






一个请求的生命周期(HTTP请求过程详解、TCP/IP五层网络模型)
一个请求的生命周期
前言:当我们从电脑上去访问一个网址时,究竟发生了什么?这个问题可能是自己思考或者面试的时候问到,这里我们以访问百度首页为例,进行一个全面的HTTP请求分析。
核心概念
计算机网络核心结构,就是TCP/IP五层网络模型(OSI七层模型是将应用层分为了三层)

以及,每一层对应的协议

始于本地
键盘输入:你要访问www.baidu.com,自然需要在浏览器地址栏中使用键盘输入(正常情况下),这个过程就涉及到输入设备与计算机的交互了,这个属于物理层,这里就不探讨了(==其实是我不会)
请求域名:首先你访问的是www.baidu.com,并不带域名,所以浏览器会自动补全协议头。但是我们知道,很多时候域名会有http和https,它俩的默认端口一个是80,一个是443,在这里,一般都是对应域名的网站做了端口转发,http协议实现了HSTS机制来使得重定向到HTTPS下的域名。所以HTTP到HTTPS这个过程是服务器来完成的,至于浏览器的默认端口一直是80端口
路由转发
IP查找:目前我们只知道了带协议类型的域名,那么是如何到具体的服务器的呢?我们知道,对于因特网内每个公有地址IP都是唯一的(局域网内不一定),域名相当于IP的别名,因为我们无法去记住一大堆无意义的IP地址,但如果用一堆有意义的字母组成,大家就能快速访问对应网站。
DNS解析:通过域名去查找IP,先从本地缓存查找,其中本地的hosts文件也绑定了对应IP,若在本机中无法查到,那么就会去请求本地区域的域名服务器(通常是你对应的网络运营商如移动),这个通过网络设置中的LDNS去查找,如果还是没有命中的话,那么就去根域名服务器查找,这里有所有因特网上可访问的域名和IP对应信息(根域名服务器全球共13台)。至少到了这里,我们肯定能查找对应的IP了,要不就是这个域名不对。
路由转发:然后我们通过网卡、路由器、交换机等设备,实现两个IP地址之间的通信。这里用到的主要就是路由转发技术,根据路由表去转发报文。。。还有子网掩码、IP广播等等知识点。这里就不多做介绍了,计算机网络里有详细准确的概念~~
连接建立
三次握手:HTTP的底层基于TCP/IP协议,TCP连接的建立过程少不了三次握手。

第一次握手:客户端主动发送SYN包到服务器,并进入SYN_SEND状态,等待服务器确认
第二次握手:服务器收到SYN包并确认,发送SYN+ACK到客户端,服务器进入SYN_RECV状态
第三次握手:客户端收到SYN+ACK包,发送ACK确认连接,发送完毕后客户端和服务端进入ESTABLISHED状态,完成三次握手
数据发送:建立完连接后,TCP才能真正的开始传输数据==。TCP会依次、有序的发送一定大小的报文,其中包括了超时重传、拥塞窗口、慢开始快重传等等概念。总之加了很多机制,用来保证数据包的完整、有序。当然以上都只是传输层中TCP做的事,实现上在应用层也加了很多机制。
HTTPS:

大家请看这张图,一个完整的HTTPS由以上众多模块组成。
a. Queueing:请求等待时间
b. Stalled: 从TCP建立连接耗时
c. DNS Lookup:DNS解析
d. Initial connection:初始化连接
e. SSL:SSL就是HTTPS的重头戏,相比于HTTP建立于TCP基础上的明文传输,HTTPS基于SSL/TLS,而SSL/TLS又是基于TCP/IP,也就是说SSL/TLS基于TCP基础上再做了一层封装,对内容进行加密。对HTTPS如何实现加密感兴趣的同学可以取看看相关的话题
f. TTFB:客户端发起报文到服务器接收到第一个报文的耗时
g. Content Download:服务器响应网页内容接收时间
GOOGLE原文解释 文档地址需翻墙
Queueing The browser queues requests when:
1There are higher priority requests.
2There are already six TCP connections open for this origin, which is the limit. Applies to HTTP/1.0 and HTTP/1.1 only.
3The browser is briefly allocating space in the disk cache
Stalled The request could be stalled for any of the reasons described in Queueing.
DNS Lookup The browser is resolving the request’s IP address.
Proxy negotiation The browser is negotiating the request with a proxy server.
Request sent The request is being sent.
ServiceWorker Preparation The browser is starting up the service worker.
Request to ServiceWorker The request is being sent to the service worker.
Waiting (TTFB) The browser is waiting for the first byte of a response. TTFB stands for Time To First Byte. This timing includes 1 round trip of latency and the time the server took to prepare the response.
Content Download The browser is receiving the response.
Receiving Push The browser is receiving data for this response via HTTP/2 Server Push.
Reading Push The browser is reading the local data previously received.
服务器处理
LVS架构:这个请求在到达某一个服务器前,可能还要经历重重筛选==。反作弊判断,网关过滤,CDN等等。其中大型网站最常见的是LVS架构。LVS分负载调度器,服务器池,共享存储。主要就是为了分布式和高并发场景啦。
LVS文档

代理服务器:接下来,这个请求总算到了服务器了。去监听它的通常是代理服务器,如Nginx、Apache等。监听到之后代理服务器会将请求转发给对应的socket去处理。比如Nginx和PHP的交互就是Nginx将请求转发给fastcgi_pass定义的socket(文件socket或IPsocket),然后通过fastcgi处理,才会真正将请求和参数丢给server,cgi-app。。。
程序处理
接下来就是代码去处理具体的逻辑,然后通过response返回啦~~

在前两篇文章中,我们完整的描述了计算机网络 OSI 五层模型的相关内容。那么,本篇将会从一个实践案例开始,带你从整体上重新认识我们的计算机网络。 
我们以访问 Google 为例,当我们在浏览器地址栏中敲下回车键之后,整个计算机网络将会发生什么呢?
本机的网络相关参数如下: 
首先我们应用层的浏览器决定向 DNS 服务器请求解析域名「www.google.com」,那么就要遵循 DNS 协议。
DNS 运行在 53 号端口,于是浏览器会创建一个 UDP 套接字,标识该套接字的二元组分别是『目的 IP 地址』和『目的端口』。而套接字本质上就是为了唯一标识应用层进程,就是为了让响应报文能够找到目的地。
那么这里会创建一个 UDP 套接字,二元组为「本机 IP 地址 192.168.43.138」和「随机产生一个未使用的端口号」。
接着,浏览器将 DNS 请求报文封装好推入套接字,开始我们的 DNS 解析过程。
有关 DNS 的相关细节,这里不再赘述了,可以参考前面的文章,拿到 DNS 服务器的响应报文,运输层拆开数据报,得到该报文的目的 IP 地址和目的端口号,于是对应着去找套接字交付报文即可。
最终我们会从『本地 DNS 服务器』得到 Google 的 IP 地址为:172.194.72.105。
整个 HTTP 请求可以说才刚刚开始:
应用层
浏览器封装 HTTP 请求报文,然后创建一个 TCP 套接字,采用四元组标识,具体为「源 IP 地址:192.168.43.138」+「源端口号:随机的,这里假设为 1234」+「目的 IP 地址:172.194.72.105」+「目的端口号:80」。
HTTP 报文也就是我们的应用层数据报,大致是这样的: 
指定了一些请求参数与动作,以及一些要求响应报文的返回格式要求,具体的我们不细说了。
紧接着,这个报文会被推进 TCP 套接字中,等待运输层来收取。
运输层
运输层收取了报文,并判断与目的主机是否建立了 TCP 连接,这里假设没有。
那么,运输层将不急着发送应用层数据,得先判断与目的主机之间能够正常通讯,也就是需要『握手』打招呼。
『三次握手』的相关细节,我们这里也不再赘述了,上篇文章描述的很详细了,通过『三次握手』,发送端和接收端确认过发送与确认序号,分配了相应的缓存资源等。
一切准备就绪之后,运输层将应用层发过来的数据报又一层封装,添加进『源端口号』和『目的端口号』以及相关差错检验字段。
最后将 TCP 数据报向下传递到网络层。
网络层
网络层其实很简单,拿到数据报并封装成 IP 数据报,即在原 TCP 报文的前提之上添加『源 IP 地址』和『目的 IP 地址』等字段信息。
然后交由数据链路层。
链路层
数据链路层拿到 IP 数据报,它需要封装成以太网帧才能在网络中传输,也就是它需要目的主机的 Mac 地址,然而我们只知道目的主机的 IP 地址。
所以,链路层有一个 ARP 协议,直接或间接的能够根据目的 IP 地址获得使用该 IP 地址的主机 Mac 地址。
当然,ARP 协议运行的前提是,目的 IP 地址和当前发送方主机处于同一子网络中。如果不然,发送方将目的 Mac 地址填自己网关路由的 Mac 地址,然后通过物理层发送出去。
网关路由由于具有转发表和路由选择算法,所以它知道目的网络该怎么到达,所以一路转发,最终会发送到目的网络的网关路由上。
最后,目的网络的网关路由同样会经由 ARP 协议,取得目的主机的 Mac 地址,然后广播发送,最后被目的主机接受。
这样谷歌的服务器就接受到一个 HTTP 请求,于是它解析这个请求,确定该请求的动作是什么,也就是它需要什么东西,并构建响应报文,以同样的方式从网络到达源主机。
最后你将看到你想要的谷歌搜索页面: 
整体上我们自顶而下的描述了一个请求到达目的地的完整过程,旨在宏观上建立完整的框架体系,相关细节之处可以参照前两篇文章。
浏览器输入网址到响应的整个过程-http 请求到响应详解
这一过程详细来讲涉及到计算机的整个网络架构系统,从应用层到物理层都可以讲述。本讲聚焦应用层发生了什么事。
在应用层,浏览器首先需要获得将要访问的网站的 IP 地址,因此首先需要进行域名解析,从网址提取出域名,然后进行 DNS 请求(UDP)。首先在本机的域名缓存中查询,若查询不到再到直连的路由器中查询,还是没有则到直连的网络服务提供商的 DNS 服务器查询,查询不到则会有两种方式继续查询一种是递归方式,即一级一级的往上一级 DNS 服务器查询,直到根 DNS 服务器,此时基本能查到;
示例:
主机——>本地 DNS 服务器——>权限 DNS 服务器——>顶级 DNS 服务器——>根服务器。其结果是要么能查到要么报错。
一种是非递归方式,即直接找根 DNS 服务器,然后由它指示要找哪一个根服务器的下一级 DNS 服务器。
当查到需要的 IP 地址后,地址中没有端口的话则使用 HTTP 协议的默认短号,进行 TCP 的三次握手,与对端主机连接。
成功连接后,则可以向对端主机发送 HTTP 请求,成功收到响应则进行断连,即 TCP 的四次挥手。若响应是重定向,则需要再一次发送 HTTP 请求到重定向的地址(是否需要重新 DNS 解析?)
最后浏览器解析服务器的响应内容,并显示再浏览器页面。
参考链接:
https://blog.csdn.net/lzghxjt/article/details/51458540
https://www.jianshu.com/p/aa97810e5fa4
在浏览器中输入www.baidu.com后执行的全部过程
在浏览器中输入www.baidu.com后执行的全部过程
1、客户端浏览器通过DNS解析到www.baidu.com的IP地址220.181.27.48,通过这个IP地址找到客户端到服务器的路径。客户端浏览器发起一个HTTP会话到220.161.27.48,然后通过TCP进行封装数据包,输入到网络层。
2、在客户端的传输层,把HTTP会话请求分成报文段,添加源和目的端口,如服务器使用80端口监听客户端的请求,客户端由系统随机选择一个端口如5000,与服务器进行交换,服务器把相应的请求返回给客户端的5000端口。然后使用IP层的IP地址查找目的端。
3、客户端的网络层不用关心应用层或者传输层的东西,主要做的是通过查找路由表确定如何到达服务器,期间可能经过多个路由器,这些都是由路由器来完成的工作,我不作过多的描述,无非就是通过查找路由表决定通过那个路径到达服务器。
4、客户端的链路层,包通过链路层发送到路由器,通过邻居协议查找给定IP地址的MAC地址,然后发送ARP请求查找目的地址,如果得到回应后就可以使用ARP的请求应答交换的IP数据包现在就可以传输了,然后发送IP数据包到达服务器的地址。
事件顺序
(1) 浏览器获取输入的域名www.baidu.com
(2) 浏览器向DNS请求解析www.baidu.com的IP地址
(3) 域名系统DNS解析出百度服务器的IP地址
(4) 浏览器与该服务器建立TCP连接(默认端口号80)
(5) 浏览器发出HTTP请求,请求百度首页
(6) 服务器通过HTTP响应把首页文件发送给浏览器
(7) TCP连接释放
(8) 浏览器将首页文件进行解析,并将Web页显示给用户。
涉及到的协议
(1) 应用层:HTTP(WWW访问协议),DNS(域名解析服务)
DNS解析域名为目的IP,通过IP找到服务器路径,客户端向服务器发起HTTP会话,然后通过运输层TCP协议封装数据包,在TCP协议基础上进行传输
(2) 传输层:TCP(为HTTP提供可靠的数据传输),UDP(DNS使用UDP传输)
HTTP会话会被分成报文段,添加源、目的端口;TCP协议进行主要工作
(3)网络层:IP(IP数据数据包传输和路由选择),
为数据包选择路由,IP协议进行主要工作
(4)数据链路层:ICMP(提供网络传输过程中的差错检测),ARP(将本机的默认网关IP地址映射成物理MAC地址)
相邻结点的可靠传输,ARP协议将IP地址转成MAC地址。
作为一个软件开发者,你一定会对网络应用如何工作有一个完整的层次化的认知,同样这里也包括这些应用所用到的技术:像浏览器,HTTP,HTML,网络服务器,需求处理等等。
本文将更深入的研究当你输入一个网址的时候,后台到底发生了一件件什么样的事~
1. 首先嘛,你得在浏览器里输入要网址:
2. 浏览器查找域名的IP地址
导航的第一步是通过访问的域名找出其IP地址。DNS查找过程如下:
- 浏览器缓存 – 浏览器会缓存DNS记录一段时间。 有趣的是,操作系统没有告诉浏览器储存DNS记录的时间,这样不同浏览器会储存个自固定的一个时间(2分钟到30分钟不等)。
- 系统缓存 – 如果在浏览器缓存里没有找到需要的记录,浏览器会做一个系统调用(windows里是gethostbyname)。这样便可获得系统缓存中的记录。
- 路由器缓存 – 接着,前面的查询请求发向路由器,它一般会有自己的DNS缓存。
- ISP DNS 缓存 – 接下来要check的就是ISP缓存DNS的服务器。在这一般都能找到相应的缓存记录。
- 递归搜索 – 你的ISP的DNS服务器从跟域名服务器开始进行递归搜索,从.com顶级域名服务器到Facebook的域名服务器。一般DNS服务器的缓存中会有.com域名服务器中的域名,所以到顶级服务器的匹配过程不是那么必要了。
DNS递归查找如下图所示:
DNS有一点令人担忧,这就是像wikipedia.org 或者 facebook.com这样的整个域名看上去只是对应一个单独的IP地址。还好,有几种方法可以消除这个瓶颈:
- 循环 DNS 是DNS查找时返回多个IP时的解决方案。举例来说,Facebook.com实际上就对应了四个IP地址。
- 负载平衡器 是以一个特定IP地址进行侦听并将网络请求转发到集群服务器上的硬件设备。 一些大型的站点一般都会使用这种昂贵的高性能负载平衡器。
- 地理 DNS 根据用户所处的地理位置,通过把域名映射到多个不同的IP地址提高可扩展性。这样不同的服务器不能够更新同步状态,但映射静态内容的话非常好。
- Anycast 是一个IP地址映射多个物理主机的路由技术。 美中不足,Anycast与TCP协议适应的不是很好,所以很少应用在那些方案中。
大多数DNS服务器使用Anycast来获得高效低延迟的DNS查找。
3. 浏览器给web服务器发送一个HTTP请求
因为像Facebook主页这样的动态页面,打开后在浏览器缓存中很快甚至马上就会过期,毫无疑问他们不能从中读取。
所以,浏览器将把一下请求发送到Facebook所在的服务器:
GET http://facebook.com/ HTTP/1.1 Accept: application/x-ms-application, image/jpeg, application/xaml+xml, [...] User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; [...] Accept-Encoding: gzip, deflate Connection: Keep-Alive Host: facebook.com Cookie: datr=1265876274-[...]; locale=en_US; lsd=WW[...]; c_user=2101[...]
GET 这个请求定义了要读取的URL: “http://facebook.com/”。 浏览器自身定义 (User-Agent 头), 和它希望接受什么类型的相应 (Accept and Accept-Encoding头). Connection头要求服务器为了后边的请求不要关闭TCP连接。
请求中也包含浏览器存储的该域名的cookies。可能你已经知道,在不同页面请求当中,cookies是与跟踪一个网站状态相匹配的键值。这样cookies会存储登录用户名,服务器分配的密码和一些用户设置等。Cookies会以文本文档形式存储在客户机里,每次请求时发送给服务器。
用来看原始HTTP请求及其相应的工具很多。作者比较喜欢使用fiddler,当然也有像FireBug这样其他的工具。这些软件在网站优化时会帮上很大忙。
除了获取请求,还有一种是发送请求,它常在提交表单用到。发送请求通过URL传递其参数(e.g.: http://robozzle.com/puzzle.aspx?id=85)。发送请求在请求正文头之后发送其参数。
像“http://facebook.com/”中的斜杠是至关重要的。这种情况下,浏览器能安全的添加斜杠。而像“http: //example.com/folderOrFile”这样的地址,因为浏览器不清楚folderOrFile到底是文件夹还是文件,所以不能自动添加 斜杠。这时,浏览器就不加斜杠直接访问地址,服务器会响应一个重定向,结果造成一次不必要的握手。
4. facebook服务的永久重定向响应
图中所示为Facebook服务器发回给浏览器的响应:
HTTP/1.1 301 Moved Permanently Cache-Control: private, no-store, no-cache, must-revalidate, post-check=0, pre-check=0 Expires: Sat, 01 Jan 2000 00:00:00 GMT Location: http://www.facebook.com/ P3P: CP="DSP LAW" Pragma: no-cache Set-Cookie: made_write_conn=deleted; expires=Thu, 12-Feb-2009 05:09:50 GMT; path=/; domain=.facebook.com; httponly Content-Type: text/html; charset=utf-8 X-Cnection: close Date: Fri, 12 Feb 2010 05:09:51 GMT Content-Length: 0
服务器给浏览器响应一个301永久重定向响应,这样浏览器就会访问“http://www.facebook.com/” 而非“http://facebook.com/”。
为什么服务器一定要重定向而不是直接发会用户想看的网页内容呢?这个问题有好多有意思的答案。
其中一个原因跟搜索引擎排名有 关。你看,如果一个页面有两个地址,就像http://www.igoro.com/ 和http://igoro.com/,搜索引擎会认为它们是两个网站,结果造成每一个的搜索链接都减少从而降低排名。而搜索引擎知道301永久重定向是 什么意思,这样就会把访问带www的和不带www的地址归到同一个网站排名下。
还有一个是用不同的地址会造成缓存友好性变差。当一个页面有好几个名字时,它可能会在缓存里出现好几次。
5. 浏览器跟踪重定向地址
现在,浏览器知道了“http://www.facebook.com/”才是要访问的正确地址,所以它会发送另一个获取请求:
GET http://www.facebook.com/ HTTP/1.1 Accept: application/x-ms-application, image/jpeg, application/xaml+xml, [...] Accept-Language: en-US User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; [...] Accept-Encoding: gzip, deflate Connection: Keep-Alive Cookie: lsd=XW[...]; c_user=21[...]; x-referer=[...] Host: www.facebook.com
头信息以之前请求中的意义相同。
6. 服务器“处理”请求
服务器接收到获取请求,然后处理并返回一个响应。
这表面上看起来是一个顺向的任务,但其实这中间发生了很多有意思的东西- 就像作者博客这样简单的网站,何况像facebook那样访问量大的网站呢!
- Web 服务器软件
web服务器软件(像IIS和阿帕奇)接收到HTTP请求,然后确定执行什么请求处理来处理它。请求处理就是一个能够读懂请求并且能生成HTML来进行响应的程序(像ASP.NET,PHP,RUBY...)。举 个最简单的例子,需求处理可以以映射网站地址结构的文件层次存储。像http://example.com/folder1/page1.aspx这个地 址会映射/httpdocs/folder1/page1.aspx这个文件。web服务器软件可以设置成为地址人工的对应请求处理,这样 page1.aspx的发布地址就可以是http://example.com/folder1/page1。
- 请求处理
请求处理阅读请求及它的参数和cookies。它会读取也可能更新一些数据,并讲数据存储在服务器上。然后,需求处理会生成一个HTML响应。
所 有动态网站都面临一个有意思的难点 -如何存储数据。小网站一半都会有一个SQL数据库来存储数据,存储大量数据和/或访问量大的网站不得不找一些办法把数据库分配到多台机器上。解决方案 有:sharding (基于主键值讲数据表分散到多个数据库中),复制,利用弱语义一致性的简化数据库。
委 托工作给批处理是一个廉价保持数据更新的技术。举例来讲,Fackbook得及时更新新闻feed,但数据支持下的“你可能认识的人”功能只需要每晚更新 (作者猜测是这样的,改功能如何完善不得而知)。批处理作业更新会导致一些不太重要的数据陈旧,但能使数据更新耕作更快更简洁。
7. 服务器发回一个HTML响应
图中为服务器生成并返回的响应:
HTTP/1.1 200 OK Cache-Control: private, no-store, no-cache, must-revalidate, post-check=0, pre-check=0 Expires: Sat, 01 Jan 2000 00:00:00 GMT P3P: CP="DSP LAW" Pragma: no-cache Content-Encoding: gzip Content-Type: text/html; charset=utf-8 X-Cnection: close Transfer-Encoding: chunked Date: Fri, 12 Feb 2010 09:05:55 GMT 2b3Tn@[...]
整个响应大小为35kB,其中大部分在整理后以blob类型传输。
内容编码头告诉浏览器整个响应体用gzip算法进行压缩。解压blob块后,你可以看到如下期望的HTML:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en" id="facebook" class=" no_js"> <head> <meta http-equiv="Content-type" content="text/html; charset=utf-8" /> <meta http-equiv="Content-language" content="en" /> ...
关于压缩,头信息说明了是否缓存这个页面,如果缓存的话如何去做,有什么cookies要去设置(前面这个响应里没有这点)和隐私信息等等。
请注意报头中把Content-type设置为“text/html”。报头让浏览器将该响应内容以HTML形式呈现,而不是以文件形式下载它。浏览器会根据报头信息决定如何解释该响应,不过同时也会考虑像URL扩展内容等其他因素。
8. 浏览器开始显示HTML
在浏览器没有完整接受全部HTML文档时,它就已经开始显示这个页面了:
9. 浏览器发送获取嵌入在HTML中的对象
在浏览器显示HTML时,它会注意到需要获取其他地址内容的标签。这时,浏览器会发送一个获取请求来重新获得这些文件。
下面是几个我们访问facebook.com时需要重获取的几个URL:
- 图片
http://static.ak.fbcdn.net/rsrc.php/z12E0/hash/8q2anwu7.gif
http://static.ak.fbcdn.net/rsrc.php/zBS5C/hash/7hwy7at6.gif
… - CSS 式样表
http://static.ak.fbcdn.net/rsrc.php/z448Z/hash/2plh8s4n.css
http://static.ak.fbcdn.net/rsrc.php/zANE1/hash/cvtutcee.css
… - JavaScript 文件
http://static.ak.fbcdn.net/rsrc.php/zEMOA/hash/c8yzb6ub.js
http://static.ak.fbcdn.net/rsrc.php/z6R9L/hash/cq2lgbs8.js
…
这些地址都要经历一个和HTML读取类似的过程。所以浏览器会在DNS中查找这些域名,发送请求,重定向等等...
但 不像动态页面那样,静态文件会允许浏览器对其进行缓存。有的文件可能会不需要与服务器通讯,而从缓存中直接读取。服务器的响应中包含了静态文件保存的期限 信息,所以浏览器知道要把它们缓存多长时间。还有,每个响应都可能包含像版本号一样工作的ETag头(被请求变量的实体值),如果浏览器观察到文件的版本 ETag信息已经存在,就马上停止这个文件的传输。
试着猜猜看“fbcdn.net”在地址中代表什么?聪明的答案是"Facebook内容分发网络"。Facebook利用内容分发网络(CDN)分发像图片,CSS表和JavaScript文件这些静态文件。所以,这些文件会在全球很多CDN的数据中心中留下备份。
静态内容往往代表站点的带宽大小,也能通过CDN轻松的复制。通常网站会使用第三方的CDN。例如,Facebook的静态文件由最大的CDN提供商Akamai来托管。
举例来讲,当你试着ping static.ak.fbcdn.net的时候,可能会从某个akamai.net服务器上获得响应。有意思的是,当你同样再ping一次的时候,响应的服务器可能就不一样,这说明幕后的负载平衡开始起作用了。
10. 浏览器发送异步(AJAX)请求
在Web 2.0伟大精神的指引下,页面显示完成后客户端仍与服务器端保持着联系。
以 Facebook聊天功能为例,它会持续与服务器保持联系来及时更新你那些亮亮灰灰的好友状态。为了更新这些头像亮着的好友状态,在浏览器中执行的 JavaScript代码会给服务器发送异步请求。这个异步请求发送给特定的地址,它是一个按照程式构造的获取或发送请求。还是在Facebook这个例 子中,客户端发送给http://www.facebook.com/ajax/chat/buddy_list.php一个发布请求来获取你好友里哪个 在线的状态信息。
提起这个模式,就必须要讲讲"AJAX"-- “异步JavaScript 和 XML”,虽然服务器为什么用XML格式来进行响应也没有个一清二白的原因。再举个例子吧,对于异步请求,Facebook会返回一些JavaScript的代码片段。
除了其他,fiddler这个工具能够让你看到浏览器发送的异步请求。事实上,你不仅可以被动的做为这些请求的看客,还能主动出击修改和重新发送它们。AJAX请求这么容易被蒙,可着实让那些计分的在线游戏开发者们郁闷的了。(当然,可别那样骗人家~)
Facebook聊天功能提供了关于AJAX一个有意思的问题案例:把数据从服务器端推送到客户端。因为HTTP是一个请求-响应协议,所以聊天服务器不能把新消息发给客户。取而代之的是客户端不得不隔几秒就轮询下服务器端看自己有没有新消息。
这些情况发生时长轮询是个减轻服务器负载挺有趣的技术。如果当被轮询时服务器没有新消息,它就不理这个客户端。而当尚未超时的情况下收到了该客户的新消息,服务器就会找到未完成的请求,把新消息做为响应返回给客户端。
基于Web的HTTP请求/响应生命周期的关键点
路由
建立一个复杂将URL映射到函数的路由器。
函数执行
函数应该通过异步的方式执行,一旦函数执行完成,就应该执行一个回调函数。
响应/渲染
一旦执行完成,就应该通过异步的方式执行渲染。
序列化
在执行、渲染阶段获取和使用过的所有数据都应该成为服务器端响应的一部分。
反序列化
任何对象和数据都需要在客户端重新创建,因为当用户和应用进行交互时,客户端运行时需要用到这些数据。
添加事件
应绑定事件处理器,以便应用可交互。
#目录
##1、基本概念
* 什么是CGI?
* 部分专业术语解释
* 图解静态请求和动态请求
* php组成
##2、PHP的生命周期
##3、PHP底层工作原理
###基本概念
####1.什么是CGI?
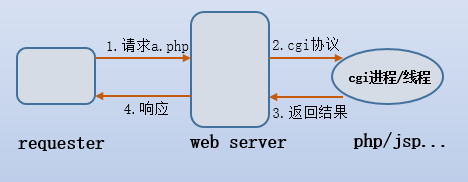
1)什么是cgi呢?
CGI是common gateway interface的缩写,译作通用网关接口,但很不幸,我们无法见名知意,我们知道,web服务器所处理的内容都是静态的,要想处理动态内容,需要依赖于web应用程序,如php、jsp、python、perl等。但是web server如何将动态的请求传递给这些应用程序?它所依赖的就是cgi协议。没错,是协议,也就是web server和web应用程序交流时的规范。换句话说,通过cgi协议,再结合已搭建好的web应用程序,就可以让web server也能"处理"动态请求,你肯定知道处理两字为什么要加上双引号。
简单版的cgi工作方式如下:
***
####2.部分专业术语解释
#####CGI:
**概念**:它是一种协议。通过cgi协议,web server可以将动态请求和相关参数发送给专门处理动态内容的应用程序。
**工作原理**:CGI方式在遇到连接请求(用户请求)先要创建cgi的子进程,激活一个CGI进程,然后处理请求,处理完后结束这个子进程。这就是fork-and-execute模式。所以用cgi方式的服务器有多少连接请求就会有多少cgi子进程,子进程反复加载是cgi性能低下的主要原因。当用户请求数量非常多时,会大量挤占系统的资源如内存,CPU时间等,造成效能低下。
***
#####2)FASTCGI:
**概念**:也是一种协议,只不过是cgi的优化版。cgi的性能较烂,fastcgi则在其基础上进行了改进。FastCGI技术目前支持语言有:C/C++、Java、Perl、Tcl、Python、SmallTalk、Ruby等
**工作原理**:fast-cgi是cgi的升级版本,是一个进程可以处理多个请求,和上面的cgi协议完全不一样,cgi是一个进程只能处理一个请求,这样就会导致大量的cgi程序,因此会给服务器带来负担。FastCGI像是一个常驻型的CGI,它可以一直执行着,只要激活后,不会每次都要花费时间去fork一次
***
#####3)PHP-CGI:
**概念**:PHP-CGI是PHP自带的FastCGI管理器。
**工作原理**:fastcgi是一种协议,而php-cgi实现了这种协议。不过这种实现比较烂。它是单进程的,一个进程处理一个请求,处理结束后进程就销毁。
#####4)PHP-FPM:
**概念**:PHP-FPM是一个PHP FastCGI管理器,是只用于PHP的是对php-cgi的改进版,它直接管理多个php-cgi进程/线程。也就是说,php-fpm是php-cgi的进程管理器因此它也算是fastcgi协议的实现。
**工作原理**:php-fpm会开启多个php-cgi程序,并且php-fpm常驻内存,每次web serve服务器发送连接过来的时候,php-fpm将连接信息分配给下面其中的一个子程序php-cgi进行处理,处理完毕这个php-cgi并不会关闭,而是继续等待下一个连接(一个进程至少服务上万次请求才退出),这也是fast-cgi加速的原理,但是由于php-fpm是多进程的,而一个php-cgi基本消耗7-25M内存,因此如果连接过多就会导致内存消耗过大,引发一些问题,例如nginx里的502错误。
**为什么一定要退出?**因为担心RINIT->RSHUTDOWN循环,有哪个代码写的不好,变量一直没释放,内存泄露GC又回收不了。php-fpm里的pm.max_requests配置就是设置RINT循环多少次,退出进程。
**同时php-fpm还附带一些其他的功能**:例如平滑过渡配置更改,普通的php-cgi在每次更改配置后,需要重新启动才能初始化新的配置,而php-fpm是不需要,php-fpm分将新的连接发送给新的子程序php-cgi,这个时候加载的是新的配置,而原先**正在运行**的php-cgi还是使用的原先的配置,等到**这个连接后下一次连接**的时候会使用新的配置初始化,这就是**平滑过渡**。
***
#####5)CGI进程/线程
**概念**:在php上,就是php-cgi进程/线程。专门用于接收web server的动态请求,**调用并初始化zend虚拟机。**
***
#####6)CGI脚本:
**概念**:被执行的php源代码文件。
***
#####7)ZEND虚拟机:
**概念**:对php文件做词法分析、语法分析、编译成opcode,并执行。最后关闭zend虚拟机。
**CGI进程/线程和ZEND虚拟机的关系**:cgi进程调用并初始化zend虚拟机的各种环境。
***
#####8)常见的SAPI
SAPI提供了一个和外部通信的接口,常见的SAPI有:cgi 、fast-cgi、cli、isapi、apache 模块的 DLL
***
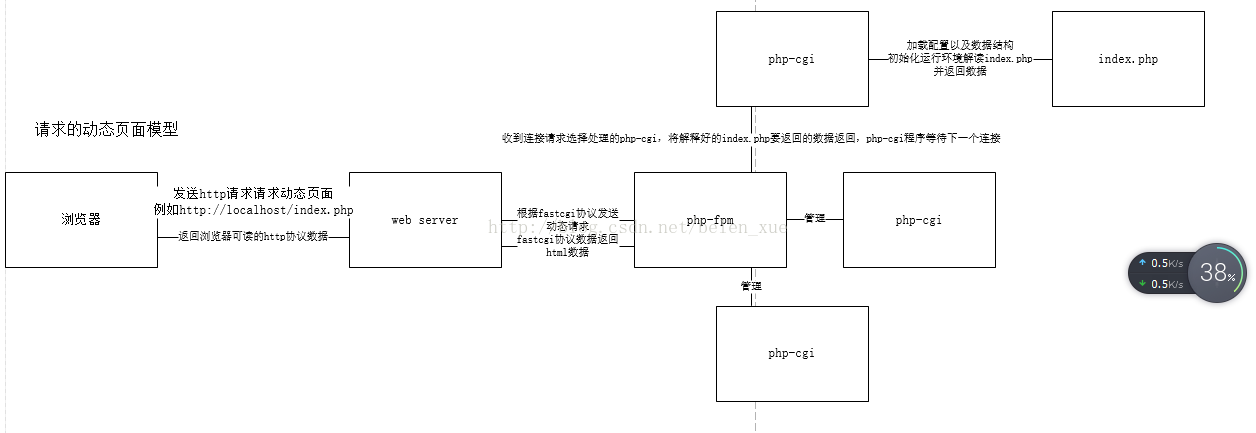
####3.图解静态请求和动态请求

***
###4.PHP的组成
**PHP总共有三个模块:内核、Zend引擎、以及扩展层。**
**PHP内核**用来处理请求、文件流、错误处理等相关操作。
**Zend引擎**用以将源文件转换成机器语言,然后在虚拟机上运行它。
**扩展层**是一组函数、类库和流,PHP使用它们来执行一些特定的操作。
比如,我们需要mysql扩展来连接MySQL数据库; 当ZE执行程序时可能会需要连接若干扩展,这时ZE将控制权交给扩展,等处理完特定任务后再返还;最后,ZE将程序运行结果返回给PHP内核,它再将结果传送给SAPI层,最终输出到浏览器上。
####5、WEB-SERVER和PHP-CGI的交互模式
web server和php-cgi有3种交互模式。
* **cgi模式**:httpd接收到一个动态请求就fork一个cgi进程,cgi进程返回结果给httpd进程后自我销毁。
* **动态模块模式**:将php-cgi的模块编译进httpd(Apache的方法)。在httpd启动时会加载模块,加载时也将对应的模块激活,php-cgi也就启动了。(注:纠正一个小小错误,很多人以为动态编译的模块是可以在需要的时候随时加载调用,不需要的时候它们就停止了,实际上不是这样的。和静态编译的模块一样,动态加载的模块在被加载时就被加入到激活链表中,无论是否使用它,它都已经运行在apache httpd的内部)
* **php-fpm模式**:使用php-fpm管理php-cgi,此时httpd不再控制php-cgi进程的启动。可以将php-fpm独立运行在非web服务器上,实现所谓的动静分离。
实际上,借助模块mod_fastcgi还可以实现fastcgi模式。同cgi一样,管理模式的先天缺陷决定了这并不是一种好方法。
###
###2、PHP的生命周期
####流程图解:

####PHP开始和结束阶段:

由上面的图,我们能知道,SAPI运行PHP都经过下面几个阶段
* 模块初始化阶段(Module init):即调用每个拓展源码中的的PHP\_MINIT\_FUNCTION中的方法初始化模块,进行一些模块所需变量的申请,内存分配等。
* 请求初始化阶段(Request init):即接受到客户端的请求后调用每个拓展的PHP\_RINIT\_FUNCTION中的方法,初始化PHP脚本的执行环境。
* 执行PHP脚本
* 请求结束(Request Shutdown):这时候调用每个拓展的PHP\_RSHUTDOWN\_FUNCTION方法清理请求现场,并且ZE开始回收变量和内存。
* 关闭模块(Module shutdown): Web服务器退出或者命令行脚本执行完毕退出会调用拓展源码中的PHP\_MSHUTDOWN\_FUNCTION 方法。
####我们具体来看看每一步都做了什么?
1)**模块初始化阶段**:
在整个SAPI生命周期内(例如Apache启动以后的整个生命周期内或者命令行程序整个执行过程中), 该过程只进行一次,第一步的操作在任何请求到达之前就发生了。
PHP调用各个扩展的MINIT方法,从而使这些扩展切换到可用状态。我们可以看看php.ini文件里打开了哪些扩展,这些扩展会在这个阶段进行”模块初始化“。 MINIT的意思是“模块初始化”。各个模块都定义了一组函数、类库等用以处理其他请求。
2) **请求初始化**:
当一个页面请求发生时,SAPI层将控制权交给PHP层。于是PHP设置了用于回复本次请求所需的环境变量。同时,它还建立一个变量表,用来存放执行过程 中产生的变量名和值。PHP调用各个模块的RINIT方法,即“请求初始化”。一个经典的例子是Session模块的RINIT,如果在php.ini中 启用了Session模块,那在调用该模块的RINIT时就会初始化$_SESSION变量,并将相关内容读入;RINIT方法可以看作是一个准备过程, 在程序执行之间就会自动启动。
3)**执行脚本**
一旦请求被初始化了,ZE开始接管控制权,将PHP脚本翻译成符号(OPcode),最终形成操作码并逐步运行之。如任一操作码需要调用扩展的函数,ZE将会把参数绑定到该函数,并且临时交出控制权直到函数运行结束。
1. scanner
将PHP代码转换为Tokens,详见代码Zend/zend\_language\_scanner.l。
2. parser
将Tokens转换成表达式,详见代码Zend/zend\_language\_parser.y。
3. compile
将表达式编译成opcode。opcode存放在op\_array中。
4. execute
Zend Engine调用zend\_execute来执行op\_array,输出结果。
4)**关闭第一步(请求关闭)**
如同PHP启动一样,PHP的关闭也分两步。一旦页面执行完毕(无论是执行到了文件末尾还是用exit或die函数中止),PHP就会启动清理程序。它会按顺序调用各个模块的RSHUTDOWN方法。 RSHUTDOWN用以清除程序运行时产生的符号表,也就是对每个变量调用unset函数。
5)**关闭第二步(模块关闭)**
所有的请求都已处理完毕,SAPI也准备关闭了,PHP开始执行第二步:PHP调用每个扩展的MSHUTDOWN方法,这是各个模块最后一次释放内存的机会。
**这样,整个PHP生命周期就结束了。要注意的是,只有在服务器没有请求的情况下才会执行“启动第一步”和“关闭第二步”。**
###3、PHP底层工作原理
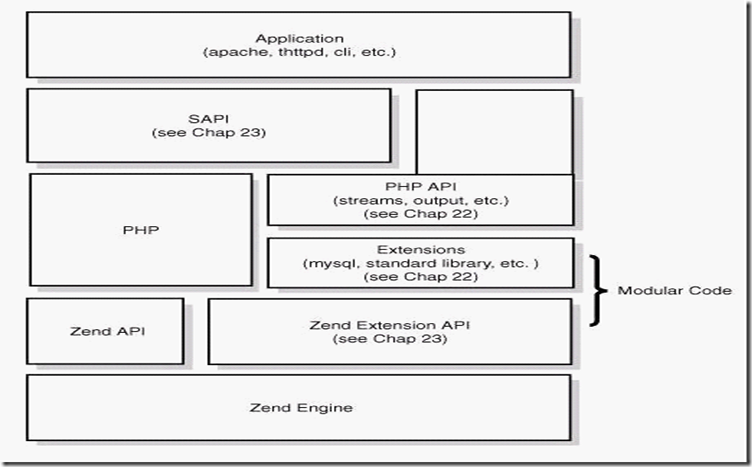
**从图上可以看出,php从下到上是一个4层体系**
**①Zend引擎**
Zend整体用纯c实现,是php的内核部分,它将php代码翻译(词法、语法解析等一系列编译过程)为可执行opcode的处理并实现相应的处理方法、实现了基本的数据结构(如hashtable、oo)、内存分配及管理、提供了相应的api方法供外部调用,是一切的核心,所有的外围功能均围绕zend实现。
**②Extensions**
围绕着zend引擎,extensions通过组件式的方式提供各种基础服务,我们常见的各种内置函数(如array系列)、标准库等都是通过extension来实现,用户也可以根据需要实现自己的extension以达到功能扩展、性能优化等目的(如贴吧正在使用的php中间层、富文本解析就是extension的典型应用)。
**③Sapi**
Sapi全称是Server Application Programming Interface,也就是服务端应用编程接口,sapi通过一系列钩子函数,使得php可以和外围交互数据,这是php非常优雅和成功的一个设计,通过sapi成功的将php本身和上层应用解耦隔离,php可以不再考虑如何针对不同应用进行兼容,而应用本身也可以针对自己的特点实现不同的处理方式。后面将在sapi章节中介绍
**④上层应用**
这就是我们平时编写的php程序,通过不同的sapi方式得到各种各样的应用模式,如通过webserver实现web应用、在命令行下以脚本方式运行等等。
**构架思想:**
引擎(Zend)+组件(ext)的模式降低内部耦合
中间层(sapi)隔绝web server和php















 618
618











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









