







这周试着学了下Python
于是准备做个小爬虫练练手
——————————————————————————————
以下是爬取结果的分析:
爬取目标,百度 丽水学院 贴吧
截止至 2017年2月19号 15:30
爬了1855个网页
共计爬取到87535条主题贴数据(贴吧总主题数共92723个 在爬取过程中因不明原因而丢失了5188个主题贴)
以下文章将主题称为贴子,本文所指的贴子,全部是主题贴的意思
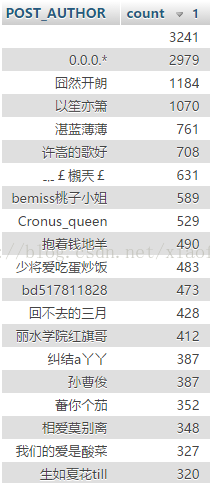
先来看下贴吧里发贴数量最多的人是谁吧
被回复最多的贴子是 2014年新生咨询帖 http://tieba.baidu.com/p/3120231970?pn=1 共有4402个回复信息
其次是 2016年新生咨询贴 欢迎小鲜肉们报考我校 http://tieba.baidu.com/p/4626377932?pid=92369872419&cid=103380480624#1033804806
共有3985个回复信息
接着来看下从2006年到2016年10年间的发贴情况
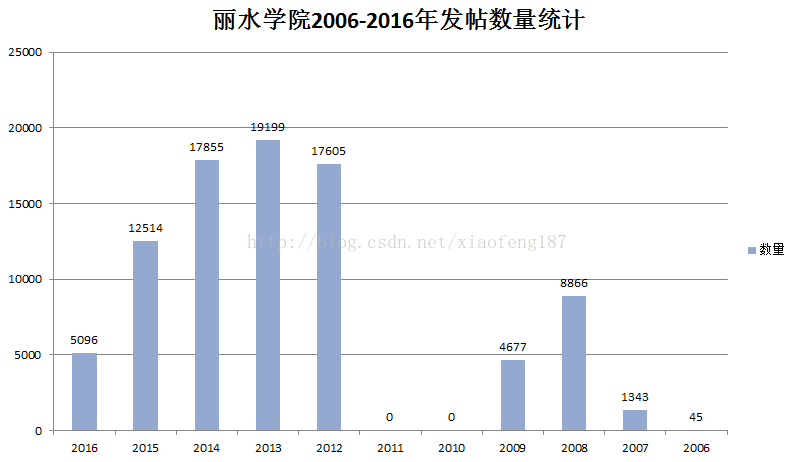
可以看出在2012-2015这三年发贴都比较多
2016年发贴数量极具减少,甚至少于2008年
最早的贴子,可以追溯到2006年的8月份
在2010与2011年这两年里没有一条贴子数据,一开始我以为是自己爬漏了数据,但在贴吧里翻找后,确实没有发现2010年与2011年的贴子
而且通过查找数据,发现这个断层是从 2009年的5月到 2012年的1月
期间究竟发生了什么,我也不太清楚,也许是贴吧暂时被关闭了?或者被管理删帖删完了? 不得而知
我们再来看下2016年与2015年每月的发帖情况,先看2016年
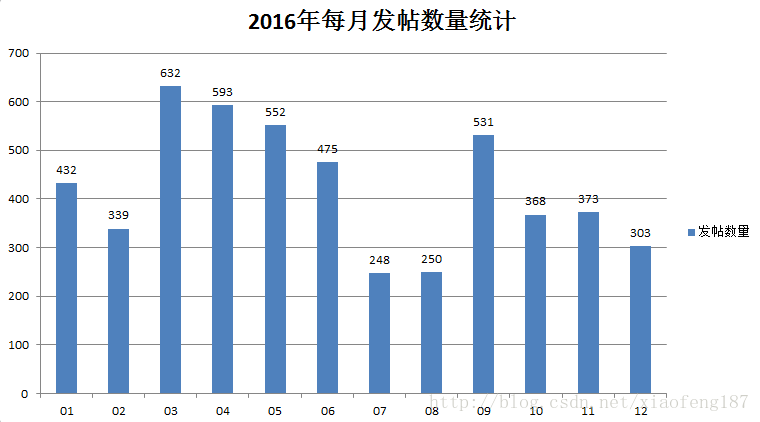
发帖数量最多的是3月份
9月份也算一个峰值,估计和新生入学有关吧
下面我们来看下2015年的发帖情况
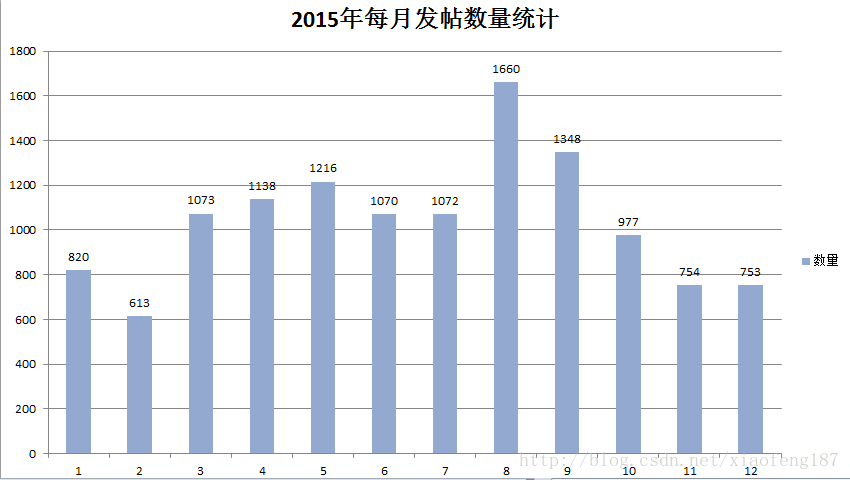
2015年发帖数量最多的是8月份,估计是和新生开学有关
对比2015年与2016年,发现寒暑假的时候贴吧发帖数量对比平时呈现下降趋势
自己想了些关键词来模糊匹配了下
以下是统计结果
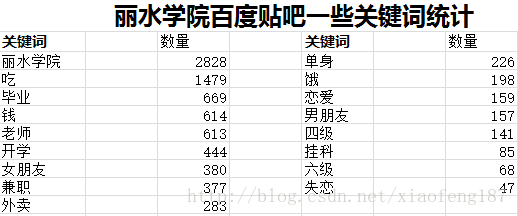
与“丽水学院” 有关的关键字最多,达到了2828个
和“吃”有关的话题还是很重要的!
“毕业” 比 “开学” 更容易成为话题
“女朋友” 提到的次数 大于 “男朋友”
“单身”比“四六级” 更重要
接下来是发帖最多的月份了
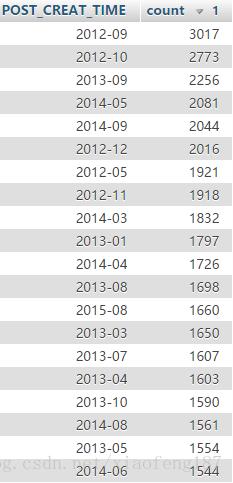
2012年的9月,是发帖最多的一个月
然后我们来看下一般发帖后,你会收到几个回复
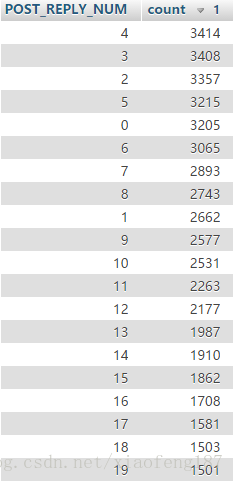
可以看出,发一个贴子,一般只有10个以下的回复
4个回复的贴子占最多,有3414个
还有3205个贴子没有人回复(0)
分析到此结束
——————————————————————————————————
好了,下面是技术实现部分
一开始打算匹配字符用正则表达式来实现,但是感觉太麻烦。
后来经Robinson推荐,选用lxml库里的 xPath 来实现
但是一直不成功
后来发现是坑爹的百度贴吧为了防止xpath,把帖子的主体部分给注释掉了,估计在浏览器里打开的时候用了某些
奇技淫巧把帖子还原了出来。
但是一般request请求并不会解析与执行 js里的内容,所以xpath 在这里是不能用的
于是又用回了正则表达式
匹配了好久,终于弄好了
然后又是连接数据库,写入数据库。。
但是某些帖子的标题里是含有emoji的
所以要把原本设置的 utf8 格式数据库 改为utf8mb4 格式
总之出了很多岔子。。
总结下,Python是一个很容易上手的语言,我周五下午才开始自学这个语言,当天晚上就写了一个抓去一个网页里所有图片的小程序。可以说,Python 入门简单,但想深入,比较难
下面是源代码地址:https://github.com/xiaoshidefeng/crawler/blob/master/postcrawler/PostCrawler.py
感兴趣的人可以拿去玩玩。。
再在这里贴下代码吧
import re
import urllib.request
import pymysql
#打开数据库连接
import sys
import time
print("连接数据库...")
db = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='', db='POSTINFO', charset='utf8mb4')
print("数据库连接成功")
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db.cursor()
#存在就删表重建
cursor.execute("DROP TABLE IF EXISTS POSTINFOS")
# 创建表
sql = """CREATE TABLE POSTINFOS (
ID INT NOT NULL AUTO_INCREMENT,
POST_REPLY_NUM TEXT,
POST_TITLE TEXT,
POST_AUTHOR TEXT,
POST_CREAT_TIME TEXT,
PRIMARY KEY (ID))"""
cursor.execute(sql)
def insert(replynum,posttitle,postauthor,creattime):
sqlorder = """INSERT INTO POSTINFO(POST_REPLY_NUM,POST_TITLE,POST_AUTHOR,POST_CREAT_TIME) VALUES ('"""+replynum+"'"+","+"'"+posttitle+"'"+","+"'"+postauthor+"'"+","+"'"+creattime+"')"
try:
# 执行sql语句
cursor.execute(sqlorder)
# 提交到数据库执行
db.commit()
print("数据库写入成功")
except:
# 如果发生错误
print("数据库写入失败")
if __name__ == "__main__":
pageurl = ''
pageurl = input("是否开始爬取数据(y/n)")
if(pageurl=='n'):
sys.exit(0)
pagenum = 0
initial_page = "http://tieba.baidu.com/f?kw=%E4%B8%BD%E6%B0%B4%E5%AD%A6%E9%99%A2&ie=utf-8&pn="
webheader = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/51.0.2704.63 Safari/537.36'
}
while pagenum<=92700:
newpage = initial_page + str(pagenum)
req = urllib.request.Request(url=newpage, headers=webheader)
webPage = urllib.request.urlopen(req)
contentBytes = webPage.read()
contentBytes = contentBytes.decode('UTF-8')
for onepost in set(re.findall( r'<div class="col2_left j_threadlist_li_left">(.*?)<div class="threadlist_detail clearfix">', str(contentBytes), re.S)): # 正则表达式找图
replyNumber = re.findall( r'title="回复">(.*?)</span>', onepost , re.S)
postTitle = re.findall( r'<a href=".*?" title="(.*?)" target="_blank"', onepost , re.S)
postAuthor = re.findall( r'title="主题作者:(.*?)"', onepost , re.S)
postCreatTime = re.findall( r'title="创建时间">(.*?)</span>', onepost , re.S)
print("回复时间:"+replyNumber[0])
print("帖子标题:" + postTitle[0])
print("帖子作者:" + postAuthor[0])
print("创建时间:" + postCreatTime[0])
insert(replyNumber[0],postTitle[0],postAuthor[0],postCreatTime[0])
print("---------------------------------")
print("开始休眠")
time.sleep(3)
print("休眠结束")
print("---------------------------------")
pagenum=pagenum+50
print("数据抓取完毕 程序运行结束")
# 关闭数据库连接
db.close()














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









