







Flink 1.11支持与Hive表的Join,Flink 1.11官方文档如下图所示。
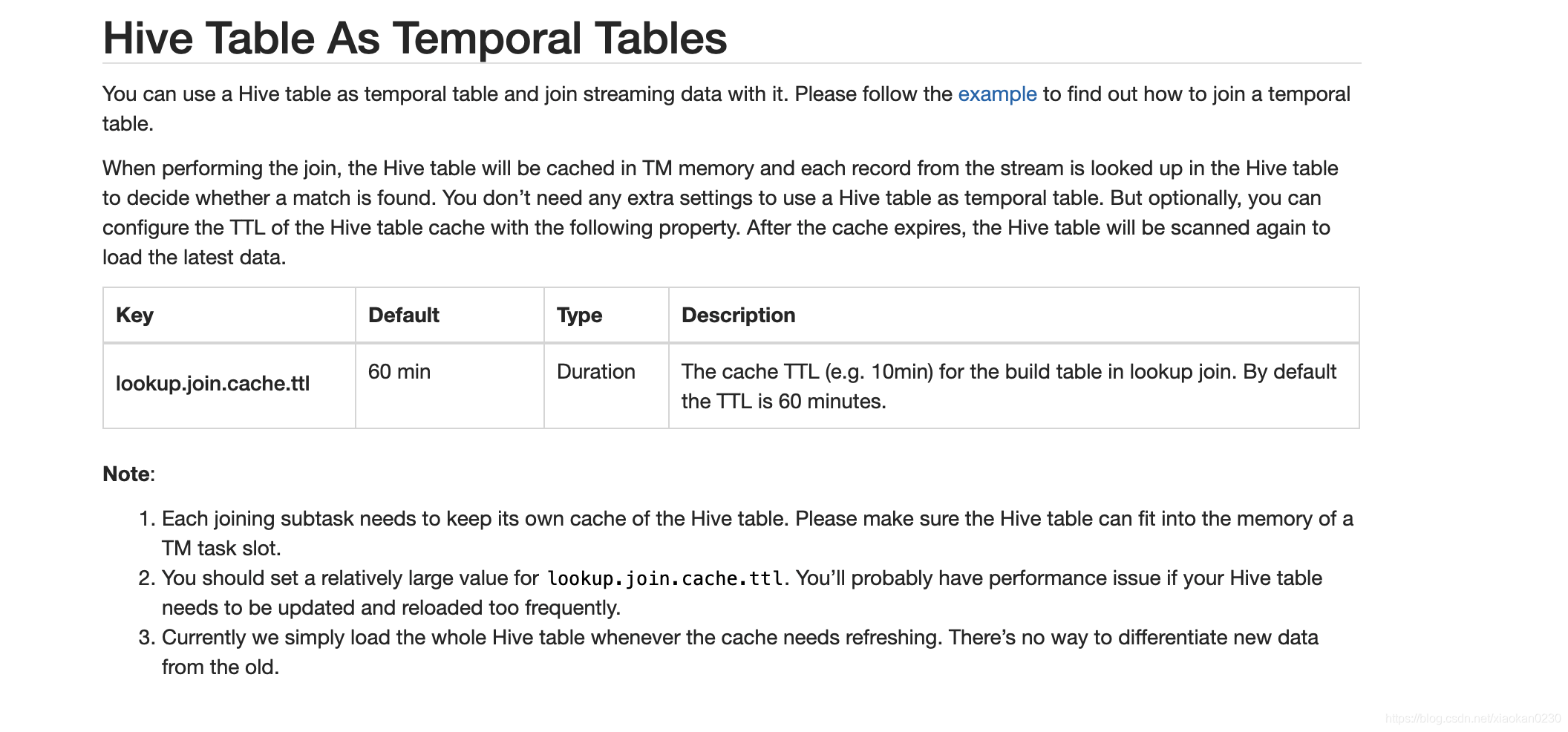
根据官方文档:
1.hive表会缓存到TM内存,所以join的hive表不宜太大。
2.根据lookup.join.cache.ttl 参数,flink会定期刷新hive缓存
而业务需求是Flink 读取kafka 和T+1更新的hive表,对于kafka的数据,只处理type字段在hive表中存在的数据。
首先尝试了如下Flink sql:
select a.* from flink_tab a where a.type in (select type from hive_tab);
这种sql 可以运行,也会读取hive表,但是从flink web ui 上可以看到,在读取hive表结束后,task就直接finish了。也不会定期刷新hive的数据,所以不符合我们的要求。
Flink 1.12 的文档中给出了标准的写法
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 621
621











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









