







HashMap还没讲完,还有几篇文章,目前在构思中,HashMap是集合类的精华,底层实现也比较复杂,真正理解了HashMap,也算是上了小小的一层台阶。
这篇文章我们先轻松一下,不讲HashMap,来说说HashSet。如果有点Java基础的童鞋,应该都知道List和Set都实现自Collection,List保证元素的添加顺序,元素可重复。而Set不保证元素的添加顺序,元素不可重复
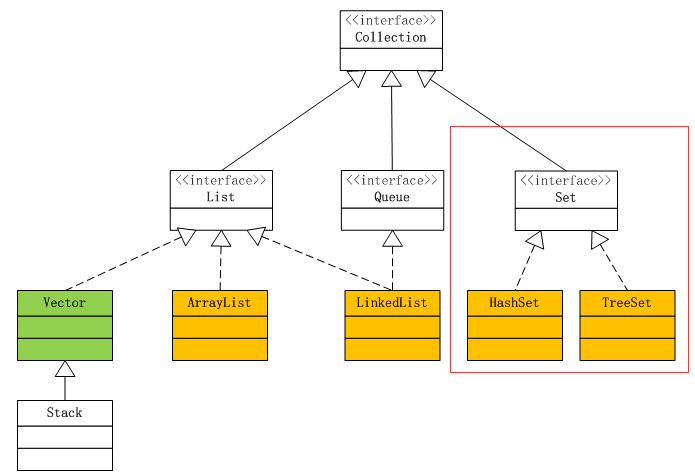
先来看看Set家族在Collection中的位置,红框里的内容就是Set的大家族了,Set接口继承自Collection。有两个很重要的实现HashSet和TreeSet。其中黄色部分前面已经说过了是要重点了解的,老规矩,上代码,大家可以先想一想以下代码的执行结果。
public static void main(String[] args){
Set<String> strSet = new HashSet<>();//new了一个HashSet
strSet.add("张三");
strSet.add("李四");
strSet.add("王五");
strSet.add("赵六");
System.out.println("strSet : " + strSet);
System.out.println("strSet.size() : " + strSet.size());
System.out.println("strSet里是否为空 : " + strSet.isEmpty());
System.out.println("删除王五。。。。");
boolean delFlag = strSet.remove("王五");
System.out.println("删除王五是否成功" + delFlag);
System.out.println("删除王五后的strSet : " + strSet);
System.out.println("strSet中是否包含王五:" + strSet.contains("王五"));
System.out.println("strSet中是否包含张三:" + strSet.contains("张三"));
System.out.println("clear清除元素...");
strSet.clear();
System.out.println("clear清除元素后的strSet : " + strSet);
System.out.println("strSet长度 : " + strSet.size());
System.out.println("strSet里是否为空 : " + strSet.isEmpty());
}先来看第一行代码:
Set<String> strSet = new HashSet<>();//new了一个HashSetnew了一个HashSet,前面的文章已经说过很多次了,只要是看到new,这货肯定在堆内存里开辟了一块空间,先找到HashSet的构造函数看看,看到如下代码:

等等,怎么出现了HashMap,这个HashMap到底是什么鬼?再看一下map,追踪一下

就是一个HashMap,老规矩画图吧
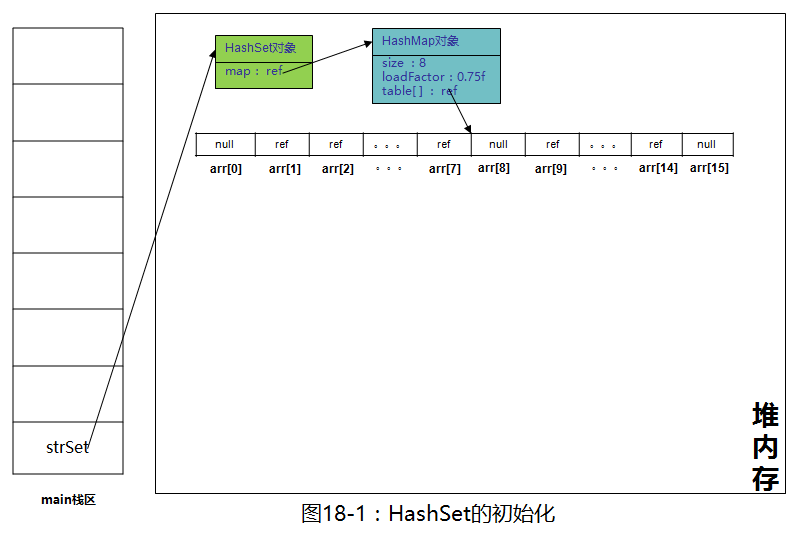
HashMap的初始化在HashMap底层实现原理(上)一文中已经说过了,这里就不再详解了,需要了解的朋友请自行回顾。继续执行以下代码,往strSet添加元素"张三"
strSet.add("张三"); 再看add方法

上面红框里的这行代码和等同于
boolean putFlag = map.put(e,PRESENT);
return putFlag;原来就是调用底层HashMap的put方法,把"张三"作为key,PRESENT作为value放在hashMap里,讲HashMap的时候讲过了,如果put时key重了,会返回被覆盖的value值(oldValue),否则返回null,这儿的HashSet又给包装了一下,如果key没有重(oldValue == null),就返回true,否则返回false。继续看这个PRESENT是什么鬼
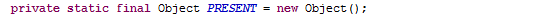
很简单就是new了一个Object,继续画图
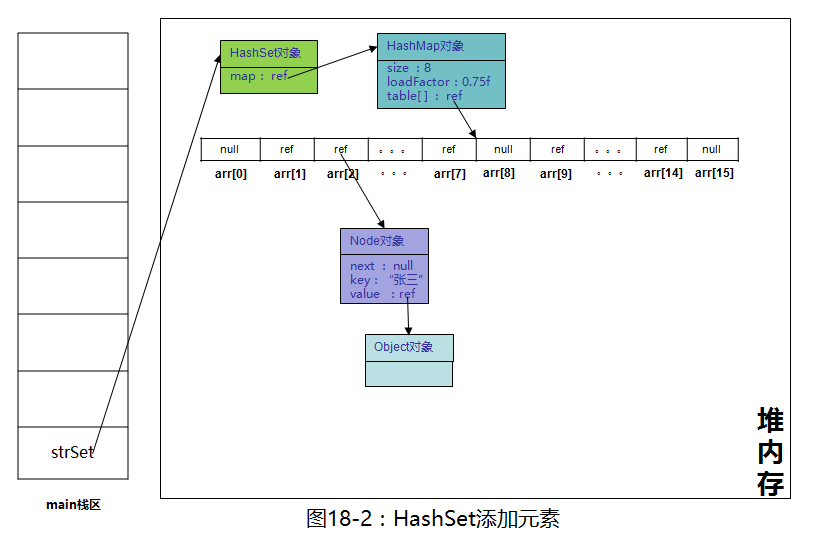
调用底层HashMap的时候,key是传进去的“张三”,value是PRESENT,也就是一个Object对象,继续往里添加“李四”,“王五”,“赵六”
strSet.add("李四");
strSet.add("王五");
strSet.add("赵六"); 依次放入“李四”,“王五”,“赵六”,value都是一样的,为PRESENT,继续画图
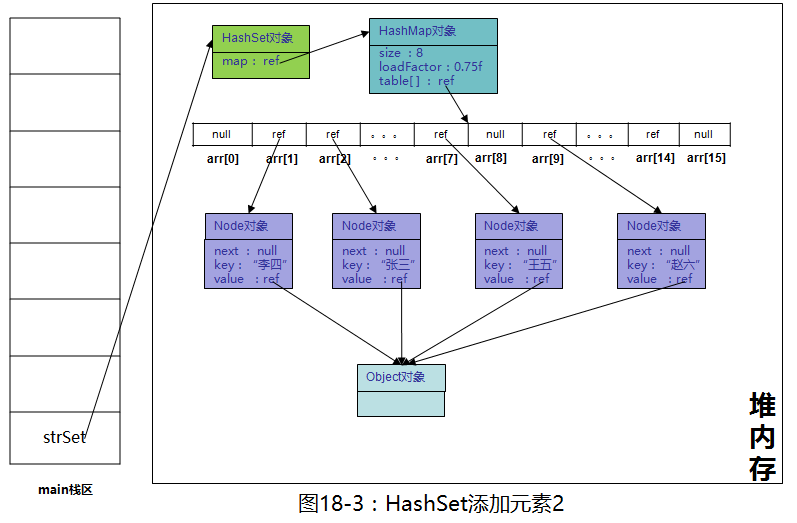
所有元素的value都指向Object对象,HashSet虽然底层是用HashMap来实现的,但由于用不到HashMap的value,所以不会为底层HashMap的每个value分配一个内存空间,因此并不会过多的占用内存,请放心使用。
再来看看示例代码里的size()、isEmpty()、remove()、contains()、clear()等方法的实现

调用的是底层HashMap的size方法

调用的是底层HashMap的isEmpty方法

调用的是底层HashMap的remove方法

调用的是底层HashMap的contains方法

调用的是HashMap的clear方法。
这些方法基本上没什么逻辑代码,就是复用了HashMap里的方法而已。HashSet就是利用HashMap来实现的。这时候我们大胆的猜测一下,TreeSet是不是也是用TreeMap来实现的呢?迫不及待打开TreeSet的源码

构造函数this调了另一个构造函数

再来看m
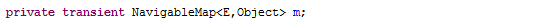
这个m是NavigableMap类型的,NavigableMap只是一个接口而已

再来看TreeMap,实现了NavigableMap这个接口

绕了好大一个圈,其实就是相当于
NavigableMap m = new TreeMap<>();也就是说,TreeSet底层实现也是利用TreeMap来实现的,再来看看TreeSet的其它方法

调用的是底层TreeMap的size方法

调用的是底层TreeMap的isEmpty方法

TreeMap的add方法是调用底层TreeMap的put方法,只是改了个名字而已
其它方法大致上也是如此,就不一一举例说明了,感兴趣的朋友请自行阅读源码。
最后,执行一下本文开始那段示例代码的执行结果

注:本文示例代码,已上传至公众号:saysayJava,需要练习的朋友请自行下载。
小结:HashSet底层声明了一个HashMap,HashSet做了一层包装,操作HashSet里的元素时其实是在操作HashMap里的元素。TreeSet底层也是声明了一个TreeMap,操作TreeSet里的元素其实是操作TreeMap里的元素。
本文刚一上线就收到了大量评论,评论区里有人说TreeSet和LinkedHashSet是有序的,这里强调一下,我们指的Set不保证插入有序是指Set这个接口的规范,实现类只要遵循这个规范即可,当然也可以写有序的版本出来,比如LinkedHashSet。而TreeSet是里面的内容有序(按照一定规则排序),但不是指元素的添加顺序。
注意:大家在写TreeSet测试本文代码的时候,可能刚好得到张三,李四,王五、赵六这样的顺序,这是碰巧,请大家打乱顺序测试。
转载无限欢迎,但请注明「清浅池塘」和「https://zhuanlan.zhihu.com/p/29021276」。转载请在文中保留此段,感谢您对作者版权的尊重。如需商业转载或刊登,请联系作者获得授权。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









