile函数的时候就会变成一个跳转语句,跳转到目标地址sub_401080处,双击跟踪该函数:
int __stdcall sub_401080(HANDLE hFile, LPCVOID input_flag, DWORD nNumberOfBytesToWrite, LPDWORD lpNumberOfBytesWritten, LPOVERLAPPED lpOverlapped)
{
int v5; // ebx
v5 = sub_401000((int)input_flag, nNumberOfBytesToWrite); //真正加密函数,后面分析
sub_401140(); //重写WriteFile函数地址处的内存,和前面4010D0处函数的三句类似,只是代码 WriteProcessMemory(hProcess, lpAddress, &unk_40C9B4, 5u, 0);写入的地址为&unk_40C9B4,这的确是WriteFile函数地址,就是为了下面那个WriteFile函数不受影响,真正是写入文件函数
WriteFile(hFile, input_flag, nNumberOfBytesToWrite, lpNumberOfBytesWritten, lpOverlapped); //真正的写入函数
if ( v5 )
*lpNumberOfBytesWritten = 1; //这里*lpNumberOfBytesWritten已经赋值为1了,也是全局变量,你会猛的发现主函数的sub_401240(input_flag, &NumberOfBytesWritten);这个幌子函数就算对不上数组字符也不会设置*lpNumberOfBytesWritten = 0;所以只要这里真正加密的对了,后面错误退出*lpNumberOfBytesWritten还是等于1.
return 0;
}
分析真正加密函数 sub_401140():
int __cdecl sub_401000(int input_flag, int _19)
{
char i; // al
char v3; // bl
char v4; // cl
int v5; // eax
for ( i = 0; i < _19; ++i )
{
if ( i == 18 )
{
*(_BYTE *)(input_flag + 18) ^= 19u; // 这里犯下第五个错误,写脚本时这种单独的if语句应该直接在外面单独成行,不然就要多写几个elif语句了,界面就会很乱!
}
else
{
if ( i % 2 )
v3 = *(_BYTE *)(i + input_flag) - i;
else
v3 = *(_BYTE *)(i + input_flag + 2);
*(_BYTE *)(i + input_flag) = i ^ v3;
}
}
v4 = 0;
if ( _19 <= 0 ) // 不会小于等于,所以不会在这里返回
return 1;
v5 = 0;
while ( aAjygkfm[v5] == *(_BYTE *)(v5 + input_flag) ) //这里犯下第四个错误,前面的加密逻辑中我们没有可以参照的字符串,因为flag是推出来的,而真正的字符串在后面,所以逆向逻辑时首先要找到非输入的字符串才行!这里双击跟踪 aAjygkfm等于ajygkFm.\x7f_~-SV{8mLn
{
v5 = ++v4;
if ( v4 >= _19 )
return 1;
}
return 0;
}
所以最后脚本:
flag=list("-------------------") #这是学别人的,因为我们要的是19个元素的数组,所以List函数很不错喔
print(len(flag))
key1="ajygkFm.\x7f_~-SV{8mLn"
flag[18]=chr(ord(key1[18])^19)
for i in range(18):
v3=ord(key1[i])^i
if i%2==1: #把18的判断条件抽出去后里面就只有一层条件了,简便很多。
flag[i]=chr(v3+i)
else:
flag[i+2]=chr(v3)
print(''.join(flag))
结果,改第一个字符为f即可:

引用别人博客的一句话:
现在程序流程就很明朗了
粗略来看程序流程是CreateFileA->(lpAddress里存的指令)WriteFile->sub_401240
但是在经过sub_401220()的处理以后,变成了CreateFileA->(lpAddress里存的指令)sub_401080->sub_401240。
那么最后的sub_401240又干了什么事呢,分析一下代码:(这里我重命名了一些变量名):
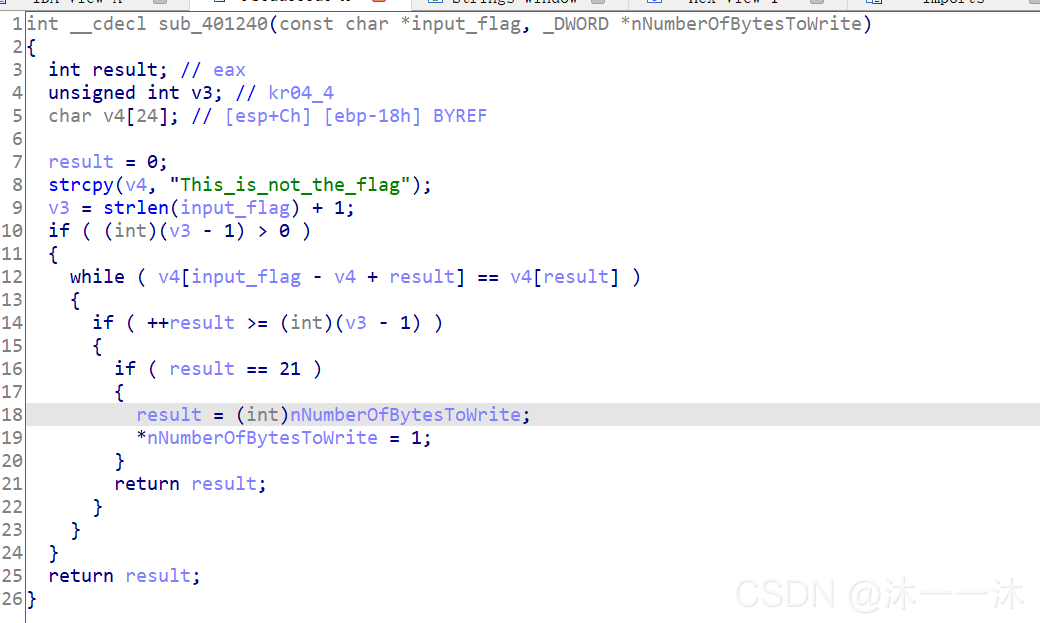
这里最有意思的是这个函数完全符合就会执行nNumberOfBytesToWrite = 1;,但是不符合也没有nNumberOfBytesToWrite = 0;的操作啊,我们前面真加密函数的时候就赋值*nNumberOfBytesToWrite = 1;了,也就是说不管这里对还是错都会输出you flag is right啊!而且动态调试的时候你会发现,这里循环执行一次就退出来了,因为while ( v4[input_flag - v4 + result] == v4[result] )这个代码根本不合逻辑。
最后动态调试就不想搞了:
我记得IDA动态运行到主函数WriteFile处的时候用F7单步执行会看到一个jmp的指令,继续动态到sub_401240函数的时候也是正如我说的循环运行第一次就退出来了,但是照样输出you flag is right。
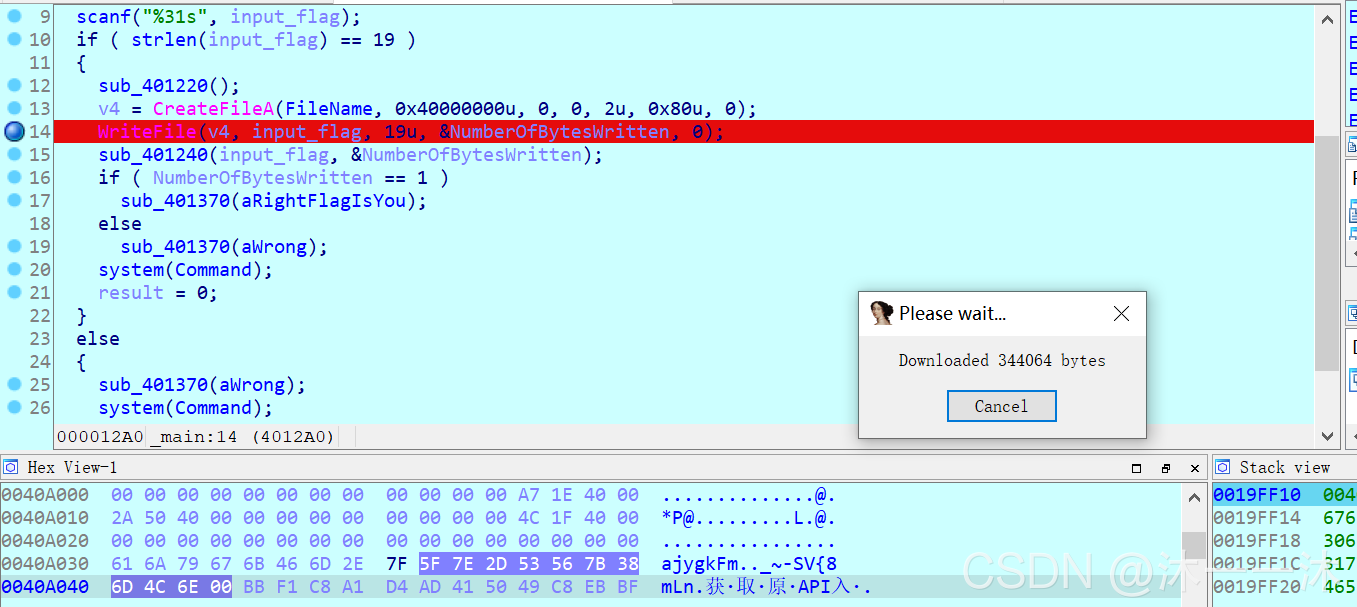
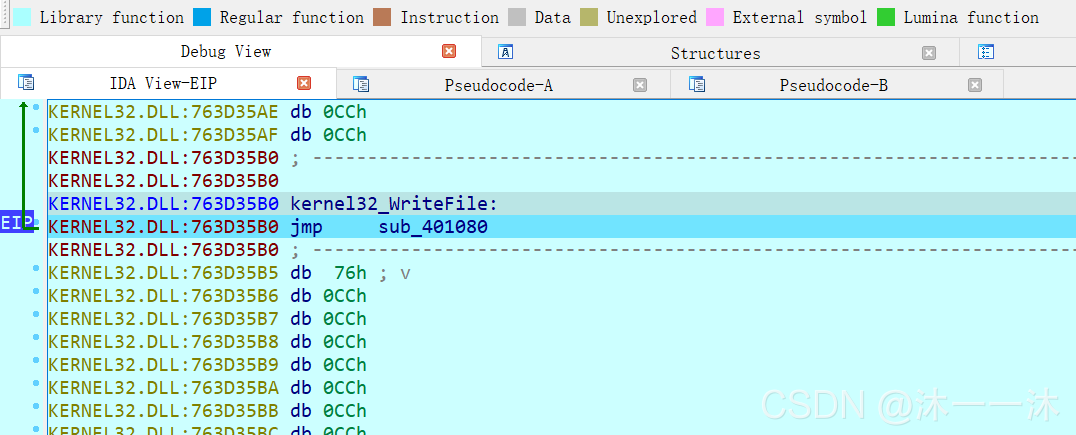
安卓java类逆向分析
java逻辑平铺:
攻防世界Guess-the-Number:(代码截断重写)
下载了一个jar文件,根据题目描述猜个数字然后找到flag.,估计题目类型是flag存储型,满足条件就有flag:
用我之前做安卓逆向下载的jar.gui打开,查看代码逻辑:
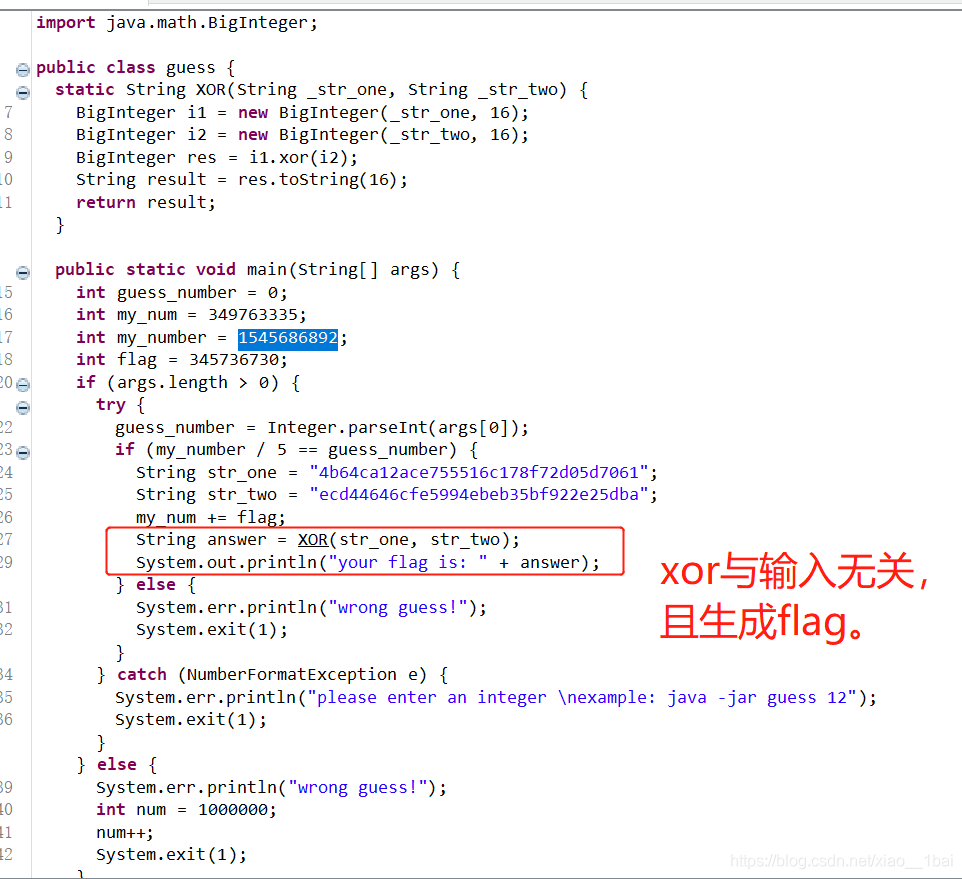
逻辑不难,果然是满足条件就有的存储型flag,这里我直接修改截断代码即可,xor是生成存储型flag的代码,要保留:
import java.math.BigInteger;
public class guess {
static String XOR(String _str_one, String _str_two) {
BigInteger i1 = new BigInteger(_str_one, 16);
BigInteger i2 = new BigInteger(_str_two, 16);
BigInteger res = i1.xor(i2);
String result = res.toString(16);
return result;
}
public static void main(String[] args) {
int guess_number = 0;
int my_num = 349763335;
int my_number = 1545686892;
int flag = 345736730;
String str_one = "4b64ca12ace755516c178f72d05d7061";
String str_two = "ecd44646cfe5994ebeb35bf922e25dba";
my_num += flag;
String answer = XOR(str_one, str_two);
System.out.println("your flag is: " + answer);
}
}
这里截断代码的时候遇到第一个错误,我竟然忘记编译命令是什么了,还傻傻的用java -c,真的是马冬梅啊马冬梅,后来查看了百度才想起编译命令是javac,运行即得flag:

当然还有第二种方法,看输入后处理的判断逻辑,输入正确的数即可:
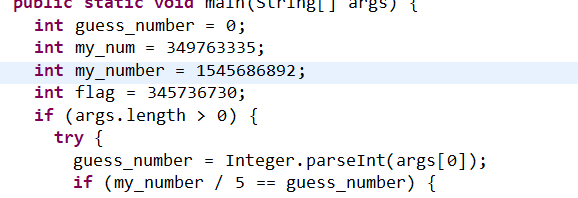
这里判断逻辑是my_number / 5 == guess_number,一开始不记得前面的guess_number = Integer.parseInt(args[0])是什么意思,所以就没往这里想,后来才发现是简单的获取整数参数而已,所以计算机运算1545686892 / 5再取整数就是我们要输入的数:(PS:参数写在右边)

RC4解密脚本:
#include<stdio.h>
void rc4_init(unsigned char* s, unsigned char* key, unsigned long Len_k) //初始化函数
{
int i = 0, j = 0;
char k[256] = { 0 };
unsigned char tmp = 0;
for (i = 0; i < 256; i++) {
s[i] = i;
k[i] = key[i % Len_k];
}
for (i = 0; i < 256; i++) {
j = (j + s[i] + k[i]) % 256;
tmp = s[i];
s[i] = s[j];
s[j] = tmp;
}
}
void rc4_crypt(unsigned char* Data, unsigned long Len_D, unsigned char* key, unsigned long Len_k) //加解密
{
unsigned char s[256];
rc4_init(s, key, Len_k);
int i = 0, j = 0, t = 0;
unsigned long k = 0;
unsigned char tmp;
for (k = 0; k < Len_D; k++) {
i = (i + 1) % 256;
j = (j + s[i]) % 256;
tmp = s[i];
s[i] = s[j];
s[j] = tmp;
t = (s[i] + s[j]) % 256;
Data[k] = Data[k] ^ s[t];
}
}
void main()
{
unsigned char key[] = "[Warnning]Access_Unauthorized"; //密钥
unsigned long key_len = sizeof(key) - 1;
unsigned char data[] = { 0xC3,0x82,0xA3,0x25,0xF6,0x4C,
0x36,0x3B,0x59,0xCC,0xC4,0xE9,0xF1,0xB5,0x32,0x18,0xB1,
0x96,0xAe,0xBF,0x08,0x35};//把加密脚本放在kali中打开,根据kali推荐的编码再复制到burp中用hex编码写出来放在这里。 kali ISO-8859-1编码显示类似于 ??£%?L6;Yì?é?μ2±???5
int i;
rc4_crypt(data, sizeof(data), key, key_len);
for ( i = 0; i < sizeof(data); i++)
{
printf("%c", data[i]);
}
printf("\n");
return;
}
//flag{RC4&->ENc0d3F1le}
INT3断点:
INT3断点,简单地说就是将你要断下的指令地址处的第一个字节设置为0xCC,软件执行到0xCC(对应汇编指令INT3)时,会触发异常代码为EXCEPTION_BREAKPOINT的异常。这样我们的调试程序就能够接收到这个异常,然后进行相应的处理。如果没有处理就会强制退出程序,就无法调试了。
INT3断点的信息结构体如下:
struct stuPointInfo
{
PointType ptType; //断点类型
int nPtNum; //断点序号
LPVOID lpPointAddr; //断点地址
BOOL isOnlyOne; //是否一次性断点(针对INT3断点)
char chOldByte; //原先的字节(针对INT3断点)
};
而每一个INT3断点信息结构体指针又保存到一个链表中。
INT3断点的设置:
设置INT3断点比较简单,只需要根据用户输入的断点地址和断点类型(是否一次性断点),将被调试进程中对应地址处的字节替换为0xCC,同时将原来的字节保存到INT3断点信息结构体中,并将该结构体的指针加入到断点链表中。
如果在被调试的某地址处已经存在一个同样的断点了,那么用户 还要往这个地址上设置相同的断点,则必然会因为重复设置断点导致错误。例如这里的INT3断点,如果不对用户输入的地址进行是否重复的检查,而让用户在同 一个地址先后下了两次INT3断点,则后一次INT3断点会误以为这里本来的字节就是0xCC而一直断点在这里。
所以在设置INT3断点之前应该先看该地址是否已经下过 INT3断点,如果该地址已经存在一个INT3断点,且是非一次性的,则不能再在此地址下INT3断点,如果该地址有一个INT3一次性断点,而用户要继续下一个INT3非一次性断点,则将原来存在的INT3断点的属性从一次性改为非一次性断点。
INT3断点被断下的处理:
INT3断点被断下后,首先从断点链表中找到对应的断点信息结构体。如果没有找到,则说明该INT3断点不是用户下的断点,调试器不做处理,交给系统程序去处理(其他类型的断点触发异常也需要做同样的处理,而系统通常是强制退出结束程序),这也是攻防世界的csaw2013reversing2的考点。
如果找到对应的断点,根据断点信息将断下地址处的字节还原为原来的字节,并将被调试进程的 EIP减一,因为INT3异常被断下后,被调试进程的EIP已经指向了INT3指令后的下一条指令,所以为了让被调试进程执行本来需要执行的指令,应该让 其EIP减1。
如以下代码:
地址 机器码 汇编代码
01001959 55 push ebp
0100195A 33ED xor ebp,ebp
0100195C 3BCD cmp ecx,ebp
0100195E 896C24 04 mov dword ptr ss:[esp+4],ebp
当用户在0100195A地址处设置INT3断点后,0100195A处的字节将改变为0xCC(原先是0x33)。
此时对应的代码如下:
地址 机器码 汇编代码
01001959 55 push ebp
0100195A CC int3
0100195B ED in eax,dx
0100195C 3BCD cmp ecx,ebp
0100195E 896C24 04 mov dword ptr ss:[esp+4],ebp
当被调试程序执行到0100195A地址处,触发异常,进入异常处理程序后,获取被调试线程的环境(GetThreadContext),可看 出此时EIP指向了0100195B,也就是INT3指令之后,所以我们除了要恢复0xCC为原来的字节之外,还要将被调试线程的EIP减一,让EIP指 向0100195A。否则CPU就会执行0100195B处的指令(0100195B ED in eax,dx),显然这是错误的。
如果查找到的断点信息显示该INT3断点是一个非一次性断点,那么需要设置单步,然后在进入单步后将这一个断点重新设置上(硬件执行断点和内存 断点如果是非一次性的也需要做相同的处理)。因为INT3断点同时只会断下一个,所以可以用一个临时变量保存要重新设置的INT3断点的地址,然后用一个 BOOL变量表示当前是否有需要重新设置的INT3断点。
关于INT3断点的一些细节:
1. 创建调试进程后,为了能够让被调试程序断在OEP(程序入口点),我们可以在被调试程序的OEP处下一个一次性INT3断点。
2. 在创建调试进程的过程中(程序还没有执行到OEP处),会触发一个ntdll.dll中的INT3,遇到这个断点直接跳出不处理。这个断点在使用微 软自己的调试工具WinDbg时会被断下,可以猜测,微软设置这个断点是为了能够在程序到达OEP之前就被断下,方便用户做一些处理(如设置各种断点)。
3. 因为INT3断点修改了被调试程序的代码内容,所以在进行反汇编和显示被调试进程内存数据的时候,需要检查碰到的0xCC字节是否是用户所下的 INT3断点,如果是需要替换为原来的字节,再做相应的反汇编和显示数据工作。这一点olldbg做的很不错,而有一些国产的调试器好像没有注意到这些小 的细节。
IDA获取地址内容命令嵌入:
提取&s处的数组内容:
addr=0x08048AA8 #数组的地址
arr = []
for i in range(39): #数组的个数
arr.append(Dword(addr+4* i))
print(arr)















 7466
7466











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











