







用OpenCV处理图像,特别涉及到机器学习,需要批量地读取图像。方法比较简单,唯一的要求就是文件夹下的图片名称是有规律的,本文将介绍一下,如何批量的读入图片,极其简单,各位可以根据自己的需求做一些修改:
首先我们看一下小博我的图片格式,直接借用上次分帧出来的图片吧,我的图片放在D盘img文件夹里,命名格式很怪异,img381—-img475看一下我的贴图吧。
话不多说,贴出我的代码吧,调用了opencv库读入图像,大家拿去用吧。
#include<direct.h>
#include<opencv2/opencv.hpp>
#include<iostream>
using namespace cv;
using namespace std;
#define null 95
int main()
{
Mat image;
string ImageName;
int n = 381;
while (n <= 475)
{
ImageName = "img";
stringstream ss;
string str;
ss << n;
ss >> str;
ImageName = ImageName + str;
ImageName = "D:\\img\\" + ImageName + ".jpg";
cout << "处理:" << ImageName << endl;
image = imread(ImageName);
if (image.data == 0)
printf("[erro]没有图片\n");
n++;
}
waitKey(0);
system("pause");
return 0;
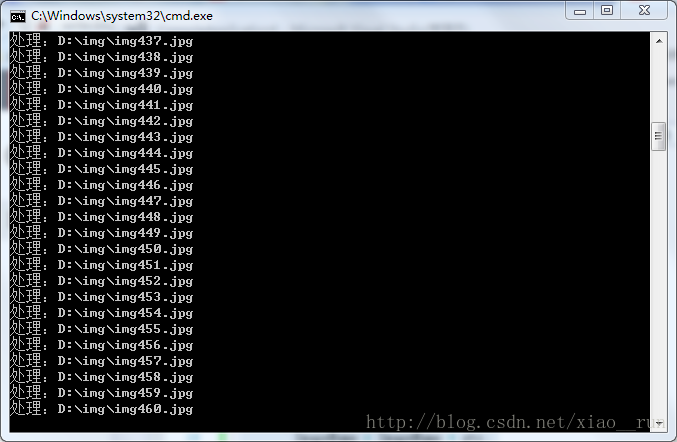
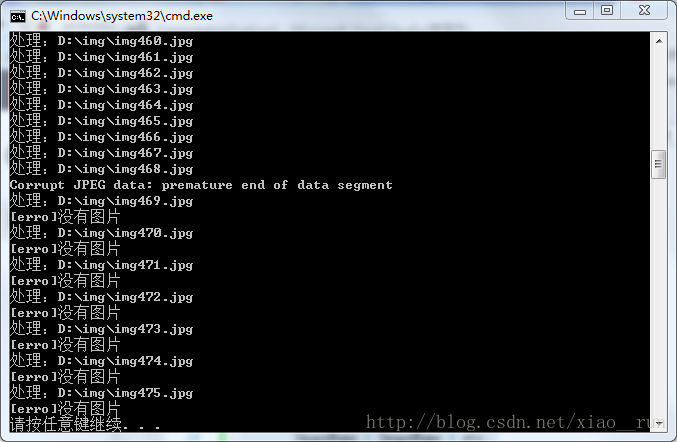
}看下运行结果吧。直到读完图片。
方法二:
我们可以直接无脑不按顺序的遍历一遍也可以哦,话不多说,上代码吧:
#include "opencv2/opencv.hpp"
#include <fstream>
#include <iostream>
#include <string>
#include "dirent.h"
using namespace std;
using namespace cv;
int main()
{
DIR *dir;
struct dirent *entry;
if((dir=opendir("D:\\img"))==NULL)
printf( "Error opening \n ");
else {
while((entry=readdir(dir))!=NULL) {
cout<<entry->d_name<<endl;
}
}
closedir(dir);
system("pause");
return 0;
} 下面我挂出Python代码吧,python对文件的操作真的是好简单啊,小编突然好喜欢python了
#!/usr/bin/python
import cv2
import numpy as np
import os
print os.getcwd()
def main():
i=1
while i<=27:
str1=str(i)
path="F:\\img\\"+ str1.zfill(4)+'.jpg'
print path
img=cv2.imread(path)
#print img.shape
cv2.imshow("xiaorun",img)
cv2.waitKey(400)
i=i+1
if __name__=='__main__':
main()python批量对图像进行resize,由于对数据集处理,需要对图像批量resize ,很简单,直接贴代码吧;
import cv2
import numpy as np
import os
fullfilename=[]
filepath="/home/xiaorun/deeplerning/classification_keras/images/not_santa/"
filepath1="/home/xiaorun/deeplerning/classification_keras/images/resizename"
for filename in os.listdir(filepath):
print filename
print (os.path.join(filepath,filename))
filelist=os.path.join(filepath,filename)
fullfilename.append(filelist)
i=1
for imagename in fullfilename:
img=cv2.imread(imagename)
img=cv2.resize(img,(256,256))
resizename=str(i)+'.jpg'
isExists = os.path.exists(filepath1)
if not isExists:
os.makedirs(filepath1)
print('mkdir resizename accomploshed')
savename=filepath1+'/'+resizename
cv2.imwrite(savename,img)
print('{} is resized'.format(savename))
i=i+1
文件夹批量复制,将filepath=’/home/xiaorun/deeplerning/keras-yolo3/VOCdevkit/VOC2007/Annotations/’ 复制到filepath1=’/home/xiaorun/deeplerning/keras-yolo3/VOCdevkit/VOC2007/xinjian/’
import numpy as np
import os
import glob
import shutil
filepath='/home/xiaorun/deeplerning/keras-yolo3/VOCdevkit/VOC2007/Annotations/'
filepath1='/home/xiaorun/deeplerning/keras-yolo3/VOCdevkit/VOC2007/xinjian/'
filelist=[]
for filename in os.listdir(filepath):
#print filename
filenamepath=os.path.join(filepath,filename)
#print filenamepath
filelist.append(filenamepath)
isexist = os.path.exists(filepath1)
if not isexist:
os.makedirs(filepath1)
print 'xinjian finished'
i=1
for xmlname in filelist:
fpath, fname = os.path.split(xmlname)
print fpath,fname
dstpath=filepath1+fname
print dstpath
if dstpath is not None:
print "exist"
continue
shutil.copyfile(xmlname,dstpath)
#shutil.move(xmlname,dstfile) 移动文件
print('{} is copy to {}'.format(xmlname,dstpath))将两个文件夹构建成字典查询python代码
import os
import pandas as pd
imagefilepath='/home/xiaorun/data/VOCdevkit/VOC2007/JPEGImages/'
annotationpath='/home/xiaorun/data/VOCdevkit/VOC2007/Annotations/'
fullimagelist=[]
fullannotationlist=[]
for imagename in os.listdir(imagefilepath):
print(imagename)
fulliamgename=os.path.join(imagefilepath,imagename)
fullimagelist.append(fulliamgename)
imagename1=imagename
#print fullimagelist
for annotationname in os.listdir(annotationpath):
annotationname1=annotationname
print(annotationname)
fullannotation=os.path.join(annotationpath,annotationname)
print imagename1.split('.')[-2]
if imagename1.split('.')[-2]==annotationname1.split('.')[-2]:
fullannotationlist.append(fullannotation)
x=dict(zip(fullimagelist,fullannotationlist))
print type (x)
print x
print (x['/home/xiaorun/data/VOCdevkit/VOC2007/JPEGImages/000478.jpg'])















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











