







1、不平衡数据集举例
- 网页中有很多广告,我们只会点击很少量我们感兴趣的广告。广告被点击 y=1 的样本要比 y=0的少很多。
- 信用卡欺诈,不会还款的只是少数
- 推荐系统,推荐的物品被购买的比例很低
2、解决方案
-
从数据的角度:抽样
数据不是不均衡嘛,通过抽样,让它变平衡就可以了。
-
从算法的角度:代价敏感学习
不改动数据,就不能只考虑 正确率,还需要添加别的评价指标。于是 考虑 不同误分类情况下,代价不一样(代价敏感的学习)。
以信用卡举例,将正例误认为负例,代价为1,而负例误认为正例,代价10,甚至100
3、抽样
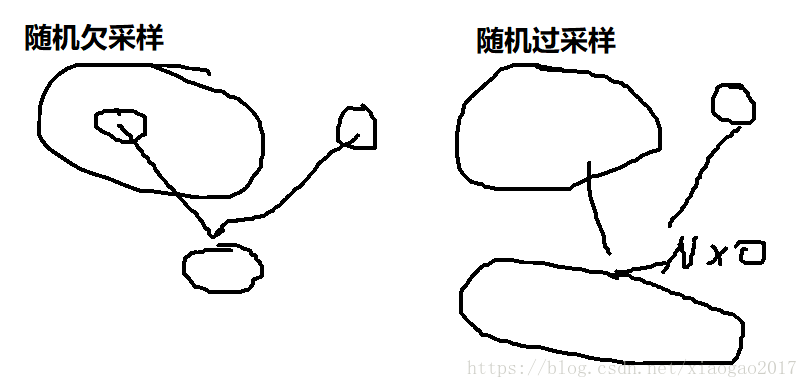
【1】随机欠采样
(1)抽取部分。所以,容易造成信息缺失。解决:集成学习
(2)又分为 有放回、无放回采样。
【2】随机过采样
(1)将少数数据,成倍数的扩大。所以,它的缺点就是容易过拟合。
(2)解决方案:不要随机复制,而是“插值”来为少数类合成新的样本:SMOTE
4、代价敏感学习
(1)核心要素:不同类型的误分类情况 导致的代价不一样。
(2)三种实现方式
- 预处理:
添加权重。如logistic回归中,class_weight(类别权重)、sample_weight(样本权重)
class_weight:只在分类中有,回归中没有这个参数。
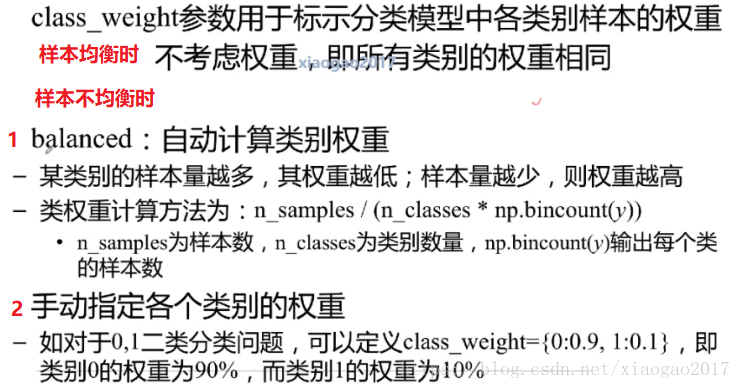
sample_weight:

- 中间处理
对学习模型本身做改造,使得它能够适应数据不平衡的情况。如支持向量机、决策树、神经网络。
- 后处理
让平均风险最小。
优点:任何学习算法都可以。
缺点:分类器输出值为概率。














 3592
3592











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









