







适合初学者阅读
引:
我们在做数据库开发用 pl sql 加工数据时,经常会遇到需要去除重复脏数据的情况,所以特地对此做个简单的总结,以便以后用到回顾。
重复数据分为 整条记录重复 和某个字段重复,删除目标分为重复数据全删除和重复数据删除留一条。
解决:
1 distinct 删除某字段所有重复的数据
假设要去重的字段为b 表为 a 先建个临时表a_temp,把select distinct a.b 的数据放入到a_temp,然后用delete from a where b in (select b from a_temp)
2 删除 某个字段重复数据 但是留下最小rowid的那条(即还留一条 且不重复)
delete from wh_td2 a
where a.rowid > (select min(b.rowid)
from wh_td2 b
where a.processinstid = b.processinstid)3 group by 删除某字段所有重复的数据
delete from wh_td2 a
where a.processinstid > (select b.processinstid
from wh_td2 b
group by b.processinstid having count(1)>1)4 row_number over() 删除某字段所有重复的数据
下面的语句是查询出 object_id 重复的语句,partition 分组 跟group by 分组的区别是
partition分组后 可以看到组内成员的信息,而group by
只能看到组的总统计信息。
select t.object_id,
row_number() over(partition by t.object_id order by t.object_id) del_flag
from scott.dba_objects_bak t;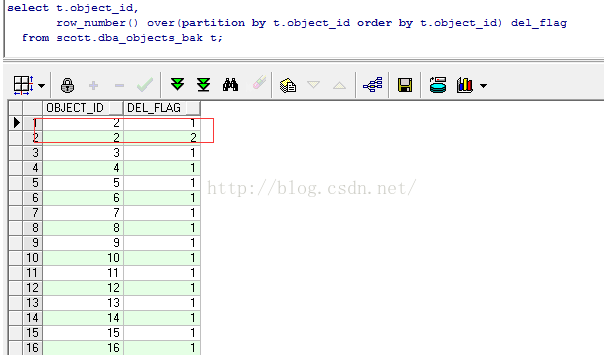
删除语句:
delete from scott.dba_objects_bak
where object_id in (select object_id
from (select t.object_id,
row_number() over(partition by t.object_id order by t.object_id) as del_flag
from scott.dba_objects_bak t)where del_flag > 1 );
5 row_number over() 删除某字段所有重复的数据(根据条件指定留一条)
如下图:根据 partition 分组后的object_id 若有重复的话 ,根据object_name 排序,
同样的object_id 可以识别出object_name最小的那条数据,即按指定条件 去重了 到时候加上del_flag=1 条件即可
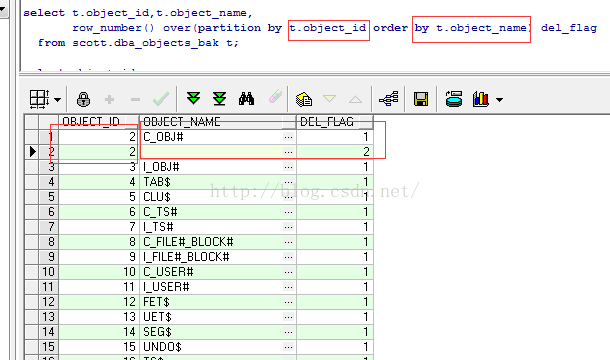
需要数据的话 把
del_flag=1 条件后的数据 放入到新建表即可。














 1432
1432











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









