







1.MONGODB副本集高可用架构
------------------------------------------------------------------------------------
1.1 简介
Mongodb复制集由一组Mongod实例(进程)组成,包含一个Primary节点和多个Secondary节点。
Mongodb Driver(客户端)的所有数据都写入Primary,Secondary从Primary同步写入的数据,以保持复制集内所有成员存储相同的数据集,实现数据的高可用。
使用场景:
数据冗余,用做故障恢复使用,当发生硬件故障或者其它原因造成的宕机时,可以使用副本进行恢复。
读写分离,读的请求分流到副本上,减轻主节点的读压力。
一个典型的副本集架构如下图所示:
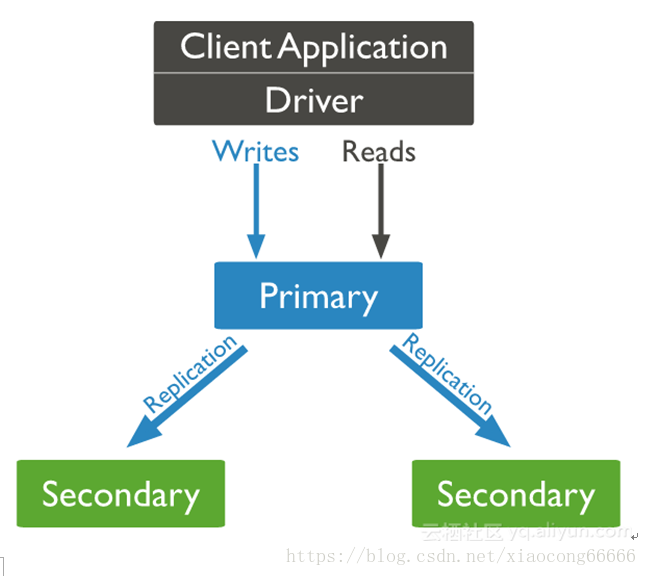
1.2 副本集角色
主节点(Primary):
接收所有的写请求,然后把修改同步到所有Secondary。一个Replica Set只能有一个Primary节点,当Primary挂掉后,其他Secondary或者Arbiter节点会重新选举出来一个主节点。默认读请求也是发到Primary节点处理的,可以通过修改客户端连接配置以支持读取Secondary节点。
副本节点(Secondary):
与主节点保持同样的数据集。当主节点挂掉的时候,参与选主。
仲裁者(Arbiter):
不保有数据,不参与选主,只进行选主投票。使用Arbiter可以减轻数据存储的硬件需求,Arbiter几乎没什么大的硬件资源需求,但重要的一点是,在生产环境下它和其他数据节点不要部署在同一台机器上。
1.3 两种架构模式
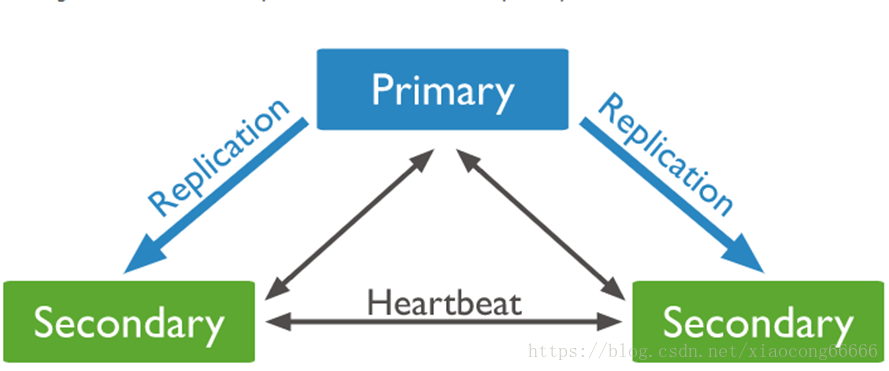
1.3.1 PSS
Primary + Secondary + Secondary模式,通过Primary和Secondary搭建的Replica Set
该模式下 Replica Set节点数必须为奇数,目的是选主投票的时候要出现大多数才能进行选主决策
由一个主和两个次级组成的3个成员副本集的图:
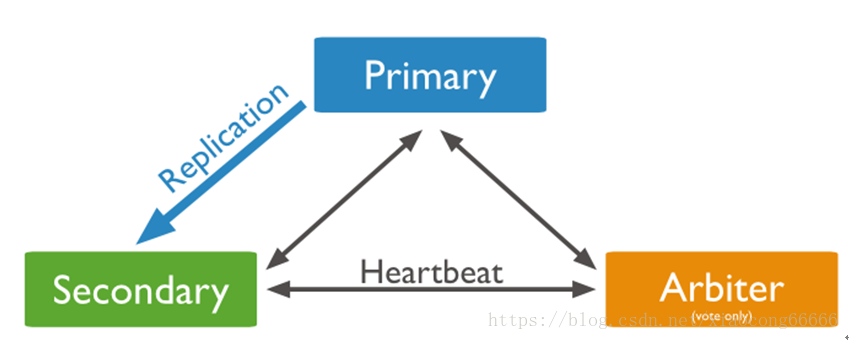
1.3.2 PSA
Primary + Secondary + Arbiter模式,使用Arbiter搭建Replica Set
偶数个数据节点,加一个Arbiter构成的Replica Set
1.4 数据同步
Primary 与 Secondary 之间通过 oplog 来同步数据,Primary 上的写操作完成后,会向特殊的 local.oplog.rs 特殊集合写入一条 oplog,Secondary 不断的从 Primary 取新的 oplog 并应用。
因 oplog 的数据会不断增加,local.oplog.rs 被设置成为一个 capped 集合,当容量达到配置上限时,会将最旧的数据删除掉。另外考虑到 oplog 在 Secondary 上可能重复应用,oplog 必须具有幂等性,即重复应用也会得到相同的结果。
在异常回滚方面,当 Primary 宕机时,如果有数据未同步到 Secondary,当 Primary 重新加入时,如果新的 Primary 上已经发生了写操作,则旧 Primary 需要回滚部分操作,以保证数据集与新的 Primary 一致。旧 Primary 将回滚的数据写到单独的 rollback 目录下,数据库管理员可根据需要使用 mongorestore 进行恢复
如下 oplog 的格式,包含 ts、h、op、ns、o 等字段。
{
"ts" : Timestamp(1446011584, 2),
"h" : NumberLong("1687359108795812092"),
"v" : 2,
"op" : "i",
"ns" : "test.nosql",
"o" : { "_id" : ObjectId("563062c0b085733f34ab4129"), "name" : "mongodb", "score" : "100" }
}
属性说明
ts 操作时间,当前 timestamp + 计数器,计数器每秒都被重置
h 操作的全局唯一标识
v oplog 版本信息
op 操作类型
op.i 插入操作
op.u 更新操作
op.d 删除操作
op.c 执行命令(如 createDatabase,dropDatabase)
op.n 空操作,特殊用途
ns 操作针对的集合
o 操作内容
o2 操作查询条件,仅 update 操作包含该字段
转载,参考:
https://www.cnblogs.com/littleatp/p/8562842.html
https://blog.csdn.net/yisun123456/article/details/79161279














 333
333











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









